1. Introduction
The two-dimensional (2D) bin-packing problem (BPP) is a combinatorial optimization problem classified as NP-Complete [
1] since no exact algorithm for this problem is known to run in polynomial time. Then, computational heuristics have to be used to find near-optimal problem solutions. 2D BPP consists of placing a set of usually small elements (pieces) in one or more large objects (bins) and optimizing some objective function. In digital printing presses, a bin is a paper sheet where elements (regular, irregular, or amorphous shapes) are placed without overlapping so that the residual area is minimal. The residual area is the difference between the paper sheet area and the sum of each of the shapes’ areas placed in it. It is then a geometric problem of optimally accommodating the shapes (regular, irregular, and amorphous) without overlapping them.
In the existing literature, there are several approaches to 2D irregular BPP. In [
2], a Constructive Algorithm (CA) to the nesting problem with irregular pieces is introduced. The solution is built by successively adding a new one to a set of pieces previously placed on a plate. Several criteria to choose the next piece to be added and to define its orientation are also proposed. A not-fit polygon (NFP) algorithm to determine the feasible location points in the placed pieces’ contour is used. In [
3], a tutorial of the primary geometric methodologies currently used for cutting and packaging irregular pieces is provided. They use the NFP algorithm as their insertion procedure. This algorithm traverses the inserted pieces’ contour, trying to place a new one as close as possible to this contour, considering its concavities. In [
4], authors explore different problem representations and mechanisms to move between solutions and evaluate basic approaches to solve them. In [
5], one ordered list of pieces to be packed represents the 2D irregular BPP, which is solved using both TOPOS and beam-search approaches. In [
6], the 2D irregular (convex) BPP with guillotine constraints is solved using three two-stage strategies. These strategies first place one or two pieces in a rectangle area that is then packed using a competitive algorithm.
In [
7], a one-dimensional (1D) BPP heuristic is adapted to solve the 2D irregular BPP. The authors carried out several tests using a wide variety of convex polygons and applied various insertion techniques, such as First Fit (FF), First Fit Decreasing (FFD), First Fit Increasing (FFI), Filler, and Best Fit (BF). Unlike the NFP method, these strategies insert polygons, omitting their concavities. The insertion is carried out by ordering the polygons and placing them, starting in the coordinates (0,0). In [
8], several variants of a constructive algorithm able to solve a wide variety of 2D irregular BPP variants are described. This algorithm first applies an Integer Programming model to assign pieces to bins and then uses a Mixed Integer Programming model for placing the pieces into the bins. The second stage tests a promising set of rotations for the piece and puts the one that fits the piece into the bin. A tested method is the FF algorithm, which is similar to the FFD method proposed in [
9] to solve the 1D BPP. FFD takes an ordered list of pieces and assigns them sequentially to bins. To assign a piece, FFD examines the bins in the order they are opened and places the piece in the first bin that it will fit into. If the piece does not fit in any existing bin, a new one is created, and the piece is assigned to it. This algorithm is efficient but critically dependent on the initial order of the pieces. In [
10], an evolutionary hyper-heuristic that chooses the best of six deterministic algorithms to solve BPP instances, either 1D or 2D, and uses regular or irregular pieces is introduced. In [
11], the Heuristic Search Diversification Mechanism (HSDM), addressing both the piece allocation and placement problems together, is proposed. The authors implemented several strategies to handle piece rotations, such as Bottom-Left, Minimum-Length, and Maximum Utilization. These strategies can use a set of four angles or unrestricted rotations. In [
12], a review about mathematical models for the cutting and packing problem using 2D/3D construction techniques is detailed. Furthermore, authors use the technique to insert each piece at the bottom left of another already inserted. This technique considers the pieces already inserted to avoid overlapping between them and to be able to fill the spaces that were left empty in previous insertion stages. Finally, in [
13], one improved typology of cutting and packing problems is introduced, based on the one proposed by Dyckhoff [
14], but with a new criterion and setting new and different categories. The authors demonstrated the typology viability, classifying the papers in the existing literature between 1995 and 2004.
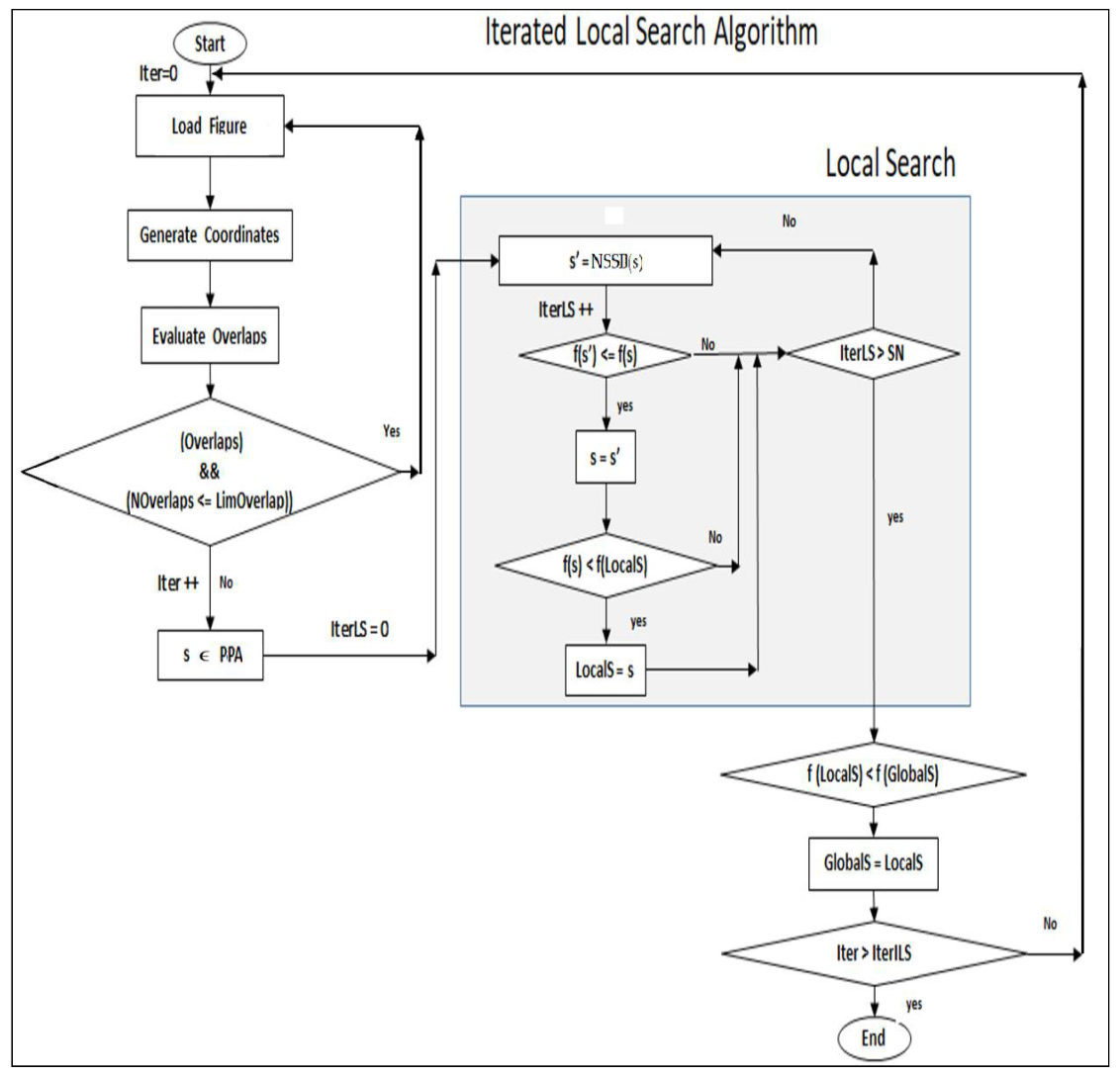
Unlike the approaches proposed in the existing literature, this article presents an iterated local search-based approach to insert pieces in bins. The iterated local search (ILS) is a powerful technique, simple to implement, robust, and highly efficient to traverse a complex solution space and reach near-optimal solutions [
15,
16]. In particular, in this paper, ILS uses a neighborhood structure that consists of making small movements on pieces previously placed in the bin to obtain more available space for new pieces. This neighborhood structure has been successfully used to solve various NP-complete problems [
1]. For the paper waste reduction problem, the neighborhood structure is determined using a geometry-based method for overlap detection between pieces (regular, irregular, amorphous, or a combination of them) [
4] and achieving feasible and optimized results. The experimental results show that this approach works efficiently and effectively to detect and correct the overlaps between regular, irregular, and amorphous figures.
The rest of this paper is organized as follows.
Section 2 describes the paper waste reduction problem using a graphical representation and mathematical model based on the 2D BPP. The neighborhood structure proposed in this paper, as well as the ILS algorithm to solve the problem, is detailed in
Section 3.
Section 4 presents the experimental results obtained by the proposed method, and the comparison with those of several algorithms in the existing literature using five benchmark problems. Finally, the conclusions of this work are discussed in
Section 5.
4. Experimental Results
The experimental tests were carried out on a HP PC computer (México, City) with an, Intel Core i7-870 2.93 Ghz CPU and 5.0 GB RAM, using a Windows 10 operating system, install from the factory by HP with a Microsoft Visual C ++ 2012, and the Allegro Ver 5.0 with free software license (GitHub, Inc.) for the overlap detection.
For the initial ILS tests, amorphous pieces, such as those presented in
Figure 2, were used.
Figure 4 depicts the landscape behavior of 500 tests carried out, each one consuming 500 seconds. The parameters shown are (1) shapes (the number of pieces placed on the PPA), (2) residual area, and (3) overlaps (the number of overlaps generated). The red rectangle in
Figure 4 encloses the best solutions found using a high number of attempts (based on the number of checked overlaps before reaching a feasible solution). This figure also shows a portion enclosed in a grid of black lines, indicating the best values reached using the fewest attempts. These values ranged between 48 and 50 for the number of pieces placed on the PPA. ILS obtained the best solution when the objective function with 50 pieces was placed on the PPA.
It is interesting to see the difficulty degree of obtaining feasible solutions. Suppose the solutions had a more significant number of pieces inserted on the PPA. In that case, ILS could generate many overlaps before finding improved solutions. However, the best solutions found generated close to 500,000 to 1,500,000 overlaps. In contrast, solutions with a lower value (marked in
Figure 4 with a red rectangle) used 46 and 47 pieces and detected close to 3,500,000 overlaps. This result is interesting since it points out that a local search finds a better trajectory in the solution space, avoiding further exploration of the best solutions.
Table 1 shows the best and worst values and the mean and mode of the objective function values. The PPA value was 983,040 square pixels. The area of each piece was 7242 square pixels. The best solution obtained from the implemented algorithm’s objective function represents 63.16% of the occupation area. This data was obtained considering the pieces inserted on the PPA and the PPA without pieces.
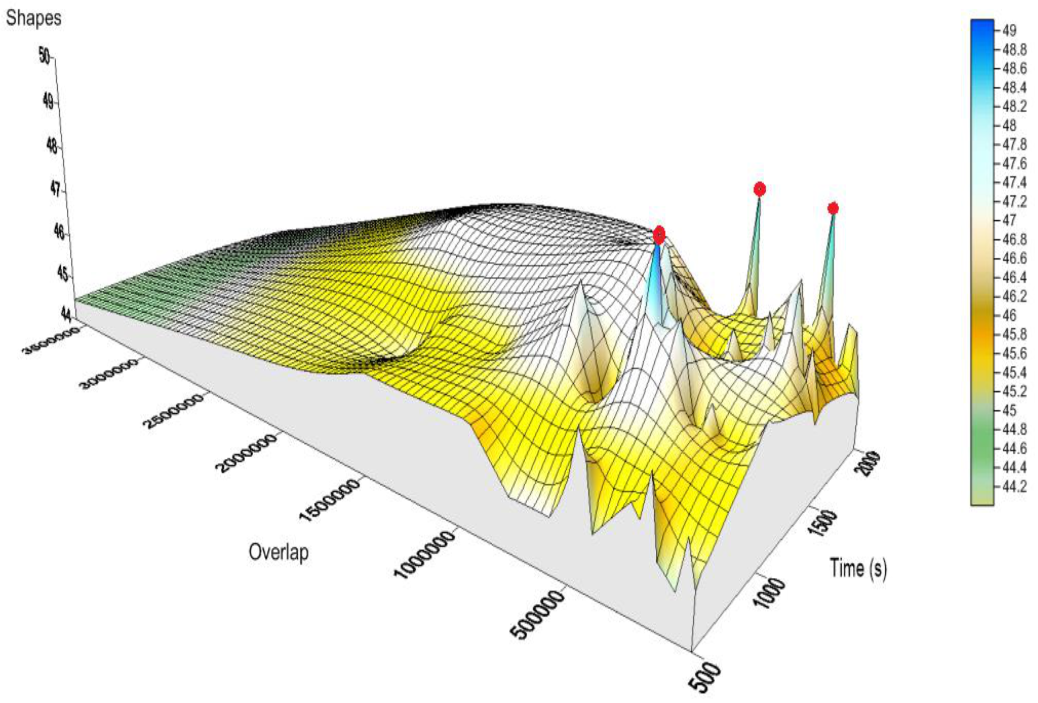
Figure 5 shows the landscape behavior as a function of time. This graph is based on the number of pieces, the number of overlaps, and the execution time in seconds, using 120 experimental tests.
The total ILS iterations are 10,000. The best solutions obtained are within the range of 100,000 to 1,500,000 overlaps, with 1000 and 2000 s of execution time, as shown in
Figure 5. The red dots identify the best solutions on the figure. It can be seen that the worst solutions were when the number of overlaps increased until approximately 2,000,000 overlaps. Peaks and valleys are observed in the figure, representing the best and worst solutions, respectively. This behavior indicates that the quality increase is not directly or inversely proportional to the ILS execution time. It is observed that bad solutions in the landscape surround the best solutions. This behavior indicates that the ILS execution can find good solutions in each of its executions.
Table 2 and
Table 3 show a summary of all results obtained by the implemented algorithm.
From the values in
Table 2 and
Table 3, it can be concluded that the best solutions obtained by the algorithm were in the time intervals between 1000 and 1500 s, with 50 pieces. However, in the time interval of 2000 s, a solution of 49 pieces was found.
The graph in
Figure 6 shows the landscape behavior as a function of time.
In
Figure 3, the behavior of the parameters on 120 experimental tests is represented. In this figure, bad solutions can be distinguished based on the largest residual area, which stands out in the landscape peaks. The worst and best solutions are displayed in the landscape using yellow and red dots, respectively. It can be seen that the worst solutions increased the number of overlaps to about 2,000,000. A black point in
Figure 6 identifies the worst solution obtained by the objective function. This point is located on the upper right corner of the graph, specifically where the blue part of the landscape with the worst solutions is located. The algorithm behavior is considered variably since the surface describes an irregular landscape where the best solutions are found. The total iterations were 10,000.
Table 4 and
Table 5 represent a summary of the results obtained by the objective function. It is observed that the best and the worst values are 620,940 and 671,634 square pixels, respectively. The best solutions found in the time intervals of 1000, 1500, and 2000 s were 620,940, 620,940, and 628,182 square pixels, respectively, with 63.13% and 63.90% of the PPA used. In these intervals, the algorithm consumed more time applying perturbation movements to exploiting the solutions space.
Comparative tests of the ILS algorithm were performed with other algorithms proposed in the existing literature, using the following benchmark instances [
2]: Shapes 0, Shapes 1, Shapes 2, Shirts, and Swim.
Table 6 presents the pieces in each instance. For the Shape 0 instance, 4 different shapes were required. For the Shape 1 instance, 6 different shapes were required. For the Shape 2 instance, 7 different shapes were required. For the Shirts instance, 8 different shapes were required, and for the Swim instance, 10 different shapes were required. The sizes of each figure used for ILS testing were the same. Note that no amorphous shapes were used in these instances, and studies in the existing literature with comparable results did not use rotational movements either. They placed the pieces to build sets with different orientations (0°, 90°, 180°, and 270°) before inserting them into the bin. In the algorithm proposed in this paper, some figures were rotated before introducing them to ILS to match the solution presented in the existing literature, since in this work, ILS does not handle figure rotation.
Table 7 presents the comparative tests of ILS with other algorithms in the existing literature, including the Constructive Algorithm (CA) [
2], the Placement Heuristic with Not-Fit-Polygon (PHNFP) [
5], the First Fit algorithm (FF) [
8], and the Heuristic Search Diversification Mechanism (HSDM) [
11]. In these methods, the number of pieces is kept constant and the paper size is reduced until the same number of pieces can no longer be inserted. In the case of the ILS procedure, the paper size is kept constant (40 × 80 units). To use pixels, a transformation of those dimensions from world coordinates to screen coordinates is conducted to obtain the sheet size in pixels, which is 625 × 1250, with a total sheet area of 781,250 pixels. It is observed in this table that ILS takes more time than the others to find the same solution. This behavior is due to the fact that the overlap detection algorithm used by ILS must be generating the mask of each piece moving in the PPA to find a new neighboring solution s’. This algorithm always considers amorphous pieces even if they are not present. Therefore, it was necessary to evaluate the pixels mask representing the piece for overlapping detection. However, the solutions presented in
Table 7 of each instance were found. As the ILS algorithm does not have some rotation procedure, the pieces were previously rotated to be used in the algorithm to compare the results with those described in the existing literature. For example, in Shape 1 instance shown in
Table 6, 4 pieces of type 5 were used and 2 pieces (5 and 6) were rotated before introducing them to the algorithm. It has been established that in future work, the pieces will rotate at any angle to improve the ILS algorithm efficiency.
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
Figure 11 present the solution for the five instances. These are the same as those found for the compared algorithms. However, the locations of the pieces in the PPA were naturally different and the residual area was huge.
Table 8 presents the optimized ILS tests with the benchmark instances of
Table 6 based on a time limit of two hours, keeping the sheet size constant and increasing the number of inserted pieces. There were 30 tests performed for each instance, and the best, worst, and mode solutions are presented. ILS could insert more pieces in the same sheet size if the time increased to 2 h. However, the percentage of residual area was still huge (between 36.78% to 66.52%). It is not possible to compare the results of other methods described in the existing literature, since they reduce the bin area using a constant number of pieces to be inserted. Alternatively, the method proposed in this study was used to optimize the paper waste in digital printers where the paper area was constant. However, if irregular pieces with few concavities were used, the results of other authors were better than the method proposed in this work. RA is the residual area in percentage, and RAOp is the optimized residual area in percentage, both measured in square pixels.
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
Figure 16 show the ILS algorithm’s solution for each instance with 2 h of processing time. In each figure, can be observed that several pieces presented an approach within the mask of inactive pixels. This allowed for a better approach without overlapping the pieces’ edges (regular, irregular, amorphous, or a combination). This behavior can allow for a more significant number of piece insertions when amorphous pieces are used.
Each piece used in the instances described in
Table 6 had a reduced number of vertices and few concavities. The complexity to compute overlaps in two convex pieces, A and B, is
O(
nm), where
n and
m are the number of vertices of A and B, respectively. Concavities found in concave polygons are a challenge to avoiding overlap between them, and are more difficult when there are a large number of concavities in the pair of pieces A and B. This problem has been dealt with in the literature by dividing each piece into convex polygons, which are simpler to deal with. A different approach is to slide a reference point of piece B around the circumference of piece A. Another approach uses diagrams, where the slope is computed only in the piece concavities requiring special treatment [
19]. The methods to overlap detection between a pair of pieces using trigonometric calculations have one increased time complexity to detect overlaps in irregular pieces when the number of concavities and vertices is increased. In this work, ILS generated a mask with the Allegro software for each inserted piece and used the
CheckOverlaps function of Algorithm 2, avoiding the use of trigonometric. Because no instances with amorphous pieces were found in the literature to be able to make comparisons with ILS, in this work, instances containing amorphous pieces were proposed.
Table 9 shows the instances proposed in this paper using amorphous figures. These figures have a huge number of vertices and concavities that are commonly printed in digital printers. Instances A0-A3 presented different piece designs to be able to evaluate the ILS procedure and check if the residual area increased according to the complexity of the inserted figures, depending on their vertices and concavities. Instance A0 showed several figures with pronounced concavities and a large number of vertices.
Table 10 presents the ILS results of running the algorithm for 2 h for each instance with amorphous pieces. There were 30 tests conducted for each instance. We observed that the residual area RAOp obtained for the four instances was similar to that obtained for the instances that handled few vertices and reduced concavities (
Table 8), except for Shape 2, where the inserted pieces had a larger area, allowing for better optimization of the RAOp. This behavior indicates that the execution of ILS does not have a visible effect when the number of vertices and concavities in the pieces to be inserted is high.
Figure 17,
Figure 18,
Figure 19 and
Figure 20, show the solution of the ILS algorithm for A0–A4 instances with 2 h of running time. We performed a comparison of the RAOp results with the instances presented in the literature with irregular pieces (
Table 8) and the proposed instances of amorphous pieces (
Table 10). From
Table 8, for the Shape 2 instance, where the RAOp was 36.78%, it can be seen (
Figure 14) that the pieces were larger than the other instances in
Table 8, indicating that when ILS inserts larger figures, it works more efficiently. If we see instance A0 (
Table 10), which obtains one of the best RAOp, it is observed (
Figure 17) that the figures were a little larger than instances A1 to A3, but we can also see that instance A3 obtained the best RAOp and presented the largest number of different pieces to insert. This behavior indicates that ILS works better when a greater number of different pieces are inserted and when they have a greater number of vertices and concavities.
For conducting the statistical analysis, both data normality and homoscedasticity were first verified. The test data were the run times (
Table 7) to obtain the same results in each evaluated algorithm (PHNFP, FF, HSDM, and ILS). The null hypothesis,
in Equation (11), indicates that the means of the results are equal. The alternative hypothesis, Equation
in (12), points out that the means are not equal, or at least one is different.
Figure 21 shows no normality for the data since the points are not located on the graph’s diagonal.
The homoscedasticity analysis is shown using the box-and-whisker graphs presented in
Figure 22. It can be seen that the boxes for each algorithm are not equal, so a difference in variances can be admitted, which indicates that homoscedasticity cannot exist. As the normality and homoscedasticity of the data do not exist, the parametric ANOVA test could not be used. Thus, a robust ANOVA with the Welch and Box tests [
20] was used.
Welch’s test, defined by Equations (13)–(23), uses weights
wi to reduce the data heterogeneity. The weights
wi in Equation (13) are based on the sample size
ni of the data generated by the
i-th algorithm and the observed variance
s2w,i for each
i-th group of data generated by the
i-th algorithm. For the
i-th group of data generated by the
i-th algorithm,
where
ni is the sample size of the i-th algorithm,
s2w,i is the winsorized variance (of the trimmed data),
hi is the adequate sample size of the
i-th group (number of observations remaining after the cut-off).
where
are the trimmed means.
From the
Fw statistic, if
H0 is true, then a Snedecor
Fw distribution with
v1 and
v2 degrees of freedom is used, where
Then, the decision rule to control the significance level
α is
If Ho is true, the Fw statistic follows a Snedecor probability distribution with degrees of freedom.
The robust generalization of the Box test is presented in (24)–(27), where the
Fw statistic is as follows:
where
The null hypothesis is rejected for large values of the
Fw statistic. If the null hypothesis is accepted, it follows a Snedecor F-distribution with the following freedom degrees:
where
In this work, the statistical analysis was carried out using the robust ANOVA test, defined in Equations (12)–(23) with Welch’s test and (24)–(30) with Box’s.
Welch was implemented in the
t1way (
x,
tr,
grp) function of the WRS R package [
21]. In the
t1way function,
x is the data,
tr is the trimmed means, and
grp indicates the subset size to be compared. In this case, 4 algorithms were compared using 10% of the trimmed means. A
p-value of 3.315954 × 10
−4 was obtained. The null hypothesis was refused since there were differences between the algorithms’ trimmed means. The
Fw value was 26.45909, and the freedom degrees were
v1 = 3, and
v2 = 7.039397, with
= 0.95, the
v1 and
v2 values, Fisher table values [
22], and a Snedecor value of 4.347. Since
, the
H0 was refused, indicating that differences in the trimmed means existed.
The robust generalization of the Box test was implemented with tr = 10% in the box1way (
x,
0.1) function of the WRS R package [
21]. A
p-value of 6.406586 × 10
−3 was obtained,
Fw was 13.219, and
v1 and
v2 were 1.527593 and 6.5418, respectively. The Snedecor value was 7.322 and the null hypothesis was refused (
). These values indicate that differences existed between the behaviors of the analyzed algorithms.



 ,
, 


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




























































