1. Introduction
The stochastic nature of values in run-off triangles (and quadrangles) has generally not been examined in traditional non-life reserving. Instead, actuaries have tended to focus on ameliorating the point estimates for ultimate claims. This approach has gradually changed since stochastic claims reserving methods became common practice, see
England and Verrall (
2002);
Wüthrich and Merz (
2008). The prediction of future claims’ or payments’ random nature is more and more frequently required in the insurance industry; therefore, the spread of stochastic methods in practice is fairly natural. The estimation of standard deviation, value-at-risk (VaR) and tail value-at-risk (TVaR) have started to become regular exercises in the insurance and financial industries.
England et al. (
2019) demonstrates methods for analysing reserve risk and provides models for full predictive claim distribution, which can be applied both for SII and IFRS 17. In the present article, we scrutinise the appropriateness of these models and compare them with two other reserving methods. In essence, stochastic reserving methods forecast probability distributions. Therefore, it is reasonable that we apply tools from the theory of probabilistic forecasts in order to measure the quality of the reserving techniques. The theory of probabilistic forecasting has become widespread in recent years, see
Gneiting and Katzfuss (
2014);
Gneiting et al. (
2007). Applications of this theory for non-life claims reserving can be found in
Arató et al. (
2017), for instance.
We will show that the VaR estimations of the tested methods are generally inaccurate. This result is not surprising: the adequate estimation of the -VaR can hardly be expected based on 50–200 connected data points, let alone of the -VaR. Nevertheless, our view is that this inherent inaccuracy does not necessarily mean that the system is less useful, since the -VaR that the standard formula of SII yields has hardly anything to do with the real -VaR. Yet, the system works. The stochastic reserving methods demonstrated in the present paper reflect on the future’s uncertainty; however, we need to acknowledge their limits.
In the past decade, granular models were established that use policy-by-policy claim development information. These models are referred to as micro models
Antonio and Plat (
2014). Even more recently, non-linear neural network regression models have started to be explored
Wüthrich (
2018). Due to the availability of actual observations, we focus on models on run-off triangles.
In terms of structure, after the present introduction,
Section 2 compares the predictive performance of four models on real data from
Meyers and Shi (
2011). The time horizon of forward-looking is one year in accordance with Solvency II.
Section 3 repeats the same test of model appropriateness, but on artificially simulated data from log-normal and gamma distributions.
Section 4 is the juxtaposition of one-year Solvency II and multi-year IFRS 17 value-at-risk quantiles. Despite the fact that IFRS 17 does not stipulate the exact metric for risk adjustment calculation, we may expect that VaR will be widely applied by insurance institutions. Fully completed triangles (quadrangles), i.e., claim run-offs in the long run are looked at in
Section 4 and in more detail in
Martinek (
2019).
Section 5 concludes the paper.
2. Actual Data–Based Validation of Techniques
Several insurance institutions have contributed to the publishing of actual loss data from six business lines
Meyers and Shi (
2011). We will refer to these data as NAIC data (National Association of Insurance Commissioners). The associated claims occurred during accident years between 1988 and 1997 with a development lag of a maximum of 10 years each. Therefore, each triangle is of the size
. In the present analysis, 355 observations have been used, combined from business lines of commercial auto and truck liability and medical insurance (84), medical malpractice—claims made (12), other liability—occurrence (99), private passenger auto liability and medical (88), product liability—occurrence (14), and workers’ compensation (58).
Four models are compared in this paper. The first two can be found in
England et al. (
2019). These are non-parametric and parametric bootstrapped modifications of the original model
Mack (
1993), resampling with replacement from the scaled bias adjusted Pearson residuals. The third and the fourth ones are credibility-type models that embed information from a range of observed triangles in the completion of every single triangle, see
Martinek (
2019). One is based on the over-dispersed Poisson model and the other one is a semi-stochastic model. See
Appendix A for a more detailed description of the models.
Value-at-risk is a key metric in SII that determines the solvency capital ratio and consequently the risk margin. We have tested the relation of estimated VaR to the actually observed claims data, see
Table 1. Each element of the table reflects the following: Applying a given model one-by-one on the available triangles to calculate the
and
-VaR, in what percentage of the cases does the estimated VaR exceed the actual observation? All metrics correspond to the claims development result
, where (1) stands for the claims reserves at the beginning of calendar year
y, (2) denotes the payments made during calendar year
y and (3) represents the claims reserves at the end of calendar year
y. Similarly, in the multiyear case, (1) and (3) are the beginning and the end of the period reserve, and (2) the payments made in this particular time frame. If a reserving model perfectly fits the underlying characteristics of the data, this value should be exactly the VaR-percentile on average in the corresponding column of the table.
We have concluded that all of the observed models underestimate the VaR based on the NAIC data. The most extreme one is the parametric version of the Mack bootstrap, where only of the total ultimate claims are below the -VaRs. The credibility semi-stochastic model performs somewhat better, where this value is vs. the -VaR. Overall, running the four models on the actual data implies a systematic underestimation of VaRs, i.e., the underestimation of the capital requirement and the risk margin.
Subsequently, we look at the claim distributions estimated by the models in comparison with the empirical distributions determined by the actual claims. In probabilistic forecasts
-coverage expresses the probability that the observation (from the real distribution) falls into the
-central prediction interval of the estimated distribution, see
Baran et al. (
2013). In other words, with
F estimation and
G real distribution,
-coverage is the
G-measure of the central
prediction interval of
F, i.e.,
In the ideal case when
the
-coverage value is exactly
, see the ideal coverage line in
Figure 1. Observe that each of the models are below the ideal identity line, which reinforces the finding pointed out in relation to the VaR, i.e., overly narrow prediction intervals. For instance, the
-coverage of the prediction made by the non-parametric Mack bootstrap model is
, very similarly to the credibility semi-stochastic (
) and credibility ODP (
) methods, and only the parametric Mack bootstrap stands out with
.
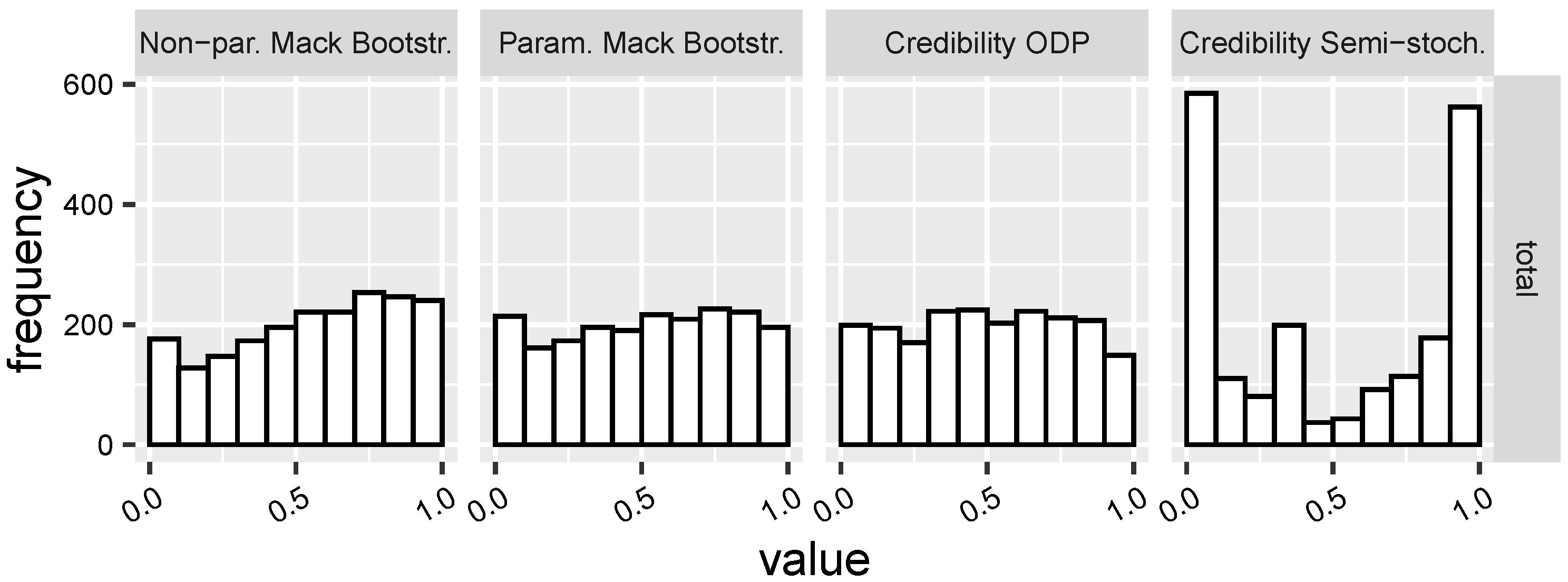
In order to further improve our understanding of the prediction quality, we have visualised the PIT-plots for each model, see
Meyers (
2015). Firstly, we have calculated the probability integral transform values of each triangle and prediction:
, where
is the prediction made by the specific model on one triangle and
the real observation. Secondly, we have plotted the histogram of
. If
is governed by
for each
i, then
. Hence, we expect a uniform histogram for a perfect model (as a necessary condition). However, the plots turn out to be non-uniform in
Figure 2 and mainly underdispersed ∪-shaped, which implies narrow prediction intervals. In addition, these graphs are asymmetric, meaning that the predictions’ levels of underdispersion are asymmetric.
Continuous ranked probability scores (CRPS) measure the quality of probabilistic forecasts, see
Gneiting and Raftery (
2007). By definition, given a prediction
F and claim observation
x,
We have approximated the expected CRPS by the average of scores resulting from prediction-observation pairs in
Table 2. Sporadically, there can be score values with extreme absolute values; therefore, the median scores are also shown in the table. CRPS has its range in
and the higher the value, the better the prediction. The best ones, the non-parametric Mack bootstrap and credibility ODP models, perform similarly, trailed by the parametric Mack bootstrap model, and lastly, the credibility semi-stochastic one, which underperforms all of them. (The extreme CRPS is due to an extreme value, see the median for comparison.)
At last, the average width of prediction
expresses the
G-expected value of the
-central prediction interval’s width determined by
F, where
F is the predicted distribution and
G is the real one,
. The lower the average width, the sharper the prediction. Note that this metric is expressed in terms of monetary value. In
Figure 3, it can be observed that the Mack bootstrap methods are consistently sharper than the credibility-type methods.
3. Validation of Techniques from Simulations
Having tested the predictive power of the models on actual data in
Section 2, now we simulate fictitious claim histories, i.e., upper triangles and their lower counterparts. Two claim evolution models, the log-normal and the gamma ones, will be used, see
Arató et al. (
2017). Once these hypothetical observations are done, the validation works in exactly the same manner as in
Section 2. The selection of log-normal and gamma models is arbitrary; however, in one form or another these are applied by the insurance industry.
The sample size is 2000, i.e., the number of observed triangles (quadrangles) is significantly larger than in the NAIC database. The number of bootstrapping steps in the Mack bootstrap and credibility ODP models is 200,000 for each triangle. For the initial parameter selection of both log-normal and gamma models, we have estimated the parameters from the triangle published by
Taylor and Ashe (
1983). This initial run-off triangle has been used exclusively for setting the model parameters.
First, we look at the quality of VaR estimations. When the real claim run-off is governed by the log-normal model, we observe that each of the four estimation methods underestimates the quantiles, see
Table 3. In contrast, if the real model is gamma, then both Mack bootstrap models and the credibility ODP model highly overestimate the associated VaRs, see
Table 4. Remarkably, the credibility semi-stochastic method consistently underestimates VaRs regardless of the underlying simulation, while it has outperformed all the other estimation methods on real data in
Section 2.
In terms of coverage, Mack bootstrap and credibility ODP models perform reasonably well, see
Figure 4 and
Figure 5. As we have seen above with VaR estimation performance, the credibility semi-stochastic method is again an outlier compared to the other three, resulting in underdispersed estimations. These findings in the log-normal and gamma simulations, to the contrary, are substantially different than in the case of real observations.
For further visualisation of how narrow or good-fit the prediction intervals are, see the PIT histograms in
Figure 6 and
Figure 7. For the log-normal underlying distribution, all the methods except for the semi-stochastic one (that has ∪-shaped PIT) result in uniform PIT histograms. However, in the case of the gamma distribution, all the methods deviate from the uniform shape. See
Appendix B for CRPS and average width figures.
In this section, we have scrutinised claims evolutions with finite higher moments. However, it is interesting to consider the performance of reserving models in the context of distributions with non-finite moments.
Denuit and Trufin (
2017) presents a case study based on real claims and describes a frequency-severity setting with a discrete mixture severity distribution for each claim size: gamma or inverse Gaussian with probability
as a light-tailed component and Pareto type II with probability
as a heavy-tailed component.
4. Reconciliation of Solvency II Risk Margin with IFRS 17 Risk Adjustment
In this section, we compare in two ways how the one-year -VaR of SII relates to the multiyear VaR of IFRS 17, i.e., the long-term view of reserve risk. In contrast to SII, the IFRS 17 regime does not stipulate the exact way of risk calculation and how the risk adjustment needs to be determined. Nevertheless, we may assume that a large proportion of market participants will apply either VaR or possibly TVaR for the shocked scenarios.
Firstly, we take a reserving model and , and observe the proportion of actual long-term observations compared to the total where the models’ one-year -VaR would have also been sufficient on the long-run. Secondly, for every method and run-off triangle i, we find which multiyear -VaR is equal to the one-year -VaR. Overall, 50,000 scenarios have been used in the Mack Bootstrap models.
In
Table 5, we show how the one-year VaRs relate to the actual observations, i.e., in what ratio they exceed the actually observed payments in the total (10-year) run-off of claims, see Equation (
1). In other words, the number of cases where the one-year VaR exceeds the long-run claims development divided by the total number of observations. This table contains comparisons not only for the SII one-year
-VaR, but also for the
and the
ones. For instance, applying the non-parametric Mack Bootstrap method, the resulted
-VaR values (in accordance with SII) provided a sufficient capital buffer in
of the cases in the long-run. Observe that these values are rather different per estimation method, just as we have seen in
Table 1.
In the second comparison, we determine which
results in the same multiyear VaR as the
-VaR on the NAIC data, i.e., we solve
where the left hand side represents the multiyear and the right hand side the one-year development of claims. The results are based on 355 observations (company per business line) from the NAIC database, and the six business lines contribute to the results combined. In
Table 6, these
solutions per method are shown. In contrast to the first comparison, the second one produces
values. Therefore, each of the four models outlines a distribution of
values, and the quartiles, means and medians are incorporated into the table.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








