Abstract
An RNA bi-structure is a pair of RNA secondary structures that are considered as arc-diagrams. We present a novel weighted homology theory for RNA bi-structures, which was obtained through the intersections of loops. The weighted homology of the intersection complex X features a new boundary operator and is formulated over a discrete valuation ring, R. We establish basic properties of the weighted complex and show how to deform it in order to eliminate any 3-simplices. We connect the simplicial homology, , and weighted homology, , in two ways: first, via chain maps, and second, via the relative homology. We compute by means of a recursive contraction procedure on a weighted spanning tree and via an inflation map, by which the simplicial homology of the 1-skeleton allows us to determine the weighted homology . The homology module is naturally obtained from via chain maps. Furthermore, we show that all weighted homology modules are trivial for . The invariant factors of our structure theorems, as well as the weighted Whitehead moves facilitating the removal of filled tetrahedra, are given a combinatorial interpretation. The weighted homology of bi-structures augments the simplicial counterpart by introducing novel torsion submodules and preserving the free submodules that appear in the simplicial homology.
1. Introduction
This paper is concerned with the weighted homology of the nerve complex of RNA bi-structures [1]. The weighted nerve complex of such bi-structures provides a framework for studying the computational complexity of algorithms for identifying sequences that are thermodynamically stable with respect to a given bi-structure. Such sequences hold the key for evolutionary optimization [2].
The weighted homology introduced here augments the simplicial homology by making the weights of the simplices an integral part of the theory. In our situation, these weights encode the cardinality of intersections of loops in a bi-structure. Along the lines of [3], the notion of a weighted complex is introduced. Differently from [3], the weights of simplices in this paper are taken from a discrete valuation ring that contains a copy of the integers as units and in which the weight of a simplex divides the weight of its faces.
1.1. Background
RNA sequences are linear, single-stranded sequences composed of the bases A,U,G, and C. In contrast to double-stranded DNA, RNA sequences fold into structures (see Figure 1). A particularly important class of RNA structures is that of RNA secondary structures [4]. Secondary structures can be represented as planar, non-crossing arc diagrams [5,6]. By means of its folded structure, RNA facilitates a plethora of important functional roles [7]. The boundary components of an RNA secondary structure, when viewed as a fatgraph [8], are called loops, and they determine the minimum free energy of the structure.
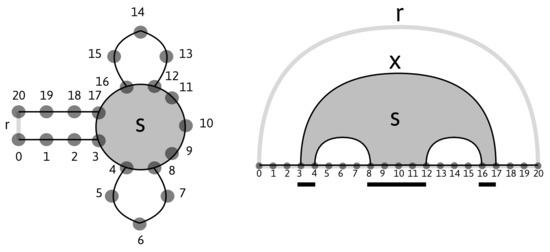
Figure 1.
Left: a planar RNA secondary structure with a closing base pair . Right: its diagram representation on the set of vertices with two additional vertices, 0 and 20, forming the rainbow , the loop (shaded), and the corresponding intervals (underlined). The arc is the maximal arc of s, .
Secondary structures have been studied from the perspectives of enumerative combinatorics [9,10,11,12], algebraic combinatorics [13], matrix models [14,15], and topology [16,17,18].
In [10], a bijection between linear trees and secondary structures was presented. In [13], the authors enumerated k-non-crossing RNA structures by employing a bijection between k-non-crossing partial matchings and walks in the interior of the Weyl-chamber based on a certain bijection between oscillating tableaux and matchings [19,20,21]. The geometrical realization of a certain complex of secondary structures was studied in [22].
A key determinant of a sequence–structure pair is its thermodynamic stability, which is measured via its free energy. Given a sequence , RNA structure prediction algorithms identify structures by assuming minimal or low free energy with respect to [23]. Given any RNA sequence–structure pair , the free energy is computed by adding all loop energy contributions [24,25], i.e., . Here, depends on the loop type of s (hairpin, interior, multi-branch, etc.) and the particular nucleotides of the sequence a that appear in the loop s. Details on loop decompositions, partition functions, and recursive constructions for the folded structure—derived via polynomial-time dynamic programming (DP)—can be found in [9,23,26,27,28]. In [12], the notion of bi-secondary structures was introduced. Bi-secondary structures are central to identifying sequences that can realize two mutually exclusive minimum free energy (mfe) conformations. Such sequences naturally appear in the context of evolutionary transitions [29] and of RNA riboswitches, i.e., sequences that exhibit two distinct, stable configurations [30].
1.2. Motivation
This paper was motivated by the problem of computing thermodynamically stable sequences for two distinguished secondary structures, S and T [2]. The problem can be formalized as the computation of a sequence a that minimizes , where
The sub-problems of the underlying DP routine are associated with sets of loops and recursively constructed by adding one loop at a time, where subsequently added nucleotides affect the energy calculation if they appear in multiple loops simultaneously; see Figure 2. This leads to the consideration of all such intersections as a simplicial complex, X, whose homology provides insights into the above optimization problem.
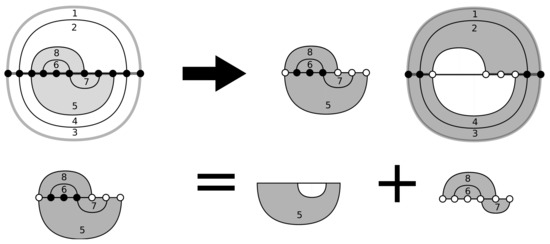
Figure 2.
Top: a bi-structure decomposed into a distinguished sub-structure and its complement. The vertices contained in both (white) control the complexity of the dynamic programming (DP) routine in [2]. Bottom: the recursive step of the DP routine. Note that the recursion changes the set of white vertices by removing some and adding others.
In [1,31], we computed the simplicial homology groups of X and proved that only the second homology group carries information. This group was identified to be free, and its generators were identified as the crossing components within the diagram representation. All known RNA riboswitches exhibit one such crossing component, while random pairs of structures contain multiple crossing components.
The simplicial homology of X in [1] only allows us to express the existence of loop intersections. However, the crucial determinant for the algorithmic complexity of the DP routine in [2] is the size of such intersections; see Figure 2. The recursion is over the set of loops, successively examining one loop at a time. Each such examination affects certain vertices that the currently examined loop shares with the unprocessed loops.
It is thus natural to employ a homology theory that accounts for the intersection size. The notion of weighted homology as originally formulated [3], assigns a certain weight to each simplex, imposing specific divisibility conditions on these weights.
Our framework represents a variation on weighted homology as follows: We consider homology with coefficients in a discrete valuation ring, which, in fact, makes any divisibility constraints obsolete and allows us to deal with the cardinality of intersections in a natural way. The boundary operator introduced here is new, and so is our approach to connecting the weighted and simplicial homologies. More specifically, the construction of an inflation map relating and is a new technique. The computation of the weighted homology groups, , , and , is also novel. Specifically, the idea of obtaining a combinatorial interpretation for the invariant factors in the structure theorems for and via particular -spanning trees is original. The chain maps between and , which relate the and introduced here, are new and nontrivial. In particular, the injection that induces the isomorphism is a result of the fact that, in the expressions for the generators of , any triangle has a corresponding intersection size of one.
1.3. Organization
The paper is organized as follows: In Section 2, the simplicial loop complex of a bi-structure is introduced and the splicing of nucleotides is recalled [1]. In Section 3, the weighted complex of a bi-structure and a modified splicing procedure are discussed. In Section 4, the weighted homology and simplicial collapses [3,32] are introduced. In Section 5, a relative point of view is adopted by relating the simplicial and weighted homologies. Specifically, we introduce the inflation map, which maps classes of unweighted 1-cycles into corresponding weighted 1-cycles. In Section 6, we construct certain spanning trees that will be instrumental for proving our main results in Section 7. Here, we compute the weighted homology modules of bi-structures and provide combinatorial interpretations. The torsion module emerging in the zeroth homology stems from a recursive contraction scheme on the distinguished weighted spanning trees of the complex. The torsion of the first homology module can be understood via particular weighted edges that reference the aforementioned spanning tree. We conclude the paper with the computation of the second homology module, with all others being trivial. We integrate our results and outline future work in Section 8.
2. The Simplicial Loop Complex of a Bi-Structure
An RNA diagram S over the set is a vertex-labeled graph—whose vertices represent nucleotides—drawn on the horizontal axis and labeled with elements of the set . An arc , is an ordered pair of vertices, which represents the base pairing between the i-th and j-th nucleotides. Each S-vertex can be paired with at most one other vertex, and the arc that connects them is drawn in the upper half-plane. An RNA diagram over the set is augmented with two additional vertices associated with positions 0 and , together with the arc , which is called the rainbow, representing the closing base pair of the external loop of the RNA structure; see [23]. The set of vertices is called an interval, and is denoted by . The set is referred to as the backbone of the diagram. Two arcs, and with , are called crossing if and only if . S is called a secondary structure if it does not contain any crossing arcs. A loop s in a secondary structure S is represented as the disjoint union of intervals , such that and , for , are arcs, and any other interval-vertices are unpaired. We denote by the unique, maximal arc of the loop s, and we have a correspondence between loops and their maximal arcs; see Figure 1.
S-arcs and loops can be endowed with a partial order: . Abusing the notation, for the two loops , we write if . Accordingly, (a) any unpaired vertex is contained in exactly one loop, (b) any non-rainbow arc appears in exactly two loops, and (c) the Hasse diagram of is a rooted tree with the rainbow arc as the root.
Given two secondary structures S and T, we refer to as a bi-secondary structure (bi-structure). Abusing the notation, we let be the loop set of R. We represent a bi-structure with the S-arcs in the upper and the T-arcs in the lower half-plane along the same horizontal backbone.
Let be a collection of finite sets. We call a d-simplex of A if . We set and let . Let be the set of all d-simplices of A. Then, the complex (nerve) of A is A -simplex is called a -face of B if and . Let be a -face of a maximal simplex B, where . Then, is B-free if no other maximal simplex of contains as a face. By construction, is a simplicial complex. For a secondary structure S, is a tree.
Let be a bi-structure with the loop complex . Then, a simplicial order, , is given by
We specify a d-simplex, , by the ordered -tuple , where .
A 1-simplex is called pure if and are loops in the same secondary structure and mixed otherwise; see Figure 3.
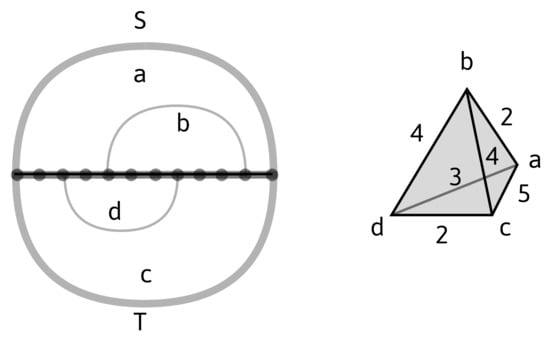
Figure 3.
Left: a bi-structure with S-loops , S-rainbow arc , T-loops , and T-rainbow arc . Right: its weighted loop nerve (with and being pure edges, and any other edge being mixed), and . We have , , , , , while the weights of 1-simplices are displayed directly in the figure.
By construction, any 2-simplex contains exactly one pure and two mixed edges. Furthermore, X cannot contain simplices of a dimension greater than or equal to four, as that would imply that three or more loops in the same secondary structure intersect non-trivially. Moreover, for any , and .
In [31], we investigated the effect of splicing a nucleotide p into two adjacent nucleotides such that the two arcs incident to p were resolved into two non-crossing arcs. In the case , splitting does not change X, and if , splitting induces a specific alteration: the removal of from X, as well as a distinguished free edge, , and exactly two free triangles, , glued at . We refer to as a -butterfly; see Figure 4.
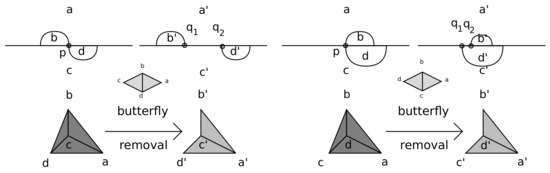
Figure 4.
Splicing and removing tetrahedra together with their corresponding butterflies.
Lemma 1.
Let be a bi-structure with complex X; then, there exists a simple bi-structure with a complex , where is derived from X by successively removing any 3-simplex, σ, together with an associated σ-butterfly.
Thus, successively splicing all nucleotides in P induces a bi-structure , together with an associated complex , which is obtained by removing all -butterflies and their corresponding s from X.
Removing a -butterfly and its corresponding is equivalent to —a simplicial collapse consisting of two elementary collapses [32,33]. The first removes and , and the second removes and .
Proposition 1.
Let X be the loop complex of a bi-structure , and let be an X-sub complex obtained by removing all 3-simplices, σ, from X, together with corresponding σ-butterflies. Then, is the complex of a bi-structure that satisfies for any , .
Note that after splicing, we have simplified X to a complex of a bi-structure, , thus reducing its maximum simplex dimension and maintaining its homology. In the following, we generalize this to weighted complexes.
3. -Splicings and the Weighted Complex of a Bi-Structure
We begin by modifying the splicing introduced in Section 2 as follows: Instead of replacing a nucleotide by the two nucleotides , we substitute it by three nucleotides, , such that the arcs in R that share p as an endpoint now have endpoints and , which are non-crossing, and a is unpaired. We call this a -splicing of p.
Note that -splicing and splicing all have exactly the same effect on X—namely, eventually removing any 3-simplex and a corresponding -butterfly. In terms of bi-structures, from , -splicing P produces the bi-structure augmented by a set of distinguished, unpaired nucleotides , which only appear in 0- and 1-simplices. By construction, the complex of does not contain any 3-simplices. Furthermore, after -splicing P, any distinguished nucleotide produced is flanked by two distinct endpoints of non-crossing arcs. Thus, for any simplex , we have , where denotes the difference between the number of non-distinguished and distinguished nucleotides contained in . Note that h is a natural generalization of in the context of complexes of bi-structures. Accordingly, we define a weighted complex associated with a bi-structure as follows.
First, we recall that a ring R is called a discrete valuation ring if it is a Principal Ideal Domain (PID) with exactly one non-zero maximal ideal. Any irreducible element is a generator of this ideal and is called a uniformizer for R, and furthermore, any two such elements differ only up to multiplication with a unit.
Definition 1.
Let X be a complex of a bi-structure such that for any , we have . Let be a discrete valuation ring with uniformizer π. We define the weight function , , and call the weighted complex of .
Lemma 2.
Let be a bi-structure with no distinguished vertices and complex X. Let be derived from via μ-splicing P, and we denote its complex by . Then, there exists an embedding
where is a X-subcomplex obtained by removing any 3-simplices and associated butterflies. Moreover, ϵ is an embedding of weighted complexes: .
Proof.
Successively -splicing P generates the series of complexes . By construction, given and a 3-simplex , the corresponding -splicing at p replaces p with the triple . Since is unpaired, is contained in exactly two loops, , the only two loops that change size in terms of number of nucleotides when passing to . Since the distinguished nucleotide contributes a , we note that and ; furthermore, . Any other -simplex—differently from and its -butterfly, which are removed—is not affected by the splicing, and consequently retains its weight in , whence the lemma. □
4. Weighted Homology
Consider , where denotes the free R-module generated by all n-simplices contained in X. Let be given by
where the symbol is defined to be . This is, in view of , a non-negative power of the uniformizer and, hence, still an element of the ring R. As a result, the boundary operator is well defined. Since , we obtain , i.e., is a boundary map.
Let denote the -homology groups. For , we have
and we denote the relative homology groups by . These are connected via the long exact sequence
Lemma 2 guarantees that, for any weighted complex of a bi-structure , there exists a bi-structure with a weighted complex such that and where . Thus, the relative homology groups and their associated long sequence are well defined.
However, a weighted complex does not have to be induced by a bi-structure. The previous definitions still hold as long as for an arbitrary -pair. Weighted complexes represent a general combinatorial-algebraic framework that enhances the simplicial homology for a wide range of applications. The next proposition extracts the algebraic core of -splicings; it represents a variation of [32], and it also appears in some form in [3].
Proposition 2.
Let be a weighted complex and let such that: (a) τ is σ-free; (b) . Let Y be the X-subcomplex obtained by removing any (). Then,
Proof.
Claim 1. It suffices to prove the Lemma for a σ-free τ with the property .
We may assume that and . The lattice of sub-simplices of is isomorphic to a binary k-cube, where cover relations are induced by face inclusions.
We prove by induction on k that a k-cube can be recursively decomposed into a sequence of pairs , where is a maximal simplex with a free face . The induction basis is immediate.
For the induction step, note that a k-cube decomposes into two disjoint copies of a -cube based on if the last coordinate is zero or one. By the induction hypothesis, for a -cube, there exists a sequence, , with the desired properties; appending one or zero as the last coordinate yields two mappings from the cube into the k cube. By construction, these form a family of disjoint-type embeddings, i.e., their images are injective copies of the -cube that are vertex disjoint in the k-cube. Accordingly, we obtain and . As the two sub-cubes are disjoint, we can immediately construct the desired sequence for the k-cube, ; the claim follows.
Claim 2. Let , where maximal, τ is σ-free, and . Then, for any , .
Note that only and are non-trivial. implies ; hence, . Note that , so implies ; thus, . Similarly, , so is also generated by . Now, , and so . Finally, for , , so for any , and Claim 2 follows.
The proposition is implied in view of Claim 2 and the following long exact sequence:
□
In view of and , for any and its corresponding -butterfly, Proposition 2 implies the following.
Corollary 1.
Let be the complex of the bi-structure , and let be the complex of that is obtained by completely μ-splicing . Then,
5. The Inflation Map
In view of Corollary 1, we can assume that X is the complex of a bi-structure with the property , where denotes the simplicial complex induced by all k-simplices in X [34]. Clearly, the natural embedding is an embedding of weighted complexes, and we have the exact sequence
producing the long exact sequence
We now adopt a relative point of view by relating the simplicial homology to the weighted homology . To this end, we consider the following two segments of the long homology sequences
where the surjectivity of is given by [1].
While these sequences belong to different categories, the first two vertical maps are natural injections and relate simplicial and weighted homology modules.
Indeed, the first vertical injection is induced by chain maps of the form , , which make the following diagram commutative:
The second vertical injection is given by the fact that, since , is an R-submodule of and, by construction, and .
This motivates us to ask if there exists a -linear map that makes the above diagram commutative. It turns out that such a map exists and will prove useful for understanding .
Lemma 3.
The mapping
where , is well defined and -linear; the following diagram is commutative:
Proof.
By construction, it suffices to show that infl is well defined. Observe that, in view of sequence (1), is surjective. Hence, any can be expressed as , where is unique, modulo elements of . Secondly, in [31], we showed that
where ; is contained in the -crossing component and .
Any face e contained in appears with opposite signs in two distinct the 2-simplices and , where . Therefore,
i.e., ; infl is well defined, and a lemma follows. □
We next employ to obtain information about . is connected, and for a spanning tree , the free generators of are in bijection with ’s mixed cycle closing edges for . A generator is a sum of edges and the closing edge , with each such edge appearing exactly once. We fix as follows: Consider the trees of the sub-complexes for S and T, respectively, and let be the tree obtained by connecting the -roots with the mixed edge , corresponding to the two rainbow loops.
Lemma 4.
The following sequence of R modules is exact:
Proof.
With as above, consider a generator where, for , are pure S- or T-edges and while . Since is surjective, we can also write
This involves additional mutually canceling edges, k, all of which are mixed and appear as faces of pairs of 2-simplices, . Without loss of generality (w.l.o.g.), we can traverse the cycle beginning at via the pure S-edges until we arrive at , after which we return back to via the pure T-edges. Any pair satisfies either or , and we accordingly categorize the k edges into - and -edges, respectively. As a result, in
-edges persist with the coefficient, say , while all -edges cancel. Hence,
where . Note that only and are mixed -edges, and so .
Any set M of -cycles induces a set of distinct mixed faces . In the two sub-trees of S and T formed by the respective pure edges of the -paths, these mixed faces connect an S-leaf with a T-minimal vertex or a T-leaf with an S-minimal vertex. By construction, these edges are distinct from any of the produced by any M-cycle, and the coefficients of any of these in a linear combination are zero. Iterating this argument, we arrive at
Accordingly, freely generate , and the following diagram is commutative:
Since , we have whence
□
6. The Rank of
Next, we compute the rank of by constructing a basis. Note that an element in is a sum of cycles, and it is natural to ask what the analogue of a cycle in is.
Let be minimal in terms of the number of edges it contains. A straightforward computation shows that there exist with , where the multi-set is unique up to a scalar factor. This shows that, except for a scalar multiple, minimal cycles determine the distinguished cycles, and we shall call a cycle elementary if and is a minimal cycle. An elementary cycle is precisely the -analogue of a minimal -cycle.
In view of being connected, a basis of can be comprised of all minimal cycles derived from a fixed -spanning tree : Any non-tree edge added to this tree results in a unique minimal cycle in the basis that is labeled by the edge. One key observation here is that generates for an arbitrary spanning tree of .
To derive a basis of in an analogous fashion, an arbitrary choice of an -spanning tree is no longer sufficient because of the weights involved. However, in the following, we construct a distinguished tree that is particularly well suited to the understanding of the embedding of into .
Lemma 5.
There exists an -spanning tree, , such that the following sequence is exact:
Proof.
It suffices to construct such that . To this end, we fix an arbitrary -spanning tree and let . We examine M-edges one by one, yielding a chain of processed edges, , and a sequence of trees, . We claim that these have the property .
The above holds trivially for , and we assume that and are constructed with . Let and set . Then, there exist such that . Letting and leads to where, by construction, at least one edge has a coefficient of one. In case the , set . Otherwise, remove a -edge with coefficient one, and add to , obtaining . Note then that
By induction, when the processes terminates, it yields the desired . □
induces a new set of closing edges and the associated minimal -cycles . We shall show that the corresponding elementary cycles constitute a basis of .
Proposition 3.
There exists an isomorphism
Furthermore, is freely generated by the set of elementary cycles and has rank , where e and v are the numbers of 1- and 0-simplices in .
Proof.
is free, as it is a sub-module of the finitely generated free module over the PID R and . By construction, to each , there corresponds a unique elementary -cycle , whose coefficient is one. Furthermore, is non-torsion in ; if , R being an integral domain implies .
Claim. Any has the representation with a unique .
We proceed by induction on the number of -closing edges in c.
To establish the induction basis, let be the unique term that contains in c. Using the fact that appears with a coefficient of one in , we derive .
For the induction step, distinguishing as a closing edge summand in c, we have with . By inductive hypothesis, with unique coefficients , hence the claim.
From the claim and the fact that the are non-torsion, we conclude that
hence the proposition. □
7. The Modules of the Weighted Homology
By Lemma 5, we have
from which .
Since is a module over the PID R, we arrive at
where , and is the -torsion module of .
We shall proceed by computing . Note that the -tree is a spanning tree of , and generates . Thus, we can compute via . To this end, we process as follows: We select a -vertex and an incident edge for which is minimal. We contract onto by removing and replacing any edges of the form with while maintaining their original weights . Recursively contracting all edges in produces a sequence of trees , where is a single vertex at which point the process terminates. Relabeling the -vertices, we may assume that is removed at the ith step of this process.
Theorem 1.
There exists an isomorphism
where , as described above.
Proof.
Let denote the set of recursively contracted edges up to and including the mth step. Set , , and , where the formal fractions are well defined by the minimality of the denominator exponent. Note then that .
Claim 1. for any .
We proceed by induction on i, where Lemma 5 implies the induction basis . Consider the contraction at step i: . A -edge of the form induces the -edge with . Then,
implies , and Claim 1 follows by induction.
Claim 2. .
Let , where is removed from at the ith contraction step. We rewrite the z in terms of the . This is done recursively, starting with , as follows: Let be the coefficient of at step p. Then, implies , and we obtain the updated -coefficient
Processing all , we arrive at , and Claim 2 follows.
Claim 3. with .
By Claim 2, we have , and we make the following ansatz:
First, is a well-defined homomorphism: Suppose . Since is linearly independent from , , this immediately implies that . Claim 1 guarantees that , and consequently, there exist unique coefficients, , such that
In view of , we obtain
The linear independence of , in turn, implies that for any i, from which , and thus, .
is, by construction, surjective and does not have a nontrivial kernel from which Claim 3 follows.
By construction, , and as for the direct summands , for , we consider the mapping , . Suppose that ; then, implies that , so h is well defined. Clearly h is surjective, and it remains to check the injectivity. implies that and implies that , hence the theorem. □
We proceed by analyzing . We begin with the expression for in Lemma 4:
where is the 2-simplex containing the edge , and are mixed edges that appear when transitioning between 2-simplices with different weights that share a face.
The “troublemakers” here are the off-diagonal terms of the embedding, , which stem from passing from trivial to nontrivial crossing components and vice versa. We shall eliminate such transitions by appropriately deforming X without affecting its homology. We then have to check that the deformation gives rise to an inflation map that is just a restriction of the original inflation map for X. Let be a 2-simplex corresponding to a non-crossing arc, i.e., is maximal in X. W.l.o.g., we can assume that with . Then, is -free, and by construction, . Removing and from X produces a sub-complex with . By Proposition 2, we may remove all 2-simplices contained in X corresponding to non-crossing arcs together with their pure faces without changing the homology. Accordingly, the resulting is an X-sub-complex such that . Note that is, in general, not a complex induced by a bi-structure.
Lemma 6.
There exists an -spanning tree, , with .
Proof.
Let be a fixed -spanning tree. We then continue with -edge replacements, as in Lemma 5, and the process terminates with the -spanning tree , which has the property .
Note that a pure edge e that is not in can be written as , where is the unique 2-simplex containing the pure edge e. Since , we have or , depending on the sign of e in . Consequently, , and the lemma follows. □
Note that and . Furthermore, by Proposition 3, is generated by elementary cycles induced by . Hence, we can exploit the structure of in order to compute .
Theorem 2.
is an R-torsion module, and there exists an isomorphism
where is a closing edge of a minimal cycle with respect to .
Proof.
We begin by establishing that the inflation map naturally restricts to .
Claim 1. We have the commutative diagram
Clearly, and , and by the long homology sequences, and are embeddings. Lemma 6 shows that is also a -tree, from which is obtained from by just adding all elementary cycles induced by the pure edges that are not contained in . Consequently, removing these edges from is equivalent to restricting the inflation map to the sub-complex , and Claim 1 follows.
Claim 2. For , we have . As in Lemma 4:
where is the 2-simplex containing the edge , and are mixed edges that appear when transitioning between 2-simplices with different weights that share a face. By construction, for any , , and so no edges emerge in the inflation images. In particular, has the coefficient in . By Lemma 6 , and so the corresponding elementary cycle has the coefficient 1 at . Since is freely generated by all elementary cycles, Claim 2 follows.
is freely generated by and is free of rank . By Lemma 4, , from which is, by the structure theorem of finitely generated modules over PIDs, a full-torsion module. The exact sequence
implies that , and clearly,
□
Theorem 3.
The injection induces an isomorphism of R-modules:
Proof.
The long homology sequence for the weighted homology induces the exact sequence
where and . Hence, , and the sequence is exact. In view of and Proposition 3, all modules in the sequence are free and, thus, projective; hence, . Analogously, the exact sequence
of free modules implies that . Since
and , we can conclude that
Finally, since both and are free finitely generated modules over the PID R, the theorem follows. □
Remark 1.
Since , by construction, . As such, , and, in view of Corollary 1, this holds for weighted complexes stemming from arbitrary bi-structures.
8. Conclusions and Future Work
In this paper, we introduced the weighted homology of the nerve complex X of an RNA bi-structure. We demonstrated that the weighted homology of a bi-structure distinctively augments the simplicial homology.
In the simplicial homology, only the zeroth and second homology groups are nontrivial [1]. Since the complex of a bi-structure is, by construction, connected, the simplicial homology carries key information exclusively via .
The weighted homology not only conserves the information provided by the simplicial homology, but it also supplies additional information. Specifically, connectivity is still picked up by the free submodule of ; however, additional torsion now emerges. This torsion is given a concrete combinatorial interpretation via the compression algorithm on the spanning tree . In fact, the compression procedure naturally generates the free submodule of rank one at its final step.
In the case of , we consider and observe that the nontrivial chain maps , , produce an injection , in which all coefficients are one, since any 2-simplex contained in the expression of an -generator (i.e., appearing in a crossing component) has a weight of one. As a result, passing to the ring R preserves the information present in .
In the computation of , we employed the simplicial homology in a different way. Here, we consider the relative homology and transcend the information from the 1-skeleton, . While is trivial [1], carries information, which we can utilize by extracting from
the embedded exact sequence of Lemma 4. After resolving some technicalities, this allows us to compute . Note that passing to the deformation greatly simplifies the inflation map, and we observe that it acts on as would on the 1-skeleton.
The structure theorems for the weighted homology enable the classification of bi-structures by their R-modules. Such classifications can provide insights into the algorithmic complexity of problems involving bi-structures. For instance, the problem of computing thermodynamically stable sequences for a bi-structure can be efficiently solved in polynomial time when the second homology R-module is trivial [2].
As for future work, we shall extend the homological analysis to RNA–RNA interaction structures [35]. An interaction structure can be represented as a diagram with two backbones drawn horizontally on top of each other such that both intra-molecular and inter-molecular bonds are non-crossing; see Figure 5.
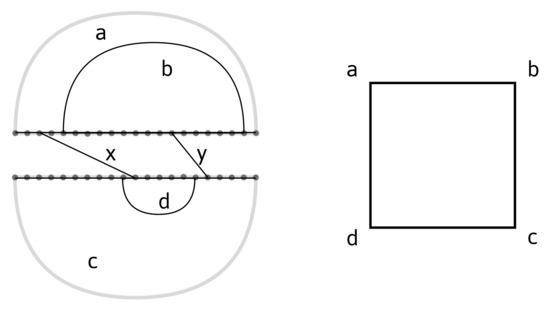
Figure 5.
Left: an interaction structure with two interaction arcs, x and y. Right: the corresponding interaction complex.
The inter-molecular arcs naturally induce an equivalence relation on the vertices of the two backbones. The intersection of two loops is accordingly defined to be the set of -equivalence classes of vertices that they share. A bi-secondary structure can then be viewed as a particular type of interaction structure—namely, an interaction structure with two identical backbones, where interaction arcs connect any pair for . In contrast to a bi-structure, an interaction structure can exhibit nontrivial first-simplicial homology and requires revisiting the notion of a crossing component for interaction structures. The analysis involves many more topologies—in particular, surfaces and Mayer–Vietoris sequences [34].
The framework of the weighted homology is by no means restricted to bi- or interaction structures. It also gives rise to the consideration of the dissimilarity complex of a finite set of genomic sequences, which we briefly discuss in the following. A multiple sequence alignment W of genomic sequences is defined to be a finite set of words of equal length m over the finite alphabet . For any , let be the map that returns the symbol at position k of a word, namely, for . A subset forms a d-simplex if there exists at least one position j such that . In other words, all sequences in contain mutually different nucleotide types at the site j. For a fixed , the number of different positions j for which the above holds is called the dissimilarity of . This leads to the aforementioned dissimilarity complex for genomic sequences; see Figure 6. This complex is, by definition, low dimensional; its highest dimension is . For , the 1-skeleton of the dissimilarity complex captures the well-known Hamming distance—the number of positions in which two genetic sequences differ. It may be worth pointing out that this framework integrates well-known generalizations of distances, as these appear naturally as weights in the dissimilarity complex. Triangle inequalities generalize to tetrahedron inequalities, etc., and this could enhance our understanding of genetic sequences. This is because basic constructs—e.g., trees, such as the tree of life—that reflect the ancestral relations between sequences depend on the notion of Hamming distance. Our preliminary investigations suggest that the homology of the dissimilarity complex captures evolutionary events. For example, the free rank of the first homology module gives bounds of the possible recombinations within the sequence set.
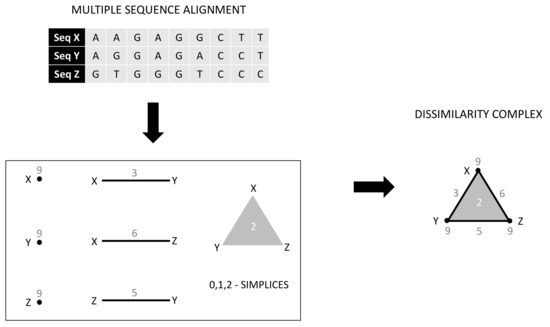
Figure 6.
A multiple-sequence alignment of three sequences , their corresponding weighted simplices, and the associated dissimilarity complex.
Author Contributions
Conceptualization, A.B., Q.H. and C.R.; writing, A.B., Q.H. and C.R.; review, A.B., Q.H. and C.R.; investigation: A.B., Q.H. and C.R. All authors have contributed equally to this work. All authors have read and agreed to the possible publication of the manuscript.
Funding
This research received no external funding; the authors received no external financial support for the research, authorship, and/or publication of this article.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
We gratefully acknowledge the comments from and discussions with Fenix Huang and Thomas Li. We also appreciate the constructive feedback provided by the anonymous reviewers.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bura, A.C.; He, Q.; Reidys, C.M. Loop Homology of Bi-secondary Structures. Discret. Math. 2021, 344, 112371. [Google Scholar] [CrossRef]
- Huang, F.W.; Barrett, C.L.; Reidys, C.M. The energy-spectrum of bicompatible sequences. arXiv 2019, arXiv:1910.00190. [Google Scholar]
- Ren, S.; Wu, C.; Wu, J. Weighted persistent homology. Rocky Mt. J. Math. 2018, 48, 2661–2687. [Google Scholar] [CrossRef]
- Holley, R.W.; Apgar, J.; Everett, G.A.; Madison, J.T.; Marquisee, M.; Merrill, S.H.; Penswick, J.R.; Zamir, A. Structure of a ribonucleic acid. Science 1965, 147, 1462–1465. [Google Scholar] [CrossRef] [PubMed]
- Thirumalai, D.; Lee, N.; Woodson, S.A.; Klimov, D. Early events in RNA folding. Annu. Rev. Phys. Chem. 2001, 52, 751–762. [Google Scholar] [CrossRef]
- Fresco, J.R.; Alberts, B.M.; Doty, P. Some molecular details of the secondary structure of ribonucleic acid. Nature 1960, 188, 98–101. [Google Scholar] [CrossRef] [PubMed]
- Darnell, J.E. RNA: Life’s Indispensable Molecule; Cold Spring Harbor Laboratory Press: New York, NY, USA, 2011. [Google Scholar]
- Chapuy, G. A new combinatorial identity for unicellular maps, via a direct bijective approach. Adv. Appl. Math. 2011, 47, 874–893. [Google Scholar] [CrossRef]
- Waterman, M.S. Secondary structure of single-stranded nucleic acids. Adv. Math. Suppl. Stud. 1978, 1, 167–212. [Google Scholar]
- Schmitt, W.R.; Waterman, M.S. Linear trees and RNA secondary structure. DIscrete Appl. Math. 1994, 51, 317–323. [Google Scholar] [CrossRef]
- Hofacker, I.L.; Schuster, P.; Stadler, P.F. Combinatorics of RNA secondary structures. Discret. Appl. Math. 1998, 88, 207–237. [Google Scholar] [CrossRef]
- Haslinger, C.; Stadler, P.F. RNA structures with pseudo-knots: Graph-theoretical, combinatorial, and statistical properties. Bull. Math. Biol. 1999, 61, 437–467. [Google Scholar] [CrossRef] [PubMed]
- Jin, E.Y.; Qin, J.; Reidys, C.M. Combinatorics of RNA structures with pseudoknots. Bull. Math. Biol. 2008, 70, 45–67. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Orland, H.; Zee, A. RNA folding and large N matrix theory. Nucl. Phys. B 2002, 620, 456–476. [Google Scholar] [CrossRef]
- Andersen, J.E.; Chekhov, L.O.; Penner, R.; Reidys, C.M.; Sułkowski, P. Topological recursion for chord diagrams, RNA complexes, and cells in moduli spaces. Nucl. Phys. B 2013, 866, 414–443. [Google Scholar] [CrossRef]
- Bon, M.; Vernizzi, G.; Orland, H.; Zee, A. Topological classification of RNA structures. J. Mol. Biol. 2008, 379, 900–911. [Google Scholar] [CrossRef] [PubMed]
- Andersen, J.E.; Penner, R.C.; Reidys, C.M.; Waterman, M.S. Topological classification and enumeration of RNA structures by genus. J. Math. Biol. 2013, 67, 1261–1278. [Google Scholar] [CrossRef] [PubMed]
- Huang, F.W.; Reidys, C.M. Shapes of topological RNA structures. Math. Biosci. 2015, 270, 57–65. [Google Scholar] [CrossRef]
- Chen, W.; Deng, E.; Du, R.; Stanley, R.; Yan, C. Crossings and nestings of matchings and partitions. Trans. Am. Math. Soc. 2007, 359, 1555–1575. [Google Scholar] [CrossRef]
- Stanley, R.P. Enumerative Combinatorics; Wadsworth Publ.: Belmont, CA, USA, 1986. [Google Scholar]
- Sundaram, S. The Cauchy Identity for sp (2n). J. Comb. Theory Ser. A 1990, 52, 209–238. [Google Scholar] [CrossRef]
- Penner, R.; Waterman, M.S. Spaces of RNA secondary structures. Adv. Math. 1993, 101, 31–49. [Google Scholar] [CrossRef]
- Zuker, M.; Sankoff, D. RNA secondary structures and their prediction. Bull. Math. Biol. 1984, 46, 591–621. [Google Scholar] [CrossRef]
- Gralla, J.; Crothers, D.M. Free energy of imperfect nucleic acid helices: II. Small hairpin loops. J. Mol. Biol. 1973, 73, 497–511. [Google Scholar] [CrossRef]
- Turner, D.H.; Mathews, D.H. NNDB: The nearest neighbor parameter database for predicting stability of nucleic acid secondary structure. Nucleic Acids Res. 2009, 38, D280–D282. [Google Scholar] [CrossRef] [PubMed]
- Nussinov, R.; Jacobson, A.B. Fast algorithm for predicting the secondary structure of single-stranded RNA. Proc. Natl. Acad. Sci. USA 1980, 77, 6309–6313. [Google Scholar] [CrossRef]
- Waterman, M.S.; Smith, T.F. Rapid dynamic programming algorithms for RNA secondary structure. Adv. Appl. Math. 1986, 7, 455–464. [Google Scholar] [CrossRef]
- McCaskill, J.S. The equilibrium partition function and base pair binding probabilities for RNA secondary structure. Biopolym. Orig. Res. Biomol. 1990, 29, 1105–1119. [Google Scholar] [CrossRef]
- Reidys, C.M. Random induced subgraphs of generalizedn-cubes. Adv. Appl. Math. 1997, 19, 360–377. [Google Scholar] [CrossRef][Green Version]
- Flamm, C.; Hofacker, I.L.; Maurer-Stroh, S.; Stadler, P.F.; Zehl, M. Design of multistable RNA molecules. RNA 2001, 7, 254–265. [Google Scholar] [CrossRef]
- Bura, A.C.; He, Q.; Reidys, C.M. Loop homology of bi-secondary structures II. arXiv 2019, arXiv:1909.01222. [Google Scholar]
- Whitehead, J. Simplicial Spaces, Nuclei and m-Groups. Proc. Lond. Math. Soc. 1939, 2, 243–327. [Google Scholar] [CrossRef]
- Cohen, M.M. A Course in Simple-Homotopy Theory, 2nd ed.; Springer: Berlin, Germany, 1973. [Google Scholar]
- Hatcher, A. Algebraic Topology; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Andersen, J.E.; Huang, F.W.; Penner, R.C.; Reidys, C.M. Topology of RNA-RNA interaction structures. J. Comput. Biol. 2012, 19, 928–943. [Google Scholar] [CrossRef] [PubMed]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).