
Sentiments about Mental Health on Twitter—Before and during the COVID-19 Pandemic



Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Data Collection
3.2. Sentiment Libraries
3.3. Topic Modeling with Latent Dirichlet Allocation
3.4. Classification
3.4.1. Based on TF-IDF
3.4.2. Based on Sentiment Libraries
3.4.3. Based on BERT
4. Results
4.1. Data Statistics
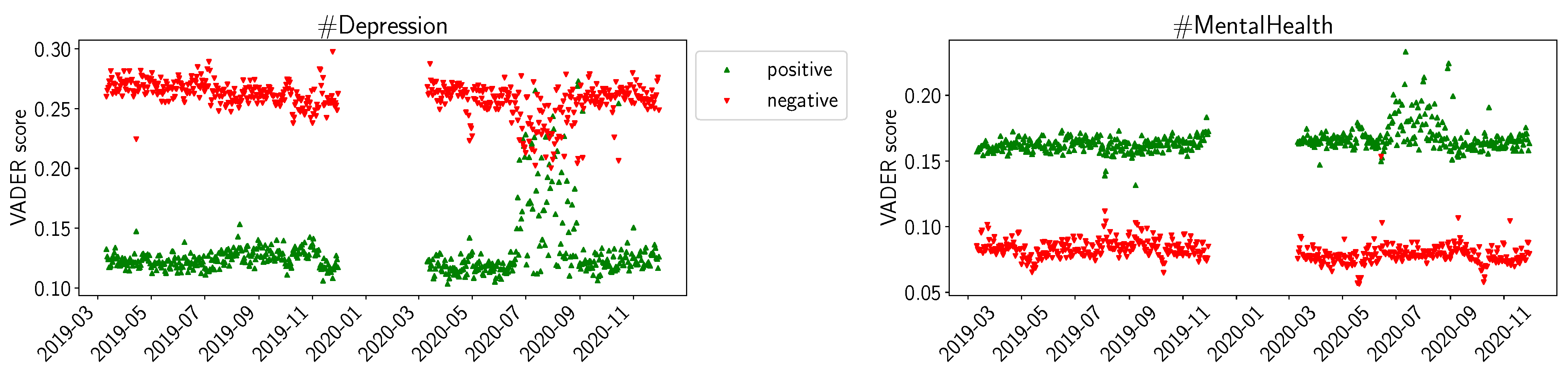
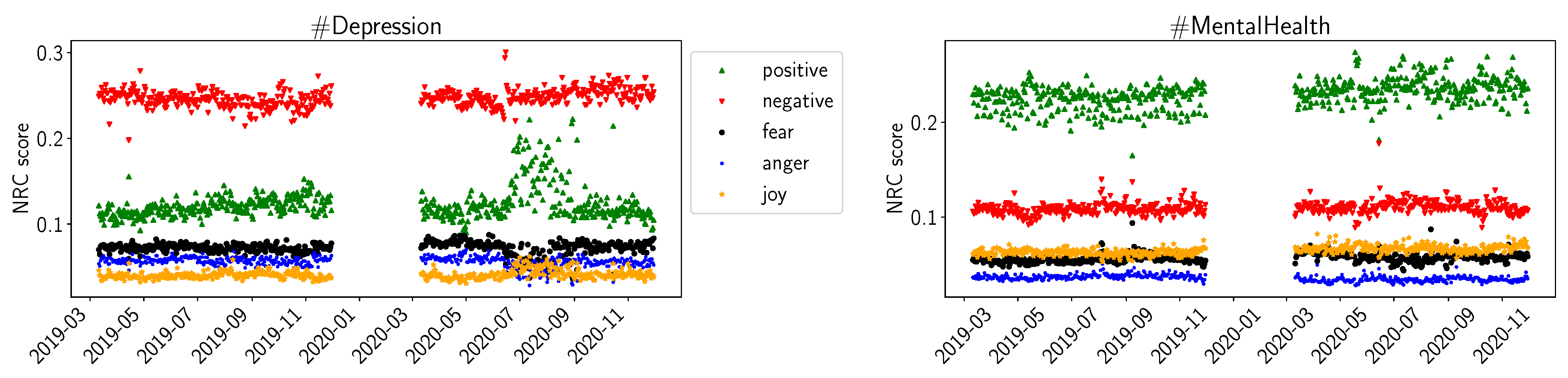
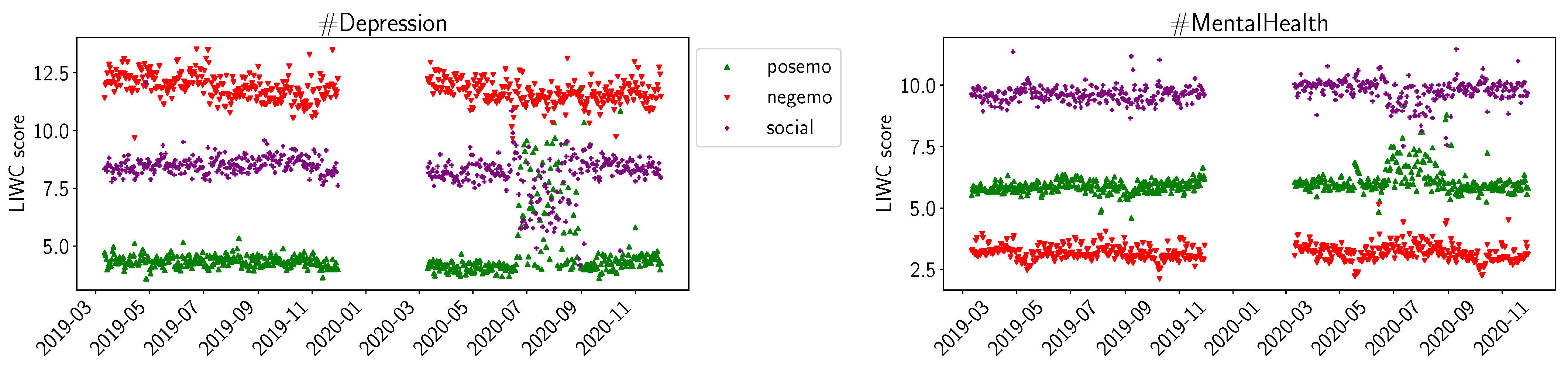
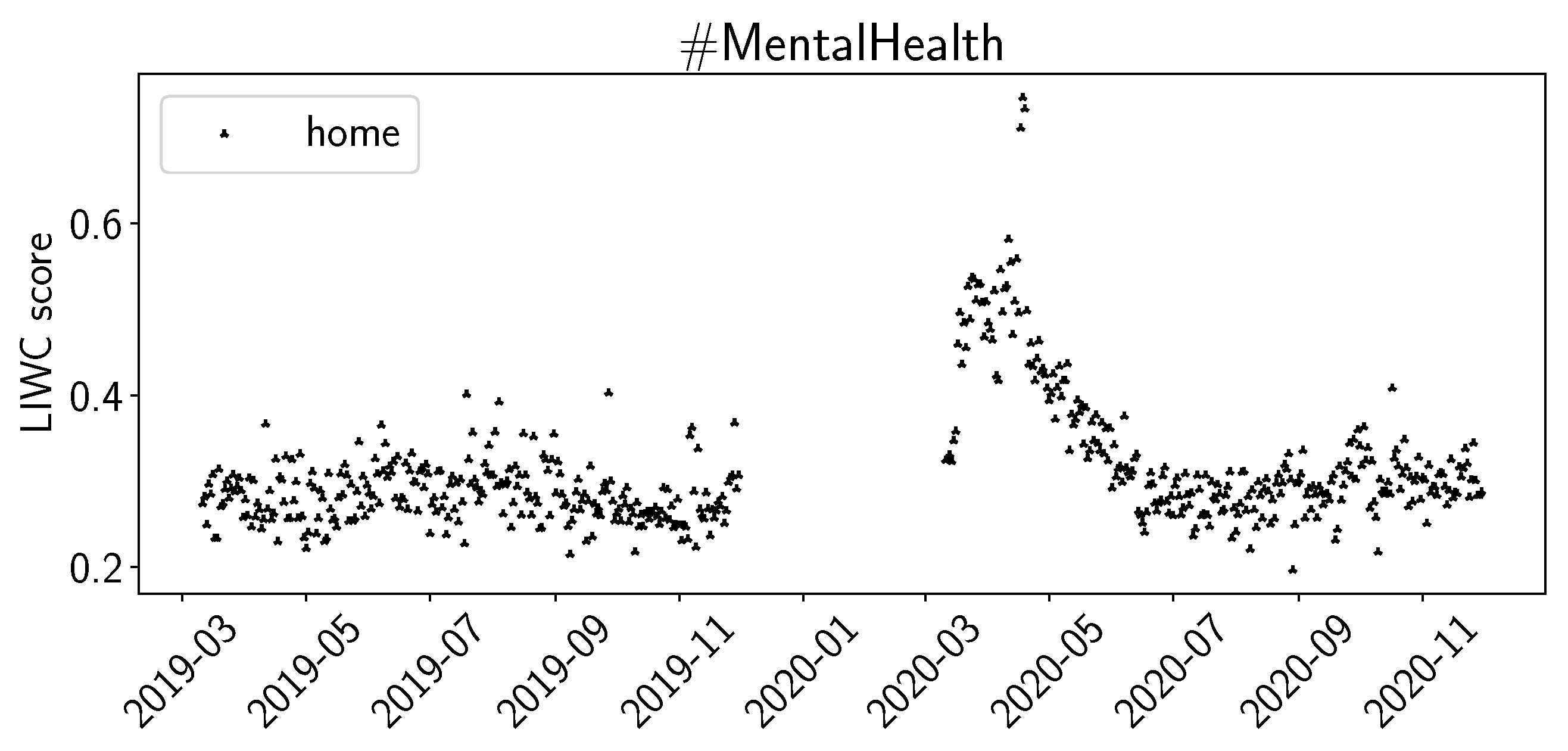
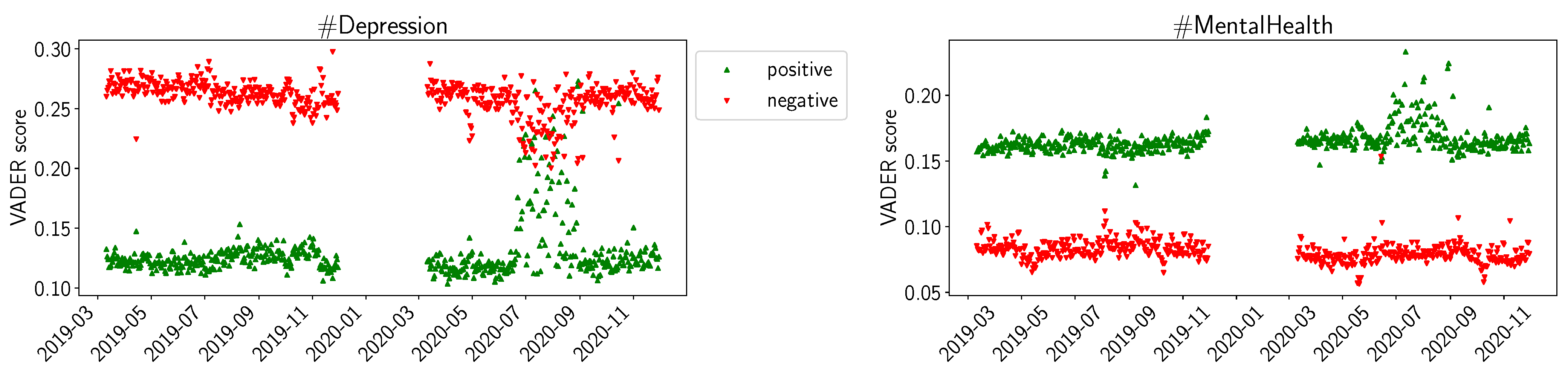
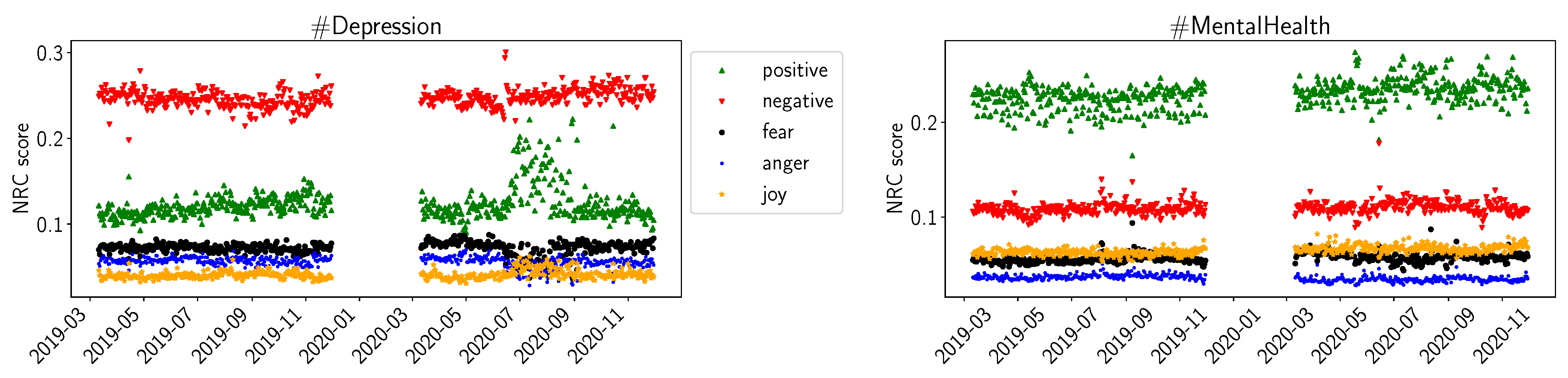
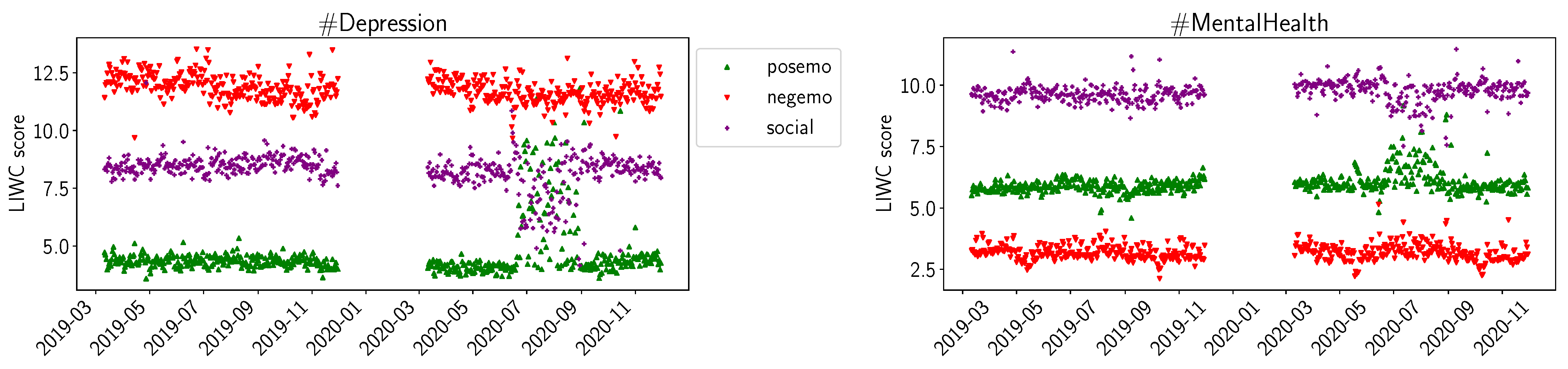
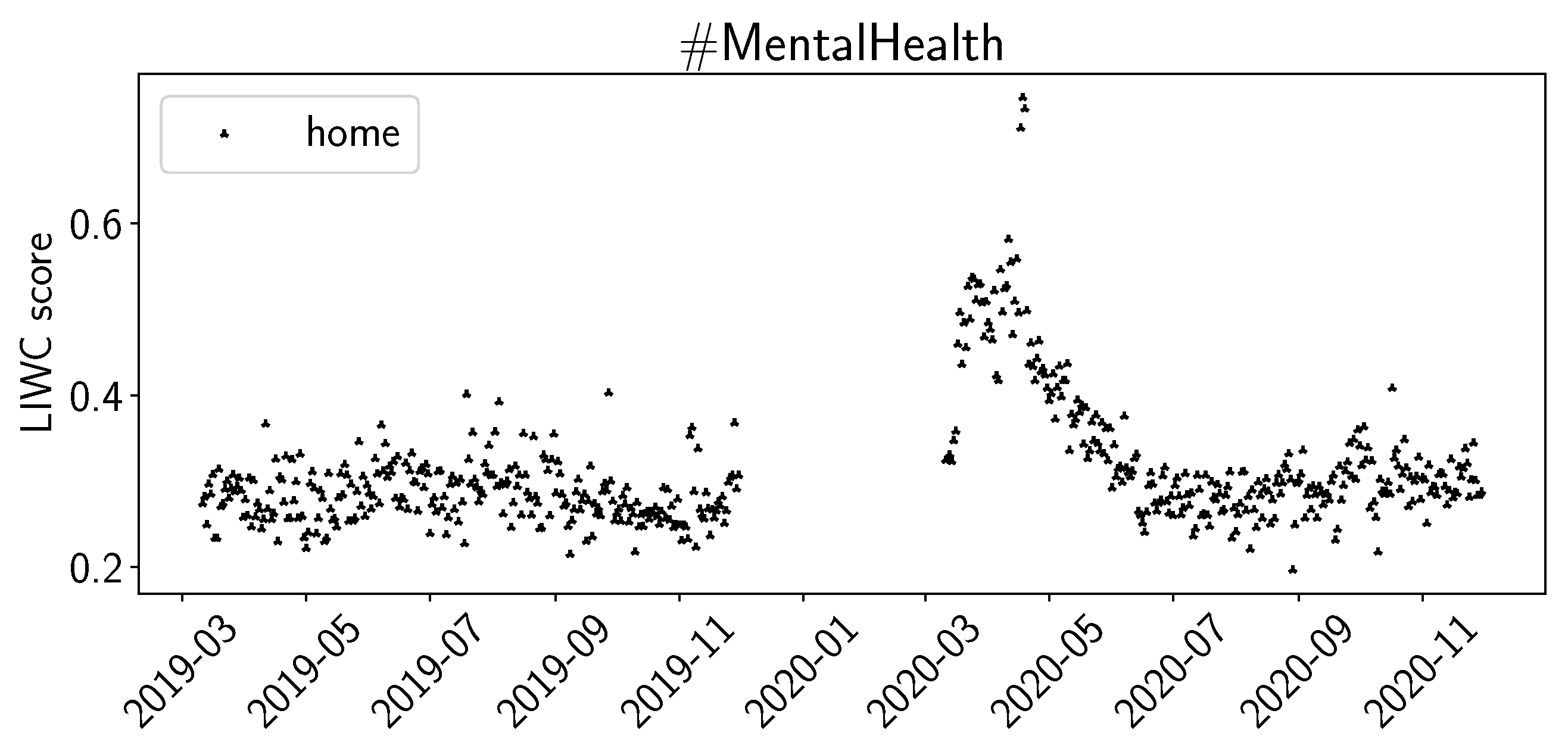
4.2. Sentiment Analysis Results
4.3. Topic Modeling Results
4.4. Classification Results
5. Discussion
Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Smith, K. Mental Health: A World of Depression. Nature 2014, 515, 180–181. [Google Scholar] [CrossRef]
- Zhang, Y.; Ma, Z.F. Impact of the COVID-19 Pandemic on Mental Health and Quality of Life among Local Residents in Liaoning Province, China: A Cross-Sectional Study. Int. J. Environ. Res. Public Health 2020, 17, 2381. [Google Scholar] [CrossRef]
- Wang, C.; Pan, R.; Wan, X.; Tan, Y.; Xu, L.; Ho, C.S.; Ho, R.C. Immediate Psychological Responses and Associated Factors during the Initial Stage of the 2019 Coronavirus Disease (COVID-19) Epidemic among the General Population in China. Int. J. Environ. Res. Public Health 2020, 17, 1729. [Google Scholar] [CrossRef]
- Gualano, M.R.; Lo Moro, G.; Voglino, G.; Bert, F.; Siliquini, R. Effects of COVID-19 Lockdown on Mental Health and Sleep Disturbances in Italy. Int. J. Environ. Res. Public Health 2020, 17, 4779. [Google Scholar] [CrossRef]
- Xiong, J.; Lipsitz, O.; Nasri, F.; Lui, L.M.W.; Gill, H.; Phan, L.; Chen-Li, D.; Iacobucci, M.; Ho, R.; Majeed, A.; et al. Impact of COVID-19 Pandemic on Mental Health in the General Population: A Systematic Review. J. Affect. Disord. 2020, 277, 55–64. [Google Scholar] [CrossRef]
- Gloster, A.T.; Lamnisos, D.; Lubenko, J.; Presti, G.; Squatrito, V.; Constantinou, M.; Nicolaou, C.; Papacostas, S.; Aydın, G.; Chong, Y.Y.; et al. Impact of COVID-19 Pandemic on Mental Health: An International Study. PLoS ONE 2020, 15, e0244809. [Google Scholar] [CrossRef]
- Limcaoco, R.S.G.; Mateos, E.M.; Fernández, J.M.; Roncero, C. Anxiety, Worry and Perceived Stress in the World Due to the COVID-19 Pandemic, March 2020. Preliminary Results. medRxiv 2020. [Google Scholar] [CrossRef]
- Pierce, M.; McManus, S.; Hope, H.; Hotopf, M.; Ford, T.; Hatch, S.L.; John, A.; Kontopantelis, E.; Webb, R.T.; Wessely, S.; et al. Mental Health Responses to the COVID-19 Pandemic: A Latent Class Trajectory Analysis Using Longitudinal UK Data. Lancet Psychiatry 2021, 8, 610–619. [Google Scholar] [CrossRef]
- Pieh, C.; Budimir, S.; Delgadillo, J.; Barkham, M.; Fontaine, J.R.J.; Probst, T. Mental Health during COVID-19 Lockdown in the United Kingdom. Psychosom. Med. 2021, 83, 328–337. [Google Scholar] [CrossRef]
- Dale, R.; Budimir, S.; Probst, T.; Stippl, P.; Pieh, C. Mental Health during the COVID-19 Lockdown over the Christmas Period in Austria and the Effects of Sociodemographic and Lifestyle Factors. Int. J. Environ. Res. Public Health 2021, 18, 3679. [Google Scholar] [CrossRef]
- Budimir, S.; Pieh, C.; Dale, R.; Probst, T. Severe Mental Health Symptoms during COVID-19: A Comparison of the United Kingdom and Austria. Healthcare 2021, 9, 191. [Google Scholar] [CrossRef]
- Beierle, F.; Schobel, J.; Vogel, C.; Allgaier, J.; Mulansky, L.; Haug, F.; Haug, J.; Schlee, W.; Holfelder, M.; Stach, M.; et al. Corona Health—A Study- and Sensor-Based Mobile App Platform Exploring Aspects of the COVID-19 Pandemic. Int. J. Environ. Res. Public Health 2021, 18, 7395. [Google Scholar] [CrossRef]
- Wetzel, B.; Pryss, R.; Baumeister, H.; Edler, J.S.; Gonçalves, A.S.O.; Cohrdes, C. “How Come You Don’t Call Me?” Smartphone Communication App Usage as an Indicator of Loneliness and Social Well-Being across the Adult Lifespan during the COVID-19 Pandemic. Int. J. Environ. Res. Public Health 2021, 18, 6212. [Google Scholar] [CrossRef]
- Beierle, F.; Allgaier, J.; Stupp, C.; Keil, T.; Schlee, W.; Schobel, J.; Vogel, C.; Haug, F.; Haug, J.; Holfelder, M.; et al. Self-Assessment of Having COVID-19 with the Corona Check mHealth App. IEEE J. Biomed. Health Inform. 2023, 27, 2794–2805. [Google Scholar] [CrossRef]
- Gianfredi, V.; Provenzano, S.; Santangelo, O.E. What Can Internet Users’ Behaviours Reveal about the Mental Health Impacts of the COVID-19 Pandemic? A Systematic Review. Public Health 2021, 198, 44–52. [Google Scholar] [CrossRef]
- Boon-Itt, S.; Skunkan, Y. Public Perception of the COVID-19 Pandemic on Twitter: Sentiment Analysis and Topic Modeling Study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef]
- Lwin, M.O.; Lu, J.; Sheldenkar, A.; Schulz, P.J.; Shin, W.; Gupta, R.; Yang, Y. Global Sentiments Surrounding the COVID-19 Pandemic on Twitter: Analysis of Twitter Trends. JMIR Public Health Surveill. 2020, 6, e19447. [Google Scholar] [CrossRef]
- Mathur, A.; Kubde, P.; Vaidya, S. Emotional Analysis Using Twitter Data during Pandemic Situation: COVID-19. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 845–848. [Google Scholar] [CrossRef]
- Manguri, K.H.; Ramadhan, R.N.; Amin, P.R.M. Twitter Sentiment Analysis on Worldwide COVID-19 Outbreaks. Kurd. J. Appl. Res. 2020, 5, 54–65. [Google Scholar] [CrossRef]
- Xue, J.; Chen, J.; Hu, R.; Chen, C.; Zheng, C.; Su, Y.; Zhu, T. Twitter Discussions and Emotions about the COVID-19 Pandemic: Machine Learning Approach. J. Med. Internet Res. 2020, 22, e20550. [Google Scholar] [CrossRef]
- Valdez, D.; ten Thij, M.; Bathina, K.; Rutter, L.A.; Bollen, J. Social Media Insights Into US Mental Health during the COVID-19 Pandemic: Longitudinal Analysis of Twitter Data. J. Med. Internet Res. 2020, 22, e21418. [Google Scholar] [CrossRef]
- Sarirete, A. Sentiment Analysis Tracking of COVID-19 Vaccine through Tweets. J. Ambient. Intell. Humaniz. Comput. 2022. [Google Scholar] [CrossRef]
- Cohrdes, C.; Yenikent, S.; Wu, J.; Ghanem, B.; Franco-Salvador, M.; Vogelgesang, F. Indications of Depressive Symptoms during the COVID-19 Pandemic in Germany: Comparison of National Survey and Twitter Data. JMIR Ment. Health 2021, 8, e27140. [Google Scholar] [CrossRef]
- Koh, J.X.; Liew, T.M. How Loneliness Is Talked about in Social Media during COVID-19 Pandemic: Text Mining of 4,492 Twitter Feeds. J. Psychiatr. Res. 2022, 145, 317–324. [Google Scholar] [CrossRef]
- Zhang, S.; Sun, L.; Zhang, D.; Li, P.; Liu, Y.; Anand, A.; Xie, Z.; Li, D. The COVID-19 Pandemic and Mental Health Concerns on Twitter in the United States. Health Data Sci. 2022, 2022, 9758408. [Google Scholar] [CrossRef]
- Zhang, Y.; Lyu, H.; Liu, Y.; Zhang, X.; Wang, Y.; Luo, J. Monitoring Depression Trends on Twitter during the COVID-19 Pandemic: Observational Study. JMIR Infodemiol. 2021, 1, e26769. [Google Scholar] [CrossRef]
- Guntuku, S.C.; Sherman, G.; Stokes, D.C.; Agarwal, A.K.; Seltzer, E.; Merchant, R.M.; Ungar, L.H. Tracking Mental Health and Symptom Mentions on Twitter during COVID-19. J. Gen. Intern. Med. 2020, 35, 2798–2800. [Google Scholar] [CrossRef]
- El-Gayar, O.; Wahbeh, A.; Nasralah, T.; Elnoshokaty, A.; Al-Ramahi, M. Mental Health and the COVID-19 Pandemic: Analysis of Twitter Discourse. In Proceedings of the AMCIS 2021 Proceedings, Online, 9–13 August 2021. [Google Scholar]
- Saha, K.; Torous, J.; Caine, E.D.; Choudhury, M.D. Psychosocial Effects of the COVID-19 Pandemic: Large-scale Quasi-Experimental Study on Social Media. J. Med. Internet Res. 2020, 22, e22600. [Google Scholar] [CrossRef]
- Ng, Q.X.; Lee, D.Y.X.; Yau, C.E.; Lim, Y.L.; Ng, C.X.; Liew, T.M. Examining the Public Messaging on ‘Loneliness’ over Social Media: An Unsupervised Machine Learning Analysis of Twitter Posts over the Past Decade. Healthcare 2023, 11, 1485. [Google Scholar] [CrossRef]
- Pennebaker, J.W.; Francis, M.E.; Booth, R.J. Linguistic Inquiry and Word Count: LIWC 2001. Mahway Lawrence Erlbaum Assoc. 2001, 71, 2001. [Google Scholar]
- Pennebaker, J.W.; Booth, R.J.; Boyd, R.L.; Francis, M.E. Linguistic Inquiry and Word Count: LIWC2015; Pennebaker Conglomerates: Austin, TX, USA, 2015. [Google Scholar]
- Mohammad, S.M.; Turney, P.D. Emotions Evoked by Common Words and Phrases: Using Mechanical Turk to Create an Emotion Lexicon. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text (CAAGET’10), Los Angeles, CA, USA, 5 June 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 26–34. [Google Scholar]
- Mohammad, S.M.; Turney, P.D. Crowdsourcing a Word–Emotion Association Lexicon. Comput. Intell. 2013, 29, 436–465. [Google Scholar] [CrossRef]
- Hutto, C.J.; Gilbert, E. VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; AAAI: Washington, DC, USA, 2014; pp. 216–225. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Ramos, J. Using TF-IDF to Determine Word Relevance in Document Queries. In Proceedings of the First Instructional Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003; pp. 133–142. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Arpaci, I.; Alshehabi, S.; Mahariq, I.; Topcu, A.E. An Evolutionary Clustering Analysis of Social Media Content and Global Infection Rates during the COVID-19 Pandemic. J. Inf. Knowl. Manag. 2021, 20, 2150038. [Google Scholar] [CrossRef]
- Arpaci, I.; Alshehabi, S.; Al-Emran, M.; Khasawneh, M.; Mahariq, I.; Abdeljawad, T.; Hassanien, A. Analysis of Twitter Data Using Evolutionary Clustering during the COVID-19 Pandemic. Comput. Mater. Contin. 2020, 65, 193–204. [Google Scholar] [CrossRef]
- Jetten, J.; Haslam, S.A.; Reicher, S.; Cruwys, T. (Eds.) Together Apart: The Psychology of COVID-19, 1st ed.; SAGE Publications: Thousand Oaks, CA, USA, 2020. [Google Scholar]
- Wang, X.; Chen, X.; Tang, M.; Yang, T.; Wang, Z. Aspect-Level Sentiment Analysis Based on Position Features Using Multilevel Interactive Bidirectional GRU and Attention Mechanism. Discret. Dyn. Nat. Soc. 2020, 2020, e5824873. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Hashtag | Year | No. of Tweets | No. of Unique Users |
|---|---|---|---|---|
| D19 | #Depression | 2019 | 279,900 | 74,964 |
| D20 | #Depression | 2020 | 276,830 | 78,888 |
| M19 | #MentalHealth | 2019 | 995,770 | 219,119 |
| M20 | #MentalHealth | 2020 | 1,304,112 | 302,496 |
| M20S | #MentalHealth | 2020 | 995,770 | 254,558 |
| Hashtag | Count | |
|---|---|---|
| #anxiety | 96,888 | (35%) |
| #mentalhealth | 75,433 | (27%) |
| #mentalhealthawareness | 16,347 | (6%) |
| #ptsd | 15,244 | (5%) |
| #stress | 13,783 | (5%) |
| #addiction | 13,583 | (5%) |
| #mentalillness | 13,391 | (5%) |
| #mindfulness | 13,269 | (5%) |
| #love | 12,720 | (5%) |
| #suicide | 12,213 | (4%) |
| #onlinetherapy | 10,477 | (4%) |
| #health | 10,180 | (4%) |
| #jesus | 10,129 | (4%) |
| Hashtag | Count | |
|---|---|---|
| #anxiety | 94,021 | (34%) |
| #mentalhealth | 93,272 | (34%) |
| #life | 19,595 | (7%) |
| #mentalhealthawareness | 17,607 | (6%) |
| #motivation | 16,328 | (6%) |
| #meditation | 15,233 | (6%) |
| #stress | 15,201 | (5%) |
| #lockdown | 15,013 | (5%) |
| #ptsd | 14,871 | (5%) |
| #COVID19 | 14,221 | (5%) |
| #quarantine | 13,662 | (5%) |
| #stressrelief | 13,155 | (5%) |
| #socialdistancing | 13,045 | (5%) |
| Hashtag | Count | |
|---|---|---|
| #depression | 74,901 | (8%) |
| #anxiety | 65,608 | (7%) |
| #mentalhealthawareness | 59,298 | (6%) |
| #health | 42,095 | (4%) |
| #wellbeing | 38,971 | (4%) |
| #mentalillness | 33,477 | (3%) |
| #psychology | 32,050 | (3%) |
| #mentalhealthmatters | 30,496 | (3%) |
| #selfcare | 30,196 | (3%) |
| #mindfulness | 29,012 | (3%) |
| #wellness | 28,768 | (3%) |
| #love | 19,411 | (2%) |
| #therapy | 18,919 | (2%) |
| Hashtag | Count | |
|---|---|---|
| #COVID19 | 112,053 | (9%) |
| #depression | 97,113 | (7%) |
| #anxiety | 84,284 | (6%) |
| #mentalhealthawareness | 81,838 | (6%) |
| #wellbeing | 68,717 | (5%) |
| #mentalhealthmatters | 62,132 | (5%) |
| #selfcare | 54,558 | (4%) |
| #health | 46,274 | (4%) |
| #mindfulness | 45,045 | (3%) |
| #coronavirus | 43,845 | (3%) |
| #wellness | 37,226 | (3%) |
| #love | 35,380 | (3%) |
| #motivation | 32,465 | (2%) |
| Dataset | Percentage | Keywords | Theme(s) |
|---|---|---|---|
| D19 | 44.0% | mentalhealth, love, anxiety, feel, day, life, today, just, make, prayer, help | awareness |
| 34.7% | anxiety, therapy, mindfulness, online, skype, &, thank, mentalhealth, help, visit, learn | support | |
| 21.3% | anxiety, health, mental, mentalhealth, stress, &, help, people, symptom, treatment, suicide | symptoms | |
| D20 | 50.3% | mentalhealth, anxiety, feel, help, just, day, love, &, know, life, time | awareness |
| 31.4% | anxiety, therapy, mindfulness, online, stress, skype, learn, treatment, addiction, visit, & | support | |
| 18.3% | life, anxiety, mentalhealth, COVID, lockdown, motivation, job, health, trend, quarantine, joy | symptoms, COVID, social distancing | |
| M19 | 41.1% | health, mental, &, support, help, work, child, people, need, issue, service | awareness |
| 33.8% | anxiety, depression, life, stress, psychology, therapy, love, mindfulness, blog, new, self | support | |
| 25.1% | thank, make, late, day, help, just, time, feel, good, health, talk | gratitude | |
| M20 | 38.1% | day, love, life, today, stay, time, mindfulness, good, thank, late, lockdown | gratitude, social distancing |
| 33.1% | anxiety, depression, feel, help, stress, people, know, time, COVID, need, & | awareness, symptoms, COVID | |
| 28.8% | health, mental, support, &, COVID, help, need, time, work, people, care | support, COVID |
| Datasets | Classifier | Accuracy | ROC AUC | Precision | Recall | F1 | MCC |
|---|---|---|---|---|---|---|---|
| D19, D20 | TF-IDF LGBM | 0.745 | 0.845 | 0.756 | 0.719 | 0.737 | 0.490 |
| D19, D20 | SenLib LGBM | 0.721 | 0.821 | 0.726 | 0.706 | 0.716 | 0.442 |
| D19, D20 | BERT | 0.794 | 0.886 | 0.793 | 0.793 | 0.793 | 0.589 |
| M19, M20S | TF-IDF LGBM | 0.736 | 0.831 | 0.758 | 0.693 | 0.724 | 0.473 |
| M19, M20S | SenLib LGBM | 0.683 | 0.772 | 0.684 | 0.681 | 0.683 | 0.367 |
| M19, M20S | BERT | 0.809 | 0.902 | 0.826 | 0.784 | 0.804 | 0.619 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Beierle, F.; Pryss, R.; Aizawa, A. Sentiments about Mental Health on Twitter—Before and during the COVID-19 Pandemic. Healthcare 2023, 11, 2893. https://doi.org/10.3390/healthcare11212893
Beierle F, Pryss R, Aizawa A. Sentiments about Mental Health on Twitter—Before and during the COVID-19 Pandemic. Healthcare. 2023; 11(21):2893. https://doi.org/10.3390/healthcare11212893
Chicago/Turabian StyleBeierle, Felix, Rüdiger Pryss, and Akiko Aizawa. 2023. "Sentiments about Mental Health on Twitter—Before and during the COVID-19 Pandemic" Healthcare 11, no. 21: 2893. https://doi.org/10.3390/healthcare11212893
APA StyleBeierle, F., Pryss, R., & Aizawa, A. (2023). Sentiments about Mental Health on Twitter—Before and during the COVID-19 Pandemic. Healthcare, 11(21), 2893. https://doi.org/10.3390/healthcare11212893