A Clustering Perspective of the Collatz Conjecture




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- The orbit of a is unbounded, i.e., .
- The orbit of a is periodic and non-trivial, i.e., there is such that , for .
- On the other hand, there are numerical experiments that show that the conjecture holds for numbers which are smaller than a certain threshold , or that the Collatz functions does not have non-trivial cycles with length less or equal to . The values of m and N have been continuously improved, and, nowadays, we can ensure that the conjecture holds for (see [1]) or that the length of a non-trivial cycle is, at least, (see [4]). These computational arguments have been feeding continuously the opinion that the Collatz conjecture is true, and that there is no non-trivial cycle.
2. Why Is Collatz Problem Difficult?
2.1. Number Theory Arguments
2.2. Probabilistic Arguments
3. Clustering Analysis and Visualization
3.1. Hierarchical Clustering
3.2. Multidimensional Scaling
3.3. The Adopted Computational Algorithm
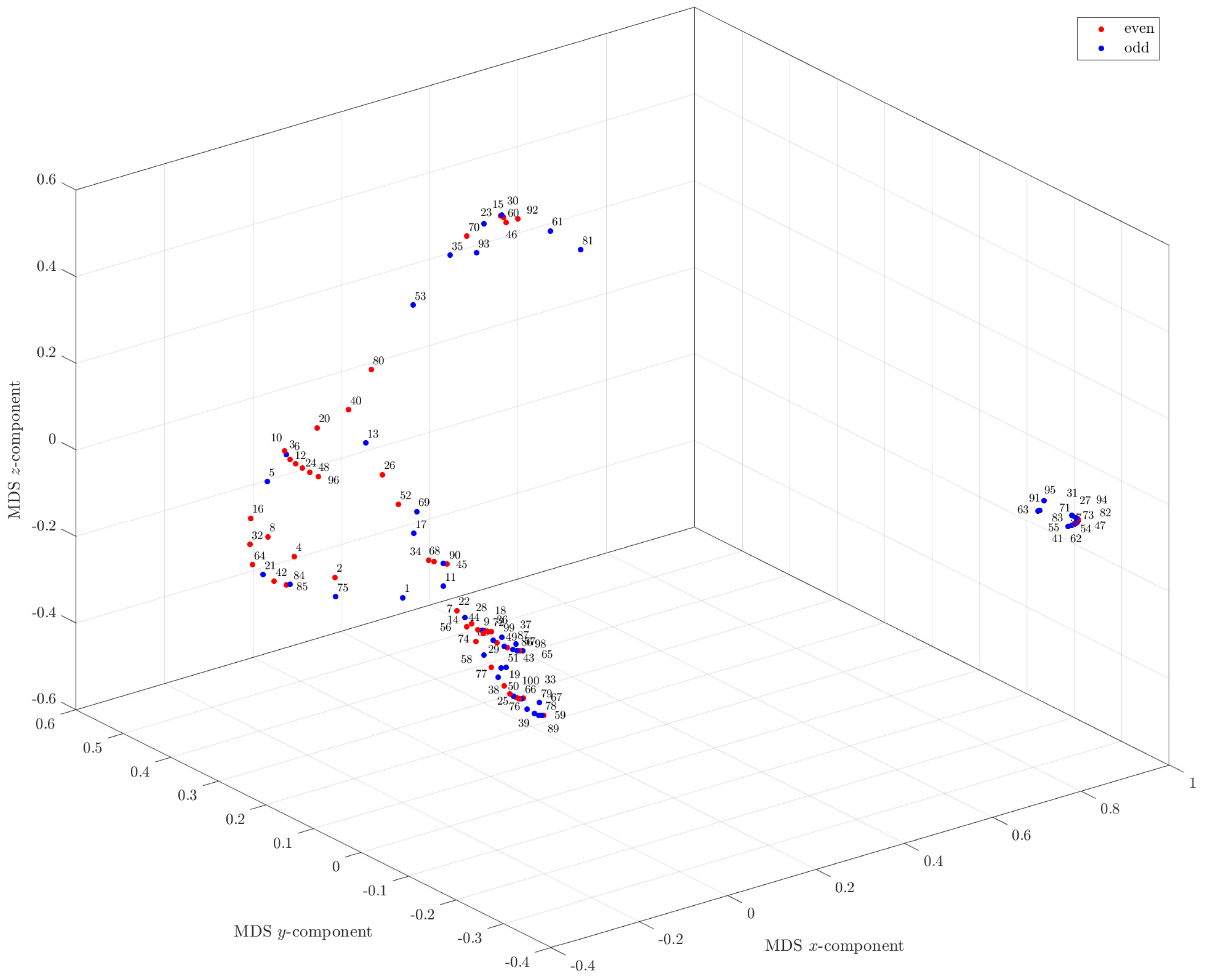
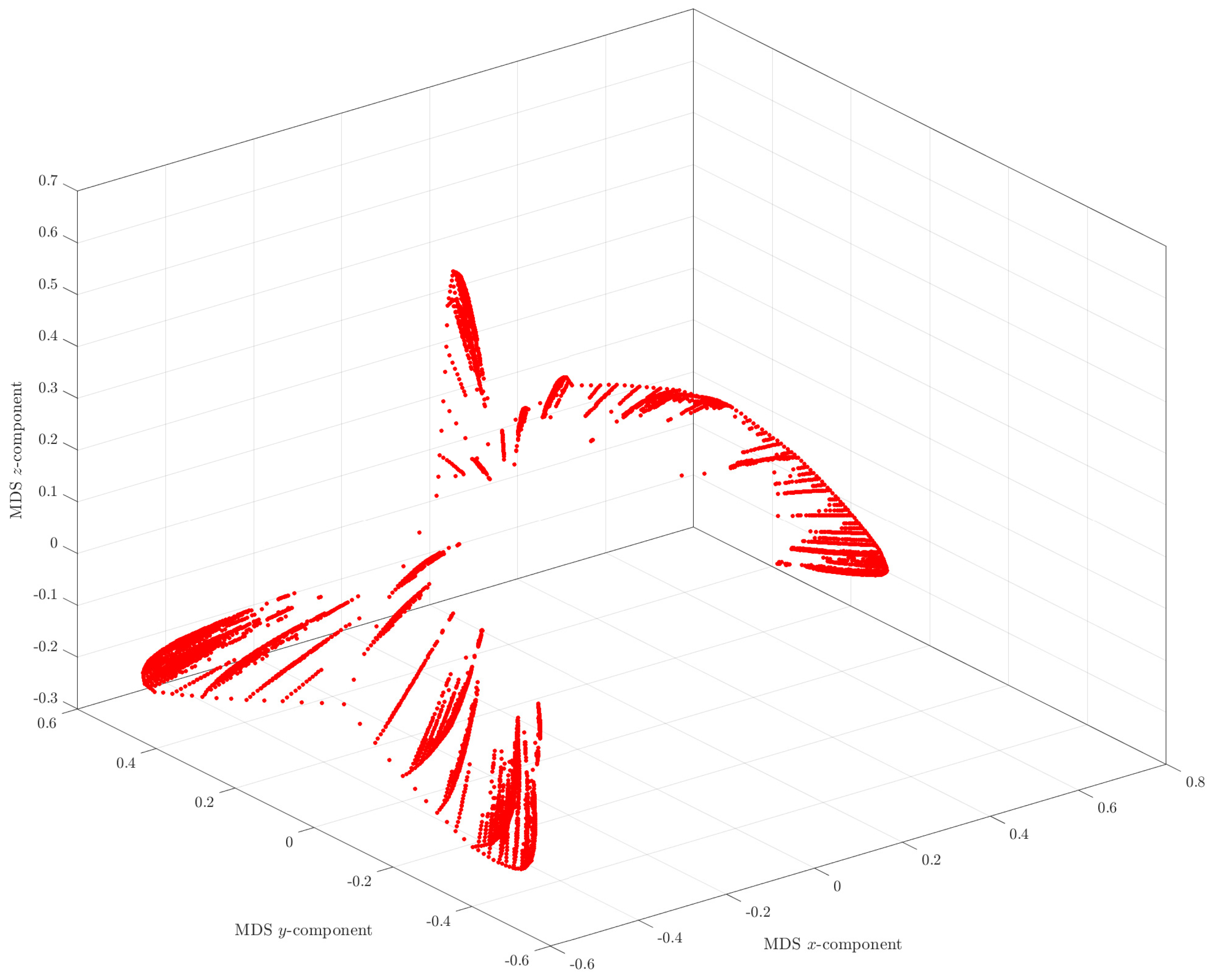
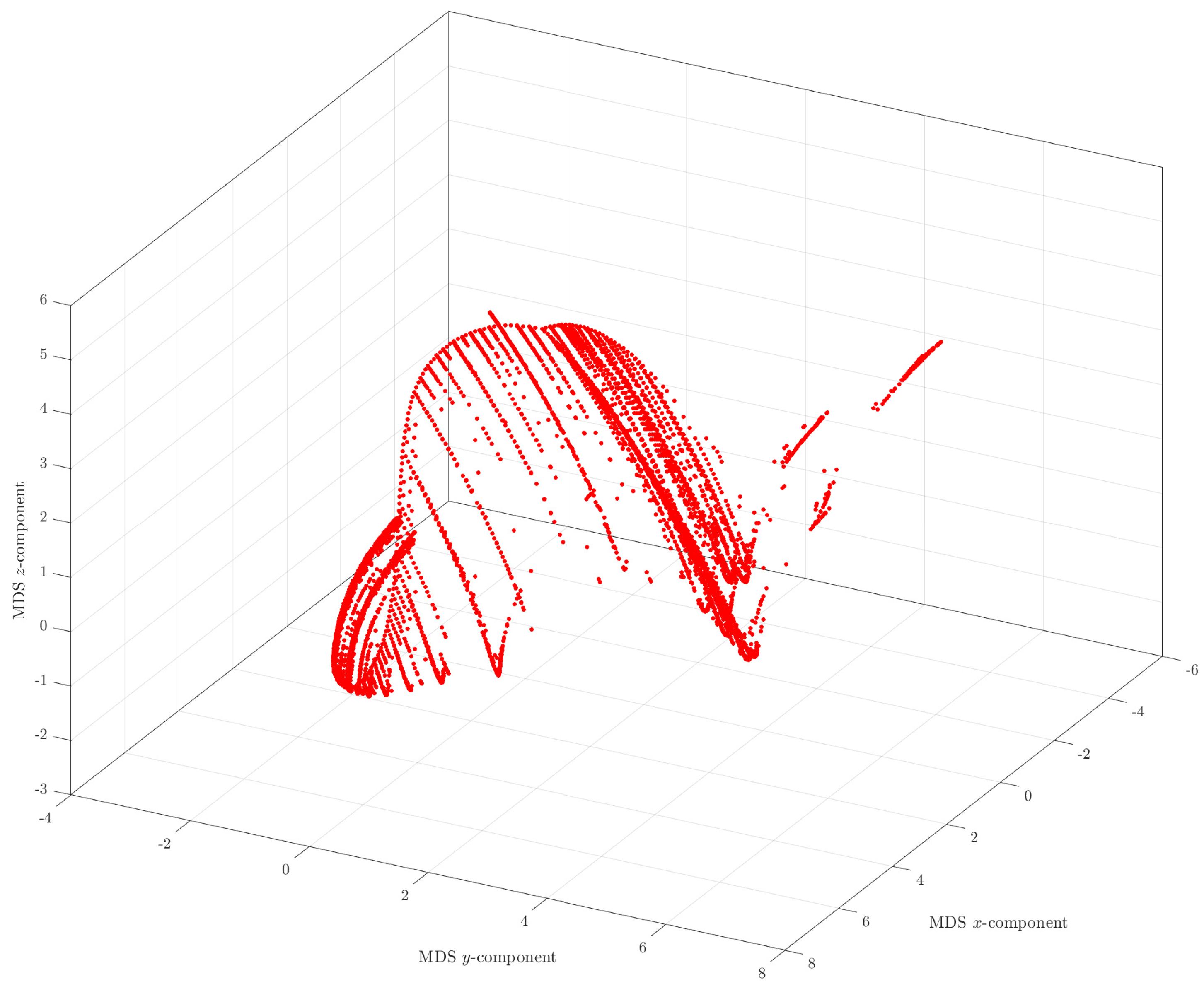
3.4. MDS Analysis of the Hailstone Sequences
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lagarias, J. The Ultimate Challenge: The 3x + 1 Problem; American Mathematical Society: Providence, RI, USA, 2010. [Google Scholar]
- Ilia Krasikov, J.C.L. Bounds for the 3x + 1 problem using difference inequalities. Acta Arith. 2003, 109, 237–258. [Google Scholar] [CrossRef][Green Version]
- Tao, T. Almost all orbits of the Collatz map attain almost bounded values. arXiv 2019, arXiv:1909.03562v3. [Google Scholar]
- Eliahou, S. The 3x + 1 problem: New lower bounds on nontrivial cycle lengths. Discret. Math. 1993, 118, 45–56. [Google Scholar] [CrossRef]
- Böhm, C.; Sontacchi, G. On the existence of cycles of given length in integer sequences like xn+1 = xn/2 if xn even, and xn+1 = 3xn + 1 otherwise. Atti Accad. Naz. Lincei VIII. Ser. Rend. Cl. Sci. Fis. Mat. Nat. 1978, 64, 260–264. [Google Scholar]
- Andrei, S.; Kudlek, M.; Niculescu, R.S. Chains in Collatz’s Tree; Technical Report; Department of Informatics, Universität Hamburg: Hamburg, Germany, 1999. [Google Scholar]
- Andaloro, P.J. The 3x + 1 Problem and Directed Graphs. Fibonacci Q. 2002, 40, 43–54. [Google Scholar]
- Snapp, B.; Tracy, M. The Collatz Problem and Analogues. J. Integer Seq. 2008, 11, 1–10. [Google Scholar]
- Laarhoven, T.; de Weger, B. The Collatz conjecture and De Bruijn graphs. Indag. Math. 2013, 24, 971–983. [Google Scholar] [CrossRef]
- Emmert-Streib, F. Structural Properties and Complexity of a New Network Class: Collatz Step Graphs. PLoS ONE 2013, 8, e56461. [Google Scholar] [CrossRef][Green Version]
- Sultanow, E.; Koch, C.; Cox, S. Collatz Sequences in the Light of Graph Theory; Universität Potsdam: Potsdam, Germany, 2019. [Google Scholar] [CrossRef]
- Ebert, H. A Graph Theoretical Approach to the Collatz Problem. arXiv 2020, arXiv:1905.07575. [Google Scholar]
- Kruskal, J. Multidimensional scaling by optimizing goodness of fit to a nonmetric hypothesis. Psychometrika 1964, 29, 1–27. [Google Scholar] [CrossRef]
- Kruskal, J.B.; Wish, M. Multidimensional Scaling; Sage Publications: Newbury Park, CA, USA, 1978. [Google Scholar]
- Sammon, J.W. A nonlinear mapping for data structure analysis. IEEE Trans. Comput. 1969, C-18, 401–409. [Google Scholar] [CrossRef]
- Hartigan, J.A. Clustering Algorithms; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1975. [Google Scholar]
- Borg, I.; Groenen, P.J. Modern Multidimensional Scaling-Theory and Applications; Springer: New York, NY, USA, 2005. [Google Scholar]
- De Leeuw, J.; Mair, P. Multidimensional scaling using majorization: Smacof in R. J. Stat. Softw. 2009, 31, 1–30. [Google Scholar] [CrossRef]
- Shepard, R.N. The analysis of proximities: Multidimensional scaling with an unknown distance function. Psychometrika 1962, 27, 125–140. [Google Scholar] [CrossRef]
- Fernández, A.; Gómez, S. Solving non-uniqueness in agglomerative hierarchical clustering using multidendrograms. J. Classif. 2008, 25, 43–65. [Google Scholar] [CrossRef]
- Saeed, N.; Nam, H.; Haq, M.I.U.; Muhammad Saqib, D.B. A Survey on Multidimensional Scaling. ACM Comput. Surv. (CSUR) 2018, 51, 47. [Google Scholar] [CrossRef]
- Machado, J.T.; Lopes, A. Multidimensional scaling and visualization of patterns in prime numbers. Commun. Nonlinea. Sci. Numer. Simul. 2020, 83, 105128. [Google Scholar] [CrossRef]
- Machado, J.A.T. An Evolutionary Perspective of Virus Propagation. Mathematics 2020, 8, 779. [Google Scholar] [CrossRef]
- Machado, J.T.; Lopes, A.M. A computational perspective of the periodic table of elements. Commun. Nonlinea. Sci. Numer. Simul. 2019, 78, 104883. [Google Scholar] [CrossRef]
- Machado, J.T.; Lopes, A.M. Multidimensional scaling locus of memristor and fractional order elements. J. Adv. Res. 2020, 25, 147–157. [Google Scholar] [CrossRef]
- Machado, J.A.T.; Rocha-Neves, J.M.; Andrade, J.P. Computational analysis of the SARS-CoV-2 and other viruses based on the Kolmogorov’s complexity and Shannon’s information theories. Nonlinear Dyn. 2020, 101, 1731–1750. [Google Scholar] [CrossRef]
- Tenreiro Machado, J.A.; Lopes, A.M.; Galhano, A.M. Multidimensional Scaling Visualization Using Parametric Similarity Indices. Entropy 2015, 17, 1775–1794. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Hinneburg, A.; Keim, D.A. On the Surprising Behavior of Distance Metrics in Gigh Dimensional Space; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Sokal, R.R.; Rohlf, F.J. The comparison of dendrograms by objective methods. Taxon 1962, 33–40. [Google Scholar] [CrossRef]
- Felsenstein, J. PHYLIP (Phylogeny Inference Package), Version 3.5 c; University of Washington: Seattle, WA, USA, 1993. [Google Scholar]
- Tuimala, J. A Primer to Phylogenetic Analysis Using the PHYLIP Package; CSC—Scientific Computing Ltd.: Leeds, UK, 2006. [Google Scholar]
- Cha, S.H. Comprehensive Survey on Distance/Similarity Measures between Probability Density Functions. Int. J. Math. Models Methods Appl. Sci. 2007, 1, 300–307. [Google Scholar]
- Deza, M.M.; Deza, E. Encyclopedia of Distances; Springer-Verlag: Berlin, Heidelberg, 2009. [Google Scholar]
- Hamming, R.W. Error Detecting and Error Correcting Codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Machado, J.A.T.; Galhano, A.; Cao Labora, D. A Clustering Perspective of the Collatz Conjecture. Mathematics 2021, 9, 314. https://doi.org/10.3390/math9040314
Machado JAT, Galhano A, Cao Labora D. A Clustering Perspective of the Collatz Conjecture. Mathematics. 2021; 9(4):314. https://doi.org/10.3390/math9040314
Chicago/Turabian StyleMachado, José A. Tenreiro, Alexandra Galhano, and Daniel Cao Labora. 2021. "A Clustering Perspective of the Collatz Conjecture" Mathematics 9, no. 4: 314. https://doi.org/10.3390/math9040314
APA StyleMachado, J. A. T., Galhano, A., & Cao Labora, D. (2021). A Clustering Perspective of the Collatz Conjecture. Mathematics, 9(4), 314. https://doi.org/10.3390/math9040314