1. Introduction
Risk measures or premium calculation principles are statistical tools for the calculations of the insurance price corresponding to a risk in the actuarial literature; see
Fischer et al. (
2018) for a discussion on recent risk measures with application to credit risk. They have also been developed to assess the reserve capital required to cover unexpected losses and ensure financial stability. For example, the value at risk (VaR) at level
p is a quantile-based risk measure such that
,
, where
X is a non-negative loss or risk random variable with a cumulative distribution function (cdf)
The conditional tail expectation (CTE) is another risk measure defined as the average value of losses beyond the
value, i.e.,
Another popular premium principle is the Gini shortfall; see
Furman et al. (
2017) and
Eugene et al. (
2021). It is given by
where
is the loading parameter and
It is said to be more comprehensive as it combines the average serenity and the variability of a loss distribution tail.
Artzner et al. (
1997,
1999) addressed the desired behaviors and characteristics of risk measures. More specifically, here, we are concerned about the coherency. Let
be a risk measure associated with a loss random variable
A risk measure is coherent if it satisfies the following four axioms: (i) monotonicity: if
; (ii) subadditivity:
; (iii) positive homogeneity: for any
; (iv) translation invariance: for any
. Subadditivity specifies that a diversified portfolio reduces the overall risk profile. It is well known that the VaR does not satisfy the subadditivity axiom and, hence, is not coherent; see
Denuit et al. (
2005) for examples. In contrast, the CTE developed by
Rockafellar and Uryasev (
2002) is a coherent risk measure.
A distortion risk measure introduced by
Denneberg (
1994) calculates the insurance premium by transforming or distorting the accumulative distribution function of the loss variable. A distortion function is a non-decreasing function mapping the unit interval
to the unit interval such that
and
. The risk-adjusted distortion risk measure denoted by
or
for a continuous loss
X is given by
where the survival function
,
and
is the first derivative of
. Based on (
1), the distortion risk measure
can be interpreted as the mean of a random variable Y with cdf
. It reflects the notion in
Yaari (
1987) that probabilities are liable to be in the decision-maker’s perception (see
Pflug 2009) and that the distortion risk can be seen as the expected utility with a utility function of
with respect to the loss distribution. According to (2), the distortion risk measure is also a spectral risk measure, which is a quantile-based risk measure that takes the form of
where
and
The function
represents the user’s risk attitude; see
Acerbi (
2002) and
Dowd et al. (
2008). For the applications of distortion risk measures, see
Sereda et al. (
2010) and
Bihary et al. (
2020).
Wang (
1995,
2000) proposed two classes of distortion operators or transformation for pricing financial and insurance risk: power distortion or the proportional hazards transform defined by
and the Wang transform defined by
where
is the standard normal cdf and
is a scalar. The power distortion brings about the dual-power distortion function
It is shown that, if the distortion function is concave, then the resulting risk measure is coherent.
Wirch and Hardy (
1999) considered the beta distribution distortion given by
where
. Note that the beta distortion is concave when
and
The distortion utilizes the beta probability density function (pdf) as its generating function. Setting
the beta distortion yields the dual-power distortion. It is the power distortion when
Applying the framework in (
3),
Samanthi and Sepanski (
2018) proposed new classes of distortion functions by replacing the beta pdf with other pdf’s.
Yin and Zhu (
2018) presented three methods for constructing new classes of distortion functions: compositing two distortions, convex linear mixing of distortions, and employing copula cdf.
Minasyan (
2020) studied two new classes of financial risk measures defined by the power function of the VaR and CTE.
Minasyan (
2021) introduced the concept of variance distortion, i.e., distorting the variance instead of the mean, by using popular existing distortion functions that yield the VaR and CTE. More references can be found in
Minasyan (
2021).
Let
be independent and identically distributed (iid) loss random variables with the pdf, cdf, and survival function given by
f,
F, and
S, respectively. Grounded by (2),
Jones and Zitikis (
2003) and
Jones and Zitikis (
2007) proposed the following empirical L-estimator, which is a linear combination of order statistics with weights being the score function
The estimator is nonparametric, intuitive, and simple to implement. Due to the scarcity of data in the tails for a heavy-tailed loss, bias-correction methods have been proposed. For example,
Brahimi et al. (
2012) introduced a new reduced-biasestimator for heavy-tailed losses; see the references therein for more bias-correction methods.
The organization of the paper is as follows. In
Section 2, we stage the method employed to produce new distortion functions and demonstrate the method by employing exponentiated exponential and Gompertz distributions as the generating functions. In
Section 3, closed-form expressions for distortion risk measures are derived for uniform, exponential, Lomax, and Weibull loss distributions. Numerical and graphical comparisons are also included. In
Section 4, we propose a plug-in, empirical-distribution-based estimator of the risk measures. The estimator does not require parametric assumptions on the loss distribution. Simulations were conducted to compare and demonstrate the performance of the proposed estimator. Concluding remarks are made in
Section 5.
2. Proposed Methods and Distortions
We first advance the method, similar to those in
Aldhufairi and Sepanski (
2020) and
Aldhufairi et al. (
2020), for constructing a distortion. The main idea stems from the fact that a cdf with a domain of the unit interval by definition is also a distortion function.
Let
Y be a non-negative continuous random variable with cdf
Consider the following two transformations of the random variable
Y:
The transformed random variables
W and
both have a support of
, and their respective cdfs are given by
for
Both
and
are continuous and non-decreasing with
and
Let
be the pdf of
Note that
in (7) can also be derived from the framework:
motivated by the framework in (
3); see
Samanthi and Sepanski (
2018).
Since W or is continuous, its quantile function or inverse cdf is non-decreasing and may also potentially serve as a distortion for the purpose of constructing new risk measures. While the cdfs and inverse cdfs of W and are distortions, they must be concave to produce coherent risk measures. To ensure the concavity, we restricted the parameter spaces where the second derivative of the functions is non-positive.
We next showcase four new admissible distortions deriving from the cases when Y has an exponentiated exponential distribution and a Gompertz distribution. A distortion function is said to be admissible if it yields coherent risk measures, i.e., if it is concave. The parameter space over which the distortion is concave is presented for each of the four distortions.
2.1. Distortions via Exponentiated Exponential Distribution
Let
Y be an exponentiated exponential random variable. Its cdf is
where
,
. We refer to cdf
G as the generating distribution. Then, the cdfs of the transformed variables in (
6) are given by
The respective inverse cdfs of
and
are
In this case,
and
are of the same functional form with different parameterizations, so are
and
. The distortion
can also be formulated with the Kumaraswamy pdf instead of the beta pdf in (
3), which was studied in
Samanthi and Sepanski (
2018). The distortion
will be cited as the Kumaraswamy distortion below.
Since the support of transformed variables in (
5) is the unit interval, we will refer to
as the unit-exponentiated exponential (UEE) distortion below. Note that the power and dual-power distortions are special cases of the beta distortion in (
3), the Kumaraswamy and UEE distortions.
Lemma 1. The Kumaraswamy distortion is concave on I if and
The notations of the parameters in (
8) or
are changed in the following lemma so that, throughout the paper,
consistently represents a parameter with a constraint of greater than or equal to one.
Lemma 2. The UEE distortion is concave on I if and
Proof. The first and second derivatives of
with respect to
w are given by
respectively. If
since
In this case, if
is non-positive for all
w in
I. If
there is no
value such that
for all
w in
I. □
2.2. Distortions via Gompertz Distribution
Let
Y be a Gompertz random variable with cdf
,
. The resulting distortions
and
from (
6) and (7) and their inverse functions are
The first and second derivatives of
are, respectively,
There exists no admissible parameter space for
and
on which
is non-positive for all
. Similarly, one can show that the same conclusion holds for
The cdfs of the transformed variables defined in (
5) are distortions, but may not be admissible, e.g.,
When
G is the Weibull cdf, the resulting distortions are not admissible, though not shown here.
In what follows, the distortion will be called the unit Gompertz (UG) distortion and the unit Gompertz quantile (UGQ) distortion.
Lemma 3. The UG distortion is concave on I if and .
Proof. The respective first and second derivatives of
are given by
The second derivative is non-positive if since for and Therefore, if , then is concave. □
Lemma 4. The UGQ distortion is concave on I if and .
Proof. The respective first and second derivatives of
are given by
Since for the second derivative is non-positive if That is, when , then is concave on I. □
In summary, applying the exponential transformation to negative random variables with the exponentiated exponential and Gompertz distributions, we obtain four new admissible distortions.
Table 1 summarizes the four lemmas in this section.
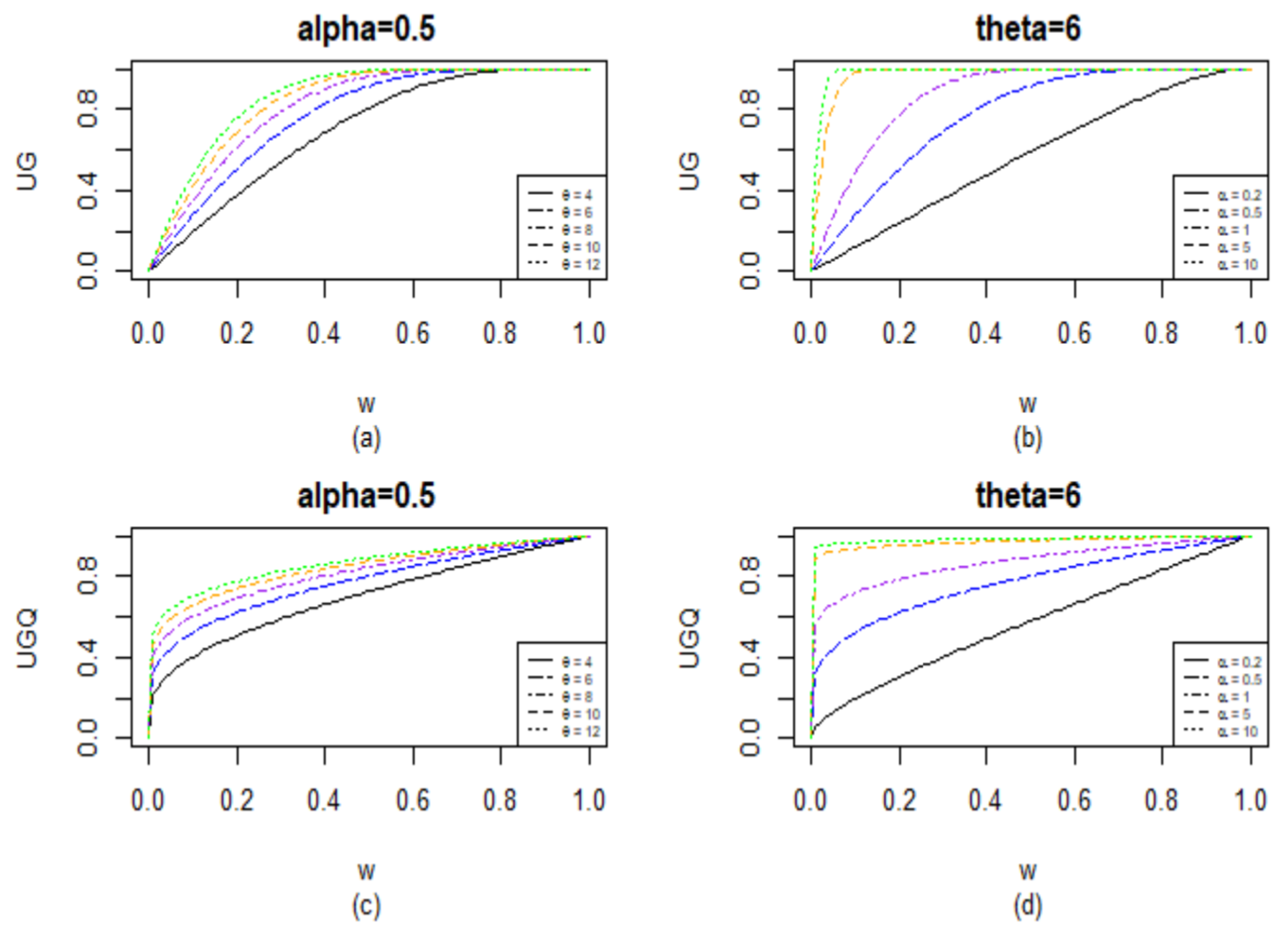
Figure 1 shows how the two new distortions UG and UGQ behave at varying
and
values. Assuming that a risk-neutral agent would not distort the survival distribution,
Belles-Sampera et al. (
2016) used the area under a distortion function as a measure of global risk attitude. The area under a concave curve on [0, 1] is always greater than half, and a larger area indicates a higher level of global risk-tolerant attitude.
For the UG distortion, when Graph (a) indicates that a higher level of global risk-tolerant attitude and risk aversion is associated with a larger value. Setting (Graph (b)), a larger value corresponds to a larger level of global risk-tolerant attitude. When and , the area under the curve is close to 1, which reflects a very conservative global risk-tolerant attitude. Similarly, for the UGQ distortion, the choice of a larger at a fixed value or a larger at a fixed value reflects a higher level of global risk-tolerant attitude.
From (2), the derivative of the distortion , i.e., the slope of the tangent line to a distortion curve at w, is the assigned weight to the loss of . For example, when , at a small extreme survival value w, the slopes of the tangent lines to the curves increase as increases. That is, a greater weight is assigned to a large extreme loss as increases, indicating a higher level of risk aversion. One, therefore, expects to obtain a larger distortion risk measure for a larger ; see Tables 2 and 3 below
5. Concluding Remarks
The framework employed in the paper was motivated by the fact that a cumulative distribution function with unit interval support is a distortion function. It utilizes an exponential transformation of a non-negative random variable, whose distribution function is named the generating distribution, to a random variable with a support of the unit interval. There are other functions, for instance that can transform a non-negative random variable into a variable with unit interval support.
There are numerous candidates for the role of the generating distribution. The generating distributions employed here included the exponentiated exponential and Gompertz distributions. The proposed framework opens the door to a world of new distortion functions. We demonstrated that the framework also produces some existing well-known distortions, e.g., power and dual-power distortions. We developed two new distortion functions and derived admissible spaces on the parameters so that the resulting distortion risk measures were coherent. The distortion risk measures for uniform, exponential, Lomax, and Weibull losses were computed. The effects of the distortion parameters on the risk measures and risk tolerance attitudes were examined by graphs and closed-form expressions of risk measures. As
Wang and Xu (
2023) pointed out, there has been little discussion on which distortion risk measures at hand should be chosen. It would be of great interest to further explore how to tune the parameters to better reflect or approximate decision-maker’s risk preferences and various risk attitudes.
We proposed a plug-in estimator for the distortion risk measure and ran simulations to compare it with the empirical L-estimator in
Jones and Zitikis (
2003). It appeared that the plug-in estimator, just like the empirical L-estimator, suffered biases when losses followed heavy-tailed or Pareto-liked distributions.
Kim (
2010) showed that, when the distortion function is concave, L-estimates of distortion risk measures are negatively biased, and the bias can be corrected through the bootstrapping for a continuous loss distribution. The negative biases in the L-estimates were demonstrated in our simulation results. While this is not the case for the proposed plug-in estimate, the simulation results indicated that the proposed plug-in estimates seemed to also perform poorly for heavy-tailed losses.
Brahimi et al. (
2012) proposed an alternative estimators of L-functionals for heavy-tailed losses by means of extreme value theory and established their asymptotic normality.
Abdelaziz (
2015) established a new estimator using an approximation of the tail of the loss distribution. The asymptotic distribution of the proposed plug-in estimator will be investigated first, and bias correction estimators may then ensue in the future.
Kim (
2010) proposed to correct the bias through bootstrapping for a continuous loss distribution.
Brahimi et al. (
2012) proposed alternative estimators of L-functionals for heavy-tailed losses by means of extreme value theory and established their asymptotic normality.
Abdelaziz (
2015) established a new estimator using an approximation of the tail of the loss distribution. The asymptotic distribution of the proposed plug-in estimator will be investigated first, and bias correction estimators may then ensue in the future.






{kind=link}
{kind=link}
{kind=link}
{kind=link}