1. Introduction
The main objective of this paper is to outline a new standard for data preparation on insurance policy listings, namely ECLIPSE. The main problem ECLIPSE addresses is that actuaries within insurance and reinsurance companies spend a lot of time cleaning dirty data, often spending more time on this data preparation and cleaning than on modeling and insight generation. To address this problem, we explore and answer several research questions: What are the key components of data preparation for policy listings? What are the most important data properties of policy listings across insurance lines? How can we leverage both the specialized domain of the datasets and modern AI algorithms/tools to improve existing processes for each data preparation component? What are important KPIs to measure improvements in the data preparation process, and can we quantify how much we advance the state-of-the-art? Finally, we explore how ECLIPSE can be generalized to datasets beyond policy listings, and other future directions of improvement.
Machine learning AI is often applied in data preparation systems. First,
Sawarkar and Kodati (
2021) of IBM explore using data science techniques of word embeddings and entity resolution for schema standardization. This paper expands on schema standardization data science by exploring the application of ensembles of ML-driven algorithms and the related human-in-the-loop workflows/systems. Second, the paper expands on entity resolution, used not only for schema standardization but generally to identify/standardize entities represented in various formats. A survey on entity resolution is presented by
Papadakis et al. (
2020), where the authors identify common blocking techniques and similarity functions. The research on entity resolution started in the 1950s and disparate methods have been proposed, summarized by
Vidhya and Geetha (
2019). Though some latest methods combine modern machine learning techniques such as semi-supervised learning and the Expectation-Maximization algorithm, it is hard to find a state-of-the-art (henceforth SOTA) model that outperforms in most areas due to the nature of the underlying entity. In addition, many entity resolution models, despite their technical soundness, are computationally infeasible for all practical purposes, especially for a system that continuously receives new data and must provide entity resolution results in a timely manner. This paper, by applying specifically to the insured companies within insurance policies, establishes novel and practical techniques that build upon the established fundamentals. Next, labeling is a critical step in data preparation, where ML is often used: Stanford researchers present the Snorkel system in
Ratner et al. (
2017), which is an ML system widely used to auto-label records. Finally, applying AI systems to data preparation means venturing into MLOps (Machine Learning Operations), a novel discipline bringing systematic rigor to ML systems.
Symeonidis et al. (
2022) provide an excellent overview of MLOps and their challenges, which we address in our application system.
Next, application papers in insurance seem more focused on modeling. A few papers that prepare insurance data focus on imputation (such as
Euller et al. (
1997)), which is only one aspect of data cleaning. This paper approaches data preparation in insurance policies more holistically.
Insurance policy data poses unique data quality challenges, depending on the data preparation task at hand. We will start with entity resolution. While ECLIPSE focuses on policy data where insured entities are mostly companies, even company data is inconsistently formatted across clients and business lines. In order to build better loss models, actuaries often need to aggregate policies on the same insured company. For example, computing the aggregate premium on Directors and Officers (D&O) policies underwritten by Walmart or by Google can be an important data point in exposure-based loss projections. That means entity resolving insured companies, in order to know a policy on Alphabet and Google, for instance, refer to the same company. Sometimes, the insured companies within policy data have only names, other times they include partial or full address identifiers (such as country, city, state, zip, and street), and other times they may include other attributes such as revenue or North American Industry Classification System (NAICS) codes. When resolving company data, there are often complete disagreements in one or many of these fields, thus requiring not only a methodology to match, but a methodology to choose the source of truth. Matching is also challenging because corporation entities may have branches, and may have large variations in fields such as name and address. These variations include (1) having just the names of people and city names for professional service firms such as law LLPs, (2) out-of-date aliases, (3) companies encoded with multiple possible names and addresses, (4) spelling errors, (5) uncommon abbreviations, and more. Finally, addressing these challenges has to be conducted in a computationally efficient manner, which is yet another challenge in itself.
To address these challenges and aggregate insured entities for policies, we developed a rule-based, pairwise corporation entity resolution framework PIERCE: Performant, Intelligent Entity Resolution for Corporation Entities. We licensed corporation listing data across the globe from vendors such as Dun and Bradstreet, which contain entity name, address, revenue, industry code, and corporation structure, which serves as our source of truth. After receiving insured corporation entity information from clients, we will conduct entity resolution to fuzzy match these entities to the standard entities in the corporation listing. Once a match is identified, we can impute the information from the corporation listing to augment corporation information and resolve duplicated entities with nuances.
Second, policy data comes in different formats from different insurers. While some industry standards exist for subsets of insurance data, different insurers still store and transmit data in inconsistent schemas. For policy listings, also known as exposures,
Open Data Standards (
2020) focuses mostly on insured properties. This means insurers are still lacking a standard industry data schema, which enhances the problem of inconsistent schemas. This problem can also be solved by entity resolving the column names of the schema but poses unique challenges. We must rely on fewer training data points, and more idiosyncratic and egregious variations and aliases. To address this, we have designed a separate schema resolution algorithm.
Third, policy data is a constantly incoming stream, with policies always being underwritten by insurers. The new policy data may feature novel data patterns, even from the same insurer. This requires a robust set of validations and a system to confirm and edit incoming data streams. Fourth, while automated systems can clean and prepare schemas and standardize insured entities/addresses, they may not be 100% accurate themselves. There are tradeoffs to evaluate here, and a need for a human-in-the-loop. To address this, we have designed a labeling framework and MLOps user interface.
These challenges and lack of definitive work on holistic AI systems for data preparation in insurance, and specifically policy listings data, as well as the significant impact on the workstreams of actuaries, present an opportunity to improve and advance the industry. ECLIPSE advances state-of-the-art by addressing these challenges and leveraging modern AI and MLOps systems techniques. To summarize, it consists of:
PIERCE: Performant, Intelligent Entity Resolution for Corporation Entities;
Schema Standardization;
Interactive Validation Resolution;
Intuitive User Interface for Human Labeling and Interactions with the MLOps System.
Future work can extend on these AI systems to further automate data preparation in new insurance lines, data standards, and entities. For example, the company resolution framework can be generalized into broader entity resolution, to de-duplicate and augment other insured entities or objects. Similarly, more ML models can be created to facilitate correcting other validation issues.
4. Discussion
We have developed ECLIPSE to standardize, improve, and automate with ML the data preparation of insurance policies. Thus far, we have outlined the details of how ECLIPSE achieves this through:
Data cleaning rules for insurance policies;
PIERCE Algorithm for Entity Resolution;
ML Modeling for Schema Standardization;
Validation Rules and ML-Assisted Resolution;
Labeling and MLOps framework.
Now, we will summarize our contributions and existing work, as well as explain the implications of our research in practice and for the future.
4.1. Contributions and Existing Work
The main contribution of this research is the ECLIPSE system, which is effectively an insurance policy data preparation standard. ECLIPSE was born out of a desire for actuaries to spend less time cleaning dirty data, and spend more time modeling. At Guy Carpenter, actuaries had designed all sorts of disparate data preparation and cleaning schemes across business lines and a significant portion of their jobs was doing this cleaning manually in Excel: when they adopted ECLIPSE, they experienced an over 50% improvement in processing time for client modeling requests and analyses. The problem that actuaries spend significant time cleaning data is also borne out in the literature. For example, the American Academy of Actuaries acknowledges that 80% of time in any modeling project is spent understanding and cleaning data
Beuerlein et al. (
2018). The idea that applying AI to insurance data preparation can lead to such drastic savings and re-allocations of actuaries’ time is also evidenced in the literature. For example, in
Ullal et al. (
2022), the authors survey the different interactions between AI and humans and find that in services sectors requiring high intelligence, AI will partner with humans and help automate many routine tasks.
The reality of data preparation is often missing in research: most actuarial research papers focus on the risk model itself, with clean data as input. For example, in
Gao et al. (
2022), the authors build a claims frequency model, but the data cleaning is limited to a simple shaping operation. As mentioned in the introduction, data preparation literature for insurance is largely missing. In that sense, the novelty of ECLIPSE as a holistic insurance data preparation standard will help bridge the literature gap.
Due to its novelty, the ECLIPSE system is not comparable to existing work as a whole, but in the Results section, we compared results for its entity resolution algorithm PIERCE, its schema standardization model, and its MLOps components with other solutions, by running those other solutions on insurance policy data.
With regards to entity resolution, we compared ECLIPSE’s PIERCE to
Zingg (
2022), another implementation of SOTA entity resolution as outlined in
Papadakis et al. (
2020), as well as Dun and Bradstreet’s entity resolution service. By including specialized cleaning rules, blocking rules, and validations, ECLIPSE has seen between 3–8% improvements in match rate and 4–7% improvements in precision, on insurance policy data (see
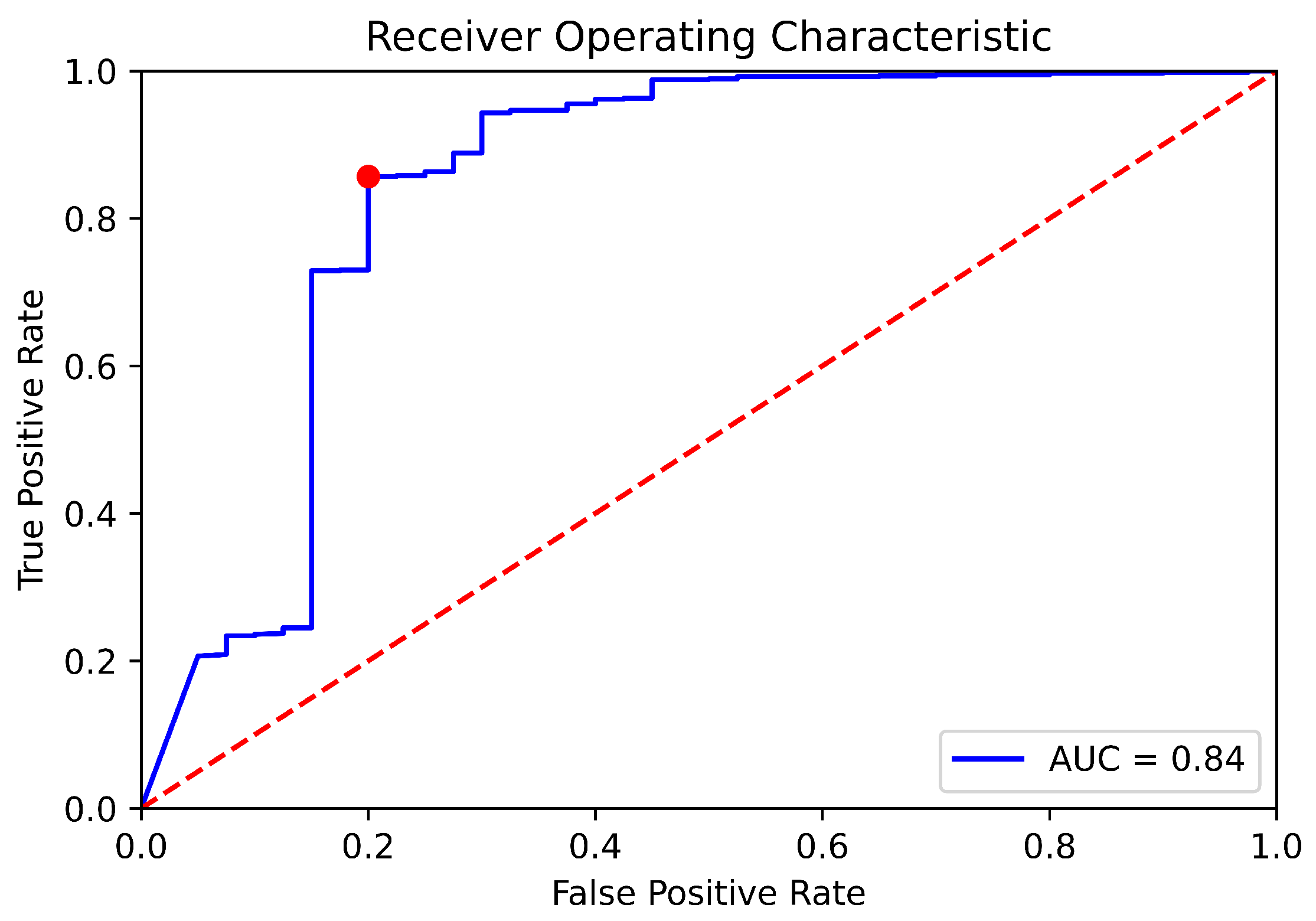
Table 20). This follows from the fact that comparable solutions are not specialized to insurance datasets, while ECLIPSE is meant to be a data preparation standard for insurance policies. By leveraging Spark distributed computing and focusing on performance, ECLIPSE has cut execution time by more than half, which is more generally applicable outside insurance.
With regards to schema standardization, we have demonstrated how ECLIPSE performs relative to two comparable methods in the literature: Snorkel (see
Ratner et al. (
2017)), and a standard edit distance baseline (see
Levenshtein (
1966)). The comparable solutions are not specialized to insurance but are also significantly simpler algorithmically than the ML ensemble model we have outlined in
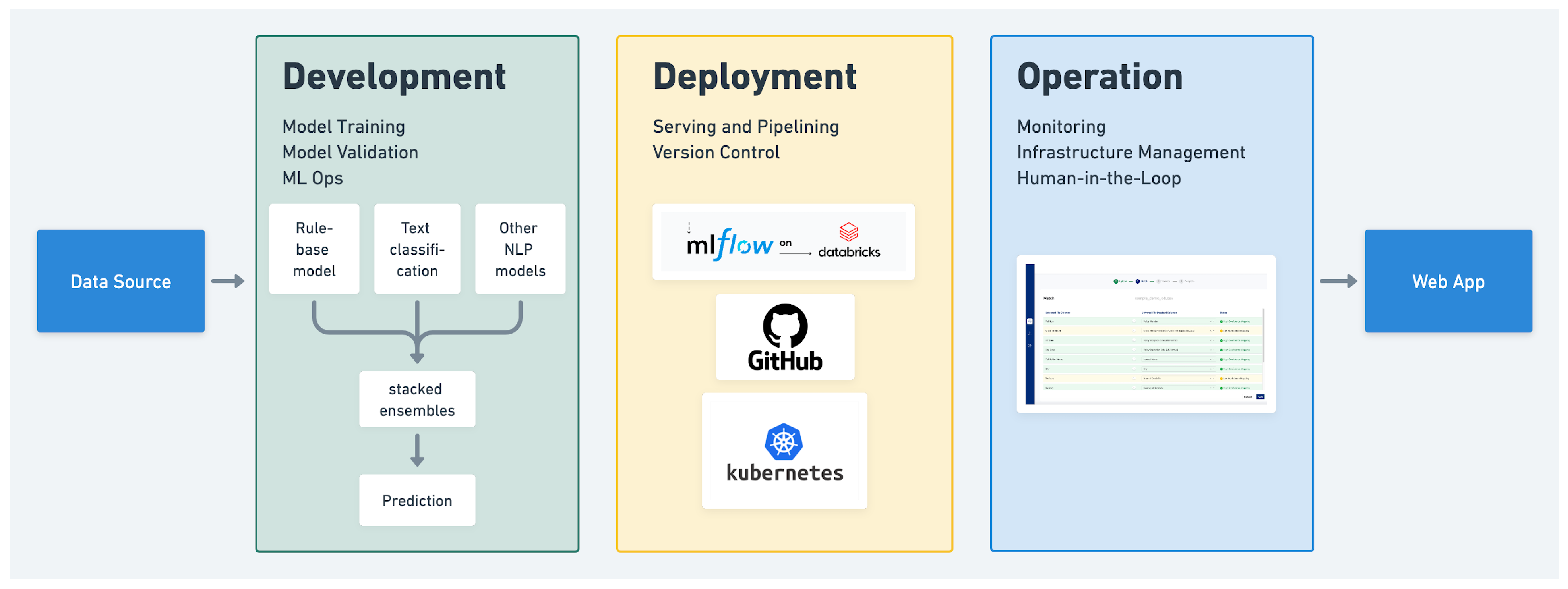
Section 3.3 and in
Figure 1. ECLIPSE’s added algorithmic complexity in schema standardization, along with features/cleaning rules specific to the insurance domain has led to significant improvements in micro/macro f1 scores (over 30% in the case of macro f1), as shown in
Table 21.
With regards to the MLOps components,
Kreuzberger et al. (
2022) compares several MLOps solutions, including BentoML, Tensorflow Serving, and more. However, based on the specialized domain and desire for widespread adoption, ECLIPSE is designed as a more customized MLOps solution built with open-source technologies such as AngularJS (for custom UX), Spark, Kubernetes, and mlflow. It handles the human-in-the-loop labeling of insured entities and monitoring of specific validations on insurance policies.
4.2. Practical and Future Implications
Based on the improvements we have outlined in terms of classification KPIs, execution time, and productivity of actuaries, we recommend actuaries and data practitioners within the insurance industry adopt ECLIPSE as a methodology for standardizing their policy listing datasets.
One key limitation of ECLIPSE as presented is that it is tailored to policy listings. However, the process and ML-assisted data preparation components that we have outlined can also be applied to other datasets within insurance, such as loss listings or claims listings. This would require some customization of the cleaning rules, validation rules, and features, and is an important future direction for this work. Within Guy Carpenter, we plan to expand ECLIPSE to support other datasets and continue to establish ML-automated and standardized data preparation on novel insurance datasets.
Another practical future implication is the need to apply more standard data schemas and data collection standards across the insurance industry: this will reduce the amount of human effort that is still needed via the human-in-the-loop labeling and monitoring sections of ECLIPSE. While some progress has been made, such as in establishing more consistent schemas in property lines by the OASIS catastrophe modeling platform (see
OpenDataStandards (
2020)), there is much more work to do to further minimize human-in-the-loop interventions across all policy lines.
Future directions on algorithmic research include (1) applying more complex ML models beyond linear weighting or similarity matrices in order to determine match scores during entity resolution, and (2) tailoring ECLIPSE’s ML models to standardize other string enumerations in insurance datasets, beyond just schema column names and policy lines. This effort will likely improve on the classification KPIs and further boost the productivity of actuaries.
5. Conclusions
By applying ML/AI and data science techniques to insurance policies, ECLIPSE empowers actuaries with clean policy data. At Guy Carpenter, we have seen an over 50% reduction in time spent per client analysis, as the data preparation and cleaning is now largely automated with some human-in-the-loop, maximizing the time actuaries spend on core analysis and insight generation. We have shown how ECLIPSE’s components such as entity resolution and schema standardization algorithms also have drastic improvements over comparable solutions.
First, we saw how PIERCE standardizes insured entities, enabling policy aggregations. We advance some of the SOTA techniques outlined in
Papadakis et al. (
2020) by incorporating normalized similarity functions, more intricate blocking rules specific to insurance policy data, and a similarity matrix with tunable heuristic thresholds. In the future, we believe further improvements can be made leveraging nonlinear ML algorithms in conjunction with the similarity matrix, such as tree-based algos or neural networks. We find that we are able to maintain higher than 95% precision with a 70% match rate when we have addresses for insured entities, and an approximately 90% precision with a 60% match rate when we do not have addresses. As demonstrated, these results drastically improve the capacity for aggregation, and significantly outperform the SOTA of industrial entity resolution vendors.
Second, we applied the stacking technique to ensemble ML algorithms and standardize schemas and other string enumeration columns, such as the line of business. In the process, we used SOTA NLP techniques and developed an end-to-end, human-in-the-loop MLOps system. We showed how we can tune this system to tradeoff between performance and accuracy, and tune thresholds for encouraging human-in-the-loop action. As a result, we presented a more comprehensive overview of applying AI in insurance data preparation, than research papers have in the past. We encourage the adoption of the ECLIPSE standard and hope this system outline not only helps set industry standards but also aids future researchers and data practitioners as they prepare insurance data, such as policies, losses, or claims listings.







{kind=link}
{kind=link}
{kind=link}