
Disentangling Trend Risk and Basis Risk with Functional Time Series

Abstract
:1. Introduction
2. Mortality Models for Multiple Populations
2.1. Augmented Common Factor Model
- ACF0 Model:In the ACF0 model, we assume the three mortality indices , , and are independent. Under this assumption, , , and can be modeled by the following expression:whereThere are eight parameters in this model, which include , and .
- ACF1 Model:The ACF1 model extends the ACF0 model to incorporate the correlations between different sequences. As a result, the Q matrix is no longer diagonal and we haveComparing to the ACF0 model, the number of unknown parameters increase from eight to eleven due to the addition of off-diagonal covariance parameters , , and .
- ACF2 Model:In the ACF2 model, we consider a more complicated autoregressive structure, the vector autoregressive (VAR) structure, for , , and sequences. We consider the simplest lag-1 vector autoregression model, the VAR(1) model, which can be expressed as follow:whereIn this model, a fully vectorized autoregressive structure is used. Even in the simplest case, the VAR(1) structure, the number of unknown parameters increase to eighteen. For a more complicated autoregressive VAR(p) () structure, the number of unknown parameters would be .
2.2. Product–Ratio Model
- The product model is defined bywhere is the square root of the product of and , is the average level at age x for the product model, m is the number of components being considered, is the error.In the product model, the quantity log() captures the average of (log-) mortality rates under different populations. The product of and is then used to reflect the evolution of (average) mortality at age x.
- The ratio model is defined bywhere is the square root of the ratio of and , is the average level at age x for the ratio model, n is the number of components being considered, is the error.In the ratio model, the quantity log() captures the deviation between the two populations. The product of and is then used to reflect the evolution of such deviation at age x.
3. Numerical Analysis
3.1. Data
3.2. Parameter Estimation
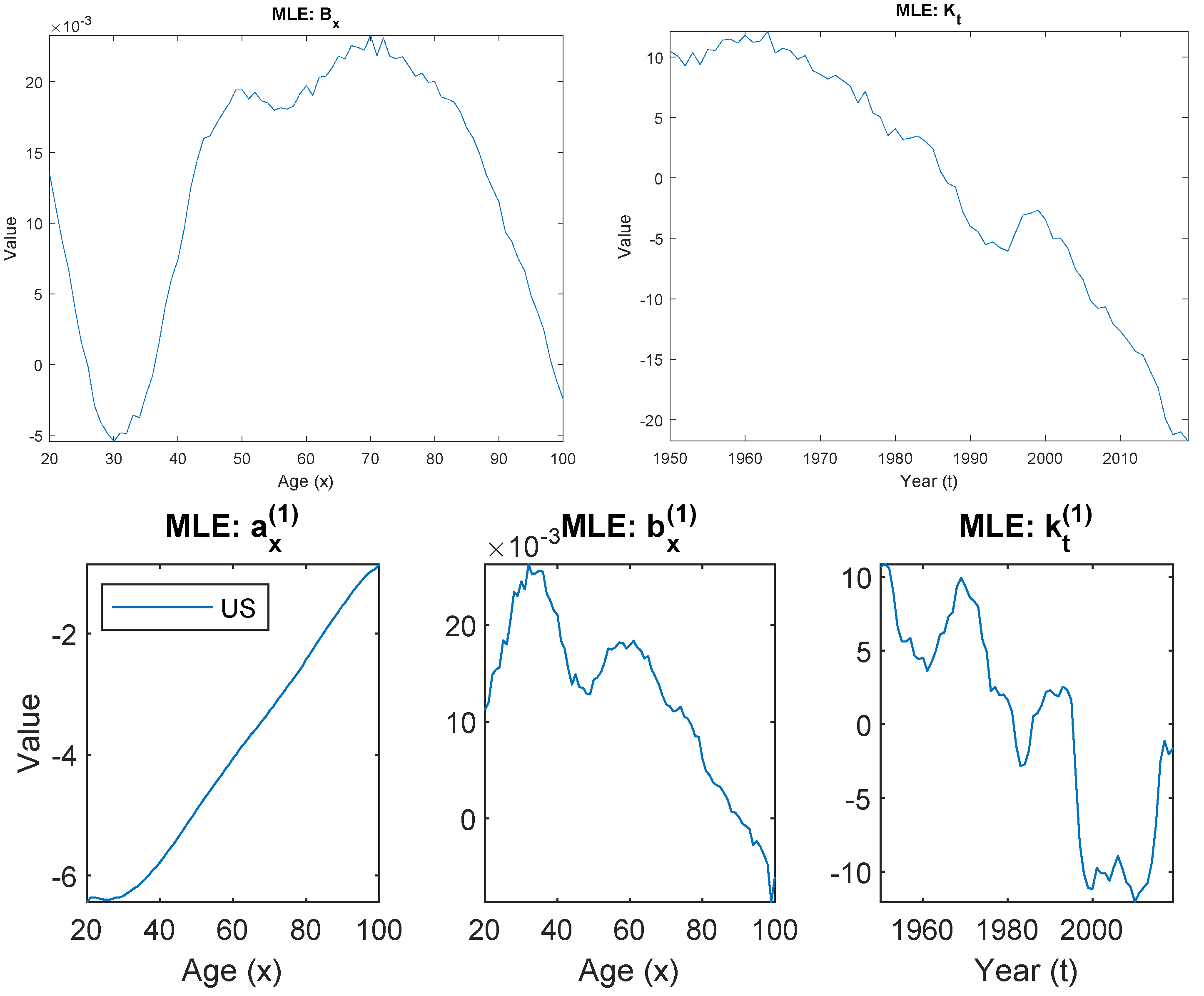
- The ACF ModelThe ACF model uses the common factor to capture the general mortality trend shared by all populations, and the population-specific factor to capture any deviation from the common trend. The estimated values of are therefore representing the co-movement of the mortality dynamic shared by the two countries, and representing the common age sensitivity to such co-movement.For the U.S. and Canada, although they are not identical, these two countries do share a great amount of similarities in economy, culture, living style, and healthcare system. As a result, the estimated levels as well as the population-specific factors and from the two countries are quite similar to each other, causing a vague distinction between trend risk and basis risk.
- The PR ModelThe PR model, on the other hand, decomposes trend risk and population basis risk by construction, meaning that these two risks are separated in the first place when the product model and ratio model are defined. As a result, the product model would be solely focusing on trend risk while the ratio model is solely focusing on basis risk, respectively, leading to a clear distinction between the two.
- –
- In the product model, the estimated represents the mean level of the general trend. It carries very similar shape to both of and in the ACF model. The estimated carries similar downward pattern as that in the ACF model, representing general mortality improvement overtime. For the estimated , it presents similar peak (around age 70) and trough (around age 30) to those shown in the ACF model, with different magnitudes.
- –
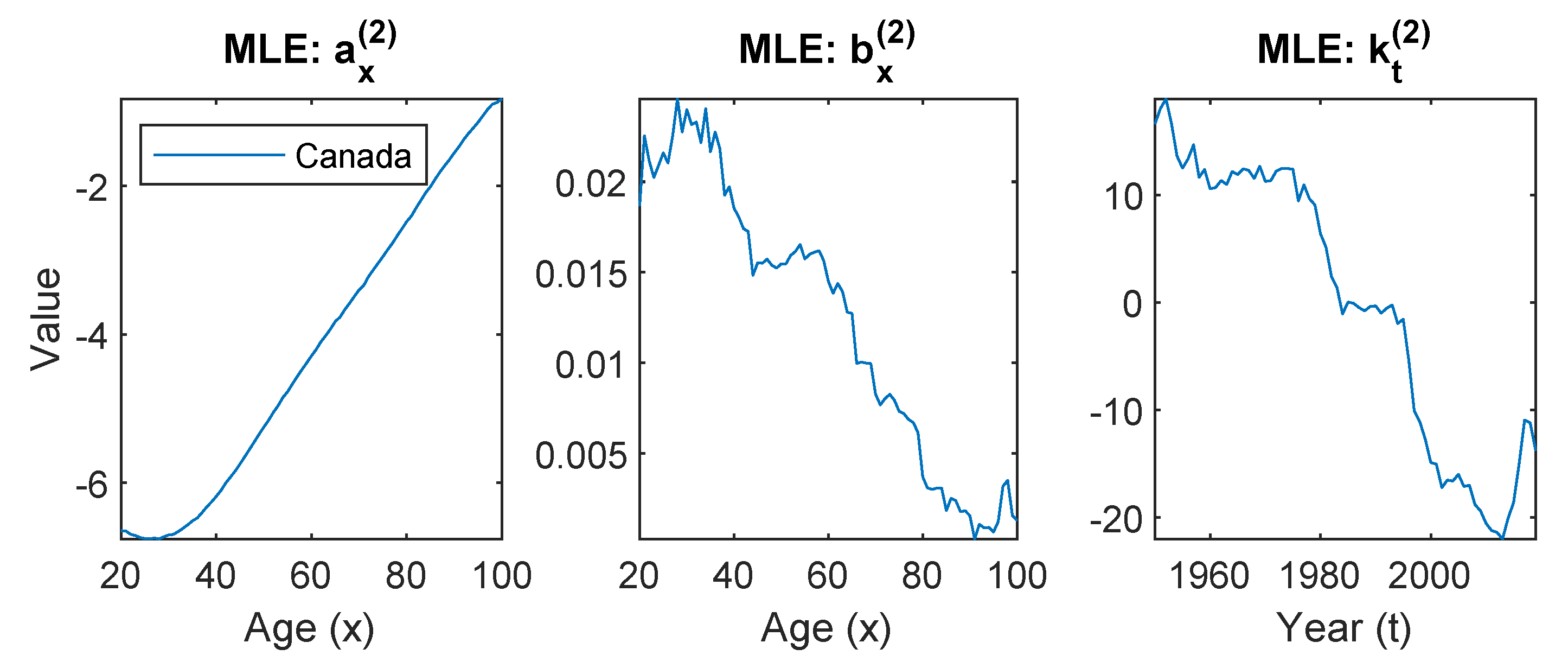
- In the ratio model, the estimated describes the difference in the mean level between the two populations. It can be easily observed in the pattern of that the biggest difference between the two populations lies in the working age males (from 25 to 65). The gap closes out quickly toward older ages.Besides the difference in the mean level, the ratio model further decomposes the difference between the U.S. and Canada into two components, and . The upward pattern of suggests that the differences between the two countries are getting bigger over time, and the pattern of shows such a gap is more significant in young adults around age 20. The remaining residuals not explained through the first component are then captured by the second component .
3.3. The Time-Series Process
3.3.1. Sample Cross-Correlation Matrix
3.3.2. AICs and Likelihood Ratio Test
3.3.3. Term Structure of Correlation
- ACF0 vs. ACF1Let us first focus on ACF0 model and ACF1 model. For these models, the only difference is the specification of Q matrix. To be more specific, In ACF0, the off-diagonal elements of Q matrix are zeros, while in ACF1, those elements are all non-zeros. The term structures of correlation under ACF0 and ACF1 have similar shape. However, a 10% increase is observed when the model does incorporate the off-diagonal covariance elements.
- ACF2 vs. ACF1 or ACF0The mortality indices in the ACF2 model follows a VAR(1) model where additional parameters are used to capture the cross-correlation among different period effects. Comparing to ACF1 and ACF0, a dramatic change of shape (the black dotted line) is observed for the ACF2, reflecting those additional interactions.
- PR0 vs. PR1 vs. PR2Within the PR framework, the resulting term structures of correlation from the three models carry two features. The first feature is related to the magnitudes of the lines, with the values being greater for more complex models. The second feature is related to the shape of the lines, where all three lines yield very similar patterns. This finding is consistent with the observations we made in Section 3.3.1 and Section 3.3.2. It also justifies the argument made by Hyndman et al. (2013) that the latent factors are uncorrelated in the PR model.
- PR vs. ACFSince the two models have different model specification, the shape of the curve may not be the same. For the PR model, the three variants yield similar term structure of correlations, while for the ACF model, the ACF0 variant and ACF1 variant have omitted the cross-correlation between different latent states, and thereby not adequately fitting the data and leading to the worst term structure of correlations. When the full VAR structure is used in the ACF2 variant, its term structure of correlation would be similar to those in the PR framework.
4. Hedge Performance
4.1. Basic Set Up
4.2. Illustration of Hedge Performance
- The liability is a life annuity sold to individuals aged 70 () 20 years from now (). The liability is linked to population 1, the U.S. males. The maximum age is set to be .
- The q-forward has a reference age of 65 () and will matures 20 years from now (). The q-forward is linked to population 2, the Canadian males.
- The interest rate is assumed to be 1% per annum.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Partial Derivatives of Liability and Hedging Instrument
Appendix A.1. The ACF Model:
Appendix A.2. The PR Model:
Appendix B. Simulation Procedure
- Simulate M sample paths of and . We denote these simulated paths as , for . Accordingly, for each simulated path , the values of the corresponding state variables are and .
- For each simulated path , , we project the life table at time , based on the simulated and . The methodology of how we project the life table is summarized as follows:
- 1.
- Based on and , we first compute the central death rate of an individual aged x, :
- –
- ACF Model
- –
- PR Model
- 2.
- Then we compute the death probability , based on the value of . Throughout this study, we assume constant force of mortality. Therefore, can be computed through the following equation:and accordingly
- 3.
- We use to denote the probability that an individual aged x at time survives to age , for a particular path . The survival probability is computed as
- For each projected life table, we calculate the value of the life annuity , which is
| 1 | Data source: Human Mortality Database (HMD). |
| 2 | For an expanded data set, the same MLE method can be used. |
References
- Cairns, Andrew J. G., David Blake, and Kevin Dowd. 2006. A two-factor model for stochastic mortality with parameter uncertainty: Theory and calibration. Journal of Risk and Insurance 73: 687–718. [Google Scholar] [CrossRef]
- Cairns, Andrew J. G., David Blake, Kevin Dowd, Guy D. Coughlan, and Marwa Khalaf-Allah. 2011. Bayesian stochastic mortality modelling for two populations. ASTIN Bulletin: The Journal of the IAA 41: 29–59. [Google Scholar]
- Cairns, Andrew J. G., David Blake, Kevin Dowd, Guy D. Coughlan, David Epstein, Alen Ong, and Igor Balevich. 2009. A quantitative comparison of stochastic mortality models using data from england and wales and the united states. North American Actuarial Journal 13: 1–35. [Google Scholar] [CrossRef]
- Cairns, Andrew J. G., Malene Kallestrup Lamb, Carsten Rosenskjold, David P. Blake, and Kevin Dowd. 2019. Modelling Socio-Economic Differences in the Mortality of Danish Males Using a New Affluence Index. London: Pensions Institute, Cass Business School, City University London. [Google Scholar]
- Chen, Hua, Richard MacMinn, and Tao Sun. 2015. Multi-population mortality models: A factor copula approach. Insurance: Mathematics and Economics 63: 135–46. [Google Scholar] [CrossRef]
- Dong, Yumo, Fei Huang, Honglin Yu, and Steven Haberman. 2020. Multi-population mortality forecasting using tensor decomposition. Scandinavian Actuarial Journal 8: 754–75. [Google Scholar] [CrossRef]
- Dowd, Kevin, Andrew J. G. Cairns, David Blake, Guy D. Coughlan, and Marwa Khalaf-Allah. 2011. A gravity model of mortality rates for two related populations. North American Actuarial Journal 15: 334–56. [Google Scholar] [CrossRef]
- Graziani, George. 2014. Longevity risk—A fine balance. Journal of Retirement 1: 35–37. [Google Scholar]
- Hunt, Andrew, and David Blake. 2020. Identifiability in age/period mortality models. Annals of Actuarial Science 14: 461–99. [Google Scholar] [CrossRef]
- Hyndman, Rob. 2023. Demography: Forecasting Mortality, Fertility, Migration and Population Data. R Package Version 2.0. Available online: https://CRAN.R-project.org/package=demography (accessed on 30 September 2023).
- Hyndman, Rob J., Heather Booth, and Farah Yasmeen. 2013. Coherent mortality forecasting: The product-ratio method with functional time series models. Demography 50: 261–83. [Google Scholar] [CrossRef] [PubMed]
- Lee, Ronald D., and Lawrence R. Carter. 1992. Modeling and forecasting u. s. mortality. Journal of the American Statistical Association 87: 659–71. [Google Scholar]
- Li, Johnny Siu-Hang, and Yanxin Liu. 2020. The heat wave model for constructing two-dimensional mortality improvement scales with measures of uncertainty. Insurance: Mathematics and Economics 93: 1–26. [Google Scholar] [CrossRef]
- Li, Nan, and Ronald Lee. 2005. Coherent mortality forecasts for a group of populations: An extension of the lee-carter method. Demography 42: 575–94. [Google Scholar] [CrossRef] [PubMed]
- Lyu, Pintao, Anja De Waegenaere, and Bertrand Melenberg. 2021. A multipopulation approach to forecasting all-cause mortality using cause-of-death mortality data. North American Actuarial Journal 25: S421–56. [Google Scholar] [CrossRef]
- Michaelson, Avery, and Jeff Mulholland. 2014. Strategy for increasing the global capacity for longevity risk transfer: Developing transactions that attract capital markets investors. Journal of Alternative Investment 17: 18–27. [Google Scholar] [CrossRef]
- Plat, Richard. 2009. On stochastic mortality modeling. Insurance: Mathematics and Economics 45: 393–404. [Google Scholar] [CrossRef]
- Renshaw, Arthur E., and Steven Haberman. 2006. A cohort-based extension to the lee-carter model for mortality reduction factors. Insurance: Mathematics and Economics 38: 556–70. [Google Scholar] [CrossRef]
- Russolillo, Maria, Giuseppe Giordano, and Steven Haberman. 2011. Extending the lee–carter model: A three-way decomposition. Scandinavian Actuarial Journal 2011: 96–117. [Google Scholar] [CrossRef]
- Tsai, Cary Chi-Liang, and Ying Zhang. 2019. A multi-dimensional bühlmann credibility approach to modeling multi-population mortality rates. Scandinavian Actuarial Journal 5: 406–31. [Google Scholar] [CrossRef]
- Zhou, Rui, Guangyu Xing, and Min Ji. 2019. Changes of relation in multi-population mortality dependence: An application of threshold vecm. Risks 7: 14. [Google Scholar] [CrossRef]
- Zhou, Rui, Yujiao Wang, Kai Kaufhold, Johnny Siu-Hang Li, and Ken Seng Tan. 2014. Modeling period effects in multi-population mortality models: Applications to solvency ii. North American Actuarial Journal 18: 150–67. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ACF Model | P/R Model | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Lag 0 | |||||||||||
| 1.0000 | 0.1797 | 0.2752 | + | . | . | 1.0000 | –0.0405 | 0.3563 | + | . | . |
| 0.1797 | 1.0000 | 0.9426 | . | + | + | –0.0405 | 1.0000 | 0.0180 | . | + | . |
| 0.2752 | 0.9426 | 1.0000 | . | + | + | 0.3563 | 0.0180 | 1.0000 | . | . | + |
| Lag 1 | |||||||||||
| 0.0668 | 0.2995 | 0.3395 | . | . | . | 0.2952 | –0.0118 | 0.2574 | . | . | . |
| 0.1238 | 0.9612 | 0.8934 | . | + | + | –0.0062 | 0.9484 | –0.0333 | . | + | . |
| 0.2453 | 0.9377 | 0.9688 | . | + | + | 0.3023 | 0.0684 | 0.8464 | . | . | + |
| Lag 2 | |||||||||||
| 0.3110 | 0.3811 | 0.3538 | . | . | . | 0.2163 | –0.0193 | 0.3509 | . | . | . |
| 0.0895 | 0.8990 | 0.8371 | . | + | + | –0.0487 | 0.9092 | –0.0683 | . | + | . |
| 0.2414 | 0.9178 | 0.9348 | . | + | + | 0.2803 | 0.1131 | 0.8269 | . | . | + |
| Lag 3 | |||||||||||
| 0.1718 | 0.3854 | 0.3461 | . | . | . | 0.0640 | –0.0482 | 0.3242 | . | . | . |
| 0.0817 | 0.8311 | 0.7815 | . | + | + | –0.0924 | 0.8635 | –0.1339 | . | + | . |
| 0.2139 | 0.8959 | 0.9005 | . | + | + | 0.2535 | 0.1753 | 0.7405 | . | . | + |
| Lag 4 | |||||||||||
| 0.0070 | 0.4049 | 0.3551 | . | + | . | 0.1223 | –0.0878 | 0.3519 | . | . | . |
| 0.0786 | 0.7685 | 0.7310 | . | + | + | –0.1899 | 0.8075 | –0.1704 | . | + | . |
| 0.1759 | 0.8736 | 0.8643 | . | + | + | 0.1557 | 0.2055 | 0.6686 | . | . | + |
| Lag 5 | |||||||||||
| 0.1093 | 0.3565 | 0.2957 | . | . | . | 0.0949 | –0.0788 | 0.3239 | . | . | . |
| 0.0840 | 0.7078 | 0.6851 | . | + | + | –0.2548 | 0.7553 | –0.2155 | . | + | . |
| 0.1583 | 0.8397 | 0.8243 | . | + | + | 0.1600 | 0.2280 | 0.6172 | . | . | + |
| ACF0 | ACF1 | ACF2 | PR0 | PR1 | PR2 | |
|---|---|---|---|---|---|---|
| 8 | 11 | 18 | 8 | 11 | 18 | |
| –338.5748 | –297.5167 | –285.9478 | –144.2575 | –141.3853 | –135.7845 | |
| AIC | 693.1496 | 617.0334 | 607.8957 | 304.5149 | 304.7706 | 307.5689 |
| Restricted Model | Unrestricted Model | p-Value |
| ACF0 | ACF1 | 0.0000 |
| ACF0 | ACF2 | 0.0000 |
| ACF1 | ACF2 | 0.0016 |
| PR0 | PR1 | 0.1247 |
| PR0 | PR2 | 0.0756 |
| PR1 | PR2 | 0.1301 |
| Simulation | Simulation | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Calibration | Model | ACF0 | ACF1 | ACF2 | Calibration | Model | PR0 | PR1 | PR2 |
| ACF0 | 52.6756% | 61.7846% | 77.8786% | PR0 | 68.7645% | 68.2410% | 73.0943% | ||
| ACF1 | 52.6756% | 61.7846% | 77.8786% | PR1 | 68.7645% | 68.2410% | 73.0943% | ||
| ACF2 | 47.1669% | 53.5626% | 70.2547% | PR2 | 68.6478% | 68.1193% | 72.9632% | ||
| Max diff. = 30.7117% | Max diff. = 4.9750% | ||||||||
| Calibration | Simulation | Calibration | Simulation | ||||||
| Model | ACF0 | ACF1 | ACF2 | Model | PR0 | PR1 | PR2 | ||
| ACF0 | 182.9765 | 182.9765 | 182.9765 | PR0 | 146.9599 | 146.9599 | 146.9599 | ||
| ACF1 | 182.9765 | 182.9765 | 182.9765 | PR1 | 146.9599 | 146.9599 | 146.9599 | ||
| ACF2 | 141.4138 | 141.4138 | 141.4138 | PR2 | 146.5070 | 146.5070 | 146.5070 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Li, J.S.-H. Disentangling Trend Risk and Basis Risk with Functional Time Series. Risks 2023, 11, 208. https://doi.org/10.3390/risks11120208
Liu Y, Li JS-H. Disentangling Trend Risk and Basis Risk with Functional Time Series. Risks. 2023; 11(12):208. https://doi.org/10.3390/risks11120208
Chicago/Turabian StyleLiu, Yanxin, and Johnny Siu-Hang Li. 2023. "Disentangling Trend Risk and Basis Risk with Functional Time Series" Risks 11, no. 12: 208. https://doi.org/10.3390/risks11120208
APA StyleLiu, Y., & Li, J. S.-H. (2023). Disentangling Trend Risk and Basis Risk with Functional Time Series. Risks, 11(12), 208. https://doi.org/10.3390/risks11120208