
Towards the Development of a Substance Abuse Index (SEI) through Informatics


Abstract
:1. Introduction
- i
- The number of times a patient requires a hospital visit due to substance abuse/overdose/addiction.
- ii
- The differing potency of drugs e.g., carfentanil (used as an analgesic agent) is hundred times more potent than fentanyl, which in return is a order of magnitude more potent than morphine or codeine.
- iii
- Individual differences due to genetics/biology/physiology/psychology.
- IV
- Interaction between different hospital visits and other possible comorbidities.
2. Materials and Methods
2.1. Overview of Logistic Regression
2.2. Patient Notations
2.3. Dataset
2.3.1. Source and Permission
2.3.2. Data Extraction
2.3.3. Preprocessing Dataset
Attribute Selection
Missing Values
Others
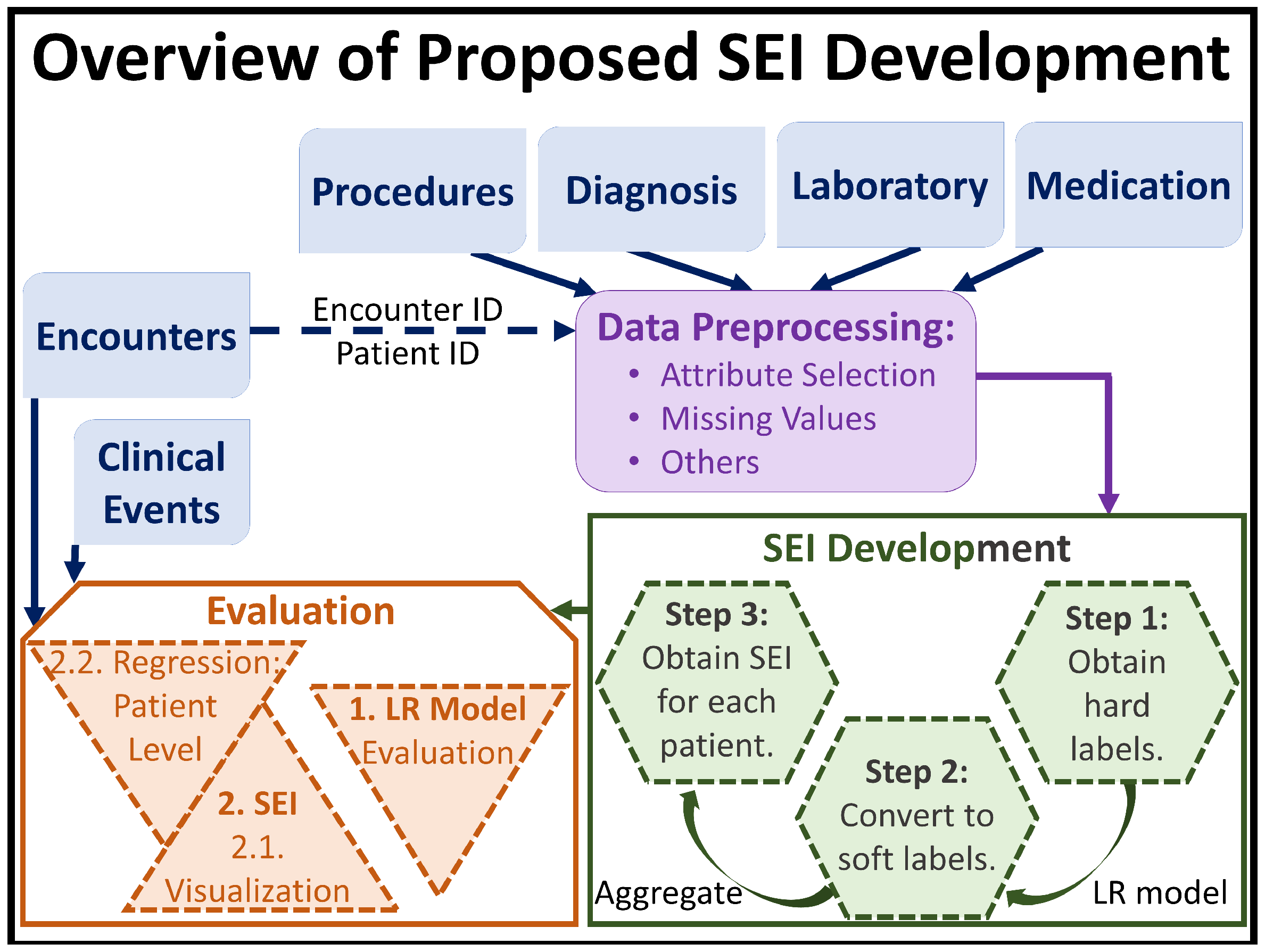
2.4. Our Proposed Method
- Step 1: Obtain hard labels. SEI is a measure for an individual. However the EMR data system, which is one of the most common and highly informative clinical data system, records patient data as a series of encounters. Thus, the first step in the development of SEI is to label each encounter, (see Section 2.2), with hard labels of 0 or 1 using only the DiagnosisCode and DiagnosisDescription variables from the Diagnosis relational table.In the EMR dataset, if an encounter was categorized as substance abuse/addiction using the ICD9 and/or ICD10 codes, and/or if the diagnosis description of the encounter contained words related to substance abuse, such as “overdose”, “abuse”, “opioid”, etc., the encounter was labeled with, and 0 otherwise. Extending the notations presented in Section 2.2, and after obtaining the hard labels, we can express the resulting encounter set of as:where is the hard label for ’s encounter, and . Note, the hard labels are assigned to each encounter, and at this stage describing one individual using the hard labels would require an array/collection of hard labels.
- Step 2: Convert hard labels to soft labels. We define SEI to be numerical because the spectrum of substance abuse patient is very wide, and defining SEI to be categorical with a limited set of values/levels would be restrictive. The wide range of the substance abuse spectrum can be attributed to individual, background, medical, and prescription strength differences. Thus, this step consists of transforming the hard labels, , to soft labels.This transformation is achieved through the use of LR. Once has been obtained for all values of k (e.g., for all patients) from our previous stage, we train a LR model on the training set of encounters using as the response variable; in other words, we train the LR model on for all i and k in the training set to learn/predict binary response variable.
- Step 2.1: Obtaining the soft labels. Once we have a trained LR model, we use Equation (3) to obtain for all encounters and all patients (from both training and testing sets) e.g., for all i and k in the entire dataset. This now becomes the soft label for . Thus, we update the encounter set of as follows:where is the soft label for ’s encounter, and . At the end of this stage, one individual still requires an array/collection of soft labels to be properly described.
- Step 2.2: Fine tuning the value of . In order to ensure that the hard labels were properly transformed into representative soft labels, we need to make sure that the LR model was properly trained. However, before calculating the evaluation metrics, we need to fine tune the value of , because scaling the effect of the independent variables may not be cleanly encapsulated by the general threshold value of 0.5. We reason that if the model learnt properly, then soft labels ≤ 0.4 will correspond to hard coded label of 0, and soft labels ≥ 0.6 with hard label of 1. As such, we use a Receiver Operating Characteristic (ROC) curve to determine the cutoff point, , within the (0.4, 0.6) open interval, and accordingly set .
- Step 2.3: Evaluating the trained LR model. Once the value of has been determined, we use Equation (4) only on the test set to evaluate the trained LR model based on accuracy, specificity, and sensitivity.
- Step 3: SEI Definition. We need to transform the array of soft labels for an individual patient to a scalar value. Thus, we define the SEI of as the average of soft labels found in .
3. Results
3.1. Evaluation for Step 1 (Obtain Hard Labels)
3.2. Evaluation for Step 2 (Convert Hard Labels to Soft Labels)
- The ROC curve of the LR model is used to determine the cutoff point (or the value of defined in Equation (4)) in the open (0.4, 0.6) interval. Thus, we use the area under the ROC curve (AUROC) to determine the performance of the LR model. Figure 2a displays the ROC curve of the trained LR model, which was used to set the value of at 0.56. The AUROC value (Figure 2b) was obtained using Riemann sum method of finding the area under the curve and found to be 95% (where the underestimated AUROC was 92%, and the overestimated AUROC was 97.76%).
- The statistical significance of all the attributes in Table 2 using the LR model came out with p-values of 0.00*, where ’*’ indicates that the minimum p-value was even lower.
- Since the output of LR is a probability, p, LR is usually used as a classification model through the use of as shown in Equation (4). Thus, using (from the ROC curve computation mentioned above), the accuracy, sensitivity and specificity of the trained LR model is calculated (and presented in Figure 2b) using the following definitions, where TP = true positive, FP = false positive, TN = true negative and FN = false negative:
- In addition, we also provide a histogram of soft label values obtained from the trained LR model in Figure 3. The histogram shows us that a large proportion of the encounters obtained the soft label in the proximity of values 0.4 and 0.6. Figure 3 also ensures that the range of value of the soft labels fall within the range of 0 and 1. This is to be expected because the output of the LR model, , is a probability, which we are regarding as soft labels. And since SEI for a patient is defined as the mean of their associated soft labels, this means that SEI is also restricted within the closed [0, 1] range.
3.3. Evaluation for Step 3 (SEI Definition)
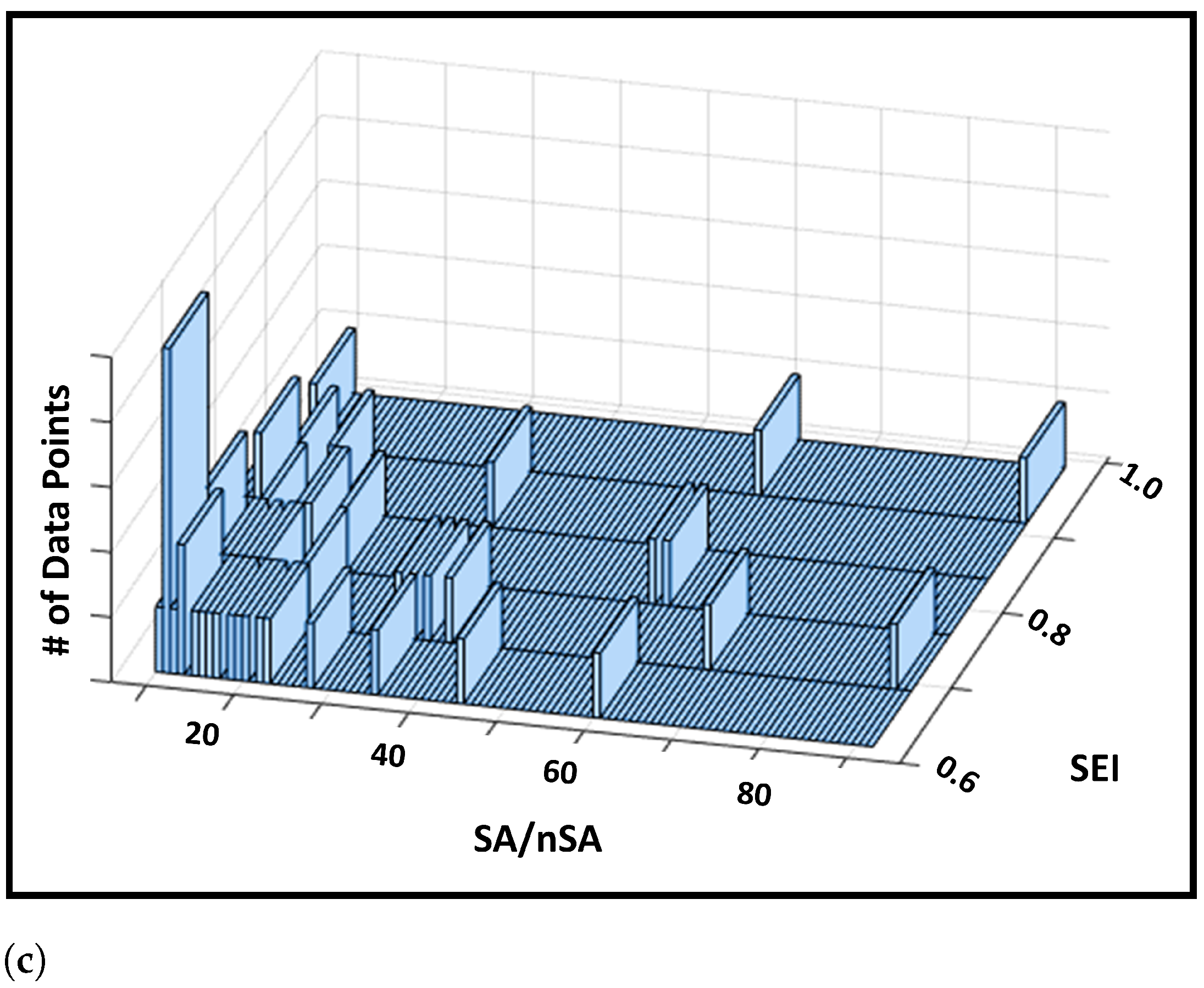
3.3.1. Visual Validation
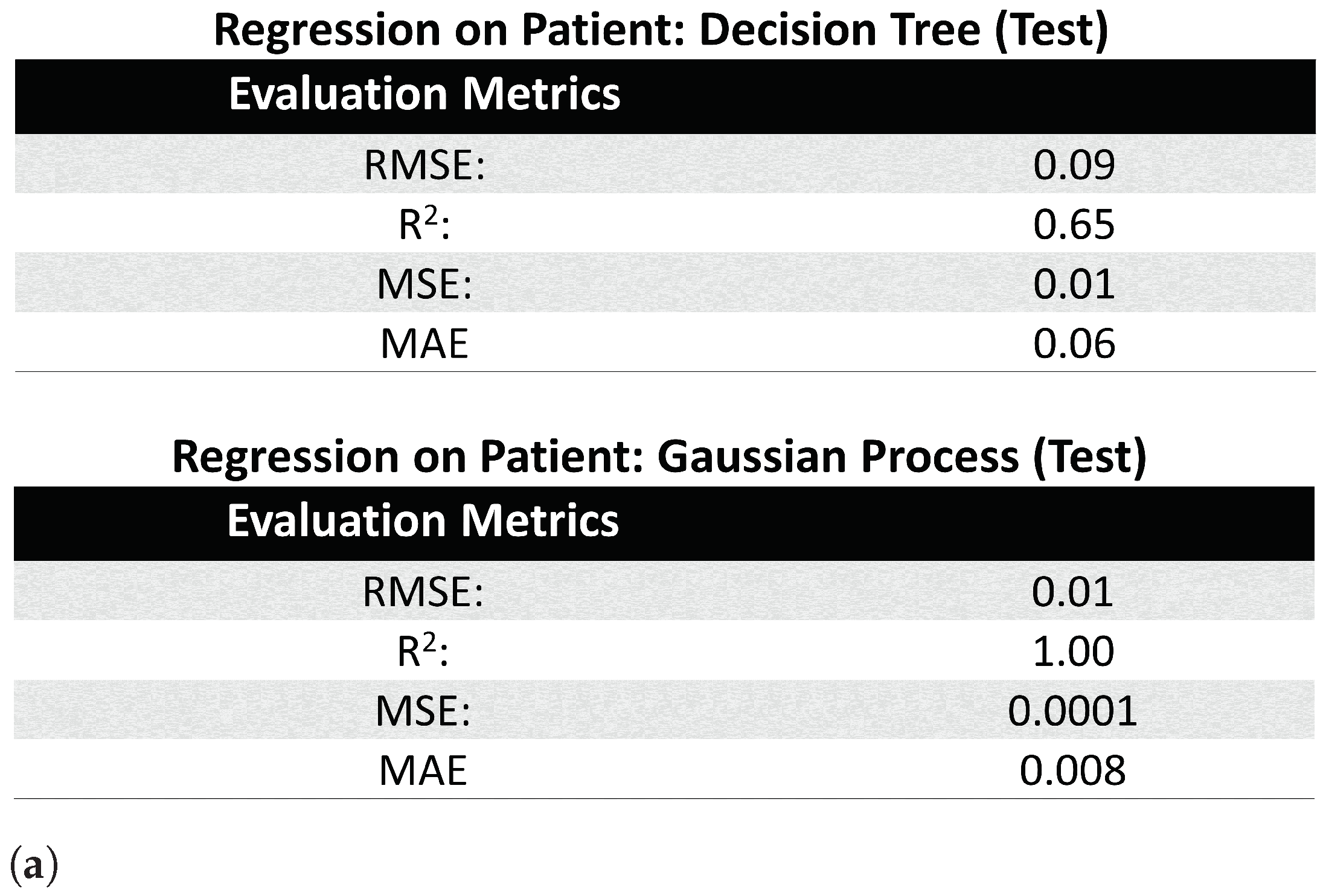
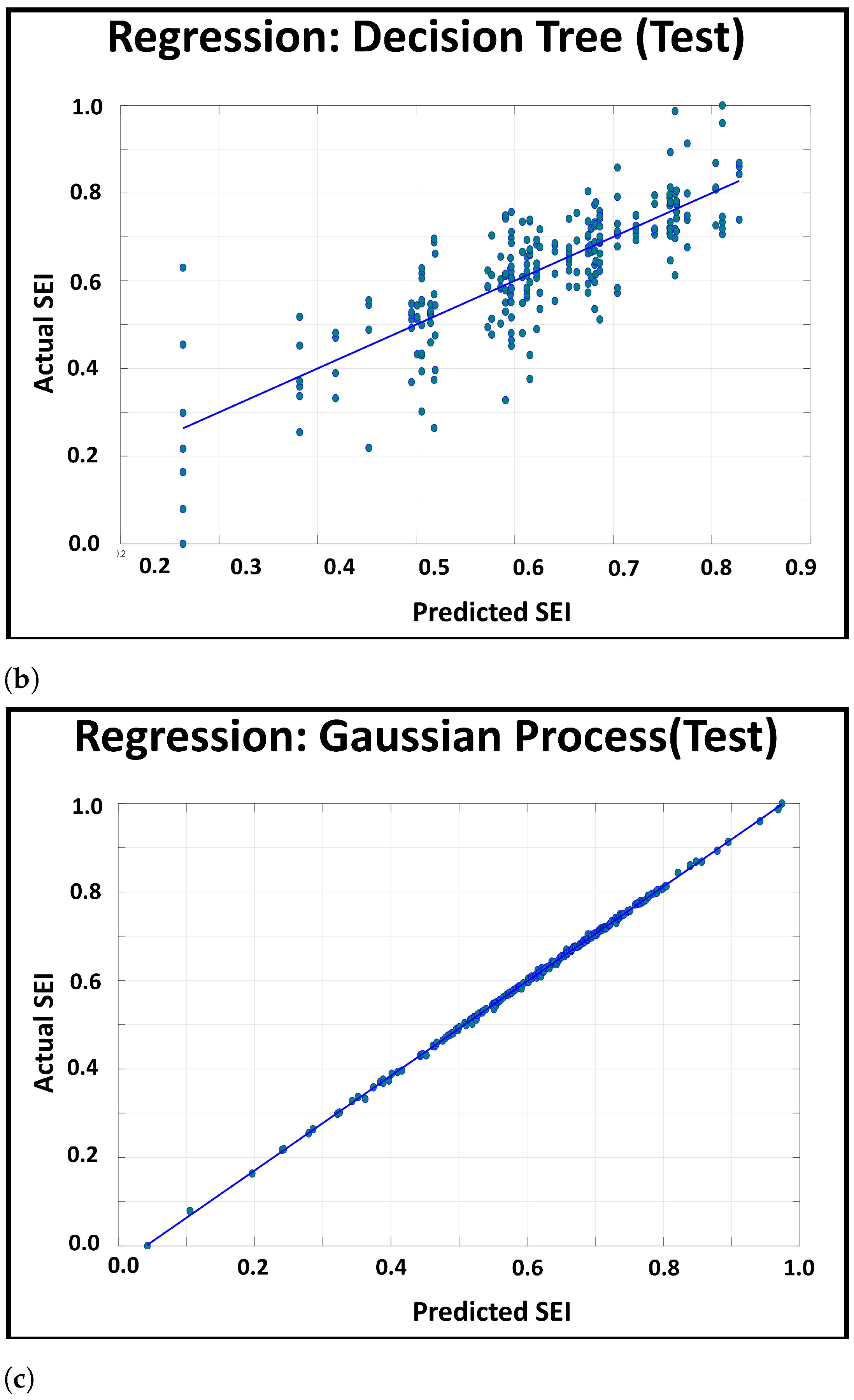
3.3.2. Patient Level Information Encapsulation
- (i)
- Regression Tree: Similar to classification with Decision Trees [24], the Decision Tree for regression splits the attributes into mutually exclusive intervals to create step-wise linear decision boundaries. However, unlike classification trees (which uses entropy and information gain for branching), the regression tree splits the attributes using the mean square error (MSE), and thus, the leaf nodes of the regression tree consists of the attribute’s value at the node, the number of samples at the leaf node (e.g., the leaf’s size), and the MSE between the attribute’s node value and the attribute’s samples’ values.
- (ii)
- Gaussian Process Regression: The Gaussian Process [25] assumes an infinite set of variables, where any finite collection of variables follow a joint multivariate Gaussian joint distribution. Thus, this regression model predicts the response variable by optimizing the covariance function of this distribution, while setting the mean to 0.
4. Discussion
- First, since we use logistic regression for obtaining soft labels in this paper, SEI is restricted to lie between 0 and 1. The only reason we favored the range of SEI to lie between 0 and 1, is because a bounded variable is easier to study; however, there is no practical or physical concerns that dictates that SEI needs to be bounded. As our future work, we expect to conduct a comparison study between a bounded SEI variable and an unbounded SEI variables. Similarly, even though logistic regression seems to be the most appropriate model for obtaining the soft labels, analyzing the expression in Equation (6), we realize that obtaining the soft labels may boil down to the obtaining the optimized coefficients ( in Equation (6)). Thus, other machine learning models, which are capable of binary classification through optimization of weights (e.g., finding equivalents) for given attributes, can be used as well. Experimenting with different machine learning models, which can handle non-linear patterns, may also allow us to obtain better sensitivity and specificity [24,25,31,32,33].
- Second, the interaction that SEI has with medication and other attributes in the EMR dataset might be worth deeper understanding. Developing a system that can trace the interactions in a complex system, or using some of the existing technology [34], may shed new light into the factors and their influence on individuals for substance abuse.
- Third, note that SEI does not need to be a function of just an EMR dataset. Using computational techniques of multi-modal dataset analysis, SEI can be developed from a combined dataset of EMR data and survey questionnaires to incorporate the psychological aspect of substance abuse.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Koob, G.F.; Volkow, N.D.T. Neurocircuitry of addiction. Neuropsychopharmacology 2010, 35, 217–238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsuang, M.T.; Lyons, M.J.; Meyer, J.M.; Doyle, T.; Eisen, S.A.; Goldberg, J.; True, W.; Lin, N.; Toomey, R.; Eaves, L. Co-occurrence of abuse of different drugs in men: The role of drug- specific and shared vulnerabilities. Arch. Gen. Psychiatry 1998, 55, 967–972. [Google Scholar] [CrossRef] [PubMed]
- Kendler, K.S.; Myers, J.; Prescott, C.A. Specificity of genetic and environmental risk factors for symptoms of cannabis, cocaine, alcohol, caffeine, and nicotine dependence. Arch. Gen. Psychiatry 2007, 64, 1313–1320. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, X.; Deng, J.; Rashidian, S.; Abell-Hart, K.; Hou, W.; Rosenthal, R.N.; Saltz, M.; Saltz, J.H.; Wang, F. Identifying risk of opioid use disorder for patients taking opioid medications with deep learning. J. Am. Med. Inform. Assoc. 2021, 28, 1683–1693. [Google Scholar] [CrossRef] [PubMed]
- Shahriar, A.; Faisal, F.; Mahmud, S.U.; Chakrabarti, A.; Rabiul Alam, M.G. A Machine Learning Approach to Predict Vulnerability to Drug Addiction. In Proceedings of the 22nd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 18–20 December 2019; pp. 1–7. [Google Scholar]
- Conway, K.P.; Levy, J.; Vanyukov, M.; Chandler, R.; Rutter, J.; Swan, G.E.; Neale, M. Measuring addiction propensity and severity: The need for a new instrument. Drug Alcohol Depend. 2010, 111, 4–12. [Google Scholar] [CrossRef] [Green Version]
- Skinner, H.A.; Allen, B.A. Alcohol dependence syndrome: Measurement and validation. J. Abnorm. Psychol. 1982, 91, 199–209. [Google Scholar] [CrossRef]
- Stockwell, T.; Hodgson, R.; Edwards, G.; Taylor, C.; Rankin, H. The Development of a Questionnaire to Measure Severity of Alcohol Dependence. Br. J. Addict. Alcohol Other Drugs 1979, 74, 79–87. [Google Scholar] [CrossRef]
- Tarter, R.E.; Laird, S.B.; Kabene, M.; Bukstein, O.; Kaminer, Y. Drug abuse severity in adolescents is associated with magnitude of deviation in temperament traits. Br. J. Addict. 1990, 85, 1501–1504. [Google Scholar] [CrossRef]
- McLellan, A.T.; Luborsky, L.; Woody, G.E.; O’Brien, C.P. An improved diagnostic evaluation instrument for substance abuse patients: The addiction severity index. J. Nerv. Ment. Dis. 1980, 168, 26–33. [Google Scholar] [CrossRef]
- Dennis, M.L.; Kaminer, Y. Introduction to special issue on advances in the assessment and treatment of adolescent substance use disorders. Am. J. Addict. 2006, 15 (Suppl. 1), 1–3. [Google Scholar] [CrossRef]
- Kirisci, L.; Mezzich, A.; Tarter, R. Norms and sensitivity of the adolescent version of the drug use screening inventory. Addict. Behav. 1995, 20, 149–157. [Google Scholar] [CrossRef]
- Ovalle, A.; Goldstein, O.; Kachuee, M.; Wu, E.S.C.; Hong, C.; Holloway, I.W.; Sarrafzadeh, M. Leveraging Social Media Activity and Machine Learning for HIV and Substance Abuse Risk Assessment: Development and Validation Study. J. Med. Internet Res. 2021, 23, e22042. [Google Scholar] [CrossRef]
- Barenholtz, E.; Fitzgerald, N.D.; Hahn, W.E. Machine-learning approaches to substance-abuse research: Emerging trends and their implications. Curr. Opin. Psychiatry 2020, 33, 334–342. [Google Scholar] [CrossRef] [PubMed]
- Garrouste-Orgeas, M.; Troché, G.; Azoulay, E.; Caubel, A.; de Lassence, A.; Cheval, C.; Montesino, L.; Thuong, M.; Vincent, F.; Cohen, Y.; et al. Body mass index. Intensive Care Med. 2004, 30, 437–443. [Google Scholar] [CrossRef] [PubMed]
- Trung, T.Q.; Le, H.S.; Dang, T.M.L.; Ju, S.; Park, S.Y.; Lee, N.-E. Freestanding, Fiber-Based, Wearable Temperature Sensor with Tunable Thermal Index for Healthcare Monitoring. Adv. Healthcare Mater. 2018, 7, e1800074. [Google Scholar] [CrossRef] [PubMed]
- Humphreys, J.S. Delimiting ‘Rural’: Implications of an Agreed ‘Rurality’ Index for Healthcare Planning and Resource Allocation. Aust. J. Rural. Health 1998, 6, 212–216. [Google Scholar] [CrossRef] [PubMed]
- Cheong, K.H.; Tang, K.J.W.; Zhao, X.; Koh, J.E.W.; Faust, O.; Gururajan, R.; Ciaccio, E.J.; Rajinikanth, V.; RajendraAcharya, U. An automated skin melanoma detection system with melanoma-index based on entropy features. Biocybern. Biomed. Eng. 2021, 41, 997–1012. [Google Scholar] [CrossRef]
- Rios, A.; Kavuluru, R. Neural transfer learning for assigning diagnosis codes to EMRs. Artif. Intell. Med. 2019, 96, 116–122. [Google Scholar] [CrossRef]
- Yang, B.; Dai, G.; Yang, Y.; Tang, D.; Li, Q.; Lin, D.; Zheng, J.; Cai, Y. Automatic Text Classification for Label Imputation of Medical Diagnosis Notes Based on Random Forest. Health Inf. Sci. 2018, 11148, 87–97. [Google Scholar]
- Wu, L.-T.; Ringwalt, C.L.; Williams, C.E. Use of Substance Abuse Treatment Services by Persons With Mental Health and Substance Use Problems. Psychiatr. Serv. 2003, 54, 363–369. [Google Scholar] [CrossRef]
- Kleinbaum, D.G.; Klein, M. Logistic Regression; Springer: New York, NY, USA, 2002. [Google Scholar]
- Suthar, B.; Patel, H.; Goswami, A. A survey: Classification of imputation methods in data mining. Int. J. Emerg. Technol. Adv. Eng. 2012, 2, 309–312. [Google Scholar]
- Suthaharan, S. Decision Tree Learning. In Machine Learning Models and Algorithms for Big Data Classification. Integrated Series in Information Systems; Springer: Boston, MA, USA, 2016; pp. 237–269. [Google Scholar]
- Rasmussen, C.E. Gaussian Processes in Machine Learning. In Advanced Lectures on Machine Learning; Bousquet, O., von Luxburg, U., Rätsch, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 63–71. [Google Scholar]
- Hoo, Z.H.; Candlish, J.; Teare, D. What is an ROC curve? Emerg. Med. J. 2017, 34, 357–359. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Zeng, N.; Wang, N. Sensitivity, specificity, accuracy, associated confidence interval and ROC analysis with practical SAS implementations. NESUG Proc. Health Care Life Sci. 2010, 19, 67. [Google Scholar]
- Cuffel, B.J.; Heithoff, K.A.; Lawson, W. Correlates of Patterns of Substance Abuse Among Patients With Schizophrenia. Psychiatr. Serv. 1993, 44, 247–251. [Google Scholar] [CrossRef] [PubMed]
- Daws, L.C.; Avison, M.J.; Robertson, S.D.; Niswender, K.D.; Galli, A.; Saunders, C. Insulin signaling and addiction. Neuropharmacology 2011, 61, 1123–1128. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bharti, K.; Singh, B.Y.P.; Sanjay, K. Addiction to vitamin D: Unusual, unexpected substance abuse. J. Acad. Med Sci. 2012, 2, 43–45. [Google Scholar]
- Steele, V.R.; Maurer, J.M.; Arbabshirani, M.R.; Claus, E.D.; Fink, B.C.; Rao, V.; Calhoun, V.D.; Kiehl, K.A. Machine Learning of Functional Magnetic Resonance Imaging Network Connectivity Predicts Substance Abuse Treatment Completion. Biol. Psychiatry Cogn. Neurosci. Neuroimaging 2018, 3, 141–149. [Google Scholar] [CrossRef] [PubMed]
- Acion, L.; Kelmansky, D.; van der Laan, M.; Sahker, E.; Jones, D.; Arndt, S. Use of a machine learning framework to predict substance use disorder treatment success. PLoS ONE 2017, 12, e0175383. [Google Scholar] [CrossRef]
- Nath, P.; Kilam, S.; Swetapadma, A. A machine learning approach to predict volatile substance abuse for drug risk analysis. In Proceedings of the Third International Conference on Research in Computational Intelligence and Communication Networks (ICRCICN), Kolkata, India, 3–5 November 2017; pp. 255–258. [Google Scholar]
- Lee, E.; Braines, D.; Stiffler, M.; Hudler, A.A.; Harborne, D. Developing the sensitivity of LIME for better machine learning explanation. In Proceedings of the Artificial Intelligence and Machine Learning for Multi-Domain Operations Applications, SPIE, Baltimore, MD, USA, 10 May 2019; Volume 11006, p. 1100610. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Table Names | Relevant Attributes |
|---|---|
| Encounters | Encounter Id, Patient Id, Age, Weight, Geography, Race, Gender, Admission type, Health Insurance, Timestamp |
| Procedures | Procedure description, Procedure Priority, Timestamp |
| Diagnosis | Diagnosis Type, Diagnosis Code, Diagnosis Description, Timestamp |
| Clinical Events | Event Descriptions, Results, Range, Timestamp |
| Laboratory | Blood Test, Urine Test, Other fluid test, Drug Screening, Results, Range, Timestamp |
| Medication | Generic Name, Specific Name, Dosage, Timestamp |
| Tables Used in SEI Definition | Selected Attributes |
|---|---|
| Diagnosis | EncounterId, DiagnosisId, DiagnosisType, DiagnosisCode, DiagnosisDescription, ConditionCategory, DiagnosisPriority, DiagnosisTypeId, DiagnosisTypeDisplay, PresentOnAdmitId |
| Laboratory | EncounterId, DetailLabProcedureId, LabProcedureName, LabProcedureGroup, LabSuperGroup, ResultIndicatorId, ResultIndicatorDesc, Accession, NumericResult, ResultUnitsId, UnitDesc, LabOrderedDtTm, LabDrawnDtTm, LabReceivedDtTm, LabPerformedDtTm, LabVerifiedDtTm, LabCompletedDtTm |
| Procedure | EncounterId, ProcedureId, ProcedureType, ProcedureCode, ProcedureDescription, ProcedurePriority, ProcedureDtTm |
| Medication | EncounterId, MedicationId, NdcCode, BrandName, GenericName, ProductStrengthDescription, RouteDescription, DoseFormDescription, FrequencyId, FrequencyDesc, TotalDispensedDoses, DoseQuantity, InitialDoseQuantity, DoseUnitsId, DoseUnitsDesc, OrderStrength, OrderStrengthUnitsId, OrderStrengthUnitsDisp, MedEnteredDtTm, MedStartedDtTm, MedStoppedDtTm, MedDiscontinuedDtTm |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guttha, N.; Miao, Z.; Shamsuddin, R. Towards the Development of a Substance Abuse Index (SEI) through Informatics. Healthcare 2021, 9, 1596. https://doi.org/10.3390/healthcare9111596
Guttha N, Miao Z, Shamsuddin R. Towards the Development of a Substance Abuse Index (SEI) through Informatics. Healthcare. 2021; 9(11):1596. https://doi.org/10.3390/healthcare9111596
Chicago/Turabian StyleGuttha, Nikhila, Zhuqi Miao, and Rittika Shamsuddin. 2021. "Towards the Development of a Substance Abuse Index (SEI) through Informatics" Healthcare 9, no. 11: 1596. https://doi.org/10.3390/healthcare9111596
APA StyleGuttha, N., Miao, Z., & Shamsuddin, R. (2021). Towards the Development of a Substance Abuse Index (SEI) through Informatics. Healthcare, 9(11), 1596. https://doi.org/10.3390/healthcare9111596