Identifying Veterans Using Electronic Health Records in the United Kingdom: A Feasibility Study

 , , and
, , and
Abstract
:1. Introduction
1.1. Veterans
1.2. Electronic Health Records
1.3 Current Study
2. Methods
2.1 Study Materials
2.2. Study Population
- Veterans who had accessed secondary mental health care services within a ten-year window—1 January 2007 to 31 December 2016. The CRIS register was implemented in 2007, so this was the earliest that EHRs could be accessed. This project commenced in 2018, so 2017 was the last full year that digital records were available.
- Veterans who had served in the UK AF—we retained records for those whose country of birth was noted as the UK or was left as blank (as we noticed that this field was often left blank if the individual was a UK national).
Study Procedure
- Identifying: As there is no structured field for flagging (or denoting) probable veterans within CRIS, our objective was to identify this group by applying a military-related keyword search strategy to the unstructured free-text notes filled in for each patient by clinicians. All EHRs identified as potential veteran records were manually checked by a member of the research team (KMM, DL or DP), to ensure they indicated that the patient had served in the military. It must be noted that, although military terms and phrases were used, we were unable to confirm whether patients had served in the AF. In this study, we use the term “probable veteran” from this point onwards. Percentage agreement between KMM, DL and DP was 100% for a random 10% of the 1600 possible veteran records.
- Extracting: Three members of the research team (KMM, DL and DP) identified probable veterans in CRIS and extracted relevant data. Data fields were exported from CRIS and imported into a comma separated values file. Structured fields relating to the veterans’ socio-demographic characteristics, mental disorders and treatment pathways through care were extracted. The details were transferred to a bespoke study database. The 11 specific variables of interest extracted are shown in Table 1. The variables of interest were extracted through structured fields which are predefined within the CRIS system. In some cases, values were not present within the structured fields, this could be due to human or system error. Where possible, the research team sought to backfill missing data by reading through each patients’ clinical notes and identify the missing information.
- Analysing: Our utility and feasibility investigation used qualitative methods. This allowed us to discuss the practicality of the approach used. We focused on the utility and feasibility of identifying probable veterans and of extracting veteran data. In addition to the descriptive results, this paper also reports on the socio-demographic profiles, mental disorders and treatment pathways of the identified probable veterans.
2.3. Statistical Analysis
3. Results
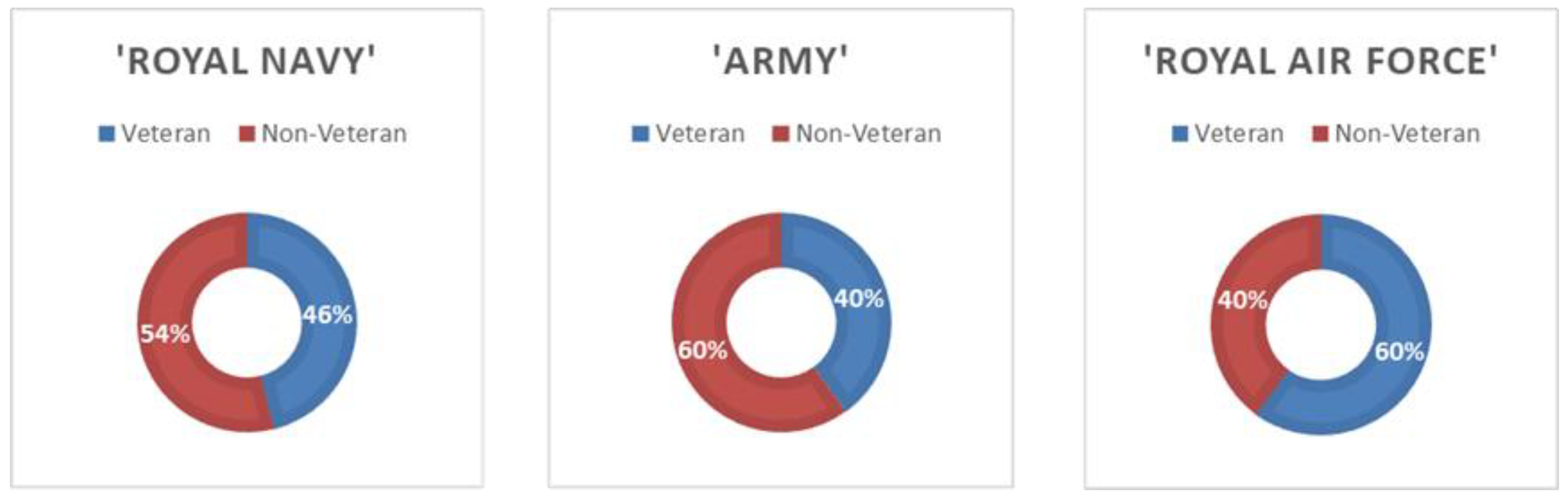
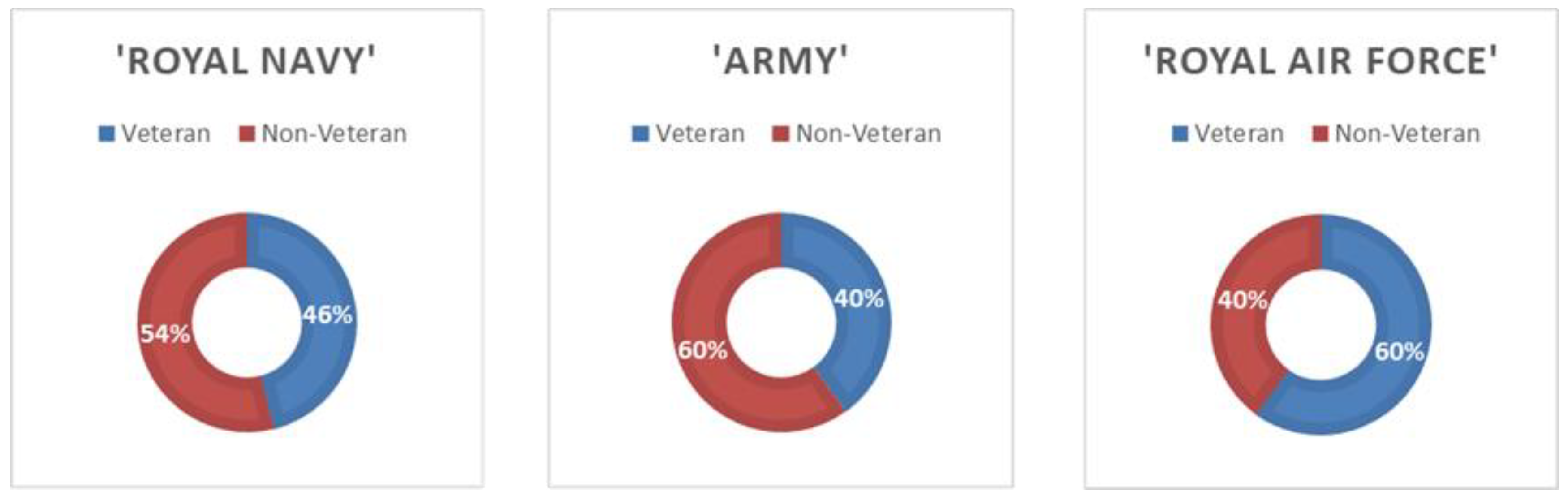
3.1. Identifying
3.2. Extracting
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Veterans: Key Facts. 2016. Available online: https://www.armedforcescovenant.gov.uk/wp-content/uploads/2016/02/Veterans-Key-Facts.pdf (accessed on 12 March 2019).
- Population Projections: UK Armed Forces Veterans residing in Great Britain, 2016 to 2028; UK Military of Defence: London, UK, 2019.
- Williamson, V.; Diehle, J.; Dunn, R.; Jones, N.; Greenberg, N. The impact of military service on health and well-being. Occup. Med. 2019, 69, 64–70. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fear, N.T.; Jones, M.; Murphy, D.; Hull, L.; Iversen, A.C.; Coker, B.; Machell, L.; Sundin, J.; Woodhead, C.; Jones, N.; et al. What are the consequences of deployment to Iraq and Afghanistan on the mental health of the UK armed forces? A cohort study. Lancet 2010, 375, 1783–1797. [Google Scholar] [CrossRef]
- Stevelink, S.A.M.; Jones, M.; Hull, L.; Pernet, D.; MacCrimmon, S.; Goodwin, L.; MacManus, D.; Murphy, D.; Jones, N.; Greenberg, N.; et al. Mental health outcomes at the end of the British involvement in the Iraq and Afghanistan conflicts: A cohort study. Br. J. Psychiatry 2018, 213, 690–697. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dhiele, J.; Williamson, V.; Greenberg, N. Out of sight out of mind: A meta-analysis of mental health problems in UK military reservists and veterans. Eur. J. Public Health 2017. [Google Scholar] [CrossRef] [Green Version]
- Woodhead, C.; Rona, R.J.; Iversen, A.; MacManus, D.; Hotopf, M.; Dean, K.; McManus, S.; Meltzer, H.; Brugha, T.; Jenkins, R.; et al. Mental health and health service use among post-national service veterans: Results from the 2007 Adult Psychiatric Morbidity Survey of England. Psychol. Med. 2011, 41, 363–372. [Google Scholar] [CrossRef] [Green Version]
- Stevelink, S.A.M.; Jones, N.; Jones, M.; Dyball, D.; Khera, C.K.; Pernet, D.; MacCrimmon, S.; Murphy, D.; Hull, L.; Greenberg, N.; et al. Do serving and ex-serving personnel of the UK armed forces seek help for perceived stress, emotional or mental health problems? Eur. J. Psychotraumatol. 2019, 10, 1556552. [Google Scholar] [CrossRef] [Green Version]
- Leightley, D.; Williamson, V.; Darby, J.; Fear, N.T. Identifying probable post-traumatic stress disorder: Applying supervised machine learning to data from a UK military cohort. J. Ment. Health 2019, 28, 34–41. [Google Scholar] [CrossRef]
- Leightley, D.; Puddephatt, J.-A.; Jones, N.; Mahmoodi, T.; Chui, Z.; Field, M.; Drummond, C.; Rona, R.J.; Fear, N.T.; Goodwin, L. A Smartphone App and Personalized Text Messaging Framework (InDEx) to Monitor and Reduce Alcohol Use in Ex-Serving Personnel: Development and Feasibility Study. JMIR mHealth uHealth 2018, 6, e10074. [Google Scholar] [CrossRef] [Green Version]
- Wickersham, A.; Petrides, P.M.; Williamson, V.; Leightley, D. Efficacy of mobile application interventions for the treatment of post-traumatic stress disorder: A systematic review. Digit. Health 2019, 5. [Google Scholar] [CrossRef]
- Iversen, A.; Dyson, C.; Smith, N.; Greenberg, N.; Walwyn, R.; Unwin, C.; Hull, L.; Hotopf, M.; Dandeker, C.; Ross, J.; et al. ‘Goodbye and good luck’: The mental health needs and treatment experiences of British ex-service personnel. Br. J. Psychiatry 2005, 186, 480–486. [Google Scholar] [CrossRef] [Green Version]
- Iversen, A.C.; van Staden, L.; Hughes, J.H.; Browne, T.; Greenberg, N.; Hotopf, M.; Rona, R.J.; Wessely, S.; Thornicroft, G.; Fear, N.T. Help-seeking and receipt of treatment among UK service personnel. Br. J. Psychiatry 2010, 197, 149–155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hines, L.A.; Goodwin, L.; Jones, M.; Hull, L.; Wessely, S.; Fear, N.T.; Rona, R.J. Factors Affecting Help Seeking for Mental Health Problems After Deployment to Iraq and Afghanistan. Psychiatr. Serv. 2014, 65, 98–105. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mojtabai, R.; Olfson, M.; Mechanic, D. Perceived need and help-seeking in adults with mood, anxiety, or substance use disorders. Arch. Gen. Psychiatry 2002, 59, 77–84. [Google Scholar] [CrossRef] [PubMed]
- Leightley, D.; Chui, Z.; Jones, M.; Landau, S.; McCrone, P.; Hayes, R.D.; Wessely, S.; Fear, N.T.; Goodwin, L. Integrating electronic healthcare records of armed forces personnel: Developing a framework for evaluating health outcomes in England, Scotland and Wales. Int. J. Med. Inform. 2018, 113, 17–25. [Google Scholar] [CrossRef] [PubMed]
- Morgan, V.A.; Jablensky, A.V. From inventory to benchmark: Quality of psychiatric case registers in research. Br. J. Psychiatry 2010, 197, 8–10. [Google Scholar] [CrossRef]
- Bevan, G. The Impacts of Asymmetric Devolution on Health Care in the Four Countries of the UK; The Health Foundation and Nuffield Trust: London, UK, 2014. [Google Scholar]
- Stewart, R. The big case register. Acta Psychiatr. Scand. 2014, 130, 83–86. [Google Scholar] [CrossRef] [Green Version]
- Stewart, R.; Soremekun, M.; Perera, G.; Broadbent, M.; Callard, F.; Denis, M.; Hotopf, M.; Thornicroft, G.; Lovestone, S. The South London and Maudsley NHS Foundation Trust Biomedical Research Centre (SLAM BRC) case register: Development and descriptive data. BMC Psychiatry 2009, 9, 51. [Google Scholar] [CrossRef] [Green Version]
- Perera, G.; Broadbent, M.; Callard, F.; Chang, C.-K.; Downs, J.; Dutta, R.; Fernandes, A.; Hayes, R.D.; Henderson, M.; Jackson, R.; et al. Cohort profile of the South London and Maudsley NHS Foundation Trust Biomedical Research Centre (SLaM BRC) Case Register: Current status and recent enhancement of an Electronic Mental Health Record-derived data resource. BMJ Open 2016, 6, e008721. [Google Scholar] [CrossRef] [Green Version]
- Collen, M.F. Clinical research databases? A historical review. J. Med. Syst. 1990, 14, 323–344. [Google Scholar] [CrossRef]
- Saunders, J.B.; Aasland, O.G.; Babor, T.F.; De La Fuente, J.R.; Grant, M. Development of the Alcohol Use Disorders Identification Test (AUDIT): WHO Collaborative Project on Early Detection of Persons with Harmful Alcohol Consumption-II. Addiction 1993, 88, 791–804. [Google Scholar] [CrossRef]
- Woodhead, C.; Sloggett, A.; Bray, I.; Bradbury, J.; McManus, S.; Meltzer, H.; Brugha, T.; Jenkins, R.; Greenberg, N.; Wessely, S.; et al. An estimate of the veteran population in England: Based on data from the 2007 Adult Psychiatric Morbidity Survey. Popul. Trends 2009, 138, 50–54. [Google Scholar] [CrossRef] [PubMed]
- National Health Service. How We Use Your Data. Available online: https://resolution.nhs.uk/how-we-use-your-data/ (accessed on 1 September 2018).
- Metraux, S.; Stino, M.; Culhane, D.P. Validation of self-reported veteran status among two sheltered homeless populations. Public Health Rep. 2014, 129, 73–77. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bergman, B.P.; Mackay, D.F.; Smith, D.J.; Pell, J.P. Long-Term Mental Health Outcomes of Military Service: National Linkage Study of 57,000 Veterans and 173,000 Matched Nonveterans. J. Clin. Psychiatry 2016, 77, 793–798. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fernandes, A.C.; Dutta, R.; Velupillai, S.; Sanyal, J.; Stewart, R.; Chandran, D. Identifying Suicide Ideation and Suicidal Attempts in a Psychiatric Clinical Research Database using Natural Language Processing. Sci. Rep. 2018, 8, 7426. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cambria, E.; White, B. Jumping NLP Curves: A Review of Natural Language Processing Research. IEEE Comput. Intell. Mag. 2014, 9, 48–57. [Google Scholar] [CrossRef]
- Manning, C.; Schutze, H. Foundations of Statistical Natural Language Processing; The MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Chowdhury, G.G. Natural language processing. Annu. Rev. Inf. Sci. Technol. 2005, 37, 51–89. [Google Scholar] [CrossRef] [Green Version]
- Wickersham, A.; Epstein, S.; Sugg, H.V.R.; Stewart, R.; Ford, T.; Downs, J. The association between depression and later educational attainment in children and adolescents: A systematic review protocol. BMJ Open 2019, 9, e031595. [Google Scholar] [CrossRef]
- Downs, J.M.; Ford, T.; Stewart, R.; Epstein, S.; Shetty, H.; Little, R.; Jewell, A.; Broadbent, M.; Deighton, J.; Mostafa, T.; et al. An approach to linking education, social care and electronic health records for children and young people in South London: A linkage study of child and adolescent mental health service data. BMJ Open 2019, 9, e024355. [Google Scholar] [CrossRef]
- Kovalchuk, Y.; Stewart, R.; Broadbent, M.; Hubbard, T.J.P.; Dobson, R.J.B. Analysis of diagnoses extracted from electronic health records in a large mental health case register. PLoS ONE 2017, 12, e0171526. [Google Scholar] [CrossRef] [Green Version]
- Anderson, H.D.; Pace, W.D.; Brandt, E.; Nielsen, R.D.; Allen, R.R.; Libby, A.M.; West, D.R.; Valuck, R.J. Monitoring suicidal patients in primary care using electronic health records. J. Am. Board Fam. Med. 2015, 28, 65–71. [Google Scholar] [CrossRef]

{kind=link}
| Variables Extracted | |
|---|---|
| 1. Age (in years) in 2018 | 7. Number of mental disorder diagnoses |
| 2. Gender | 8. Number of outpatient secondary mental health care appointments booked |
| 3. Living arrangements | 9. Number of outpatient secondary mental health care appointments attended |
| 4. Ethnicity | 10. Number of inpatient secondary mental health care stays |
| 5. Age at mental disorder diagnoses | 11. Duration of inpatient secondary mental health care stays (in days) |
| 6. Types of mental disorder diagnoses | |
| Included Key Words | Exclusion Criteria | Notes |
|---|---|---|
| Army | “who was/is in (the) army” | Majority of times this refers to someone other than the patient |
| “Salvation Army” | ||
| “army knife” | ||
| “army gear” | ||
| “army style” | ||
| “army cadet” | ||
| “army cadette” | ||
| “army themed” | ||
| “child army” | ||
| “army family” | ||
| “rebel army” | ||
| “refugee army” | ||
| “army service” | ||
| “private army” | ||
| “army green” | ||
| “army <item of clothing>” | Clothing | |
| “army type” | ||
| Foreign armies: Eritrea, Sri Lanka | Reference to service in non-UK army, or experiences relating to non-UK army | |
| Navy | “navy blue” | Clothing |
| “dark navy” | Clothing | |
| “navy colour” | Clothing | |
| “wearing (a) navy” | Clothing | |
| “dressed in navy” | Clothing | |
| “navy <item of clothing>” | Clothing | |
| “Merchant Navy” | ||
| “Army and Navy Store” | ||
| “worked for Navy, Army, Air Force Institute” | NAAFI | |
| “<family member> was/is in (the) navy” | Family member in Navy | |
| “due to join the Navy” | (Thinking of) joining Navy | |
| “accepted into Navy” | (Thinking of) joining Navy | |
| “potential careers, including Navy” | (Thinking of) joining Navy | |
| Foreign navies: Italian, US, Israeli, Portuguese, Burmese, Eritrea | Reference to service in non-UK navy, or experiences relating to non-UK navy | |
| RAF/air force | “<family member> was/is in (the) RAF” | Family member in RAF |
| Armed Forces | ||
| Afghan | Deployment location | |
| Iraq | Deployment location | |
| Bosnia | Deployment location | |
| Kosovo | Deployment location | |
| Falklands | Deployment location | |
| N Ireland | Deployment location | |
| Cyprus | Deployment location | |
| Germany | Deployment location | |
| Enlisted | ||
| National service | ||
| Veteran | ||
| Combat Stress | Military charity | |
| SSAFA | Military charity | |
| Help for Heroes | Military charity |
| Overall (n = 693) | n Missing (n, %) | NS Era (n = 349) | n Missing (n, %) | Post NS Era (n = 344) | n Missing (n, %) | Chi2 (p) | p Value | |
|---|---|---|---|---|---|---|---|---|
| Age at sampling point (years; 2018) [median, IQR] | 74 (53–86) | - | 86 (82–90) | - | 52 (41–61) | - | - | <0.001 |
| Gender (n, %) -Male -Female | 629 (90.76) 64 (9.24) | - | 317 (90.83) 32 (9.17) | - | 312 (90.70) 32 (9.30) | - | 0.0037 (0.952) | - |
| Residency (n, %) -Alone -Friends/family/other -Partner/children | 263 (37.95) 108 (15.58) 225 (32.46) | 97 (13.99) | 129 (36.96) 39 (11.17) 147 (42.12) | 34 (9.74) | 134 (38.95) 69 (20.05) 78 (22.67) | 63 (18.31) | 50.614 (<0.001) | - |
| Ethnicity (n, %) -White British -Other | 610 (88.02) 58 (8.36) | 25 (3.60) | 330 (94.55) 15 (4.29) | 4 (1.14) | 280 (81.39) 43 (12.50) | 21 (6.10) | 21.215 (<0.001) | - |
| Number of veterans with an inpatient admission (n, %) | 146 (21.07) | - | 59 (16.90) | - | 87 (25.29) | - | - | 0.068 |
| Number of veterans with an outpatient appointment (n, %) | 116 (16.74) | - | 35 (10.02) | - | 81 (23.54) | - | - | <0.001 |
| Number of veterans with an inpatient admission and outpatient appointment (n, %) | 36 (5.19) | - | 16 (4.58) | - | 20 (5.81) | - | - | 0.162 |
| Age at mental disorder diagnosis (years) [median, IQR] | 71 (46–83) | 52 (7.50) | 82 (77–87) | 11 (3.15) | 46 (36–55) | 41 (11.91) | - | <0.001 |
| Types of mental disorder diagnoses (n, %) -Alcohol use disorders -Drug disorders -Stress disorders -Depressive disorders -Anxiety disorders -Schizophrenic disorders -Personality disorders -Other mental disorders * | n = 822 86 (10.46) 34 (4.13) 75 (9.12) 188 (22.87) 62 (7.54) 40 (4.86) 37 (4.50) 67 (8.15) | - | n = 306 16 (5.22) 1 (0.32) 24 (7.84) 88 (28.75) 27 (8.82) 15 (4.90) 5 (1.63) 9 (2.94) | - | n = 516 70 (13.56) 33 (6.39) 51 (9.88) 100 (19.37) 35 (6.78) 25 (4.84) 32 (6.20) 58 (11.24) | - | 39.607 (<0.001) 32.160 (<0.001) 11.341 (0.001) 1.302 (0.254) 1.264 (0.261) 2.808 (0.094) 21.228 (<0.001) 40.460 (<0.001) | - |
| Number of comorbid mental health diagnoses (n, %) -Zero -One -Two -Three or more | 336 (48.48) 190 (21.41) 76 (10.96) 26 (3.75) | 65 (9.37) | 164 (46.99) 122 (34.95) 40 (11.46) 11 (3.15) | 12 (3.43) | 172 (50.00) 68 (19.76) 36 (10.46) 15 (4.36) | 53 (15.40) | 13.927 (0.016) | - |
| Number of outpatient appointments booked ** [median, IQR] *** -Booked -Attended | 2 (1–5) 2 (1–4) | - | 2 (1–3) 1.5 (1–3) | - | 3 (1–13) 2 (1–9) | - | - | 0.293 0.186 |
| Number of inpatient mental health care stays [median, IQR] *** | 1 (1–2) | - | 1 (1–2) | - | 1 (1–2) | - | - | 0.124 |
| Duration of inpatient mental health care stays (in days) [median, IQR] *** | 28.5 (12–73.5) | - | 60.5 (31–120) | - | 15 (7–35) | - | - | 0.038 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
M. Mark, K.; Leightley, D.; Pernet, D.; Murphy, D.; Stevelink, S.A.M.; T. Fear, N. Identifying Veterans Using Electronic Health Records in the United Kingdom: A Feasibility Study. Healthcare 2020, 8, 1. https://doi.org/10.3390/healthcare8010001
M. Mark K, Leightley D, Pernet D, Murphy D, Stevelink SAM, T. Fear N. Identifying Veterans Using Electronic Health Records in the United Kingdom: A Feasibility Study. Healthcare. 2020; 8(1):1. https://doi.org/10.3390/healthcare8010001
Chicago/Turabian StyleM. Mark, Katharine, Daniel Leightley, David Pernet, Dominic Murphy, Sharon A.M. Stevelink, and Nicola T. Fear. 2020. "Identifying Veterans Using Electronic Health Records in the United Kingdom: A Feasibility Study" Healthcare 8, no. 1: 1. https://doi.org/10.3390/healthcare8010001
APA StyleM. Mark, K., Leightley, D., Pernet, D., Murphy, D., Stevelink, S. A. M., & T. Fear, N. (2020). Identifying Veterans Using Electronic Health Records in the United Kingdom: A Feasibility Study. Healthcare, 8(1), 1. https://doi.org/10.3390/healthcare8010001