
A Semi-Static Replication Method for Bermudan Swaptions under an Affine Multi-Factor Model

Abstract
:1. Introduction
2. Mathematical Background
2.1. Model Formulation
2.2. The Bermudan Swaption Pricing Problem
3. A Semi-Static Replication for Bermudan Swaptions
3.1. The Algorithm
| Algorithm 1 The algorithm for a Bermudan swaption |
|
3.1.1. Sample the Independent Variables
- Discretize the SDE of the risk factor and sample by the means of an Euler or Milstein scheme. Make sure that a sufficiently coarse time-stepping grid is used, which includes the M monitor dates. See, for example, Kloeden and Platen (2013) for details.
- The asset should be a square integrable random variable that is measurable, taking values in .
- The risk-neutral price of should only be dependent on the current state of the risk factor and be almost surely unique; that is, the mapping should be continuous and injective. This is required to guarantee a well-defined parametrization of the option value.
3.1.2. Regress the Option Value against an IR Asset
3.1.3. Compute the Continuation Value
3.2. A Neural Network Approach to
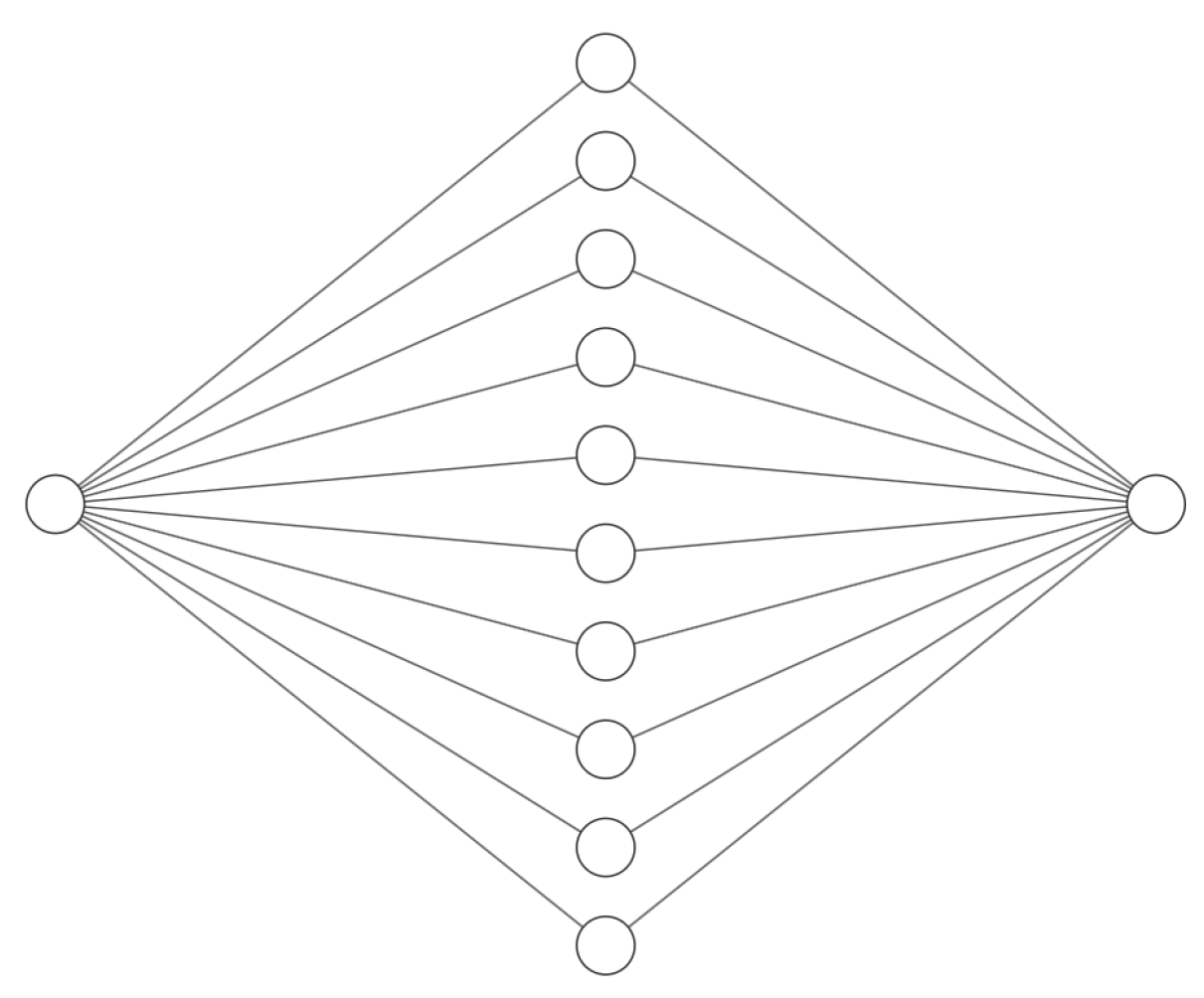
3.2.1. The 1-Factor Case
- The first layer consists of a single node and corresponds to the discount bond price, which serves as input. It is represented by the left node in Figure 1. The hidden layer has hidden nodes, represented by the center layer in Figure 1. The affine transformation acting between the first two layers is denoted and is of the formAs an activation function acting on the hidden layer, we take the ReLU-function, given byNote that the ReLU function corresponds to the pay-off function of a European option.
- The output of the network estimates contract value and therefore takes value in . It is represented by the right node in Figure 1. We consider a linear transformation acting between the second and last layer , given byOn top of that, we apply the linear activation, which comes down to an identity function, mapping x to itself.
3.2.2. Interpretation of the Neural Network
- If and , we havewhich is the pay-off of a forward contract on units in and units of currency.
- If and , we havewhich is the pay-off corresponding to units of a European call option written on , with strike price .
- If and , we havewhich is the pay-off corresponding to units of a European put option written on , with strike price .
- If and , we havewhich clearly represents a worthless contract.
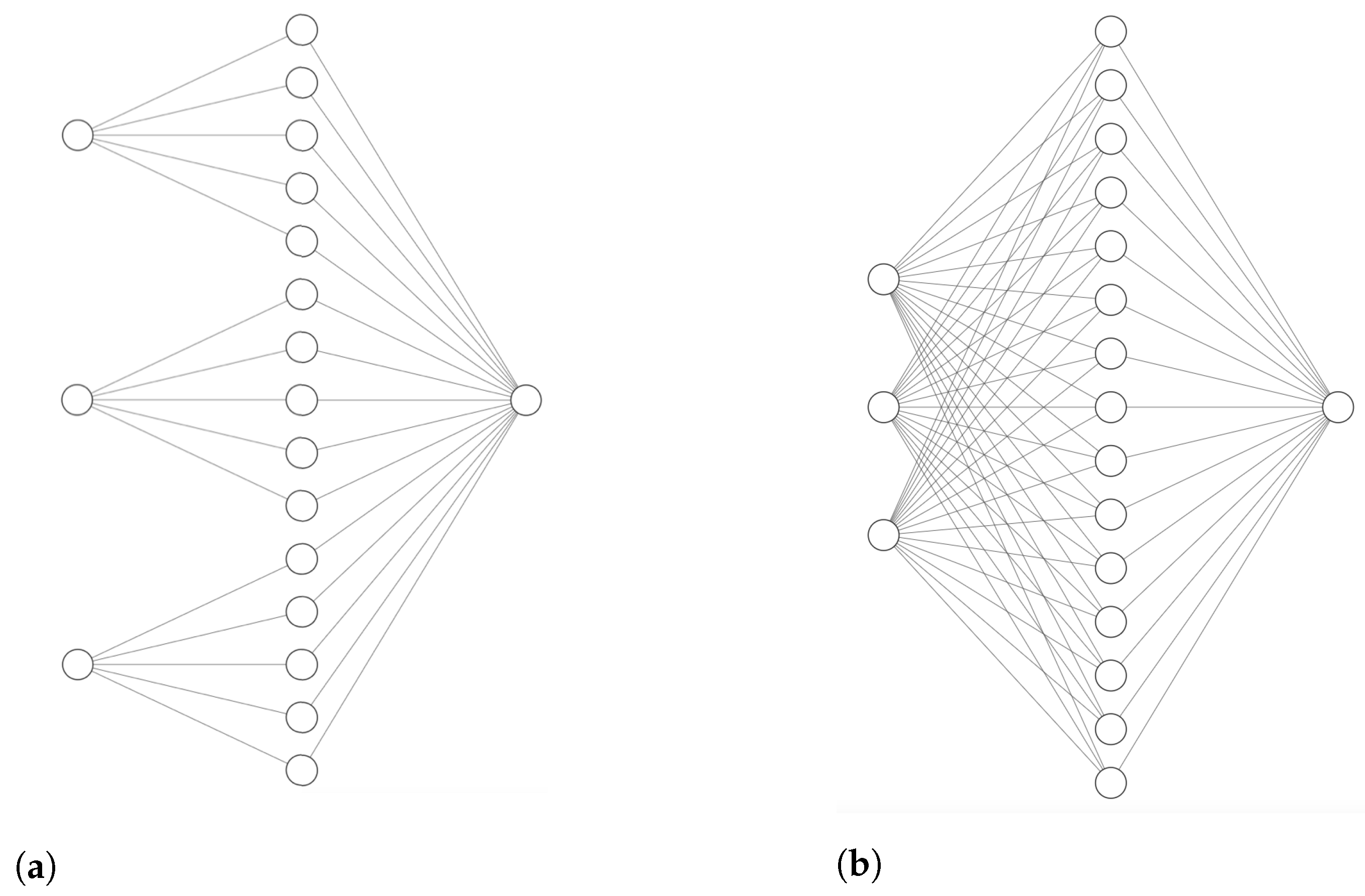
3.2.3. The Multi-Factor Case
- The first layer consists of d nodes and the hidden layer has hidden nodes. The affine transformation and activation acting between the first two layers are denoted and , respectively, given by
- The output contains a single node. A linear transformation acts between the second and last layer , together with the linear activation, given by
- The network is given by .
3.2.4. Suggestion 1: A Locally Connected Neural Network
3.2.5. Suggestion 2: A Fully Connected Neural Network
3.3. Training of the Neural Networks
Optimization
- As an optimizer, we apply AdaMax Kingma and Ba (2014), a variation of the commonly used Adam algorithm. This is a stochastic, first-order, gradient-based optimizer that updates weights inversely proportional to the -norm of their current and past gradient, whereas Adam is based on the -norm. Our experiments indicate that AdaMax slightly outperforms comparable algorithms in the scope of our objectives.
- The batch size, i.e., the number of training points used per weight update, is set to a standard 32. The learning rate, which scales the step size of each update, is kept in the range 0.0001–0.0005.
- For the initial network, , we use random initialization of the parameters. If the considered contract is a payer Bermudan swaption, we initialize the (non-zero) entries of i.i.d. unif and the biases i.i.d. unif. In the case of a receiver contract, it is the other way around. The weights are initialized i.i.d. unif.
- For the subsequent networks, , each network is initialized with the final set of weights of the previous network .
- As a training set for the optimizer, we use a collection of 20,000 data-points.
4. Lower and Upper Bound Estimates
4.1. The Lower Bound
4.2. The Upper Bound
5. Error Analysis
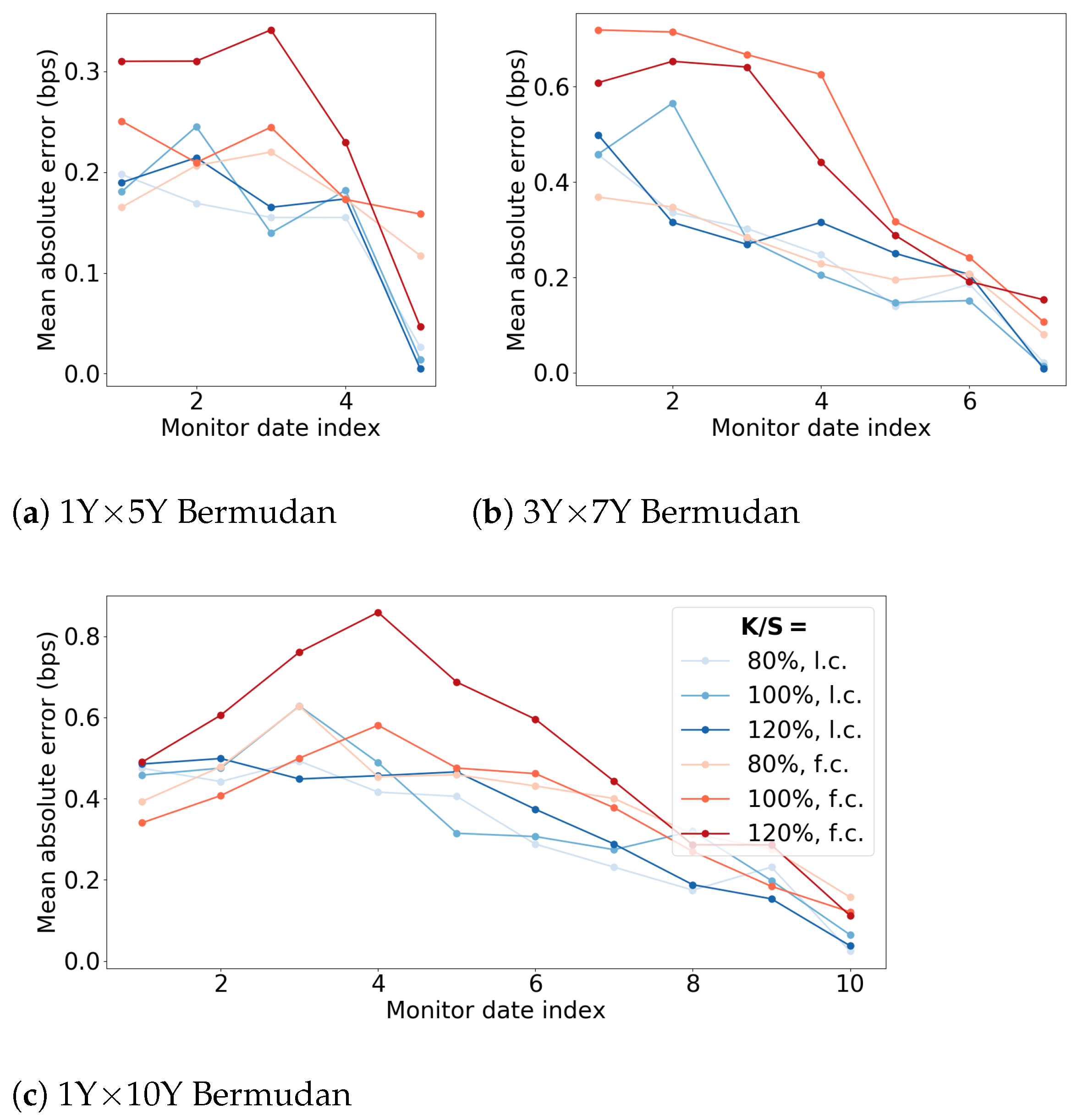
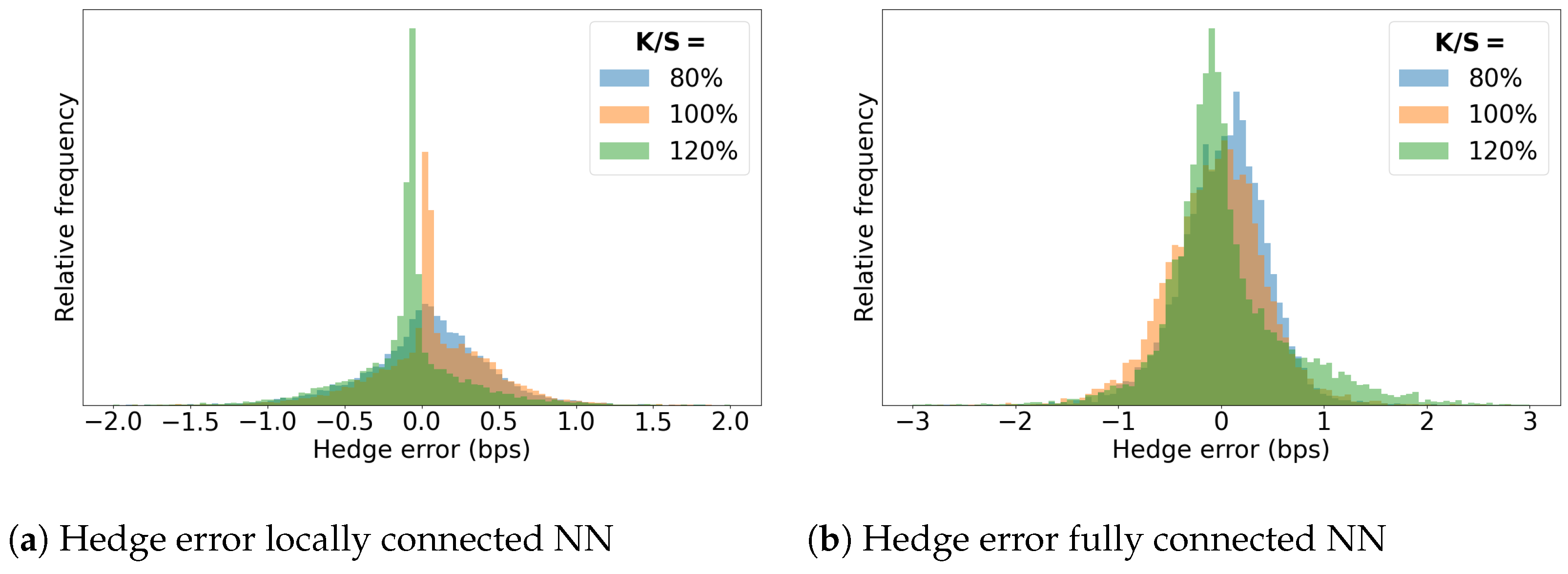
5.1. Accuracy of the Semi-Static Hedge
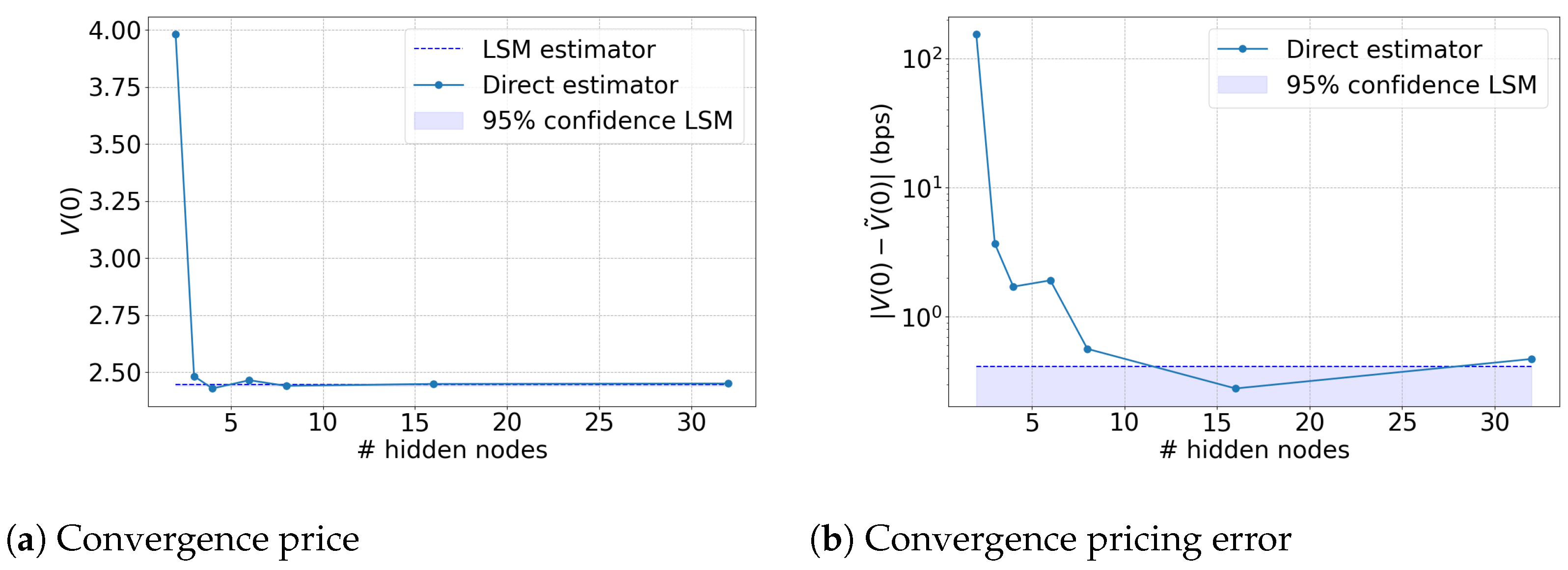
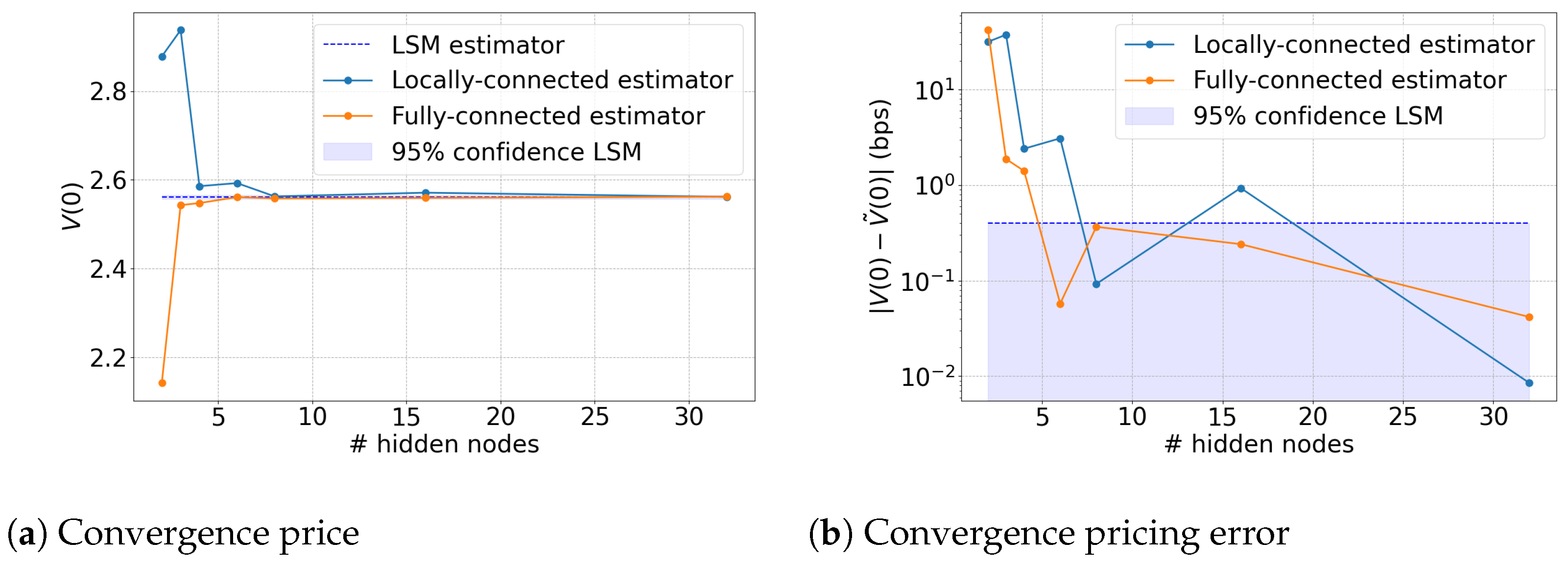
5.2. Error of the Direct Estimator
5.3. Tightness of the Lower Bound Estimate
5.4. Tightness of the Upper Bound Estimate
6. Numerical Experiments
6.1. 1-Factor Swaption
6.2. 1-Factor Bermudan Swaption
6.3. 2-Factor Bermudan Swaption
6.4. Performance Semi-Static Hedge
6.4.1. 1-Factor Swaption
6.4.2. 2-Factor Bermudan Swaption
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Disclosure
Appendix A. Evaluation of the Conditional Expectation
Appendix A.1. The Continuation Value with Locally Connected NN
Appendix A.2. The Continuation Value with Fully Connected NN
Appendix B. Pre-Processing the Regression-Data
- The locally connected NN case: Consider the outcome of the hidden node and denote the input of the network as . Then, , where k is the index of the only non-zero entry of , the row of weight matrix . The transformation implies thatAs a consequence, in the analysis of Appendix A.1, the transformations and should be taken into account. Additionally, the transformation is required to account for the scaling of .
- The fully connected NN case: Again, consider the outcome of the hidden node . This time, the transformation implies thatAs a consequence, in the analysis of Appendix A.2, the transformations and should be taken into account. And, again, the transformation is required to account for the scaling of .
Appendix C. Hyperparameter Selection
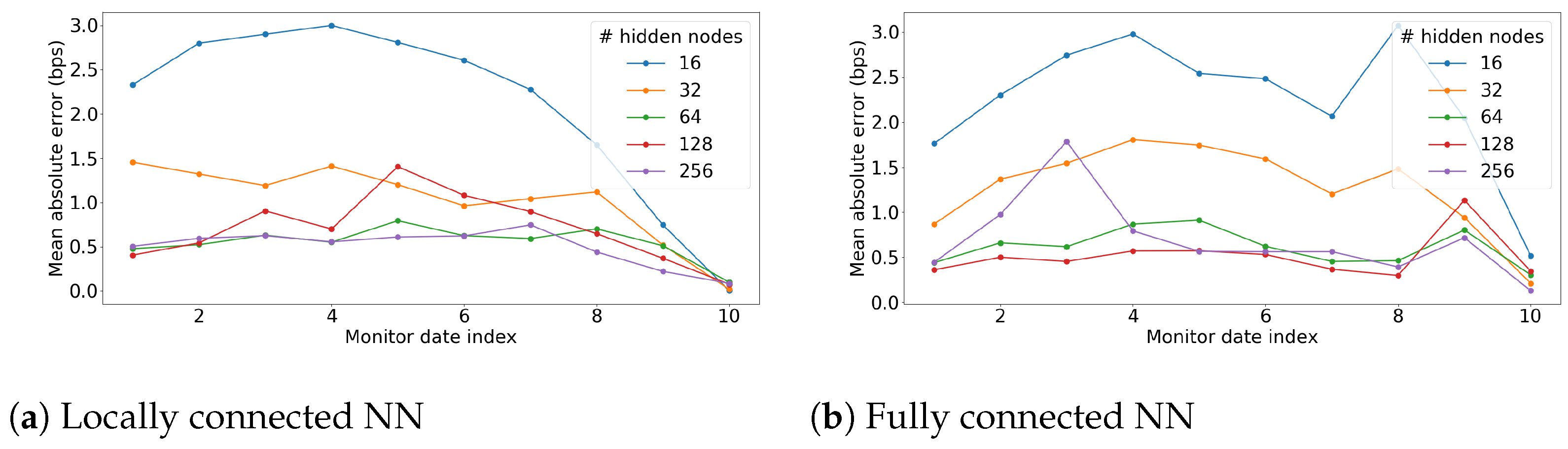
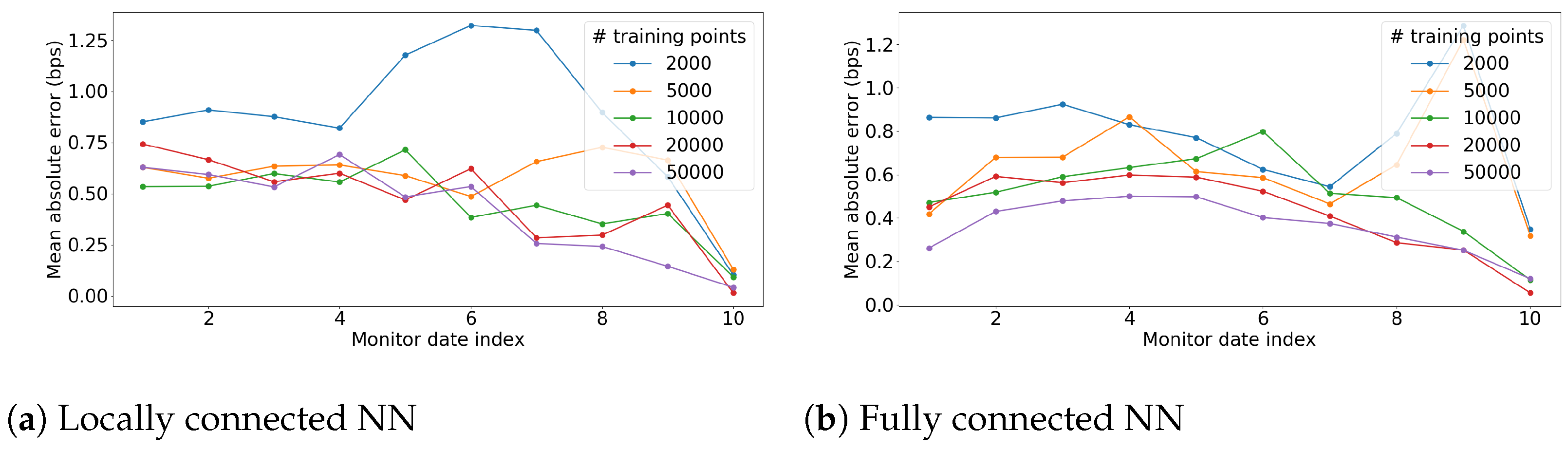

Appendix D. Proof of Theorem 1
- , then ;
- , then ;
- , then;
- , then.
Appendix E. Proof of Theorem 2
- Let denote the true price of the Bermudan swaption at conditioned on the fact that it is not yet exercised.
- Let denote the estimator of the continuation value at .
- Let denote the estimator of .
- Let denote the neural network approximation of .
- Let denote the numéraire at .
- Let .
Appendix F. Proof of Theorem 3
Appendix G. Proof of Theorem 4
References
- Ametrano, Ferdinando, and Luigi Ballabio. 2003. Quantlib—A Free/Open-Source Library for Quantitative Finance. Available online: https://github.com/lballabio/QuantLib (accessed on 1 March 2020).
- Andersen, Leif, and Mark Broadie. 2004. Primal-dual simulation algorithm for pricing multidimensional american options. Management Science 50: 1222–34. [Google Scholar] [CrossRef]
- Andersen, Leif B. G., and Vladimir V. Piterbarg. 2010a. Interest Rate Modeling, Volume I: Foundations and Vanilla Models. London: Atlantic Financial Press. [Google Scholar]
- Andersen, Leif B. G., and Vladimir V. Piterbarg. 2010b. Interest Rate Modeling, Volume II: Term Structure Models. London: Atlantic Financial Press. [Google Scholar]
- Andersson, Kristoffer, and Cornelis W. Oosterlee. 2021. A deep learning approach for computations of exposure profiles for high-dimensional bermudan options. Applied Mathematics and Computation 408: 126332. [Google Scholar] [CrossRef]
- Becker, Sebastian, Patrick Cheridito, and Arnulf Jentzen. 2019. Deep optimal stopping. Journal of Machine Learning Research 20: 74. [Google Scholar]
- Becker, Sebastian, Patrick Cheridito, and Arnulf Jentzen. 2020. Pricing and hedging american-style options with deep learning. Journal of Risk and Financial Management 13: 158. [Google Scholar] [CrossRef]
- Beyna, Ingo. 2013. Interest Rate Derivatives: Valuation, Calibration and Sensitivity Analysis. Berlin/Heidelberg: Springer Science & Business Media. [Google Scholar]
- Bishop, Christopher M. 1995. Neural Networks for Pattern Recognition. Oxford: Oxford University Press. [Google Scholar]
- Breeden, Douglas T., and Robert H. Litzenberger. 1978. Prices of state-contingent claims implicit in option prices. Journal of Business 51: 621–51. [Google Scholar] [CrossRef]
- Brigo, Damiano, and Fabio Mercurio. 2006. Interest Rate Models-Theory and Practice: With Smile, Inflation and Credit. Berlin/Heidelberg: Springer, vol. 2. [Google Scholar]
- Carr, Peter, and Jonathan Bowie. 1994. Static simplicity. Risk 7: 45–50. [Google Scholar]
- Carr, Peter, Katrina Ellis, and Vishal Gupta. 1999. Static hedging of exotic options. In Quantitative Analysis in Financial Markets: Collected Papers of the New York University Mathematical Finance Seminar. Singapore: World Scientific, pp. 152–76. [Google Scholar]
- Carr, Peter, and Liuren Wu. 2014. Static hedging of standard options. Journal of Financial Econometrics 12: 3–46. [Google Scholar] [CrossRef]
- Carriere, Jacques F. 1996. Valuation of the early-exercise price for options using simulations and nonparametric regression. Insurance: Mathematics and Economics 19: 19–30. [Google Scholar] [CrossRef]
- Chollet, François. 2015. Keras. Available online: https://keras.io (accessed on 1 May 2020).
- Chung, San-Lin, and Pai-Ta Shih. 2009. Static hedging and pricing american options. Journal of Banking & Finance 33: 2140–49. [Google Scholar]
- Dai, Qiang, and Kenneth J. Singleton. 2000. Specification analysis of affine term structure models. The Journal of Finance 55: 1943–78. [Google Scholar] [CrossRef]
- Derman, Emanuel, Deniz Ergener, and Iraj Kani. 1995. Static options replication. Journal of Derivatives 2. [Google Scholar] [CrossRef]
- Duffie, Darrell, and Rui Kan. 1996. A yield-factor model of interest rates. Mathematical Finance 6: 379–406. [Google Scholar] [CrossRef]
- Ferguson, Ryan, and Andrew Green. 2018. Deeply learning derivatives. arXiv arXiv:1809.02233. [Google Scholar]
- Filipovic, Damir. 2009. Term-Structure Models. A Graduate Course. Berlin/Heidelberg: Springer. [Google Scholar]
- Geman, Helyette, Nicole El Karoui, and Jean-Charles Rochet. 1995. Changes of numeraire, changes of probability measure and option pricing. Journal of Applied probability 32: 443–58. [Google Scholar] [CrossRef]
- Glasserman, Paul. 2013. Monte Carlo Methods in Financial Engineering. Berlin/Heidelberg: Springer Science & Business Media, vol. 53. [Google Scholar]
- Glasserman, Paul, and Bin Yu. 2004. Simulation for american options: Regression now or regression later? In Monte Carlo and Quasi-Monte Carlo Methods 2002. Berlin/Heidelberg: Springer, pp. 213–26. [Google Scholar]
- Gnoatto, Alessandro, Christoph Reisinger, and Athena Picarelli. 2023. Deep xva solver—A neural network based counterparty credit risk management framework. SIAM Journal on Financial Mathematics 14: 314–352. [Google Scholar] [CrossRef]
- Goodfellow, Ian, Yoshua Bengio, Aaron Courville, and Yoshua Bengio. 2016. Deep Learning. Cambridge: MIT Press Cambridge, vol. 1. [Google Scholar]
- Gregory, Jon. 2015. The xVA Challenge: Counterparty Credit Risk, Funding, Collateral and Capital. Hoboken: John Wiley & Sons. [Google Scholar]
- Hagan, Patrick S. 2005. Convexity conundrums: Pricing cms swaps, caps, and floors. The Best of Wilmott, 305. [Google Scholar] [CrossRef]
- Harrison, J. Michael, and Stanley R. Pliska. 1981. Martingales and stochastic integrals in the theory of continuous trading. Stochastic Processes and Their Applications 11: 215–60. [Google Scholar] [CrossRef]
- Haugh, Martin B., and Leonid Kogan. 2004. Pricing american options: A duality approach. Operations Research 52: 258–70. [Google Scholar] [CrossRef]
- Henrard, Marc. 2003. Explicit bond option formula in heath–jarrow–morton one factor model. International Journal of Theoretical and Applied Finance 6: 57–72. [Google Scholar] [CrossRef]
- Henry-Labordere, Pierre. 2017. Deep Primal-Dual Algorithm for BSDEs: Applications of Machine Learning to CVA and IM. Available online: https://ssrn.com/abstract=3071506 (accessed on 1 October 2020).
- Hornik, Kurt, Maxwell Stinchcombe, and Halbert White. 1989. Multilayer feedforward networks are universal approximators. Neural Networks 2: 359–66. [Google Scholar] [CrossRef]
- Hutchinson, James M., Andrew W. Lo, and Tomaso Poggio. 1994. A nonparametric approach to pricing and hedging derivative securities via learning networks. The Journal of Finance 49: 851–89. [Google Scholar] [CrossRef]
- Jain, Shashi, and Cornelis W. Oosterlee. 2015. The stochastic grid bundling method: Efficient pricing of bermudan options and their greeks. Applied Mathematics and Computation 269: 412–31. [Google Scholar] [CrossRef]
- Jamshidian, Farshid. 1989. An exact bond option formula. The Journal of Finance 44: 205–209. [Google Scholar] [CrossRef]
- Kingma, Diederik P., and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv arXiv:1412.6980. [Google Scholar]
- Kloeden, Peter E., and Eckhard Platen. 2013. Numerical Solution of Stochastic Differential Equations. Berlin/Heidelberg: Springer Science & Business Media, vol. 23. [Google Scholar]
- Kohler, Michael, Adam Krzyżak, and Nebojsa Todorovic. 2010. Pricing of high-dimensional american options by neural networks. Mathematical Finance: An International Journal of Mathematics, Statistics and Financial Economics 20: 383–410. [Google Scholar] [CrossRef]
- Lapeyre, Bernard, and Jérôme Lelong. 2019. Neural network regression for bermudan option pricing. arXiv arXiv:1907.06474. [Google Scholar] [CrossRef]
- Lokeshwar, Vikranth, Vikram Bharadwaj, and Shashi Jain. 2022. Explainable neural network for pricing and universal static hedging of contingent claims. Applied Mathematics and Computation 417: 126775. [Google Scholar] [CrossRef]
- Longstaff, Francis A., and Eduardo S. Schwartz. 2001. Valuing american options by simulation: A simple least-squares approach. The Review of Financial Studies 14: 113–47. [Google Scholar] [CrossRef]
- Musiela, Marek, and Marek Rutkowski. 2005. Martingale Methods in Financial Modelling. Berlin/Heidelberg: Springer Finance. [Google Scholar]
- Oosterlee, Kees, Qian Feng, Shashi Jain, Patrik Karlsson, and Drona Kandhai. 2016. Efficient computation of exposure profiles on real-world and risk-neutral scenarios for bermudan swaptions. Journal of Computational Finance 20: 139–72. [Google Scholar] [CrossRef]
- Pelsser, Antoon. 2003. Pricing and hedging guaranteed annuity options via static option replication. Insurance: Mathematics and Economics 33: 283–96. [Google Scholar] [CrossRef]
- Rogers, Leonard C. G. 2002. Monte carlo valuation of american options. Mathematical Finance 12: 271–86. [Google Scholar] [CrossRef]
- Ruf, Johannes, and Weiguan Wang. 2020. Neural networks for option pricing and hedging: A literature review. Journal of Computational Finance. in press. [Google Scholar] [CrossRef]
- Shreve, Steven E. 2004. Stochastic calculus for finance II: Continuous-time models. Berlin/Heidelberg: Springer Science & Business Media, vol. 11. [Google Scholar]
- Wang, Haojie, Han Chen, Agus Sudjianto, Richard Liu, and Qi Shen. 2018. Deep learning-based bsde solver for libor market model with application to bermudan swaption pricing and hedging. arXiv arXiv:1807.06622. [Google Scholar] [CrossRef]
- Xiu, Dongbin. 2010. Numerical Methods for Stochastic Computations: A Spectral Method Approach. Princeton: Princeton University Press. [Google Scholar]
- Zhu, Steven H., and Michael Pykhtin. 2007. A guide to modeling counterparty credit risk. GARP Risk Review, July/August. Available online: https://ssrn.com/abstract=1032522 (accessed on 10 November 2020).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | a | ||
|---|---|---|---|
| Value | 0.01 | 0.01 | 0.03 |
| Type | K/S | Dir.est. | Lower bnd | Upper bnd | UB-LB | LSM est. | LSM 95% CI |
|---|---|---|---|---|---|---|---|
| 1Y × 5Y | 80% | 1.527 | 1.521 (0.001) | 1.528 (0.000) | 0.007 | 1.521 (0.001) | [1.518, 1.523] |
| 100% | 2.543 | 2.534 (0.002) | 2.542 (0.000) | 0.008 | 2.534 (0.002) | [2.531, 2.538] | |
| 120% | 4.015 | 4.016 (0.002) | 4.018 (0.000) | 0.002 | 4.016 (0.002) | [4.012, 4.021] | |
| 3Y × 7Y | 80% | 3.296 | 3.293 (0.002) | 3.295 (0.000) | 0.002 | 3.293 (0.002) | [3.290, 3.296] |
| 100% | 4.767 | 4.755 (0.004) | 4.761 (0.000) | 0.006 | 4.755 (0.004) | [4.747, 4.762] | |
| 120% | 6.625 | 6.629 (0.004) | 6.631 (0.000) | 0.002 | 6.629 (0.004) | [6.621, 6.638] | |
| 1Y × 10Y | 80% | 3.950 | 3.945 (0.005) | 3.960 (0.000) | 0.015 | 3.945 (0.005) | [3.935, 3.955] |
| 100% | 5.818 | 5.811 (0.003) | 5.818 (0.000) | 0.007 | 5.811 (0.003) | [5.805, 5.816] | |
| 120% | 8.346 | 8.354 (0.005) | 8.360 (0.000) | 0.006 | 8.353 (0.005) | [8.344, 8.362] |
| Parameter | ||||||
|---|---|---|---|---|---|---|
| Value | 0.07 | 0.08 | 0.015 | 0.008 | −0.6 | 0.03 |
| Locally connected neural networks | |||||||
| Type | K/S | Dir.est. | Lower bnd | Upper bnd | UB-LB | LSM est. | LSM 95% CI |
| 1Y × 5Y | 80% | 1.617 | 1.617(0.002) | 1.619(0.000) | 0.002 | 1.617(0.002) | [1.614, 1.621] |
| 100% | 2.652 | 2.650(0.002) | 2.654(0.000) | 0.004 | 2.650(0.002) | [2.646, 2.654] | |
| 120% | 4.128 | 4.127(0.003) | 4.131(0.000) | 0.004 | 4.127(0.003) | [4.121, 4.132] | |
| 3Y × 7Y | 80% | 3.073 | 3.076(0.004) | 3.078(0.000) | 0.002 | 3.077(0.004) | [3.069, 3.085] |
| 100% | 4.554 | 4.553(0.004) | 4.553(0.000) | 0.000 | 4.552(0.004) | [4.545, 4.559] | |
| 120% | 6.444 | 6.448(0.004) | 6.451(0.000) | 0.003 | 6.446(0.005) | [6.435, 6.456] | |
| 1Y × 10Y | 80% | 3.616 | 3.624(0.002) | 3.626(0.000) | 0.002 | 3.622(0.002) | [3.618, 3.627] |
| 100% | 5.508 | 5.509(0.002) | 5.514(0.000) | 0.005 | 5.508(0.002) | [5.503, 5.512] | |
| 120% | 8.128 | 8.123(0.005) | 8.130(0.000) | 0.007 | 8.121(0.005) | [8.110, 8.132] | |
| Fully connected neural networks | |||||||
| Type | K/S | Dir.est. | Lower bnd | Upper bnd | UB-LB | LSM est. | LSM 95% CI |
| 1Y × 5Y | 80% | 1.617 | 1.617(0.002) | 1.619(0.000) | 0.002 | 1.617(0.002) | [1.614, 1.621] |
| 100% | 2.651 | 2.650(0.002) | 2.654(0.000) | 0.004 | 2.650(0.002) | [2.646, 2.654] | |
| 120% | 4.129 | 4.127(0.003) | 4.131(0.000) | 0.004 | 4.127(0.003) | [4.121, 4.132] | |
| 3Y × 7Y | 80% | 3.076 | 3.077(0.004) | 3.078(0.000) | 0.001 | 3.077(0.004) | [3.069, 3.085] |
| 100% | 4.553 | 4.553(0.004) | 4.554(0.000) | 0.001 | 4.552(0.004) | [4.545, 4.559] | |
| 120% | 6.451 | 6.447(0.005) | 6.451(0.000) | 0.004 | 6.446(0.005) | [6.435, 6.456] | |
| 1Y × 10Y | 80% | 3.616 | 3.624(0.002) | 3.626(0.000) | 0.002 | 3.622(0.002) | [3.618, 3.627] |
| 100% | 5.506 | 5.509(0.002) | 5.514(0.000) | 0.005 | 5.508(0.002) | [5.503, 5.512] | |
| 120% | 8.124 | 8.123(0.005) | 8.130(0.000) | 0.007 | 8.121(0.005) | [8.110, 8.132] | |
| Hedge Error (bps) | K/S | Static Hedge | Dyn. Hedge |
|---|---|---|---|
| Mean | 80% | ||
| 100% | |||
| 120% | |||
| St. dev. | 80% | ||
| 100% | |||
| 120% | |||
| 95%-percentile | 80% | ||
| 100% | |||
| 120% |
| Hedge Error (bps) | K/S | Loc. conn. NN | Fully conn. NN |
|---|---|---|---|
| Mean | 80% | ||
| 100% | |||
| 120% | |||
| St. dev. | 80% | ||
| 100% | |||
| 120% | |||
| 95%-percentile | 80% | ||
| 100% | |||
| 120% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoencamp, J.; Jain, S.; Kandhai, D. A Semi-Static Replication Method for Bermudan Swaptions under an Affine Multi-Factor Model. Risks 2023, 11, 168. https://doi.org/10.3390/risks11100168
Hoencamp J, Jain S, Kandhai D. A Semi-Static Replication Method for Bermudan Swaptions under an Affine Multi-Factor Model. Risks. 2023; 11(10):168. https://doi.org/10.3390/risks11100168
Chicago/Turabian StyleHoencamp, Jori, Shashi Jain, and Drona Kandhai. 2023. "A Semi-Static Replication Method for Bermudan Swaptions under an Affine Multi-Factor Model" Risks 11, no. 10: 168. https://doi.org/10.3390/risks11100168
APA StyleHoencamp, J., Jain, S., & Kandhai, D. (2023). A Semi-Static Replication Method for Bermudan Swaptions under an Affine Multi-Factor Model. Risks, 11(10), 168. https://doi.org/10.3390/risks11100168