
Improved Object Detection Artificial Intelligence Using the Revised RetinaNet Model for the Automatic Detection of Ulcerations, Vascular Lesions, and Tumors in Wireless Capsule Endoscopy


 , , ,
, , , 
Abstract
1. Introduction
2. Materials and Methods
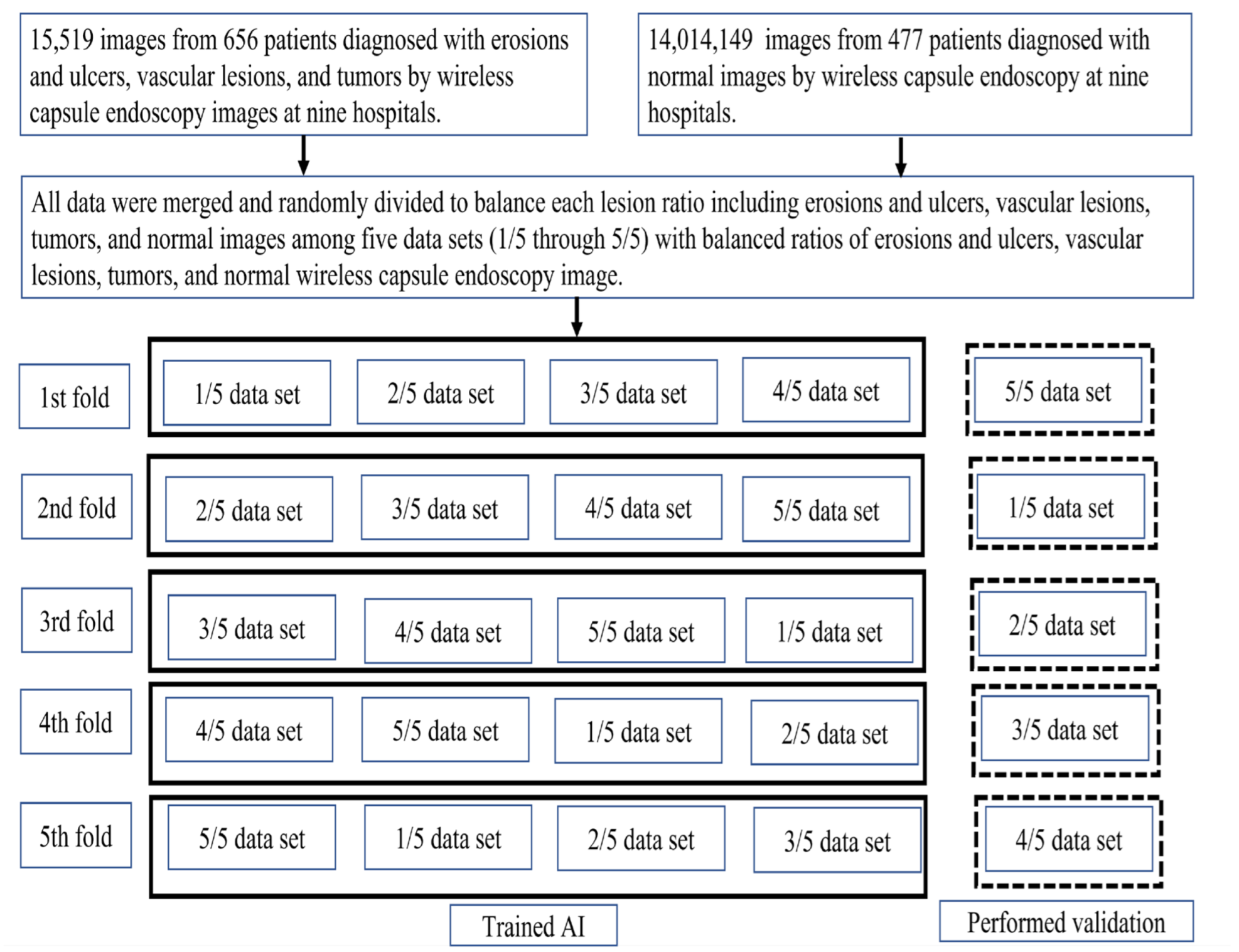
2.1. Study Sample and Preparation of the Image Set
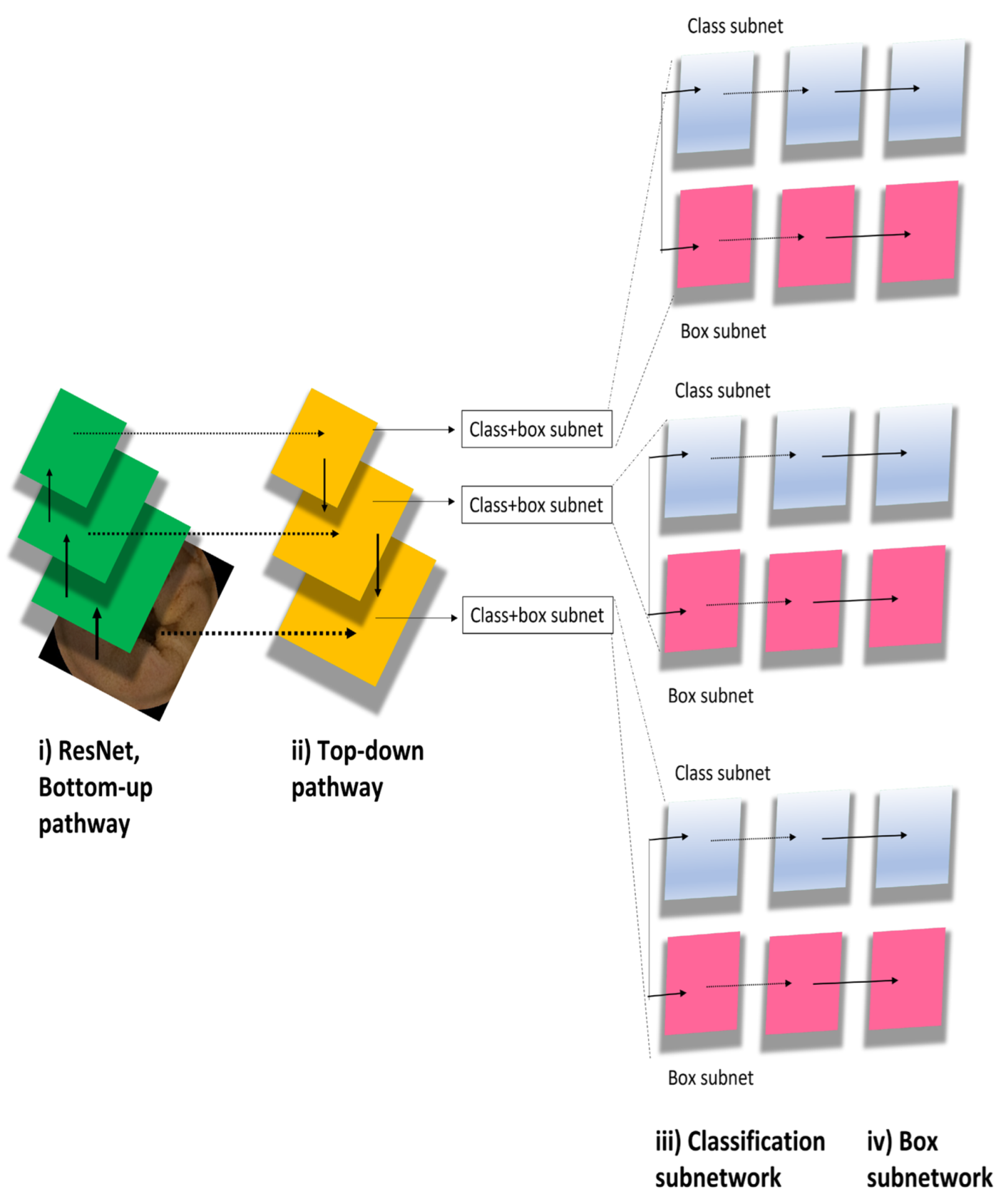
2.2. RetinaNet Algorithm
2.3. Outcome Measures and Statistics
3. Results
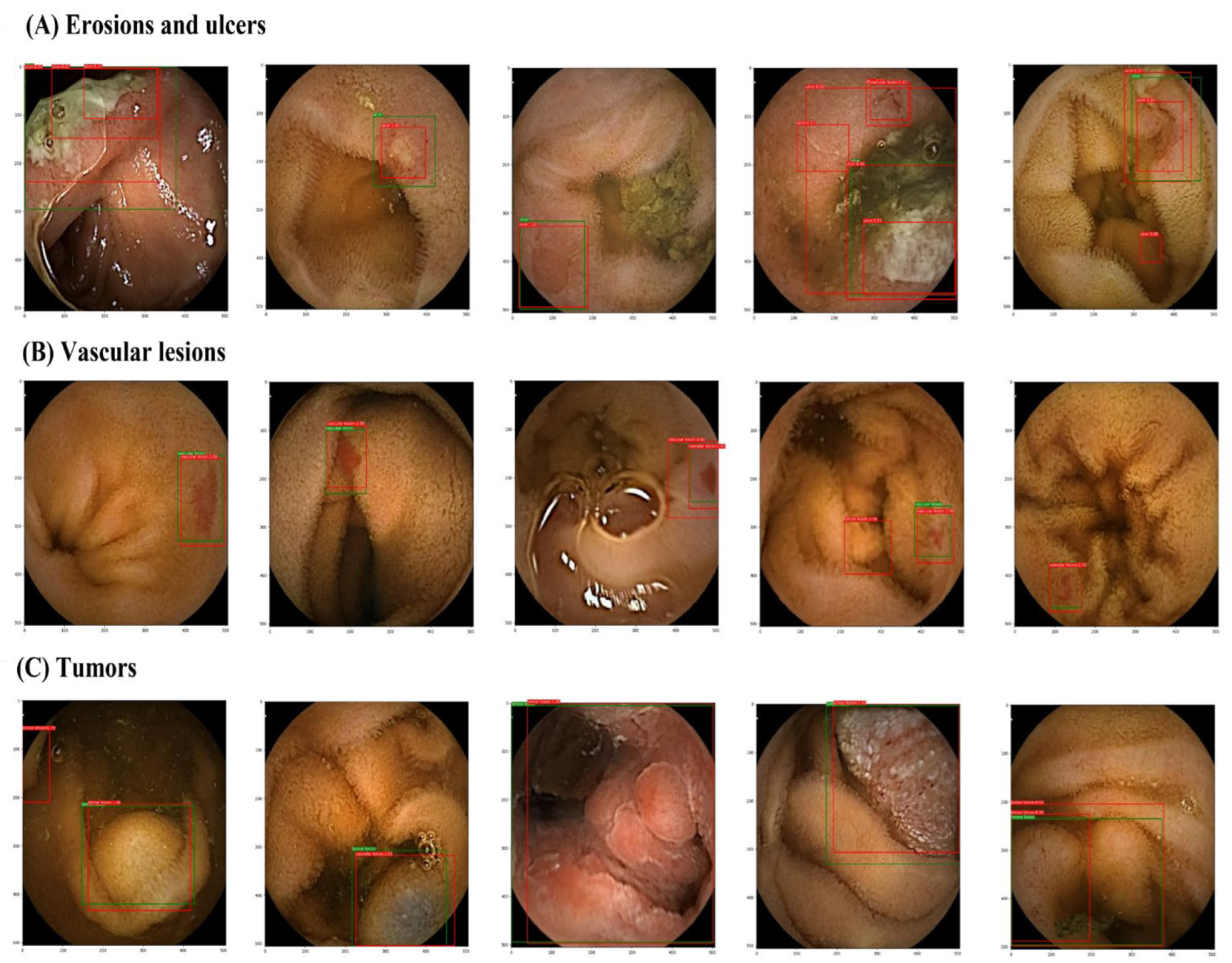
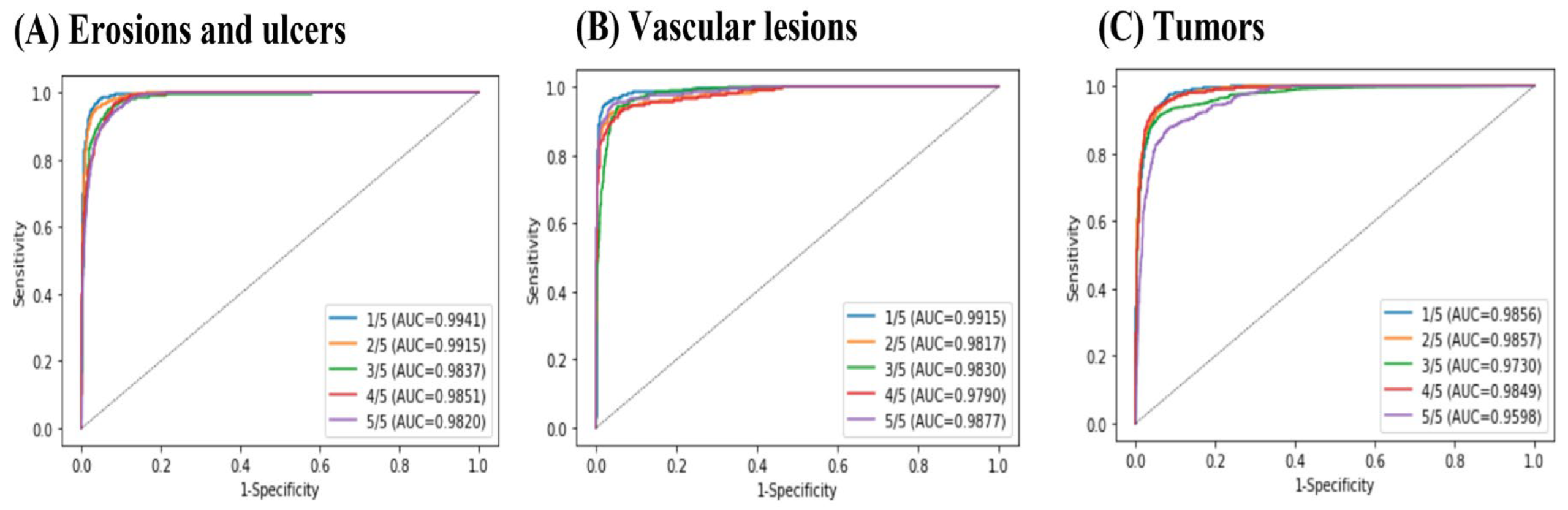
3.1. Per-Lesion Image Analyses
3.2. Per-Lesion IOU Analyses
3.3. Per-Patient Analyses
4. Discussion
4.1. Improved Specificity and Accuracy of Tumor Detection
4.2. High Specificity of the RetinaNet Algorithm for All Types of Lesion
4.3. Future Tasks
4.4. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Iddan, G.; Meron, G.; Glukhovsky, A.; Swain, P. Wireless capsule endoscopy. Nature 2000, 405, 417. [Google Scholar] [CrossRef] [PubMed]
- Cortegoso Valdivia, P.; Deding, U.; Bjørsum-Meyer, T.; Baatrup, G.; Fernández-Urién, I.; Dray, X.; Boal-Carvalho, P.; Ellul, P.; Toth, E.; Rondonotti, E.; et al. Inter/Intra-Observer Agreement in Video-Capsule Endoscopy: Are We Getting It All Wrong? A Systematic Review and Meta-Analysis. Diagnostics 2022, 12, 2400. [Google Scholar] [CrossRef] [PubMed]
- Beg, S.; Card, T.; Sidhu, R.; Wronska, E.; Ragunath, K. UK capsule endoscopy users’ group. Dig. Liver Dis. 2021, 53, 1028–1033. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Hawkins, L.; Wolff, J.; Goloubeva, O.; Goldberg, E. Detection of Lesions During Capsule Endoscopy: Physician Performance Is Disappointing. Am. J. Gastroenterol. 2012, 107, 554–560. [Google Scholar] [CrossRef] [PubMed]
- Otani, K.; Nakada, A.; Kurose, Y.; Niikura, R.; Yamada, A.; Aoki, T.; Nakanishi, H.; Doyama, H.; Hasatani, K.; Sumiyoshi, T.; et al. Automatic detection of different types of small-bowel lesions on capsule endoscopy images using a newly developed deep convolutional neural network. Endoscopy 2020, 52, 786–791. [Google Scholar] [CrossRef] [PubMed]
- Aoki, T.; Yamada, A.; Kato, Y.; Saito, H.; Tsuboi, A.; Nakada, A.; Niikura, R.; Fujishiro, M.; Oka, S.; Ishihara, S.; et al. Automatic detection of various abnormalities in capsule endoscopy videos by a deep learning-based system: A multicenter study. Gastrointest. Endosc. 2021, 93, 165–173. [Google Scholar] [CrossRef] [PubMed]
- Niikura, R.; Yamada, A.; Maki, K.; Nakamura, M.; Watabe, H.; Fujishiro, M.; Oka, S.; Esaki, M.; Fujimori, S.; Nakajima, A.; et al. Associations between drugs and small-bowel mucosal bleeding: Multicenter capsule-endoscopy study. Dig. Endosc. 2018, 30, 79–89. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Iwata, E.; Niikura, R.; Aoki, T.; Nakada, A.; Kawahara, T.; Kurose, Y.; Harada, T.; Kawai, T. Automatic detection of small-bowel lesions from capsule endoscopy images using a deep conventional neural network: A systematic review and meta-analysis. Prog. Dig. Endosc. 2022, 100, 27–35. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hospital | Erosions and Ulcers | Vascular Lesions | Tumors | Normal |
|---|---|---|---|---|
| University of Tokyo Hospital | 161 | 19 | 73 | 314 |
| Ishikawa Prefectural Central Hospital | 51 | 21 | 20 | 142 |
| Fukui Prefectural Hospital | 6 | 0 | 3 | 0 |
| Tonan Hospital | 2 | 2 | 0 | 2 |
| Osaka University Hospital | 22 | 3 | 16 | 0 |
| University of Kanazawa Hospital | 127 | 32 | 26 | 6 |
| Nagasaki Minato Hospital | 11 | 6 | 4 | 13 |
| University of Osaka Hospital | 96 | 28 | 26 | 0 |
| Toyonaka Hospital | 1 | 0 | 1 | 0 |
| Total | 477 | 111 | 169 | 477 |
| Sensitivity | Specificity | Accuracy | |
|---|---|---|---|
| Erosions and ulcers | 0.919 (0.896–0.942) | 0.936 (0.914–0.957) | 0.930 (0.912–0.953) |
| Vascular lesions | 0.878 (0.823–0.933) | 0.969 (0.958–0.979) | 0.962 (0.951–0.973) |
| Tumors | 0.876 (0.840–0.912) | 0.937 (0.926–0.948) | 0.924 (0.911–0.936) |
| First Fold | Second Fold | Third Fold | Fourth Fold | Fifth Fold | |
|---|---|---|---|---|---|
| Erosions and ulcers | 0.8893 | 0.8972 | 0.7792 | 0.7959 | 0.8354 |
| Vascular lesions | 0.9155 | 0.8490 | 0.7913 | 0.7604 | 0.8511 |
| Tumors | 0.7991 | 0.8132 | 0.8455 | 0.8297 | 0.7061 |
| First Fold | Second Fold | Third Fold | Fourth Fold | Fifth Fold | |
|---|---|---|---|---|---|
| Erosions and ulcers | 64/67 | 65/68 | 65/68 | 63/67 | 73/74 |
| Vascular lesions | 27/27 | 30/30 | 25/25 | 34/35 | 29/29 |
| Tumors | 36/36 | 29/29 | 36/37 | 27/28 | 26/28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nakada, A.; Niikura, R.; Otani, K.; Kurose, Y.; Hayashi, Y.; Kitamura, K.; Nakanishi, H.; Kawano, S.; Honda, T.; Hasatani, K.; et al. Improved Object Detection Artificial Intelligence Using the Revised RetinaNet Model for the Automatic Detection of Ulcerations, Vascular Lesions, and Tumors in Wireless Capsule Endoscopy. Biomedicines 2023, 11, 942. https://doi.org/10.3390/biomedicines11030942
Nakada A, Niikura R, Otani K, Kurose Y, Hayashi Y, Kitamura K, Nakanishi H, Kawano S, Honda T, Hasatani K, et al. Improved Object Detection Artificial Intelligence Using the Revised RetinaNet Model for the Automatic Detection of Ulcerations, Vascular Lesions, and Tumors in Wireless Capsule Endoscopy. Biomedicines. 2023; 11(3):942. https://doi.org/10.3390/biomedicines11030942
Chicago/Turabian StyleNakada, Ayako, Ryota Niikura, Keita Otani, Yusuke Kurose, Yoshito Hayashi, Kazuya Kitamura, Hiroyoshi Nakanishi, Seiji Kawano, Testuya Honda, Kenkei Hasatani, and et al. 2023. "Improved Object Detection Artificial Intelligence Using the Revised RetinaNet Model for the Automatic Detection of Ulcerations, Vascular Lesions, and Tumors in Wireless Capsule Endoscopy" Biomedicines 11, no. 3: 942. https://doi.org/10.3390/biomedicines11030942
APA StyleNakada, A., Niikura, R., Otani, K., Kurose, Y., Hayashi, Y., Kitamura, K., Nakanishi, H., Kawano, S., Honda, T., Hasatani, K., Sumiyoshi, T., Nishida, T., Yamada, A., Aoki, T., Harada, T., Kawai, T., & Fujishiro, M. (2023). Improved Object Detection Artificial Intelligence Using the Revised RetinaNet Model for the Automatic Detection of Ulcerations, Vascular Lesions, and Tumors in Wireless Capsule Endoscopy. Biomedicines, 11(3), 942. https://doi.org/10.3390/biomedicines11030942