
Reinforcement Learning and Its Clinical Applications Within Healthcare: A Systematic Review of Precision Medicine and Dynamic Treatment Regimes

 , ,
, ,
Abstract
1. Introduction to Reinforcement Learning and Its Applications
1.1. Introduction
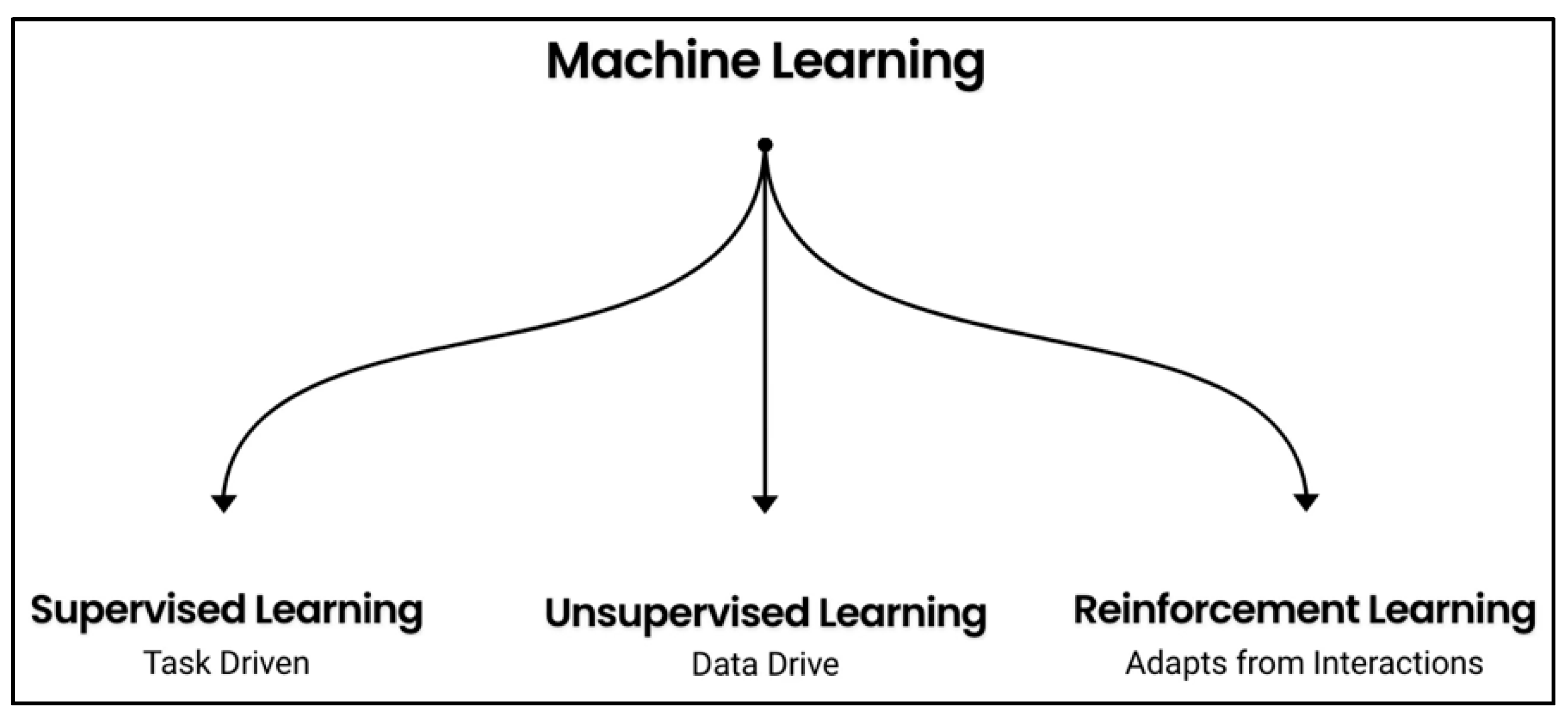
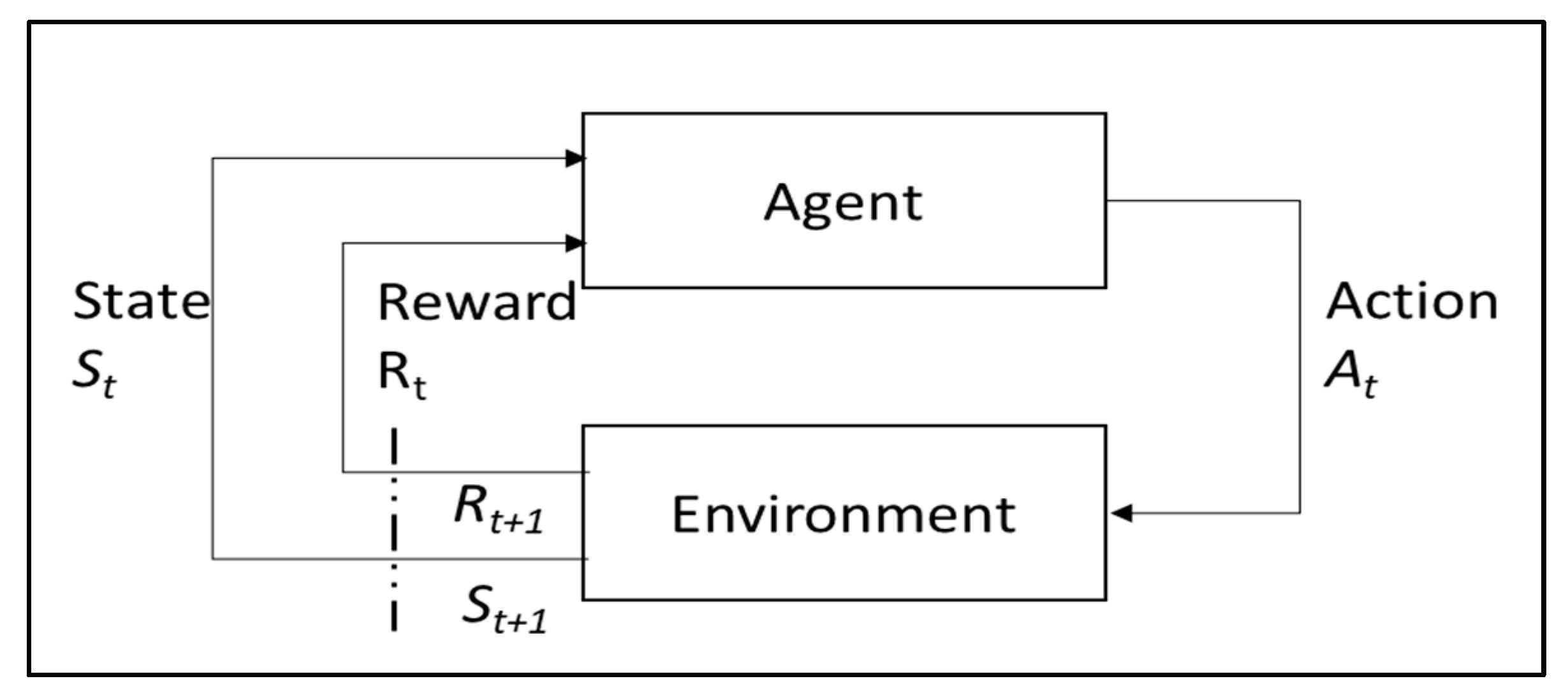
1.2. Background of RL
1.3. Research Directions
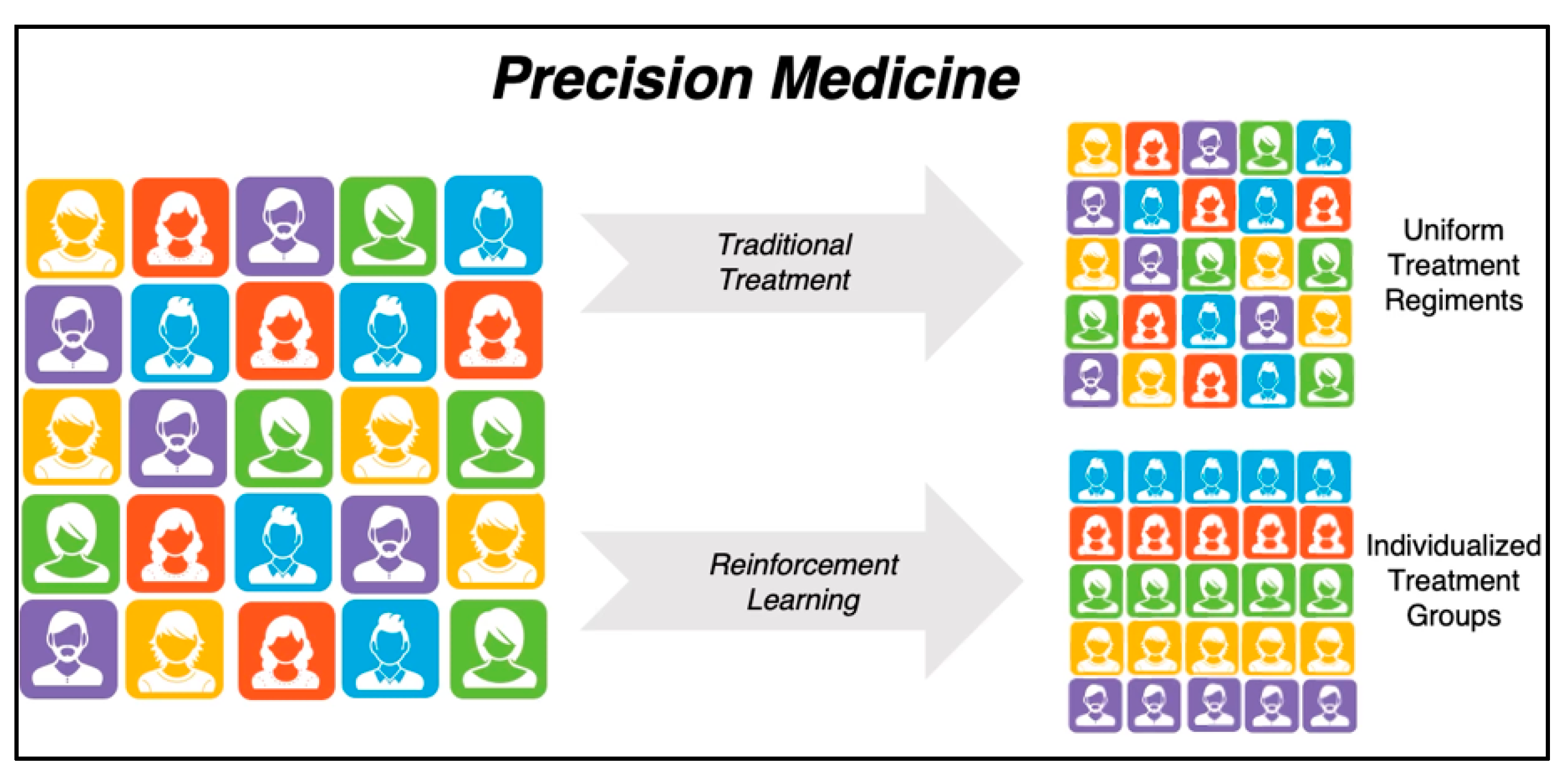
1.3.1. Introduction to Precision Medicine
1.3.2. Introduction to Dynamic Treatment Regime
1.4. Current RL Challenges
2. Systematic Review
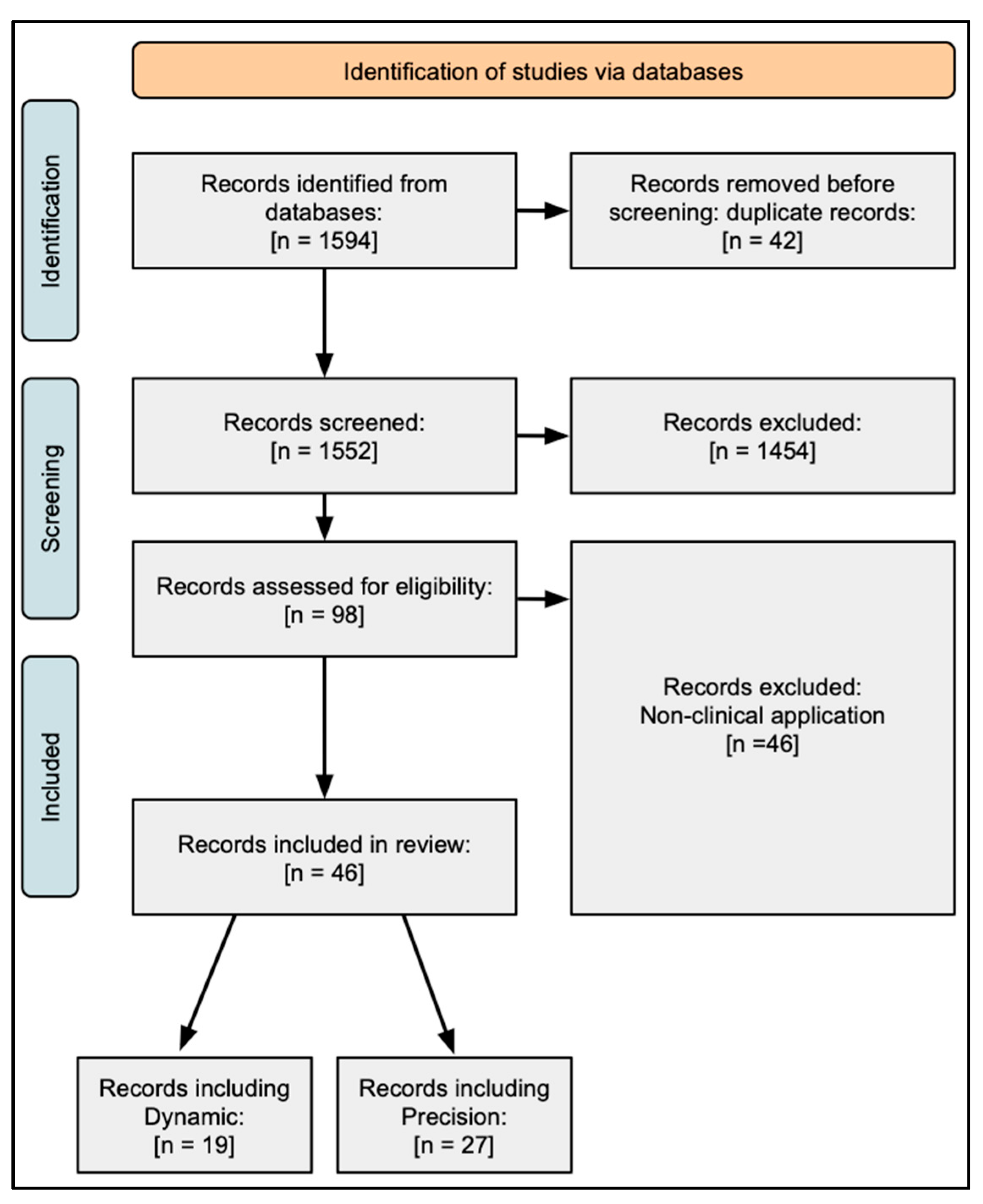
2.1. Methodology
2.2. Dynamic Treatment Regime
2.3. Precision Medicine
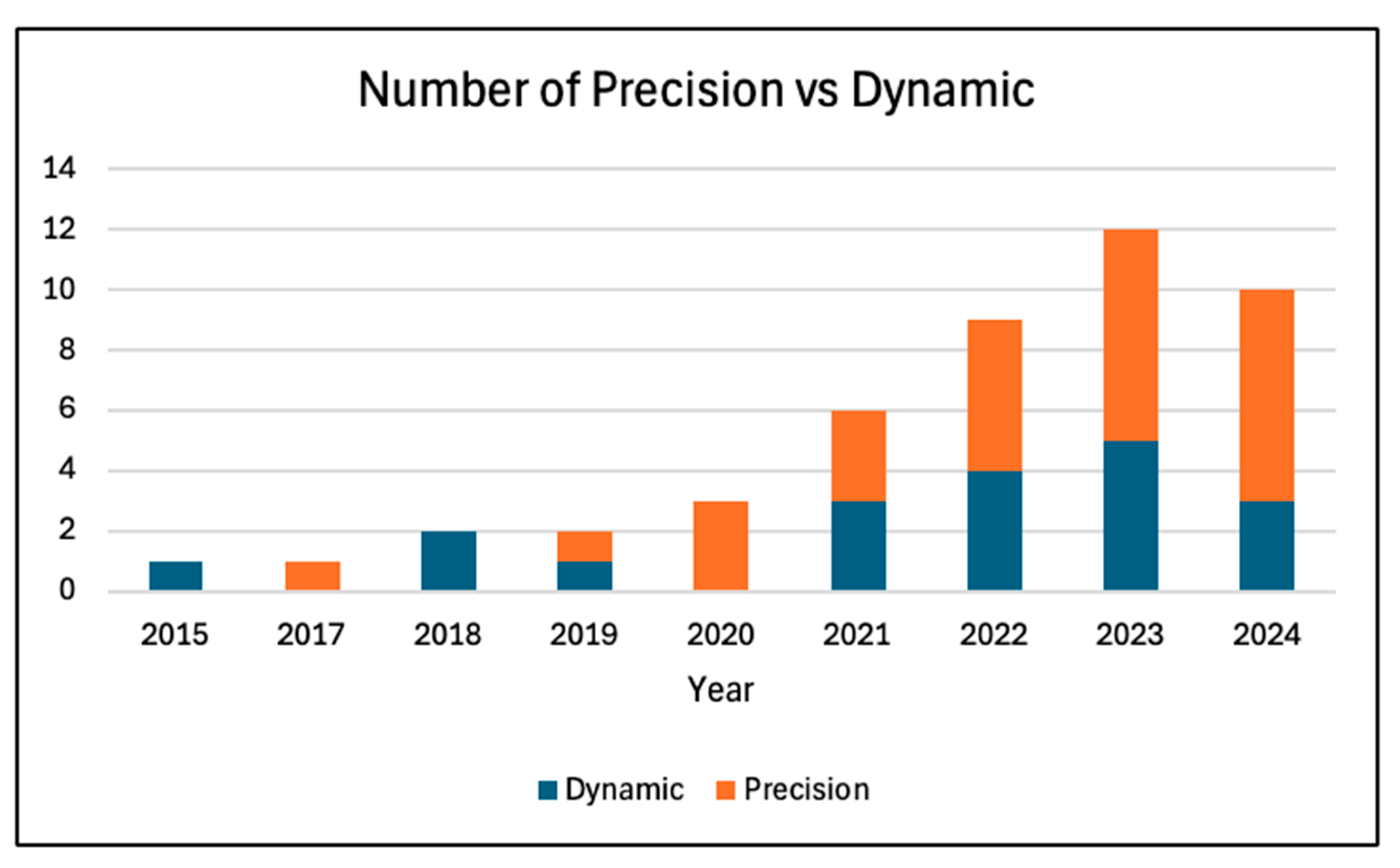
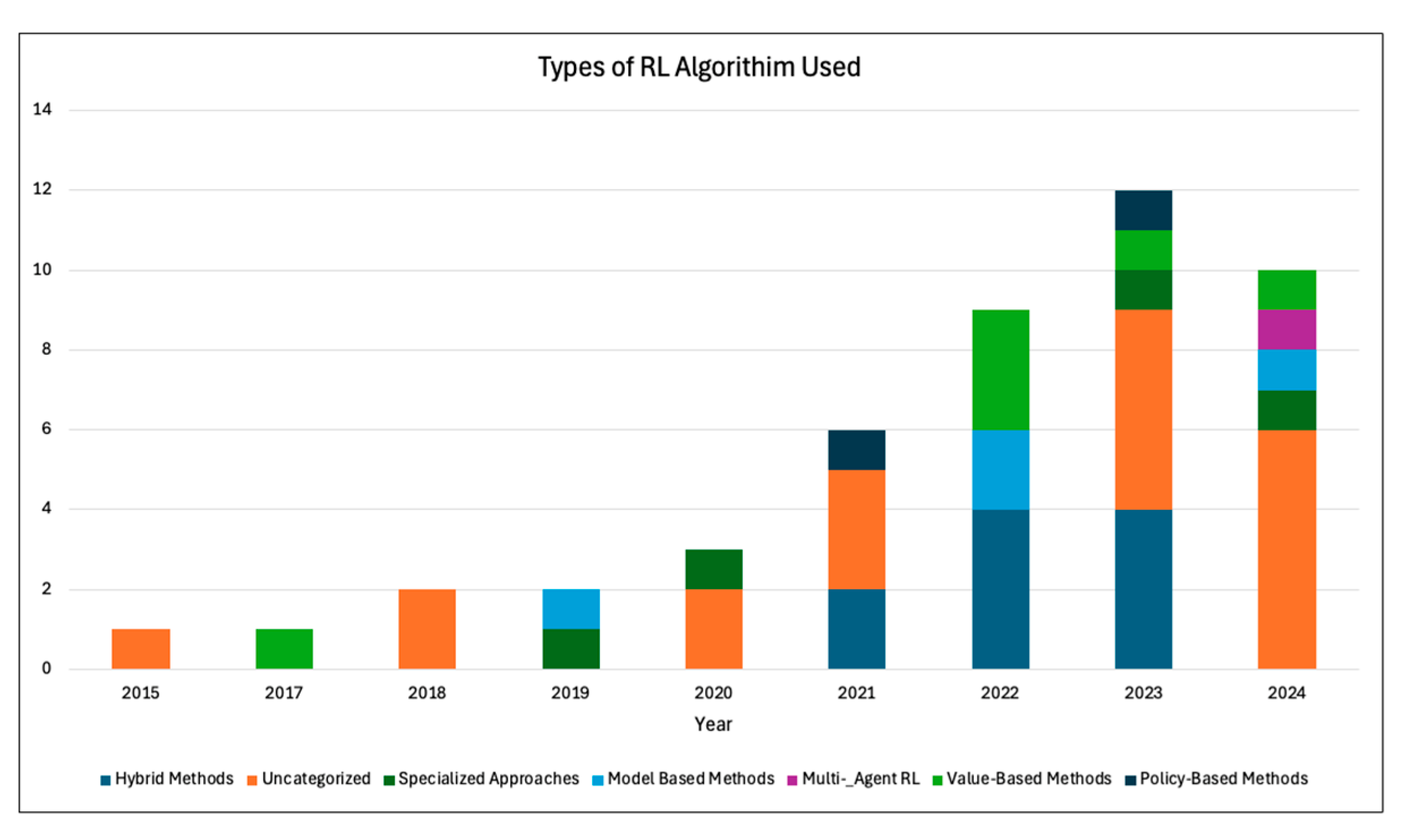
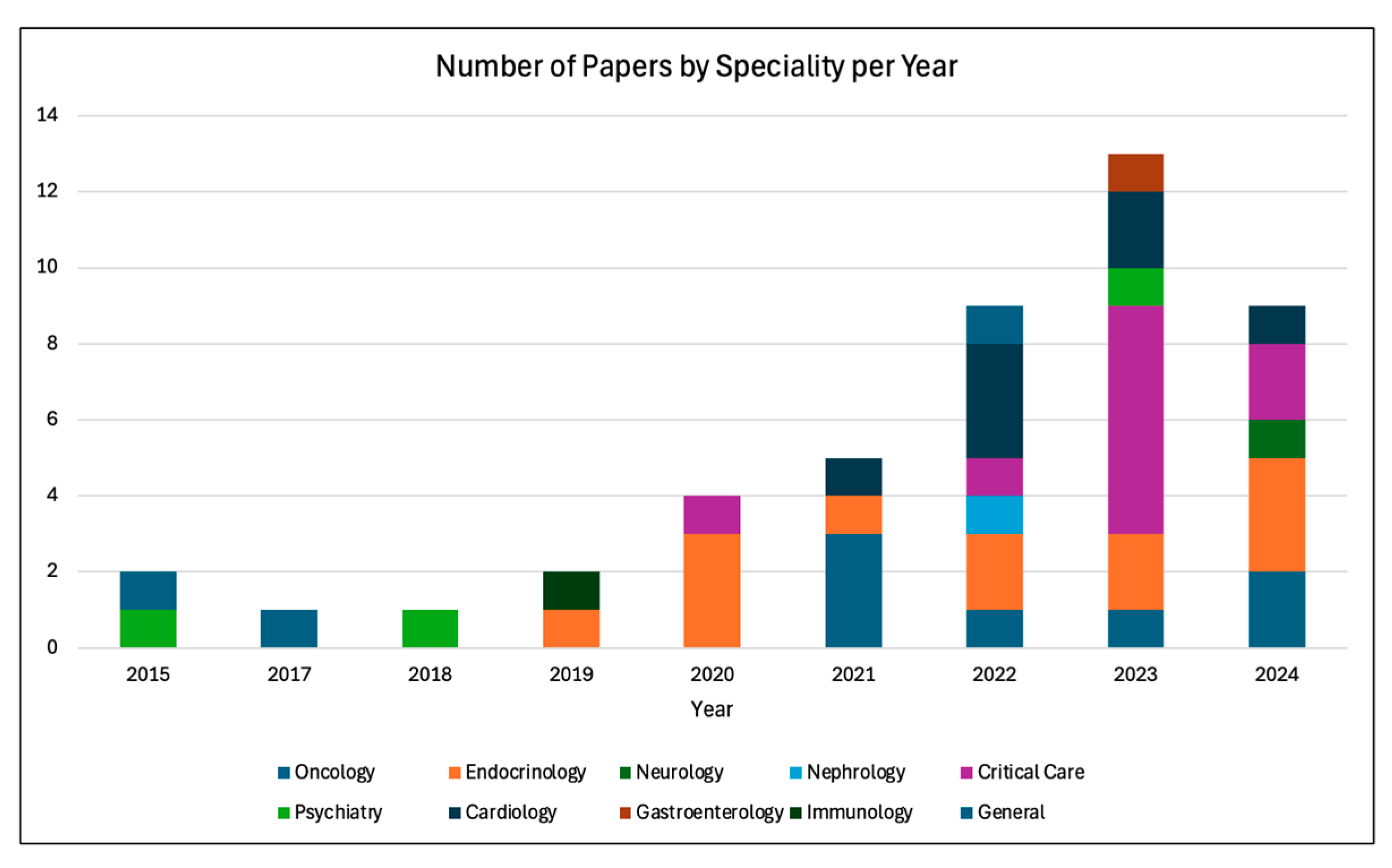
2.4. Findings of the Review
2.5. Limitations of the Review
3. Future Directions and Practical Implications
3.1. Developing Research Taxonomy for Clinicians
3.1.1. Challenges
- How can RL methods gain trust for clinician use?
- How can the RL and clinical community better communicate to develop problems of interest and a common lexicon?
- How can clinicians be better educated in algorithms?
- How can research on data augmentation and advanced experimental designs facilitate the use of RL on rare diseases?
- How is RL being applied within clinical decision making and healthcare settings to optimize both quality care and patient safety?
3.1.2. Benefits
- How can RL benefits be best illustrated and presented to clinicians?
- What metrics and assessment are best suited to enable RL benefits to be provided with minimal harm?
- How can a move toward data-driven patient outcome be best facilitated and welcomed?
3.1.3. Current Applications
- What applications are not captured in PubMed due to their interdisciplinary nature and publication in other domains?
- How can challenges posed by medicine-related RL reach medical audiences effectively?
- Can better constructed interdisciplinary teams ensure that medical applications of RL are adequately solved for potential clinical adoption?
3.1.4. Directions
- What are the current research directions in RL that are most applicable to clinical problems?
- What clinical problems should be extended for RL solutions as challenge problems?
- What is needed to best assess RL solutions to clinical problems?
3.2. Practical Implications for Clinicians
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| ML | machine learning |
| RL | reinforcement learning |
| PM | precision medicine |
| DTR | dynamic treatment regimen |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| GRADE | Grading of Recommendations, Assessment, Development, and Evaluation |
| PD | Parkinson’s disease |
| LSTM | long short-term memory |
| SUD | substance use disorder |
| BOWL | backward outcome-weighted learning |
| SOWL | simultaneous outcome-weighted learning |
| ICU | intensive care unit |
| MDP | Markov Decision Process |
| GORL | goal-oriented reinforcement learning |
| ART | adaptive radiation therapy |
| GI | gastroenterology |
| DRL | deep reinforcement learning |
| EHRs | electronic health records |
| NIV | noninvasive ventilation |
References
- Young, A.T.; Xiong, M.; Pfau, J.; Keiser, M.J.; Wei, M.L. Artificial Intelligence in Dermatology: A Primer. J. Invest. Dermatol. 2020, 140, 1504–1512. [Google Scholar] [CrossRef] [PubMed]
- Kann, B.H.; Hosny, A.; Aerts, H. Artificial intelligence for clinical oncology. Cancer Cell 2021, 39, 916–927. [Google Scholar] [CrossRef] [PubMed]
- Nawab, K.; Athwani, R.; Naeem, A.; Hamayun, M.; Wazir, M. A Review of Applications of Artificial Intelligence in Gastroenterology. Cureus 2021, 13, e19235. [Google Scholar] [CrossRef] [PubMed]
- Nakamura, T.; Sasano, T. Artificial intelligence and cardiology: Current status and perspective. J. Cardiol. 2022, 79, 326–333. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Yu, J.; Chamouni, S.; Wang, Y.; Li, Y. Integrating machine learning and artificial intelligence in life-course epidemiology: Pathways to innovative public health solutions. BMC Med. 2024, 22, 354. [Google Scholar] [CrossRef] [PubMed]
- Panch, T.; Szolovits, P.; Atun, R. Artificial intelligence, machine learning and health systems. J. Glob. Health 2018, 8, 020303. [Google Scholar] [CrossRef] [PubMed]
- Sidey-Gibbons, J.A.M.; Sidey-Gibbons, C.J. Machine learning in medicine: A practical introduction. BMC Med. Res. Methodol. 2019, 19, 64. [Google Scholar] [CrossRef] [PubMed]
- Rashidi, H.H.; Tran, N.; Albahra, S.; Dang, L.T. Machine learning in health care and laboratory medicine: General overview of supervised learning and Auto-ML. Int. J. Lab. Hematol. 2021, 43 (Suppl. 1), 15–22. [Google Scholar] [CrossRef] [PubMed]
- Uddin, S.; Khan, A.; Hossain, M.E.; Moni, M.A. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inform. Decis. Mak. 2019, 19, 281. [Google Scholar] [CrossRef] [PubMed]
- Murali, N.; Kucukkaya, A.; Petukhova, A.; Onofrey, J.; Chapiro, J. Supervised Machine Learning in Oncology: A Clinician’s Guide. Dig. Dis. Interv. 2020, 4, 73–81. [Google Scholar] [CrossRef] [PubMed]
- Roohi, A.; Faust, K.; Djuric, U.; Diamandis, P. Unsupervised Machine Learning in Pathology: The Next Frontier. Surg. Pathol. Clin. 2020, 13, 349–358. [Google Scholar] [CrossRef] [PubMed]
- Wan, Y.; Yang, P.; Xu, L.; Yang, J.; Luo, C.; Wang, J.; Chen, F.; Wu, Y.; Lu, Y.; Ruan, D.; et al. Radiomics analysis combining unsupervised learning and handcrafted features: A multiple-disease study. Med. Phys. 2021, 48, 7003–7015. [Google Scholar] [CrossRef] [PubMed]
- Colombo, T.; Mangone, M.; Agostini, F.; Bernetti, A.; Paoloni, M.; Santilli, V.; Palagi, L. Supervised and unsupervised learning to classify scoliosis and healthy subjects based on non-invasive rasterstereography analysis. PLoS ONE 2021, 16, e0261511. [Google Scholar] [CrossRef] [PubMed]
- Bednarski, B.P.; Singh, A.D.; Jones, W.M. On collaborative reinforcement learning to optimize the redistribution of critical medical supplies throughout the COVID-19 pandemic. J. Am. Med. Inform. Assoc. 2021, 28, 874–878. [Google Scholar] [CrossRef] [PubMed]
- Datta, S.; Li, Y.; Ruppert, M.M.; Ren, Y.; Shickel, B.; Ozrazgat-Baslanti, T.; Rashidi, P.; Bihorac, A. Reinforcement learning in surgery. Surgery 2021, 170, 329–332. [Google Scholar] [CrossRef] [PubMed]
- Eckardt, J.N.; Wendt, K.; Bornhauser, M.; Middeke, J.M. Reinforcement Learning for Precision Oncology. Cancers 2021, 13, 4624. [Google Scholar] [CrossRef] [PubMed]
- Oh, S.H.; Lee, S.J.; Park, J. Precision Medicine for Hypertension Patients with Type 2 Diabetes via Reinforcement Learning. J. Pers. Med. 2022, 12, 87. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.; Liu, J.; Nemati, S. Reinforcement Learning in Healthcare: A Survey. arXiv 2020, arXiv:1908.08796. [Google Scholar] [CrossRef]
- Coronato, A.; Naeem, M.; De Pietro, G.; Paragliola, G. Reinforcement learning for intelligent healthcare applications: A survey. Artif. Intell. Med. 2020, 109, 101964. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; See, K.C.; Ngiam, K.Y.; Celi, L.A.; Sun, X.; Feng, M. Reinforcement Learning for Clinical Decision Support in Critical Care: Comprehensive Review. J. Med. Internet Res. 2020, 22, e18477. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.K.; Le, H.N.; Luu, K.; H, V.N.; Ayache, N. Deep reinforcement learning in medical imaging: A literature review. Med. Image Anal. 2021, 73, 102193. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Liu, Y.; Logan, B.; Xu, Z.; Tang, J.; Wang, Y. Learning the Dynamic Treatment Regimes from Medical Registry Data through Deep Q-network. Sci. Rep. 2019, 9, 1495. [Google Scholar] [CrossRef] [PubMed]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach, 4th ed.; Pearson: Boston, MA, USA, 2020. [Google Scholar]
- Sutton, R.S.B.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Kober, J.A.B.; Bagnell, J.A.; Peters, J. Reinforcement Learning in Robotics: A Survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Badia, A.P.; Piot, B.; Kapturowski, S.; Sprechmann, P.; Vitvitskyi, A.; Guo, Z.D.; Blundell, C. Agent57: Outperforming the Atari Human Benchmark. In Proceedings of Machine Learning Research, Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; JMLR: Cambridge, MA, USA; pp. 507–517.
- Nachum, O.; Gu, S.; Lee, H.; Levine, S. Data-Efficient Hierarchical Reinforcement Learning. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 2–8 December 2018; Advances in Neural Information Processing Systems. pp. 3303–3313. [Google Scholar]
- Trevor, B.; Aaron, J.; Farr, P.; Straub, K.; Bontempo, B.; Jones, F. Assessing Multi-Agent Reinforcement Learning Algorithms for Autonomous Sensor Resource Management. In Proceedings of the 55th Hawaii International Conference on System Sciences. 2022, HICSS, Maui, HI, USA, 4–7 January 2022. [Google Scholar]
- Jonsson, A. Deep Reinforcement Learning in Medicine. Kidney Dis. 2019, 5, 18–22. [Google Scholar] [CrossRef] [PubMed]
- Watts, J.; Khojandi, A.; Vasudevan, R.; Ramdhani, R. Optimizing Individualized Treatment Planning for Parkinson’s Disease Using Deep Reinforcement Learning. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2020, 2020, 5406–5409. [Google Scholar] [PubMed]
- Shen, C.; Gonzalez, Y.; Klages, P.; Qin, N.; Jung, H.; Chen, L.; Nguyen, D.; Jiang, S.B.; Jia, X. Intelligent inverse treatment planning via deep reinforcement learning, a proof-of-principle study in high dose-rate brachytherapy for cervical cancer. Phys. Med. Biol. 2019, 64, 115013. [Google Scholar] [CrossRef] [PubMed]
- Sprouts, D.; Gao, Y.; Wang, C.; Jia, X.; Shen, C.; Chi, Y. The development of a deep reinforcement learning network for dose-volume-constrained treatment planning in prostate cancer intensity modulated radiotherapy. Biomed. Phys. Eng. Express 2022, 8, 045008. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimi Zade, A.; Shahabi Haghighi, S.; Soltani, M. Deep neural networks for neuro-oncology: Towards patient individualized design of chemo-radiation therapy for Glioblastoma patients. J. Biomed. Inform. 2022, 127, 104006. [Google Scholar] [CrossRef] [PubMed]
- Pu, G.; Jiang, S.; Yang, Z.; Hu, Y.; Liu, Z. Deep reinforcement learning for treatment planning in high-dose-rate cervical brachytherapy. Phys. Med. 2022, 94, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Roggeveen, L.; El Hassouni, A.; Ahrendt, J.; Guo, T.; Fleuren, L.; Thoral, P.; Girbes, A.R.; Hoogendoorn, M.; Elbers, P.W. Transatlantic transferability of a new reinforcement learning model for optimizing haemodynamic treatment for critically ill patients with sepsis. Artif. Intell. Med. 2021, 112, 102003. [Google Scholar] [CrossRef] [PubMed]
- Nanayakkara, T.; Clermont, G.; Langmead, C.J.; Swigon, D. Unifying cardiovascular modelling with deep reinforcement learning for uncertainty aware control of sepsis treatment. PLoS Digit. Health 2022, 1, e0000012. [Google Scholar] [CrossRef] [PubMed]
- Ju, S.; Kim, Y.J.; Ausin, M.S.; Mayorga, M.E.; Chi, M. To Reduce Healthcare Workload: Identify Critical Sepsis Progression Moments through Deep Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Orlando, FL, USA, 15–18 December 2021; pp. 1–8. [Google Scholar]
- Liu, X.; Yu, C.; Huang, Q.; Wang, L.; Wu, J.; Guan, X. Combining Model-Based and Model-Free Reinforcement Learning Policies for More Efficient Sepsis Treatment. In Bioinformatics Research and Applications; Springer International Publishing: Cham, Switzerland, 2021; pp. 105–117. [Google Scholar]
- Liu, R.; Greenstein, J.L.; Fackler, J.C.; Bergmann, J.; Bembea, M.M.; Winslow, R.L. Offline reinforcement learning with uncertainty for treatment strategies in sepsis. arXiv 2021, arXiv:2107.04491. [Google Scholar]
- Schleidgen, S.; Klingler, C.; Bertram, T.; Rogowski, W.H.; Marckmann, G. What is personalized medicine: Sharpening a vague term based on a systematic literature review. BMC Med. Ethics 2013, 14, 55. [Google Scholar] [CrossRef] [PubMed]
- National Research Council. Toward Precision Medicine: Building a Knowledge Network for Biomedical Research and a New Taxonomy of Disease; The National Academies Press: Washington, DC, USA, 2011. [Google Scholar]
- Johnson, K.B.; Wei, W.Q.; Weeraratne, D.; Frisse, M.E.; Misulis, K.; Rhee, K.; Zhao, J.; Snowdon, J.L. Precision Medicine, AI, and the Future of Personalized Health Care. Clin. Transl. Sci. 2021, 14, 86–93. [Google Scholar] [CrossRef] [PubMed]
- Weltz, J.; Volfovsky, A.; Laber, E.B. Reinforcement Learning Methods in Public Health. Clin. Ther. 2022, 44, 139–154. [Google Scholar] [CrossRef] [PubMed]
- Tosca, E.M.; De Carlo, A.; Ronchi, D.; Magni, P. Model-Informed Reinforcement Learning for Enabling Precision Dosing Via Adaptive Dosing. Clin. Pharmacol. Ther. 2024, 116, 619–636. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, B.; Murphy, S.A. Dynamic Treatment Regimes. Annu. Rev. Stat. Appl. 2014, 1, 447–464. [Google Scholar] [CrossRef] [PubMed]
- Chakraborty, B. Dynamic treatment regimes for managing chronic health conditions: A statistical perspective. Am. J. Public Health 2011, 101, 40–45. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.Y.; Shiranthika, C.; Wang, C.Y.; Chen, K.W.; Sumathipala, S. Reinforcement learning strategies in cancer chemotherapy treatments: A review. Comput. Methods Programs Biomed. 2023, 229, 107280. [Google Scholar] [CrossRef] [PubMed]
- Denes-Fazakas, L.; Szilagyi, L.; Kovacs, L.; De Gaetano, A.; Eigner, G. Reinforcement Learning: A Paradigm Shift in Personalized Blood Glucose Management for Diabetes. Biomedicines 2024, 12, 2143. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Qu, Y.; Wang, D.; Zhong, M.; Cheng, Y.; Zhang, M. Optimizing sepsis treatment strategies via a reinforcement learning model. Biomed. Eng. Lett. 2024, 14, 279–289. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Yu, Z.L.; Gu, Z.; Deng, X.; Li, Y. A novel multi-step reinforcement learning method for solving reward hacking. Appl. Intell. 2019, 49, 2874–2888. [Google Scholar] [CrossRef]
- Murphy, S.A.; Oslin, D.W.; Rush, A.J.; Zhu, J.; MCATS. Methodological challenges in constructing effective treatment sequences for chronic psychiatric disorders. Neuropsychopharmacology 2007, 32, 257–262. [Google Scholar] [CrossRef] [PubMed]
- DeSantis, C.E.; Kramer, J.L.; Jemal, A. The burden of rare cancers in the United States. CA Cancer J. Clin. 2017, 67, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed]
- Khetarpal, K.; Ahmed, Z.; Cianflone, A.; Islam, R.; Pineau, J. RE-EVALUATE: Reproducibility in Evaluating Reinforcement Learning Algorithms. In Proceedings of the ICML 2018 Reproducibility in Machine Learning Workshop, ICML 2018, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Shuqair, M.; Jimenez-Shahed, J.; Ghoraani, B. Reinforcement Learning-Based Adaptive Classification for Medication State Monitoring in Parkinson’s Disease. IEEE Trans. Neural Syst. Rehabil. Eng. 2024, 32, 1234–1245. [Google Scholar] [CrossRef] [PubMed]
- Tao, Y.; Wang, L.; Almirall, D. Tree-Based Reinforcement Learning for Estimating Optimal Dynamic Treatment Regimes. Ann. Appl. Stat. 2018, 12, 1914–1938. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.Q.; Zeng, D.; Laber, E.B.; Kosorok, M.R. New Statistical Learning Methods for Estimating Optimal Dynamic Treatment Regimes. J. Am. Stat. Assoc. 2015, 110, 583–598. [Google Scholar] [CrossRef] [PubMed]
- Bologheanu, R.; Kapral, L.; Laxar, D.; Maleczek, M.; Dibiasi, C.; Zeiner, S.; Agibetov, A.; Ercole, A.; Thoral, P.; Elbers, P.; et al. Development of a Reinforcement Learning Algorithm to Optimize Corticosteroid Therapy in Critically Ill Patients with Sepsis. J. Clin. Med. 2023, 12, 1513. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Li, T.; Li, D.; Lu, W. A goal-oriented reinforcement learning for optimal drug dosage control. Ann. Oper. Res. 2024, 338, 1403–1423. [Google Scholar] [CrossRef]
- Guo, H.; Li, J.; Liu, H.; He, J. Learning dynamic treatment strategies for coronary heart diseases by artificial intelligence: Real-world data-driven study. BMC Med. Inform. Decis. Mak. 2022, 22, 39. [Google Scholar] [CrossRef] [PubMed]
- Tang, M.; Wang, L.; Gorin, M.A.; Taylor, J.M.G. Step-adjusted tree-based reinforcement learning for evaluating nested dynamic treatment regimes using test-and-treat observational data. Stat. Med. 2021, 40, 6164–6177. [Google Scholar] [CrossRef] [PubMed]
- Tardini, E.; Zhang, X.; Canahuate, G.; Wentzel, A.; Mohamed, A.S.R.; Van Dijk, L.; Fuller, C.D.; Marai, G.E. Optimal Treatment Selection in Sequential Systemic and Locoregional Therapy of Oropharyngeal Squamous Carcinomas: Deep Q-Learning With a Patient-Physician Digital Twin Dyad. J. Med. Internet Res. 2022, 24, e29455. [Google Scholar] [CrossRef] [PubMed]
- Ebrahimi, S.; Lim, G.J. A reinforcement learning approach for finding optimal policy of adaptive radiation therapy considering uncertain tumor biological response. Artif. Intell. Med. 2021, 121, 102193. [Google Scholar] [CrossRef] [PubMed]
- Saghafian, S. Ambiguous Dynamic Treatment Regimes: A Reinforcement Learning Approach. Manag. Sci. 2023, 70, 5627–6482. [Google Scholar] [CrossRef]
- Nambiar, M.; Ghosh, S.; Ong, P.; Chan, Y.E.; Bee, Y.M.; Krishnaswamy, P. Deep Offline Reinforcement Learning for Real-world Treatment Optimization Applications. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining 2023, New York, NY, USA, 6–10 August 2023. [Google Scholar]
- Luckett, D.J.; Laber, E.B.; Kahkoska, A.R.; Maahs, D.M.; Mayer-Davis, E.; Kosorok, M.R. Estimating Dynamic Treatment Regimes in Mobile Health Using V-learning. J. Am. Stat. Assoc. 2020, 115, 692–706. [Google Scholar] [CrossRef] [PubMed]
- Hu, C.; Saboo, K.V.; Ali, A.H.; Juran, B.D.; Lazaridis, K.N.; Iyer, R.K. REMEDI: REinforcement learning-driven adaptive MEtabolism modeling of primary sclerosing cholangitis DIsease progression. arXiv 2023, arXiv:2310.01426. [Google Scholar]
- Abebe, S.; Poli, I.; Jones, R.D.; Slanzi, D. Learning Optimal Dynamic Treatment Regime from Observational Clinical Data through Reinforcement Learning. Mach. Learn. Knowl. Extr. 2024, 6, 1798–1817. [Google Scholar] [CrossRef]
- Sun, Z.; Dong, W.; Li, H.; Huang, Z. Adversarial reinforcement learning for dynamic treatment regimes. J. Biomed. Inform. 2023, 137, 104244. [Google Scholar] [CrossRef] [PubMed]
- Zhou, N.; Brook, R.D.; Dinov, I.D.; Wang, L. Optimal dynamic treatment regime estimation using information extraction from unstructured clinical text. Biom. J. 2022, 64, 805–817. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Zhang, W.; He, X.; Zha, H. Supervised Reinforcement Learning with Recurrent Neural Network for Dynamic Treatment Recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Cho, H.; Holloway, S.T.; Couper, D.J.; Kosorok, M.R. Multi-stage optimal dynamic treatment regimes for survival outcomes with dependent censoring. Biometrika 2023, 110, 395–410. [Google Scholar] [CrossRef] [PubMed]
- Jafar, A.; Kobayati, A.; Tsoukas, M.A.; Haidar, A. Personalized insulin dosing using reinforcement learning for high-fat meals and aerobic exercises in type 1 diabetes: A proof-of-concept trial. Nat. Commun. 2024, 15, 6585. [Google Scholar] [CrossRef] [PubMed]
- Zhu, T.; Li, K.; Herrero, P.; Georgiou, P. Basal Glucose Control in Type 1 Diabetes Using Deep Reinforcement Learning: An In Silico Validation. IEEE J. Biomed. Health Inform. 2021, 25, 1223–1232. [Google Scholar] [CrossRef] [PubMed]
- Zhu, T.; Li, K.; Kuang, L.; Herrero, P.; Georgiou, P. An Insulin Bolus Advisor for Type 1 Diabetes Using Deep Reinforcement Learning. Sensors 2020, 20, 5058. [Google Scholar] [CrossRef] [PubMed]
- Shifrin, M.; Siegelmann, H. Near-optimal insulin treatment for diabetes patients: A machine learning approach. Artif. Intell. Med. 2020, 107, 101917. [Google Scholar] [CrossRef] [PubMed]
- Oh, S.H.; Lee, S.J.; Park, J. Effective data-driven precision medicine by cluster-applied deep reinforcement learning. Knowl.-Based Syst. 2022, 256, 109877. [Google Scholar] [CrossRef]
- Yang, K.; Yu, Z.; Su, X.; Zhang, F.; He, X.; Wang, N.; Zheng, Q.; Yu, F.; Wen, T.; Zhou, X. PrescDRL: Deep reinforcement learning for herbal prescription planning in treatment of chronic diseases. Chin. Med. 2024, 19, 144. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Chu, Q.; Li, Z.; Wang, M.; Gatenby, R.; Zhang, Q. Deep reinforcement learning identifies personalized intermittent androgen deprivation therapy for prostate cancer. Brief. Bioinform. 2024, 25, bbae071. [Google Scholar] [CrossRef] [PubMed]
- Eastman, B.; Przedborski, M.; Kohandel, M. Reinforcement learning derived chemotherapeutic schedules for robust patient-specific therapy. Sci. Rep. 2021, 11, 17882. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Sui, X.; Song, W.; Xue, F.; Han, W.; Hu, Y.; Jiang, J. Reinforcement learning for individualized lung cancer screening schedules: A nested case-control study. Cancer Med. 2024, 13, e7436. [Google Scholar] [CrossRef] [PubMed]
- Niraula, D.; Sun, W.; Jin, J.; Dinov, I.D.; Cuneo, K.; Jamaluddin, J.; Matuszak, M.M.; Luo, Y.; Lawrence, T.S.; Jolly, S.; et al. A clinical decision support system for AI-assisted decision-making in response-adaptive radiotherapy (ARCliDS). Sci. Rep. 2023, 13, 5279. [Google Scholar] [CrossRef] [PubMed]
- Krakow, E.F.; Hemmer, M.; Wang, T.; Logan, B.; Arora, M.; Spellman, S.; Couriel, D.; Alousi, A.; Pidala, J.; Last, M.; et al. Tools for the Precision Medicine Era: How to Develop Highly Personalized Treatment Recommendations From Cohort and Registry Data Using Q-Learning. Am. J. Epidemiol. 2017, 186, 160–172. [Google Scholar] [CrossRef] [PubMed]
- Shirali, A.; Schubert, A.; Alaa, A. Pruning the Way to Reliable Policies: A Multi-Objective Deep Q-Learning Approach to Critical Care. IEEE J. Biomed. Health Inform. 2024, 28, 6268–6279. [Google Scholar] [CrossRef] [PubMed]
- Ma, S.; Serban, N.; Yang, S. Deep Attention Q-Network for Personalized Treatment Recommendation. In Proceedings of the 2023 IEEE International Conference on Data Mining Workshops, Shanghai, China, 1–4 December 2023; IEEE: Shanghai, China. [Google Scholar]
- Grolleau, F.; Petit, F.; Gaudry, S.; Diard, E.; Quenot, J.P.; Dreyfuss, D.; Tran, V.T.; Porcher, R. Personalizing renal replacement therapy initiation in the intensive care unit: A reinforcement learning-based strategy with external validation on the AKIKI randomized controlled trials. J. Am. Med. Inform. Assoc. 2024, 31, 1074–1083. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Tian, Y.; Zhou, T.; Zhu, Y.; Zhang, P.; Chen, J.; Li, J. Optimization of Dry Weight Assessment in Hemodialysis Patients via Reinforcement Learning. IEEE J. Biomed. Health Inform. 2022, 26, 4880–4891. [Google Scholar] [CrossRef] [PubMed]
- Prasad, N.; Mandyam, A.; Chivers, C.; Draugelis, M.; Hanson, C.W., 3rd; Engelhardt, B.E.; Laudanski, K. Guiding Efficient, Effective, and Patient-Oriented Electrolyte Replacement in Critical Care: An Artificial Intelligence Reinforcement Learning Approach. J. Pers. Med. 2022, 12, 661. [Google Scholar] [CrossRef] [PubMed]
- Weisenthal, S.J.; Thurston, S.W.; Ertefaie, A. Relative sparsity for medical decision problems. Stat. Med. 2023, 42, 3067–3092. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Wang, D.; Pan, Q.; Yan, M.; Liu, X.; Shen, Y.; Fang, L.; Cai, G.; Ning, G. Reinforcement Learning Model for Managing Noninvasive Ventilation Switching Policy. IEEE J. Biomed. Health Inform. 2023, 27, 4120–4130. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Li, R.; He, Z.; Yu, T.; Cheng, C. A value-based deep reinforcement learning model with human expertise in optimal treatment of sepsis. NPJ Digit. Med. 2023, 6, 15. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Xiao, C.; Glass, L.M.; Sun, J. Dr. Agent: Clinical predictive model via mimicked second opinions. J. Am. Med. Inform. Assoc. 2020, 27, 1084–1091. [Google Scholar] [CrossRef] [PubMed]
- Zeng, J.; Shao, J.; Lin, S.; Zhang, H.; Su, X.; Lian, X.; Zhao, Y.; Ji, X.; Zheng, Z. Optimizing the dynamic treatment regime of in-hospital warfarin anticoagulation in patients after surgical valve replacement using reinforcement learning. J. Am. Med. Inform. Assoc. 2022, 29, 1722–1732. [Google Scholar] [CrossRef] [PubMed]
- Barrett, C.D.; Suzuki, Y.; Hussein, S.; Garg, L.; Tumolo, A.; Sandhu, A.; West, J.J.; Zipse, M.; Aleong, R.; Varosy, P.; et al. Evaluation of Quantitative Decision-Making for Rhythm Management of Atrial Fibrillation Using Tabular Q-Learning. J. Am. Heart Assoc. 2023, 12, e028483. [Google Scholar] [CrossRef] [PubMed]
- Petch, J.; Nelson, W.; Wu, M.; Ghassemi, M.; Benz, A.; Fatemi, M.; Di, S.; Carnicelli, A.; Granger, C.; Giugliano, R.; et al. Optimizing warfarin dosing for patients with atrial fibrillation using machine learning. Sci. Rep. 2024, 14, 4516. [Google Scholar] [CrossRef] [PubMed]
- Zuo, L.; Du, X.; Zhao, W.; Jiang, C.; Xia, S.; He, L.; Liu, R.; Tang, R.; Bai, R.; Dong, J.; et al. Improving Anticoagulant Treatment Strategies of Atrial Fibrillation Using Reinforcement Learning. AMIA Annu. Symp. Proc. 2020, 2020, 1431–1440. [Google Scholar] [PubMed]
- Piette, J.D.; Thomas, L.; Newman, S.; Marinec, N.; Krauss, J.; Chen, J.; Wu, Z.; Bohnert, A.S.B. An Automatically Adaptive Digital Health Intervention to Decrease Opioid-Related Risk While Conserving Counselor Time: Quantitative Analysis of Treatment Decisions Based on Artificial Intelligence and Patient-Reported Risk Measures. J. Med. Internet Res. 2023, 25, e44165. [Google Scholar] [CrossRef] [PubMed]
- Kahkoska, A.R.; Lawson, M.T.; Crandell, J.; Driscoll, K.A.; Kichler, J.C.; Seid, M.; Maahs, D.M.; Kosorok, M.R.; Mayer-Davis, E.J. Assessment of a Precision Medicine Analysis of a Behavioral Counseling Strategy to Improve Adherence to Diabetes Self-management Among Youth: A Post Hoc Analysis of the FLEX Trial. JAMA Netw. Open 2019, 2, e195137. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X. Application of discrete event simulation in health care: A systematic review. BMC Health Serv. Res. 2018, 18, 687. [Google Scholar] [CrossRef] [PubMed]
- Huntera, E.; Namee, B.M.; Kelleher, J.D. A Taxonomy for Agent-Based Models in Human Infectious Disease Epidemiology. J. Artif. Soc. Soc. Simul. 2017, 20, 2. [Google Scholar] [CrossRef]
- Lötsch, J.; Kringel, D.; Ultsch, A. Explainable Artificial Intelligence (XAI) in Biomedicine: Making AI Decisions Trustworthy for Physicians and Patients. BioMedInformatics 2022, 2, 1–17. [Google Scholar] [CrossRef]
- Paranjape, K.; Schinkel, M.; Nannan Panday, R.; Car, J.; Nanayakkara, P. Introducing Artificial Intelligence Training in Medical Education. JMIR Med. Educ. 2019, 5, e16048. [Google Scholar] [CrossRef] [PubMed]
- Frommeyer, T.C.; Fursmidt, R.M.; Gilbert, M.M.; Bett, E.S. The Desire of Medical Students to Integrate Artificial Intelligence Into Medical Education: An Opinion Article. Front. Digit. Health 2022, 4, 831123. [Google Scholar] [CrossRef] [PubMed]
- Laupichler, M.C.; Aster, A.; Meyerheim, M.; Raupach, T.; Mergen, M. Medical students’ AI literacy and attitudes towards AI: A cross-sectional two-center study using pre-validated assessment instruments. BMC Med. Educ. 2024, 24, 401. [Google Scholar] [CrossRef] [PubMed]
- Al Kuwaiti, A.; Nazer, K.; Al-Reedy, A.; Al-Shehri, S.; Al-Muhanna, A.; Subbarayalu, A.V.; Al Muhanna, D.; Al-Muhanna, F.A. A Review of the Role of Artificial Intelligence in Healthcare. J. Pers. Med. 2023, 13, 951. [Google Scholar] [CrossRef] [PubMed]
- Poalelungi, D.G.; Musat, C.L.; Fulga, A.; Neagu, M.; Neagu, A.I.; Piraianu, A.I.; Fulga, I. Advancing Patient Care: How Artificial Intelligence Is Transforming Healthcare. J. Pers. Med. 2023, 13, 1214. [Google Scholar] [CrossRef] [PubMed]
- Davenport, T.; Kalakota, R. The potential for artificial intelligence in healthcare. Future Healthc. J. 2019, 6, 94–98. [Google Scholar] [CrossRef] [PubMed]
- Bett, E.S.; Frommeyer, T.C.; Reddy, T.; Johnson, J. Assessment of patient perceptions of technology and the use of machine-based learning in a clinical encounter. Intell.-Based Med. 2023, 7, 100096. [Google Scholar] [CrossRef]
- Aburass, S.; Dorgham, O.; Al Shaqsi, J.; Abu Rumman, M.; Al-Kadi, O. Vision Transformers in Medical Imaging: A Comprehensive Review of Advancements and Applications Across Multiple Diseases. J. Imaging Inform. Med. 2025; ahead of print. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories of Reinforcement Learning in Medicine | |
|---|---|
| (1) Precision Medicine (2) Dynamic Treatment Regime (3) Clinical Support Systems (4) Medical Imaging (5) Diagnostic Systems (6) Dialog Systems | (7) Personalized Rehabilitation (8) Control Systems (9) Health Management Systems (10) Drug Discovery and Development (11) Robotic-Assisted Surgery (12) Wearable Devices and Remote Patient Monitoring |
| Taxonomy of Reinforcement Learning for Clinical Applications | |
|---|---|
| Challenges | Benefits |
| Compute power Lack of data Defining rewards Understandability | Dynamic Efficient Data-driven outcomes |
| Current Applications | Directions |
| Precision medicine Dynamic treatments Clinical support Diagnostic systems Medical imaging | Intervention delivery optimization Individual treatment plans Manage complex disease over time |
| Aspect | Practical Know-How |
|---|---|
| RL Basics | RL learns through interactions by using rewards and penalties to optimize decisions. |
| Data Familiarity | Know the importance of high-quality data and how RL uses patient-specific variables for PM. |
| Integrations | RL offers real-time recommendations. Use clinical judgment to interpret and validate suggestions. |
| Patient Safety and Ethics | Prioritize patient safety by ensuring treatments guided by RL are safe. Ensure transparency in the RL application to encourage patient trust and shared decision making. |
| Limitations | Be aware of data limitations and biases in RL models, including the risk of overfitting. Critically evaluate model performance across diverse and heterogeneous patient populations. |
| Collaborations | Work with administrators, regulators, and data scientists to align the RL models with clinical priorities, ensuring patient safety, health outcomes, ethical considerations, and regulatory compliance. |
| Training and Education | Engage in continuous education to learn AI/ML concepts and develop critical evaluation skills to assess RL models in clinical practice. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frommeyer, T.C.; Gilbert, M.M.; Fursmidt, R.M.; Park, Y.; Khouzam, J.P.; Brittain, G.V.; Frommeyer, D.P.; Bett, E.S.; Bihl, T.J. Reinforcement Learning and Its Clinical Applications Within Healthcare: A Systematic Review of Precision Medicine and Dynamic Treatment Regimes. Healthcare 2025, 13, 1752. https://doi.org/10.3390/healthcare13141752
Frommeyer TC, Gilbert MM, Fursmidt RM, Park Y, Khouzam JP, Brittain GV, Frommeyer DP, Bett ES, Bihl TJ. Reinforcement Learning and Its Clinical Applications Within Healthcare: A Systematic Review of Precision Medicine and Dynamic Treatment Regimes. Healthcare. 2025; 13(14):1752. https://doi.org/10.3390/healthcare13141752
Chicago/Turabian StyleFrommeyer, Timothy C., Michael M. Gilbert, Reid M. Fursmidt, Youngjun Park, John Paul Khouzam, Garrett V. Brittain, Daniel P. Frommeyer, Ean S. Bett, and Trevor J. Bihl. 2025. "Reinforcement Learning and Its Clinical Applications Within Healthcare: A Systematic Review of Precision Medicine and Dynamic Treatment Regimes" Healthcare 13, no. 14: 1752. https://doi.org/10.3390/healthcare13141752
APA StyleFrommeyer, T. C., Gilbert, M. M., Fursmidt, R. M., Park, Y., Khouzam, J. P., Brittain, G. V., Frommeyer, D. P., Bett, E. S., & Bihl, T. J. (2025). Reinforcement Learning and Its Clinical Applications Within Healthcare: A Systematic Review of Precision Medicine and Dynamic Treatment Regimes. Healthcare, 13(14), 1752. https://doi.org/10.3390/healthcare13141752