Abstract
A theme that become common knowledge of the literature is the difficulty of developing a mechanism that is compatible with individual incentives that simultaneously result in efficient decisions that maximize the total reward. In this paper, we suggest an analytical method for computing a mechanism design. This problem is explored in the context of a framework, in which the players follow an average utility in a non-cooperative Markov game with incomplete state information. All of the Nash equilibria are approximated in a sequential process. We describe a method for the derivative of the player’s equilibrium that instruments the design of the mechanism. In addition, it showed the convergence and rate of convergence of the proposed method. For computing the mechanism, we consider an extension of the Markov model for which it is introduced a new variable that represents the product of the mechanism design and the joint strategy. We derive formulas to recover the variables of interest: mechanisms, strategy, and distribution vector. The mechanism design and equilibrium strategies computation differ from those in previous literature. A numerical example presents the usefulness and effectiveness of the proposed method.
1. Introduction
1.1. Brief Review
Hurwicz [1] published his seminal work on mechanism design that has emerged as a practical framework for tackling game theory problems with an engineering viewpoint when considering players that interact rationally [2,3,4]. For a survey see [5]. This theory is based on games with incomplete information for modeling mechanisms (that implements a social choice function) compatible with individual incentives that result in efficient decisions for maximizing the total reward. The primary aim consists of establishing games that consider independent private values and quasilinear payoffs [6,7], in which players receive messages containing information that is relevant to payoffs [8]. In the evolutions of the game, players commit to a mechanism that presents a result in terms of a function of the possibly untruthfully reported type. It should be pointed out that the mechanism is unknown. The mechanism designer determines a social choice function that is a mapping of the true type profile directly to the alternatives. However, a mechanism maps the reported type profile to the alternatives. The main task in computational mechanism design is to find a mechanism that both maintains the game-theoretic original futures and is computationally “efficient” and “feasible”.
This approach makes it possible managing the restrictions and controlling the information of the players that are engaged in a game. From this perspective, Arrow [9] presented a framework to claim revelation that realizes efficiency and avoids the spend of resources in the incentive payments. d’Aspremont and Gerard-Varet [10] suggested two separate methods to design a mechanism with incomplete information: a) the former consist of the fact that players beliefs are not considered, and the second where they are. Saari [11] presented a mechanism design, which involves types of information. Rogerson [12] proposed a general approach of the hold-up problem, in which several players make relation-specific investments and then decide on some cooperative action proving that first-best solutions exist under a variety of different assumptions regarding the nature of information asymmetries. Mailath and Postlewaite [13] established an approach for the bargaining problems with asymmetric information while considering multiple agents. Miyakawa [14] provided a necessary and sufficient condition for the existence of a stationary perfect Bayesian equilibrium. Athey and Bagwell [15] and Hörner et al. [16] have relevant results on equilibria in repeated games, which consider communication. Clempner and Poznyak [17] suggested a Bayesian partially observable Markov games model supported by an AI approach. Different approaches are presented in the literature, for instance, see [18,19,20].
1.2. Main Results
We contribute to this literature by proposing original outcomes, presenting an analytical method for developing a mechanism that considers incomplete state information whose preferences evolve following a Markov process, and characterizing an approximately equilibrium behavior in game theory models [17]. The foundation of the proposed method is the derivation of formulas for computing the mechanism . Subsequently, given the mechanism, compute the equilibrium strategy. The derivation of these formulas rely on a direct mechanism design. We propose an extension of the Markov model, suggesting a new variable z that represents the product of the mechanism and the joint strategy c. Additionally, the joint strategy c is defined by the product of the strategy , the observer q, and the distribution vector P. We derive formulas to recover the variables of interest: mechanism , the strategies , and the distribution vectors P. We describe a method for the derivative of the player’s equilibrium that instruments the design of the mechanism and we also showed the convergence of the proposed method.
1.3. Organization of the Paper
For ease of exposition, in the next section, we describe the Markov game model. In Section 3, we introduce the variables c and z and suggest the derivation of the formulas. The ergodicity condition expressed in z variables is proven in Section 4. The convergence to a Nash equilibrium is presented in Section 5. Section 6 concludes with some remarks.
2. Markov Games with Incomplete Information
Let us introduce a probability space , where is a finite set of elementary events, is the discrete algebra of the subsets of , and is a given probability measure defined on . Let us also consider the natural sequence as a time argument. Let S be a finite set that consists of states , , called the state space. A Stationary Markov chain [21,22] is a sequence of S-valued random variables , satisfying the Markov condition:
The random variables are defined on the sample space and they take values in S. The stochastic process is assumed to be a Markov chain. The Markov chain can be represented by a complete graph whose nodes are the states, where each edge is labeled by the transition probability in Equation (1). The matrix determines the evolution of the chain: for each , the power has in each entry the probability of going from state to state in exactly n steps.
Let be a Markov chain [21,22], where S is a finite set of states, and A is a finite set of actions. For each is the non-empty set of admissible actions at state . Without loss of generality we may take . Whereas, is the set of admissible state-action pairs. The variable is a stationary controlled transition matrix, where represents the probability that is associated with the transition from state to state , () and (), under an action (). The distribution vector is given by , such that where .
We consider the case where the process is not directly observable [23]. Let us associate with S the observation set Y, which takes values in a finite space . The stochastic process is called the observation process. By observing at time t information regarding the true value of is obtained. If and an observation will have a probability that denotes the relationship between the state and observation when an action is chosen at time t. The observation kernel is a stochastic kernel on Y, as given by . We restrict ourselves to consider .
Definition 1.
A controllable Partially Observable Markov Decision Process (POMDP) is a tuple
where: (i) is a Markov chain; (ii) Y is the observation set, which takes values in a finite space (iii) denotes the observation kernel is a stochastic kernel on Y, such that ; (iv) denotes the initial observation kernel; (v) P is the (a priori) initial distribution; and, (vi) , is the reward function at time t, given the state , the observable state , when the action is taken.
A realization of the partially observable system at time t is given by the sequence , where has a given by the distribution and is a control sequence in A that is determined by a control policy. To define a policy we cannot use the (unobservable) states . Then, we introduce the observable histories and and , if . Now, a policy is defined as a sequence , such that, for each t, is a stochastic kernel on A given . The set of all policies is denoted by . A policy and an initial distribution , also denoted as , determine all possible realizations of the POMDP. A control strategy satisfies that .
A game consists of a set of players (indexed by ). We employ l in order to emphasize the l-th player’s variables and subsumes all the other players’ variables. The dynamics is described, as follows. At time , the initial state has a given a priori distribution , and the initial observation is generated according to the initial observation kernel . If, at time t, the state of the system is and the control is applied, then each of strategy is allowed to randomize, with distribution , over the pure action choices . These choices induce immediate utilities . The system tries to maximize the corresponding one-step utility. Next, the system moves to new state , according to the transition probabilities . Subsequently, the observation is generated by the observation kernel . Based on the obtained utility, the systems adapt a mixed strategy computing for the next selection of the control actions. For any stationary strategies , we have . Then,
where Each player maximizes the individual payoff function , realizing the rule that is given by
where for a given strategies satisfy the Nash equilibrium [24,25] fulfilling, for all admissible , the condition
3. Main Relations
Following [21,26] and [27], let us introduce a matrix of elements , as follows
Let us define . Formally, a mechanism is any function , such that given represents the nonlinear programming problem
and defining , we have that
such that
Now, let us introduce the z-variable, as follows
where
Notice that by the relations
, it is easy to check that , where
We define the solution of the problem (7) as . The next lemma clarifies how we may recover and .
Lemma 1.
Variables and can be recovered from , as follows:
Proof.
See Appendix A. □
Corollary 1.
In addition,
Now, in order to derive and we have that
Corollary 2.
The strategy constructed from (11), and the distribution are given by
4. Ergodicity Conditions Expressed in Variables
We have derived the formulas, which maximize Equation (7) that is based on the variables and the formulas to recover the policy , the mechanism and . Accordingly, we focus our attention on the ergodicity restrictions.
Theorem 1.
The strategy and the mechanism are in Nash equilibrium, where every agent maximizes its expected utility, for every ,
if the quantities of satisfies the following restrictions
Proof.
See Appendix B. □
5. Convergence Analysis
The Nash Equilibrium is a game theory concept that involves several players that determines the solution in a non-cooperative game in which each player lacks any incentive to only change his/her own strategy. A practical notion in deriving Nash equilibria is a player’s best reply. The best reply is the strategy (or set of strategies) that maximizes/minimizes his/her payoff taking other players’ strategies as given. Then, a player has not just one best-reply strategy, however he/she has a best-reply strategy for each arrangement of strategies for the other players. All of the Nash’s equilibrium can be approximated in a (best reply) sequential process. We want to compute the solution of the problem (7), defined as , when considering the best reply approach. For solving the problem (7), let us consider a game whose strategies are denoted by , where X is a convex and compact set, where and . Let be the joint strategy of the players and be a strategy of the rest of the players adjoint to . We consider a Nash equilibrium problem with n players and denote, by , the vector representing the x-th player’s strategy . The method of Lagrange multipliers is an optimization approach for finding the local minimum (maximum) of a function subject to equality constraints (), as given in Equation (8). Let us consider the Lagrange function that is given by
where the Lagrange vector-multipliers may have any sign. The optimization problem
for which we propose the following iteration algorithm:
1. Proximal prediction step:
2. Gradient approximation step:
Let us define the following variables
Subsequently, the Lagrange function can be expressed as
In addition, let us introduce the following variables
and let us define the Lagrangian in terms of the previous variables
For = == and ==, we have
We provide the convergence analysis of the sequence in the following theorem [28].
Theorem 2.
Let be a convex and differentiable function with the gradient satisfying the Lipschitz condition, i.e., ≤ for all , where is a convex and compact set. Let be a sequence defined by the local search and proximal iteration algorithm that is given by
then, the sequence converges to a Nash equilibrium point .
Proof.
See Appendix C. □
6. Political Numerical Example
The theory that is related to electoral competition originates in the original contributions of Hotelling [29] and Downs [30]. The proposed framework suggests a majority rule election, where political candidates compete for a position by simultaneously and independently proposing a model from a unidimensional policy space. It is common knowledge that the equilibrium of this model is fundamentally determined on the candidates’ incentives for running for such a position. This example considers a three-player game () that is engaged in a political contest, in which the player with the highest performance wins. A question arises as to what is the design of a mechanism to select a candidate? The goal of each candidate is to end up on top. The next time a political position rolls around, pay attention to the campaigning. Candidates who are behind will talk about not only what a good choice they are for such a position, but also what a bad choice the front-runner is.
The assumption that is involved in this example considers the incomplete information version of the game, in which candidates have the same relative weight to their preference strategies versus their desire to win the position. This case is relevant from a theoretical point of view, and it is empirically important. The dynamics are modeled when considering , , and with transition matrices for describing the evolution of the partially observed Markov game. The initial transition matrices are defined, as follows:
As well as, the initial observation matrices are defined, as follows:
Fixing in the extraproximal method that is given in Equations (17) and (18), we have that the Nash equilibrium results from computing the strategies and the mechanism design applying Equations (10) and (13), which are given, as follows:
We present a full characterization of the Nash equilibrium for the case of partially observable Markov games. Figure 1, Figure 2 and Figure 3 show the convergence of the strategies .
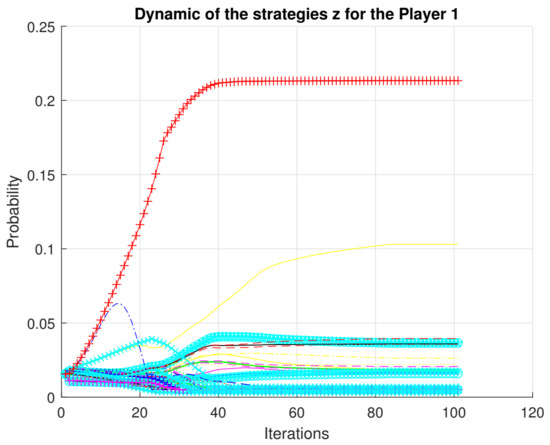
Figure 1.
Convergence of strategies for player 1.
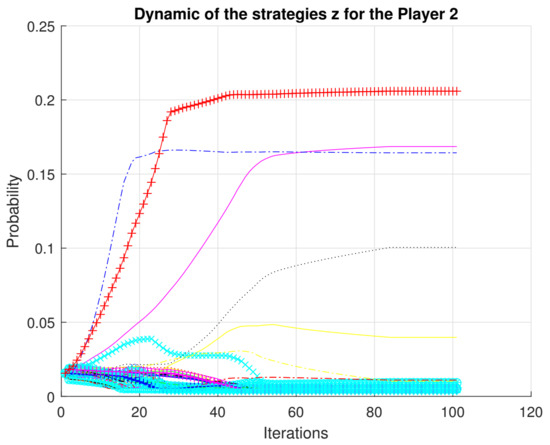
Figure 2.
Convergence of strategies for player 2.
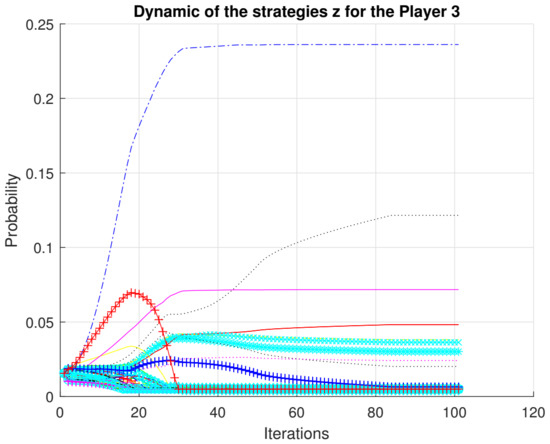
Figure 3.
Convergence of strategies for player 3.
7. Conclusions
This paper contributed to the literature on mechanism design for Markov games with incomplete state information (partially observable). We suggested an analytical method for the design of a mechanism. The main result of this work is based on the introduction of the new variable z, which makes the game problem computationally tractable and allow for obtaining the mechanism solution and the strategies for all of the players in the game. The variable z allows for the introduction of new natural additional linear restrictions for computing the Nash equilibrium of the game. A no feasible solution can be detected with a simple test on the variable z, i.e., it is possible to detect unusual conditions in the solver of the game given the information available for the simplex. A major advantage of introducing this variable relies on the fact it can be efficiently implemented for real settings, which is consistent with the engineering approach for designing economic mechanisms or incentives, toward desired objectives, where players act rationally. We applied these results to a numerical example that is related to political promotion.
In relation to future work, there are several challenges that are left to address. One interesting technical challenge is that of addressing extremum seeking in the context of mechanism design [31,32,33]. Another interesting challenge would be to consider the observer design approach in order to extend the mechanism design theory [23].
Author Contributions
Authors contributed equally to this work. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof Lemma 3.1
Hence,
Let us define as follows
To verify that the definitions of and (10) are correct we need to check the fulfilling of Equations (5) and (6), i.e., and .
(a) As for variables , these properties follow directly:
since . Summing (A2) by directly leads to the property .
Then, , see Equation (9). The Lemma is proved.
Appendix B. Proof of Theorem 4.1
Proof. This means that new variables should satisfy the following linear ergodicity constraints:
which implies
Then,
The Equation (15) is fulfilled automatically since
Now, we prove the relation given in Equation (16) as follows:
The Theorem is proved.
Appendix C. Proof of Theorem 5.1
Let us define and , then
Let also then
Using we obtain . Now, by the fact
and replacing , and to the left-hand side of the last inequality we have
Computing the square form of the third and fourth terms we have that
Let then iterating over the previous inequality, we have
By Equation (A8) we have that . Taking into account that is a sequence that is bounded, we have that there is a point such that any subsequence fulfills that (Weierstrass theorem). Now, we have that . Leting in Equation (19) and taking the limit when we obtain
As a result, we have that . Provided that is monotonically decreasing then there exists a unique limit point (equilibrium point). As a result, the sequence satisfies that with a rate given by .
References
- Hurwicz, L. Optimality and informational efficiency in resource allocation processes. In Mathematical Methods in the Social Sciences: Proceedings of the First Stanford Symposium; Arrow, K.J., Karlin, S., Suppes, P., Eds.; Stanford University Press: Palo Alto, CA, USA, 1960; pp. 27–46. [Google Scholar]
- Nobel. The Sveriges Riksbank Prize in Economic Sciences in Memory of Alfred Nobel 2007: Scientific Background; Technical Report; The Nobel Foundation: Stockholm, Sweden, 2007. [Google Scholar]
- Myerson, R.B. Allocation, Information and Markets; Chapter Mechanism Design; The New Palgrave; Palgrave Macmillan: London, UK, 1989; pp. 191–206. [Google Scholar]
- Vickrey, W. Counterspeculation, auctions, and competitive sealed tenders. J. Financ. 1961, 16, 8–37. [Google Scholar] [CrossRef]
- Bergemann, D.; Välimäki, J. Dynamic mechanism design: An introduction. J. Econ. Perspect 2019, 52, 235–274. [Google Scholar] [CrossRef]
- Clarke, E. Multi-part pricing of public goods. Public Choice 1971, 11, 17–23. [Google Scholar] [CrossRef]
- Groves, T. Incentives in teams. Econometrica 1973, 41, 617–631. [Google Scholar] [CrossRef]
- Harsanyi, J.C. Games with incomplete information played by bayesian players. part i: The basic model. Manag. Sci. 1967, 14, 159–182. [Google Scholar] [CrossRef]
- Arrow, K. Economics and Human Welfare; Chapter The Property Rights Doctrine and Demand Revelation under Incomplete Information; Academic Press: New York, NY, USA, 1979; pp. 23–39. [Google Scholar]
- D’Aspremont, C.; Gerard-Varet, L. Incentives and incomplete information. J. Public Econ. 1979, 11, 25–45. [Google Scholar]
- Saari, D.G. On the types of information and mechanism design. J. Comput. Appl. Math. 1988, 22, 231–242. [Google Scholar] [CrossRef][Green Version]
- Rogerson, W. Contractual solutions to the hold-up problem. Rev. Econ. Stud. 1992, 59, 777–793. [Google Scholar] [CrossRef]
- Mailath, G.; Postlewaite, A. Asymmetric information bargaining problems with many agents. Rev. Econ. Stud. 1990, 57, 351–360. [Google Scholar] [CrossRef]
- Miyakawa, T. Non-Cooperative Foundation of Nash Bargaining Solution under Incomplete Informational; Osaka University of Economics Working Paper Serier No. 2012-2.; Osaka University: Suita, Japan, 2012. [Google Scholar]
- Athey, S.; Bagwell, K. Collusion with persistent cost shocks. Econometrica 2008, 76, 493–540. [Google Scholar] [CrossRef]
- Hörner, J.; Takahashi, S.; Vieille, N. Truthful equilibria in dynamic bayesian games. Econometrica 2015, 83, 1795–1848. [Google Scholar] [CrossRef][Green Version]
- Clempner, J.B.; Poznyak, A.S. A nucleus for bayesian partially observable markov games: Joint observer and mechanism design. Eng. Appl. Artif. Intell. 2020, 95, 103876. [Google Scholar] [CrossRef]
- Rahman, D. The power of communication. Am. Econ. Rev. 2014, 104, 3737–3751. [Google Scholar] [CrossRef]
- Bernheim, B.; Madsen, E. Price cutting and business stealing in imperfect cartels. Am. Econ. Rev. 2017, 107, 387–424. [Google Scholar] [CrossRef][Green Version]
- Escobar, J.F.; Llanes, G. Cooperation dynamics in repeated games of adverse selection. J. Econ. Theory 2018, 176, 408–443. [Google Scholar] [CrossRef]
- Poznyak, A.S.; Najim, K.; Gómez-Ramírez, E. Self-Learning Control of Finite Markov Chains; Marcel Dekker, Inc.: New York, NY, USA, 2000. [Google Scholar]
- Clempner, J.B.; Poznyak, A.S. Simple computing of the customer lifetime value: A fixed local-optimal policy approach. J. Syst. Sci. Syst. Eng. 2014, 23, 439–459. [Google Scholar] [CrossRef]
- Clempner, J.B.; Poznyak, A.S. Observer and control design in partially observable finite markov chains. Automatica 2019, 110, 108587. [Google Scholar] [CrossRef]
- Clempner, J.B. On lyapunov game theory equilibrium: Static and dynamic approaches. Int. Game Theory Rev. 2018, 20, 1750033. [Google Scholar] [CrossRef]
- Clempner, J.B.; Poznyak, A.S. Finding the strong nash equilibrium: Computation, existence and characterization for markov games. J. Optim. Theory Appl. 2020, 186, 1029–1052. [Google Scholar] [CrossRef]
- Sragovich, V.G. Mathematical Theory of Adaptive Control; World Scientific Publishing Company: Singapore, 2006. [Google Scholar]
- Asiain, E.; Clempner, J.B.; Poznyak, A.S. A reinforcement learning approach for solving the mean variance customer portfolio for partially observable models. Int. J. Artif. Intell. Tools 2018, 27, 1850034-1–1850034-30. [Google Scholar] [CrossRef]
- Trejo, K.K.; Clempner, J.B.; Poznyak, A.S. Computing the lp-strong nash equilibrium for markov chains games. Appl. Math. Model. 2017, 41, 399–418. [Google Scholar] [CrossRef]
- Hotelling, H. Stability in competition. Econ. J. 1929, 39, 41–57. [Google Scholar] [CrossRef]
- Downs, A. An Economic Theory of Democracy; Harper & Brothers: New York, NY, USA, 1957. [Google Scholar]
- Solis, C.; Clempner, J.B.; Poznyak, A.S. Robust extremum seeking for a second order uncertain plant using a sliding mode controller. Int. J. Appl. Math. Comput. Sci. 2019, 29, 703–712. [Google Scholar] [CrossRef]
- Solis, C.; Clempner, J.B.; Poznyak, A.S. Robust integral sliding mode controller for optimisation of measurable cost functions with constraints. Int. J. Control 2019, 1–13, To be published. [Google Scholar] [CrossRef]
- Solis, C.; Clempner, J.B.; Poznyak, A.S. Continuous-time gradient-like descent algorithm for constrained convex unknown functions: Penalty method application. J. Comput. Appl. Math. 2019, 355, 268–282. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).