1. Introduction
Children’s healthcare is a topic of great global relevance, with different variants and approaches depending on the field where it is applied. One of the important issues in this area is the prevention of domestic accidents. Domestic accidents are one of the main causes of death in children; even the WHO defines them as a global health problem since it is estimated that about 830,000 children die each year as a result of domestic accidents [
1]. Children’s domestic accidents are not exclusive to underdeveloped countries; according to UNICEF [
2], injuries caused by domestic accidents are responsible for more than 40% of the deaths of children between the ages of 1 and 14 in developed nations. Countries such as Sweden, the United Kingdom, Italy and the Netherlands occupy the last places in the table of infant deaths caused by domestic accidents with an average of 5.2 to 6.6 deaths per 100,000 children, while in countries such as the United States, Portugal and Mexico, there is an average of 14.1 to 19.8 deaths per 100,000 children annually [
3]. Regardless of the statistics, the death of children due to domestic accidents is a problem that devastates society and families, regardless of the country or socioeconomic status, and is one that requires urgent attention.
Generally, homes are not designed to be completely safe spaces for children, as there are multiple scenarios and risk objects that can cause accidents for children, such as electrical contacts, stoves, stairs, glass objects, and household appliances, among others. The most common domestic accidents for children are falls, burns, poisonings and hits against objects. The home is where children spend most of their time and, depending on their age, they require adult supervision for many of the activities that they normally do. The parents or guardians of the children are in charge of providing spaces at home that are safe for performing their daily activities, having to consider the possible risk scenarios to adapt to them, thus avoiding domestic accidents as much as possible. Usually, in most cases, children’s domestic accidents occur due to the carelessness of the caregivers of children since it is difficult to monitor them at all times while they are at home, especially when parents work outside the home and they leave their children alone or in the care of someone else.
In recent years, it was common for parents to work outside the home and leave their children home alone for a few hours, which considerably increases the risk of accidents, as, even when left in the care of someone else, accidents happen. During the last year, due to the situation generated by the COVID-19 pandemic, the work scenario of many parents has changed with them having to work at home, but the accidents of children at home have not decreased; they have even increased as collateral damage caused by this health contingency since parents, having to comply with their working hours from home, neglect the activities that their children carry out, which generally causes accidents. Accidents such as trauma, poisoning, burns, choking, the presence of foreign objects in the ears and nose, have increased significantly in both frequency and severity during the period of the pandemic, compared to the same period of the previous year [
4]. This makes the emergence of systems focused on children’s healthcare increasingly necessary, especially those designed for the monitoring and prevention of children’s domestic accidents.
Therefore, children’s healthcare has become an area with enormous challenges that are being addressed through artificial intelligence, especially with machine learning and the advantages offered by data analysis applied to this discipline. Monitoring applications focused on children’s healthcare, such as accident prevention, are generally based on the use of an activity classification model. It is precisely this model that is in charge of, through a data source defined for the system, collecting information that allows it to infer the activity that is being performed by the child and identify the activity. These activity classification models are the basis for monitoring systems focused on children’s healthcare.
Most children’s activity classification models that use machine learning techniques use a combination of different sensors that are carried on the garments or parts of the body, which makes them susceptible to such problems as damage due to mishandling, and the continuous replacement of batteries, among others, which can cause data measurements errors. If an activity classification model is used with an invasive data source and is applied to a child monitoring system focused on domestic accident prevention, it is possible that the errors generated by the data source could affect the performance and accuracy of the system. One way to solve the problem of using wearable sensors is to apply another approach to child safety monitoring that uses a different data source.
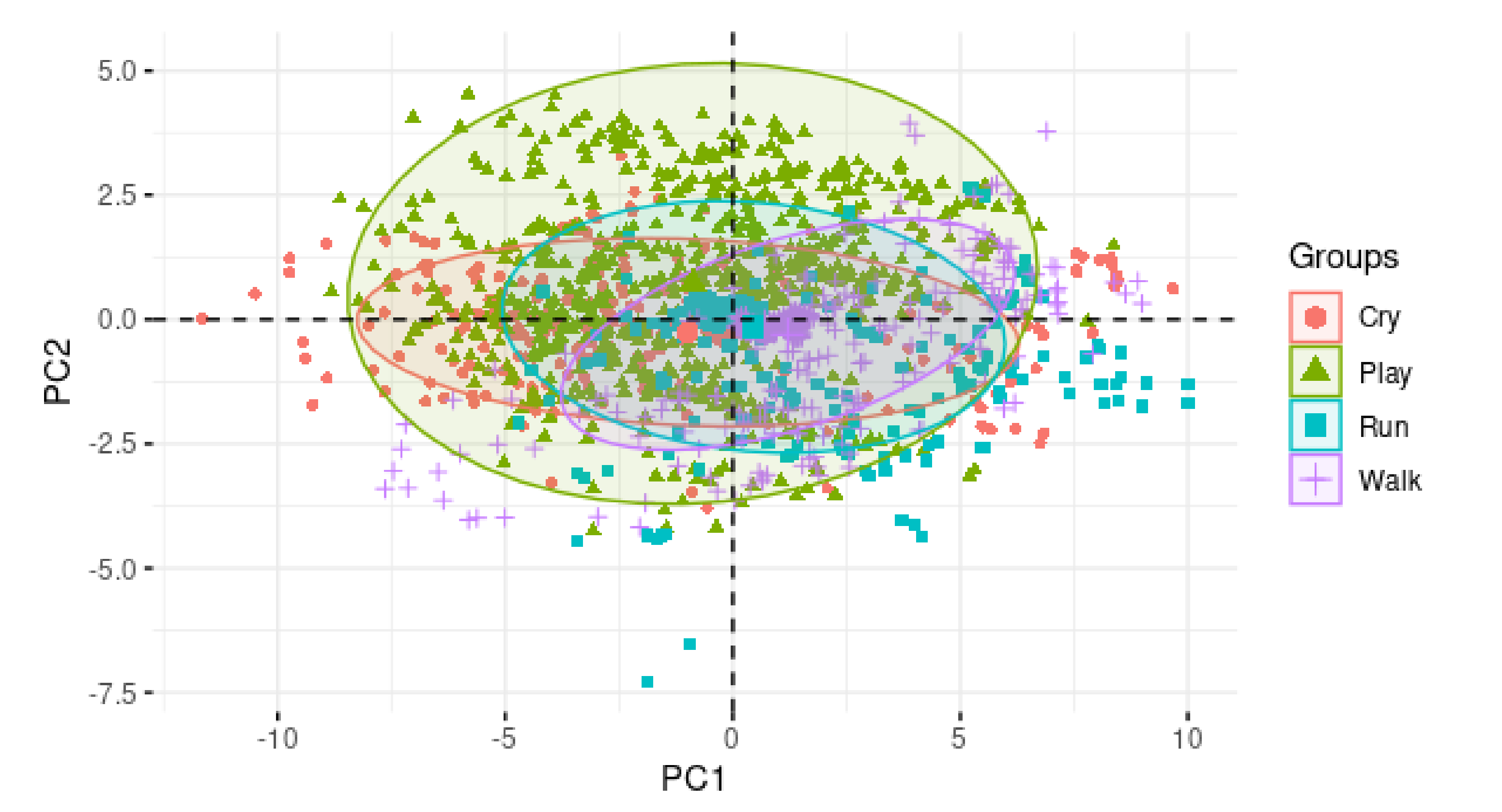
This paper proposes the generation of a children’s activity classification model, using environmental sound that can be applied in child monitoring systems focused on domestic accident prevention. The activities analyzed in this work are crying, playing (manipulating plastic blocks), running and walking. It was determined to work with this set of activities to highlight the advantage of using environmental sound as a data source by being able to classify activities that are not detectable through movement, such as crying and playing. The objective of generating a model for children’s activity classification using environmental sound is the detection of risk scenarios, that is, if the model detects activities, such as crying, and the child is in an environment with objects that obstruct their walk, then an accident prevention system that uses this model may interpret it as the result of a possible fall of the child or another dangerous event that has triggered their crying. Depending on the environment where children are monitored, activities such as walking, running or playing could represent scenarios susceptible to accidents, for example, running in small spaces or where there are glass objects, a child walking when they are just learning to walk and is not under the supervision of parents, or manipulating plastic objects when they represent a risk of suffocation, among others. This is how this work is presented as a proposal aimed at the area of the prevention of children’s domestic accidents, being that the activity classification models generated here are a fundamental part of the operation of these types of systems, helping to achieve adequate levels of safety and reliability.
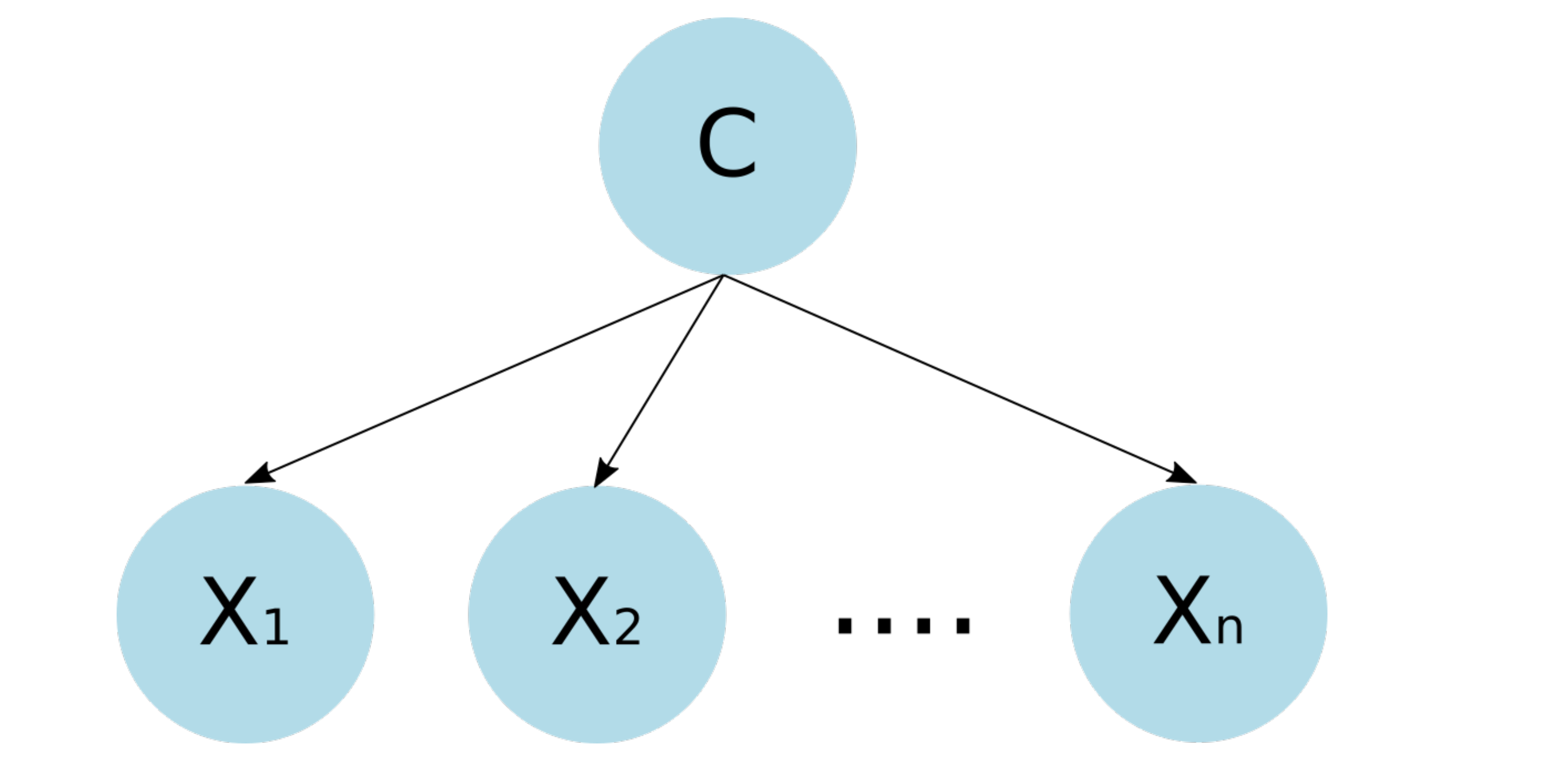
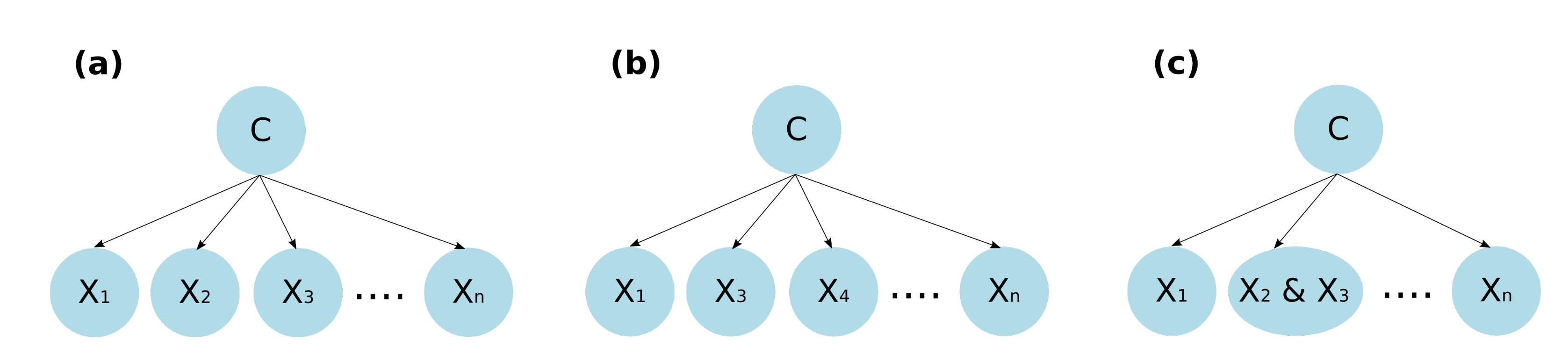
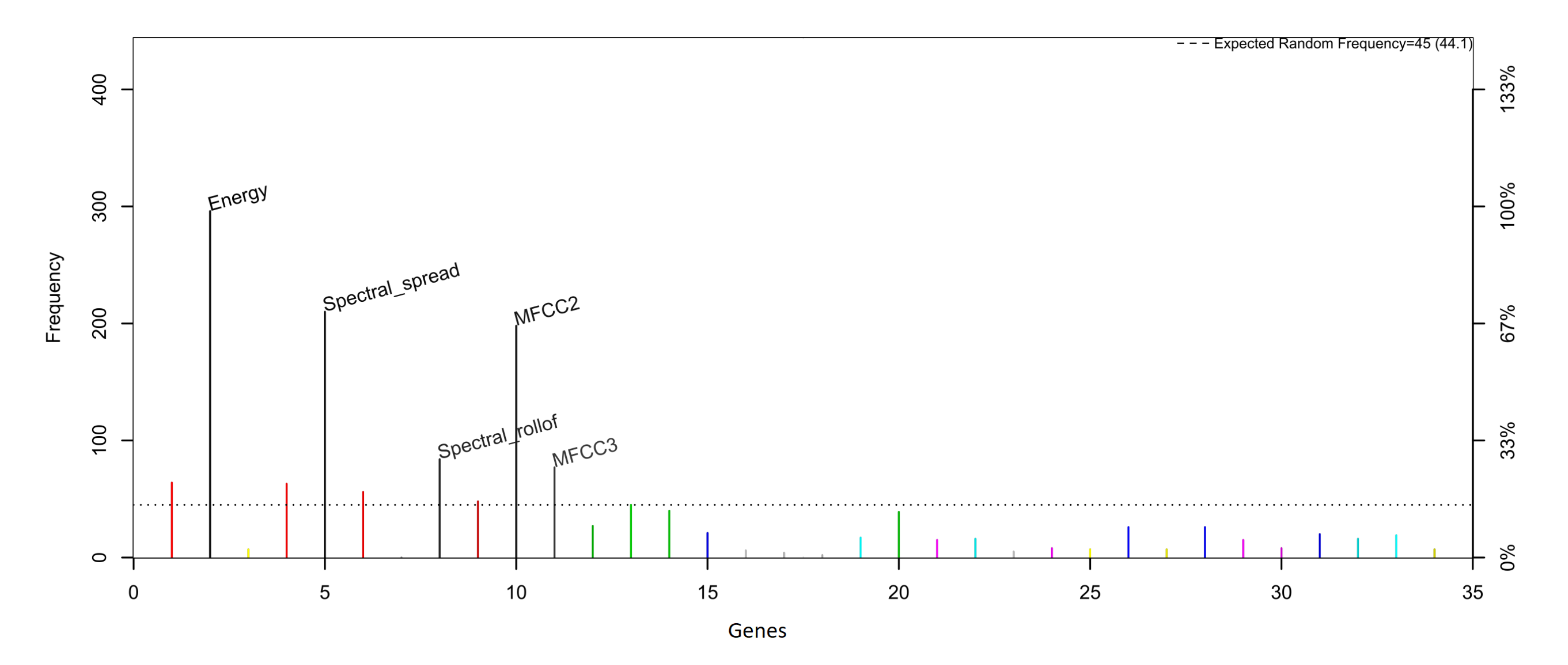
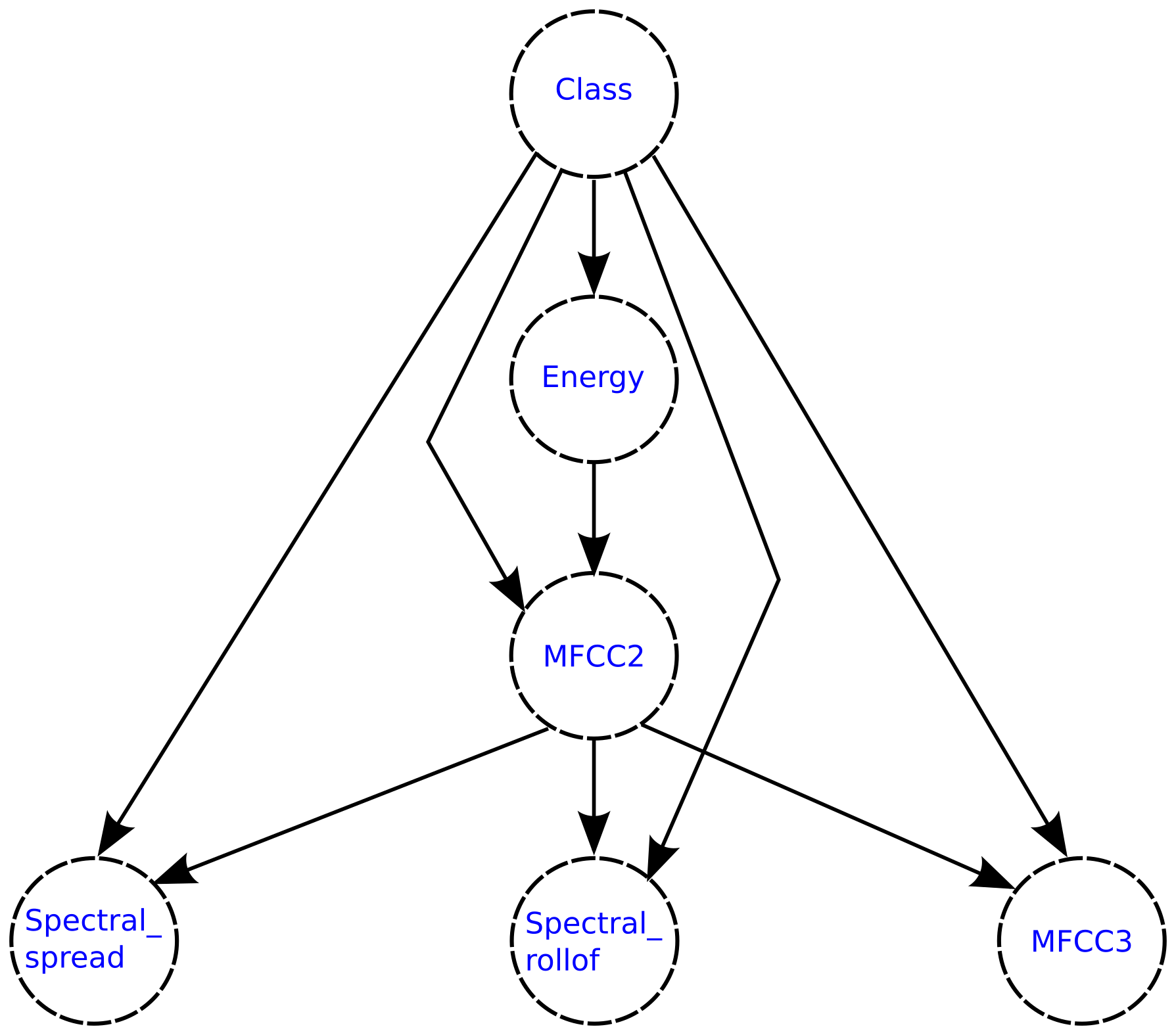
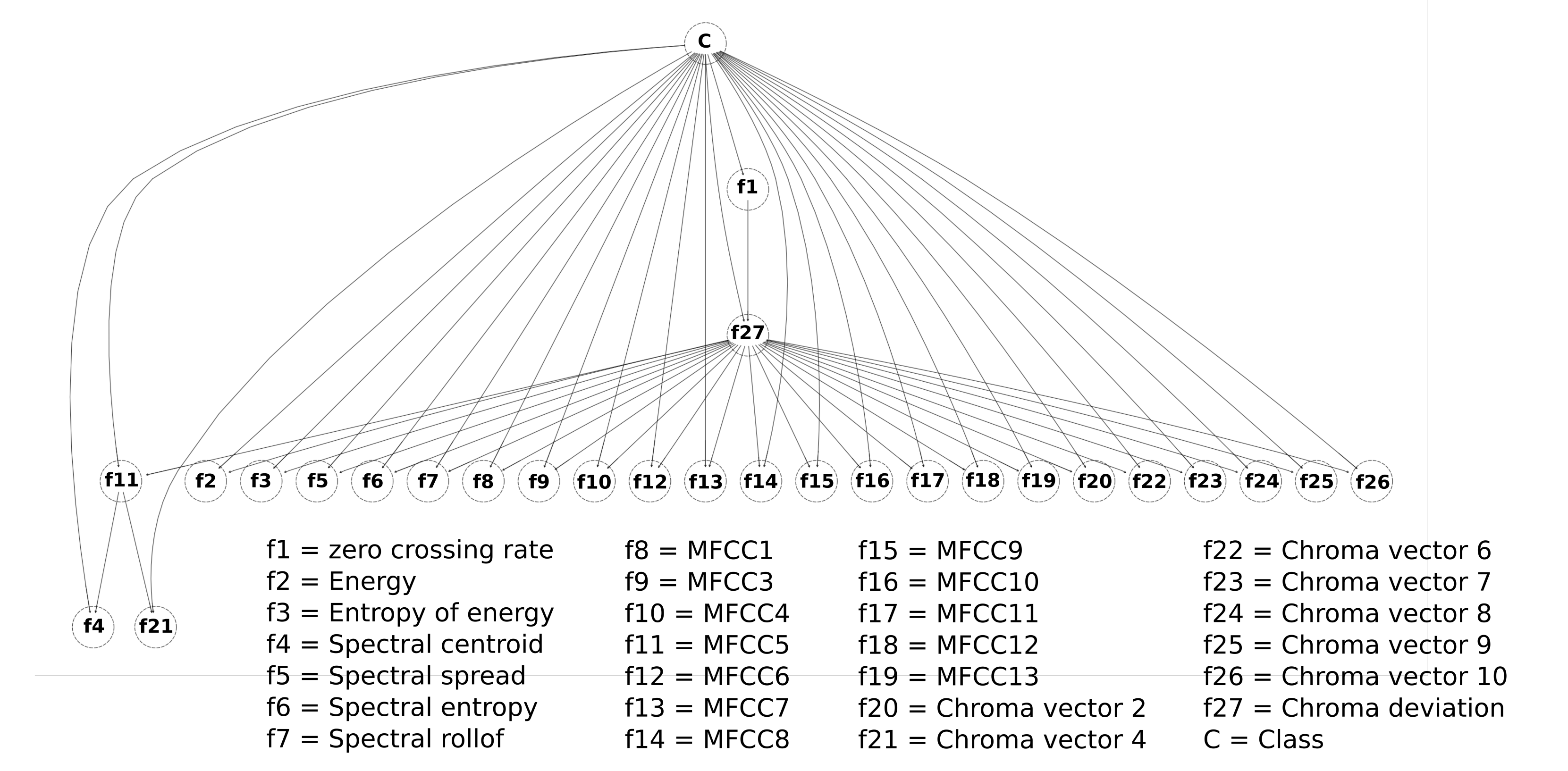
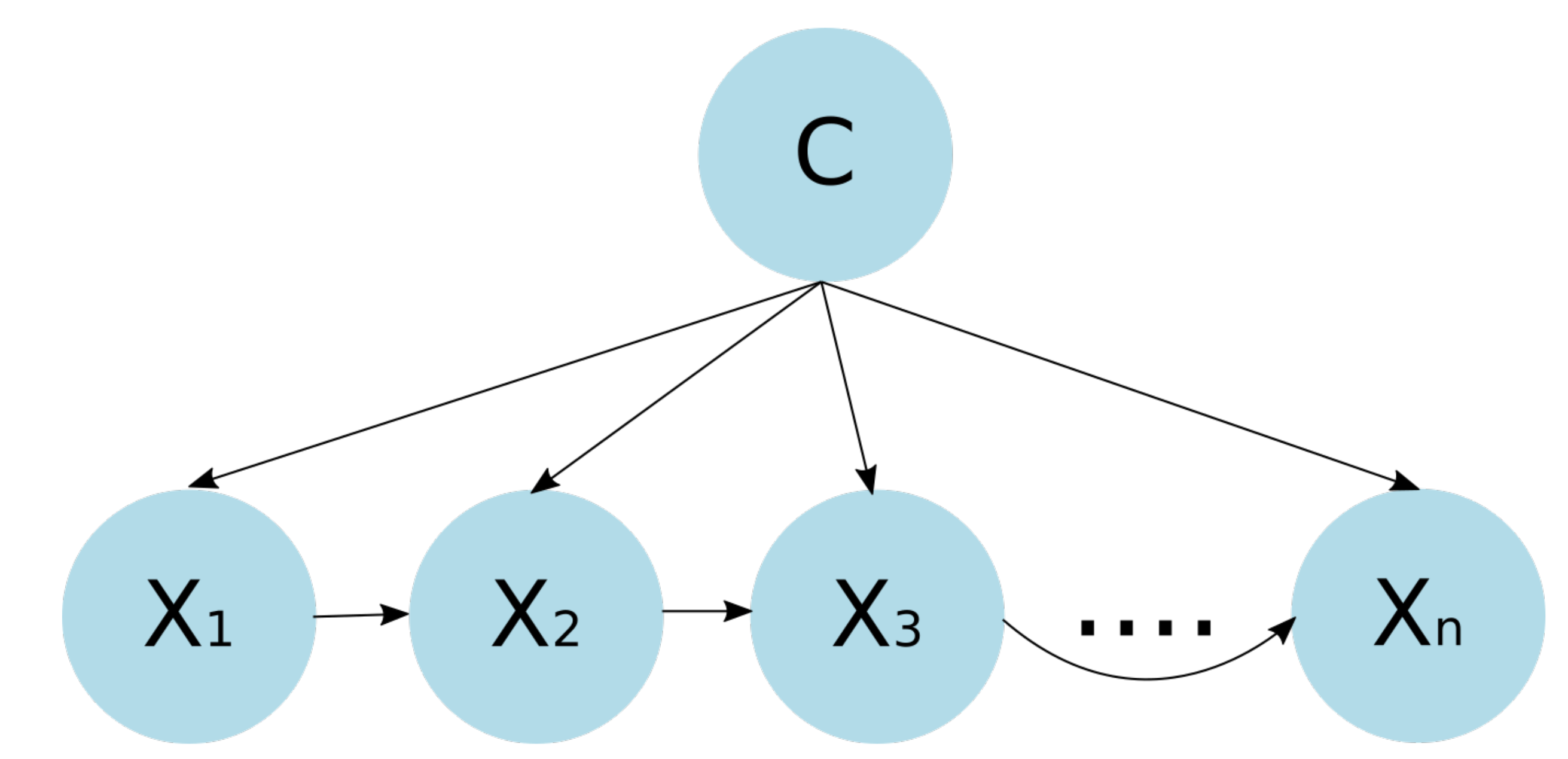
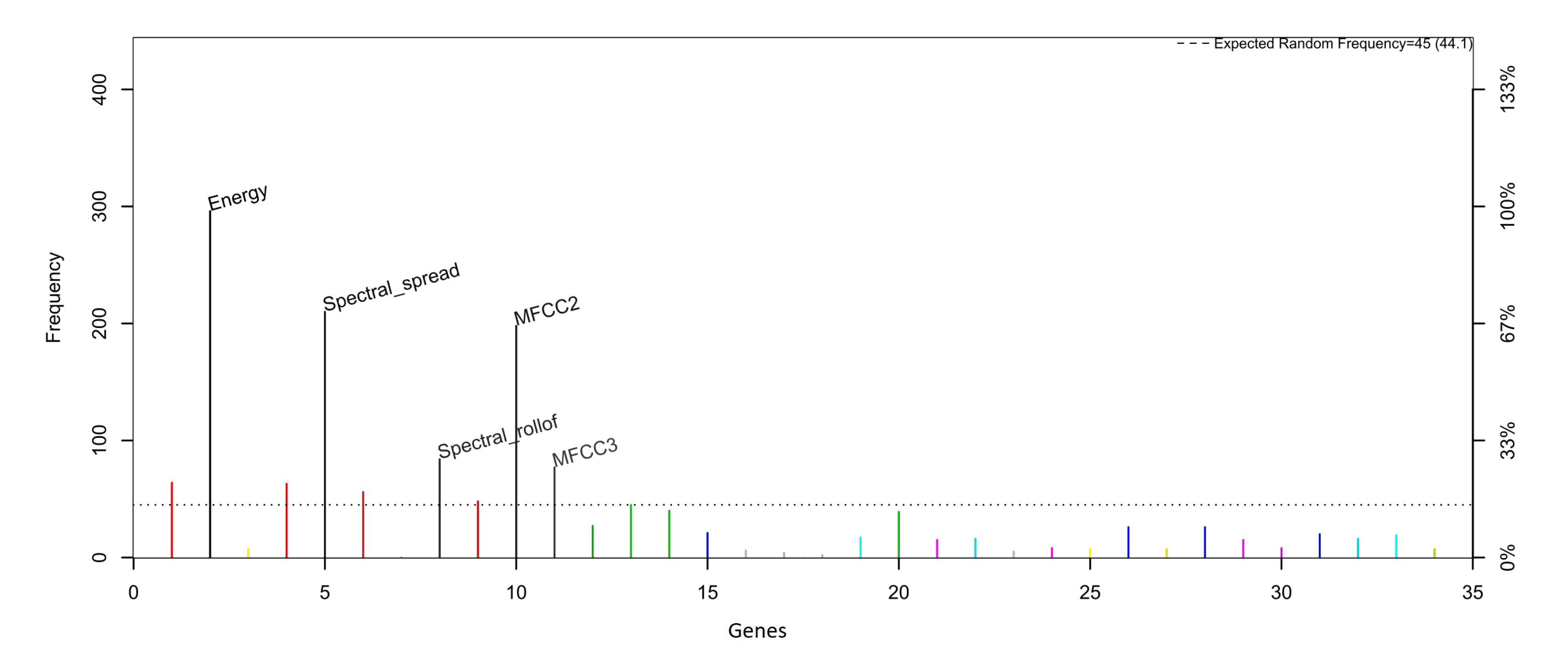
For the generation of children’s activity classification models using environmental sound focused on the prevention of domestic accidents, initially, features of the data collected from the environmental sound are extracted and refined through a feature selection process. Then, these data are used to feed a classification model generated using a Bayesian network-based classifier. The objective is for the model to classify the environmental sound data in some of the activities considered for the analysis; this can serve for its use in monitoring systems and the prevention of children’s home accidents through an activity recognition approach. The analyzed feature selection methods are the Akaike criterion and genetic algorithms, while the Bayesian structures used for the generation of the classification models are naive Bayes, semi-naive Bayes and tree-augmented naive Bayes.
This paper is organized as follows:
Section 2 presents the work related to the area of children’s activity classification and children’s healthcare.
Section 3 presents the background of the feature selection methods used: Akaike’s criterion and genetic algorithms, in addition to the Bayesian classifiers implemented: naive Bayes, semi-naive Bayes and tree-augmented naive Bayes. In
Section 4, the materials and methods used for this work are presented. In
Section 5, the experiments performed and the results obtained are described. Finally, in
Section 6, the discussion and conclusions are presented, as well as the points considered for future work.
2. Related Work
The continuous advancement of technology in recent years, especially in the areas of artificial intelligence and machine learning techniques, has led to the development of systems focused on children’s healthcare in different areas, such as those focused on the diagnosis of diseases through symptom detection [
5,
6], activity classification systems to detect patterns that indicate disease [
7,
8], or complete child monitoring systems [
9,
10], among many more. Most of the works developed for children’s healthcare use multiple sensors as a data source, which are embedded in clothing or carried directly by children in some part of the body.
Children’s activity classification is a concept on which numerous works have been developed, the main differences between them being the use that is given to the classified activities and the data source used. The data source used in the children’s activity classification models is a very important aspect for the system since other things depend on it, such as the type of data to be collected, the form of data analysis and the tools used for all phases of the process. As mentioned above, for the works in the children’s healthcare area, most of the proposals for children’s activity recognition models also use sensors embedded in children’s clothing, such as accelerometers, temperature sensors, humidity sensors, RFID devices, or devices carried somewhere on the body, such as a smart watch.
In this sense, Boughorbel et al. [
11] developed a children’s activity classification model based on multi-sensor data. They used a device with an accelerometer, a pressure sensor, and a gyroscope; the activities analyzed were walking, running, lying down, falling, climbing stairs, standing up, and other. The multi-sensor device was placed in the back pocket of the children’s pants. The objective was to classify activities for a children obesity prevention system, reaching a classification accuracy of up to 97.8%. Westeyn et al. [
12] developed a system based on augmented toys to detect children’s interactions with objects and potentially identify children with autism early. Interaction detection was performed using accelerometers, audio inputs, and contact pressure sensors embedded in specific toys chosen for this purpose. Trost et al. [
13] developed a child activity recognition system based on data provided by accelerometers placed on the hip and wrist to detect activities, such as lying down, sitting, walking, running, playing basketball and dancing, resulting in accuracy from 64% to 96% depending on the activity analyzed.
Children’s activity classification works has also focused on children’s healthcare, specifically the prevention of domestic accidents. Nam et al. [
14] presented a child activity recognition approach, using an accelerometer and a barometric pressure sensor placed on the child’s waist to prevent childhood accidents, such as unintentional injuries at home. In this work, they analyzed activities, such as wiggling, rolling, standing still, standing up, sitting down, walking, toddling, crawling, climbing up, climbing down, and stopping, achieving an accuracy of 98.43%. Jutila et al. [
15] presented a work where they developed a prototype of a portable vest to improve the safety and well-being of children in kindergarten and elementary schools, which contains a GPS, temperature sensors and accelerometers. Through this garment and the sensors it contains, they collected information on the general well-being, behavior and activities of children, being able to categorize activities, such as walking, running, sitting, staying still, as well as data on body temperature and the location of the children.
As mentioned before, using children’s activity classification models based on invasive data sources, such as sensors worn on children’s clothes or on some part of the body, can cause different problems, such as errors in the data collected due to physical failures due to the mistreatment of the sensors or the fact of constantly replacing the batteries. It has been shown that it is possible to use environmental sound as data source in human activity recognition models [
16], also obtaining good results when applying the idea to children’s activities [
17,
18,
19,
20,
21]. Using a non-invasive data source, such as environmental sound, has the advantage of not interfering with the activities that children perform, in addition to potentially having a greater range in the activities that can be analyzed by not focusing only on those that are detectable through motion, as in accelerometer-based models.
When working with activity recognition models through environmental sound, an important process prior to model generation is feature extraction, a process by which a numerical interpretation of the sounds is extracted, which are the so-called features. In the works that involve audio analysis, the most commonly used features are the zero-crossing rate, the signal bandwidth, the spectral centroid, the signal energy and the Mel-frequency cepstral coefficients (MFCC) [
22,
23], which have also been used in works of activity classification using sound [
16].
Generally, after performing the feature extraction, a feature selection process is performed in order to eliminate those features that do not provide relevant information for activity recognition, leaving only those features through which it is possible to differentiate the different classes with which the model works. There are different feature selection methods. Some of them are forward selection, backward elimination, Akaike information criterion (AIC) and genetic algorithms [
24]. Both AIC and genetic algorithms have been used in children’s activity recognition models through environmental sound, achieving a reduction in the number of features of 20% and 86%, respectively [
17,
18].
Once the set of features to be used has been defined, a classifier algorithm is required to generate the model. In the works on children’s activity recognition, there are different classifier algorithms that are implemented, such as random forest, k-nearest neighbor, support vector machines, Bayesian networks and artificial neural networks, among others [
14,
25,
26]. Specifically, in the generation of children’s activity classification models using environmental sound, classical classifying algorithms, such as support vector machines, k-nearest neighbors, random forest, extra trees, gradient boosting and artificial neural networks, are used and compared, reaching accuracies between 40% and 99% [
18,
19,
20].
The present work proposes an approach to children’s activity recognition, using environmental sound as a data source, which can serve as the basis for a child healthcare system focused on the prevention of domestic accidents. By using sound as a data source, the limitation of having sensors carried by the individuals who perform the activity is eliminated, and thus, activities that do not depend on motion detection can be recognized, such as crying, for example. In addition, feature selection processes are performed using the Akaike information criteria and genetic algorithms. For the generated classification model, three classifiers based on Bayesian networks are compared: naive Bayes, semi-naive Bayes and tree-augmented naive Bayes.
6. Discussion and Conclusions
The aim of this work is to generate children’s activity classification models, using environmental sound and applying Bayesian networks-based classifiers as a basis for the identification of potentially dangerous activities in children’s healthcare and monitoring systems. It is also important to have the following considerations:
The activities analyzed through environmental sound are independent of others. Activities that are performed alongside others require a different analysis.
In the same way, the data set is made up of recordings of activities performed by children alone, without interaction with others. Activities where there are several children interacting at the same time or where there is external noise require another type of analysis.
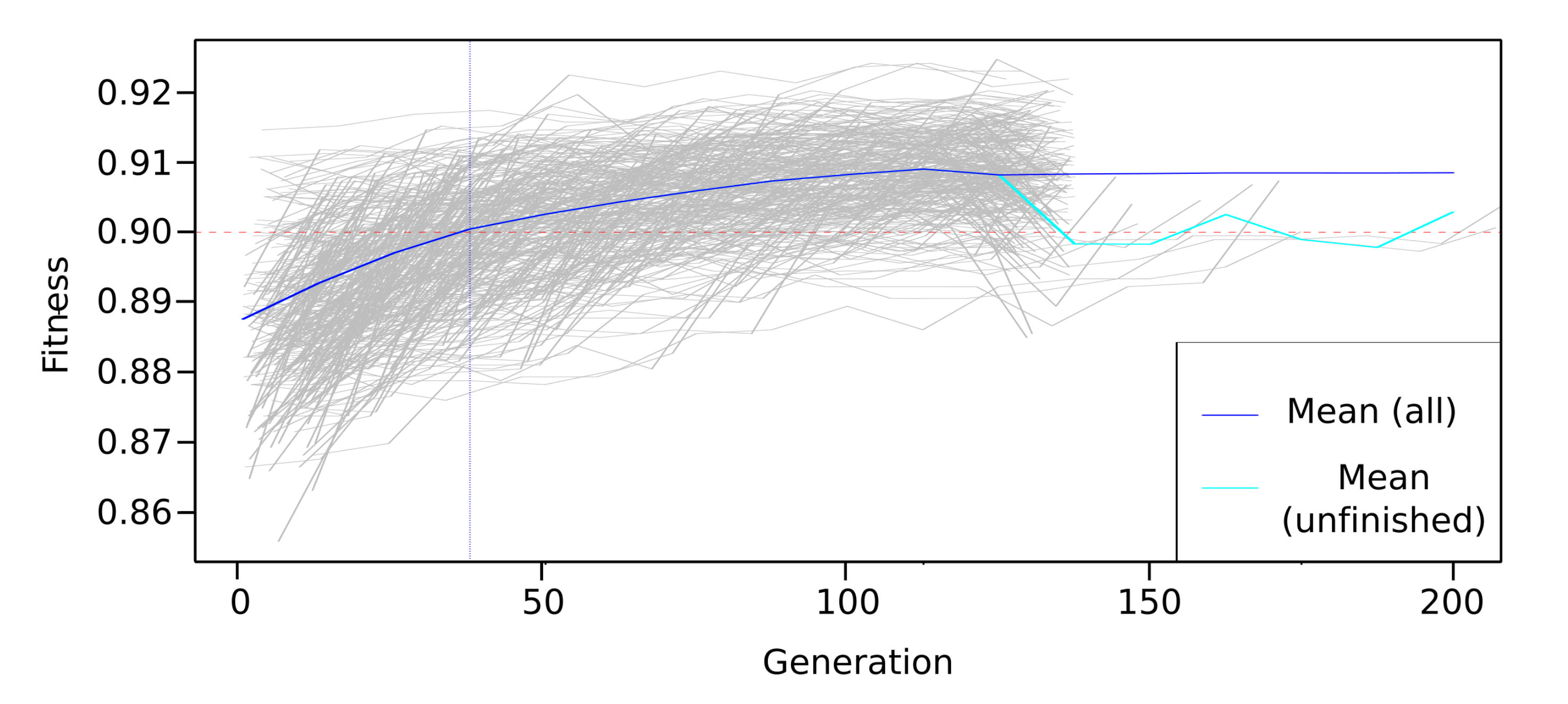
For the generation of the classification models, three different Bayesian network structures were compared: naive Bayes, semi-naive Bayes and tree-augmented naive Bayes. In addition, in order to make the models more efficient in terms of resource consumption, two feature selection techniques were implemented, which generated the subsets of data with which the classification models were generated. These techniques are the Akaike criterion and genetic algorithms. From the results presented, the following can be concluded:
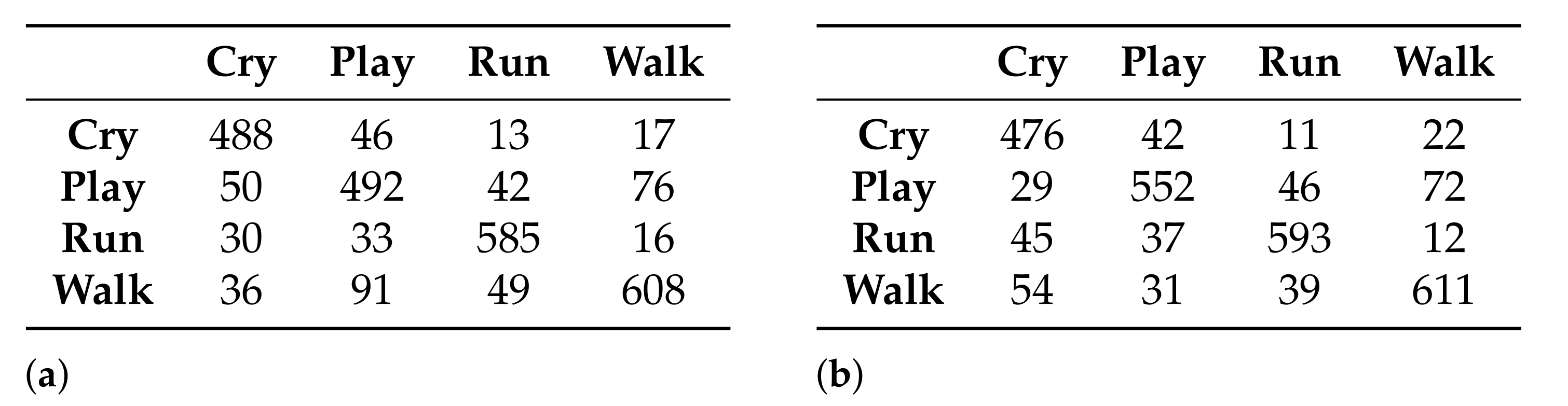
The feature selection methods used reduce the data set considerably, especially the genetic algorithm method, maintaining good levels of accuracy, as in the model generated with the TAN classifier and genetic algorithms as a feature selection method. This model manages to maintain a balance between the accuracy and number of features. The reduction in the data set generally has a favorable impact on the performance of the systems since working with a smaller amount of data generates a lower consumption of resources, an important aspect when the systems are required to be as efficient as possible. However, depending on the application of the classification model, it is preferable to work with a model that maximizes the accuracy of the classification rather than minimizing the amount of data needed for analysis. In an activity classification model focused on being used in a system for the prevention of domestic accidents in children, this aspect is linked to the expected safety for the system. In this sense, it should be noted that two of the models generated using the AIC as a feature selection method achieve an accuracy greater than 99%, while by using genetic algorithms, this is only achieved in one.
The classification accuracy for the models generated with naive Bayes and TAN is very similar and in both cases greater than 97%, despite the fact that the naive Bayes method is the simplest Bayesian network. As in the previous point, having a method that generates a simple model could favor the performance of the classification system.
Considering the nature of the problem for which the activity recognition models are to be applied, although all the models generated achieve accuracies greater than 81%, which can be considered good, not all are eligible to be used. It is necessary, as mentioned in previous points, to prioritize maximizing precision over minimizing the amount of data to work with. In this sense, the models that achieve this balance are those generated with the TAN classifier (both feature selection methods) and the model generated with the NB and AIC classifier as the feature selection method.
The results obtained in the children activity classification from the models generated by the Bayesian network approach show similar accuracy to the models generated by other machine learning techniques, such as artificial neural networks and classical classifier algorithms, with the advantage that offers the implementation of a feature selection process, by deleting those that do not provide relevant information for the classification process and generating models that work with only 5 or 27 features without affecting the classification accuracy. In addition, the use of a Bayesian networks-based approach implies the generation of simple classification models, especially with the naive Bayes classifier, which can favorably impact the performance of the system where the classification model is implemented.
Based on the results obtained in this work, it can be concluded that with environmental sound as a data source and by using classifiers algorithms based on Bayesian networks, it is possible to generate children’s activity classification models. These models can be the basis for monitoring systems focused on the prevention of domestic accidents. The activities analyzed in this work (crying, playing, running and walking) are activities that can potentially trigger risk scenarios.
Some points considered for the future are as follows:
Incorporate more activities analyzed by the classification models to expand possible risk scenarios in child monitoring systems.
Incorporate the Markovian processes theory for the analysis of activity sequences that allow the identification of complex risk scenarios (cause–effect analysis based on detected activities).
Generate children’s activity classification models that consider the interaction of two or more children at the same time, as well as simultaneous activities performed by the same child.
Propose a complete monitoring system focused on children’s healthcare where the classification models generated are used to determine potentially dangerous scenarios based on the activities detected and in combination with other elements, such as the identification of known places.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}