Abstract
Structural analysis is a method for verifying equation-oriented models in the design of industrial systems. Existing structural analysis methods need flattening of the hierarchical models into an equation system for analysis. However, the large-scale equations in complex models make structural analysis difficult. Aimed to address the issue, this study proposes a hierarchical structural analysis method by exploring the relationship between the singularities of the hierarchical equation-oriented model and its components. This method obtains the singularity of a hierarchical equation-oriented model by analyzing a dummy model constructed with the parts from the decomposing results of its components. Based on this, the structural singularity of a complex model can be obtained by layer-by-layer analysis according to their natural hierarchy. The hierarchical structural analysis method can reduce the equation scale in each analysis and achieve efficient structural analysis of very complex models. This method can be adaptively applied to nonlinear-algebraic and differential-algebraic equation models. The main algorithms, application cases and comparison with the existing methods are present in this paper. The complexity analysis results show the enhanced efficiency of the proposed method in the structural analysis of complex equation-oriented models. Compared with the existing methods, the time complexity of the proposed method is improved significantly.
1. Introduction
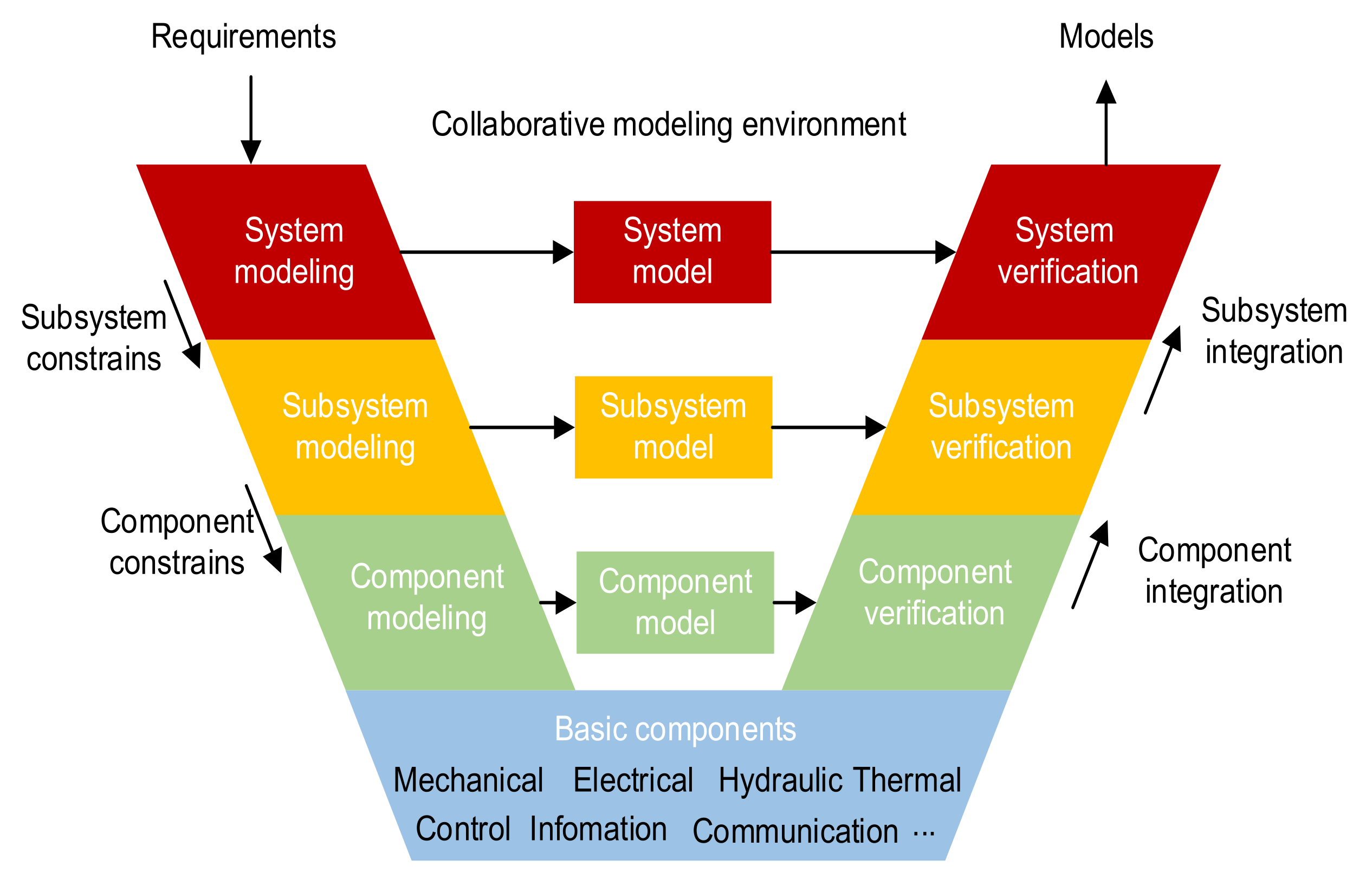
With the increasing complexity and scale of modern industrial products, model-based approaches have become essential in studying these products, being applied in areas such as design [1,2], simulation [3] and diagnosis [4,5,6]. The modular models in different abstraction levels enable collaborative work and component reuse and speed up product modeling with a V-shaped process, as shown in Figure 1. The requirements are hierarchically decomposed into the modeling constraints of subsystems and components in different abstraction levels. These models are constructed based on the predefined components or the models in the lower level, thereby forming a hierarchical structure. Equation-oriented models (EoMs) are often adopted to model multi-domain systems because of their convenience in modeling and ability to express physical characteristics [7]. Guided by the modeling purpose, hierarchical EoMs can abstract putative systems to predict states and behavior effectively [1]. Languages and tools for EoMs, such as Modelica [8], gPROMS [9], Dymola [10] and MWorks [11], have been widely investigated in engineering applications to express the static and dynamic characteristics of physical systems [7,12].
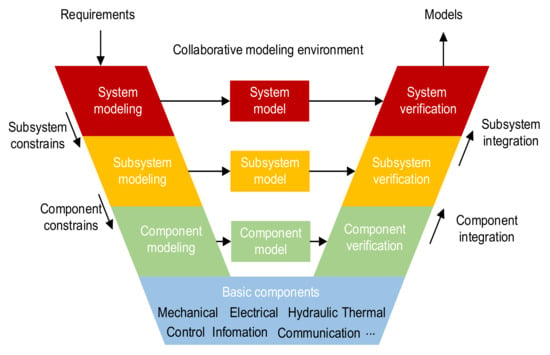
Figure 1.
V-shaped process of system modeling.
A typical problem in EoM modeling tools is the state inconsistency in the simulation, which occurs when too many or too few equations are specified in the model [7,12]. An EoM with defects is called singular, which means that the underlying equation system has no unique and deterministic solution. The non-singularity of an EoM is the preliminary of system representation and simulation.
Structural analysis can verify the non-singularity of an EoM in the static analysis stage. Theoretically, the non-singularity of an EoM can be guaranteed by the numerical non-singularity of the underlying equation system. However, verifying the numerical non-singularity is very expensive, even as expensive as solving the equations when it comes to the algebraic equation models [7,12]. During the modeling, the singularity of a model should be fed back as quickly as possible. Therefore, in the static analysis stage, the non-singularity of structural analysis is assumed to be a sufficient condition for implying that the equation system has a unique and deterministic solution [12,13]. The structural analysis of EoMs is equivalent to analyzing the structure of the underlying equation systems. It depends on the correlation between the variables and equations, regardless of the numerical values of the variables.
The structural analysis of equation systems has been an important research area since the 1960s. In 1962, Steward reviewed the related works on equation system analysis and proposed basic concepts and methods to verify the solvability of an equation system with computers [14]. Subsequently, studies on structural analysis algorithms [15,16] and applications [17] have been conducted. These early works focused on partitioning large systems into small ones and testing if each of them was solvable [15,16]. The main principle to achieve this test was to permute the incidence matrix to a block lower triangular (BLT) matrix to make all diagonal elements non-zero. Based on the BLT form, the equations can be solved efficiently and sequentially with a forward substitution process [12]. The non-zero traversal of the incidence matrix is also considered a procedure that assigns each variable to a unique equation such that the variable appears in this equation [7,18]. If pairing variables and equations is impossible, then the equation system is structurally singular. The assignment method is always performed based on a bipartite graph representation. Equivalent to the matrix traversing method, this graph-represented method can use sparsity better to achieve improved performance in the sequential computation environment. However, these methods are only applicable to the structural analysis of algebraic EoMs expressing the static characteristics of the systems.
There are also works on the structural analysis for differential-algebraic equation (DAE) models that denote the dynamic characteristics of systems. Mattsson applied the assignment method for algebraic equations to DAEs without distinguishing between the appearances of a variable and its derivatives , … [18]. This method is efficient but limited to catching singular models early, because a model can still be singular despite satisfying the assignment relation. The structural analysis of DAE models must consider the variable index and the initial conditions. Pantelides proposed a criterion for determining whether a subset of the equations should be differentiated to provide further constraints to the initial conditions [19]. His method is implemented as a graph-based algorithm to find consistent initial values for a DAE system. Unger derived the index reduction algorithm proposed by Gear [20] and presented a symbolical structural analysis algorithm based on the structural differentiation matrices [21]. The structural properties of DAEs, such as the solvability, dynamic degree of freedom and consistent initial condition, can be obtained by analyzing the structural differentiation matrices. Pryce proposed another matrix traversing approach to determine the highest order of derivatives to each equation and the highest indices of each variable based on the signature matrix [22]. This method converts the structural index problem into a maximum weight assignment problem to seek the highest-value traversal in the signature matrix. It is equivalent to the algorithm by Pantelides for the index-1 DAEs. The last 20 years have seen several extension works on developing the signature matrix-based structural analysis methods [23,24,25,26,27] and related tools [28]. However, these approaches only find, but cannot diagnose, the ill-posed model, because they will terminate their execution if a structural deficiency is encountered.
The diagnosis of structural singularity can be realized by Dulmage and Mendelsohn’s (DM) decomposition algorithm [29,30]. Bunus realized DM decomposition with a graph-represented algorithm to find singular equations in a flat equation system [12]. Ding proposed a method to locate structural singularities in hierarchical Modelica models [31]. Their diagnosis method does not distinguish a variable and its derivatives in DAE systems. Soares realized a detailed diagnosis of DAEs by extending the graph-based algorithm by Pantelides [7]. This diagnosis obtains the information about the index and dynamic degree of freedom by augmenting the DAE system and finding a maximum matching in the bipartite graph of the augmented system. This method obtains a similar result with the signature matrix method presented in [22]. The DM decomposition algorithm can be applied to the augmented bipartite graph to diagnose the singularity source.
Although extensive works have been performed toward structural analysis, the computation of existing methods and tools is prohibitive when facing large-scale equations in the models of complex systems. For example, the variables and equations in a plane model can be millions or tens of millions in size. These approaches perform structural analysis based on the overall equation system obtained by flattening the hierarchical EoMs, thereby imposing challenges for analyzing the structural singularity of equations on such a scale. Some technical attempts, such as modeling and simulating different subsystems separately, verifying the DAE as nonlinear-algebraic equation (NLAE) systems [12,31] or decomposing the equations set into parts to analyze them separately [12] have been noted to address this challenge. However, the resultant defects such as the local optimal, low accuracy and additional computations from the decomposition are non-negligible for practical implementation.
In practical engineering, the EoMs are always modular and have a hierarchical structure. The components in a model are coupled with a few variables and equations. It is the natural sparse decomposition of an EoM. The structural analysis of complex EoMs can be carried out based on the natural hierarchical structure to avoid processing all the flattened equations at once. Based on this idea, this paper explores the relationship between the structural singularities of an EoM and its components and proposes a hierarchical structural analysis method. The proposed method can be adaptively applied to EoMs of different equation types. The hierarchical structural analysis of NLAE models that express static characteristics and DAE models that express dynamic characteristics are implemented as application cases. The main algorithms and the proof of the equivalence between the proposed method and existing methods based on flattened equations are presented. The efficiency of the proposed method is examined by application comparisons with the existing methods based on the flattened model. The time complexity analysis shows that the hierarchical structural analysis has better performance than the existing methods. Compared with existing structural analysis methods, the following distinguishing features should be noted:
- Rather than performing the structural analysis based on the flattened equation model, the proposed method analyzes a hierarchical EoM based on a dummy model constructed by parts of each component.
- The hierarchical analysis can be performed from the bottom up, layer by layer in the hierarchical model structure. This reduces the scale of equations in each step and enables the structural analysis of extremely complex EoMs.
- The proposed method is more effective for hierarchical EoMs in practical engineering. It can be adaptively applied to NLAE models and DAE models.
The remainder of this paper is organized as follows. Section 2 provides a hierarchical abstraction of EoMs and introduces the basic concepts in the graph-represented structural analysis. Section 3 analyzes the relationship between the structural singularities between the model and its components and proposes the hierarchical structural analysis method. Section 4 applies the hierarchical structural analysis method to NLAE and DAE models. The main algorithms for analyzing the NLAE and DAE models are presented. The equivalence between the result of the proposed method and the existing methods is proven mathematically and verified with application examples. Section 5 discusses the time complexity of the hierarchical structural analysis method. The result is compared with the time complexity of the existing methods to prove its efficiencies. The advantages and disadvantages of the proposed method are discussed. Section 6 concludes this paper and gives possible directions for future research.
2. Preliminary
In this section, we abstract the hierarchical EoMs in different forms to describe them in a united fashion. Some basic concepts in the graph-represented structural analysis are also recalled. Table 1 gives the list of symbols throughout this paper.

Table 1.
The list of symbols.
2.1. Abstraction of Hierarchical Equation-Oriented Models
An EoM, such as the Modelica model or the Simulink model, always includes a set of variables, a set of components that represent the subsystems and a set of equations that represent the relations between these variables and components. It can be abstracted as a triple , where the following are true:
- is a finite set of variables that represents the states;
- is a finite set of components, also named submodels, that represent subsystems at a specific abstraction level;
- is a finite set of equations that represent the relation between the variables in and the variables in each component . Note that the variable in may appear in the equations in .
An EoM without components is called a primary model. A component is called a first-level component. If a sequence for exists, then the model is called an nth-level component of . Correspondingly, if all nth-level components of a model are primary models, then the model is called an n-level model. The variables and components in each level are associated with equations, thereby forming a hierarchical structure.
The hierarchical EoMs are flattened into a set of equations over a set of variables to perform the structural analysis [12]. Consider an n-level model . Define and . For indices , the sequence of variables in each level and the sequence of the components in each level can be defined such that
Let . For the finite levels of , is the set that consists of all variables in . Similarly, we can define and a sequence such that for
Let . Then, is the exact unique set of equations in . Therefore, an arbitrary EoM can be flattened into a primary model without components by induction of layers in the hierarchical structure.
In existing research, the structural analysis of a hierarchical EoM is performed based on the flattened model , which essentially is a set of equations. More details of this hierarchical abstraction of EoMs can be found in [2].
2.2. Concepts in Graph-Represented Structural Analysis
The term “structural singularity” in this paper follows the definition in [12,19]. Structural nonsingularity is a necessary condition for the uniqueness and existence of the solution. The “structural” portion means that the property is independent of the numerical values of the coefficients and variables in the equation. It has different meanings according to the type of equations in the model. For algebraic equation models, the structural singularity is equivalent such that the incidence matrix has no nonzero traversal. For ordinary differential equation (ODE) or DAE models, this means that the incidence matrix of the underlying ODEs formed by the index reduction process has no nonzero traversal. The formal definition of structural singularity for different type equation models will be present in the following sections.
The existing methods transform a hierarchical EoM into a flat equation system to perform the graph-represented or matrix-represented structural analysis [7,12,19,31]. The graph-represented structural analysis methods always have better performance in the sequential computation environment because of their better usage of the sparsity of practical EoMs. They represent the variables and equations in the model as a bipartite graph and analyze the graph to verify the existence and uniqueness of the solution. Here, some necessary concepts in the graph-represented structural analysis are introduced.
Definition 1.
A bipartite graph of an equation model consists of a node set of all variables and equations in the model and an edge set indicating the presence of a variable in each equation.
If the model is a primary model without components, its bipartite graph is . Otherwise, the bipartite graph is , where and are from the flattened model . Since the flattened form of a primary model is itself, the bipartite graph of an equation model can be generally denoted as .
Definition 2.
A matching of a bipartite graph is a subset of edges without common nodes.
Definition 3.
A matching with maximum cardinality is called a maximum matching of the bipartite graph.
Definition 4.
The nodes not covered by a matching are called exposed nodes of .
Definition 5.
If a matching covers all nodes of the variables and equations, then it is called a perfect matching.
Obviously, a perfect matching is a maximum matching. The exposed node set of a perfect matching is empty. Suppose a bipartite graph and a matching of .
Definition 6.
A path in is called an augment path of if it satisfies that (1) it has no repeated nodes; (2) its endpoints are exposed nodes of ; and (3) its edges are alternatively in and in .
Suppose that is a maximum matching of . Then, the feasible path can be defined as follows.
Definition 7.
A path in is called a feasible path if it satisfies that (1) it has no repeated nodes; (2) one of its endpoints is in and the other is an exposed node of ; and (3) its edges are alternatively in and in .
The graph-represented structural analysis needs to find a perfect matching or a maximum matching in the bipartite graph. A model with perfect matching is considered structurally non-singular [7]. Maximum and perfect matching can be found by classic augment path-searching algorithms [32,33,34]. These algorithms search augment paths from arbitrary matching (may be empty) until no new augment path can be observed. Notably, different maximum matchings can be found in a bipartite graph. Based on a maximum matching or perfect matching, new maximum matchings or perfect matchings can be found by altering the matching edges in a feasible path [35,36].
A model is considered structurally singular if its bipartite graph has no perfect matching. The source of singularity needs to be analyzed and reported to users. The canonical decomposition algorithm by Dulmage and Mendelsohn (DM decomposition) is used as one further step to reveal the source of singularity [12,29,31]. Based on a maximum matching , the DM decomposition algorithm canonically decomposes a bipartite graph into three distinct parts: the over-constrained part , the under-constrained part and the well-constrained part . The sets of variables and equations in each part are denoted as , , , , and .
Interestingly, a bipartite graph can admit different maximum matchings, but the final decomposition is unique (i.e., it does not depend on the choice of the maximum matching) [12,37]. Essentially, the DM decomposition considers all possible maximum matchings admitted by the bipartite graph. The over-constrained part is determined by the equations not covered by any possible maximum matchings. Similarly, the under-constrained part is determined by the variables not covered by any possible maximum matchings. The possible exposed variables and equations are searched by enumerating all possible maximum matchings. Although this task is apparently complex, it is indeed a very simple task. In graph theory jargon, this task is just a matter of finding feasible paths that begin at the uncovered nodes [35]:
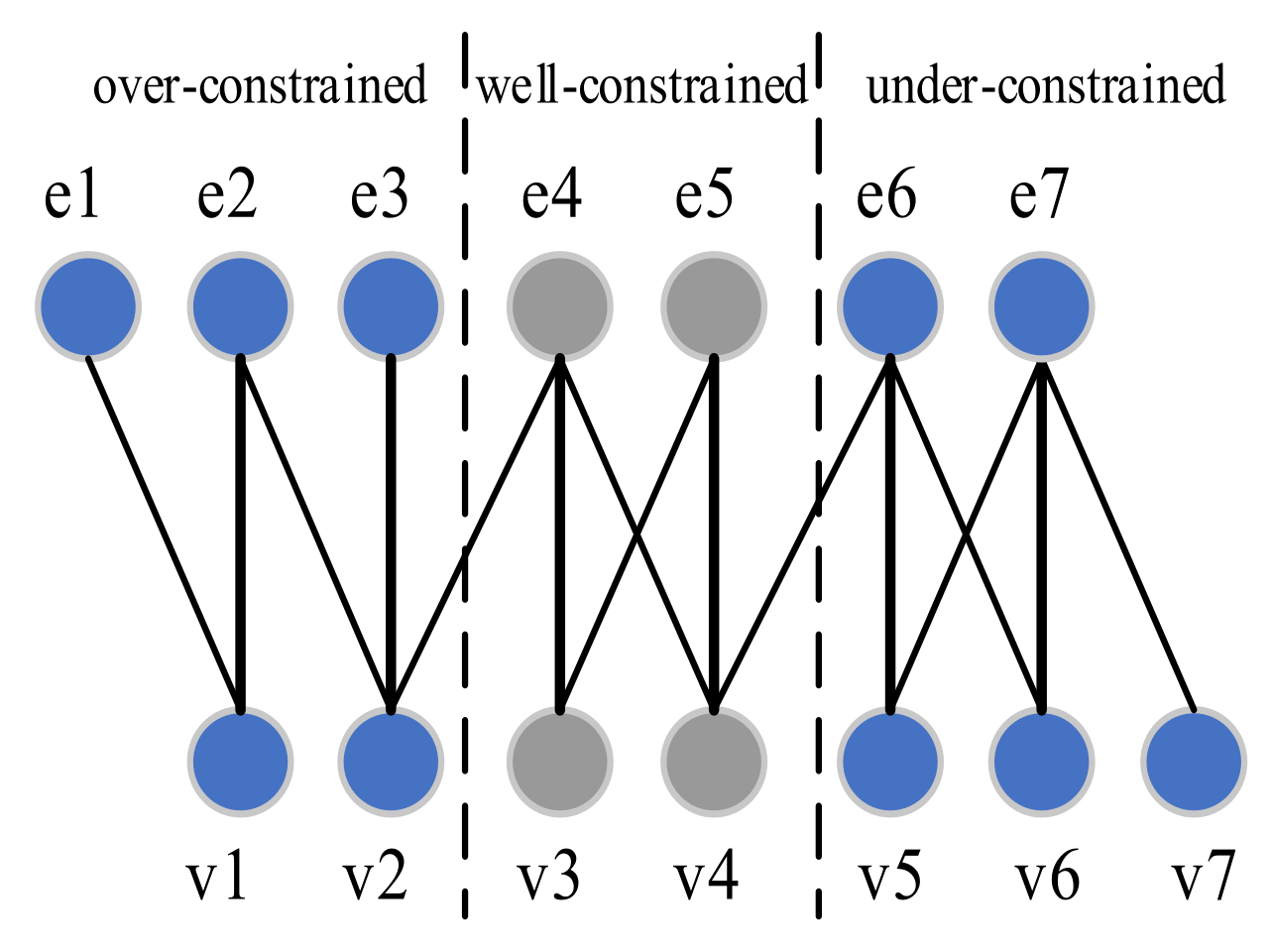
An example equation system (Equation (3)) and the corresponding bipartite graph are presented in Figure 2 to illustrate these concepts. Equation (3) is considered a primary equation model , where is the variable set and is the equation set. In the bipartite graph, the nodes in the upper and lower parts represent equations and variables, respectively. Each edge represents the presentation of a variable in an equation. The bold edges represent a maximum matching whose exposed nodes are . Two feasible paths can be observed in the graph. One is from the exposed variable node , and the other is from exposed equation node . The equations in Equation (3) are decomposed into three parts, namely , and , by applying the DM decomposition. The variables in each part are , and , respectively. The nodes in different parts are painted in different colors.
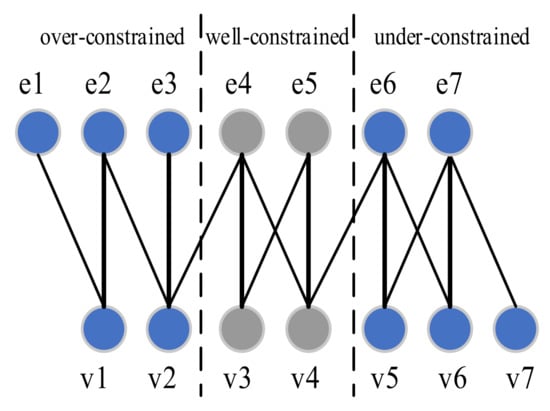
Figure 2.
Decomposition of the bipartite graph representation of the equations in Equation (3).
3. Hierarchical Structural Analysis
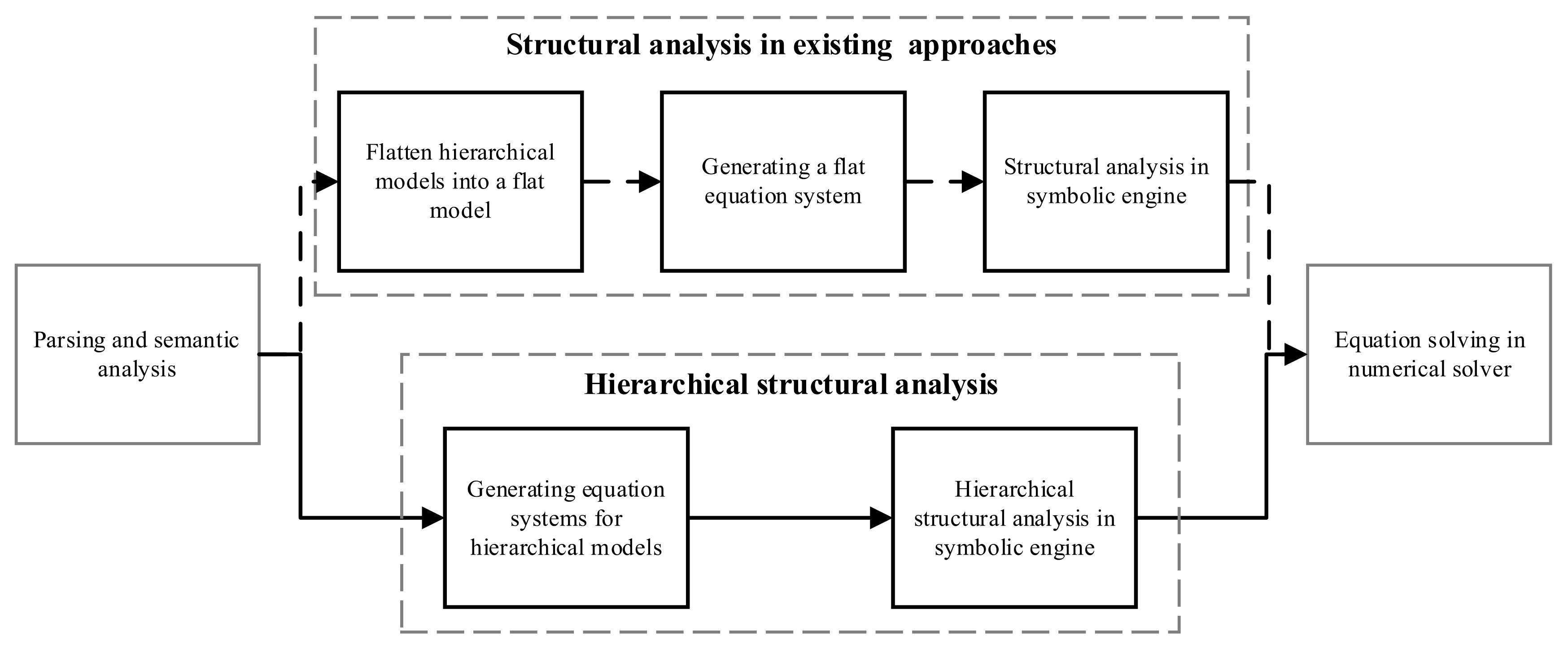
The general process of existing structural analysis methods for EoMs is shown as the dashed arrow lines in Figure 3. The models in the hierarchical structure are flattened into an overall equation system to be analyzed and solved. During the structural analysis in a symbolic engine, the large-scale equations are decomposed into strong-connection components to reduce the computation complexity. However, the sparsity from the hierarchical structure is ignored in this procedure. This section will study the relationship between the singularities of a model and its components and propose a hierarchical method for structural analysis. As the solid arrow lines in Figure 3 show, the hierarchical structural analysis method can analyze hierarchical EoMs without flattening them.
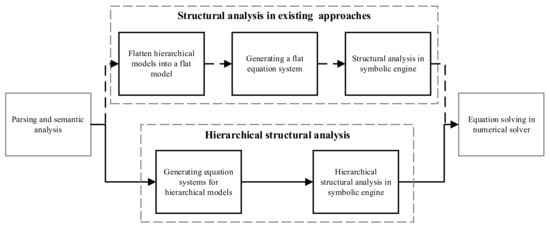
Figure 3.
Comparison between the stages of the hierarchical structural analysis method and existing structural analysis methods.
The singularity of a model can be sourced into a subset of equations in it. The key to hierarchical structure analysis is to find an equation subset, which may be the singularity source, in each component. Thus, the structural singularity of a model can be revealed by analyzing these “picked” equations. The equation subset should be unique for a specified component so it is the intrinsic property of the component and will not be changed no matter how the equation subset is obtained or where the component is used. More importantly, the union of the equation subsets should include all possible singularity sources of the model.
DM decomposition can be used to diagnose the possible singularity sources of the components. As introduced in Section 2.2, it decomposes the bipartite graph of an equation system into three distinct parts: the over-constrained part , the under-constrained part and the well-constrained part . The decomposing result is unique for each bipartite graph [12,30,37]. The singularity of a model is caused by the equations in and [7,12,31]. Therefore, the equation subset for hierarchical structural analysis can be picked up from a component by DM decomposition.
The components in a hierarchical EoM are always predefined. They should contain only the under-constrained part and the well-constrained part. A component with an over-constrained part is not allowed because the redundant equations will make the model singular. Therefore, the components are assumed to be well-constrained or under-constrained during the structural analysis of a hierarchical EoM.
In the structural analysis of a model , the under-constrained part and the well-constrained part of a component have different effects. The under-constrained part needs constraints from equations in , whereas the well-constrained part provides constraints to the common variables in and . The structural analysis of can regard the variables in the well-constrained part of as known variables or independent functions that respect the time and further analyze the equations in and the under-constrained part of . The structural singularity of the model can be revealed by structural analysis of the union set of equations in and the under-constrained part of each component .
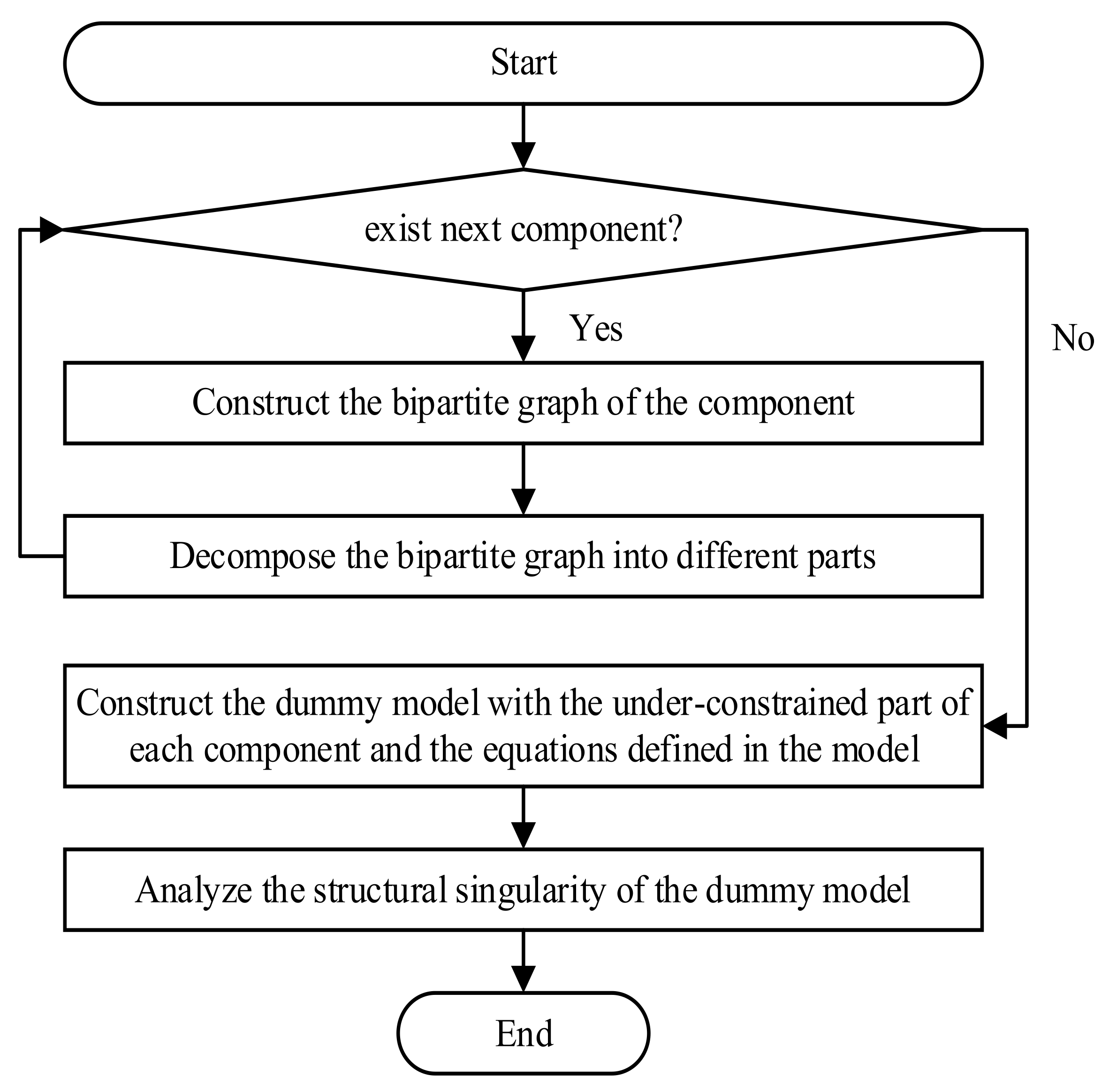
In summary, hierarchical structural analysis of an EoM can be performed as illustrated by the process in Figure 4. Each component in a model is represented as a bipartite graph and decomposed into distinct parts. The equations in the model and the under-constrained parts of the components make up a dummy model to reveal the structural singularity of the model. The equivalence between the structural singularities of the dummy model and the original model will be mathematically analyzed in a graph-theoretical context in the next section. The analysis process can be performed on hierarchical EoMs layer by layer to verify the structural singularity of very complex models.
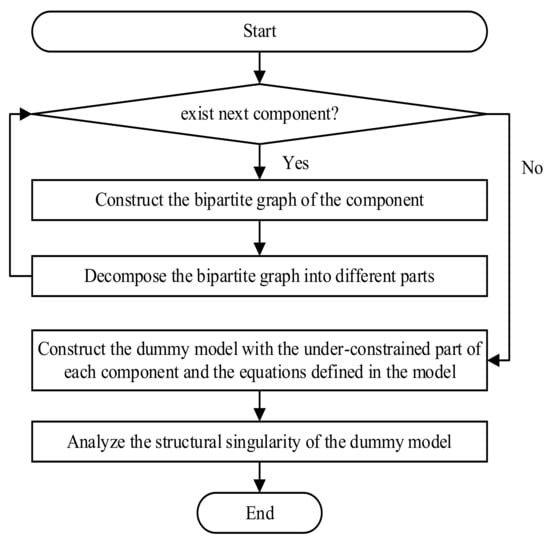
Figure 4.
Process of hierarchical structural analysis.
4. Hierarchical Structural Analysis of NLAE and DAE Models
In practical implementation, the detail of hierarchical structural analysis is different depending on the types of equations in the model. The structural singularity of NLAE models is obtained by analyzing the incidence matrix. The structural analysis of DAE models is different from that of NLAE models, because the indices of the variables should be considered. This section will implement hierarchical structural analysis for NLAE and DAE models and apply the algorithms to the practical structural analysis of NLAE and DAE models. The simpler NLAE models are considered first to explain our idea clearer.
4.1. NLAE Models
As stated in Section 2, a hierarchical NLAE model can be flattened into a primary model , which is essentially an NLAE equation system:
The structural singularity of is equivalent to the structural singularity of Equation (4). The structural singularity of Equation (4) can be analyzed by finding a nonzero traversal in the incidence matrix or finding a perfect matching in the bipartite graph [15,16].
In the graph-represented structural analysis approaches, Equation (4) is represented as a bipartite graph , where is the set of edges representing the presence of a variable in each equation and and are the variables and equations in Equation (4), respectively. Therefore, the structural singularity of an NLAE model can be defined as follows.
Definition 8.
An NLAE model is called structurally singular if its bipartite graph has no perfect matching.
4.1.1. Decomposition of Components
Hierarchical structural analysis performs DM decomposition on each component to obtain their under-constrained parts. DM decomposition can be realized by finding feasible paths in the directed bipartite graph based on a maximum matching. The feasible paths divide the bipartite graph into three distinct parts: the over-constrained part where the nodes and edges are sourced from exposed equation nodes, the under-constrained part where the nodes and edges target exposed variable nodes, and the well-constrained part where the nodes and edges are outside the feasible paths. More details on graph-represented DM decomposition are presented in [12,35,36].
Algorithm 1 is our variant implementation of DM decomposition. The difference between Algorithm 1 and other implementations, such as Bunus’ implementation in [12] and Ding’s implementation in [31], is that Algorithm 1 only considers the feasible paths starting at exposed variable nodes. It assumes that each component is consistent and has no over-constrained part. Moreover, Algorithm 1 adopts a similar skill to the Hopcroft–Karp Matching (HKMatching) algorithm [32] to speed up searching for feasible paths. In each loop, it finds multiple disjoint length-2 feasible paths from the exposed variables. Subsequently, the alternating variable nodes on these feasible paths are appended into the under-constrained variable set and treated as the exposed variables in the next loop.
The pseudocode of decomposing an NLAE component is presented as follows.
| Algorithm 1. Decomposition of an NLAE component. | |
| Input the bipartite graph of the component. | |
| Output variables and equations in the under-constrained part. | |
| 1: | let be a maximum matching, set ; |
| 2: | let be a queue of exposed variables, ; |
| 3: | if , return , ; |
| 4: | let be the set of under-constrained variables, ; |
| 5: | let be the corresponding directed graph of , ; |
| 6: | while : |
| 7: | let be an element in and remove it from |
| 8: | let be the length-2 feasible paths from , ; |
| 9: | for each : |
| 10: | if , continue; |
| 11: | append into |
| 12: | append into , ; |
| 13: | let be the equation set in the under-constrained part, |
| 14: | return , |
Our remarks on Algorithm 1 are as follows:
- This algorithm assumes that the component has no over-constrained part.
- In line 2, the function is the maximum matching algorithm by Hopcroft and Karp [32]. It can stably find a maximum matching of the bipartite graph in . This step can be realized with other maximum matching algorithms, such as the algorithms in [33,34,38] with time complexity .
- In line 3, the notation indicates an empty set. If the bipartite graph has no exposed variables, the sets of variables and equations in the under-constrained part are empty.
- In line 5, the function directs the edges to form a directed bipartite graph , where . The directions of the edges are used to state the searching process clearer. They are optional in the practical implementation.
- In line 8, the function begins from each exposed variable and finds length-2 feasible paths in . Searching of each feasible path needs to access two nodes. The time complexity of this function is , where is the average number of edges for each node.
- Lines 6–12 find all under-constrained variables from the exposed variables. Each under-constrained variable is appended in the queue and popped from the queue only once. Therefore, the time complexity is within .
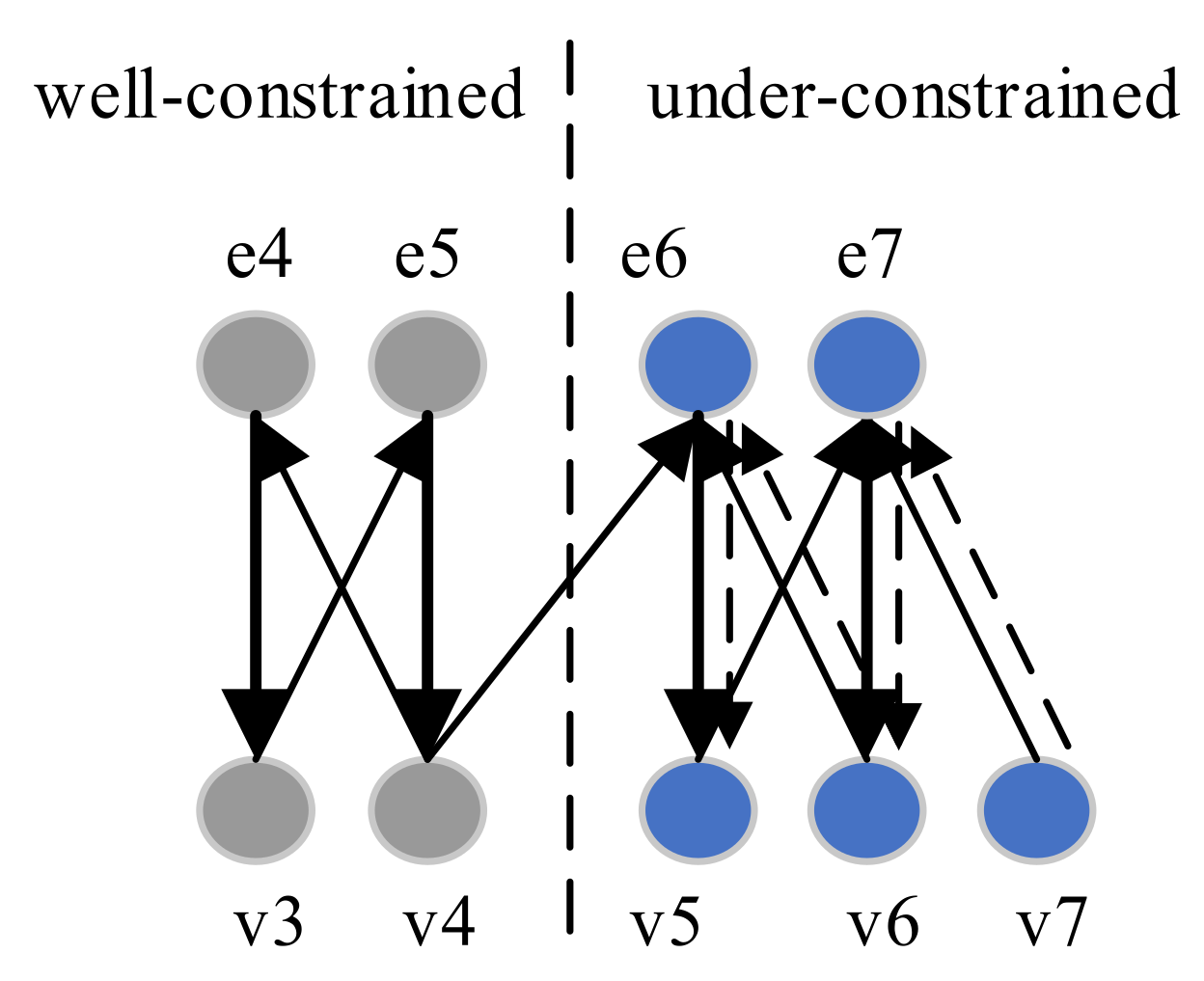
Algorithm 1 decomposes an NLAE component into the under-constrained part and well-constrained part. Take the system of equations e4, e5, e6, and e7 in Equation (3) as an example. As shown in Figure 5, the bipartite graph of the equations is decomposed into two parts by Algorithm 1. The bold edges in the bipartite graph represent a maximum matching. All edges are directed depending on whether they are in the maximum matching. In the directed bipartite graph, the variable node v7 is not covered by the matching. A feasible path (v7, e7, v6) can be found from v7. It indicates that v6 is an under-constrained variable. From v6, a feasible path (v6, e6, v5) can be found. Then, v5 is also an under-constrained variable. From v5, a length-2 path (v5, e6, v6) exists. It is not a feasible path, because v6 has been in the under-constrained part. Therefore, the under-constrained variable set can be denoted as . The under-constrained equation set is the set of equations matched to the under-constrained variables.
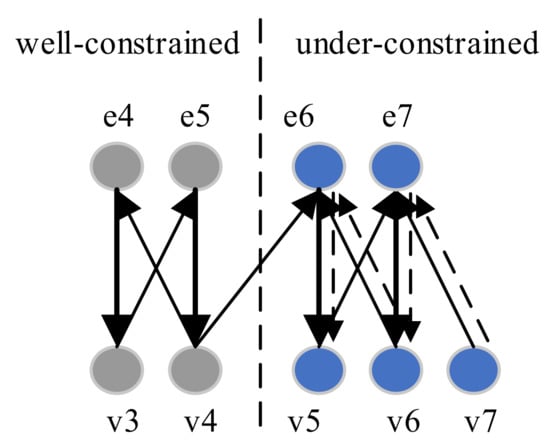
Figure 5.
Feasible paths from exposed variable v7.
Under the assumption that the component has no over-constrained nodes, Lemma 1, 2, and 3 hold.
Lemma 1.
If an equation is in the well-constrained part of a component, then its variables are also in the well-constrained part.
Proof.
Assume that a well-constrained equation is matched to a well-constrained variable . □
According to the assumption that the component has no over-constrained nodes, the variables in are well-constrained or under-constrained.
If an arbitrary variable in is under-constrained, then a feasible path exists. The feasible path indicates that the equation r and the variable are in the under-constrained part. It contradicts the assumption that and are well-constrained.
Therefore, an arbitrary variable in a well-constrained equation is well-constrained, and Lemma 1 is proven.
Lemma 2.
If a well-constrained model is augmented with a set of equations, the over-constrained part of the equation set is a subgraph of the over-constrained part of the augmented model.
Proof.
Assume a well-constrained model and an equation system with variables . □
Denote the bipartite graph of as . It has at least one perfect matching . Each equation is matched to a unique variable and vice versa.
Denote the bipartite graph of as and the bipartite graph of the augmented model as . For a maximum matching of , the union is a maximum matching of .
All nodes in are covered by the maximum matching . No new augment path exists in . The over-constrained nodes in are still over-constrained in .
Therefore, the over-constrained part of is a subgraph of the over-constrained part of , and Lemma 2 is proven.
Lemma 3.
If a well-constrained model is augmented with a set of equations, the under-constrained part of the equation set equals the under-constrained part of the augmented model.
Proof.
Assume a well-constrained model and an equation system with variables . □
Denote the bipartite graph of as . has at least one perfect matching . Each equation is matched to a unique variable and vice versa.
Denote the bipartite graph of as and the bipartite graph of the augmented model as . For a maximum matching of , the union is a maximum matching of .
Direct the edges in as . All edges between and start at the variables in and end at the equations in . For the under-constrained variables in , no feasible path enters . Therefore, no new under-constrained node can be observed in .
Moreover, no new augment path exists in , because all nodes in are covered by the maximum matching . No new matching edge can be found. Therefore, the under-constrained nodes in are still in the under-constrained part of .
Therefore, the under-constrained part of equals the under-constrained part of , and Lemma 3 is proven.
4.1.2. Construction of the Dummy Model
For a hierarchical EoM , the dummy model is constructed based on the decomposing result of each component. The equations in the dummy model are a subset of the equations in the flattened model . The structural analysis of the dummy model can reveal the structural singularity of the original model .
Definition 9.
The dummy model of an NLAE model is defined as , where and are variables and equations in the under-constrained part of each component, respectively.
The pseudocode of constructing the dummy model for an NLAE model is presented as follows.
Our remarks on Algorithm 2 are as follows:
- In line 3, the function constructs a bipartite graph for the component .
- In line 4, the function is an implementation of Algorithm 1. It decomposes a component and returns the variable set and the equation set in the under-constrained part.
- If the component set is empty, the dummy model is equivalent to the flattened model.
| Algorithm 2. Construction of the dummy model . | |
| Input a model ; output the dummy model . | |
| 1: | Let , ; |
| 2: | for each , do |
| 3: | |
| 4: | ; |
| 5: | let ; |
| 6: | let ; |
| 7: | let be the dummy model of , ; |
Theorem 1.
For an NLAE model, the structural singularities of the dummy model and the flattened model are equivalent.
Proof.
Assume an NLAE model . The corresponding flattened model is denoted as , where and represent the union sets of the variables and equations in and its components. The dummy model of is denoted as . □
If is a primary model, the component set is empty. Obviously, and . The dummy model and the flattened model contain the same variables and equations. Their structural singularities are equivalent.
If is a first-level model, each component is a primary model. Algorithm 1 decomposes each component into the under-constrained part and the well-constrained part .
According to Definition 9 and the assumptions and , the dummy model satisfies the following:
For each component , a well-constrained model can be built with the variables and equations in the well-constrained part. According to Lemma 2, the over-constrained part of is a subgraph of the over-constrained part of the model . Under the assumption that the component has no over-constrained nodes, the over-constrained parts of and are equivalent. According to Lemma 3, the under-constrained part of equals the under-constrained part of . Therefore, the structural singularities of and are equivalent.
Inductively, the structural singularity of equals that of the model . Because , , and and the contents Equation (5), .
Therefore, the structural singularity of the first-level model is equivalent to that of its dummy model .
If is an -level () model, it can be converted into a first-level model satisfying . The structural singularities of and are equivalent because they have the same variables and equations.
The dummy model of satisfies . The equivalence of the structural singularities of the first-level model and its dummy model has been proven. Therefore, the structural singularities of and are equivalent.
According to Definition 9, the dummy model of is . For each component , the under-constrained part of the dummy model is equal to the that of the flattened form , satisfying and , and therefore
The dummy models of and are equal, and the structural singularities of and are equivalent.
Therefore, the structural singularities of the -level () model , the component-flattened model , the dummy model and the dummy model are equivalent, and Theorem 1 is proven.
Theorem 1 ensures the equivalence of the dummy model and the flattened model for structural singularity verification and diagnosis. Note that this is only established if it assumes that the components have no over-constrained nodes. The over-constrained part of the dummy model is a subgraph of the over-constrained part of the flattened model. They can be equivalent when ignoring the over-constrained nodes in the components. However, if desired, the over-constrained nodes in a component can be found by searching the feasible paths in the bipartite graph augmented by the assignment equations of the variables appearing in both the component and the over-constrained parts of the dummy model.
Note that the dummy model can be built based on the dummy models of the components. Denote the dummy model of the component as . According to Lemma 3, the under-constrained part of and are equal, satisfying and . Therefore, the dummy model satisfies
and can be obtained by hierarchical structural analysis of the components. This means that the analysis results of the components can be used to build the dummy model of . This ensures that the hierarchical structural analysis can be performed iteratively layer by layer in the hierarchical structure of EoMs.
4.1.3. Hierarchical Structural Analysis Case of NLAE Models
Theorem 1 indicates that structural analysis of the dummy models can reveal the structural singularity of the hierarchical EoMs. The structural singularity of NLAE models can be obtained by performing the structural analysis method, based on maximum matching searching or DM decomposition, on the dummy model.
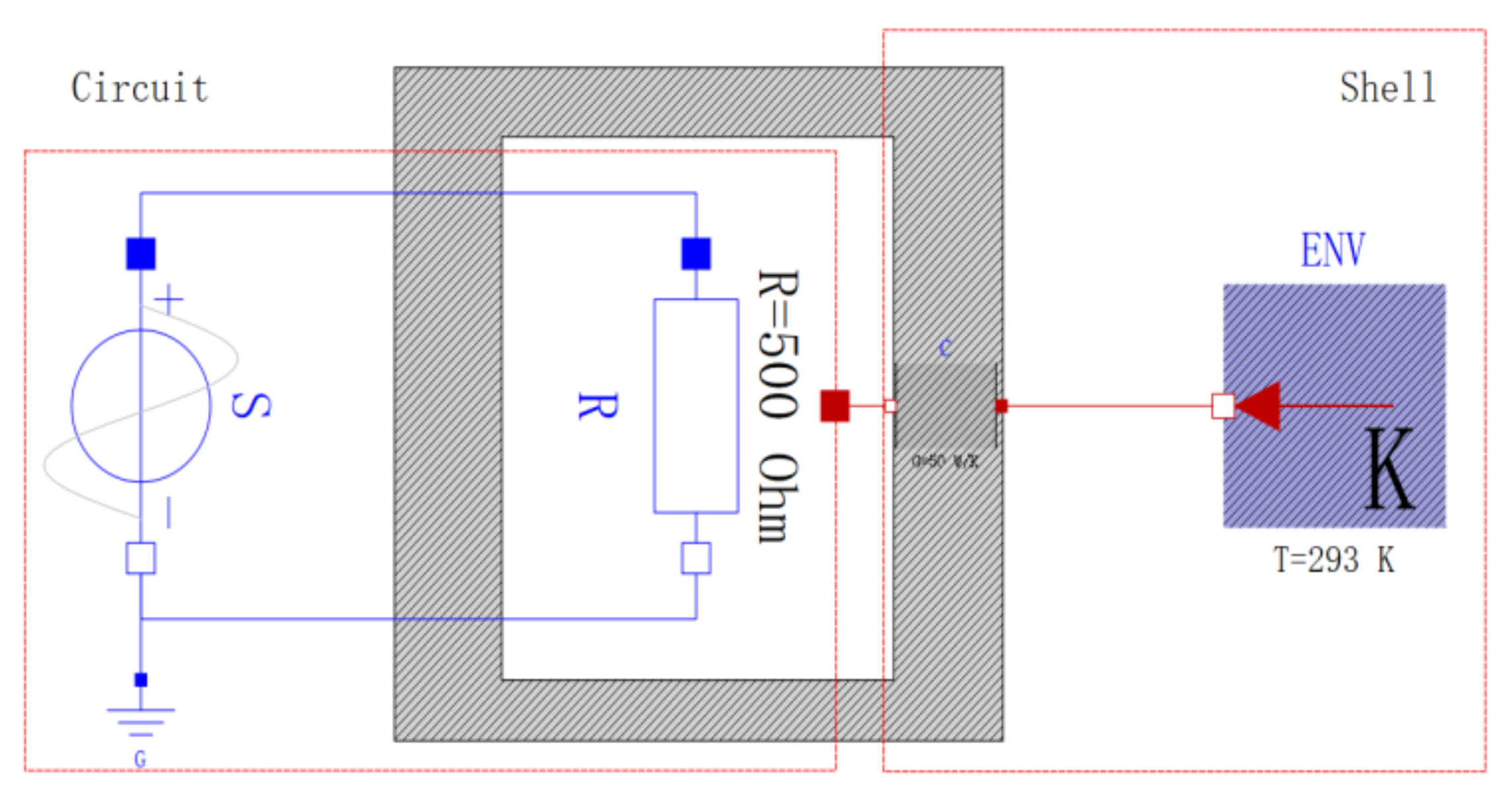
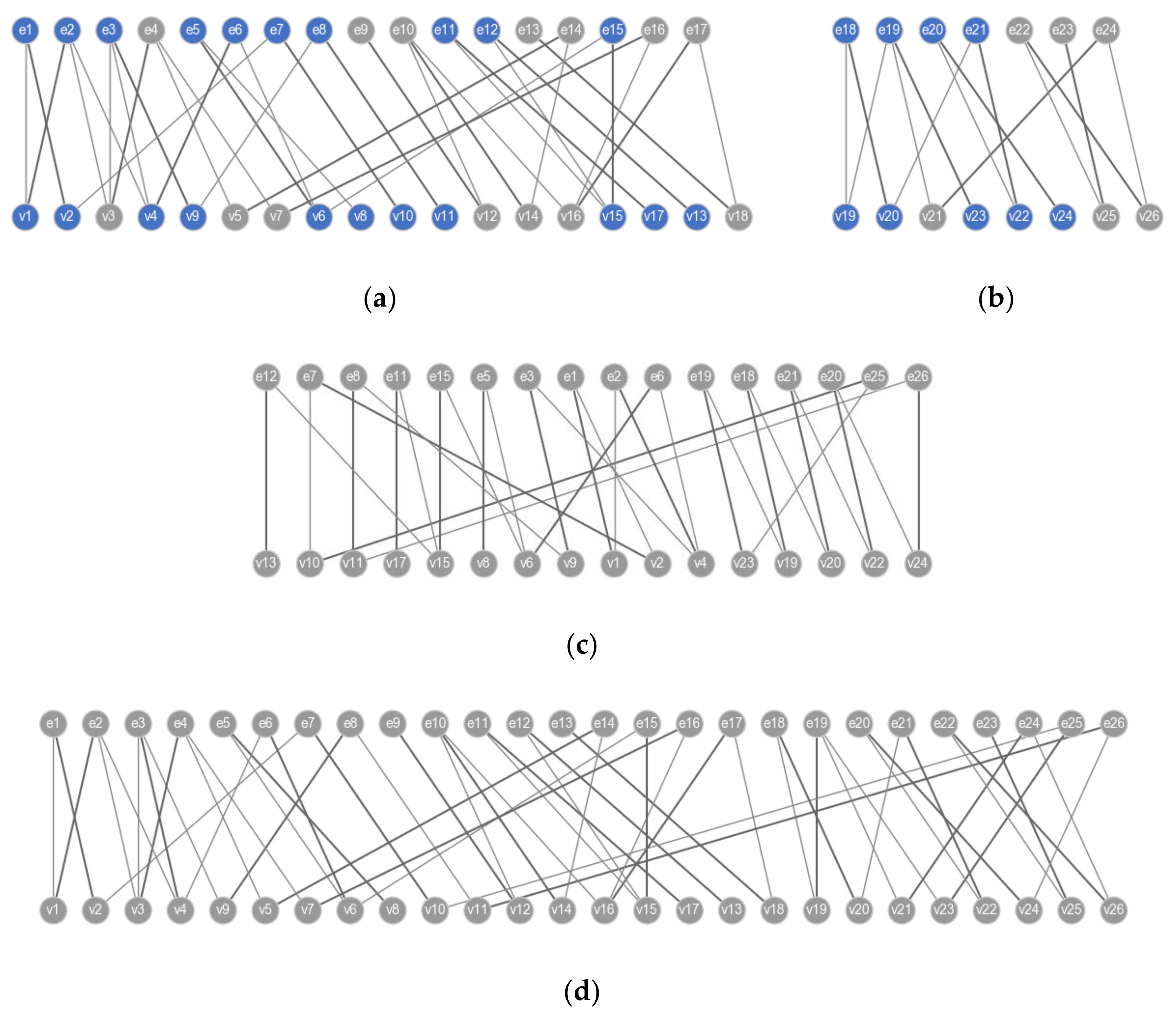
Take the system in Figure 6 as an example to illustrate the hierarchical structural analysis of the NLAE models. This system consists of a heat-generating circuit and a shell dissipating heat into the environment. The variables and equations in the models can be found in the dataset [39]. By applying Algorithm 1 on the circuit component and the shell component, the graphs in Figure 7a,b are obtained. In each bipartite graph, the bold edges represent a maximum matching. The gray nodes and the blue nodes represent the well-constrained parts and the under-constrained parts of the components, respectively. The dummy model can be constructed by performing Algorithm 2 on each component. Figure 7c shows the result of applying the DM decomposition on the dummy model. All nodes in the graph are well-constrained, which indicates that the system model is well-posed. As a comparison, Figure 7d gives the result of applying the DM decomposition algorithm on the flattened model, where all nodes are also well-constrained. The comparison of Figure 7c,d shows that the hierarchical structural analysis method is effective and can obtain an equivalent singularity result. The resulting graphs imply that the proposed method can reduce the node scale in structural analysis of NLAE models.
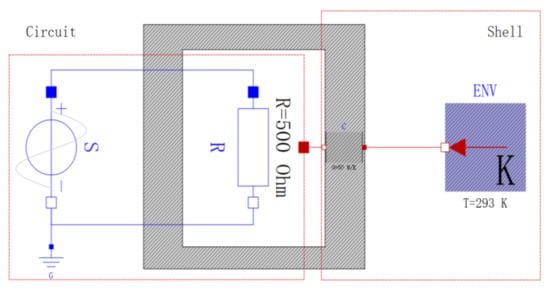
Figure 6.
Example system to illustrate the structural analysis of NLAE models.
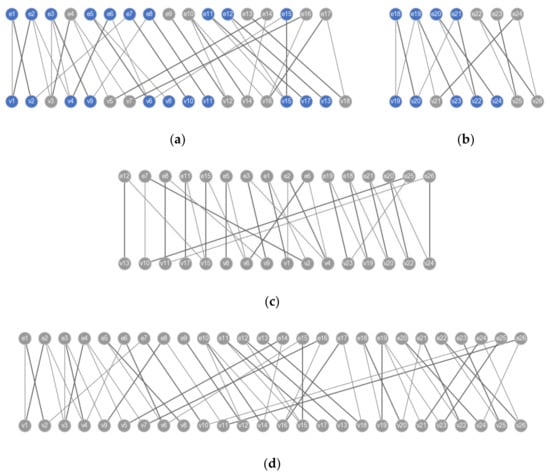
Figure 7.
Hierarchical structural analysis of the NLAE model in Figure 6. (a) Decomposition of the circuit model. (b) Decomposition of the shell model. (c) Structural analysis result of the dummy model. (d) Structural analysis result of the flattened model.
4.2. DAE Models
A hierarchical DAE-oriented model is essentially a DAE system. Assuming that the equations are infinitely differentiable, a DAE system can be equivalently augmented into an implicit underlying ODE (UODE) system in Equation (6) by an index reduction process [13,20]. Note that the equations in Equation (6) only contain the variables and their first-order derivatives:
Equation (6) is finally transformed into an ordinary differential equation (ODE) system to be solved by the numerical methods. The solvability of the UODE system demands the consistency of the differentiated variables . The UODE augmented with the equations reduced in the index reduction process is used to solve the initial value problem. The graph-represented methods are always used to efficiently verify the consistency of and the initial values [7].
In graph-represented approaches, the consistency of the variables is verified by a procedure that assigns each equation to a unique variable. The variables that need initialization are determined by the exposed variables in the bipartite graph of the augmented UODE (AUODE) system. The AUODE can be considered an NLAE by replacing the derivatives with independent algebraic variables, similar to the dummy derivative method by Mattsson [13]. A consistent AUODE is always under-constrained and needs constraints from the initial conditions. Therefore, the structural singularity of a DAE model can be defined in a graph-theoretical context as follows.
Definition 10.
A DAE model is called structurally singular if the bipartite graph of its AUODE system has an over-constrained part.
The structural analysis of a DAE model aims to find the redundant equations of the model and the variables that require initialization. This section will implement hierarchical structural analysis on the DAE models to build a dummy model. More preliminary knowledge about DAEs, such as index reduction, consistent initial values, UODE and AUODE, can be found in [7,12,13,20,31].
4.2.1. Decomposition of Components
Different from NLAE models, DAE models are structurally analyzed based on the AUODE obtained by an index reduction process. Hierarchical structural analysis decomposes the bipartite graph of the resulting AUODE of the components into different parts. The graph-represented algorithm by Soares and Secchi (SSMatching) [7] is adopted to augment the DAE system into the AUODE and find a maximum matching in the augmented bipartite graph.
The SSMatching algorithm extends the graph-represented algorithm by Pantelides. It selects equations that require differentials by prioritizing the index consistency and differentiates them in each loop. The algorithm is iteratively executed until the indices of the variables are consistent or a deficiency is found. The criterion for selecting equations and the termination condition ensures that the resulting equation system is minimal. The resulting augmented bipartite graph is equivalent to the bipartite graph of the AUODE of the DAE system.
In hierarchical structural analysis, the components of a hierarchical DAE model are augmented and decomposed to obtain the under-constrained part. The pseudocode of the DAE component decomposition algorithm is listed as follows.
Our remarks on Algorithm 3 are as follows:
- In line 1, the function augments the bipartite graph and finds a maximum matching in the augmented bipartite graph . The SSMatching algorithm needs at most operations to find a maximum matching for a DAE system.
- The difference between Algorithm 3 and Algorithm 1 is that decomposing a DAE model is performed on the augmented bipartite graph rather than the bipartite graph of the original equation system.
| Algorithm 3. Decomposition of a DAE component. | |
| Input a bipartite graph . | |
| Output the variables and equations in the under-constrained part. | |
| 1: | let be the bipartite graph of the augmented DAEs; let be a maximum matching, . |
| 2: | let be a queue of exposed variables, ; |
| 3: | if is empty, return , ; |
| 4: | set ; |
| 5: | let be the set of under-constrained variables, ; |
| 6: | while : |
| 7: | let be an element in and remove from ; |
| 8: | let be the length-2 feasible paths from , ; |
| 9: | for each : |
| 10: | if , continue; |
| 11: | append into |
| 12: | append into , ; |
| 13: | let be the equation set in the under-constrained part, |
| 14: | return , |
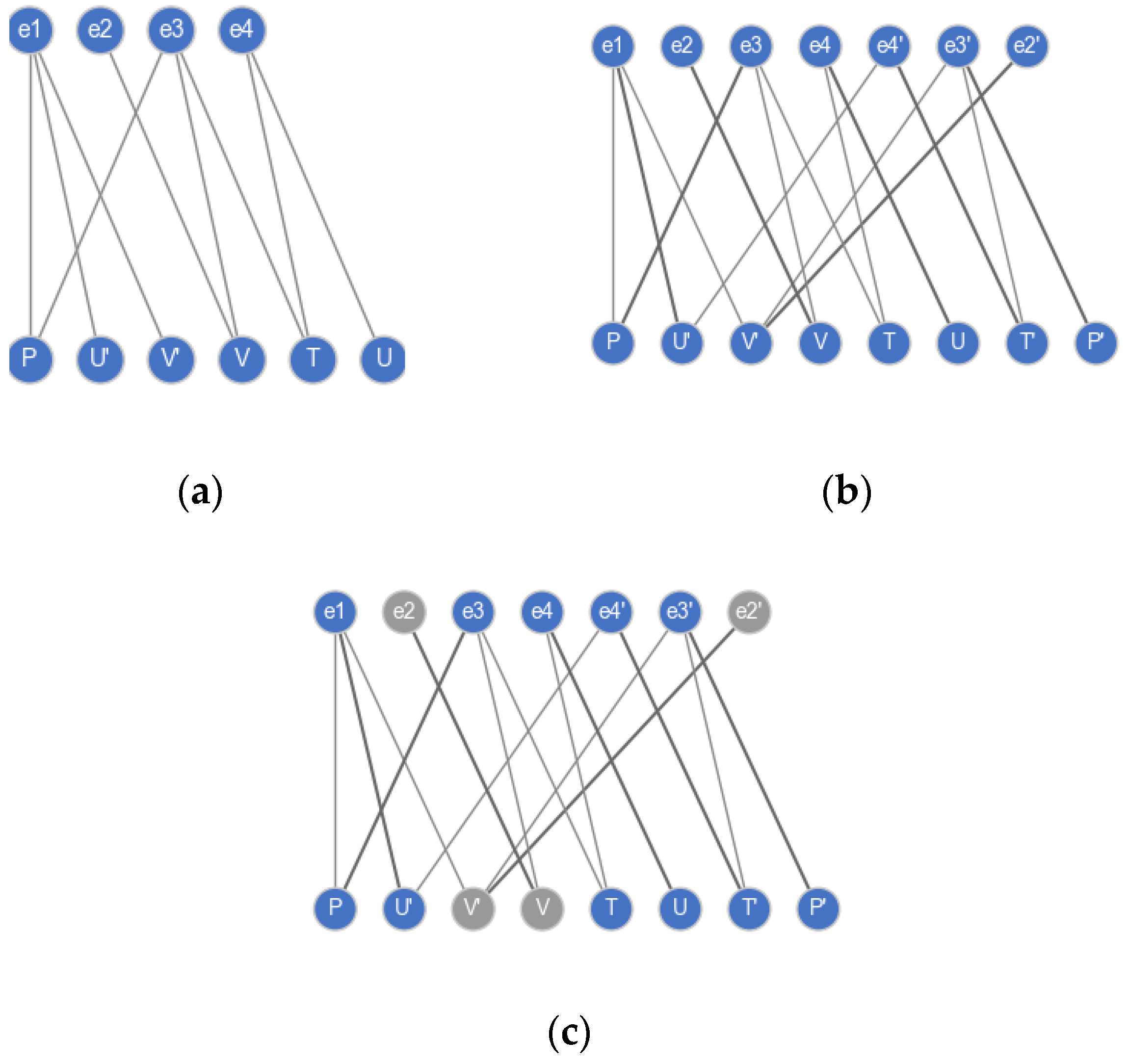
Take the DAE model in Equation (7), which is also an example in [7,40], as an example. The bipartite graph of this model is shown in Figure 8a. After applying the SSMatching algorithm, the equations , and are differentiated, and a maximum matching (bold edges) is found. The augmented bipartite graph is shown in Figure 8b. In Figure 8c, Algorithm 3 decomposes the augmented graph into two parts, where the nodes are colored in gray and blue. The nodes in the set are in the well-constrained part, and the remaining nodes are in the under-constrained part:
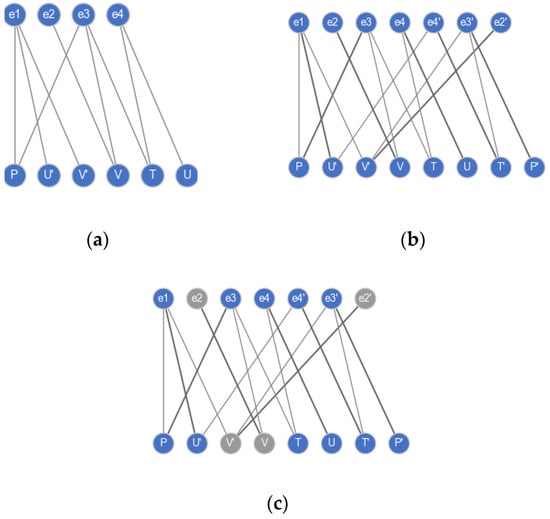
Figure 8.
Decomposition of DAEs in the model of Equation (7). (a) Original bipartite graph. (b) Augmented bipartite graph. (c) Decomposition of the model.
4.2.2. Construction of the Dummy Model
In hierarchical DAE models, the derivatives of the variables in the components may appear in the equations defined in the model. During construction of the dummy model for a DAE model, these derivatives must be handled properly. In a DAE model, if a variable is the derivative of a variable in the well-constrained part of a component, it should be ignored in the dummy model like the well-constrained variables. The reason for this is that if a variable in a DAE system is well-constrained, then all of its derivatives are also well-constrained under the assumption that the component has no over-constrained nodes.
Lemma 4.
If a variable is well-constrained in a DAE system, an arbitrary derivative of the variable is well-constrained in a system augmented by differentiating equations, and the under-constrained parts of the original system and the augmented system are equivalent.
Proof.
Assume that the bipartite graph of the AUODE system is and the decomposing results of are and . □
In , each equation is matched to a unique variable . Differentiating each equation produces a graph with a set of equations and a set of variables , and is a variable in . There exists a matching in the bipartite graph .
According to Lemma 1, all variables in are in . Therefore, the variables in are the elements of . Each variable in is matched to a unique equation. Let . The variables and equations in are in the well-constrained part of the augment bipartite graph .
Therefore, for a variable , its derivative is well-constrained in the augmented DAE system represented by .
Since the variables in and the equations in are in , differentiating them will not change the variables and equations in . Therefore, .
Inductively, the derivative is well-constrained in the augmented DAE system represented by . For the arbitrary index , the derivative is well-constrained in the augmented DAE system represented by , and the under-constrained parts of and are equivalent.
Therefore, Lemma 4 is proven.
Based on the decomposing result of the components, the dummy model of a DAE model can be built under the following definition.
Definition 11.
The dummy model of a DAE model is defined as , where the operator means removing all variables in and their derivatives from , and and are the variables and equations in the under-constrained part of each component, respectively.
The pseudocode of the dummy model’s construction is presented as follows.
Note that the derivatives of the variables in a DAE component may appear in the equations . These derivatives should be treated as variables in the component rather than in the model . The well-constrained variables in a component and their derivatives are removed from the dummy model in line 5. The handling of variable derivatives is the difference between Algorithm 2 and Algorithm 4.
| Algorithm 4. Construction of dummy model | |
| Input a model ; output the dummy model . | |
| 1: | Let , ; |
| 2: | for each , do |
| 3: | |
| 4: | ; |
| 5: | let ; |
| 6: | let ; |
| 7: | let be the dummy model of , set ; |
Theorem 2.
The structural singularities of a DAE model and its dummy model are equivalent.
Proof.
Assume a DAE model . The flattened form of is . According to Definition 10, the structural singularity of is equivalent to the structural singularity of the augmented model . □
According to Definition 11, the dummy model of is constructed with the decomposition result of the components .
If is a primary model, the variables and equations in equal the variables and equations in . Their structural singularities are equivalent.
If is a first-level model, each component is a primary model. The decomposed result of a component satisfies , , and , where the superscript represents that they are in the bipartite graph of the AUODE of .
If no new derivatives of the variables in appear in , , then can be considered the sum of the AUODE of the components and the AUODE of the equations in . The structural singularity of the dummy model is equivalent to the structural singularity of the model . When considering as a first-level NLAE model, is the dummy model of the NLAE model. According to Theorem 1, the under-constrained part and the over-constrained part of and the dummy model constructed with the decomposition results are equivalent.
If the derivatives of the variables in appear in , the variables in the dummy model satisfy the following:
Assume a well-constrained variable and a derivative in an equation in . According to Lemma 4, the derivative is the well-constrained part of an AUODE of an augmented model . The under-constrained parts of and satisfy and . Their well-constrained parts satisfy and . Then, the model can be considered a variant model , whose components are the augmented model and have no variable derivatives appearing in . Therefore, the structural singularities of and are equivalent.
The dummy model satisfies
Therefore, the dummy models m and m′ are equal. The structural singularities of the dummy model and the flattened model are equivalent.
The n-level model can be considered a first-level model by flattening its components. Therefore, the structural singularity of the DAE model and the dummy model are equivalent, and Theorem 2 is proven.
4.2.3. Hierarchical Structural Analysis Case of the DAE Models
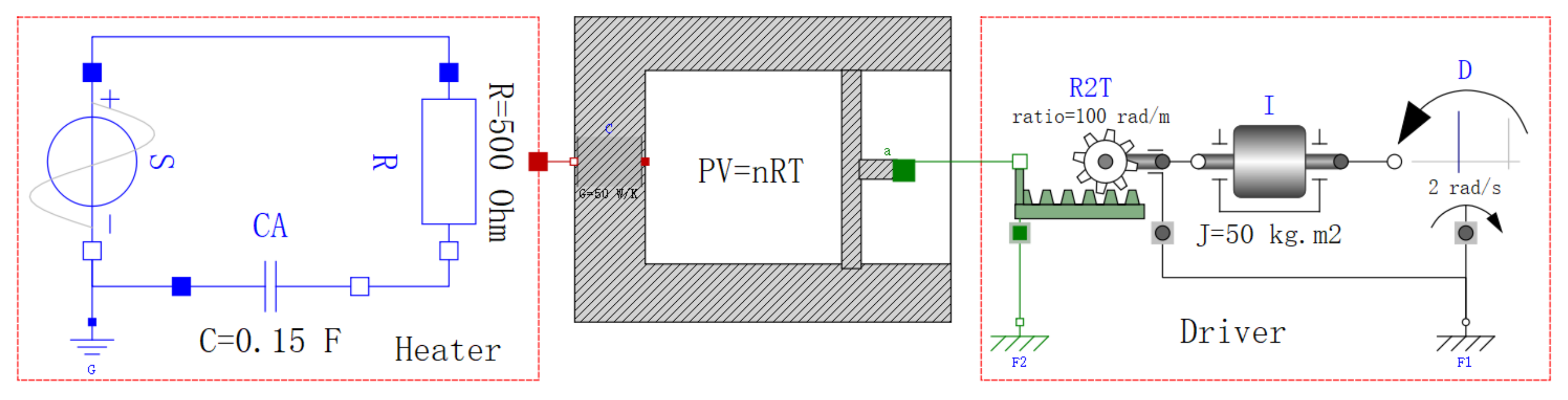
The structural singularity of the DAE models can be analyzed based on their dummy models. Take the system in Figure 9 as an example. This system consists of a heater component and a driver component connected with a vessel filled with gas. Its model is a hierarchical DAE model. The variables and equations in the model are presented in the dataset [39].
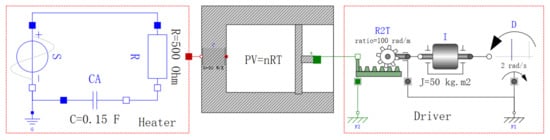
Figure 9.
Example system to illustrate the hierarchical structural analysis of DAE models.
Algorithm 3 decomposes the models of the heater and driver into distinct parts filled with colors, as shown in Figure 10a,b. The under-constrained parts of the components, combined with the equations in the top-level model, construct the dummy model of the top-level system. DM decomposition is performed on the dummy model to reveal the possible over-constrained equations and the variables that require initialization. The decomposing result is shown in Figure 10c. As a comparison, the structural analysis of the corresponding flattened model is shown in Figure 10d.
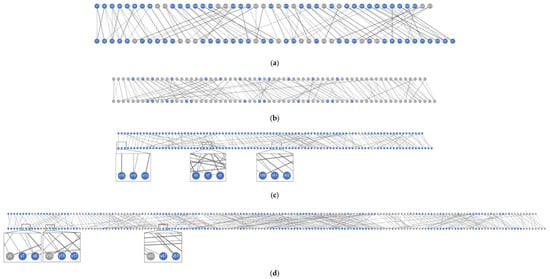
Figure 10.
Structural analysis of the DAE model in Figure 9. (a) Decomposition of the circuit model. (b) Decomposition of the driver model. (c) Structural analysis result of the dummy model. (d) Structural analysis result of the flattened model.
The variables in each part of the dummy model and the flattened model are listed in Table 2. The exposed variable set of the dummy model is {v19, v7, v51}, whereas the exposed variable set of the flattened model is {v15, v7, v47}. As shown in Figure 10d, v19 and v15 are connected by the feasible path (v15, e19, v6, e5, v8, e21, v21, e16, v19), and v47 and v51 are connected by the feasible path (v47, e43, v29, e28, v31, e46, v35, e30, v33, e36, v37, e32, v39, e63, v63, e57, v58, e54, v60, e59, v64, e60, v55, e50, v51). Therefore, the result of the hierarchical structural analysis is equivalent to that of the structural analysis based on the flattened model. We can select one from each pair of the alternating variables on the same feasible path as the variables that require initialization. For example, the variables {v7, v15, v51} can be chosen as the initial condition of the model. They represent the negative pin voltage of the resistor, the current through the source and the temperature difference at the ends of the vessel, respectively. When comparing Figure 10c,d, the nodes in the dummy model are much lower than those in the flattened model. The hierarchical structural analysis could achieve better performance than the existing structural analysis method.
Table 2.
Variables in different parts of the dummy model and the flattened model.
5. Complexity Analysis and Discussion
The hierarchical structural analysis method includes three stages: decomposing the components, constructing the dummy model and performing structural analysis on the dummy model. The time complexity of each stage can be estimated as follows.
Decomposing an NLAE component takes three steps: (1) finding a maximum matching, (2) searching the feasible paths and determining the under-constrained variable set and (3) computing other parts by set operation. In step 1, the best sequential algorithm for finding a maximum matching in a bipartite graph is due to Hopcroft and Karp [32]. Their algorithm solves the maximum matching problem in , where is the number of nodes and is the number of edges. Step 2 searches the under-constrained variables . Its time cost is , where is the number of nodes in the under-constrained part and is the average number of edges to each node. Step 3 computes the variables and equations in the well-constrained part and removes them and the related edges from the graph. The operations are in . Therefore, the total time cost of the component decomposition is . Considering that and , the time cost of the component decomposition is a function of :
The dummy model is constructed based on the decomposing results of the components. Assuming a model with components, the node number in the dummy model is , where is the number of variables and equations in the model and is the number of nodes in the under-constrained part of each component. The time cost of constructing the dummy model is , where is the average number of edges of a node.
The time cost of the last stage depends on the structural analysis algorithm adopted. Take the singularity diagnosis algorithm in [31] as an example. The number of nodes in the dummy model is . Performing the algorithm on the dummy model requires operations at most.
Equation models in practical engineering are sparse, such that . Therefore, the total time cost for the hierarchical structural analysis of an NLAE model is
In practical system modeling, the components are always reused in different models. Their under-constrained and well-constrained parts can be decomposed previously. The pre-computed decomposing results will reduce the time cost of the hierarchical structural analysis to
The existing structural analysis methods, such as the methods in [12,31], are based on flattened models. The time cost for flattening the hierarchical models is . Similar to the complexity analysis of the proposed method, the diagnosis algorithm in [31] is used here to analyze the structural singularity of a flattened model. The time complexity of the analysis is [31]. Therefore, the best time cost for the existing structural singularity analysis is
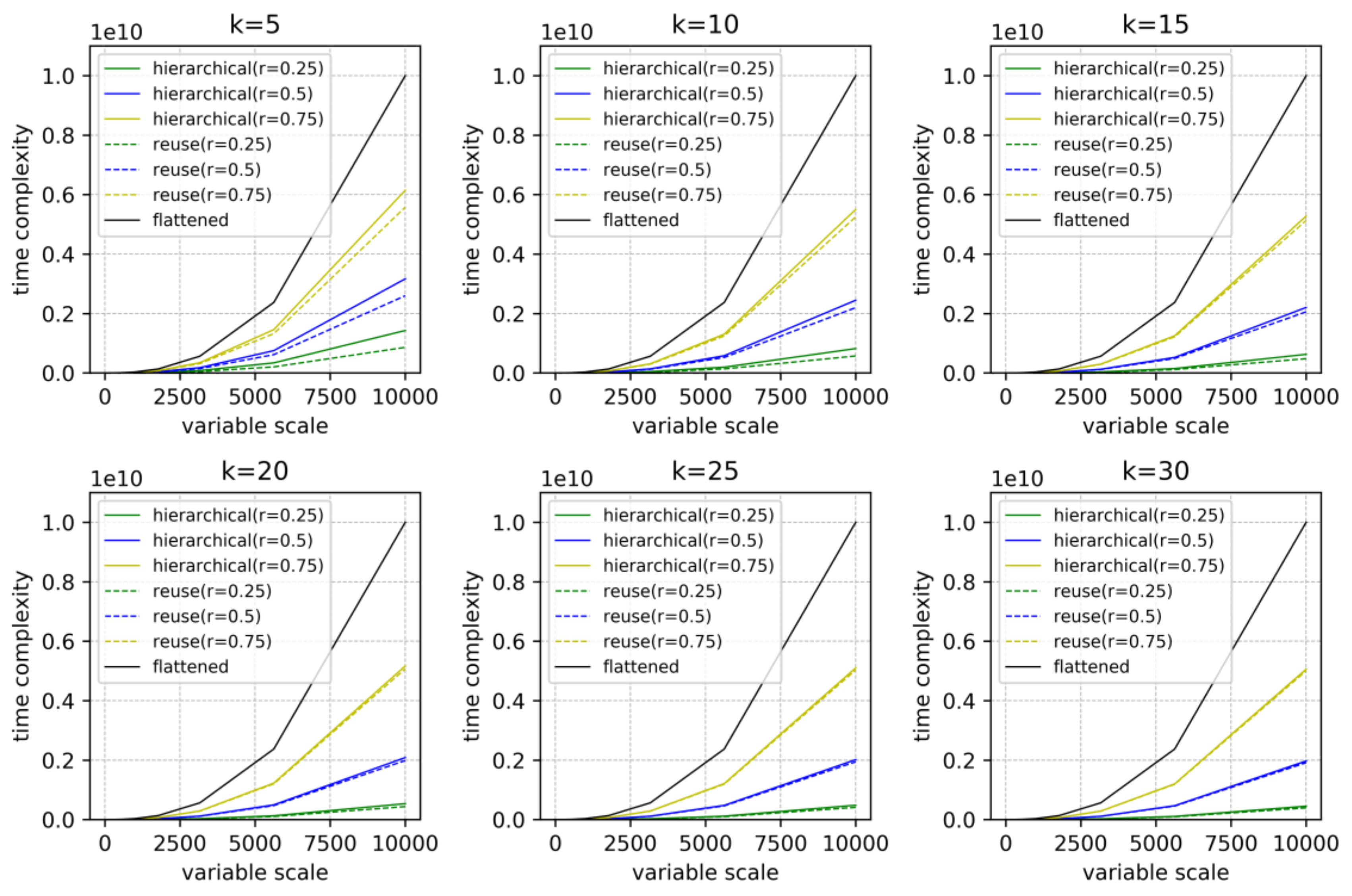
Define as the ratio of under-constrained nodes and as the average number of edges to each node. According to Equations (9) and (10), we can plot the time complexities of the hierarchical structural analysis method in different situations by varying the variable number , the component number and the under-constrained ratio r. In Figure 11, the results are compared with the time complexity of existing structural analysis methods at the same variable scale.
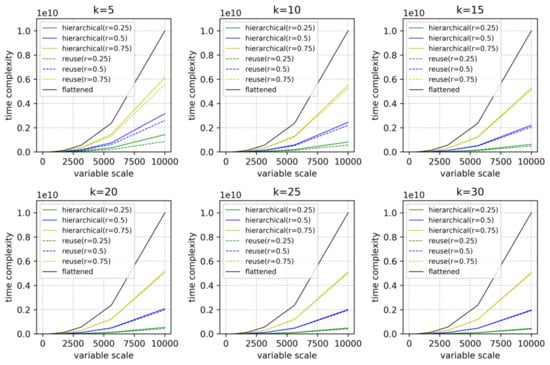
Figure 11.
Time complexity comparison of the flattened method and the hierarchical method under different conditions.
According to the comparison in Figure 11, the following conclusions can be drawn: (1) the hierarchical structural analysis method is more efficient than the existing structural analysis method based on flattened models; (2) reusing pre-computed decomposing results of the components has the least time cost; (3) in the time complexity comparison at different values of , the hierarchical structural analysis becomes more efficient as decreases; (4) at a specified variable scale and a specified under-constrained ratio , the proposed method becomes more efficient as the component number increases, but the increment slows down when reaches a certain degree; and (5) furthermore, the reuse of pre-computed decomposing results raises the efficiency more when becomes smaller.
For DAE models, the structural analysis will augment the equation system when searching for a maximum matching. The time complexity of this step is , where is the times the equation is differentiated and is the number of nodes in the augmented equation system. The time complexity of decomposing a component of a DAE model is
The subsequent steps are based on the augmented equation system. The time complexities of constructing the dummy model and the structural analysis of the dummy model for DAE and NLAE models are similar. The difference in decomposing cost does not change our conclusion on the efficiency and the influencing factors of the efficiency.
In practice, the under-constrained ratio of the components becomes smaller as the model becomes complex. The reason for this is that the number of variables increases more quickly than the variables related to other parts. Moreover, when more reuse occurs in the modeling, the structural analysis benefits more from the hierarchical method. However, for EoMs without hierarchical structure, this method has no remarkable advantages compared with the existing methods, because the decomposition of a flat equation system has high time complexity (i.e., BLT decomposition and DM decomposition need operations). Random decomposition of the bipartite graph forms components with a large under-constrained ratio. The efficiency of the hierarchical analysis method is the usage of sparsity from its hierarchical structure. It is hard to find an algorithm to efficiently decompose an equation system into different parts with a low under-constrained ratio.
6. Conclusions
This study proposed a hierarchical structural analysis method to reveal the singularity of complex EoMs. The proposed method utilizes the relationship between the singularities of a hierarchical EoM and its components. It analyzes the structural singularity of an EoM by decomposing its components, constructing a dummy model and analyzing the dummy model. The structural singularity of complex models can be analyzed by repeating this process layer by layer in their natural structure. Mathematical proofs show that the result obtained by the proposed method is equivalent to the structural analysis result based on the flattened model. Moreover, the hierarchical structural analysis method can be adaptively applied to NLAE and DAE models to realize their structural analysis. The main algorithms and application comparisons were presented for NLAE and DAE models to verify the efficiency of the proposed method. At last, the time complexity of the hierarchical structural analysis method is analyzed, and the result is compared with the time complexity of the existing structural analysis methods based on the flattened models. The comparison shows that the proposed method has better performance than the existing methods [12,31] for structural analysis of complex hierarchical EoMs, especially in the collaborative modeling environment where the components are reused, such as the crowdsourcing design platform in our previous work [41].
Compared with the existing methods, the hierarchical structural analysis method does not flatten the hierarchical EoMs. It performs the analysis layer by layer and reduces the equation scale in each analysis, thereby enabling the efficient structural analysis of complex EoMs. Based on the sparse structure of hierarchical EoMs, the proposed method avoids the defects and extra computation cost from decomposing the flattened equation system. As the comparison of the time complexity shows, the hierarchical structural analysis method has obvious advantages over the existing structural analysis methods, although the efficiency gap is affected by multiple factors. However, the application scope of the proposed method is limited in the EoMs modularly modeled in a hierarchical structure. The singularity equivalence of the dummy model and the flattened model depends on the components having no over-constrained nodes.
All algorithms in this paper have been implemented in Python to verify the efficiency of the hierarchical structural analysis method. The scripts and test cases are available on GitHub (https://github.com/wangchustcad/hierarchicalStructuralAnalysis, accessed on 9 October 2021). In the future, the algorithms should be implemented by more efficient languages, such as C++, for practice application. Moreover, the study may be extended to the hierarchical structural analysis of general EoMs in the future by finding an efficient decomposition algorithm.
Author Contributions
Conceptualization, C.W.; formal analysis, C.W.; funding acquisition, T.X. and Y.X.; methodology, C.W.; supervision, L.W.; visualization, C.W.; writing—original draft, C.W.; writing—review and editing, L.W., T.X., Y.X., S.W., J.D. and L.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the National High Technology Research and Development Program of China (grant number 2018YFB-17008), in part by the National Natural Science Foundation of China (grant number 52105019), and in part by the Guangdong Basic and Applied Basic Research Foundation (grant number 2021A1515012409 and 2020A1515110464).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The variables and equations of the example models in Section 4 are openly available in Hierarchical Structural Analysis Models at https://doi.org/10.17632/p59388zhzh.1 (accessed on 6 October 2021). The codes for the algorithm implementation and application examples can be found at https://github.com/wangchustcad/hierarchicalStructuralAnalysis (accessed on 6 October 2021).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Fitzgerald, J.; Gamble, C.; Larsen, P.G.; Pierce, K.; Woodcock, J. Cyber-physical Systems Design: Formal Foundations, Methods and Integrated Tool Chains. In Proceedings of the Third FME Workshop on Formal Methods in Software Engineering, Florence, Italy, 18 May 2015; IEEE Press: Piscataway, NJ, USA, 2015; pp. 40–46. [Google Scholar]
- Wang, C.; Wan, L.; Xiong, T.; Xie, Y.; Wang, S. A Relational Abstraction of Structure and Behavior for Cyber-Physical System Design. IEEE Access 2021, 9, 40388–40401. [Google Scholar] [CrossRef]
- Bernardeschi, C.; Dini, P.; Domenici, A.; Palmieri, M.; Saponara, S. Formal Verification and Co-Simulation in the Design of a Synchronous Motor Control Algorithm. Energies 2020, 13, 4057. [Google Scholar] [CrossRef]
- Alonso-González, C.J.; Pulido, B. Model-Based Diagnosis by the Artificial Intelligence Community: The DX Approach. In Fault Diagnosis of Dynamic Systems: Quantitative and Qualitative Approaches; Escobet, T., Bregon, A., Pulido, B., Puig, V., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 97–124. ISBN 978-3-030-17728-7. [Google Scholar]
- Ceballos, R.; Abreu, R.; Varela-Vaca, Á.J.; Gasca, R.M. Model-Based Software Debugging. In Fault Diagnosis of Dynamic Systems: Quantitative and Qualitative Approaches; Escobet, T., Bregon, A., Pulido, B., Puig, V., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 365–387. ISBN 978-3-030-17728-7. [Google Scholar]
- Zogopoulos-Papaliakos, G.; Kyriakopoulos, K.J. An Efficient Approach for Graph-Based Fault Diagnosis in UAVs. J. Intell. Robot. Syst. 2020, 97, 553–576. [Google Scholar] [CrossRef]
- Soares, R.d.P.; Secchi, A.R. Structural Analysis for Static and Dynamic Models. Math. Comput. Model. 2012, 55, 1051–1067. [Google Scholar] [CrossRef]
- Fritzson, P.; Bunus, P. Modelica—A General Object-Oriented Language for Continuous and Discrete-Event System Modeling and Simulation. In Proceedings of the 35th Annual Simulation Symposium (SS 2002), San Deigo, CA, USA, 14–18 April 2002; pp. 365–380. [Google Scholar]
- Oh, M.; Pantelides, C.C. A Modelling and Simulation Language for Combined Lumped and Distributed Parameter Systems. Comput. Chem. Eng. 1996, 20, 611–633. [Google Scholar] [CrossRef]
- Mattsson, S.E.; Olsson, H.; Elmqvist, H. Dynamic Selection of States in Dymola. In Proceedings of the Modelica Workshop 2000 Proceedings, Lund, Sweden, 23 October 2000; pp. 61–67. [Google Scholar]
- Zhou, F.L.; Chen, L.P.; Wu, Y.Z.; Ding, J.W.; Zhao, J.J. MWorks: A Modern IDE for Modeling and Simulation of Multi- domain Physical Systems Based on Modelica. In Proceedings of the 5th International Modelica Conference, Vienna, Austria, 4–5 September 2006; Volume 1, pp. 725–732. [Google Scholar]
- Bunus, P.; Fritzson, P. Automated static analysis of equation-based components. Simul. Trans. Soc. Model. Simul. Int. 2004, 80, 321–345. [Google Scholar] [CrossRef]
- Mattsson, S.E.; Söderlind, G. Index Reduction in Differential-Algebraic Equations Using Dummy Derivatives. SIAM J. Sci. Comput. 1993, 14, 677–692. [Google Scholar] [CrossRef]
- Steward, D.V. On an Approach to Techniques for the Analysis of the Structure of Large Systems of Equations. SIAM Rev. 1962, 4, 321–342. [Google Scholar] [CrossRef]
- Sargent, R.W.H. The Decomposition of Systems of Procedures and Algebraic Equations. In Proceedings of the Numerical Analysis; Watson, G.A., Ed.; Springer: Berlin, Heidelberg, Germany, 1978; pp. 158–178. [Google Scholar]
- Duff, I.S.; Reid, J.K. An Implementation of Tarjan’s Algorithm for the Block Triangularization of a Matrix. ACM Trans. Math. Softw. 1978, 4, 137–147. [Google Scholar] [CrossRef]
- Reissig, G.; Feldmann, U. A Simple and General Method for Detecting Structural Inconsistencies in Large Electrical Networks. IEEE Trans. Circuits Syst. I-Fundam. Theor. Appl. 2003, 50, 1482–1485. [Google Scholar] [CrossRef]
- Mattsson, S.E. Simulation of Object-Oriented Continuous Time Models. Math. Comput. Simul. 1995, 39, 513–518. [Google Scholar] [CrossRef]
- Pantelides, C.C. The Consistent Initialization of Differential-Algebraic Systems. SIAM J. Sci. Stat. Comput. 1988, 9, 213–231. [Google Scholar] [CrossRef]
- Gear, C.W. Differential-Algebraic Equation Index Transformations. SIAM J. Sci. Stat. Comput. 1988, 9, 39–47. [Google Scholar] [CrossRef]
- Unger, J.; Kröner, A.; Marquardt, W. Structural Analysis of Differential-Algebraic Equation Systems—Theory and Applications. Comput. Chem. Eng. 1995, 19, 867–882. [Google Scholar] [CrossRef]
- Pryce, J.D. A Simple Structural Analysis Method for DAEs. BIT Numer. Math. 2001, 41, 364–394. [Google Scholar] [CrossRef]
- McKenzie, R.; Pryce, J.D. Structural analysis based dummy derivative selection for differential algebraic equations. BIT Numer. Math. 2017, 57, 433–462. [Google Scholar] [CrossRef] [Green Version]
- Tan, G.; Nedialkov, N.S.; Pryce, J.D. Conversion Methods for Improving Structural Analysis of Differential-Algebraic Equation Systems. BIT Numer. Math. 2017, 57, 845–865. [Google Scholar] [CrossRef] [Green Version]
- Pryce, J.D.; Nedialkov, N.S.; Tan, G.; Li, X. How AD Can Help Solve Differential-Algebraic Equations. Optim. Method Softw. 2018, 33, 729–749. [Google Scholar] [CrossRef]
- Tang, J.; Rao, Y. A New Block Structural Index Reduction Approach for Large-Scale Differential Algebraic Equations. Mathematics 2020, 8, 2057. [Google Scholar] [CrossRef]
- Zolfaghari, R.; Nedialkov, N.S. Structural Analysis of Linear Integral-Algebraic Equations. J. Comput. Appl. Math. 2019, 353, 243–252. [Google Scholar] [CrossRef]
- Pryce, J.D.; Nedialkov, N.S.; Tan, G. DAESA-A Matlab Tool for Structural Analysis of Differential-Algebraic Equations: Theory. ACM Trans. Math. Softw. 2015, 41, 1–20. [Google Scholar] [CrossRef]
- Dulmage, A.L.; Mendelsohn, N.S. Coverings of Bipartite Graphs. Can. J. Math. 1958, 10, 517–534. [Google Scholar] [CrossRef]
- Dulmage, A.L.; Mendelsohn, N.S. A Structure Theory of Bipartite Graphs of Finite Exterior Dimension. Trans. Roy. Soc. Canada 1959, III, 1–13. [Google Scholar]
- Ding, J.-W.; Chen, L.-P.; Zhou, F.-L. A Component-Based Debugging Approach for Detecting Structural Inconsistencies in Declarative Equation Based Models. J. Comput. Sci. Technol. 2006, 21, 450–458. [Google Scholar] [CrossRef]
- Hopcroft, J.E.; Karp, R.M. A N5/2 Algorithm for Maximum Matchings in Bipartite. In Proceedings of the 12th Annual Symposium on Switching and Automata Theory (Swat 1971); IEEE Computer Society: Washington, DC, USA, 1971; pp. 122–125. [Google Scholar]
- Berge, C. Two Theorems in Graph Theory. Proc. Natl. Acad. Sci. USA 1957, 43, 842–844. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuhn, H.W. The Hungarian Method for the Assignment Problem. Nav. Res. Logist. 2005, 52, 7–21. [Google Scholar] [CrossRef] [Green Version]
- Uno, T. Algorithms for Enumerating All Perfect, Maximum and Maximal Matchings in Bipartite Graphs. In Proceedings of the Algorithms and Computation; Leong, H.W., Imai, H., Jain, S., Eds.; Springer: Berlin/Heidelberg, Germany, 1997; pp. 92–101. [Google Scholar]
- Uno, T. A fast algorithm for enumerating bipartite perfect matchings. In Algorithms and Computation, Proceedings; Eades, P., Takaoka, T., Eds.; Springer: Berlin, Germany, 2001; Volume 2223, pp. 367–379. ISBN 978-3-540-42985-2. [Google Scholar]
- Bérczi, K.; Iwata, S.; Kato, J.; Yamaguchi, Y. Making Bipartite Graphs DM-Irreducible. SIAM J. Discrete Math. 2018, 32, 560–590. [Google Scholar] [CrossRef] [Green Version]
- Hall, M., Jr. Distinct Representatives of Subsets. Bull. Amer. Math. Soc. 1948, 54, 922–927. [Google Scholar] [CrossRef] [Green Version]
- Mendeley Data—Hierarchical Structural Analysis Models. Available online: https://doi.org/10.17632/p59388zhzh.1 (accessed on 6 October 2021).
- Kroner, A.; Marquardt, W.; Gilles, E.D. Getting around Consistent Initialization of DAE Systems? Comput. Chem. Eng. 1997, 21, 145–158. [Google Scholar] [CrossRef]
- Wang, C.; Wan, L.; Xiong, T. CoModel: A Modelica-Based Collaborative Design Web Platform for CPS Products. In Proceedings of the Advances in Mechanical Design; Springer: Singapore, 2017; pp. 317–333. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).