4.1. Essential Formal Concepts
Essential concepts, also called
mandatory concepts (MCs), play a crucial role in data mining as they allow the discovery of regular structures from data based on formal concept analysis (FCA). They qualify as essential because they belong to any conceptual coverage of a formal context [
22]. From the relational algebra (RA) perspective, an essential concept contains at least one isolated point, as introduced by Riguet [
30]. As a mathematical background, FCA and RA have already been combined and used to discover regularities in data [
18]. A formal concept represents the regular atomic structure for decomposing a binary relation. Moreover, the computing of Riguet’s difunctional relation [
30] results in a set of isolated points describing invariant structures that could be used for database decomposition and textual feature selection (TFS) [
19]. Furthermore, an isolated point belongs to a unique formal concept that exists in any conceptual coverage. Therefore, any FCA-based knowledge discovery process necessarily considers such concepts. Several approaches have been proposed to locate the essential concepts in a formal context to build conceptual coverage. This paper presents alternatives for conceptual coverage construction, and we discuss their main characteristics and features. Nevertheless, finding the most efficient strategy remains a challenging perspective.
Definition 9 (Isolated Point). Let us consider a formal context = . An element is said to be an isolated point if it belongs to only one formal concept.
Definition 10 (Essential Concept). A formal concept is called essential if it contains at least one isolated point.
Theorem 1. A formal concept is essential if it is both an object concept and an attribute concept.
Proof. ⇒. Let be a formal concept that introduces the objects in a nonempty set and the attributes in a nonempty set . Let . By definition, and . Hence, for any formal concept such that and , we have and . As is a formal concept and thus maximal, and . Consequently, for all , only belongs to , which is consequently essential.
⇐. Let be an essential concept and be an isolated point that only belongs to . We find that and . This means that , by definition, introduces both o and i and is thus an object concept and attribute concept. □
Example 7. With respect to Table 2, we find the following: , , and introduce both an object and an attribute and are essential concepts. Corollary 1. Let be a formal context. Let such as , . Let be the associated formal concept to , where . The element is an isolated point if o is a minimal generator [31] of A and i is a minimal generator of B. Proof. The proof is straightforward since, by definition, a minimal generator is the smallest element for which the closure computation leads to the closed element. Thus, since o and i are minimal generators, which is equivalent to being an object concept and attribute concept, respectively, is an isolated point. □
The following theorem introduces the formal characterization of an isolated point.
Theorem 2. Let us consider a formal context and . The element is an isolated point if .
Proof. The proof shows that for an essential formal concept , an element exists such that . Since , then we have . Moreover, we find , which means that the object exactly generates the extent part X; that is, . In addition, this also means that is the only item that appears exactly in the same objects as X. In consequence, i is also a minimal generator of Y. □
Corollary 2. Let us consider a formal concept . If , then is an essential formal concept.
Proof. If the extent part is reduced to a singleton, this single object is the object concept of C. Then, the proof that , such that it is an attribute concept of C—i.e., is an isolated point—remains true. Since the cardinality of the extent part of C is equal to 1, it means that this object, say o, fulfills this property, . □
Example 8. According to the formal context given in Table 1, the list of essential concepts can be easily checked: ; ; . If we consider the formal context given by Table 2, all of its formal concepts are essential. Remark 1. Let us consider the particular formal context given by Table 3. As this table shows, no essential formal concepts can be mined. In the following, we provide a formal characterization of the type of formal context, namely the “worst case”, and prove that we cannot mine essential formal concepts from this type of formal context. A “worst case” formal context is defined as follows:
Definition 11. A “worst case” context is a triplet where is a finite set of items of size n, represents a finite set of objects of size , and is a binary (incidence) relation (i.e., ⊆. In such a context, each item belongs to n distinct objects. Each object, among the first n objects, contains distinct items, and the last object is fulfilled by all items.
Thus, in a “worst case” context, each object concept/attribute concept is equal to its unique minimal generator. Hence, from a “worst case” context of a dimension equal to
n×
+
, 2
formal concepts can be extracted. Even if the worst case is rarely encountered in practice, “worst case” datasets have been shown to allow the behavior of an algorithm to be scrutinized on extremely sparse concepts and hence to assess its scalability [
15].
Table 4 presents an example of a “worst case” dataset for
.
Corollary 3. No essential concepts can be extracted from a worst case formal context.
Proof. Let us consider a worst case formal context . By constructing a worst case dataset, and with regard to Theorem 2, we have the following assumptions:
, we find always that . Thus, no essential concepts can be drawn from a worst case dataset. □
4.2. Description of the Concise Algorithm
In the following, we present the description and the pseudocode of the
Concise algorithm. According to the pseudocode described by Algorithm 1, we start by computing the basic information from the ground set items of the given formal context. Then, this process computes the corresponding formal concept for each item. The different steps followed to obtain minimal conceptual coverage are detailed in the remainder of this section.
| Algorithm 1: The Concise algorithm. |
 |
The Concise algorithm proceeds according to the following steps:
- Step 1:
Detect the essential concepts
After closing the items through the
Compute_Introductory_Closure procedure, the efficient detection of the set of essential formal concepts (if they exist) is conducted by the
Compute_Essential_Concepts function. The corresponding pseudocode is provided by Algorithm 2. The algorithm iterates over the seed set of attributes
. In (Lines 4–8) and with regard to Corollary 2, if the cardinality of the extent part is equal to 1, then its induced formal concept is considered an essential concept, and we remove all the covered elements from the formal context. Otherwise, we iterate over the extent part, seeking an object whose support is equal to the cardinality of the intent part (c.f. Lines 12–16). Finally, we run the second and third steps if the essential concepts do not reach the threshold
covering the formal context.
| Algorithm 2:Compute_Essential_Concepts. |
 |
- Step 2:
Compute the size of noncovered elements
For each noncovered element , we proceed by obtaining its corresponding pseudoconcept through the Get_PseudoConcept function and assessing its size by calling the Compute_Size function (c.f. Lines 10–11). We provide a more straightforward reformulation of the size in the Compute_Size function based on the following corollary.
Corollary 4. Let us consider the element . The size of its corresponding pseudoconcept according to Equation (5) can be rewritten as follows: Example 9. If we consider the formal context depicted by Table 1, then element and its corresponding pseudoconcept are calculated as The size of this pseudoconcept is computed as follows: The following pseudocode given by Algorithm 3 illustrates the
Compute_Size function.
| Algorithm 3:Compute_Size. |
 |
- Step 3:
Greedily cover the remaining concepts
We repeat this algorithm step when the fixed threshold
of covered elements (c.f. Line 14) is not reached. Then, for each uncovered element, we call the
Calculate_Best_FC function (c.f. Line 17) to obtain the best candidate to add to the concept coverage. This best candidate is selected according to a quality metric. In the
Calculate_Best_FC function, we use the
bond measure [
32], and the chosen concept is the concept that maximizes this measure. This correlation measure computes the ratio between the conjunctive support and the disjunctive support. In [
7], it was shown that this metric results in formal concepts with high quality. The bond measure of a nonempty pattern
is defined as follows:
If we consider the formal concept
, the formula of the bond can be expressed as follows:
Equation (
9) shows that for a formal concept
such that
, we have
s.t.
and
.
Therefore, if the cardinality of the intent part is equal to 1, then it is the best formal concept, in terms of the bond metric, from all the formal concepts included in the pseudoconcept induced by element .
Algorithm 4 describes the pseudocode of the
Calculate_Best_FC function. As outlined by Line 3, we have to explore
formal concepts exactly. Indeed, it is useless to explore all the formal concepts obtained by combining the seed attributes. From them, we will return the best concept in terms of the bond measure. We do not need to generate the formal concepts since we can decide on their extent. Then, we assess the bond metric value of each generated concept using Equation (
9) (c.f. Line 7). The formal concept having the highest bond value is the returned
(c.f. Line 10).
| Algorithm 4:Calculate_BestFC. |
 |
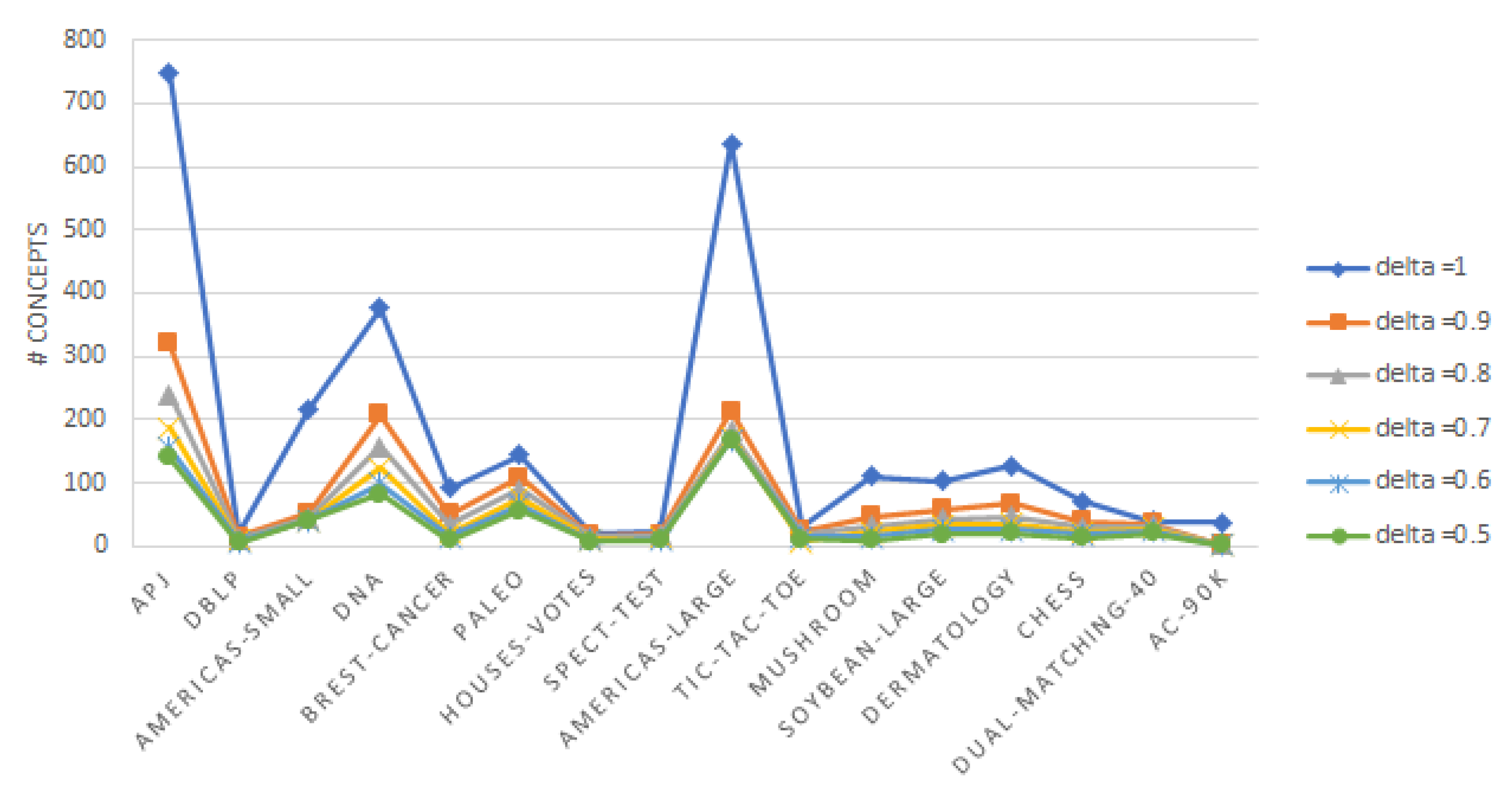
Example 10. In this example, we illustrate the different phases of theConcisealgorithm for building minimal conceptual coverage. Let us consider the formal context given by Table 1 with a threshold δ = 1. The procedure of the algorithm is depicted in Table 5. Step 1: During this step, we first call the Compute_Introductory_Closure procedure, and we obtain Table 6. Then, we invoke the Compute_Essential_Concepts function, and we find that , , are isolated points. Thus, we have three essential formal concepts and . Since does not fully cover = , we proceed to the second step. Step 2: In this step, we compute the pseudoconcept of elements in the formal concept by invoking the Get_PseudoConcept function. Next, the size of each pseudoconcept is assessed through the Compute_Size function. Then, the elements are sorted in decreasing order via the Sort_Elements procedure.
Step 3: The different outputs obtained during this step are also detailed in Table 5. After sorting the elements, we find that and are ranked first with a size value equal to . Since element has already been covered by an essential concept, the best formal concept is . Thus, we update the list of concept coverage as follows: , , , . All the elements covered by this list of formal concepts are removed from the initial list. Then, element with a size value equal to comes into play, and the formal concept is added to . Then, element with a size value equal to comes to the top. Consequently, the formal concept is added to , and the latter becomes equal to , , , , , and . After removing the covered elements, we find on the top of the remaining elements the couple (as shown by Table 5). The best concept obtainable from the latter is . Thanks to the latter formal concept, all the elements of the formal context are covered, and the final cover of 7 formal concepts is as follows: , , , , , , . 








{kind=link}
{kind=link}