1. Introduction
Random number generators are of vital importance in many areas and, particularly, in cryptography. Most cryptographic algorithms and protocols make use of random or pseudorandom numbers. Encryption and authentication schemes in wireless and mobile communications, such as Bluetooth [
1], IEEE 802.15.4, IEEE 802.11 WLAN [
2], GSM [
3] or LTE [
4], employ pseudorandom numbers; radio frequency identification [
5] standards define and recommend the utilization of true random numbers [
6].A large part of the pseudo-random number generators (PRNGs) used in cryptography are based on linear feedback shift registers (LFSRs), mainly due to their simplicity, low cost of implementation, good statistical behavior and the possibility of using a mathematical model that allows the generator to be designed for an optimal performance [
7].
In fact, the maximal sequence length generated by an LFSR of
m cells is
. However, those sequences suffer from a high predictability in such a way that the whole sequence can be reproduced if an eavesdropper gains access to
bits. Despite that, the LFSR is still an important part of the cryptographic generators because those sequences are used to derive more robust ones but keeping the original statistical properties. Two main methods are applied to fix that weakness: nonlinear combination and nonlinear filtering. The former is based on several LFSR, usually with different number of cells [
3], and the latter on a unique LFSR whose sequence is processed (filtered) by a nonlinear function [
4].
Another advantage of using LFSRs in cryptography is that the sequences generated have a uniform statistical distribution. For all these reasons, there is a lot of published works related to the LFSR, but only a few regarding its utilization to produce numbers with Gaussian distribution.
More precisely, in 2010, Kang [
8] proposed a Gaussian PRNG, using a LFSR of length
bits, to generate pseudorandom numbers of
bits. The numbers were produced by means of an accumulator applied on decimated M-bits numbers, producing a sequence of length
. In order to fix this LFSR oversizing, Condo et al [
9] proposed, in 2015, a Gaussian PRNG using permutations over the successive states of a unique LFSR, thus reducing the implementation cost. The main drawback is that not all the possible permutations yield numbers with the required Gaussian distribution and, consequently, a high computational effort must be performed to find the suitable permutations. Later, in 2020, Cotrina et al [
10] presented an improvement of the Condo’s PRNG focusing on a particular type of permutations of the LFSR state, the cyclic rotations. The authors concluded that more than
of the cycle rotations are usable for the PRNG and produce Gaussian distributed numbers.
These proposals are based on the central limit theorem (CLT) [
11], trying to obtain a Gaussian distribution using sequences of uniformly distributed numbers. In this sense, the first proposal [
12] employed several LFSRs to generate independent sequences of numbers. However, most of the proposals use a unique LFSR to generate all the sequences, such as those of Kang [
8], Condo [
9] and Cotrina [
10].
Following the same approach, the present paper describes a Gaussian PRNG based on an LFSR operated and defined in an extension field
instead of using the binary field
. An LFSR in
can be represented as a combination of
n LFSR in
. This fact, as it is described later, allows a particular implementation of the CLT. Furthermore, as it can be deduced from the equivalent model, the cyclic rotations proposed by Cotrina [
10], as a particular case of the permutations proposed by Condo [
9], are implicitly included in the operations of an LFSR in
. This proposal is also in line with the trend of using cryptographic algorithm and protocols in extended fields to take advantage of the word length of processors [
13].
On the other hand, the proposed generator is a way to keep using the LFSR as a basic element to generate pseudorandom numbers in cryptographic areas where other than uniform distribution is required. An example of this is quantum key distribution (QKD) schemes [
14]. This type of scheme, designed to establish keys between two endpoints, can be considered the most mature application of quantum communications. Currently, all developed countries have deployed QKD schemes, some experimentally (in controlled environments) and others in their current transit networks [
15]. The first QKD schemes were based on the transmission of polarized photons using non-orthogonal states. These schemes, named discrete-variable QKD (DV-QKD) [
16,
17], require the utilization of specific components for single-photon detection. A different type of QKD scheme has been developed to carry information on some continuous properties of the light, such as the values of the quadrature components of a coherent state. The so-called continuous-variable QKD (CV-QKD) [
18,
19,
20,
21], currently deployed in several countries e.g., China, Japan, Spain and Italy [
15] present a lower implementation cost due to the utilization of standard communications components. They use coherent detection techniques usually employed in classical optical communications. Furthermore, they employ Gaussian modulation to send random amplitude and phase values that must be generated following a Gaussian distribution [
10,
14,
22].
Section 2 introduces the fundamentals of the LFSR in the binary and extended Galois fields.
Section 3 describes the binary equivalent model of an LFSR defined in a
and the proposal of a Gaussian PRNG based on this model. The statistical analysis of the numbers produced by the proposed PRNG is presented in
Section 4 and compared to the Box–Muller [
23,
24] algorithm, a well-known algorithm not based on CLT. Finally, conclusions are presented in
Section 5.
2. LFSR Fundamentals
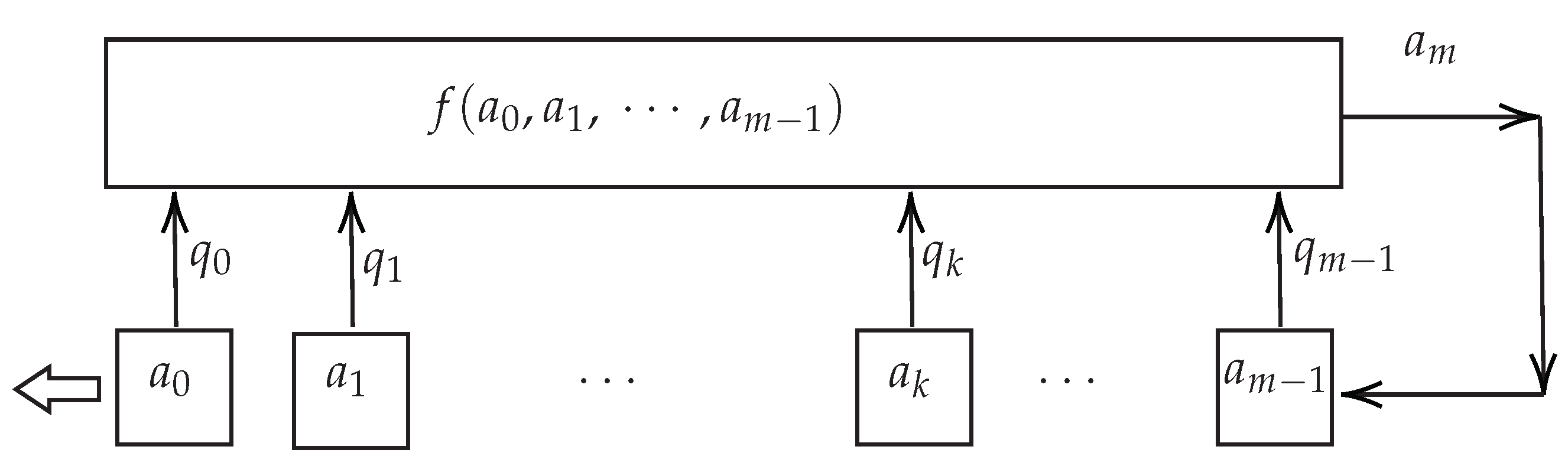
In this section the basic properties of the linear feedback shift register (LFSR) (see
Figure 1), and its generated sequences are described.
A linear feedback shift register (LSFR) is a shift register that takes a linear function of a previous state as an input. Most commonly. The LFSR [
25] of length
m consists of
m stages numbered
, each capable of storing one bit and having one input and one output and a clock which controls the movement of data.
Definition 1. An LFSR of length m consists of: A linear feedback shift register (LFSR) of length m consists of m stages numbered , each capable of storing one bit and having one input and one output; and a clock which controls the movement of data. During each unit of time the following operations are performed:
The content of stage 0 is output and forms part of the output sequence.
The content of stage i is moved to stage for each i where .
The new content content of state is the feedback bit which is calculated by adding together modulo 2 the previous contents of a fixed subset of stages .
The values are either 0
or 1
and the feedback bit is the modulo 2
sum of the contents of those stages i, , for which . As a consequence, the output sequence of the LFSR is and is uniquely determined by the following recursion: The evolution of the LFSR and their sequences generated can be performed by means of a polynomial whose coefficients are the values that represents the stages used to compute the feedback bit . For this reason, the LFSR is denoted , where is the connection polynomial.
The LFSR is said to be nonsingular if the degree of is m (that is, ). If the initial content of stage i is for each i, , then is called the initial state or seed of the LFSR.
On the other hand, the state of the LFSR at the time
t is denoted as
which corresponds to the application of the recursion in the Equation (
1)
t consecutive times starting with the seed
Example 1. Consider the LFSR . If the initial state of the LFSR is , the output sequence is the zero sequence . For the initial state , the sequence has a length of 15
The following table shows the successive states . Note that the right-most bit of each state constitutes the output sequence as we can see in Table 1. Definition 2 (cf. [
25]).
An output sequence A generated by an LFSR , is said to be periodic if there exits such that . Such is called period of the sequence. From this definition, the sequence of the example is a periodic sequence with period .
One of the advantages of LFSR is the mathematical model that allows one to predict the length of the sequences generated. The following definition and theorem states how and when the maximal length is reached by the sequences.
Definition 3 (cf. [
25]).
If is a connection polynomial of degree m, then is called a maximum length LFSR if the output sequence, with non-zero initial state, has period . This sequence is called m-sequence. Definition 4. A polynomial in is irreducible if it cannot be factored into a product of lower-degree polynomials in . An irreducible polynomial of degree is said to be primitive if .
Theorem 1 (cf. [
7]).
An output sequence A generated by an LFSR is an m-sequence if and only if the connection polynomial is a primitive polynomial. The sequence length is independent of the initial state. Consequently, a primitive polynomial of degree m will generate a sequence of length and the LFSR will run through different nonzero states, that is, all possible nonzero states. Hence, if we consider each state as an m-bit pseudorandom number, we can say that LFSR produce numbers with uniform distribution.
Besides its maximal length, the
m-sequences have many desirable statistical properties that can be summarized in the three Golomb’s postulates [
7]. Given a periodic binary sequence
with period length
, it is said to be pseudoradom if the following postulates hold.
Balance property. In every period, the number of zeros is nearly equal to the number of ones (the disparity does not exceed 1, or .
In every period, half of the run have length 1, one fourth have length 2, one eighth have length 3, and so on. For each of these lengths there are the same number of runs of 0’s and runs of 1’s.
Two level autocorrelation. The autocorrelation function
is two-valued given by
where
k is a constant. If
for
m odd, or
for
m even, we say that the sequence has the ideal two level autocorrelation function.
The ideal tuple distribution. In every period of A, if each nonzero tuple occurs q times and the zero tuple occurs times, then we say that the sequence satisfies the ideal k-tuple distribution.
LFSR over
Definition 5. Let’s suppose be a field with operations + and *, we will say that this field F is a Galois field if the cardinal of field F is finite. If the cardinal of the finite field F is p, then F will be represented as .
It is possible to extend the prime field to a field of elements, represented by , which is called an extension field of . In our case we shall work for .
To build up the field extension of , , let’s consider a primitive polynomial over of degree n, once this polynomial is defined, let’s consider a root of this primitive polynomial, therefore . Let’s consider . It can be proven that all the elements of can be represented by distinct non-zero polynomials of over with degree or less. The can be represented as the zero polynomial. Then the set with the usual operations is a Galois field with elements.
Example 2. Let’s build the finite field generated by the primitive polynomial . First of all, we consider α to be a root of the primitive polynomial , then we determine all multiplicative powers of α, until we obtain the multiplicative identity 1 on this field. For any Galois field we will have three representations as shown in Table 2. This Table 2 shows how all the elements of the extended Field are obtained. The equivalence has been obtained using the vector notation as a function of one of the roots of the primitive polynomial that generates the extended field. In the same way, it can be observed that the body is generated cyclically and that no equal values are obtained except when it has been cycled and all its elements have been obtained periodically. According to the Example 2, form this point on, we shall represent the elements of the extended fields using the vector notation, where for example the element will be represented as .
To generate an LFSR on a we will start by determining a primitive polynomial p over that will be used to generate the extended field. Once this polynomial and this field have been set, we choose a primitive polynomial g over and a seed or non-zero initial state value on which the primitive polynomial g is applied. In this way, a value , is obtained by on which the primitive polynomial g will be applied and thus the process will be repeated.
Example 3. We consider the that has been built using the primitive polynomial . Let’s consider the primitive polynomial over whose vector representation is . The initial seed will beand taking into consideration these conditions the output sequence will be As in , the LFSR in produces an m-sequence if and only of the connection polynomial is primitive. The sequence has a period of that corresponds to all nonzero states, where m is the degree of the connection polynomial.
3. Gaussian Number Generator over
To apply the CLT, Gaussian generators based on a single LFSR [
8,
9,
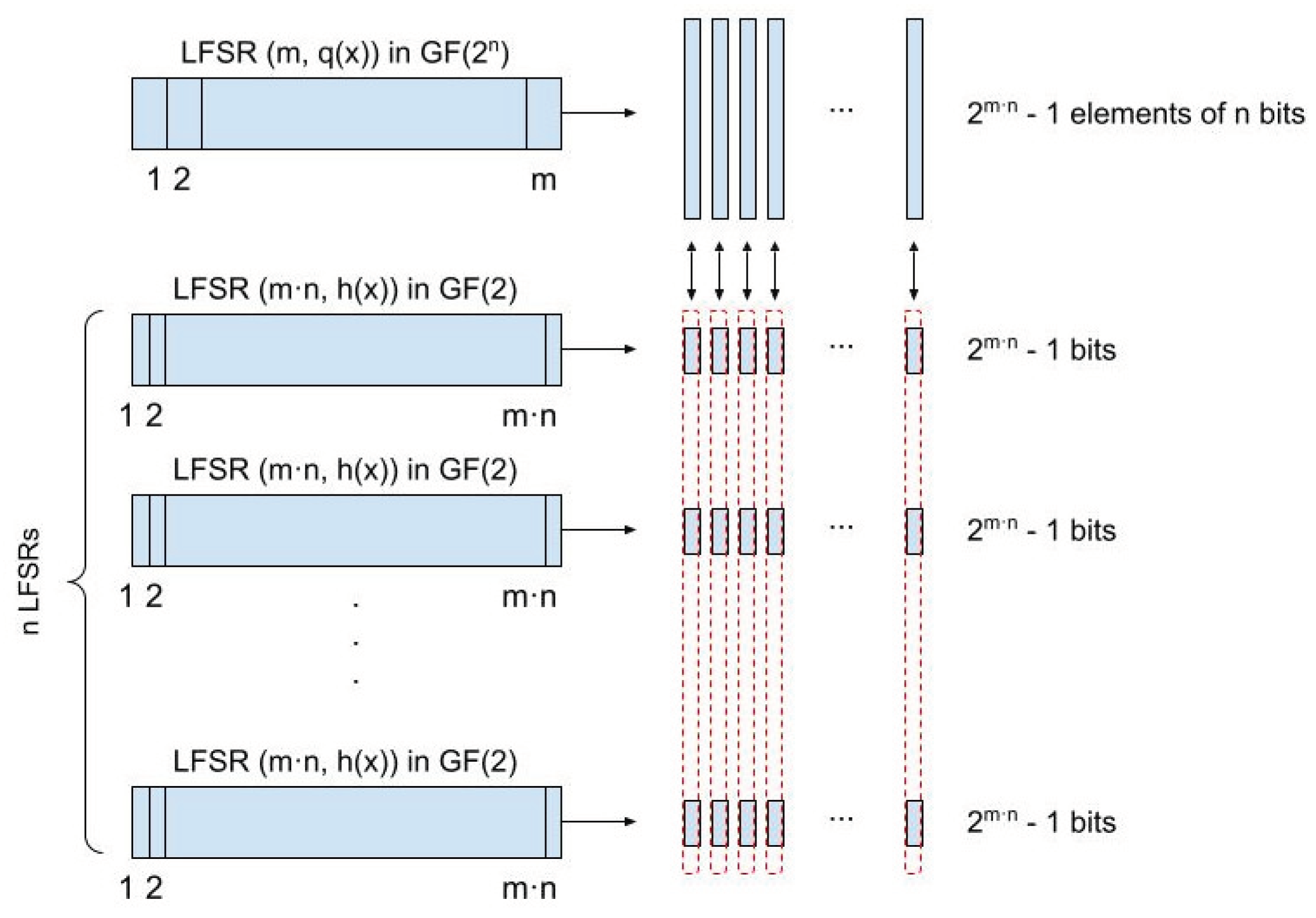
10] try to obtain different sequences of pseudo-random numbers with uniform distribution from the same sequence generated by the LFSR. To do this, they apply permutations—generic in some cases, rotations in others—on each state of the LFSR. In this way, with each number generated by the LFSR, other numbers are also being generated (as many as permutations are applied) and therefore different uniform sequences suitable to be combined in a sequence of numbers are being simultaneously constructed. LFSRs defined on an extended field can be analyzed as the combination of a series of binary LFSRs. For this reason, each state of an LFSR in an extended field is related to the states of a series of binary LFSRs. This relation is the one used to propose a PRNG with Gaussian distribution. Next, the equivalent model of an LFSR defined in an extended field that allows the definition of a Gaussian PRNG with excellent performance is described.
3.1. Binary Equivalent Model of an LFSR in
As it is known [
26], there is a relationship between the
sequences generated in
and those generated in
, in such a way that the former can be obtained from the latter. The relationship is established from the feedback polynomials that define each LFSR. Specifically, if
is the primitive polynomial of degree
m that defines the LFSR in
and therefore generates an
sequence in
, the decimated sequences obtained by taking the
th bit of each element in the
sequence are generated by a binary LFSR with primitive feedback polynomial
of degree
, where
divides
. This allows to develop an equivalent model of the LFSR defined in
using
n LFSRs in
, as shown in
Figure 2 where the
th bit of each element is generated by the
th binary LFSR. Note that all the binary LFSRs used in the model have the same polynomial
although initialized in different seeds. Therefore, the sequences generated by the binary LFSRs are
sequences in
, and consequently, shifted versions of the same sequence. In this way, the generation of an
sequence in
implies the generation of
n binary
sequences, one for each bit, which can be used as sources with a uniform distribution to later apply CLT.
Definition 6. Let be a LFSR over . Let be the state of the LFSR at time t, with that can be represented as the vector with ∀. Then, is defined as the projection over the th component of an element. Hence, and .
This definition allows us to represent the decimated sequences of a sequence as: Theorem 2. Let be an LFSR over and let be the set of all its decimated sequences then, is primitive over if and only if is primitive over . If these conditions hold, and .
Therefore, if we have an LFSR over where is primitive, then we can consider that we have n’s sequences over .
In other words, this equivalent model represents the interleaving process that generates the sequence in
; that is, the sequence generated by the LFSR in
can be expressed as an interleaved sequence, in the sense describe by Gong in [
27], composed by n component sequences, corresponding with the decimated sequences. More precisely, it is a primitive interleaved sequence as all the component sequences are generated by the same primitive polynomial in
.
On the other hand, pseudorandom sequences must be difficult to reproduce. Linear complexity (or linear span) of a sequence is defined as the degree of the minimal polynomial that generates it, or equivalently the length of the shortest LFSR that generates it. Consequently, the linear complexity of a sequence generated by a primitive LFSR is the length of that LFSR. Hence, considering the sequence produced by an LFSR of m cells in
as an interleaved sequence, its linear complexity
is n times the linear complexity
of its primitive components; that is,
3.2. The Proposed Generator
Taking in mind that one of the potential applications of a Gaussian PRNG based in LFSR could be a QKD scheme, it is important to note the following requirements:
The PRNG should allow a discrete set of values to be generated large enough to approximate the continuous probability distribution.
The set of values generated must have a Gaussian probability distribution.
The security of the system must allow the generation of a set of values with a sufficiently large cardinal.
The generation of obtained values should be done as fast as possible and within the lowest implementation cost. In addition, for the system to be effective, the possibility of a hardware implementation must be considered.
The system must allow the generation of the pseudo-random values with Gaussian distribution to be different for each of its different executions.
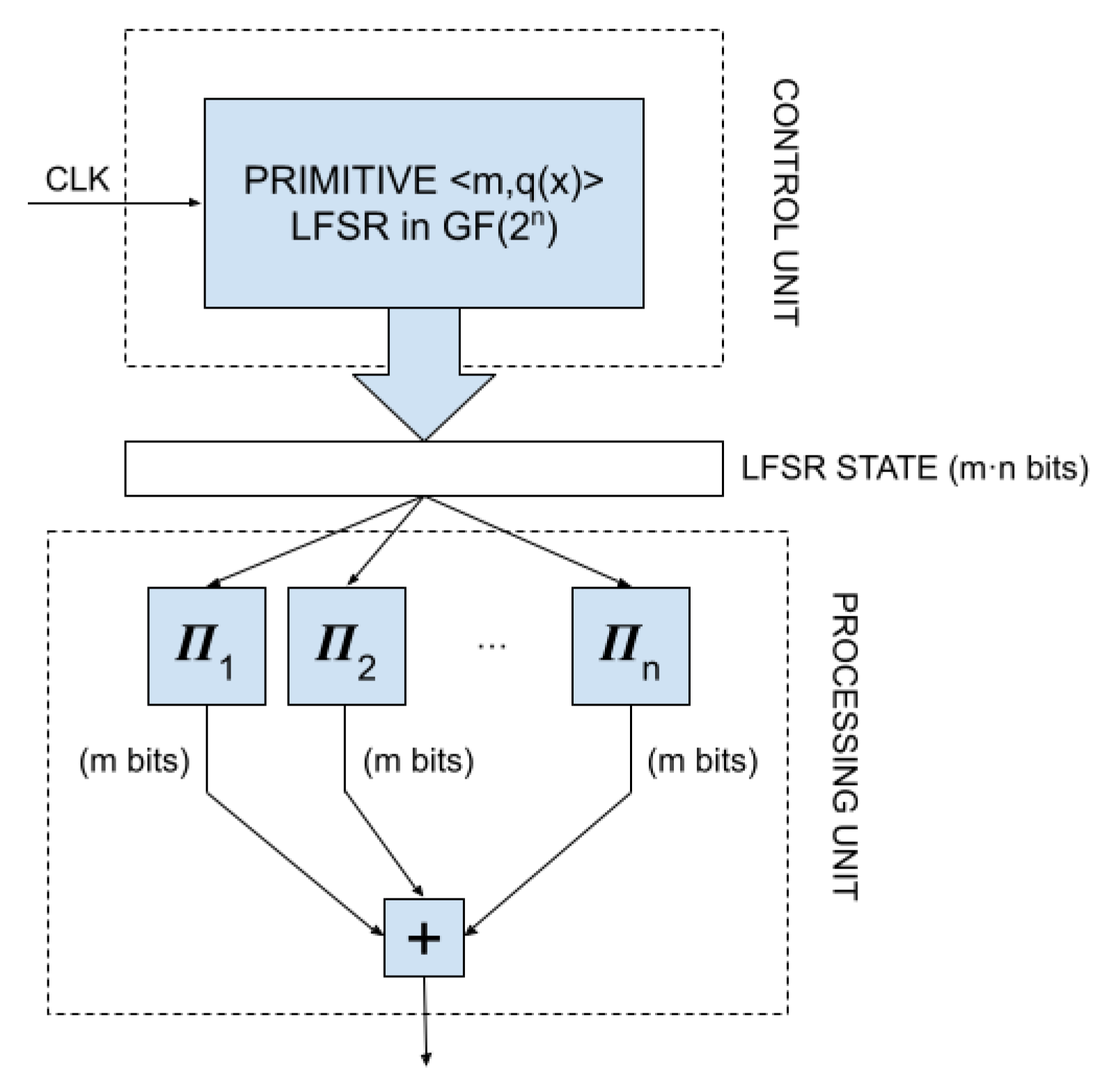
In order to fulfil all the requirements, we propose a PRNG based on an LFSR in
. The PRNG is composed by two units: the control unit and the processing unit (see
Figure 3).The control unit consists in an LFSR with
m cells, defined by a primitive polynomial
over
. This
unit is responsible for the generation of the basic
sequence from which all the sequences with uniform distribution are obtained for the subsequent application of CLT. As it is described in the previous sections,
is primitive the LFSR generates an
sequence, i.e., a sequence of maximal period
.
The processing unit has been design with a two-fold objective. On the one hand, like many other cryptosystems, it applies a nonlinear filtering to the sequence produced by the LFSR in the control unit to increase the difficulty that an eavesdropper reproduces the whole sequence. On the other hand, this unit implements the operations that transform the statistical distribution from uniform to Gaussian, i.e., implements the CLT. To do that, the operator
is applied on each LFSR state, thus producing n strings of m bits that corresponds with segments of the n binary sequences in the equivalent model described in
Section 3.1. Hence, applying the CLT, the pseudorandom number B is obtained by means of the integer sum of those
n bitstrings as:
where
D is the function that maps an
bit vector
into a decimal value,
The period, range and accuracy of the proposed PRNG can be configured using two main parameters: m and n. The sequence of pseudorandom numbers has a period of because the feedback polynomial in the LFSR is a degree m primitive polynomial in . The range of the numbers is mainly determined by m since each state of the LFSR contains bits that split in n strings of m bits later summed to produce the pseudorandom number. The parameter n increases slightly, until , the number of bits of the generated numbers due to the carry of the integer sum. Thus, for and , the PRNG generates values with a range of bits.
Finally, when the CLT is applied to obtain a Gaussian distribution, its accuracy is related to the numbers of uniform distributed numbers that are summed. In this case, each pseudorandom number is obtained summing n values. Hence, generating bit pseudorandom numbers requires the utilization of an LFSR with 16 cells. If the LFSR operates in , the PRNG will present a period of , obtained from the addition of 4 uniformly distributed sequences. The accuracy may increase using 8 values instead of 4. In that case, the LFSR would work in what would also increase the period to .
Regarding the speed of generation, although, generally, the use of LFSRs in is motivated by the speed increase that is achieved by generating n bits instead of 1 in each iteration, in this case, the use of the LFSR in pursues a second objective: to take advantage of the implicit relationship with n different binary sequences. This makes it easy to apply the CLT by using a single LFSR that is equivalent to n binary LFSRs. Therefore, the final rate of generating numbers with Gaussian distribution is the same as the rate at which a binary LFSR generates a bit. However, taking into account that the generated numbers are m bits long, the generation speed in bits per second is m times higher.
4. Statistical Analysis
In this section, the distribution of the numbers generated by the proposed PRNG is analyzed. Several normality tests have been applied to identify the configurations that generates numbers with Gaussian distribution.
4.1. Distribution Fit Test
Goodness-of-fit tests are used to evaluate how well a proposed model fits or predicts a particular data set. Usually, test statistics compute deviations between the observed data and predictions from the model. The value of a test statistic is said to be statistically significant if it is found to be within the rejection area of the distribution of the test statistic under the assumption that the model is true. The rejection area is often the upper its significance level of or of the distribution frequencies. In our work we have set this acceptance minimum level to . Therefore a distribution fit test performs a goodness of fit hypothesis test with null hypothesis that data was drawn from a population with a specific distribution of values, in this case the Normal distribution, and alternative hypothesis that it was not.
Usually, a statistical hypothesis test returns a value called p or the p-value. This value is used to reject or fail to reject the null hypothesis. This is done by comparing the p-value to a threshold value chosen beforehand called the significance level . When the p-value is less than , the default hypothesis can be rejected. In the same way, the confidence level of the test is . If we set the significance level to and the p-value is greater than , we would conclude that the null hypothesis affirming that the data is distributed according to the Normal Distribution would not be rejected at the 5 percent significance level. In the present context, the higher the p-value, the better the data fits the normal distribution.
According to the CLT [
21], if we consider
a random sample of size
n that is, a sequence of independent and identically distributed random variables drawn from a distribution of expected value given by
and finite variance given by
. Suppose we are interested in the sample average
of these random variables. By the law of large numbers, the sample averages converge in probability and almost surely to the expected value
as
. The classical central limit theorem describes the size and the distributional form of the stochastic fluctuations around the deterministic number
during this convergence. More precisely, it states that as n gets larger, the distribution of the difference between the sample average
and its limit
, when multiplied by the factor
(that is
), approximates the normal distribution with mean 0 and variance
. For large
n, the distribution of
is close to the normal distribution with mean
and variance
. The usefulness of the theorem is that the distribution of
approaches normality regardless of the shape of the distribution of the individual
.
There exist different methods to distinguish whether or not the range of values in a distribution follows a Normal distribution. Due to the large number of values that we have obtained in all our tests, we have decided to use the Chi Square Test that will be described in the next
Section 4.1.1.
4.1.1. Chi Square Test
The chi-square test [
22,
28] is used to test if a sample of data came from a population with a specific distribution. In this case we shall focus on this test to check if the distribution of numbers fits the normal distribution.
The goodness-of-fit test examines the discrepancy between observed values and the values expected under some particular distribution of a random variable A.
The null hypothesis : The random variable A follows the normal distribution.
The alternative hypothesis : The random variable A does not follow the normal distribution.
Let be the observed values of a variable A. We shall follow:
Categorize the observations into k categories.
Calculate the frequencies where and is the observed frequency of the category i.
Let be the probability, that under null hypothesis, the random variable A belongs to the category i. Calculate the expected frequencies of the observations in category i.
Now, under the null hypothesis, the random variables follow multinomial distribution with parameters .
We shall continue working out the test statistic
If n is large, then under the null hypothesis, the test statistic approximately follows where e is the number of estimated parameters.
The expected value of the test statistic, under the null hypothesis, is .
Large and small values of the test statistic (compared to the expected value) suggest that the null hypothesis does not hold.
If the p-value is small enough, the null hypothesis is rejected.
4.1.2. Measures of Central Tendency, Dispersion, Kurtosis and Skewness
To check if these measures make the values fit in a feacient way with the data of a Gaussian distribution, we have normalized the results applying the elementary transformation
From here, we have determined the measures of central tendency of the variable, the measures of dispersion and the measures of skewness and kurtosis. The first thing that we have should verify is that if the values of the degree of the feedback polynomial are increased and the cardinal of the field is increased, the obtained values fit better to the normal distribution, obtaining in each case values closer to standard values of the normal distribution.
If the numerical data have been normalized, in the sense that we have applied the typification (
11), then we can set the various control parameters to verify whether or not the data follow a normal distribution.
The expected values for the normal distribution are as follows:
Quartiles and to be
About of the observations are within 2 times the standard deviation of the mean. of the values will be within times the standard deviation from the mean (between and ). Approximately of the observations are within one standard deviation of the mean ( to ), and around of the observations would be within three standard deviations of the mean ( to 3).
The standard deviation and the mean .
The skewness for a normal distribution is zero, and any symmetric data should have a skewness near zero. Negative values for the skewness indicate data that are skewed left and positive values for the skewness indicate data that are skewed right. By skewed left, we mean that the left tail is long relative to the right tail. Similarly, skewed right means that the right tail is long relative to the left tail. If the data are multi-modal, then this may affect the sign of the skewness.
The kurtosis for a standard normal distribution is 3.
4.2. Results
In this section we will go on to show the results that have been obtained for the generation of numbers with a Gaussian distribution.
To illustrate the results obtained in the generation of numbers with a Gaussian distribution, the following polynomials have been taken into account for the generation of the base Fields and the following polynomials as polynomials of connection polynomials .
To generate all the extended fields, different primitive polynomials have been used. The degrees of these polynomials have ranged from 4 to 16. The list of primitive polynomials that have been used are represented in
Table 3.
We will continue describing the primitive polynomials that we have used as the connection polynomial for each of extended field. Note that due to the great length of each of the terms of each polynomial, the conversion to hex has been carried out.
From now on we will denote
to be the LFSR
so
represents the degree of the primtive polynomial over the extended Field
. Therefore, according to the
Table 4, the LFSR
will be the LFSR generated by
over
.
First, we will determine the arithmetic mean, the standard deviation and the quartiles of the obtained numerical values. According to the
Table 5, it can be seen that all the values obtained are within the range of expected values so that they fit to the values of a Gaussian distribution.
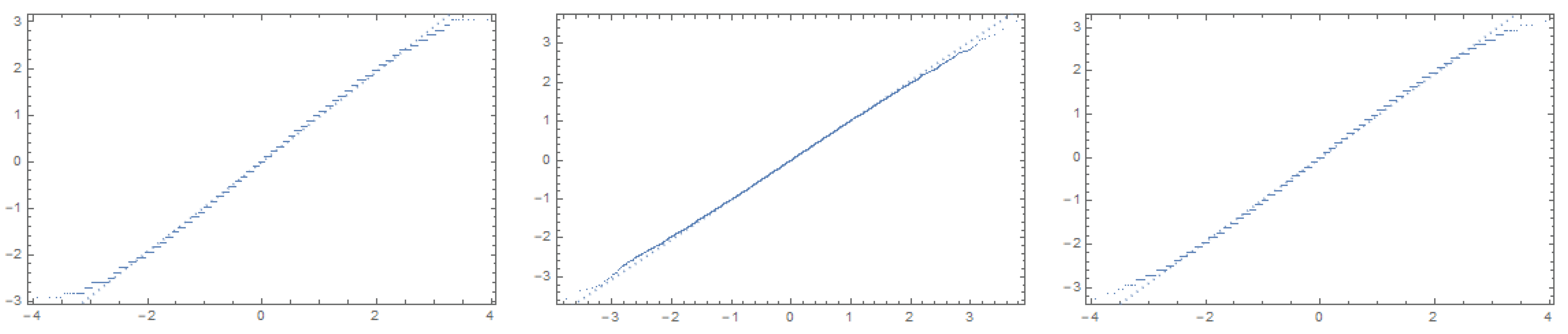
In the same way we have generated all the quantiles and we have compared them with the theoretical values of those of the Gaussian distribution. In each of the cases it can be verified that the values fit the Gaussian model. In the
Figure 4 we plot the obtained quantiles list against the quantiles list of a normal distribution for some cases.
In order to better support the results presented, we have represented the cumulative distribution function (CDF) and the results obtained and compared them with those expected in the normal distribution. In the
Figure 5 we confront the CDFs of the normal distribution against those obtained resutls.
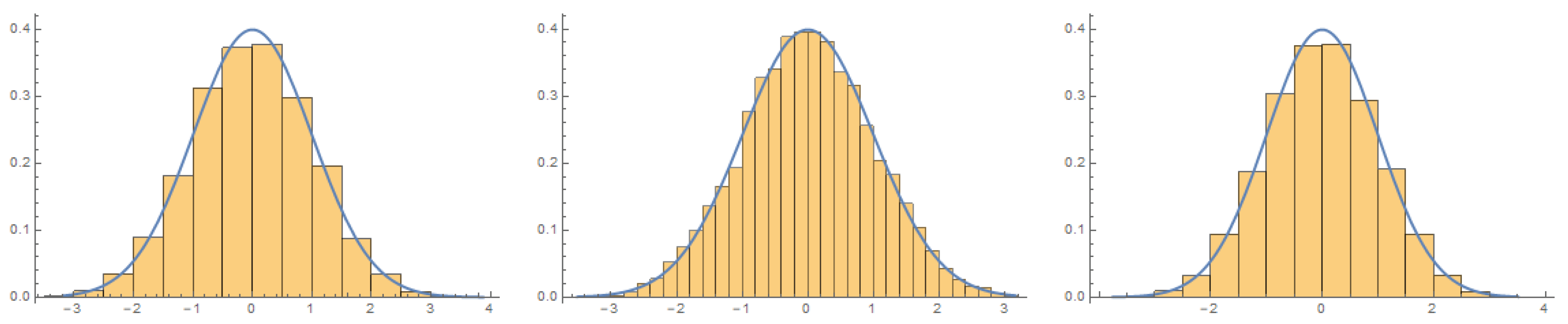
In this regard, it should also be noticed that the histograms of the results obtained have been analyzed and these have been compared within the corresponding histograms of the normal distribution. Continuity correction has been applied since a discrete set of values are being used and we have also been able to verify that the data fit a normal distribution of values. In the
Figure 6 we can see how the histograms tend to the normal ditribution CDFs curve.
Although different normality tests were originally used to check if the data fit the normal distribution, as we can see in
Table 6, due to the large number of data, we have opted for the method of the Chi-Square Test, which allows us to check whether or not a model or theory follows an approximately normal distribution.
These described tests have been used to check whether the statistical variables are distributed according to a Normal distribution. A minimum level of confidence has been set to therefore the significance level is set to and according to that level of confidence the sequence obtained has been screened. That is, given a set of values, the Normality tests have been applied to verify whether the data followed a normal distribution or not. The output of these mentioned tests is a p-test. If the p-test value obtained is greater than , the sequence obtained is considered valid and otherwise has been discarded.
The proposed generator has been tested for all possible polynomials. All primitive polynomial combinations have been tested using the Mathematica environment. The tests have been performed using Chi sqaure, the Anderson–Darling and Shapiro methods. The results are exemplified in
Table 6.
The proposed PRNG [
24] has also been compared with the Box–Muller algorithm that was designed as a pseudo-random number sampling method for generating pairs of independent, standard, normally distributed (zero expectation, unit variance) random numbers, given a source of uniformly distributed random numbers. If
and
are independent samples chosen from the uniform distribution on the unit interval
, then the variables defined as:
are independent random variables with a standard normal distribution.
After having executed the Box–Muller algorithm we have found the following disadvantages.
Another way to improve the accuracy of the Gaussian distribution is to modify the way the
m-bit strings are generated. If all the states of the LFSR are used, each cell is used in the generation of
n consecutive pseudo-random numbers. Although the fit tests reveal very good results (see
Section 4.2), decreasing or removing the amount of numbers affected by the same cell would help to improve the accuracy. Therefore, we propose, as an alternative, to use one out of every m states. More formally, we propose to decimate by
m the LFSR output. In this way, the period would be
giving rise to select
such that
in order to reach the same period
.
In any case, it is important to note that the period is much greater than the range, i.e., , giving rise to a probability about of generating the same number in values generated.
5. Conclusions
A new Gaussian PRNG has been proposed in this paper. It is based on a unique LFSR, using the same approach than the previous proposals [
8,
9,
10], in order to generate a certain number of sequences of uniformly distributed numbers, needed to apply the CLT. Unlike the previous proposals, no explicit permutations or rotations have been applied to the successive LFSR states. Instead, the PRNG is operated in
to take advantage of the relationship between the states and sequences generated in
and
, that allows to represent the
sequences in
as primitive interleaved sequences composed by
sequences in
.
The PRNG, presented in
Section 3.2, allows to configure it by means of two main parameters,
m (the number of cells in the LFSR) and
n (the dimension of
), determining the period as
, and the range
. The statistical analysis reveals an excellent behaviour when the fit tests are applied.
Finally, this PRNG is a way to keep using LFSR in cryptographic applications where a uniform distribution is not required. Furthermore, as in other applications, the use of LFSRs in is motivated by the speed increase that is achieved by generating n bits instead of 1 in each iteration; in this case, the use of the LFSR in pursues a second objective: to take advantage of the implicit relationship with n different binary sequences looking for an easier implementation of the CLT. Therefore, the final rate of generating numbers with Gaussian distribution is the same as the rate at which a binary LFSR generates a bit. However, taking into account that the generated numbers are bits long, the generation speed in bits per second is times higher.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}