
An International Non-Inferiority Study for the Benchmarking of AI for Routine Radiology Cases: Chest X-ray, Fluorography and Mammography

 , ,
, ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Reference Dataset
- Pneumothorax;
- Atelectasis;
- Nodules or mass;
- Infiltrate or consolidation;
- Miliary pattern, or dissemination;
- Cavity;
- Pulmonary calcification;
- Pleural effusion;
- Fracture, or rupture of the bone cortical layer.
2.2. AI Models
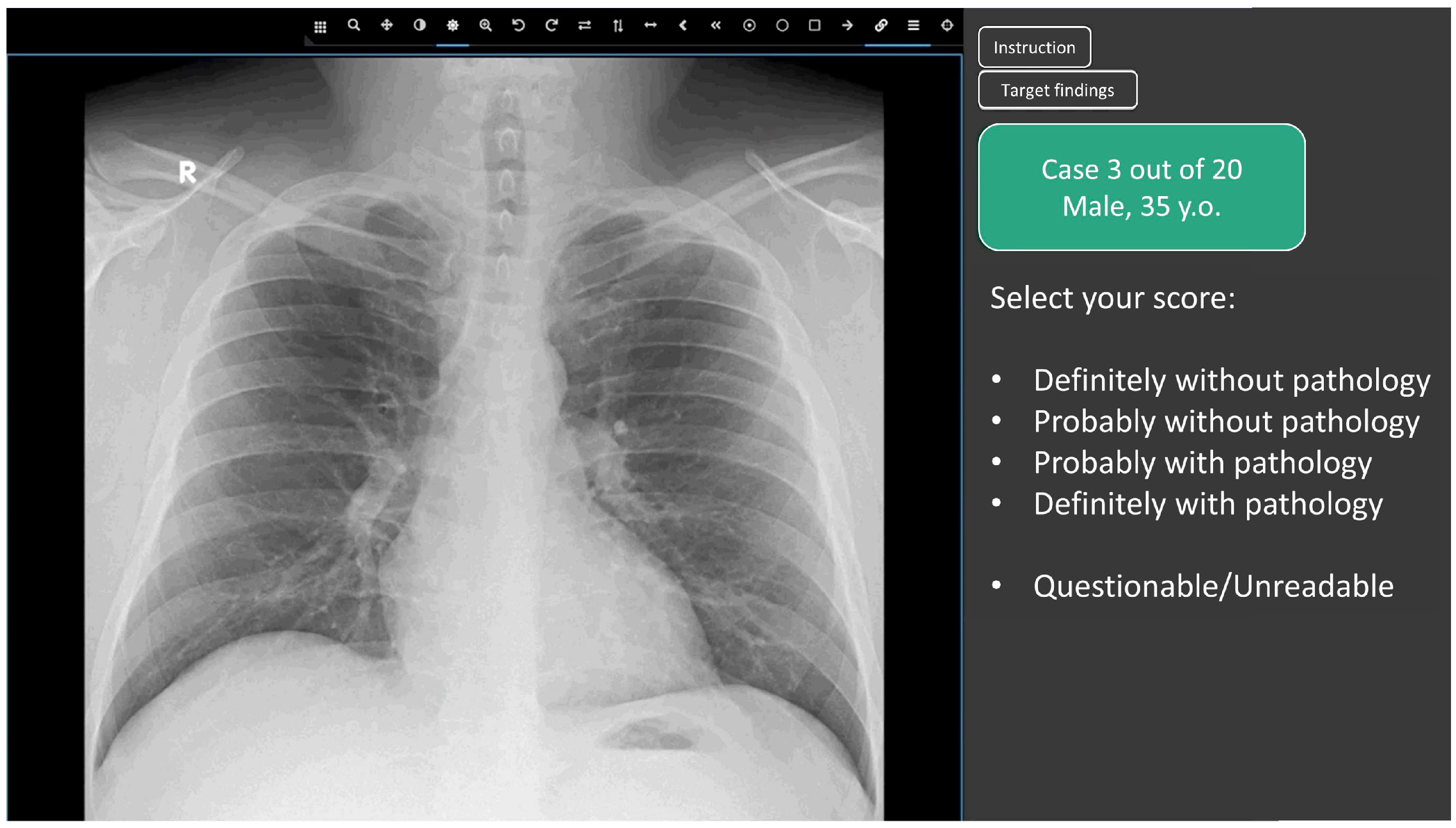
2.3. Web Platform for Conducting the Reader Study
- Definitely without pathology (probability of pathology = 0.0);
- Probably without pathology (probability of pathology = 0.25);
- Undefined (questionable/unreadable) (probability of pathology = 0.5)
- Probably with pathology (probability of pathology = 0.75);
- Definitely with pathology (probability of pathology = 1.0);
2.4. Participating Radiologists
2.5. Score Analysis: Determination of the Consensus Score for Radiologists and AI Models
2.6. Statistical Analysis
3. Results
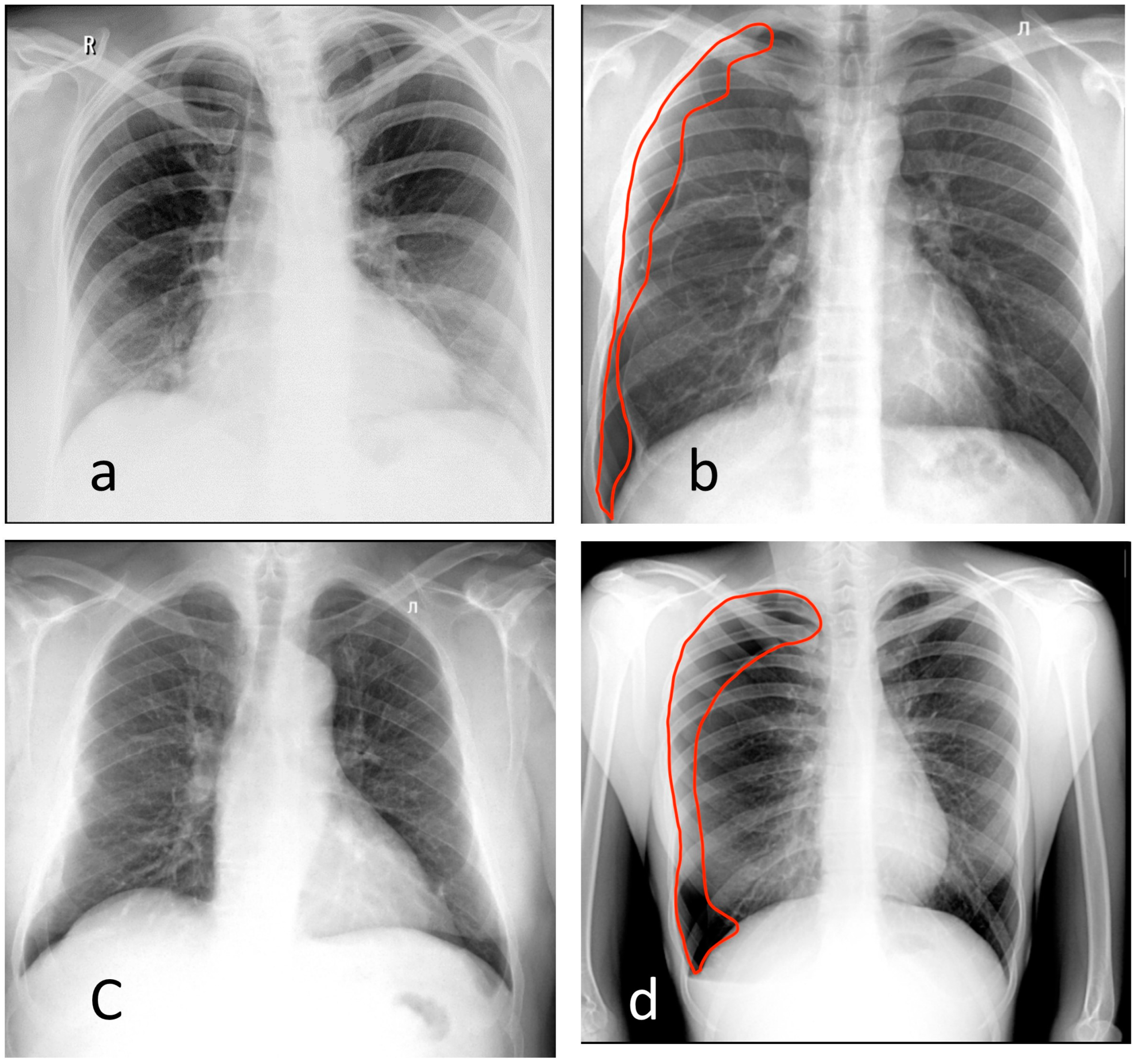
3.1. Chest X-ray
3.2. Chest Digital Fluorography (FLG)
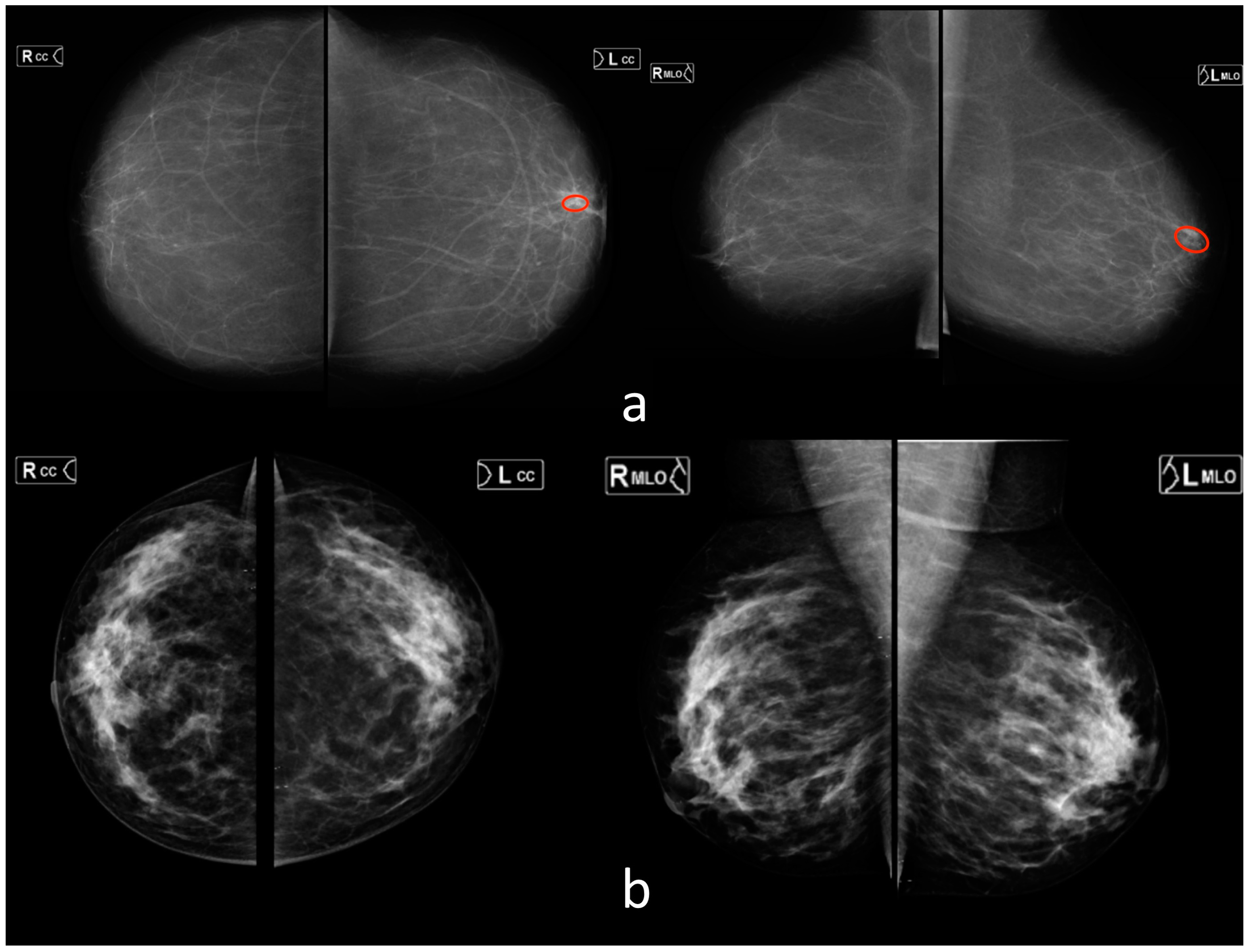
3.3. Mammography (MMG)
3.4. Overall
4. Discussion
5. Conclusions
6. Limitation
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yu, K.-H.; Lee, T.-L.M.; Yen, M.-H.; Kou, S.C.; Rosen, B.; Chiang, J.-H.; Kohane, I.S. Reproducible Machine Learning Methods for Lung Cancer Detection Using Computed Tomography Images: Algorithm Development and Validation. J. Med. Internet Res. 2020, 22, e16709. [Google Scholar] [CrossRef]
- Herron, J.; Reynolds, J.H. Trends in the on-call workload of radiologists. Clin. Radiol. 2006, 61, 91–96. [Google Scholar] [CrossRef]
- Seibert, J.A. Projection X-ray Imaging: Radiography, Mammography, Fluoroscopy. Health Phys. 2019, 116, 148–156. [Google Scholar] [CrossRef]
- Schaffter, T.; Buist, D.S.M.; Lee, C.I.; Nikulin, Y.; Ribli, D.; Guan, Y.; Lotter, W.; Jie, Z.; Du, H.; Wang, S.; et al. Evaluation of Combined Artificial Intelligence and Radiologist Assessment to Interpret Screening Mammograms. JAMA Netw. Open 2020, 3, e200265. [Google Scholar] [CrossRef]
- Screening Programmes: A Short Guide. Increase Effectiveness, Maximize Benefits and Minimize Harm; WHO Regional Office for Europe: Copenhagen, Denmark, 2020. Available online: https://apps.who.int/iris/bitstream/handle/10665/330829/9789289054782-eng.pdf (accessed on 22 July 2021).
- Use of Chest Imaging in COVID-19: A Rapid Advice Guide; World Health Organization: Geneva, Switzerland, 2020. Available online: https://img-cdn.tinkoffjournal.ru/-/who-2019-ncov-clinical-radiology_imaging-20201-eng-1.pdf (accessed on 1 June 2023).
- Adams, S.J.; Henderson, R.D.E.; Yi, X.; Babyn, P. Artificial Intelligence Solutions for Analysis of X-ray Images. Can. Assoc. Radiol. J. 2021, 72, 60–72. [Google Scholar] [CrossRef]
- Alexander, A.; Jiang, A.; Ferreira, C.; Zurkiya, D. An Intelligent Future for Medical Imaging: A Market Outlook on Artificial Intelligence for Medical Imaging. J. Am. Coll. Radiol. 2020, 17, 165–170. [Google Scholar] [CrossRef]
- Raya-Povedano, J.L.; Romero-Martín, S.; Elías-Cabot, E.; Gubern-Mérida, A.; Rodríguez-Ruiz, A.; Álvarez-Benito, M. AI-based Strategies to Reduce Workload in Breast Cancer Screening with Mammography and Tomosynthesis: A Retrospective Evaluation. Radiology 2021, 300, 57–65. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed]
- Tadavarthi, Y.; Vey, B.; Krupinski, E.; Prater, A.; Gichoya, J.; Safdar, N.; Trivedi, H. The State of Radiology AI: Considerations for Purchase Decisions and Current Market Offerings. Radiol. Artif. Intell. 2020, 2, e200004. [Google Scholar] [CrossRef]
- Omoumi, P.; Ducarouge, A.; Tournier, A.; Harvey, H.; Kahn, C.E.; Verchère, F.L.-D.; Dos Santos, D.P.; Kober, T.; Richiardi, J. To buy or not to buy—Evaluating commercial AI solutions in radiology (the ECLAIR guidelines). Eur. Radiol. 2021, 31, 3786–3796. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez-Ruiz, A.; Lång, K.; Gubern-Merida, A.; Broeders, M.; Gennaro, G.; Clauser, P.; Helbich, T.H.; Chevalier, M.; Tan, T.; Mertelmeier, T.; et al. Stand-Alone Artificial Intelligence for Breast Cancer Detection in Mammography: Comparison With 101 Radiologists. JNCI J. Natl. Cancer Inst. 2019, 111, 916–922. [Google Scholar] [CrossRef] [PubMed]
- McKinney, S.M.; Sieniek, M.; Godbole, V.; Godwin, J.; Antropova, N.; Ashrafian, H.; Back, T.; Chesus, M.; Corrado, G.S.; Darzi, A.; et al. International evaluation of an AI system for breast cancer screening. Nature 2020, 577, 89–94. [Google Scholar] [CrossRef]
- WHO Issues First Global Report on Artificial Intelligence (AI) in Health and Six Guiding Principles for Its Design and Use. 2021. Available online: https://www.who.int/news/item/28-06-2021-who-issues-first-global-report-on-ai-in-health-and-six-guiding-principles-for-its-design-and-use (accessed on 1 June 2023).
- Elmore, J.G.; Jackson, S.L.; Abraham, L.; Miglioretti, D.L.; Carney, P.A.; Geller, B.M.; Yankaskas, B.C.; Kerlikowske, K.; Onega, T.; Rosenberg, R.D.; et al. Variability in interpretive performance at screening mammography and radiologists’ characteristics associated with accuracy. Radiology 2009, 253, 641–651. [Google Scholar] [CrossRef] [PubMed]
- Lehman, C.D.; Wellman, R.D.; Buist, D.S.M.; Kerlikowske, K.; Tosteson, A.N.A.; Miglioretti, D.L. Diagnostic accuracy of digital screening mammography with and without computer-aided detection. JAMA Intern. Med. 2015, 175, 1828–1837. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.T.; Wong, K.C.L.; Gur, Y.; Ansari, N.; Karargyris, A.; Sharma, A.; Morris, M.; Saboury, B.; Ahmad, H.; Boyko, O.; et al. Comparison of Chest Radiograph Interpretations by Artificial Intelligence Algorithm vs Radiology Residents. JAMA Netw. Open 2020, 3, e2022779. [Google Scholar] [CrossRef]
- Thammarach, P.; Khaengthanyakan, S.; Vongsurakrai, S.; Phienphanich, P.; Pooprasert, P.; Yaemsuk, A.; Vanichvarodom, P.; Munpolsri, N.; Khwayotha, S.; Lertkowit, M.; et al. AI Chest 4 All. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 1229–1233. [Google Scholar] [CrossRef]
- Singh, R.; Kalra, M.K.; Nitiwarangkul, C.; Patti, J.A.; Homayounieh, F.; Padole, A.; Rao, P.; Putha, P.; Muse, V.V.; Sharma, A.; et al. Deep learning in chest radiography: Detection of findings and presence of change. PLoS ONE 2018, 13, e0204155. [Google Scholar] [CrossRef]
- Hansell, D.M.; Bankier, A.A.; MacMahon, H.; McLoud, T.C.; Müller, N.L.; Remy, J. Fleischner Society: Glossary of Terms for Thoracic Imaging. Radiology 2008, 246, 697–722. [Google Scholar] [CrossRef]
- Breast Imaging Reporting & Data System|American College of Radiology [Internet]. Available online: https://www.acr.org/Clinical-Resources/Reporting-and-Data-Systems/Bi-Rads. (accessed on 1 June 2023).
- Hwang, E.J.; Nam, J.G.; Lim, W.H.; Park, S.J.; Jeong, Y.S.; Kang, J.H.; Hong, E.K.; Kim, T.M.; Goo, J.M.; Park, S.; et al. Deep Learning for Chest Radiograph Diagnosis in the Emergency Department. Radiology 2019, 293, 573–580. [Google Scholar] [CrossRef]
- Ftizisbiomed. Available online: https://ftizisbiomed.ru/#test (accessed on 1 June 2023).
- Nitris, L.; Zhukov, E.; Blinov, D.; Gavrilov, P.; Blinova, E.; Lobishcheva, A. Advanced neural network solution for detection of lung pathology and foreign body on chest plain radiographs. Imaging Med. 2019, 11, 57–66. [Google Scholar]
- Sirazitdinov, I.; Kholiavchenko, M.; Mustafaev, T.; Yixuan, Y.; Kuleev, R.; Ibragimov, B. Deep neural network ensemble for pneumonia localization from a large-scale chest x-ray database. Comput. Electr. Eng. 2019, 78, 388–399. [Google Scholar] [CrossRef]
- Celsus - Medical Screening Systems. Available online: https://celsus.ai/en/products-fluorography/ (accessed on 1 June 2023).
- Kim, H.-E.; Kim, H.H.; Han, B.-K.; Kim, K.H.; Han, K.; Nam, H.; Lee, E.H.; Kim, E.-K. Changes in cancer detection and false-positive recall in mammography using artificial intelligence: A retrospective, multireader study. Lancet Digit. Health 2020, 2, e138–e148. [Google Scholar] [CrossRef]
- Karpov, O.; Bronov, O.; Kapninskiy, A.; Pavlovich, P.; Abovich, Y.; Subbotin, S.; Sokolova, S.; Rychagova, N.; Milova, A.; Nikitin, E. Comparative study of data analysis results of digital mammography AI-based system «CELSUS» and radiologists. Bull. Pirogov. Natl. Med. Surg. Cent. 2021, 16, 86–92. [Google Scholar] [CrossRef]
- Mayo, R.C.; Kent, D.; Sen, L.C.; Kapoor, M.; Leung, J.W.T.; Watanabe, A.T. Reduction of False-Positive Markings on Mammograms: A Retrospective Comparison Study Using an Artificial Intelligence-Based CAD. J. Digit. Imaging 2019, 32, 618–624. [Google Scholar] [CrossRef]
- Rodríguez-Ruiz, A.; Krupinski, E.; Mordang, J.-J.; Schilling, K.; Heywang-Köbrunner, S.H.; Sechopoulos, I.; Mann, R.M. Detection of Breast Cancer with Mammography: Effect of an Artificial Intelligence Support System. Radiology 2019, 290, 305–314. [Google Scholar] [CrossRef]
- Wu, N.; Phang, J.; Park, J.; Shen, Y.; Huang, Z.; Zorin, M.; Jastrzebski, S.; Fevry, T.; Katsnelson, J.; Kim, E.; et al. Deep Neural Networks Improve Radiologists’ Performance in Breast Cancer Screening. IEEE Trans. Med. Imaging 2019, 39, 1184–1194. [Google Scholar] [CrossRef] [PubMed]
- Majkowska, A.; Mittal, S.; Steiner, D.F.; Reicher, J.J.; McKinney, S.M.; Duggan, G.E.; Eswaran, K.; Chen, P.-H.C.; Liu, Y.; Kalidindi, S.R.; et al. Chest Radiograph Interpretation with Deep Learning Models: Assessment with Radiologist-adjudicated Reference Standards and Population-adjusted Evaluation. Radiology 2020, 294, 421–431. [Google Scholar] [CrossRef] [PubMed]
- Freeman, K.; Geppert, J.; Stinton, C.; Todkill, D.; Johnson, S.; Clarke, A.; Taylor-Phillips, S. Use of artificial intelligence for image analysis in breast cancer screening programmes: Systematic review of test accuracy. BMJ 2021, 374, n1872. [Google Scholar] [CrossRef] [PubMed]
- Seah, J.C.Y.; Tang, C.H.M.; Buchlak, Q.D.; Holt, X.G.; Wardman, J.B.; Aimoldin, A.; Esmaili, N.; Ahmad, H.; Pham, H.; Lambert, J.F.; et al. Effect of a comprehensive deep-learning model on the accuracy of chest x-ray interpretation by radiologists: A retrospective, multireader multicase study. Lancet Digit. Health 2021, 3, e496–e506. [Google Scholar] [CrossRef]
- Murphy, K.; Smits, H.; Knoops, A.J.G.; Korst, M.B.J.M.; Samson, T.; Scholten, E.T.; Schalekamp, S.; Schaefer-Prokop, C.M.; Philipsen, R.H.H.M.; Meijers, A.; et al. COVID-19 on chest radiographs: A multireader evaluation of an artificial intelligence system. Radiology 2020, 296, E166–E172. [Google Scholar] [CrossRef]
- Sun, X.; Xu, W. Fast Implementation of DeLong’s Algorithm for Comparing the Areas Under Correlated Receiver Operating Characteristic Curves. IEEE Signal Process. Lett. 2014, 21, 1389–1393. [Google Scholar] [CrossRef]
- Pauly, M.; Asendorf, T.; Konietschke, F. Permutation-based inference for the AUC: A unified approach for continuous and discontinuous data. Biom. J. 2016, 58, 1319–1337. [Google Scholar] [CrossRef] [PubMed]
- Youden, W.J. Index for rating diagnostic tests. Cancer 1950, 3, 32–35. [Google Scholar] [CrossRef] [PubMed]
- Ruopp, M.D.; Perkins, N.J.; Whitcomb, B.W.; Schisterman, E.F. Youden Index and optimal cut-point estimated from observations affected by a lower limit of detection. Biom. J. 2008, 50, 419–430. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Faes, L.; Kale, A.U.; Wagner, S.K.; Fu, D.J.; Bruynseels, A.; Mahendiran, T.; Moraes, G.; Shamdas, M.; Kern, C.; et al. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: A systematic review and meta-analysis. Lancet Digit. Health 2019, 1, e271–e297. [Google Scholar] [CrossRef] [PubMed]
- Zinchenko, V.; Chetverikov, S.; Akhmad, E.; Arzamasov, K.; Vladzymyrskyy, A.; Andreychenko, A.; Morozov, S. Changes in software as a medical device based on artificial intelligence technologies. Int. J. Comput. Assist. Radiol. Surg. 2022, 17, 1969–1977. [Google Scholar] [CrossRef] [PubMed]
- Dratsch, T.; Chen, X.; Rezazade Mehrizi, M.; Kloeckner, R.; Mähringer-Kunz, A.; Püsken, M.; Baeßler, B.; Sauer, S.; Maintz, D.; dos Santos, D.P. Automation Bias in Mammography: The Impact of Artificial Intelligence BI-RADS Suggestions on Reader Performance. Radiology 2023, 307, e222176. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. ChestX-Ray8: Hospital-Scale Chest X-Ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3462–3471. [Google Scholar] [CrossRef]
- Gusev, A.V.; Vladzymyrskyy, A.V.; Sharova, D.E.; Arzamasov, K.M.; Khramov, A.E. Evolution of research and development in the field of artificial intelligence technologies for healthcare in the Russian Federation: Results of 2021. Digit. Diagn. 2022, 3, 178–194. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | X-ray | Fluorography | MMG |
|---|---|---|---|
| Number of cases (cases “with pathology”) * | 140 (47) | 184 (84) | 269 (167) |
| Confirmation of (ab)normality by | Two experts (>5 years of experience) | ||
| Male/female/unknown | 59/77/4 | 94/113/4 | 0/269/0 |
| Age (years) ** | 49 ± 18 [15, 89] | 53 ± 19 [19, 93] | 63 ± 6 [34, 80] |
| Radiological findings |
| 1. Pleural effusion (26) 2. Pneumothorax (7) 3. Nodules or mass (28) 4. Infiltrate or consolidation (26) Pulmonary calcification (14) | BiRADS 0 |
| Number of diagnostic devices | 61 | 69 | 11 |
| Vendors | (1) GE Medical Systems, LLC (2) Fujifilm (3) Toshiba Medical Systems, Inc (4) RENinMED, LLC | (1) S.P. Gelpik, LLC | (1) Fujifilm |
| Radiologists (number) | 185 | 28 | 113 (96 breast imaging specialists) |
| Years of experience | |||
| 0–1 | 36 | 6 | 16 (15) |
| 1–5 | 60 | 8 | 32 (28) |
| 5–10 | 36 | 5 | 28 (24) |
| 10+ | 53 | 9 | 37 (29) |
| Country *** | AM—1 AZ—1 BY—11 GE—1 KG—2 KZ—6 LV—1 MD—2 RU—141 UA—17 UZ—2 | BY—1 GE—1 KZ—1 RU—25 | AZ—1 BY—4 GE—1 KG—1 KZ—4 LV—1 MD—1 RU—95 UA—4 UZ—1 |
| Modality | Diagnostic Performance Metrics | |||||
|---|---|---|---|---|---|---|
| AUROC (CI 95%) | Sensitivity * (CI 95%) | Specificity * (CI 95%) | Accuracy * (CI 95%) | p-Value (for the AUROC) | ||
| X-ray | AI n = 90 | 0.92 (0.85–0.98) | 0.81 (0.66–0.91) | 0.94 (0.83–0.99) | 0.88 (0.79–0.94) | - |
| Radiologists (all) n = 90 | 0.97 (0.94–1.0) | 0.88 (0.74–0.96) | 0.96 (0.86–0.99) | 0.92 (0.85–0.97) | 0.104 | |
| Radiologists (0–1 year) n = 83 | 0.87 (0.79–0.95) | 0.74 (0.57–0.87) | 0.96 (0.85–0.99) | 0.86 (0.76–0.92) | 0.76 | |
| Radiologists (1–5 years) n = 86 | 0.92 (0.86–0.99) | 0.83 (0.69–0.93) | 1.00 (0.92–1.00) | 0.92 (0.84–0.97) | 0.43 | |
| Radiologists (5–10 years) n = 65 | 0.93 (0.86–1.00) | 0.83 (0.65–0.94) | 0.97 (0.85–1.00) | 0.91 (0.81–0.97) | 0.40 | |
| Radiologists (10+ years) n = 84 | 0.98 (0.96–1.00) | 0.92 (0.79–0.98) | 0.93 (0.82–0.99) | 0.93 (0.85–0.97) | 0.08 | |
| FLG | AI n = 162 | 0.83 (0.76–0.9) | 0.71 (0.58–0.81) | 0.91 (0.83–0.96) | 0.83 (0.76–0.88) | - |
| Radiologists (all) n = 162 | 0.98 (0.96–1.00) | 0.89 (0.79–0.96) | 0.98 (0.93–1.00) | 0.94 (0.90–0.97) | 0.00 ** | |
| Radiologists (0–1 year) n = 14 | 0.96 (0.87–1.00) | 1.00 (0.63–1.00) | 0.83 (0.36–1.00) | 0.93 (0.66–1.00) | 0.25 | |
| Radiologists (1–5 years) n = 42 | 0.99 (0.98–1.00) | 0.91 (0.72–0.99) | 1.00 (0.82–1.00) | 0.95 (0.84–0.99) | 0.06 | |
| Radiologists (5–10 years) n = 12 | 1.00 (1.00–1.00) | 1.00 (0.48–1.00) | 1.00 (0.59–1.00) | 1.00 (0.74–1.00) | 0.09 | |
| Radiologists (10+ years) n = 27 | 0.97 (0.90–1.00) | 1.00 (0.74–1.00) | 0.93 (0.68–1.00) | 0.96 (0.81–1.00) | 0.04 ** | |
| MMG General Radiologists | AI n = 151 | 0.89 (0.83–0.94) | 0.71 (0.59–0.81) | 0.95 (0.87–0.99) | 0.83 (0.76–0.88) | - |
| Radiologists (all) n = 151 | 0.94 (0.91–0.97) | 0.85 (0.75–0.92) | 0.96 (0.89–0.99) | 0.91 (0.85–0.95) | 0.01 ** | |
| Radiologists (0–1 year) n = 15 | 0.91 (0.77–1.00) | 0.88 (0.47–1.00) | 0.86 (0.42–1.00) | 0.87 (0.60–0.98) | 0.33 | |
| Radiologists (1–5 years) n = 62 | 0.92 (0.87–0.98) | 0.77 (0.56–0.91) | 0.94 (0.81–0.99) | 0.87 (0.76–0.94) | 0.15 | |
| Radiologists (5–10 years) n = 35 | 0.90 (0.78–1.00) | 0.83 (0.59–0.96) | 0.94 (0.71–1.00) | 0.89 (0.73–0.97) | 0.26 | |
| Radiologists (10+ years) n = 55 | 0.97 (0.93–1.00) | 0.91 (0.72–0.99) | 1.00 (0.89–1.00) | 0.96 (0.87–1.00) | 0.02 ** | |
| MMG Breast Imaging Radiologists | AI n = 120 | 0.89 (0.83–0.94) | 0.72 (0.58–0.83) | 0.92 (0.82–0.97) | 0.82 (0.75–0.89) | - |
| Breast Imaging Radiologists (all) n = 120 | 0.96 (0.93–0.99) | 0.95 (0.85–0.99) | 0.90 (0.80–0.96) | 0.93 (0.86–0.97) | 0.01 ** | |
| Breast Imaging Radiologists (0–1 year) n = 13 | 0.85 (0.66–1.00) | 1.00 (0.63–1.00) | 0.60 (0.15–0.95) | 0.85 (0.55–0.98) | 0.52 | |
| Breast Imaging Radiologists (1–5 years) n = 36 | 0.88 (0.76–1.00) | 0.93 (0.68–1.00) | 0.71 (0.48–0.89) | 0.81 (0.64–0.92) | 0.55 | |
| Breast Imaging Radiologists (5–10 years) n = 58 | 0.92 (0.85–0.98) | 0.88 (0.68–0.97) | 0.74 (0.56–0.87) | 0.79 (0.67–0.89) | 0.10 | |
| Breast Imaging Radiologists (10+ years) n = 109 | 0.97 (0.94–1.00) | 0.91 (0.80–0.97) | 0.96 (0.87–1.00) | 0.94 (0.87–0.97) | 0.001 ** | |
| Overall result (X-ray + FLG + MMG) | AI solutions (All) n = 403 | 0.87 (0.83–0.9) | 0.71 (0.64–0.78) | 0.93 (0.89–0.96) | 0.83 (0.79–0.87) | |
| Radiologists and Breast Imaging Radiologists (All) n = 403 | 0.96 (0.94–0.97) | 0.91 (0.86–0.95) | 0.90 (0.85–0.94) | 0.91 (0.87–0.93) | 0.00 ** | |
| Radiologists (0–1 year) n = 112 | 0.93 (0.89–0.97) | 0.93 (0.8–0.98) | 0.80 (0.69–0.89) | 0.85 (0.77–0.91) | 0.65 | |
| Radiologists (1–5 years) n = 190 | 0.94 (0.91–0.97) | 0.89 (0.81–0.94) | 0.87 (0.79–0.92) | 0.87 (0.83–0.91) | 0.02 ** | |
| Radiologists (5–10 years) n = 112 | 0.95 (0.92–0.98) | 0.90 (0.81–0.96) | 0.90 (0.82–0.95) | 0.90 (0.85–0.94) | 0.23 | |
| Radiologists (10+ years) n = 166 | 0.97 (0.95–0.99) | 0.92 (0.86–0.96) | 0.91 (0.86–0.95) | 0.92 (0.88–0.95) | 0.00 ** | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arzamasov, K.; Vasilev, Y.; Vladzymyrskyy, A.; Omelyanskaya, O.; Shulkin, I.; Kozikhina, D.; Goncharova, I.; Gelezhe, P.; Kirpichev, Y.; Bobrovskaya, T.; et al. An International Non-Inferiority Study for the Benchmarking of AI for Routine Radiology Cases: Chest X-ray, Fluorography and Mammography. Healthcare 2023, 11, 1684. https://doi.org/10.3390/healthcare11121684
Arzamasov K, Vasilev Y, Vladzymyrskyy A, Omelyanskaya O, Shulkin I, Kozikhina D, Goncharova I, Gelezhe P, Kirpichev Y, Bobrovskaya T, et al. An International Non-Inferiority Study for the Benchmarking of AI for Routine Radiology Cases: Chest X-ray, Fluorography and Mammography. Healthcare. 2023; 11(12):1684. https://doi.org/10.3390/healthcare11121684
Chicago/Turabian StyleArzamasov, Kirill, Yuriy Vasilev, Anton Vladzymyrskyy, Olga Omelyanskaya, Igor Shulkin, Darya Kozikhina, Inna Goncharova, Pavel Gelezhe, Yury Kirpichev, Tatiana Bobrovskaya, and et al. 2023. "An International Non-Inferiority Study for the Benchmarking of AI for Routine Radiology Cases: Chest X-ray, Fluorography and Mammography" Healthcare 11, no. 12: 1684. https://doi.org/10.3390/healthcare11121684
APA StyleArzamasov, K., Vasilev, Y., Vladzymyrskyy, A., Omelyanskaya, O., Shulkin, I., Kozikhina, D., Goncharova, I., Gelezhe, P., Kirpichev, Y., Bobrovskaya, T., & Andreychenko, A. (2023). An International Non-Inferiority Study for the Benchmarking of AI for Routine Radiology Cases: Chest X-ray, Fluorography and Mammography. Healthcare, 11(12), 1684. https://doi.org/10.3390/healthcare11121684