1. Introduction
Statistical modeling to explain variables, such as the concentration of sulfur in the tissue in 100 g of leaves of a certain genotype of bean (measured by turbidimetric methods), the proportion of children killed by unknown causes in the main cities of a country, the proportion of deaths caused by smoking, the prevalence rate of a certain disease in a community, the proportion of votes in favor of a presidential candidate for reelection, the proportion of income spent on education, and, in general, any response variable on the unit interval
as proportions, rates, or indices, has been studied by several researchers, highlighting the works of Paolino [
1], Cribari-Neto and Vasconcellos [
2], Kieschnick and Mccullough [
3], Ferrari and Cribari-Neto [
4], and Vasconcellos and Cribari-Neto [
5].
Among the most recent works, we emphasize Ospina and Ferrari [
6,
7], Bayes et al. [
8] and Martínez-Flórez et al. [
9,
10] who have presented extensions of the works mentioned above, some of them by incorporating a set of covariates to the model. Other works in this same area are those of Mazucheli et al. [
11,
12,
13] and Menezes et al. [
14], which extend the Birbaum–Saunders, gamma, Weibull, and logistic models, respectively, to situations of models able to fit datasets whose variables are on a unity interval. These families have proven to be a good alternative to the beta model of Ferrari and Cribari-Neto [
4] and the Kumaraswamy distribution by [
15].
The previously mentioned distributions used for modeling proportions, rates, and indices as well as their respective extensions have special characteristics from which is possible to decide if is a favorable option for fitting a particular dataset; usually, the asymmetry and kurtosis coefficients are the most used. Unquestionably, these measures are associated with certain parameters of each model; generally, the parameters to which we refer are linked to characteristics of shape and/or asymmetry or the kurtosis of the distribution. Some works include the case of unit variables that contain an excessive amount of zeros and/or ones, and they are known in the literature as inflated distributions in the values of zero or one. Some works for dealing with these situations have been proposed by Ospina and Ferrari [
7] and Martínez-Flórez et al. [
10], among others.
The main objective of this article is to propose a new class of regression models based on the power-skew-normal distribution, which are useful for fitting data with response on the unit interval. The new models allow taking into account possible excesses of the zero and/or one values of the response variable and are also able to capture different forms of the response distribution, as well as high (or low) degrees of asymmetry and kurtosis present in the data.
The rest of this paper is organized as follows:
Section 2 presents some asymmetric distributions and its main characteristics. In
Section 3, the power-skew-normal/logit model is introduced, and its main properties are discussed. In addition, the statistical inference is carried out by using the maximum likelihood method.
Section 4 presents the unit-power-skew-normal model for fitting data on the
interval. For this model, the maximum likelihood method is used to carry out the estimation of parameters. The score function and the elements of the observed information matrix are presented in detail.
Section 5 presents the extension of the inflated unit-power-skew-normal model, which is an alternative to the inflated beta regression model. In particular, the log-UPSN model is studied. In
Section 6, the doubly censored PSN model is presented, and the generalized two-part PSN model with covariates is studied as a particular case. Finally, in
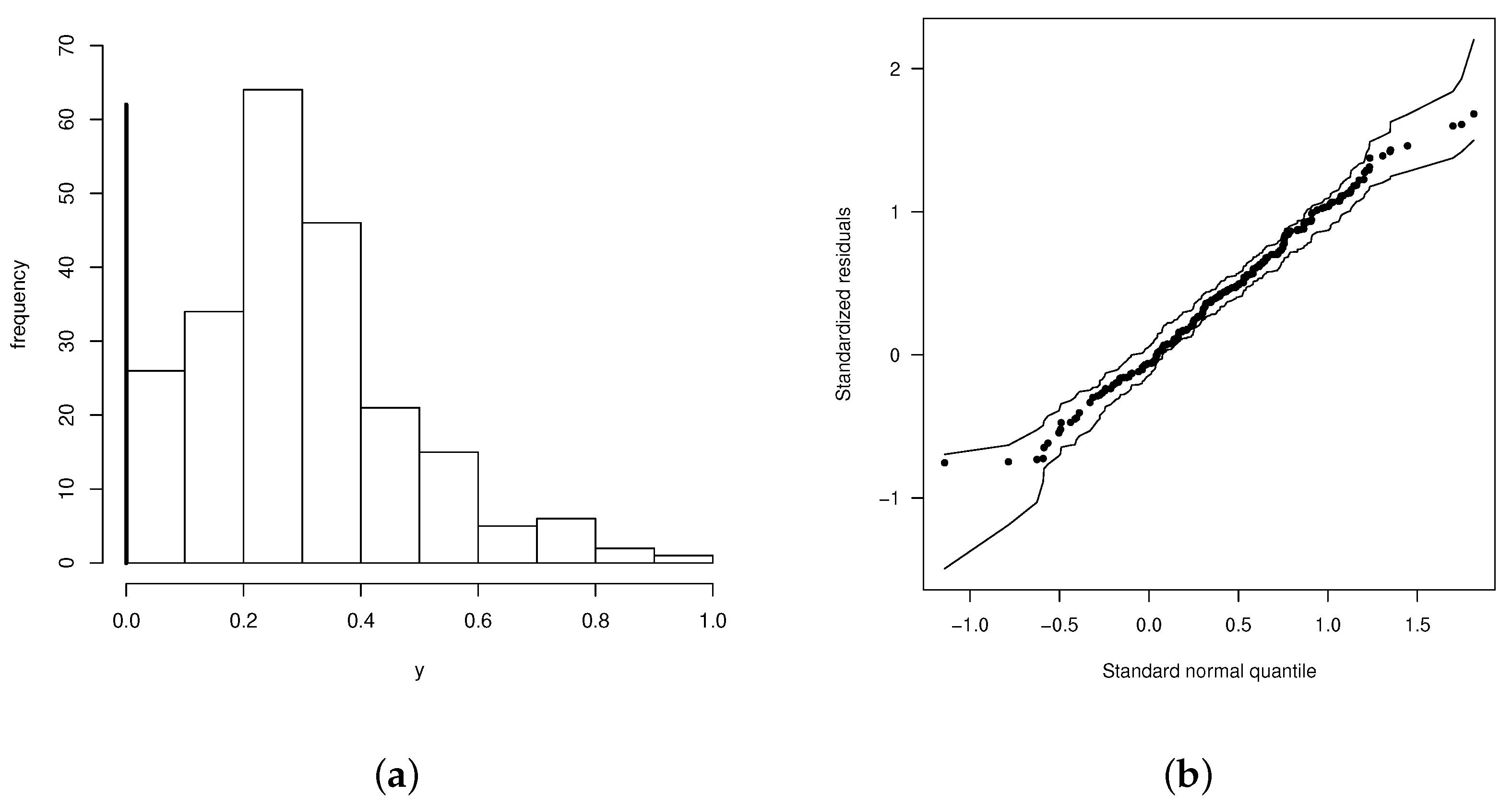
Section 7, two illustrative examples are reported and compared with several rival models.
2. Asymmetric Distributions
The study of families with flexible distributions capable of modeling different degrees of asymmetry and kurtosis has been of great interest in the recent statistical literature. Different works have been published, with initial works by Birnbaum [
16], Lehmann [
17], Roberts [
18], and O’Hagan and Leonard [
19] and more recently by Fernandez and Steel [
20], Mudholkara and Hutson [
21], Azzalini [
22], Durrans [
23], Gupta and Gupta [
24], Arellano-Valle et al. [
25,
26], Gómez et al. [
27], and Pewsey et al. [
28]. Azzalini [
22] introduces the skew-normal (SN) distribution by adding an extra parameter
to the normal model. The inclusion of this new parameter allows for fitting data with high degrees of asymmetry. The probability density function (pdf) for the skew-normal model with location parameter
and scale parameter
is given by
where
and
. The functions
and
denote the pdf and cumulative distribution function (cdf) of the standard normal distribution. The model in (
1) is denoted by
, and the respective cdf is written as
where
is the Owen function (see [
29]). Another asymmetric model widely studied in the statistical literature is the named power-normal (PN), which was initially introduced by Durrans [
23]. The PN model is sometimes denominated the generalized Gaussian distribution. Later, Gupta and Gupta [
24,
30] studied some statistical properties of the PN model, and they called it the exponential distribution. On the other hand, Pewsey et al. [
28] studied the statistical inference of the PN model by using the maximum likelihood method; here, the authors deduce the expected information matrix, and they show the non-singularity of the matrix. The pdf of the location-scale version of the PN model is given by
where
is a shape parameter, which contributes strongly to the kurtosis of the model. The model in (
3) is denoted by
, and the respective cdf is given by
An extension of the PN model which is capable of capturing greater ranges of asymmetry and kurtosis was proposed by Martínez-Flórez et al. [
31]. This proposal, which is named the power-skew-normal (PSN) model, is originated by replacing the pdf and cdf of the normal distribution in the PN model by those of the SN model, that is, the PSN model contains both shape and asymmetry parameters. The pdf for the location-scale version of the PSN model is given by
where
and
. This is denoted by
. One can observe that, for
, the SN model is obtained, while for
, the PN model is followed. The normal model is obtained when
and
, that is, the PSN model is more flexible than the normal, SN and PN models. If
, then the cdf of
X is given by
where
is Owen’s function. For
and
values ranging in the
interval, the asymmetry and kurtosis coefficients for the PSN model are
and
, respectively; these intervals contain the respective asymmetry and kurtosis coefficients of the SN and PN models (see Pewsey et al. [
28]). The extensions for the positive data of the random variable
X following the SN, PN or PSN models are obtained by applying the transformation
, and they are denominated as a log-skew-normal (LSN) distribution, log-power-normal (LPN) distribution and log-power-skew-normal (LPSN) distribution, respectively (see Martínez-Flórez et al. [
9,
32], Mateus-Figueras and Pawlosky-Glanh [
33]).
Asymmetric models have become very useful statistical tools for modeling censored or truncated data using covariates: see, for example, the log-gamma model by Moulton and Halsey [
34], the log-skew-normal model of Chai and Bailey [
35], the power-normal model by Martínez-Flórez et al. [
9], and log-power-normal models by Martínez-Flórez et al. [
9,
32]. In this work, we extend the PSN model to the case of proportions, rates or indices data. The proposed extension is useful for modeling data with a response on the unit interval with an excess of zeros and/or ones and covariates to explain the response and the excess of zeros and/or ones.
3. The Power-Skew-Normal/Logit Mixture Model
The linear regression model with errors following a
distribution was introduced and studied in detail by Martínez-Flórez et al. [
32]. This model is expressed as
where
is an unknown vector of regression coefficients,
is a vector containing
p known explanatory variables with
, and
for
. It follows that
Since , it follows that ; therefore, it is necessary to correct the parameter in the form , where . Thus, it is obtained that , where . The ordinary least squares method can be used to obtain an estimate of the parameter vector , which can be used as an initial value in the maximum likelihood estimation process.
The main interest in this paper is centered on the case where the measured variable has a response on the unit interval, and the expected response or predicted value falls outside of this unit interval, which could lead to negative estimates without any interpretation or meaning. To avoid these inconveniences, the assumption of response variable
Y being a linear function of the vector of explanatory variables
is replaced by the assumption of a non-linear transformation of this set of variables. This model is obtained by assuming that the location parameter of the
variable can be written as
where
is a strictly monotonic link function whose second derivative exists. Two link functions
widely used in practical situations that can be considered in (
7) are the probit with
, where
is the cdf of the standard normal distribution, and the logit function given by
. These two options lead to very similar results in the predicted values, with some exceptions for extreme values. For the ease of handling deductions, in this work, we opt for the logit function. Thus, in this case, we have
For the function in (
8), the parameters are interpreted from the odds ratio between the odds of the prediction or mean when one of the variables is increased
m units (keeping the rest of the explanatory variables fixed) and the odds without the increase. One can show that this quotient of odds ratios is given by
, where
is the parameter associated with the explanatory variable increased by
m units. It follows that the distribution of the study variable is
From the model in (
9), some special cases can be obtained; for example, if
, the skew-normal-logit model is obtained, while, for
, the exponential or alpha-power-logit case is followed. If
and
, it has the normal-logit model.
The parameter estimation of the PSN regression model on the unit interval
with logit link function can be obtained by using the maximum likelihood method. The log-likelihood function obtained from a random sample of size
n is given by
where
for
. To obtain the elements of the score function and the observed information matrix of the parameters
, we use the fact that
where
is given in (
8). Then, the elements of the score function can be written in the form
where
and
. The scores equations are obtained by setting the elements of the score function equal to zero, that is, the first derivative of
with respect to the parameters
,
,
, and
. By solving this system of equations, the maximum likelihood estimates are obtained. To maximize the log-likelihood function, it is necessary to use iterative numeric methods. Likewise, as in the standard case, the observed and expected Fisher information matrices are obtained as minus the Hessian matrix (the second derivative of
with respect to the parameters) and the expected value of the elements of the observed information matrix, respectively. After some algebraic manipulations, it follows that the elements of the observed information matrix can be written in the form
,
and
being the set of observations.
Letting
and
the elements
are given by
Now, by letting
and
, and using numerical integration, the Fisher information matrix is given by
where
with
and
with
. The determinant of the
matrix is given by
Since is of full-column rank, and is a diagonal matrix, the rank of is the same as the , that is, the matrix is of full-column rank; therefore, will be full-rank and hence invertible, that is, its determinant is different from zero. Now, to find the last determinant, we write where ; this partition leads to expressing the matrix as a partitioned matrix, for which we can use the existing expressions of the matrix algebra to find the inverse of a partitioned matrix, that is, we can determine . With this result, it follows that, and, as for , , which leads to , concluding that that is, is non-singular, and therefore its rows and/or columns are linearly independent. Thus, the rows and/or columns of the information matrix are linearly independent, that is, . This leads to a non-singular matrix, because its columns (or rows) are linearly independent. Therefore, the regularity conditions are satisfied, and the known -property for the maximum likelihood estimators is satisfied for all and .
This important result further supports the hypothesis of singularity in the information matrix for the SN model for cases where the variable is a linear transformation of the location parameter. For other non-linear transformations, such as the asymmetric Birbaum–Saunders distributions studied by Vilca and Leiva-Sánchez [
36], the asymmetric sinh-normal model of Leiva-Sánchez [
37], and the asymmetric Birbaum–Saunders exponential distribution in Mattínez-Flórez et al. [
38], the information matrices turned out to be non-singular.
4. Unit-Power-Skew-Normal Model
The unit-power-skew-normal (UPSN) model can be defined from the doubly truncated power-skew-normal (TPSN) distribution on the interval
, which has a pdf given by
where
The properties of the doubly TPSN model can be studied from the properties of the truncated models. One can observe from Equation (
14) that, if
, the standard unit skew-normal-logit model is obtained, while, for
, the standard unit exponential-logit or alpha-power-logit model is obtained. Finally, when
and
, the standard unit normal-logit model is followed.
The cdf of the TPSN model is given by
and the survival and Hazard functions are given by
respectively. The moments of the TPSN model can be calculated by the expression
where
being the inverse function of
. The estimates of the parameters of the doubly TPSN-logit model (
14) considering a set of covariates can be obtained by using the maximum likelihood method. The log-likelihood function for estimating
is given by
where
,
,
are defined in (
15). The scores equations are obtained by setting the first derivative of
with respect to the parameters
, and
, equal to zero. The solution of the resulting system of equations leads to maximum likelihood estimates, which is maximized by using iterative numeric methods.
The covariance matrix and standard errors for the TPSN model can be obtained from the inverse of the observed information matrix, given by minus the second derivative of the log-likelihood function in Equation (
20) with respect to the parameters of the model,
,
,
, and
. Then, the observed information matrix of the truncated unit PSN-logit model can be found from the elements of the matrix of the unit PSN-logit model; these elements can be written as
where
In addition, for
it follows that
According to the results found for the the PSN-logit model, the information matrix of the model is non-singular; therefore, for large sample sizes, we have
That is, the vector of the estimators is consistent and has a normal asymptotic distribution, with covariance matrix being the inverse of the Fisher information matrix. In practice, since the matrix is consistent for , then we can take as the covariance matrix of the vector of estimators of the standard unit PSN-logit regression model.
5. Inflated Unit-Power-Skew-Normal Model
Ospina and Ferrari [
6] introduced the zero-one inflated beta (BIZU) model, which is a mixture between a random variable with Bernoulli distribution with parameter
, for
and a reparameterized beta distribution of parameters
and
. Particular cases of this model follow for the situations of a unique inflated extreme value (zero or one) called BIZ and BIU, respectively. These ideas can be extended to the truncated unit-PSN model.
By considering that the mass point at value zero can be modeled by a Bernoulli random variable with parameter
, namely
and the responses between zero and one can be modeled by the truncated centered unit-power-skew-normal distribution,
with parameter
, the random variable on the unit interval
then follows a truncated unit distribution inflated at zero and one, with parameters
if its pdf is represented by the mixture
where
. By the construction shown in the previous pdf, it holds that
and
,
being the mixture parameter. For
w,
, and
defined as in Equation (
15), the cdf of
Y can be written as
Considering the parameterization
and
where
, the above model can be written in the form
From this model, inflation at zero is obtained by taking
, and inflation at one follows by taking
. Now, we introduce covariates in the model. For the discrete part, we assume that the responses in zero and one can be explained by the covariate vectors
and
, respectively. Then, following the construction of a logistic model with polytomous response, it is obtained that
where
and
are vectors of unknown parameters associated with the covariate vectors
and
, respectively. For the continuous part, we continue assuming a truncated centered unit-PSN model, with parameters
, defined in (
14). One can show that the log-likelihood function for the parameters vector
, given
,
,
, and
, can be written in the form
where
and
is defined in Equation (
20).
This guarantees that the parameter estimates can be obtained in separate forms. The score functions and the observed information matrix are obtained by differentiating the log-likelihood function once and twice, with respect to the parameters, respectively. The fact that the log-likelihood function can be broken down into two independent components implies that the Fisher information matrix is a diagonal block, that is, it can be written as
where
is related to the discrete part and
to the set of parameters of the continuous part. This matrix coincides with the respective matrix for the previous case of the model for the standard on interval
.
The elements of the observed information matrix for the discrete part are presented in
Appendix A. Taking the expected value to these elements, the Fisher information matrix is obtained. Likewise, given the properties of the inverse of a diagonal matrix, one can conclude that the covariance matrix of the estimators vector can be written as
Confidence intervals for with confidence coefficient can be obtained as . Taking , the inflated model at zero is followed, UPSNIZ, and taking , the inflated model at one is followed, UPSNIU
The Log-UPSN Model
In some cases, the random variable
does not follow a
distribution; however, the random variable
can have a
distribution. In those cases, it is said that the random variable
follows a truncated log-unit-PSN model, and its pdf is given by
where
for
.
is used instead of
due to the non-existence of the logarithm at the point
. In the cases with covariates, it holds that
where
This new model is denoted by
. For
in (
25),
is replaced by
which is defined in (
8).
The estimation of the parameters follows the same routine as in the case of the UPSN model; likewise, the information matrix of this model can be obtained from the information matrix of the UPSN model. It is enough to change to in the respective expressions. For this model, in the case of inflation at zero and/or one, that is, in the intervals, , , and are used for the discrete part—a random variable binomial under a logit link function, similar to the case of the UPSN model.
6. Doubly Censored PSN Model
In this section, the model given by Moulton and Halsey [
39] is generalized to the case of a mixture model for two limit points, lower and upper. One of the first models for the fit of the mixture between a discrete and a continuous random variable was proposed by Cragg [
40], often called
the two-part model. Under the Cragg model, the pdf of
can be formally written as
, where
is the probability that determines the relative contribution made by the point mass to the general mixture distribution,
f is a density function with positive support,
if
and
if
. In this model, the two components are determined by different stochastic processes, so a positive response is necessarily reached from
f. On the other hand, a zero comes from the point mass distribution. This model, however, does not consider the situation of a lower limit and that part of the observations may be below the lower limit.
We extend Cragg’s model [
40] to the case of the doubly censored and centered power-skew-normal model. A random variable is said to be doubly censored when measurements above the upper limit of detection and below the lower limit of detection are taken as those values. The lower and upper detection limits are specified by the researcher and generally depend on the measuring device used to produce the measurements. For our particular case, the lower and upper detection limits are given by
and
, respectively. For
, a random sample where, for
, the doubly censored random variable PSN between zero and one is defined as
We use the notation
. The contribution of the uncensored observations to the likelihood function,
, is given by the density function
On the other hand, the contribution of the censored observations at
is given by
while the contribution of the censored observations at
is given by
Then, from (
26)–(
28), the
model has a pdf given by
where
,
and
are defined in Equation (
15).
The parameters estimation of the DCPSN model can be achieved by maximizing the log-likelihood function given by
Generalized Two-Part PSN Model with Covariates
Moulton and Halsey [
39] generalize the two-part model by explicitly allowing the possibility that some limited responses are the result of the censoring interval of
f. This means that an observed zero can be a realization from the point mass distribution or partial observation of
f with a critical value not precisely known, but close to
for a small prespecified constant
T, the lower detection limit.
Formally,
where
F is the cdf associated with the
f density function. In many studies,
. Therefore, a large family of mixed models can be generated by varying the basic density
f and the corresponding link function
. One can see that if
, for
, the Moulton and Halsey [
39] model is reduced to the Tobit model.
The two-part model by Moulton and Halsey [
39] is extended to the situations of doubly censored responses. If
denotes the proportion of observations below the lower detection limit,
, and
denotes the proportion of observations above the upper detection limit,
, then the doubly censored model can be defined from the pdf.
with
, as in the generalized doubly censored model of Cragg [
40], and
is the distribution of the truncated PSN model defined on the
interval. Some mixture models have been used in practical applications in different fields such as biology, economy, agriculture, etc.—to mention a few, the probit/truncated-normal, logit/log-normal, logit/log gamma and probit/log-skew-normal mixture models (see Chai and Bailey [
35] and Martínez-Flórez et al. [
9]).
We consider an extension of the two-part generalized model for the situations of logit/doubly censored power-skew-normal model, together with covariates in each part of the model. Denoting
and
as auxiliary covariates for the discrete part at zero and one, respectively; denoting a set of covariates
for the continuous part at
; and letting
be the proportion of observations below zero, with
being the lower detection limit and
the proportion of observations above one, with
as the upper detection limit, then the extension of the Moulton and Halsey [
39] model for the case of the doubly censored PSN model is represented by the density function
where
and
are the point mass probabilities at the values zero and one, respectively, and
,
and
are defined as in the equations given in (
15). For modeling the responses at the mass points
and
, we define a binomial random variable with logit link function and polytomous response as defined in Equations (
21) to (
23).
A more general model, where only a proportion,
, with
, of censored observations come from the censored PSN model and the rest of the censored observations, say
, are located below or at the point
, and
are located above or at the point
, can be obtained from the model in Expression (
29).
The log-likelihood function for estimating the parameter vector of the model,
given
,
is
To obtain the information matrix, we proceed as in the case of the truncated UPSN model in the interval
. Again, the right-censored or left-censored cases will be special cases of this model for
and
, respectively. The log-doubly censored case is constructed in the same way as was done for the truncated UPSN model, that is, by taking
with
,
, and
defined as in (
25).




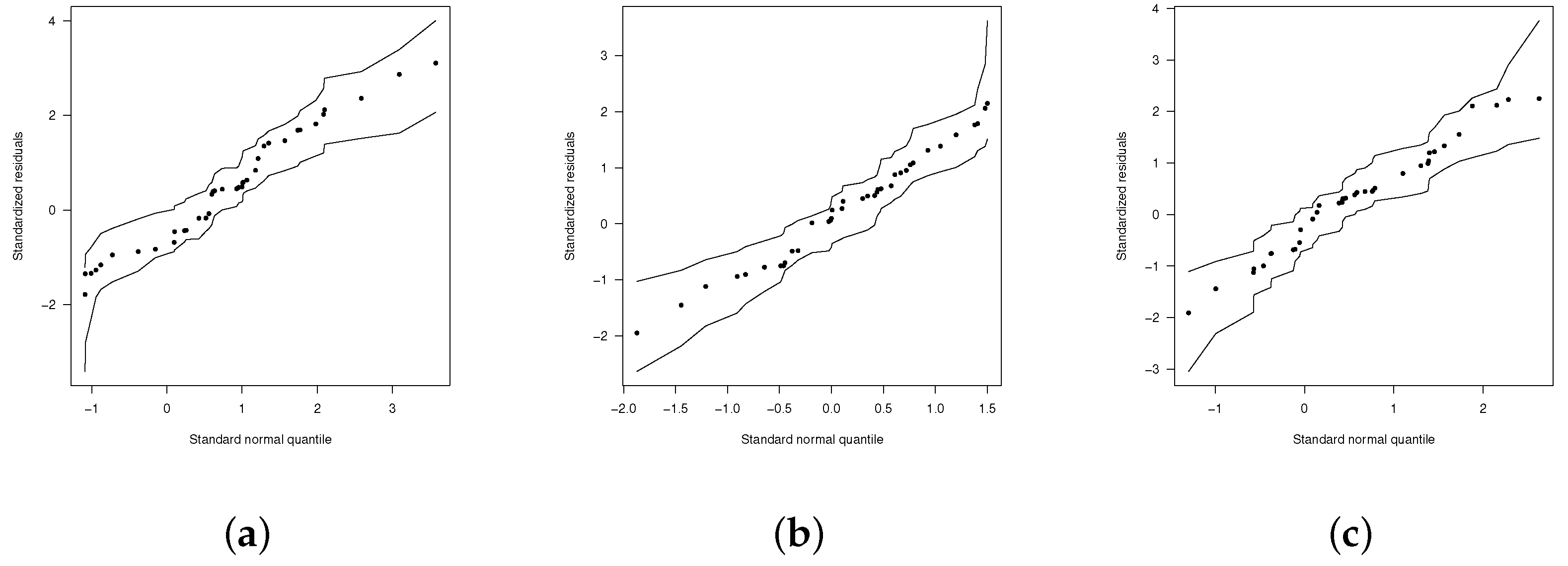
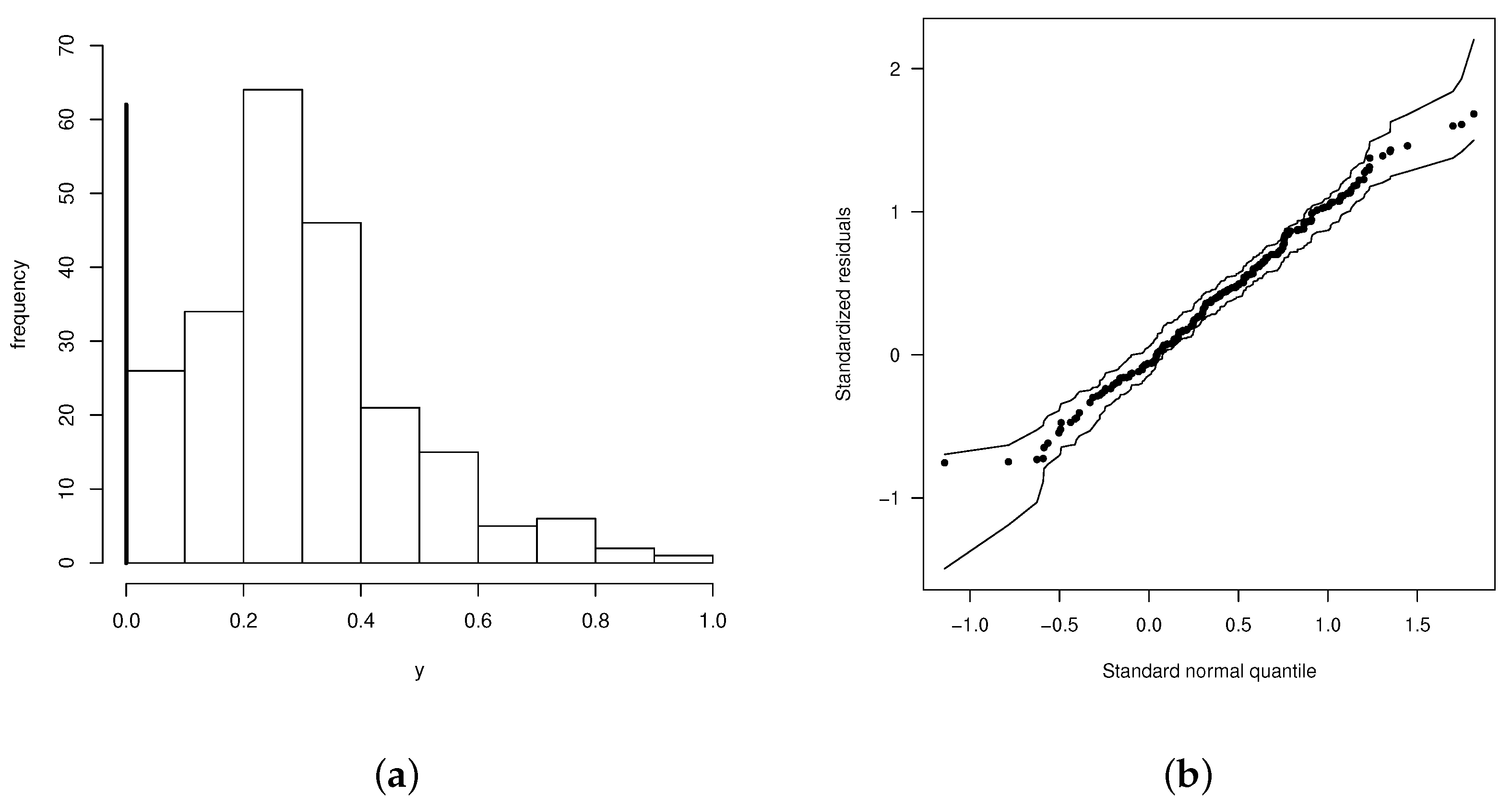
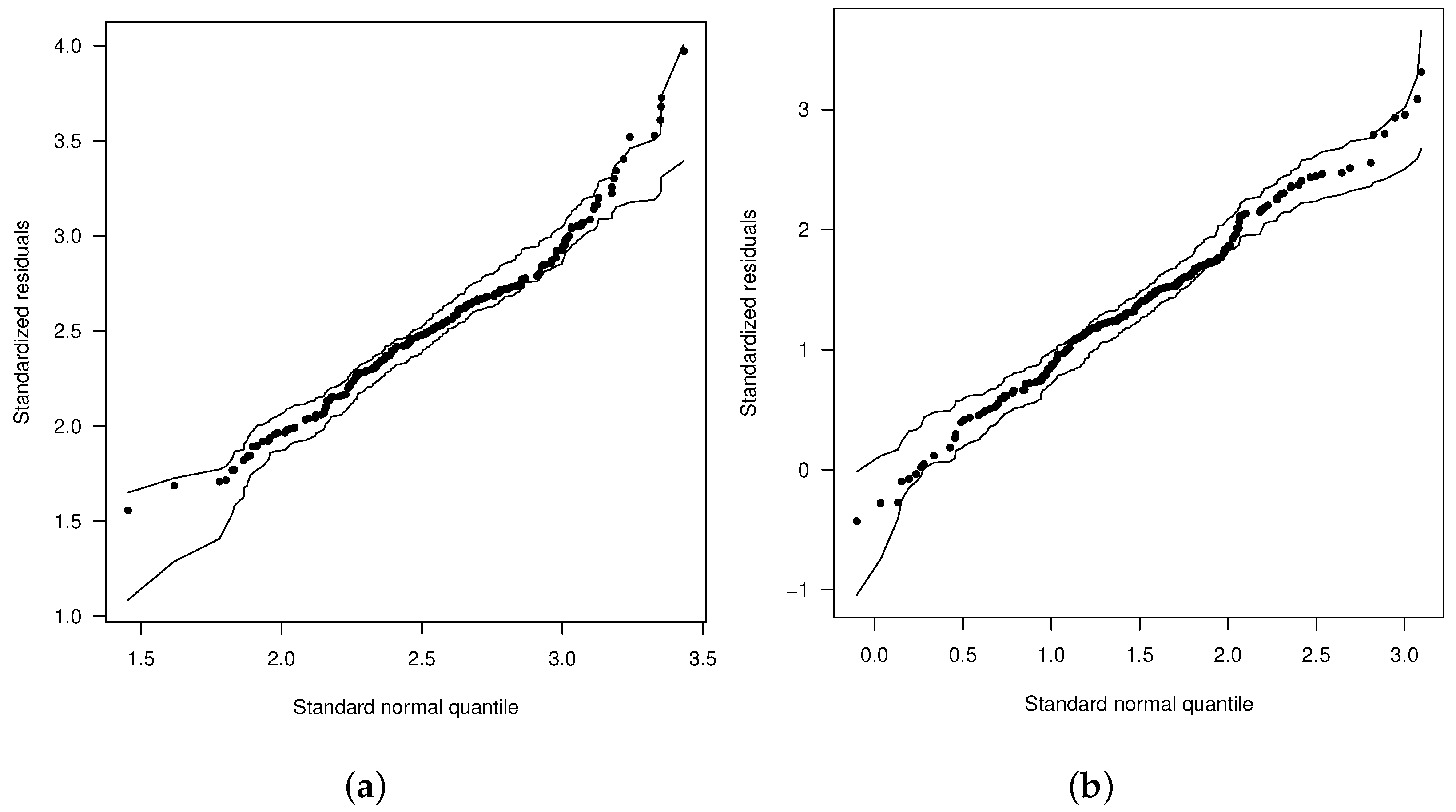

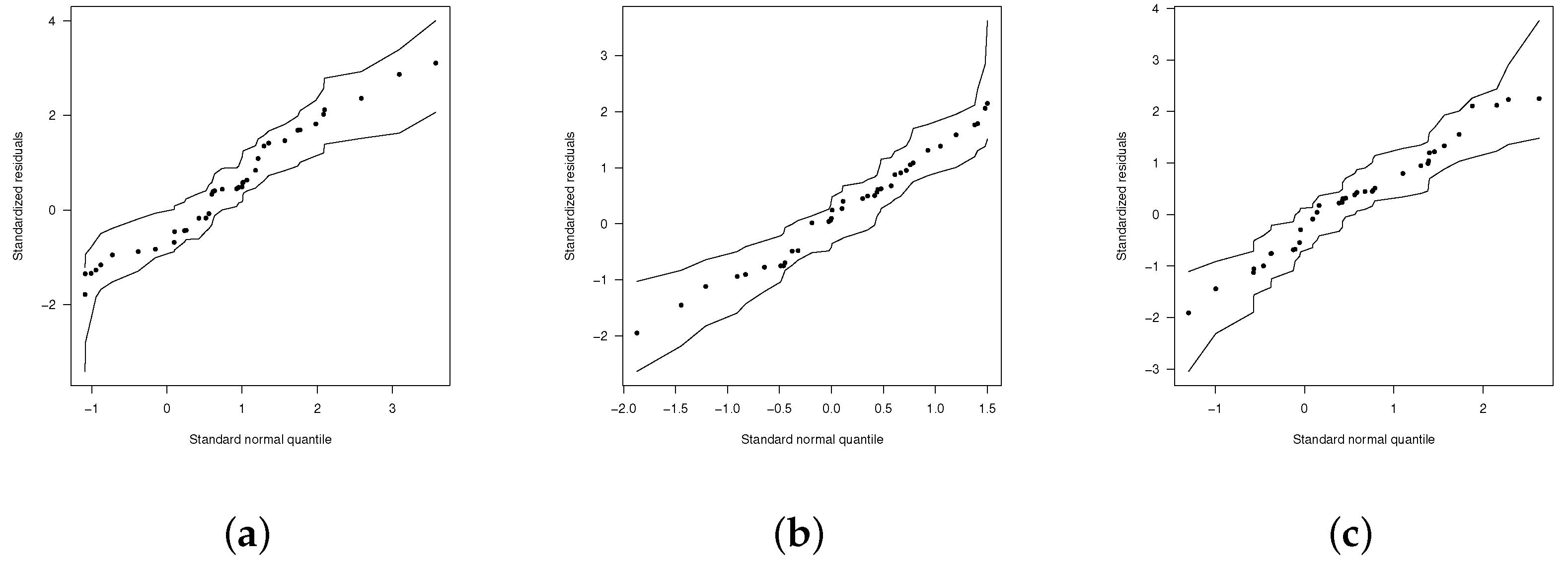{kind=link}
{kind=link}
{kind=link}