
Adversarial Artificial Intelligence in Insurance: From an Example to Some Potential Remedies




Abstract
1. Introduction
2. Fraud in Insurance
3. AI and Adversarial AI in Insurance
4. Adversarial Attacks and Their Taxonomy
4.1. Adversarial Goal
4.2. Adversarial Capability
4.3. Adversarial Properties
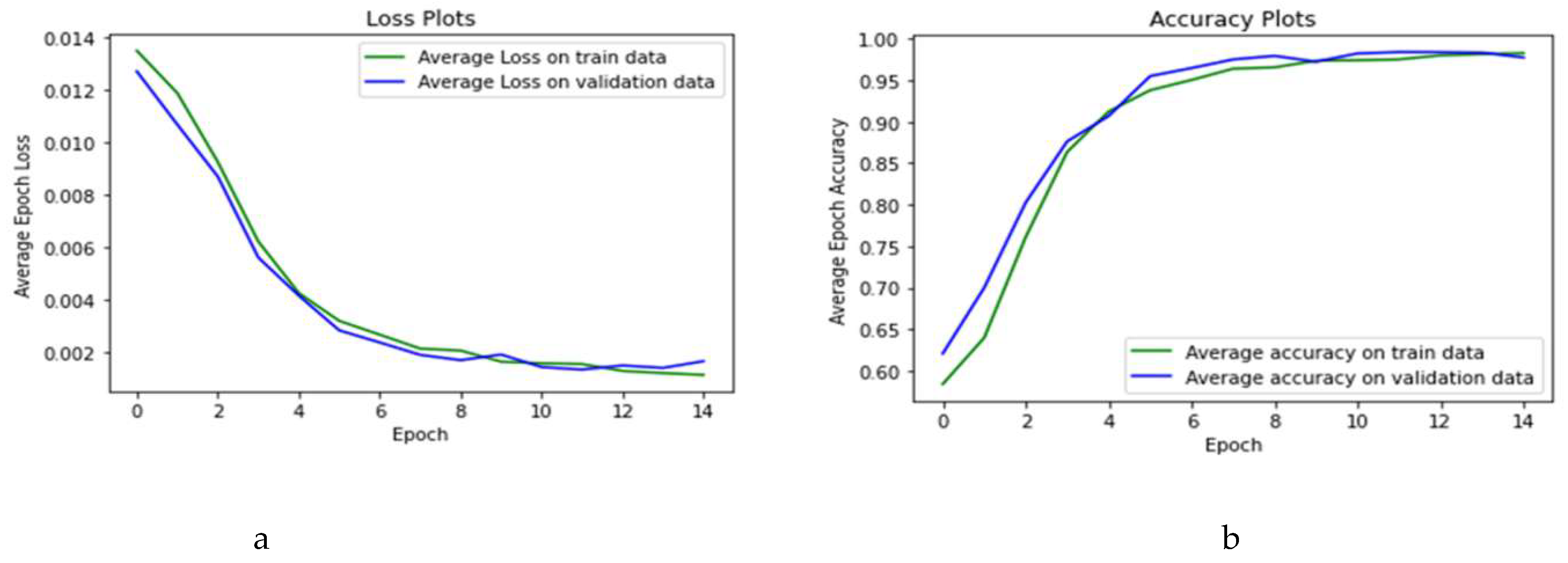
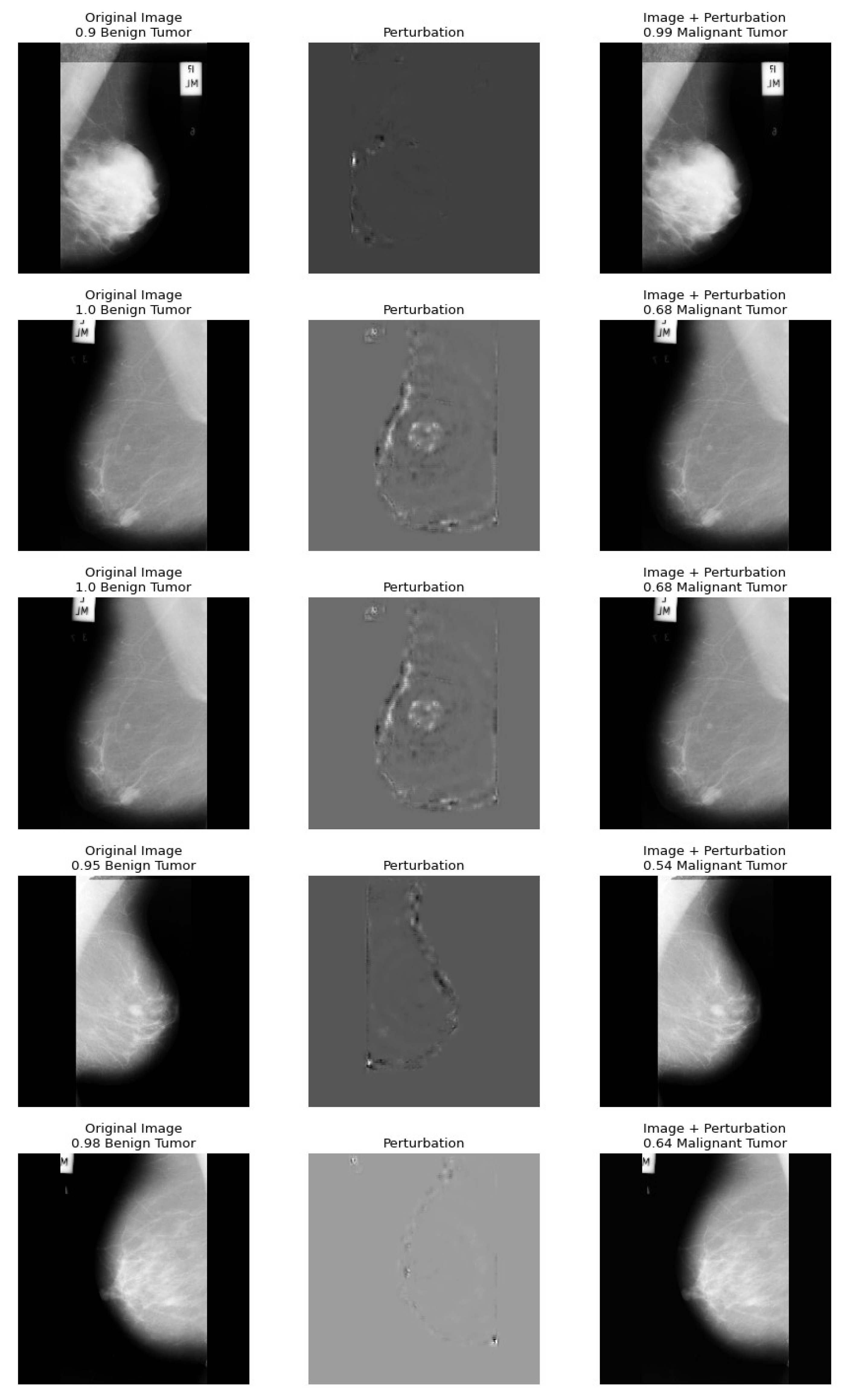
5. A Health Insurance Example and the Assessment of Damages
Dataset
6. Preparing for Adversarial Attacks
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. White-Box Attacks
- (1)
- Fast Gradient Sign Method
- (2)
- Projected Gradient Descent
- (3)
- DeepFool
- (4)
- Carlini and Wagner
Appendix A.1.1. Fast Gradient Sign Method
Appendix A.1.2. Projected Gradient Descent
Appendix A.1.3. DeepFool
Appendix A.1.4. Carlini and Wagner Attack (C and W)
Appendix A.2. Black-Box Attacks
- Substitute Model
- Gradient Estimation
Appendix A.2.1. Substitute Model
- (a).
- Synthesize a substitute training dataset: create a “replica” training set. For example, to attack handwritten digit recognition, create an initial substitute training set X by: (a) requiring samples from the test dataset or (b) creating handcrafting samples.
- (b).
- Training the surrogate model: feed the surrogate training dataset into the victim classifier to obtain their labels . Select a surrogate DNN model to train on to obtain . Based on the attacker′s knowledge, the chosen DNN should have a similar structure to the victim model.
- (c).
- Dataset augmentation: augment the dataset and iteratively re-train the substitute model . This procedure helps to increase the diversity of the replica training set and improve the accuracy of the substitute model .
- (d).
- Attacking the substitute model: use the previously presented attack methods, such as FGSM, to attack the model . The generated adversarial examples are also very likely to mislead the target model , due to the “transferability” property.
Appendix A.2.2. Gradient Estimation
Appendix A.3. Universal Attack
| 1 | |
| 2 | Accuracy in AI is defined as the ratio of true positives and true negatives to all positive and negative outcomes. It measures how frequently the model gives a correct prediction out of the total predictions it made. |
| 3 | |
| 4 | See, for instance, https://www.pinow.com/articles/305/insurers-on-the-alert-for-false-claims-turn-to-private-investigators, (accessed on 10 December 2022). |
| 5 | See https://www.fbi.gov/stats-services/publications/insurance-fraud (accessed on 5 June 2021). |
References
- Ai, Jing, Patrick L. Brockett, Linda L. Golden, and Montserrat Guillén. 2013. A robust unsupervised method forfraud rate estimation. Journal of Risk and Insurance 80: 121–43. [Google Scholar] [CrossRef]
- Artís, Manuel, Mercedes Ayuso, and Montserrat Guillén. 1999. Modelling different types of automobile insurance fraud behavior in the Spanish market. Insurance: Mathematics and Economics 24: 67–81. [Google Scholar]
- Artís, Manuel, Mercedes Ayuso, and Montserrat Guillén. 2002. Detection of automobile insurance fraud with discrete choice models and misclassified claims. The Journal of Risk and Insurance 69: 325–40. [Google Scholar] [CrossRef]
- Brockett, Patrick L., Richard A. Derrig, Linda L. Golden, Arnold Levine, and Mark Alpert. 2002. Fraud classification using principal component analysis of RIDITs. Journal of Risk and Insurance 69: 341–71. [Google Scholar] [CrossRef]
- Byra, Michał, Grzegorz Styczynski, Cezary Szmigielski, Piotr Kalinowski, Lukasz Michalowski, Rafal Paluszkiewicz, Bogna Wróblewska, Krzysztof Zieniewicz, and Andrzej Nowicki. 2020. Adversarial attacks on deep learning models for fatty liver disease classification by modification of ultrasound image reconstruction method. IEEE International Ultrasonics Symposium (IUS), 1–4. [Google Scholar] [CrossRef]
- Carlini, Nicholas, and David Wagner. 2017. Towards Evaluating the Robustness of Neural Networks. Paper presented at IEEE Symposium on Security and Privacy, San Jose, CA, USA, May 22–24; pp. 39–57. [Google Scholar] [CrossRef]
- Caron, Louis, and Georges Dionne. 1999. Insurance Fraud Estimation: More Evidence from the Quebec Automobile Insurance Industry. Automobile Insurance: Road Safety, New Drivers, Risks, Insurance Fraud and Regulation. Huebner International Series on Risk, Insurance, and Economic Security. Boston: Springer, vol. 20. [Google Scholar]
- Chen, Pin-Yu, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. 2017. ZOO: Zeroth Order Optimization based Black-Box Attacks to Deep Neural Networks without Training Substitute Models. Paper presented at 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, November 3; pp. 15–26. [Google Scholar] [CrossRef]
- Dionne, Georges, Florence Giuliano, and Pierre Picard. 2008. Optimal Auditing with Scoring: Theory and Application to Insurance Fraud. Management Science 55: 58–70. [Google Scholar] [CrossRef]
- Finlayson, Samuel G., Hyung Won Chung, Isaac S. Kohane, and Andrew L. Beam. 2019. Adversarial Attacks against Medical Deep Learning Systems. Science 363: 1287–89. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. 2015. Explaining and Harnessing Adversarial Examples. Paper presented at Conference ICLR, San Diego, CA, USA, May 7–9. [Google Scholar]
- Grize, Yves-Laurent, Wolfram Fischer, and Christian Lützelschwab. 2020. Machine learning applications in nonlife insurance. Applied Stochastic Models in Business and Industry 36: 523–37. [Google Scholar] [CrossRef]
- Hirano, Hokuto, Akinori Minagi, and Kazuhiro Takemoto. 2021. Universal adversarial attacks on deep neural networks for medical image classification. BMC Medicial Imaging 21: 1–13. [Google Scholar] [CrossRef]
- Joel, Marina Z., Sachin Umrao, Enoch Chang, Rachel Choi, Daniel Yang, James Duncan, Antonio Omuro, Roy Herbst, Harlan M. Krumholz, and Sanjay Aneja. 2021. Adversarial Attack Vulnerability of Deep Learning Models for Oncologic Images. medRxiv. [Google Scholar] [CrossRef]
- Kenett, Ron S., and Thomas C. Redman. 2019. The Real Work of Data Science: Turning Data into Information, Better Decisions, and Stronger Organizations. Hoboken: John Wiley & Sons. [Google Scholar]
- Kenett, Ron S., Shelemyahu Zacks, and Peter Gedeck. 2022. Modern Statistics: A Computer-Based Approach with Python. Berlin/Heidelberg: Springer Nature. [Google Scholar]
- Kooi, Thijs, Geert Litjens, Bram Van Ginneken, Albert Gubern-Mérida, Clara I. Sánchez, Ritse Mann, Ard den Heeten, and Nico Karssemeijer. 2017. Large scale deep learning for computer aided detection of mammographic lesions. Medical Image Analysis 35: 303–12. [Google Scholar] [CrossRef] [PubMed]
- Kurakin, Alexey, Ian J. Goodfellow, and Samy Bengio. 2017a. Adversarial Examples in the Physical World. Paper presented at ICLR, Toulon, France, April 24–26; p. 14. [Google Scholar]
- Kurakin, Alexey, Ian J. Goodfellow, and Samy Bengio. 2017b. Adversarial Machine Learning at Scale. Paper presented at ICLR, Toulon, France, April 24–26. [Google Scholar]
- Li, Bin, Yunhao Ge, Yanzheng Zhao, Enguang Guan, and Weixin Yan. 2018. Benign and malignant mammographic image classification based on Convolutional Neural Networks. Paper presented at 2018 10th International Conference on Machine Learning and Computing, Macau, China, February 26–28. [Google Scholar]
- Mirsky, Yisroel, Tom Mahler, Ilan Shelef, and Yuval Elovici. 2019. CT-GAN: Malicious Tampering of 3D Medical Imagery using Deep Learning. Paper presented at 28th USENIX Security Symposium, Santa Clara, CA, USA, August 14–16. [Google Scholar]
- Moosavi-Dezfooli, Seyed-Mohsen, Alhussein Fawzi, and Pascal Frossard. 2016. A Simple and Accurate Method to Fool Deep Neural Networks. Paper presented at IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, June 27–30; pp. 2574–82. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, Seyed-Mohsen, Alhussein Fawzi, Omar Fawzi, and Pascal Frossard. 2017. Universal Adversarial Perturbations. Paper presented at IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, July 21–26. [Google Scholar]
- Papernot, Nicolas, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z. Berkay Celik, and Ananthram Swami. 2017. A Practical Black-Box Attacks against Machine Learning. Paper presented at 2017 ACM Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, April 2–6; pp. 506–19. [Google Scholar] [CrossRef]
- Qiu, Shilin, Qihe Liu, Shijie Zhou, and Chunjiang Wu. 2019. Review of Artificial Intelligence Adversarial Attack and Defense Technologies. Applied Science 9: 909. [Google Scholar] [CrossRef]
- Ren, Kui, Tianhang Zheng, Zhan Qin, and Xue Liu. 2020. Adversarial Attacks and Defenses in Deep Learning. Engineering 3: 346–60. [Google Scholar] [CrossRef]
- Sadeghi, Somayeh, Sajjad Dadkhah, Hamid A. Jalab, Giuseppe Mazzola, and Diaa Uliyan. 2018. State of the Art in Passive Digital Image Forgery Detection: Copy-Move Image Forgery. Pattern Analysis and Applications 21: 291–306. [Google Scholar] [CrossRef]
- Singh, Amit Kumar, Basant Kumar, Ghanshyam Singh, and Anand Mohan. 2017. Medical Image Watermarking Techniques: A Technical Survey and Potential Challenges. Cham: Springer International Publishing, pp. 13–41. [Google Scholar] [CrossRef]
- Suckling, John. 1996. The Mammographic Image Analysis Society Digital Mammogram Database. Available online: https://www.kaggle.com/datasets/tommyngx/mias2015 (accessed on 10 February 2019).
- Ware, Colin. 2019. Information Visualization: Perception for Design. Burlington: Morgan Kaufmann. ISBN 9780128128756. [Google Scholar]
- Wetstein, Suzanne C., Cristina González-Gonzalo, Gerda Bortsova, Bart Liefers, Florian Dubost, Ioannis Katramados, Laurens Hogeweg, Bram van Ginneken, Josien P. W. Pluim, Mitko Veta, and et al. 2020. Adversarial Attack Vulnerability of Medical Image Analysis Systems: Unexplored Factors. Medical Image Analysis 73: 102141. [Google Scholar]
- Xu, Han, Yao Ma, Haochen Liu, Debayan Deb, Hui Liu, Jiliang Tang, and Anil K. Jain. 2020. Adversarial attacks and defenses in images, graphs and text: A review. International Journal of Automation and Computing 17: 151–78. [Google Scholar]
- Zhang, Jiliang, and Chen Li. 2018. Adversarial Examples: Opportunities and Challenges. IEEE Transactions on Neural Networks and Learning Systems 16: 2578–93. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Chaoning, Philipp Benz, Chenguo Lin, Adil Karjauv, Jing Wu, and In So Kweon. 2021. A Survey On Universal Adversarial Attack. Paper presented at Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, August 19–26. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Adversarial Goal | Adversarial Properties | Adversarial Capability | |
|---|---|---|---|
| Confidence Reduction | Training | Inference | |
| Misclassification | Transferability | Data Injection | White-Box Attack |
| Targeted Misclassification | Adversarial Instability | Data Modification | Black-Box Attack |
| Source Misclassification | Regularization Effect | Logic Corruption | Gray-Box Attack |
| Perturbation ϵ | Model Accuracy | Perturbation ϵ | Accuracy |
|---|---|---|---|
| 0 | 0.959 | 0.006 | 0.626 |
| 0.001 | 0.927 | 0.007 | 0.610 |
| 0.002 | 0.878 | 0.008 | 0.569 |
| 0.003 | 0.821 | 0.010 | 0.512 |
| 0.004 | 0.756 | 0.015 | 0.431 |
| 0.005 | 0.691 | 0.20 | 0.390 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amerirad, B.; Cattaneo, M.; Kenett, R.S.; Luciano, E. Adversarial Artificial Intelligence in Insurance: From an Example to Some Potential Remedies. Risks 2023, 11, 20. https://doi.org/10.3390/risks11010020
Amerirad B, Cattaneo M, Kenett RS, Luciano E. Adversarial Artificial Intelligence in Insurance: From an Example to Some Potential Remedies. Risks. 2023; 11(1):20. https://doi.org/10.3390/risks11010020
Chicago/Turabian StyleAmerirad, Behnaz, Matteo Cattaneo, Ron S. Kenett, and Elisa Luciano. 2023. "Adversarial Artificial Intelligence in Insurance: From an Example to Some Potential Remedies" Risks 11, no. 1: 20. https://doi.org/10.3390/risks11010020
APA StyleAmerirad, B., Cattaneo, M., Kenett, R. S., & Luciano, E. (2023). Adversarial Artificial Intelligence in Insurance: From an Example to Some Potential Remedies. Risks, 11(1), 20. https://doi.org/10.3390/risks11010020