
Estimation of Surgery Durations Using Machine Learning Methods-A Cross-Country Multi-Site Collaborative Study


 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Cross Country Collaborative Platform
2.2. Descriptive Analysis
2.3. Moving Average Estimation
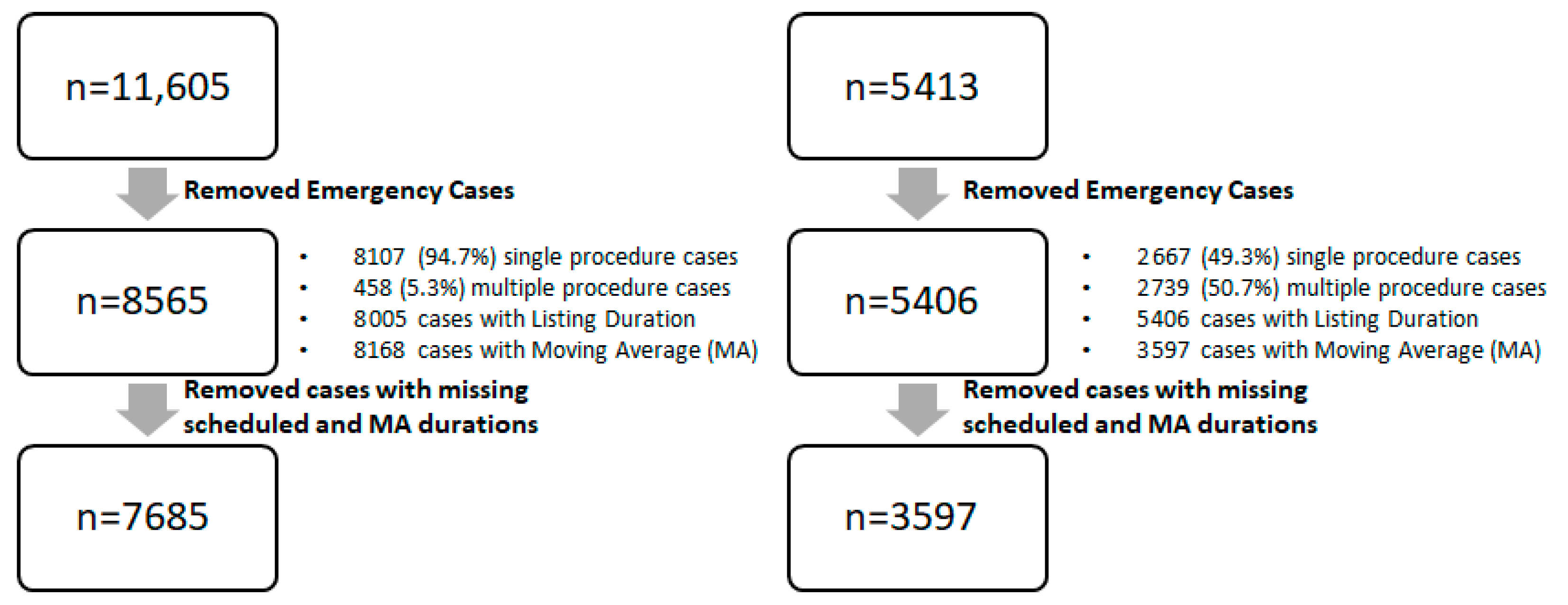
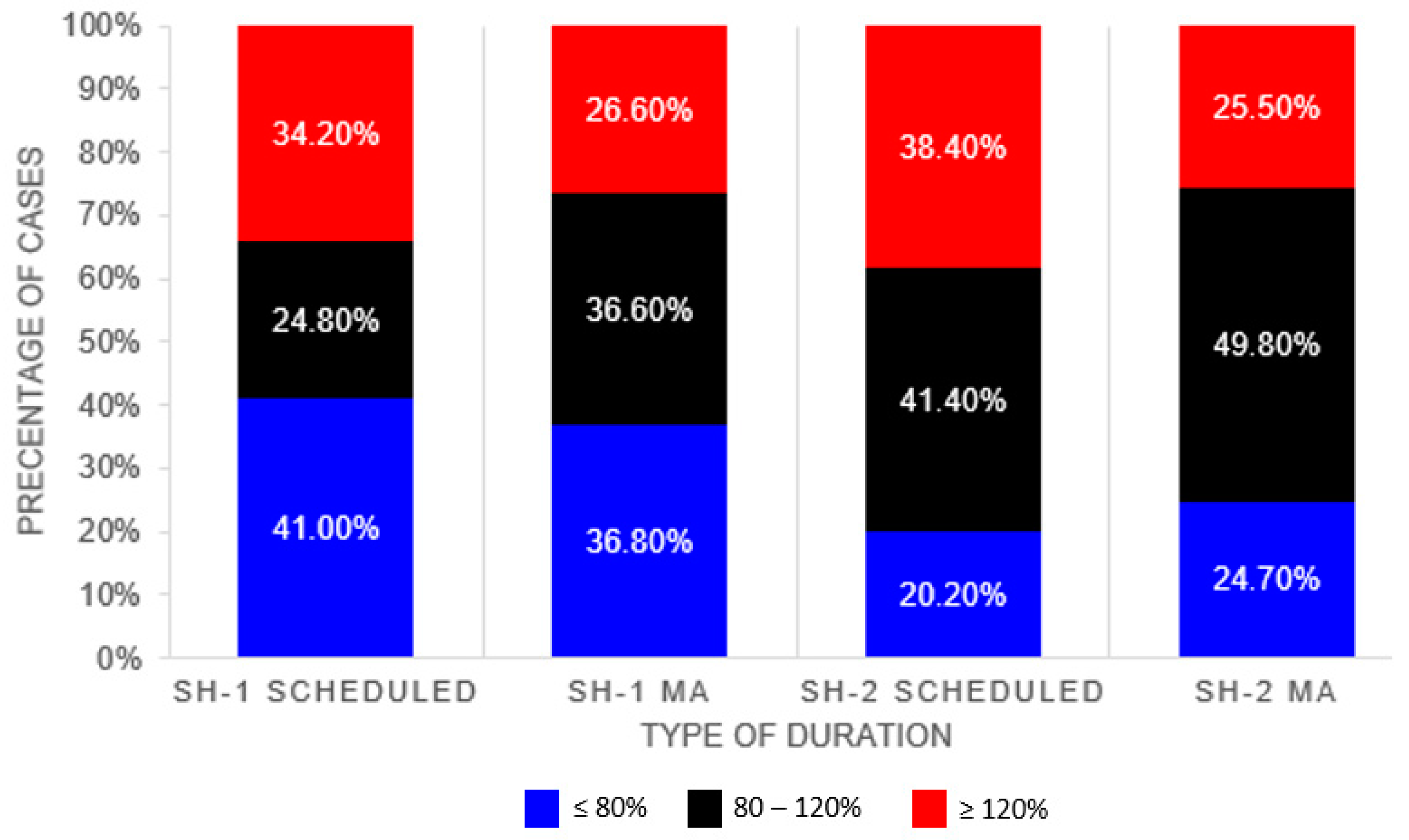
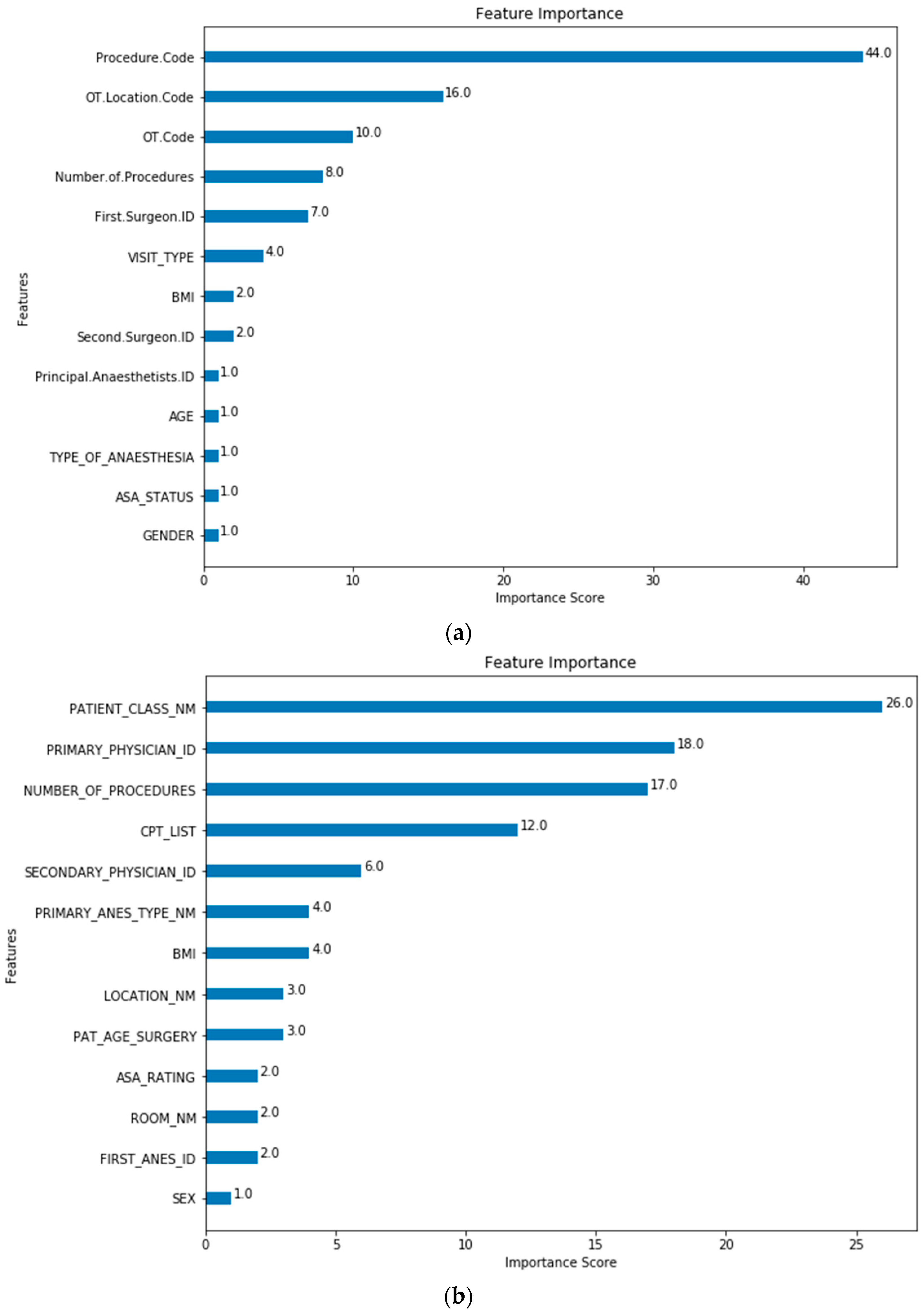
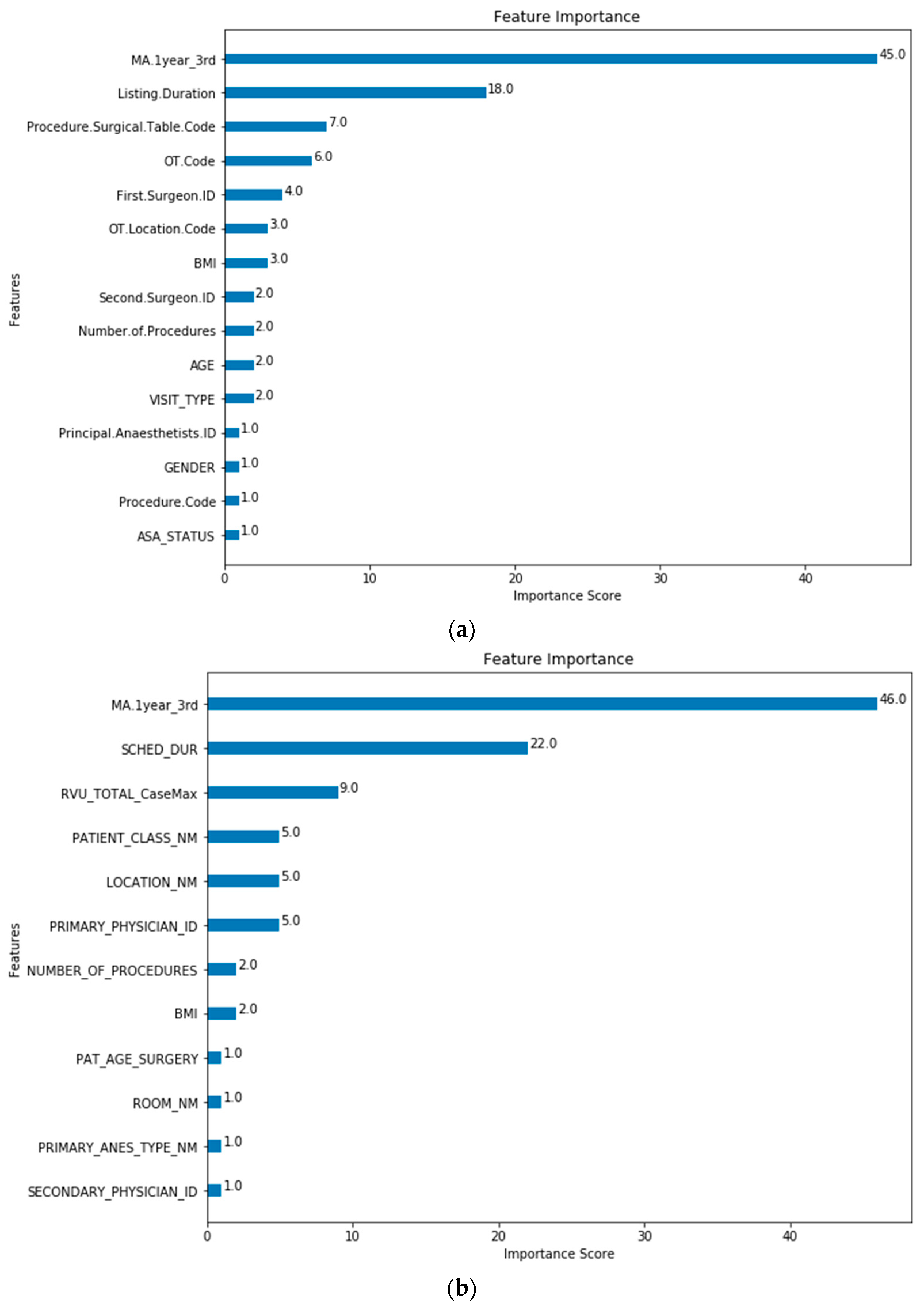
3. Results
Scheduler and System Average Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Anatomical System | Type of Procedure | CPT Code | TOSP Codes | TOSP Table |
|---|---|---|---|---|
| Digestive | Hepatectomy | 47120 | SF815L | 4C |
| Digestive | Hepatectomy | 47120 | SF813L | 5C |
| Digestive | Hepatectomy | 47122 | SF809L | 7C |
| Digestive | Hepatectomy | 47125 | SF812L | 6B |
| Digestive | Hepatectomy | 47130 | SF812L | 6B |
| Digestive | Appendectomy | 44950 | SF849A | 3B |
| Digestive | Appendectomy | 44950 | SF723A | 4A |
| Digestive | Appendectomy | 44960 | SF849A | 3B |
| Digestive | Appendectomy | 44960 | SF723A | 4A |
| Digestive | Appendectomy | 44970 | SF849A | 3B |
| Digestive | Appendectomy | 44970 | SF723A | 4A |
| Digestive | Colorectal | 44140 | SF701C | 6C |
| Digestive | Colorectal | 44140 | SF803C | 5C |
| Digestive | Colorectal | 44140 | SF806C | 5C |
| Digestive | Colorectal | 44143 | SF808R | 5C |
| Digestive | Colorectal | 44144 | SF808R | 5C |
| Digestive | Colorectal | 44145 | SF805R | 6C |
| Digestive | Colorectal | 44145 | SF703R | 6C |
| Digestive | Colorectal | 44145 | SF807R | 6B |
| Digestive | Colorectal | 44146 | SF805R | 6C |
| Digestive | Colorectal | 44146 | SF703R | 6C |
| Digestive | Colorectal | 44146 | SF807R | 6B |
| Digestive | Colorectal | 44147 | SF703R | 6C |
| Digestive | Colorectal | 44150 | SF804C | 6A |
| Digestive | Colorectal | 44150 | SF712C | 6A |
| Digestive | Colorectal | 44151 | SF804C | 6A |
| Digestive | Colorectal | 44151 | SF712C | 6A |
| Digestive | Colorectal | 44160 | SF803C | 5C |
| Digestive | Colorectal | 44204 | SF701C | 6C |
| Digestive | Colorectal | 44204 | SF803C | 5C |
| Digestive | Colorectal | 44204 | SF806C | 5C |
| Digestive | Colorectal | 44205 | SF803C | 5C |
| Digestive | Colorectal | 44206 | SF808R | 5C |
| Digestive | Colorectal | 44207 | SF805R | 6C |
| Digestive | Colorectal | 44207 | SF703R | 6C |
| Digestive | Colorectal | 44207 | SF807R | 6B |
| Digestive | Colorectal | 44208 | SF805R | 6C |
| Digestive | Colorectal | 44208 | SF703R | 6C |
| Digestive | Colorectal | 44208 | SF807R | 6B |
| Digestive | Colorectal | 44210 | SF712C | 6A |
| Digestive | Colorectal | 44210 | SF804C | 6A |
| Digestive | Esophagectomy | 43101 | SF802E | 5B |
| Digestive | Esophagectomy | 43107 | SF809E | 7B |
| Digestive | Esophagectomy | 43108 | SM702L | 7C |
| Digestive | Esophagectomy | 43112 | SF809E | 7B |
| Digestive | Esophagectomy | 43112 | SM702L | 7C |
| Digestive | Esophagectomy | 43113 | SF809E | 7B |
| Digestive | Esophagectomy | 43113 | SM702L | 7C |
| Digestive | Esophagectomy | 43116 | SF806E | 7C |
| Digestive | Esophagectomy | 43117 | SF804E | 6B |
| Digestive | Esophagectomy | 43117 | SF809E | 7B |
| Digestive | Esophagectomy | 43118 | SF804E | 6B |
| Digestive | Esophagectomy | 43118 | SF809E | 7B |
| Digestive | Esophagectomy | 43121 | SF804E | 6B |
| Digestive | Esophagectomy | 43122 | SF804E | 6B |
| Digestive | Esophagectomy | 43123 | SF804E | 6B |
| Digestive | Esophagectomy | 43124 | SF812E | 3A |
| Digestive | Esophagectomy | 43124 | SF806E | 7C |
| Digestive | Pancreatectomy | 48120 | SF705P | 4C |
| Digestive | Pancreatectomy | 48120 | SF706P | 5A |
| Digestive | Pancreatectomy | 48140 | SF708P | 5B |
| Digestive | Pancreatectomy | 48145 | SF809P | 7C |
| Digestive | Pancreatectomy | 48145 | SF712P | 5C |
| Digestive | Pancreatectomy | 48146 | SF703P | 7A |
| Digestive | Pancreatectomy | 48146 | SF704P | 7A |
| Digestive | Pancreatectomy | 48148 | SF807B | 5C |
| Digestive | Pancreatectomy | 48150 | SF809P | 7C |
| Digestive | Pancreatectomy | 48152 | SF809P | 7C |
| Digestive | Pancreatectomy | 48153 | SF809P | 7C |
| Digestive | Pancreatectomy | 48154 | SF809P | 7C |
| Digestive | Pancreatectomy | 48155 | SF809P | 7C |
| Digestive | Colorectal | 44155 | SF712C | 6A |
| Digestive | Colorectal | 44155 | SF804C | 6A |
| Digestive | Colorectal | 44155 | SF805C | 6B |
| Digestive | Colorectal | 44156 | SF805C | 6B |
| Digestive | Colorectal | 44157 | SF805C | 6B |
| Digestive | Colorectal | 44157 | SF713C | 6C |
| Digestive | Colorectal | 44158 | SF713C | 6C |
| Digestive | Colorectal | 44211 | SF713C | 6C |
| Digestive | Colorectal | 44212 | SF712C | 6A |
| Digestive | Colorectal | 44212 | SF804C | 6A |
| Digestive | Colorectal | 44212 | SF805C | 6B |
| Digestive | Colorectal | 45110 | SF845A | 6B |
| Digestive | Colorectal | 45110 | SF805R | 6C |
| Digestive | Colorectal | 45111 | SF805C | 6B |
| Digestive | Colorectal | 45111 | SF701R | 5C |
| Digestive | Colorectal | 45112 | SF807R | 6B |
| Digestive | Colorectal | 45113 | SF807R | 6B |
| Digestive | Colorectal | 45114 | SF701R | 5C |
| Digestive | Colorectal | 45116 | SF701R | 5C |
| Digestive | Colorectal | 45119 | SF807R | 6B |
| Digestive | Colorectal | 45120 | SF803R | 5C |
| Digestive | Colorectal | 45120 | SF700R | 5C |
| Digestive | Colorectal | 45121 | SF803R | 5C |
| Digestive | Colorectal | 45126 | SF703R | 6C |
| Digestive | Colorectal | 45126 | SF808R | 5C |
| Digestive | Colorectal | 45126 | SF805A | 6B |
| Digestive | Colorectal | 45130 | SF700R | 5C |
| Digestive | Colorectal | 45135 | SF700R | 5C |
| Digestive | Colorectal | 45160 | SF701R | 5C |
| Digestive | Colorectal | 45395 | SF805C | 6B |
| Digestive | Colorectal | 45395 | SF805C | 6B |
| Digestive | Colorectal | 45397 | SF713C | 6C |
| Digestive | Colorectal | 45402 | SF701R | 5C |
| Digestive | Colorectal | 45550 | SF701R | 5C |
| Endocrine | Thyroid | 60200 | SJ801T | 3B |
| Endocrine | Thyroid | 60210 | SJ802T | 4A |
| Endocrine | Thyroid | 60212 | SJ802T | 4A |
| Endocrine | Thyroid | 60220 | SJ804T | 6A |
| Endocrine | Thyroid | 60220 | SJ802T | 4A |
| Endocrine | Thyroid | 60225 | SJ804T | 6A |
| Endocrine | Thyroid | 60225 | SJ802T | 4A |
| Endocrine | Thyroid | 60240 | SJ803T | 5C |
| Endocrine | Thyroid | 60240 | SJ703T | 6C |
| Endocrine | Thyroid | 60252 | SJ702T | 6A |
| Endocrine | Thyroid | 60254 | SJ702T | 6A |
| Endocrine | Thyroid | 60260 | SJ702T | 6A |
| Endocrine | Thyroid | 60270 | SJ702T | 6A |
| Endocrine | Thyroid | 60271 | SJ702T | 6A |
| Reproductive | Hysterectomy/Myomectomy | 58140 | SI816U | 3B |
| Reproductive | Hysterectomy/Myomectomy | 58146 | SI815U | 5A |
| Reproductive | Hysterectomy/Myomectomy | 58150 | SI803U | 4A |
| Reproductive | Hysterectomy/Myomectomy | 58150 | SI804U | 5C |
| Reproductive | Hysterectomy/Myomectomy | 58150 | SI805U | 5C |
| Reproductive | Hysterectomy/Myomectomy | 58150 | SI812U | 5C |
| Reproductive | Hysterectomy/Myomectomy | 58152 | SI702U | 4C |
| Reproductive | Hysterectomy/Myomectomy | 58180 | SI802U | 4A |
| Reproductive | Hysterectomy/Myomectomy | 58210 | SI825U | 5C |
| Reproductive | Hysterectomy/Myomectomy | 58210 | SI827U | 5A |
| Reproductive | Hysterectomy/Myomectomy | 58210 | SI828U | 4A |
| Reproductive | Hysterectomy/Myomectomy | 58240 | SI824U | 6B |
| Reproductive | Hysterectomy/Myomectomy | 58260 | SI837U | 4A |
| Reproductive | Hysterectomy/Myomectomy | 58260 | SI713V | 4A |
| Reproductive | Hysterectomy/Myomectomy | 58262 | SI723U | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58263 | SI721U | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58270 | SI713V | 4A |
| Reproductive | Hysterectomy/Myomectomy | 58290 | SI837U | 4A |
| Reproductive | Hysterectomy/Myomectomy | 58290 | SI713V | 4A |
| Reproductive | Hysterectomy/Myomectomy | 58291 | SI723U | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58292 | SI721U | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58294 | SI713V | 4A |
| Reproductive | Hysterectomy/Myomectomy | 58541 | SI713U | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58542 | SI713U | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58543 | SI712U | 5A |
| Reproductive | Hysterectomy/Myomectomy | 58544 | SI712U | 5A |
| Reproductive | Hysterectomy/Myomectomy | 58545 | SI709U | 3C |
| Reproductive | Hysterectomy/Myomectomy | 58546 | SI700O | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58548 | SI800O | 5C |
| Reproductive | Hysterectomy/Myomectomy | 58548 | SI804O | 4A |
| Reproductive | Hysterectomy/Myomectomy | 58550 | SI718U | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58552 | SI718U | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58553 | SI718U | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58554 | SI718U | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58570 | SI713U | 4B |
| Reproductive | Hysterectomy/Myomectomy | 58572 | SI712U | 5A |
| Reproductive | Hysterectomy/Myomectomy | 58940 | SI805O | 3B |
| Reproductive | Hysterectomy/Myomectomy | 58951 | SI800O | 5C |
| Reproductive | Hysterectomy/Myomectomy | 58951 | SI711U | 6A |
| Reproductive | Hysterectomy/Myomectomy | 58953 | SI804O | 4A |
| Reproductive | Hysterectomy/Myomectomy | 58954 | SI800O | 5C |
| Reproductive | Hysterectomy/Myomectomy | 58954 | SI804O | 4A |
| Musculoskeletal | THA | 27125 | SB838H | 5C |
| Musculoskeletal | THA | 27130 | SB839H | 6A |
| Musculoskeletal | THA | 27130 | SB723H | 6B |
| Musculoskeletal | THA | 27132 | SB724H | 6C |
| Musculoskeletal | THA | 27134 | SB724H | 6C |
| Musculoskeletal | THA | 27137 | SB724H | 6C |
| Musculoskeletal | THA | 27138 | SB724H | 6C |
| Kidney | Nephrectomy | 50220 | SG816K | 4B |
| Kidney | Nephrectomy | 50225 | SG816K | 4B |
| Kidney | Nephrectomy | 50230 | SG804K | 5C |
| Kidney | Nephrectomy | 50234 | SG800K | 5C |
| Kidney | Nephrectomy | 50236 | SG800K | 5C |
| Kidney | Nephrectomy | 50240 | SG721K | 5C |
| Kidney | Nephrectomy | 50543 | SG720K | 6A |
| Kidney | Nephrectomy | 50545 | SG710K | 6A |
| Kidney | Nephrectomy | 50546 | SG700K | 6A |
| Kidney | Nephrectomy | 50546 | SG722K | 4C |
| Kidney | Nephrectomy | 50548 | SG700K | 6A |
| Model Number | ||||||||
|---|---|---|---|---|---|---|---|---|
| SN | SH-1 Data Fields | SH-2 Data Fields | 0 (Baseline) | 1 | 2 | 3 | 4 | 5 |
| 1 | OT Code | Room | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 2 | Actual Duration | In-Out Duration | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 3 | First Surgeon Department Code | Service Type | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 4 | Priority of Operation | Case Class | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 5 | Department Code | Division | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 6 | OT Location Code | Location | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 7 | Procedure Code | CPT List | ✓ | ✓ | ||||
| 8 | Type of Anesthesia | Primary Anesthesia Type | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 9 | ASA Status | ASA Rating | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 10 | Age | Patient Age | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 11 | Gender | Sex | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 12 | Visit Type | Patient Class | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 13 | BMI | BMI | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 14 | Height | Height | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 15 | Weight | Weight | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 16 | First Surgeon ID | Primary Physician ID | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 17 | Second Surgeon ID | Secondary Physician ID | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 18 | Principal Anesthetist ID | First Anesthetist ID | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 19 | MA 1year_3rd | MA 1year_3rd (calculated) | ✓ | ✓ | ✓ | |||
| 20 | Number of Procedures | Number of Procedures | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 21 | Number of Panels | Number of Panels | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 22 | Multiple Procedure Codes | Sorted CPT List | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 23 | Listing Duration | Scheduled Duration | ✓ | ✓ | ✓ | |||
References
- Ang, W.; Sabharwal, S.; Johannsson, H.; Bhattacharya, R.; Gupte, C. The cost of trauma operating theatre inefficiency. Ann. Med. Surg. 2016, 7, 24–29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weiser, T.G.; Regenbogen, S.E.; Thompson, K.D.; Haynes, A.B.; Lipsitz, S.R.; Berry, W.R.; Gawande, A.A. An estimation of the global volume of surgery: A modelling strategy based on available data. Lancet 2008, 372, 139–144. [Google Scholar] [CrossRef]
- Kayış, E.; Khaniyev, T.T.; Suermondt, J.; Sylvester, K. A robust estimation model for surgery durations with temporal, operational, and surgery team effects. Health Care Manag. Sci. 2014, 18, 222–233. [Google Scholar] [CrossRef] [PubMed]
- Memon, A.G.; Naeem, Z.; Zaman, A. Occupational Health Related Concerns among Surgeons. Int. J. Health Sci. 2016, 10, 265–277. [Google Scholar] [CrossRef]
- Erdogan, S.A.; Denton, B.T. Surgery Planning and Scheduling. In Wiley Encyclopedia of Operations Research and Management Science; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2011. [Google Scholar]
- Kayis, E.; Wang, H.; Patel, M.; Gonzalez, T.; Jain, S.; Ramamurthi, R.J.; Santos, C.; Singhal, S.; Suermondt, J.; Sylvester, K. Improving prediction of surgery duration using operational and temporal factors. AMIA Annu. Symp. Proc. 2012, 2012, 456–462. [Google Scholar] [PubMed]
- Thiels, C.A.; Yu, D.; Abdelrahman, A.M.; Habermann, E.B.; Hallbeck, S.; Pasupathy, K.S.; Bingener, J. The use of patient factors to improve the prediction of operative duration using laparoscopic cholecystectomy. Surg. Endosc. 2016, 31, 333–340. [Google Scholar] [CrossRef] [PubMed]
- Bellini, V.; Guzzon, M.; Bigliardi, B.; Mordonini, M.; Filippelli, S.; Bignami, E. Artificial Intelligence: A New Tool in Operating Room Management. Role of Machine Learning Models in Operating Room Optimization. J. Med. Syst. 2019, 44, 20. [Google Scholar] [CrossRef] [PubMed]
- Hosseini, N.; Sir, M.Y.; Jankowski, C.J.; Pasupathy, K.S. Surgical Duration Estimation via Data Mining and Predictive Modeling: A Case Study. AMIA Annu. Symp. Proc. 2015, 2015, 640–648. [Google Scholar] [PubMed]
- Tuwatananurak, J.P.; Zadeh, S.; Xu, X.; Vacanti, J.A.; Fulton, W.R.; Ehrenfeld, J.M.; Urman, R.D. Machine Learning Can Improve Estimation of Surgical Case Duration: A Pilot Study. J. Med. Syst. 2019, 43, 44. [Google Scholar] [CrossRef] [PubMed]
- Edelman, E.R.; Van Kuijk, S.M.J.; Hamaekers, A.E.W.; De Korte, M.J.M.; Van Merode, G.G.; Buhre, W.F.F.A. Improving the Prediction of Total Surgical Procedure Time Using Linear Regression Modeling. Front. Med. 2017, 4, 85. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Taaffe, K.; Pearce, B.; Ritchie, G. Using kernel density estimation to model surgical procedure duration. Int. Trans. Oper. Res. 2018, 28, 401–418. [Google Scholar] [CrossRef]
- Stepaniak, P.S.; Heij, C.; Mannaerts, G.H.H.; de Quelerij, M.; de Vries, G. Modeling Procedure and Surgical Times for Current Procedural Terminology-Anesthesia-Surgeon Combinations and Evaluation in Terms of Case-Duration Prediction and Operating Room Efficiency: A Multicenter Study. Anesth. Analg. 2009, 109, 1232–1245. [Google Scholar] [CrossRef] [PubMed]
- Ng, N.H.; Gabriel, R.A.; McAuley, J.; Elkan, C.; Lipton, Z.C. Predicting Surgery Duration with Neural Heteroscedastic Regression. In Proceedings of the 2nd Machine Learning for Healthcare Conference, Boston, MA, USA, 18–19 August 2017; Finale, D.-V., Ed.; PMLR (Proceedings of Machine Learning Research): Freiburg, Germany, 2017; pp. 100–111. [Google Scholar]
- ShahabiKargar, Z.; Khanna, S.; Good, N.; Sattar, A.; Lind, J.; O’Dwyer, J. Predicting Procedure Duration to Improve Scheduling of Elective Surgery. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 998–1009. [Google Scholar]
- Li, T.; Yang, K.; Stein, J.D.; Nallasamy, N. Gradient Boosting Decision Tree Algorithm for the Prediction of Postoperative Intraocular Lens Position in Cataract Surgery. Transl. Vis. Sci. Technol. 2020, 9, 38. [Google Scholar] [CrossRef] [PubMed]
- Bartek, M.A.; Saxena, R.C.; Solomon, S.; Fong, C.T.; Behara, L.D.; Venigandla, R.; Velagapudi, K.; Lang, J.D.; Nair, B.G. Improving Operating Room Efficiency: Machine Learning Approach to Predict Case-Time Duration. J. Am. Coll. Surg. 2019, 229, 346–354.e3. [Google Scholar] [CrossRef] [PubMed]
- Evans, S. Introduction to the PACE Project. In Computers and Medicine; Springer: New York, NY, USA, 1997; pp. 1–25. [Google Scholar]
- SingHealth Annual Reports. Available online: https://www.singhealth.com.sg/about-singhealth/newsroom/Documents/SingHealth%20Duke-NUS%20AR%202019-20.pdf (accessed on 6 April 2022).
- About Duke University Hospital Durham, NC Duke Health. Available online: https://www.dukehealth.org/hospitals/duke-university-hospital (accessed on 6 April 2022).
- Facts & Statistics Duke Health. Available online: https://corporate.dukehealth.org/who-we-are/facts-statistics (accessed on 6 April 2022).
- Protected Analytics Computing Environment (PACE). Available online: https://pace.ori.duke.edu/ (accessed on 6 April 2022).
- Sunrise™. Allscripts. Available online: https://as.allscripts.com/ (accessed on 6 April 2022).
- Electronic Health Intelligence System. Available online: https://www.ihis.com.sg/Project_Showcase/Healthcare_Systems/Pages/eHINTS.aspx (accessed on 6 April 2022).
- Maestro Care for Research Duke University School of Medicine. Available online: https://medschool.duke.edu/research/research-support/research-support-offices/duke-office-clinical-research-docr/get-docr-0 (accessed on 6 April 2022).
- Duo Access Gateway. Duo Security. Available online: https://duo.com/docs/dag (accessed on 6 April 2022).
- Python Language Reference. In Python for Bioinformatics; Chapman and Hall/CRC: Boca Raton, FL, USA, 2009; pp. 457–538.
- Ministry of Health Table of Surgical Procedures. Available online: https://www.moh.gov.sg/docs/librariesprovider5/medisave/table-of-surgical-procedures-(1-feb-2021).pdf (accessed on 6 April 2022).
- American Medical Association. CPT® Overview and Code Approval. Available online: https://www.ama-assn.org/practice-management/cpt/cpt-overview-and-code-approval (accessed on 18 April 2022).
- PFS Relative Value Files CMS. Available online: https://www.cms.gov/Medicare/Medicare-Fee-for-Service-Payment/PhysicianFeeSched/PFS-Relative-Value-Files (accessed on 18 April 2022).
- Garside, N.; Zaribafzadeh, H.; Henao, R.; Chung, R.; Buckland, D. CPT to RVU conversion improves model performance in the prediction of surgical case length. Sci. Rep. 2021, 11, 14169. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost-state-of-the-art open-source gradient boosting library with categorical features support. In Proceedings of the Workshop on ML Systems, NIPS 2017, Long Beach, CA, USA, 8 December 2017. [Google Scholar]
- Macario, A. What does one minute of operating room time cost? J. Clin. Anesth. 2010, 22, 233–236. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Dexter, F.; Macario, A.; Lubarsky, D.A. Relying solely on historical surgical times to estimate accurately future surgical times is unlikely to reduce the average length of time cases finish late. J. Clin. Anesth. 1999, 11, 601–605. [Google Scholar] [CrossRef]
- Strömblad, C.T.; Baxter-King, R.G.; Meisami, A.; Yee, S.-J.; Levine, M.R.; Ostrovsky, A.; Stein, D.; Iasonos, A.; Weiser, M.R.; Garcia-Aguilar, J.; et al. Effect of a Predictive Model on Planned Surgical Duration Accuracy, Patient Wait Time, and Use of Presurgical Resources: A Randomized Clinical Trial. JAMA Surg. 2021, 156, 315–321. [Google Scholar] [CrossRef] [PubMed]
| SN | SH-1 Data Fields | SH-2 Data Fields |
|---|---|---|
| 1 | OT Code | Room |
| 2 | Actual Duration | In-Out Duration |
| 3 | First Surgeon Department Code | Service Type |
| 4 | Priority of Operation | Case Class |
| 5 | Department Code | Division |
| 6 | OT Location Code | Location |
| 7 | Procedure Code | CPT List |
| 8 | Type of Anesthesia | Primary Anesthesia Type |
| 9 | ASA Status | ASA Rating |
| 10 | Age | Patient Age |
| 11 | Gender | Sex |
| 12 | Visit Type | Patient Class |
| 13 | BMI | BMI |
| 14 | Height | Height |
| 15 | Weight | Weight |
| 16 | First Surgeon ID | Primary Physician ID |
| 17 | Second Surgeon ID | Secondary Physician ID |
| 18 | Principal Anesthetist ID | First Anesthetist ID |
| 19 | MA 1 year_3rd | MA 1 year_3rd (calculated) |
| 20 | Number of Procedures | Number of Procedures |
| 21 | Number of Panels | Number of Panels |
| 22 | Multiple Procedure Codes | Sorted CPT List |
| 23 | Listing Duration | Scheduled Duration |
| Name | Features Considered |
|---|---|
| Model 0 | Baseline Model which considered patient and surgery factors only |
| Model 1 | Baseline Model + RVU/Procedure Surgical Table Code |
| Model 2 | Baseline Model + Moving Average |
| Model 3 | Baseline Model + Scheduled Duration |
| Model 4 | Baseline Model + Moving Average + Scheduled Duration |
| Model 5 | Baseline Model + Moving Average + Scheduled Duration + RVU/Procedure Surgical Table Code |
| SH-1 | SH-2 | |||
|---|---|---|---|---|
| Scheduled | MA | Scheduled | MA | |
| N (cases) | 7685 | 7685 | 3597 | 3597 |
| RMSE | 61.5 | 51.5 | 57.5 | 48.2 |
| MAE (mins) | 37.7 | 29.2 | 34.8 | 29.5 |
| MAPE (%) | 7.49% | 2.40% | 15.91% | 5.54% |
| <=80% | 41.0% | 36.8% | 20.2% | 24.7% |
| 80–120% | 24.8% | 36.6% | 41.4% | 49.8% |
| >=120% | 34.2% | 26.6% | 38.4% | 25.5% |
| Model | Percentage within +\−20% | RMSE | MAE | MAPE |
|---|---|---|---|---|
| Listing | 24.68% | 62.31 | 37.505 | 65.57% |
| MA | 37.66% | 55.16 | 28.844 | 46.85% |
| Model 0 | 40.31% | 48.15 | 26.323 | 36.74% |
| Model 1 | 43.15% | 47.88 | 25.221 | 34.61% |
| Model 2 | 43.28% | 47.30 | 24.938 | 35.56% |
| Model 3 | 41.34% | 46.26 | 25.426 | 34.97% |
| Model 4 | 42.89% | 45.30 | 24.325 | 34.50% |
| Model 5 | 44.06% | 45.18 | 23.986 | 34.40% |
| Model | Percentage within +\−20% | RMSE | MAE | MAPE |
|---|---|---|---|---|
| Listing | 43.06% | 53.57 | 32.167 | 27.63% |
| MA | 48.33% | 45.39 | 28.19 | 27.30% |
| Model 0 | 49.86% | 50.845 | 30.492 | 27.23% |
| Model 1 | 52.78% | 38.817 | 24.412 | 23.83% |
| Model 2 | 55.42% | 40.9 | 25.529 | 24.90% |
| Model 3 | 55.28% | 43.208 | 26.18 | 24.54% |
| Model 4 | 55.42% | 39.367 | 24.518 | 23.79% |
| Model 5 | 56.11% | 38.482 | 23.61 | 23.36% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lam, S.S.W.; Zaribafzadeh, H.; Ang, B.Y.; Webster, W.; Buckland, D.; Mantyh, C.; Tan, H.K. Estimation of Surgery Durations Using Machine Learning Methods-A Cross-Country Multi-Site Collaborative Study. Healthcare 2022, 10, 1191. https://doi.org/10.3390/healthcare10071191
Lam SSW, Zaribafzadeh H, Ang BY, Webster W, Buckland D, Mantyh C, Tan HK. Estimation of Surgery Durations Using Machine Learning Methods-A Cross-Country Multi-Site Collaborative Study. Healthcare. 2022; 10(7):1191. https://doi.org/10.3390/healthcare10071191
Chicago/Turabian StyleLam, Sean Shao Wei, Hamed Zaribafzadeh, Boon Yew Ang, Wendy Webster, Daniel Buckland, Christopher Mantyh, and Hiang Khoon Tan. 2022. "Estimation of Surgery Durations Using Machine Learning Methods-A Cross-Country Multi-Site Collaborative Study" Healthcare 10, no. 7: 1191. https://doi.org/10.3390/healthcare10071191
APA StyleLam, S. S. W., Zaribafzadeh, H., Ang, B. Y., Webster, W., Buckland, D., Mantyh, C., & Tan, H. K. (2022). Estimation of Surgery Durations Using Machine Learning Methods-A Cross-Country Multi-Site Collaborative Study. Healthcare, 10(7), 1191. https://doi.org/10.3390/healthcare10071191