1. Introduction
One crucial actuarial task is designing a charge structure that fairly distributes the responsibility of claims among policyholders. This is computed using the best model available to determine insurance premiums. The bonus-malus system (BMS) adjusts the premiums according to individual claim history and is popularly used, especially in automobile insurance, to determine that fair premiums are paid by all policyholders. As a reward for accident-free driving, a bonus is offered as a discount, whereas a malus results in an increase in the premium. The introduction of a BMS that links the premium to the number of reported claims will cause a tendency for policyholders to shoulder small claims on their own and not report them to their company to avoid a premium increase. “Hunger for bonus” is the term used to describe this phenomenon (
Lemaire 1985).
Lemaire (
1976,
1977) studied the hunger for bonus and proposed a dynamic programming algorithm to determine the optimal claiming behavior. The BMS is used by insurance companies for two main reasons. The first is to encourage insureds to drive more cautiously throughout the year to avoid claims, and the latter is to ensure that insureds pay premiums that are proportional to their risks based on their claim experiences (
Bühlmann 1967). The basic principle of this system is that greater claim frequencies result in higher premiums. The traditional BMS was solely dependent on the random variable of number of claims (
Déniz 2016). However, not all events result in the same claim amount for an insured person. Because of different claim sizes, it makes sense to design a BMS based on both claim frequency and claim severity.
Several methodologies under the BMS framework have been used to determine fair premiums paid by policyholders. One of the most popular ways to determine premiums is the Bayesian method. Each policyholder has a constant as an unequal underlying risk. This unknown constant is referred to as a risk parameter and is treated as a random variable, with a specific probability distribution known as a prior distribution or structure-function distribution. This method is useful for calculating premiums in the BMS based on specific transition rules that distinguish policyholders as a bonus or malus. By dividing a posterior mean of the parameter by a prior mean, the basic Bayesian tool is easily applied to Bayes’ theorem. This tool employs the net premium principle and provides an estimate of risk parameters to distinguish between low- and high-risk policyholders.
The Poisson distribution is normally used to explain an independent random event of claims in vehicle insurance and expresses the behavior probability of individual policyholders (
Déniz 2016). However, it cannot adequately describe the number of claims in an insurance portfolio. The negative binomial distribution, a type of mixing distribution with a Poisson distribution and a gamma distribution, was studied by
Greenwood and Yule (
1920). This marked the start of the process of constructing mixed Poisson distributions. A mixed Poisson was proposed for claim frequency distribution by
Tremblay (
1992). He designed an optimal BMS by mixing the Poisson distribution with the inverse Gaussian distribution, which has a wide variety of applications in medicine, finance, business, survival analysis and even in the maximum durability problem of investment in the gold market (
Moumeesri and Klongdee 2019). In the automobile insurance sector, the random number of claims was also assumed to be Poisson distributed, while the randomly expected inherent risks of each insured person followed an inverse Gaussian distribution. Here, the Bayesian method was applied to estimate the posterior portfolio distribution function for a scenario covering the past t years. The expected premium value was calculated based on the BMS principle. Several papers have discussed mixing other distributions to obtain an optimal bonus-malus premium for the claim frequency (
Dionne and Vanasse 1992;
Lemaire 1995;
Walhin and Paris 1999;
Tzougas and Frangos 2014;
Tzougas et al. 2019;
Tzougas 2020). However, premium payments based on the BMS show no difference between a claim made by a policyholder for a small loss and another with a big loss. This phenomenon is called “hunger for bonus” (
Lemaire 1985). For instance, a claim of USD 50 by a policyholder should not be penalized by the same increase in premium as a claim of USD 500.
Déniz (
2016) and
Hernawati et al. (
2017) proposed a model to determine premiums based on a BMS that distinguished two types of claims: those less than the limit value and those that exceeded this value. The result was a fairer method of penalizing all policyholders in the portfolio.
Déniz and Calderín-Ojeda (
2018) further developed the proposal of
Déniz (
2016). They studied a trivariate model where claims were distinguished into three types, while
Pongsart et al. (
2022) proposed a model for computing Bayesian bonus-malus premiums by distinguishing different multiple types of claims.
Our analysis identified situations where this concept should not be regarded as the fairest approach for penalizing policyholders. These included cases where only a few claims were made but the claim amount was large, or where a policyholder made a higher number of claims but the total claim amount was small. Therefore, the premium calculation based on the BMS should also assess the total claim amount. An optimal method to determine the premium charged to an insured must take both frequency and severity components into account (
Frangos and Vrontos 2001). Many studies have attempted to determine premiums based on the BMS by including more factors than using only claim frequency in a model (
Frangos and Vrontos 2001;
Mert and Saykan 2005;
Ibiwoye et al. 2011;
Ni et al. 2014;
Tzougas et al. 2015,
2017,
2018;
2020;
Santi et al. 2016;
Oh et al. 2019;
Moumeesri et al. 2020;
Jacob and Wu 2020). They proposed a model in which claim frequency and claim severity were included jointly to compute the bonus-malus premiums. This model was constructed by multiplying the bonus-malus premium based only on the number of claims with the bonus-malus premium based on the individual claim size. In addition, there was the work done to integrate the BMS into the farm insurance product.
Boucher (
2022) suggested developing unique BMSs using recursive partitioning techniques to each type of insured.
Here, we propose a model in which claim frequency and claim severity are included jointly to determine bonus-malus premiums by distinguishing two types of claims: those below a limit value classified as small, and the rest classified as large. The number of claims was assumed to be Poisson distributed, while the total number of claims with claim size larger than the limit value was assumed to follow a binomial distribution. The underlying risk of each policyholder was taken to be Lindley and beta distributed for the prior distributions. For claim severity distribution, we assume that the claim size of each policyholder follows a gamma distribution. The prior distribution was introduced as a Lindley distribution. To calculate the posterior structure functions for claim frequency and claim severity distributions, we followed the Bayesian approach. The mean of these functions was used to calculate the premiums paid by a policyholder.
The remainder of this paper is structured as follows.
Section 2 discusses the methodology, divided into two parts as claim frequency distribution and claim severity distribution. Mixing distributions, the Bayesian method and the premium calculation are also explained.
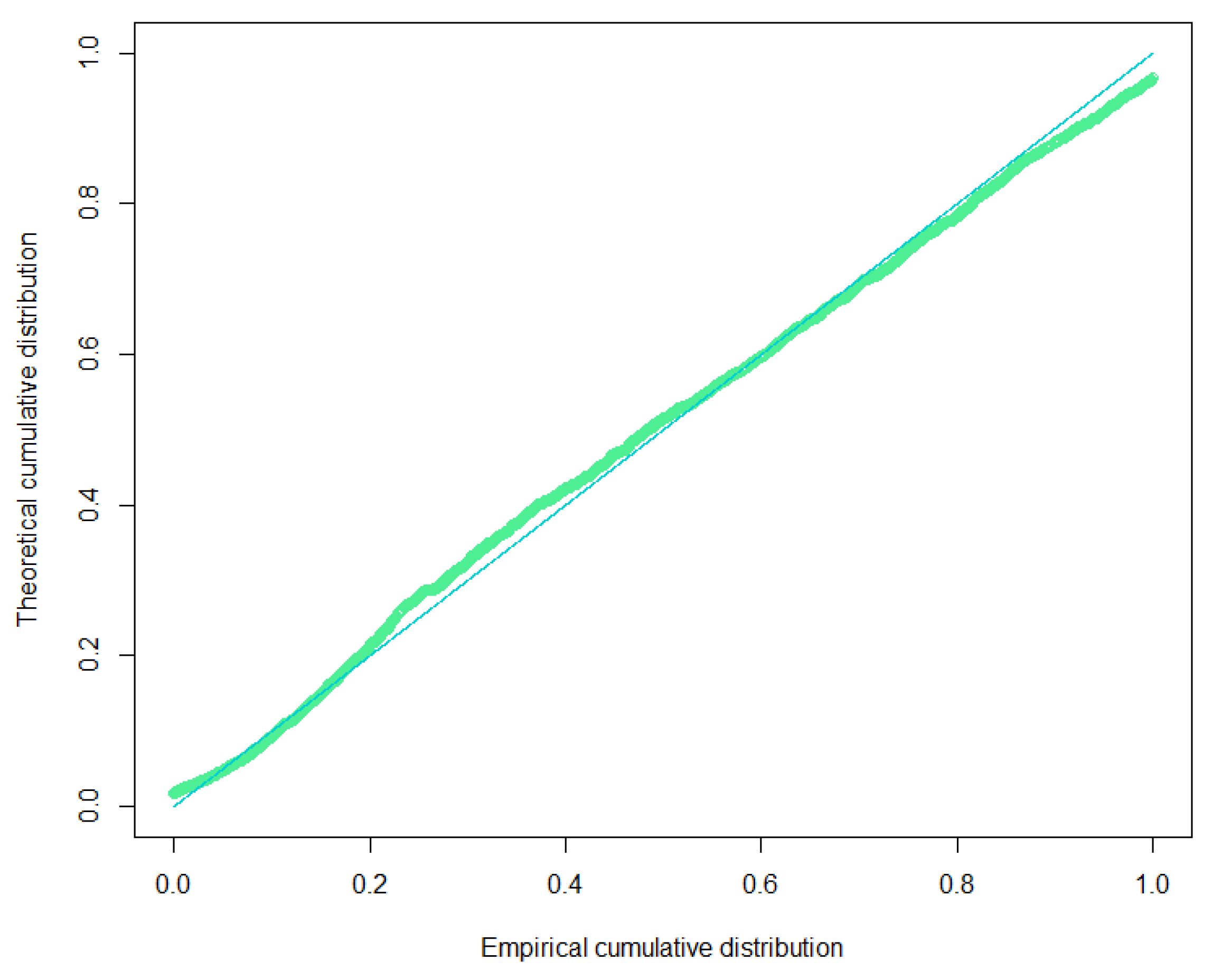
Section 3 illustrates the numerical applications and discusses the results using real claim data separated as claim frequency components and claim severity components. The results obtained are compared with those derived from the traditional Poisson-Lindley model that does not distinguish the type of claims (see
Moumeesri et al. 2020 for details), and those achieved under the Poisson binomial-exponential beta model (see
Hernawati et al. 2017 for details). The conclusions drawn are presented in
Section 4.
4. Conclusions
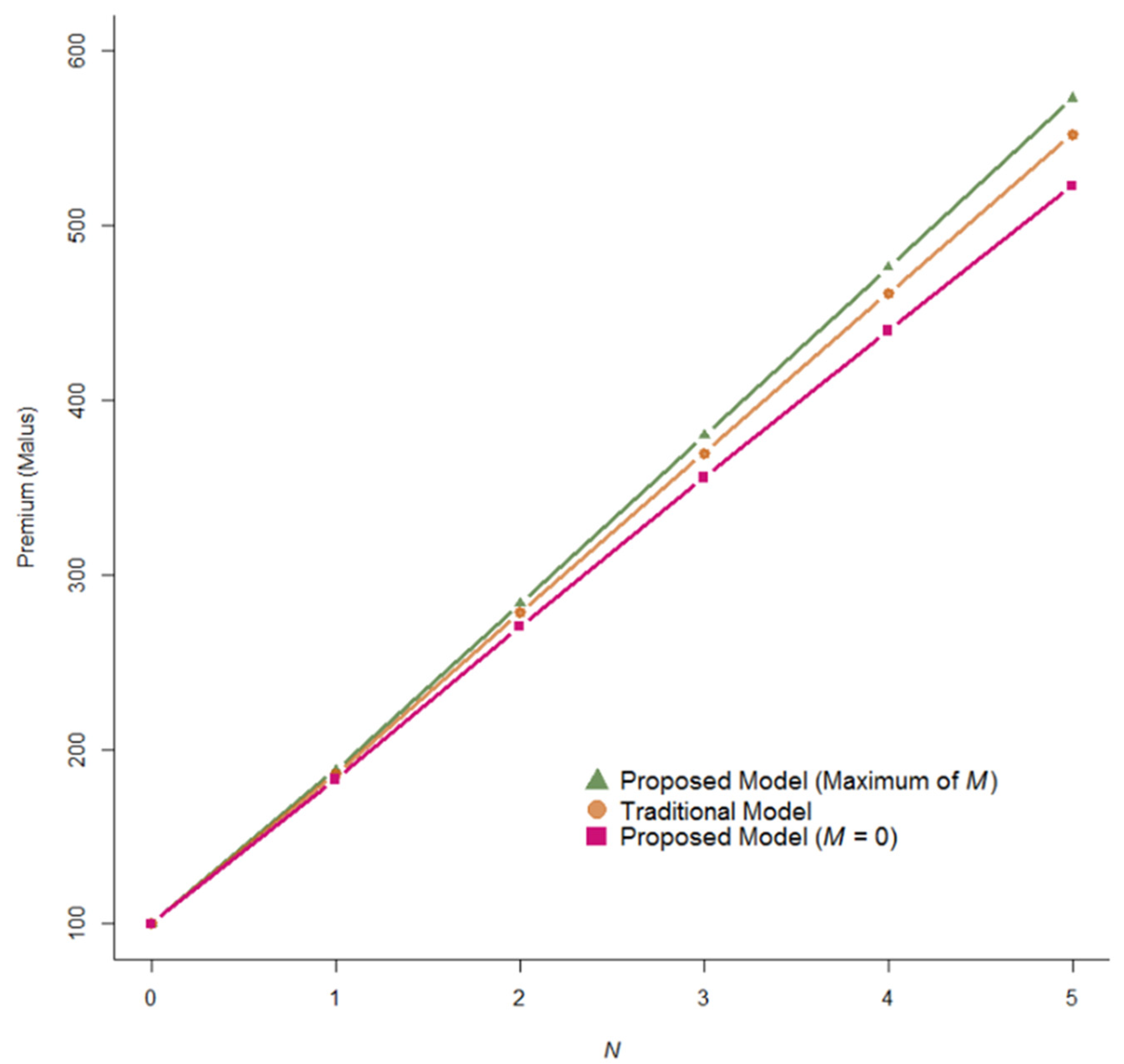
A model was proposed to determine optimal bonus-malus premiums that considered both claim frequency and claim severity components by distinguishing two types of claims based on claim amounts beneath and above a threshold value. Two mixed distributions, the Poisson binomial with the Lindley beta distribution and a mixed gamma with Lindley distribution, were investigated and employed in the model as frequency distribution and severity distribution, respectively. The Bayesian method was applied in the model as a frequency component and a severity component. Both models were then integrated. The new model rewarded and penalized all policyholders in a fairer manner.
An example of real automobile insurance data was used to illustrate our model. Fitted results of claim frequency were better than the traditional Poisson binomial-exponential beta model. When claims occurred, high-risk policyholders were liable to more severe penalties under the traditional model. Our proposed model presents a reasonable alternative method for rewarding and penalizing both low- and high-risk policyholders. The obtained premiums could be used by insurers to gain market share in the highly competitive insurance industry.
To increase impartiality of assigning premium to all policyholders, further different types of claims could be distinguished as a topic for further research.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}