1. Introduction
The term spatial econometrics was coined by the Belgian economist Jean Paelinck in 1974 during an address to the Dutch statistical association. A few years later with his famous book “Spatial Econometrics: Methods and Models” Luc Anselin was instrumental to lay down the foundation of the field [
1]. His book was (and still is after many years) a very well organized collection of tools for the analysis of spatial data. The use of spatial econometrics in empirical applications was facilitated and extended by how easily the methods and examples presented in [
1] could be reproduced in SpaceStat software. In the early years, most of the attention given to spatial econometrics was from researchers in quantitative geography and regional science. Sessions of the North American Regional Science Association annual meetings were populated by research analyzing regional data from a spatial econometric perspective. This was probably due also to certain similarities between spatial econometrics and methods typically adopted in regional science as for example Input-Output analysis. At the same time SpaceStat was complemented by other tools such as the MATLAB spatial econometrics toolbox by LeSage (
http://www.spatial-econometrics.com/) and the package
spdep in R. In recent years, the field of spatial econometrics has experienced a rapid growth in conjunction with the interest and attention received by researchers in mainstream economics and econometrics. A multiplicity of methods and models have been developed for cross-sectional as well as panel data [
2,
3,
4]. Currently, spatial econometrics routines to estimate spatial models are available from many commercial (and non commercial) software, as for example Stata and the PySal module spreg [
5]. R [
6] is with no doubt the open source environment that contains the richest variety of options.
The aim of this paper is to survey all the available spatial econometrics packages and methods in R that deal with polygon spatial data, presenting the interested researchers with an up-to-date and comprehensive review of methods in both the cross-sectional and the panel data domains. All examples are meant to be replicable with resources from the public domain, allowing the reader to immediately put the relevant method into practice.
The rest of the paper is organized as follows: in
Section 2 we present four data sets that will be then used to illustrate the libraries introduced.
Section 3 is entirely devoted to cross sectional models and R libraries that deal with them. We present those libraries following as close as possible the chronological order in which they appeared in R.
Section 4 describes static panel data model and the library
splm, which implements maximum likelihood (ML) and generalized moments (GM) estimation.
Section 5 deals with further developments and alternative methods and approaches both for cross-sectional and panel models.
Section 6 concludes the paper.
3. Cross Sectional Models
The general model presented in this section allows for endogeneity of (some of) the regressors. The point of departure is the Cliff–Ord spatial model:
where
is an
vector of observations on the dependent variable,
is an
matrix of observations on
p endogenous variables,
is a
matrix of observations on
k exogenous variables,
is an
observed and non-stochastic spatial weight matrix and, consequently,
is an
variable that is generally referred to as the spatial lag of the dependent variable;
and
are corresponding parameters; and
is the spatial autoregressive coefficient. Given the presence of
the model can be viewed as a representation of a single equation of a system of equations.
The error vector
follows a spatial autoregressive process of the form:
where
is a scalar spatial autoregressive parameter,
is an
spatial weights matrix that may or may not be the same as
is an
vector of observation on the spatially lagged vector of residuals.
An alternative, more compact way to express the same model is:
where
is the set of all (endogenous and exogenous) explanatory variables, and
is the corresponding vector of parameters. Finally, the assumption on which the ML relies is that
.
The general model (Equation (
1)) may be restricted in various ways. Particularly in ML applications,
is generally set to zero.
The spatial error model (SEM) is generated from the general model when
:
The spatial lag model (SLM) or spatial autoregressive model (SAR) is generated from the general model when
:
The spatial Durbin model (SDM) is generated from the general model when
:
It is also possible to define the spatial error model with lags of the explanatory variables (henceforth SDEM) when
:
If the only restriction are
we have a spatial autoregressive model with autoregressive error term (SARAR):
Finally, the SARAR model can also include lagged explanatory variables. In this case the only restriction on the general model is
, that corresponds to the following specification:
Over time, a characteristic of spatial lag models (and, by extension, of any model including the spatially lagged response) has become clear: that, unlike the spatial error model, the spatial dependence in the parameter feeds back. The interpretation of marginal effects should therefore not be based on the fitted parameters , but rather on correctly formulated impact measures, as discussed in references given further on.
The reason for the feedback lies with the data generation process of the spatial lag model (and by extension in the general model). Rewriting:
where
is the
identity matrix. This means that the expected impact of a unit change in an exogenous variable
r for a single observation
i on the dependent variable
is no longer equal to
, unless
. The awkward
matrix term is needed to calculate impact measures for the spatial lag model, and similar forms for other models including the general model, when
.
3.1. Initial Development in R: The spdep Package
Bivand and Gebhardt [
19] discusssed initial approaches to handling and analysing spatial data using R, based on a presentation at the 1998 European Reagional Science Association (ERSA) Congress in Vienna. A specialist meeting in Santa Barbara in May 2002 turned out to be very fruitful, but the contribution covering R took a little while to appear [
20]; the meeting proceedings were online directly. Further discussion of spatial regression for areal/lattice data was presented at the 2002 ERSA Congress in Dortmund and published straight away [
21]. The main traits of the development of spatial data handling are described by Bivand [
22]. The
spdep package was first published on the Comprehensive R Archive Network (CRAN) in March 2002, replacing and merging
spweights and
sptests first available from September 2001, and the short-lived
spsarlm package on CRAN in February 2002.
spdep inherited the ML estimation functions from
spsarlm; there have been other simpler implementations, for instance [
23].
3.1.1. Spatial Dependence and the OLS Model
Initial concerns about the presence of spatial dependence in variables included in standard Gaussian linear models concentrated on the interpretation of tests on regression coefficients. Since positive spatial dependence may signal fewer effective degrees of freedom, could one trust standard tests assuming that no spatial dependence was present?
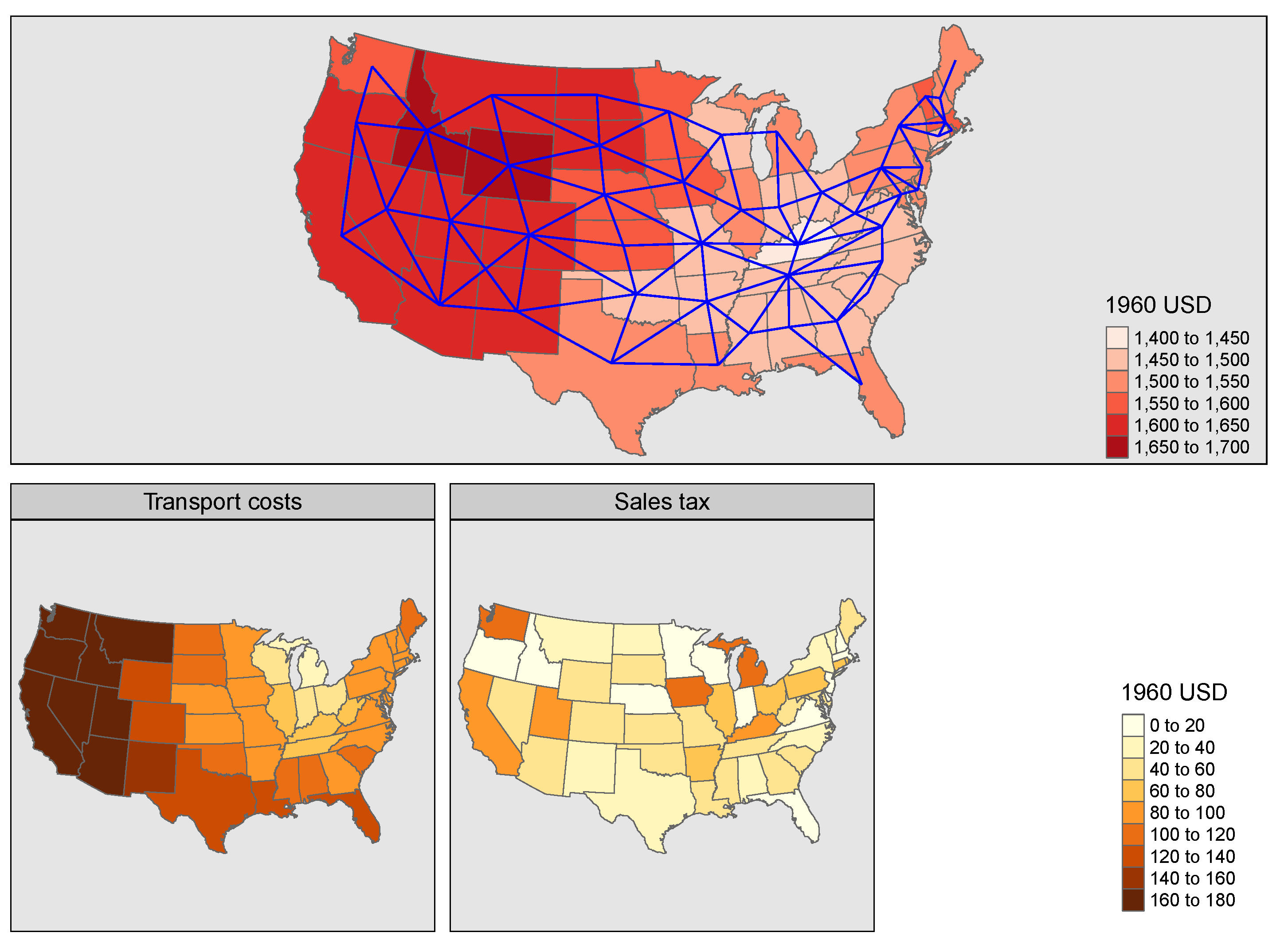
Table 1 shows a small part of the findings of Smith and Lee [
24], using the 49 coterminous states neighbour graph (
Figure 1) and 10,000 draws. If both y and
x show spatial dependence, standard test assumptions should not be used. If either is free of spatial dependence, standard test assumptions may be used. Here, we impose the levels of spatial dependence, and also know the scheme used to do this. With empirical data, we do not know where the spatial dependence is coming from, including the actual footprint of the variables. While sales taxes are determined here by states, neither prices nor transport costs are; they are aggregates.
Hepple [
8] questioned whether the relationships described by Hanna held up when spatial dependence was taken into account. He used the sum of transport costs and sales taxes as the covariate, but we can also use the two covariates directly:

Table 2 shows that the simpler model, summing the costs and taxes, appears to perform less well than the model with two separate covariates. However, we know that transport costs might be offset rather than fitted, so the third model implicitly imposes a coefficient of unity on transport costs. McMillen [
25] stresses the importance of considering whether apparent spatial dependence is in fact engendered by model mis-specification, such as the erroneous inclusion or omission of covariates, and the inappropriate functional form of included covariates.
3.1.2. The Development of the Moran and LM Tests for Spatial Dependence (Error and Lag)
When Cliff and Ord [
26,
27] proposed an extension of the Moran’s
I spatial autocorrelation test for regression residuals, there was already some confusion associated with the choice facing analysts between the spatial error model and the spatial lag model. The test was, like the Durbin–Watson test, based on testing a linear model against an alternative of omitted spatial autocorrelation in the error term.

Table 3 shows that all of the fitted models appear to show significant spatial autocorrelation in the error. Hepple [
8] draws the same conclusion from a similar test, and fitted a spatial error model. This test may also be used when a weighted linear model is used; here no major differences are observed although the level of residual spatial autocorrelatiion is not so strong when counts of cars held by households from the 1960 US Census are used as weights.
Because Moran’s
I for regression residuals gives no guidance in choosing between spatial error and spatial lag models, ref. [
28] and Anselin and Bera [
29] introduced Lagrange multiplier (LM) tests. The re are five tests, a test for residual autocorrelation (LMerr) with a robust version (RLMerr) for error dependence in the presence of spatial dependence in the response, conversely LMlag for an omitted spatially lagged response with RLMlag robust to the simulatneous presence of residual dependence, and the portmanteau test SARMA which is the sum of LMlag and RLMerr or LMerr and RLMlag.

Table 4 shows the conventional probability values for the three models and the five tests. While SARMA, LMlag and LMerr indicate strong autocorrelation mis-specification, the contrasts between the robust RLMerr and RLMlag suggest that models (1) and (2) might be suffering from an omitted spatially lagged response, while the picture for model (3) is unclear. Until the last decade, it has been felt reasonable to use the balance between the robust LM tests as a guide, because the spatial lag and spatial error models are not nested, so cannot be tested against each other using likelihood ratio tests.
3.1.3. Early ML Estimation
The ML estimation methods for spatial lattice regression models grew from developments in Cliff and Ord [
26], soon afterwards refined in Ord [
30]. In these and in [
8,
31], short-cuts were sought but largely rejected, in favour of optimizing the appropriate likelihood function. The implementation in
spdep uses line search over the single spatial coefficient, calculating the other coefficients once that is found. The development in [
26] only addresses the simultaneous autoregressive (SAR) approach, but [
32] and the rich literature based on his work prefers to treat spatial lattice regression in a Markov random field setting (conditional autoregressive, CAR), with spatially structured random effects included in an otherwise aspatial model. Reference [
33] summarizes these developments and relates the SAR and CAR approaches.
The log-likelihood function for the spatial error model is:
may be concentrated out of the sum of squared errors term, for example as:
where
is obtained by decomposing
.
The first published versions of the eigenvalue method for finding the Jacobian [
30] (p. 121) is:
where
are the eigenvalues of
One specific problem addressed by [
30] (p. 125) is that of the eigenvalues of the asymmetric row-standardized matrix
with underlying symmetric neighbour relations
. If we write
, where
is a vector of ones, we can get:
, where
; by similarity, the eigenvalues of
are equal to those of:
. From the very beginning in
spdep, sparse Cholesky alternatives were available for cases in which finding the eigenvalues of a large weights matrix would be impracticable.
The log-likelihood function for the spatial lag model is:
and by extension the same framework is used for the spatial Durbin model when
are grouped together. The sum-of-squared errors (SSE) term in the square brackets is found using auxilliary regressions
and
, and
. The cross-products of
and
can conveniently be calculated before line search begins.
The spatial error model (SEM, Equation (
4)) was fitted to Hanna’s data by Hepple [
8]; here we separate the two covariates, but if estimated using the sum of the two, the
errorsarlm() function yields the same results at those reported in the article. All the model estimation functions from the
spdep package have been split out into
spatialreg [
34], mostly because most users need
spdep for creating spatial neighbour objects and for testing for autocorrelation. A separate model estimation package permits faster development of the model fitting functions without disturbing other work. The model fitting functions follow the structure for R functions of this kind, using a formula interface. The list of weights object is required, and when no method is specified for the computation of the log Jacobian to which we will return later, the eigenvalues of the spatial weights matrix are used [
30].

While each iteration of the line search of SEM involves a regression, the spatial lag model (SLM, Equation (
5)), and the spatial Durbin model (SDM, Equation (
6)) use intermediate values from two pre-computed regressions in each iteration. Again, the implementations use the eigenvalues of the spatial weights matrix to compute the log Jacobian at each iteration. Setting the
Durbin= argument to
TRUE adds the spatially lagged covariates, omitting the lagged intercept when the spatial weights are row standardized.

Table 5 shows the fitted model output as it would have been presented until about 10 years ago. All the spatial models improve the fit of the model compared with the aspatial model in the first column. In addition, a Lagrange multiplier test of the residuals of the SLM for spatial autocorrelation has a probability value of
(SDM:
), neither of which appear to indicate any further spatial patterning. Pace and LeSage [
35] propose a Hausman test assessing whether SEM coefficients are as close to the OLS coefficients as they should be in a well-specified model; the probability value here is
. Had they been more different, one could find that the model was more seriously mis-specified. All of these tests are borderline, so all open for more analysis but do not point clearly in a single direction.
Finally, the examples of spatial regression in Waller and Gotway [
36], using both SAR and CAR approaches, and introducing case weights to try to handle heterogeneity, led to the re-implementation of the spatial error model in the
spautolm() function, which will not be presented here.
3.2. The “Advent” of The GMM
In two seminal papers [
37,
38] suggested a generalized method of moments (GMM) approach to the estimation of a SARAR model (Equation (
8)) and established asymptotic results for the estimator. The main motivation for the success of this approach was, and in part still is, the computational simplicity even for large samples compared to ML. Additionally, at the time the GMM was proposed, one further problem was the lack of formal results concerning the asymptotic properties of ML, that were only derived later in a paper by [
39]. The original approach is based on a three steps procedure:
The estimator described by these three steps is generally referred to as the feasible generalized spatial two-stage least square (FGS2SLS) estimator. One issue to emphasize is that is treated as a nuisance parameter. Basically, the idea is to filter out spatial autocorrelation in the errors that is potentially dangerous for statistical inference on the model parameters, but there is no interest to make inference on the spatial error parameter itself. (In a later unpublished document, the authors demostrated how to compute the variance for the spatial error parameter in order to make inference on it. The GMerrorsar function takes advantage of this and therefore in the demonstration below there will be a standard error for .)
At this point it should be also evident that the nested models (i.e., the SLM, SEM, SDM and SDEM) can be estimated easily by modifyng the three steps described above. On the one hand, in the SEM and SDEM models the first and third steps are simply OLS, since there is not any endogeneity deriving from the presence of the spatial lag of y. On the other hand, the SLM and SDM models can be estimated by 2SLS since the error term is no longer spatially autocorrelated.
There were three separate functions in spdep: stsls for the SLM, GMerrorsar for the SEM, initially contributed by Luc Anselin, and gs2sls for the SARAR model. These functions, along with many others, recently migrated into spatialreg.
The estimation of the lag model, as well as those of the error and SARAR models, of the DUI data cannot use the formula defined in
Section 2, since none of the functions in
spdep allow for additional endogenous variables.

Table 6 reports results for the three implementations. A glance at the table shows that, out of the regressors, only non-alcohol related arrests is not statistically significant. The presence of police force is the larger deterrent to driving under the influence of alcohol. It is also noteworthy that the coefficient estimates are very stable across different models. The value of
for the SLM is higly statistically significant (even though it is quite small in magnitude). The spatial error coefficient
in the SEM model is similar in magnitude, but it is not statistically significant. Finally, the estimated value and inference for
in the SARAR model is (almost) identical to the SLM, while
is smaller than the SEM coefficient estimates and, as we mentioned previously, inference is not available.
An Early Version of sphet
Few years later that the GM approach was implemented in
spdep, [
40] developed a new package for estimating and testing spatial models with heteroskedastic innovations. The library was mainly based on GM estimators and semi-parametric methods for the estimation of the coefficient’s variance-covariance matrix.
sphet was complementing but not overlapping with
spdep. In fact,
sphet focused only on GM and instrumental variables (IV) methods, leaving aside ML, and dealt with potential heteroskedasticity in the error term, features that was only partly taken into account in
stsls. From a theoretical point of view, the procedures implemented in
sphet were derived in [
41,
42]. The point of departure of [
41] was the SARAR model with potential heteroskedasticity in the innovations. A noticeable difference of [
41] is that they gave results for the spatial error coefficient for both consistency and asymptotic normality. Of course, this enabled to perform statistical inference on both spatial parameters. Moreover, the moment conditions were slightly different from their earlier paper, thus leading to a different system of equations, that, in turn, resulted in a different estimates for the spatial error parameter.
The corresponding function in
sphet is called
gstslshet. The syntax of the function is pretty straightforward: the first argument is a description of the model to be estimated, then the optional argument containing the data set, and, finally, the (mandatory) object of class
"listw".

Table 7 reveals that, besides the different moment conditions (that influence the estimated value of
), the model coefficients estimates, including the coefficient of the spatially lagged dependent variable, are very stable. The spatial error coefficient can be tested although, in this case, it is not statistically significant.
Reference [
42] propose a semi-parametric method for the estimation of the coefficient’s variance-covariance matrix that is robust against possible misspecifications of the disturbances and allows for unknown forms of heteroskedasticity and correlation across spatial units (HAC estimation). Instead of assuming a specific spatial structure for the error term, they assume a general form that nests many different spatial processes such as spatial autoregressive or spatial moving average. The rationale behind this idea is that the error term, being the unknown part of the model, should not be specified a priori in terms of a specific spatial process, but rather assume a very general flexible form. However, the spatial HAC estimator is not immune from possible criticisms related to the type of kernel and the bandwidth selection. If the decision about the kernel choice has been proven not to be very relevant in that different kernels lead to negligible differences in practical applications, the same does not apply for the bandwith.
The function to produce the 2SLS with HAC standard errors available from
sphet is
stslshac. The procedure is based on the choice of a distance function that along with a kernel determines the non-zero observations in the variance-covariance matrix.

Clearly, the results of the estimated coefficients in
Table 8 are not different from those obtained using the
stsls in
spatialreg. The table reports two standard errors (second and third columns): For each coefficient, the second column has the usual 2SLS standard error, while the third is produced with the HAC. Interestingly, the differences in standard errors do not change the overall conclusions that all but one variable are statistically significant.
3.3. Further Development in R: The spdep Package and the Improvement of sphet
When [
43] was published, the treatment of spatial econometrics covered the available software implementations in
spdep. LeSage and Pace [
2] appeared shortly afterwards, significantly “raising the bar” as expressed by Elhorst [
44] in an extended review. Reference [
45] discussed in detail both how to estimate an extended range of nested models using ML, and how to handle model interpretation, pursuing topics presented in Halleck Vega and Elhorst [
46] and LeSage [
47].
Work began in 2019 to split model fitting functions out from the spdep package, moving these components to the new spatialreg package. At about the same time, Bayesian fitting methods were added, based on porting of MATLAB Spatial Econometrics Toolbox code carried out by Virgilio Gómez-Rubio and Abhirup Mallik.
At the same time, the theoretical development of the generalized methods of moments in spatial econometric models was flourishing and gave rise to many important contributions. This corresponded to a series of major revisions of sphet, and, in particular, the inclusion of the wrapper function spreg. We will turn to this after describing the evolution of the ML estimation in the next subsection.
3.3.1. Evolution of the ML Estimation
Bivand et al. [
48] review the technical issues around the calculation of the log Jacobian term in ML and Bayesian model estimation. It had been established from the mid-1990s that sparse matrix decomposition (Cholesky for symmetric weights matrices and LU for intrinsically asymmetric weights matrices) was feasible [
49,
50]. This was extended to cover the initial decomposition step in sparse Cholesky decomposition, which does not need to be repeated to look up log Jacobian values for successive values of the spatial coefficient.

Gomez-Rubio et al. [
51] also show that these kinds of models may be estimated using integrated nested Laplacian approximation, yielding estimates of
n spatially structured random effects over and above the spatial coefficient itself. The domain of the spatial coefficient is transformed internally to
, so the bounds of the domain need to be known or calculated; here the extreme eigenvalues were previously calculated when fitting with ML and the eigenvalue-based log Jacobian.

Table 9 shows clearly that the coefficients of the covariates are very much the same for all estimation methods. The values of
differ a little, but all of those based on the likelihood are very close. For comparison of estimation methods, the standard error of
is more interesting. When eigenvalues are used to compute the log Jacobian, it is assumed that the data set is small enough to compute the asymptotic variance-covariance matrix of the coefficients. The estimated value in this case matches those from MCMC and INLA very well, but when the sparse Cholesky is used for the log Jacobian, inverting
is not attempted, and a finite difference Hessian approach is tried instead. This may lead, as in this case, to there being marginally negative values on the diagonal of the estimated variance-covariance matrix, leading to failures when taking square roots. Problems with estimating the variance-covariance matrix can also occur in general when the scaling of the spatial coefficient and the remaining coefficients differ greatly. In this case the problem may be avoided by dividing the response by 1000, but the introduction of sensitivity tests to the poor conditioning of these matrices may be required. The standard error of
seems to be estimated well by MCMC and INLA. The likelihood ratio test on
return the same probability value in both the eigenvalue and sparse Cholesky cases, however, so resolving numerical issues in the variance-covariance matrix has not been seen as critical, although it also impacts the Hausman test as well.
Turning to the timings reported in
Table 9, the set up times for the ML eigenvalue method, involving finding the eigenvalues of
, and for MCMC conducting many LU decompositions for a coarse grid of values of the spatial coefficient to prepare for griddy Gibbs sampling, are longer than for the other estimation methods. Fitting for INLA is much longer because the
n random effects are computed as coefficients, so that the dimensionality of the problem is bigger. MCMC here took 2500 draws only, discarding the first 500; more draws would increase the run time. Completion for the ML eigenvalue method includes the calculation of the asymptotic variance-covariance matrix of the coefficients, which could be speeded up somewhat with multi-threaded linear algebra.
There are a number of loose ends in the implementations, especially where numerical issues can appear, or where approximations lead to degradations when the spatial coefficient is near the extremities of its domain.
3.3.2. Interpretation and Impacts Evaluation
A fuller comparative treatment of model interpretation and the calculation of impacts is given by Bivand and Piras [
52]. Difficulties arise from interaction between the spatial dependence modelled in the response, parameterized as
and the coefficients on the covariates.
Here, we run into trouble with: , and rewriting: , and: , with the interaction between the coefficients in when potentially causing confusion unless clearly motivated.
As observed before, in the spatial lag mode—unlike the spatial error case—the spatial dependence in the parameter
feeds back. These difficulties are discussed as emanating effects [
53], also known as impacts [
2,
54], simultaneous spatial reaction function/reduced form [
55] and equilibrium effects [
56].
This feedback comes from the fact that, while the elements of the Hessian matrix for the ML spatial error model linking and are zero (), in the spatial lag model (and by extension in the spatial Durbin model): . In the spatial error model, for exogenous variable r, and for . In the spatial lag model, , where is the identity matrix, and is known to be dense. The awkward matrix term needed to calculate impact measures for the lag model, and for the spatial Durbin model, may be approximated using traces of powers of the spatial weights matrix as well as analytically.
The average direct impacts are represented by the sum of the diagonal elements of the matrix divided by n for each exogenous variable. The average total impacts are the sum of all matrix elements divided by n for each exogenous variable. The average indirect impacts are the differences between the direct and total impact vectors.
The development for approximation using traces of powers of the spatial weights matrix in [
2] (pp. 114–115) for the lag model and
q traces is as follows:
where the intercept
is dropped, and with
a
p-vector of ones:
Let us revert to the smaller used car data set, and show the important difference between predictions from the OLS model for the base data set and a new data set with the transport cost variable incremented by one:

and the spatial lag model (SLM):

In the OLS case, the mean difference between the predictions is (of course) the value of the coefficient for the transport cost variable. In the SLM case, is far from zero, so the feedback is strong, and the difference between predictions is much larger than the coefficient value.
If we pick apart the model output, we can calculate the
matrix for the transport cost variable, and see that the mean difference between predictions is the average total impact:

We can further check that the average direct and total impacts calculated in this way match the values returned by the
impacts() method, when the spatial weights matrix is inverted inside the method:

When the eigenvalues of the spatial weights matrix are used, the results are identical.

However, these methods do not scale to larger data sets, so the traces of the power series of the spatial weights matrix may be used instead, noting a minor degradation in accuracy caused by the limited length of the power series
q (here argument
m=):

The eigenvalue and trace methods make it possible to conduct Monte Carlo tests on the impacts using draws from the fitted model coefficients and their variance-covariance matrix.
3.3.3. Evolution of the GMM and Recent Developments
The theoretical development of the generalized methods of moments in spatial econometric models has been flourishing over the last 15 years. Many important scholars in the field got involved and major commercial software (like, for example, Stata) started implementing codes to estimate the techniques that were under development. In this context, [
52] presented a comparison of the implementations available for spatial econometric models. In the meanwhile,
sphet had gone under a process of serious revisions that culminated with the inclusion of the wrapper function
spreg. Specifyfing a
model argument,
spreg allows to estimate all of the specifications nested in the general model of Equation (
1). The re are mainly two advantages of GMM compared to ML: On the one hand, GMM can deal with very large sets of data since it does not require inversion of large matrices. On the other hand, dealing with additional (other than the spatial lag) endogeneous variables is simple, provided that one has proper and valid instruments.
For the DUI data, the size of the
police force is most likely related with the alcohol-arrest rates. The refore,
police can be treated as an endogenous variable. As we anticipated earlier, ref. [
12] also assume that the dummy variable
elect (where elect is 1 if a county government faces an election, 0 otherwise) make a valid instrument for
police.

Table 10 compares the SEM, the SLM, and the SARAR models with the corresponding models assuming that police force is endogenous.
Let us focus first on the three models with no additional endogeneity. While the SLM is the same as the one presented in
Table 6, the SEM and the SARAR models are sligthly different since
spreg uses different moment conditions. Despite this fact, results are very close to the one presented before and similar conclusions can be drawn. In particular, the spatial error parameter is not statistically significant, while the positive spatial lag coefficient is small but strongly statistically significant. This means that the DUI related arrests in neighbouring counties affects the alcohol related arrests for a given county. This result can be explained in terms of copycat policies or a certain level of coordination in police enforcement between counties. In terms of the explanatory variables in the model, nondui is the only one that is not statistically signicant. The estimated coefficient for police is large and positive in all three models. Moving to the specifications that treat police as endogenous the results are quite different particularly in terms of the magnitude of the coefficient estimates. Moreover, police turns out to be negative once endogeneity is controlled for. Two additional things have to be noted. The first relates to the SARAR model. The summary method for SARAR models automatically performs a Wald test that both
and
are statistically significant. The second relates to the SLM as well as to the SARAR model. Once again for models that are specified in terms of a spatial lag of the dependent variable appropriate summary measures needs to be used to take into account for simultaneity. This is the reason why appropriate spatial effects are calculated for the SAR and SARAR models. However, when additional endogenous variables are present, the calculation of the impacts is quite complicated. Ref. [
57] show how to approximate that calculation but since is very case specific, it has not been implemented (yet) in
sphet.
4. Spatial Panel Data Models
The econometric literature has considered panel regression models with spatially autocorrelated outcomes or disturbances and random or fixed individual effects for more than three decades now.
The pioneering book of Anselin [
1] and the famous Econometrica paper of Case [
15] have introduced the subject to a large audience. The former reserved a minor part of a book-length treatment to the SEM model in a random effects setting, while the second applied a comprehensive spatial panel data framework to the empirical analysis of rice production in Indonesia, a subject panel data econometricians would come back to in more recent years. Nevertheless, few spatial panel data applications have followed, mainly because of the computational difficulties and the lack of ready-made, user-friendly software.
The more recent methodological contributions by [
58,
59] and the first comprehensive treatments of the subject in [
60,
61] have further helped the diffusion of spatial panel methods in applied practice, this time helped by the circulation of the first general-purpose routines, written in MATLAB by J. Paul Elhorst and kindly provided for public use by the author.
Nevertheless, the number of empirical applications has constantly trailed that of theoretical developments in this particular subject. Although clearly written, well tested and not difficult to adapt to one’s problem, Elhorst’s MATLAB routines were still primarily written for the author’s own use; moreover, if the specific routines were provided free for general use, MATLAB was, and is, non-free. The availability of estimators and tests of production-quality usability (i.e., devoting much of the functionality to data and modelling interfaces, results’ presentation and consistency checks) within an open source environment would boost the number of spatial panel applications in the empirical literature. This happened with the emergence of the dedicated R package
splm described here (see [
62]); and, some years later, with the Stata add-on package ’xsmle’ [
63] (in this latter case, while the package is provided in the open domain, the base software system is not; still, Stata is a
de facto standard in econometrics and most researchers are likely to have access to a copy).
4.1. Static Spatial Panels
Spatial panel data models capture spatial interactions across spatial units observed over time. A general static panel model includes a spatial lag of the dependent variable and spatial autoregressive disturbances:
where
is an
vector of observations on the dependent variable,
is a
matrix of observations on the non-stochastic exogenous regressors,
an identity matrix of dimension
T,
is the
spatial weights matrix of known constants whose diagonal elements are set to zero, and
the corresponding spatial parameter. The disturbance vector is the sum of two terms
where
is a
vector of ones,
an
identity matrix,
is a vector of time-invariant individual specific effects and
a vector of spatially autocorrelated idiosyncratic errors that follow a spatial autoregressive process of the form
with
as the spatial autoregressive parameter,
the spatial weights matrix and
. The spatial weights matrices in the lag and the error term can differ (see the following).
is assumed non-singular.
The spatial panel model described above draws on panels of n data points observed over T time periods. Contrary to standard panel data practice, data are stacked by time, then by cross-section (so that the individual index is the “fastest” one). The spatial weight matrix is assumed time invariant, as customary in the literature, and enters spatial panel models as where ⊗ is the Kronecker product. In the following, the models are illustrated based on the Rice Farming data.
The Pooled Spatial Model
If one could safely assume out any individual heterogeneity, spatial panels could be estimated by simply applying cross-sectional estimation techniques to the pooled dataset, employing an extended
matrix as specified above. This hypothesis, nevertheless, is extremely unlikely to hold. Below we estimate the pooled model; results will be reported later, comparing them to those considering individual effects.

4.2. Tests
In principle, spatial correlation in the residuals of panel models can be tested through a Moran test, treating all observations as a pool and employing a panel extension of the neigbourhood matrix, where as discussed above . This approach nevertheless depends on the pooling assumption, i.e., assuming out any form of individual effect: which is inappropriate in the vast majority of cases. Specific test statistics have therefore been devised for spatial panels.
4.2.1. LM Tests
The Lagrange multiplier (LM), or score, test procedure on verifying whether the score of the likelihood of a restricted model is significantly different from the zero vector. If this is not the case, then the restriction is not binding w.r.t. the problem at hand and the corresponding null hypothesis is not rejected. Differently from its siblings, the asymptotically equivalent Likelihood Ratio and Wald tests, the LM test only requires to estimate the restricted model, therefore is often the procedure of choice in econometrics because of its computational parsimony, especially when estimation of the unrestricted model is complicated, costly or even problematic.
Since the seminal work of [
64], LM tests have been extensively employed to test for random effects and serial or cross-sectional correlation in panel data models. For the above reasons, LM tests are particularly appealing in a spatial random effects setting because estimates for the full model are often much more difficult to compute than those for the restricted one.
Conditional and Joint Tests for Spatial or Random Effects
Building on the earlier literature, ref. [
59] have extended the ML-based testing framework deriving joint, marginal and conditional tests for all combinations of random effects and spatial correlation. While the marginal tests are those already known, and the joint test is of little practical value because it will be a signal either of spatial or random effects without giving directions regarding which one is actually present, the conditional tests are particularly important because they allow to test for one of the two effects allowing for the presence of the other. The comparative disadvantage of conditional tests is that their implementation is slightly more complicated as being based on the ML residuals from the model containing the “other” effect–the one the test is conditional on–instead of on OLS residuals.
Specifically, the hypotheses under consideration are:
under the alternative that at least one component is not zero
(assuming = 0), under the one-sided alternative that the variance component is greater than zero
assuming no random effects (), under the two-sided alternative that the spatial autocorrelation coefficients is different from zero
assuming the possible existence of random effects ( may or may not be zero), under the two-sided alternative that the spatial autocorrelation coefficient is different from zero
assuming the possible existence of spatial autocorrelation ( may or may not be zero)and the one-sided alternative that the variance component is greater than zero.
In the following we compute the full suite of tests from the [
59] paper:

The presence of both spatial error dependence and random effects are confirmed, the spatial effect giving rise to the “most forceful” rejection.
Local CD Test
An alternative testing procedure from the heterogeneous panel literature can be applied to homogeneous panels as well, containing either fixed or random effects. This is based on a particularization of Pesaran’s ([
65]) CD test for global spatial dependence. The CD test is based on an average (across the sectional dimension) of sample estimates of the pairwise correlations of residuals of the separate (timewise) regressions for every cross sectional unit:
The CD test is asymptotically standard Normal distributed under the null of no cross-sectional correlation; moreover, it does not depend on the heterogeneity assumption. In general, residuals from any appropriate model (pooled, FE, RE) can be employed.
A variant of the
test, called
test, has been designed to test for
local cross-sectional dependence, i.e., dependence between neighbours only: in other words, for
spatial dependence. It works by considering only the subset of “neighbouring” pairs of cross-sectional units, selected by means of the familiar binary proximity matrix. Originally, a regular ordering of observations was assumed, so that the
m-th cross-sectional observation was a neighbour to the
-th and to the
-th. Reference [
66] first extended the application of the
test to an irregular lattice. The formula for the local test is an adaptation of the original
statistic where, as observed, the binary proximity matrix is employed as a selector for discarding the correlation coefficients relative to pairs of observations that are not neighbours (corresponding to zeros in
):
where
is the
-th element of the
p-th order proximity matrix, so that if
are not neighbours,
and
is canceled out. Both the global (i.e., non-spatial) and the local CD tests have been available since 2008 in the
plm package [
67]. In the following we compute the local CD test on the residuals of the random effects panel model:

Again, spatial dependence is clearly present regardless of which kind of individual effects, if any, are included.
4.2.2. Individual Effects: Fixed or Random
The spatial panel data literature, following the mainstream non-spatial approach, distinguishes between treating the unobserved individual effects as fixed or random. In a random effects specification, these are assumed uncorrelated with the regressors, so that they can be safely treated as components of the error term: see, e.g., Assumption RE.1.b in Wooldridge [
68] (10.4). Should this hypothesis not hold, then the latter strategy would introduce endogeneity and produce inconsistent estimates; the individual effects would either have to be estimated out or, which is more often the case, eliminated by first differencing or time-demeaning the data (see [
68] 10.5). The standard device for assessing the hypothesis of no correlation (i.e., for testing the appropriateness of random effects methods), is the Hausman [
69] test. In a spatial setting, Mutl and Pfaffermayr [
70] derived an appropriate Hausman test for spatial panels.
From another viewpoint, the random effects hypothesis is considered consistent with sampling individuals from a potentially infinite population. for this reason Elhorst [
61] dismissed its practical utility in spatial econometric contexts, where sampling typically takes place over a fixed set of countries or regions.
4.3. ML Estimation
For all the popularity of either the SAR and the SEM specification, econometric practice generally focuses on one effect only. With an exception made for the pioneering work of [
15], few applications in the literature allow for both. Nevertheless, the expression for the likelihood of a model combining a spatial lag with any error structure
, including spatial dependence ones, is easily written as a panel version of the general likelihood in Anselin [
1]:
As such, the spatial lag model can be estimated combining the SAR filter with any spatial or non-spatial structure, e.g., random effects:

4.3.1. Individual Effects and Spatial Errors
What differentiates the panel estimators from their cross-sectional counterparts is their ability to deal with the individual effects. In the MATLAB routines due to [
58], which have long been the de facto standard in the econometric analysis of spatial panel data, the partial time-demeaning technique familiar from standard panel data (see, e.g., [
68] Ch. 10) is combined with Anselin’s ML framework: the data are either time-demeaned (FE) or partially time-demeaned (RE) in order to eliminate the individual effects, then standard SAR or SEM estimators are applied to the transformed data (see [
61]).
Computationally, the fixed effects case is simpler, being encompassed by the pooled case: fixed effects models are generally estimated by pre-demeaning the data, according to the framework described in Elhorst [
58]. This procedure has been criticized by [
60] because time-demeaning alters the properties of the joint distribution of errors, introducing serial dependence: ([
71] p.257) also discuss the issue; see also [
62] (p.33) for Monte Carlo evidence of the magnitude of the bias. [
72] (3.2) suggest to either correct the estimates ex post or to circumvent the problem using a different orthonormal transformation of the data. The current implementation in
splm can perform the Lee and Yu correction.
In the random effects case, following [
58], to estimate the SARRE model one can add spatial filtering on
using
and the determinant of the spatial filter matrix,
, to the likelihood of the random effects model. Concentrating the likelihood with respect to
and
as
where
is the quasi-demeaning parameter and the residuals
are those of the demeaned model with a spatial filter on
and maximizing it w.r.t.
and
; then iterating until convergence between this maximization and the GLS step, whose first order conditions are
yields an efficient two-step estimation procedure.
The transformation procedure for the SEM model (which employs a spectral decomposition of the errors covariance) is omitted here: see [
58] (pp. 19–21). Although not explicitly stated by the author, [
58]’s methodology is also easily extended, by combination, to the SAREM specification (for an application see [
73]); on the other hand, it does not lend itself as easily to extensions in the direction of serially correlated errors (see the following).
The implementation in
splm works instead on untransformed data and approaches random effects together with any other feature of the error covariance, spatial dependence included [
74]. This has the advantage of keeping some components of the error term (most notably, the random effects) out of the spatial dependence, which can remain a feature of the idiosyncratic error only, as in most applications in the literature (see, e.g., [
44,
58,
59,
60,
61,
70,
71,
72,
75,
76,
77,
78,
79,
80,
81,
82,
83,
84,
85]) but entails some computational complications. The alternative specification where the individual effects follow the same spatial process as the idiosyncratic errors, as in [
86], which is also considered below, is much easier to compute.
4.3.2. Fixed Effects
Consistently with the conventions of the standard panel package
plm, the most robust specification—the FE—is the default choice in the estimator function:

Spatial error correlation is remarkably high, as expected. What about spatial lag correlation? In his seminal papers which laid the foundations for practical estimation of spatial panel data models both under the fixed and the random effects assumptions, [
58,
61] does not consider combinations of spatially lagged response and spatially autocorrelated error term; while the original contribution of Case [
15] did. With
splm it is indeed possible to estimate a model containing both effects to assess the significance of each through a Wald test. We only report estimation results for the relevant coefficients:

The results confirm the relevance of the spatial error process, while the spatial lag is only marginally significant.
4.3.3. Independent Random Effects
The Rice Farms dataset, with observations coming from a large number of small villages employing the same standard technology, is a good candidate for a random effects analysis, perhaps after controlling for the region (which itself is likely to be a source of systematic differences in soil quality and climate).
Two kinds of random effects specifications are possible in spatial error panels: one where the spatial process in the error includes the random effects, the other where the individual random effects are idiosyncratic and independent of the neighbours’ ones. In the latter case,
, and the error term can be rewritten as:
where
. As a consequence, the composite error term becomes
and its variance-covariance matrix, if
is a
matrix of ones, is
The hypothesis of independent random effects is the most natural to assume in many cases, including the one at hand; the idea being that random shocks, possibly related to weather, economic or health conditions, are likely to affect farms within the same village; while the individual heterogeneity captures the persistent random differences between individual farms in terms of soil quality or ability of the farmers.

The estimated variance of the random effect is small in proportion of that of the idiosyncratic error (about one fifth); the spatial error correlation is confirmed as very strong.
4.3.4. Spatially Correlated Random Effects
The specification for the disturbances of [
86] assumes that spatial correlation applies to both the individual effects and the idiosyncratic errors. Although the “Baltagi” and “KKP” data generating processes look similar, they do imply different spatial spillover mechanisms. The economic meaning of the two models is also different: in the first model only the time-varying components diffuse spatially, in the second spatial spillovers too have a permanent component [
76]. Reference [
87] (see also 2.4) on the difference between these two RE specifications. In this latter case, commonly referred to as “KKP”, the composite disturbance term
follows a first order spatial autoregressive process of the form:
Then the variance-covariance matrix of
is:
where
is the typical variance-covariance matrix of a one-way error component model.
It is not obvious why the spatial process should carry over to the individual effects in the case of the Rice Farms data; although one plausible hypothesis is that if the random individual heterogeneity is related to the quality of soil or to the working ability of the farmers—perhaps through tradition and cultural affinity—then one might see this as leading to a spatial process in the individual effects as well.

The practical difference between the two approaches turns out to be quite small. Again, models containing both a spatial lag and a spatial error (plus individual effects) can be estimated:

the encompassing models’ results confirming the preference for a spatial error specification, given that the spatial lag coefficient is not significant.
4.4. Serial and Spatial Correlation
Serial correlation in spatial panel data has long been overlooked, if not for the very special case of persistent random effects. Nevertheless, if autocorrelation of the autoregressive type were present it would bias ML estimates, and may be a symptom of more serious misspecification: unit roots or missing dynamics. Ref. [
75] further generalized the structure of the errors, introducing serial correlation in the remainder of the error term together with the spatial correlation and random effects. They derived a number of LM tests for the different effects, either marginal (i.e., assuming the other effects out) or conditional (i.e., allowing for their presence). The general model is:
While the marginal tests are already established testing procedures in the literature, the main contribution lies with the three-way joint test J and the one-way conditional tests C.1-3. The hypotheses under consideration are:
under under the alternative that at least one component is not zero (J)
, assuming : test for spatial correlation, allowing for serial correlation and random individual effects (C.1)
, assuming : test for serial correlation, allowing for spatial correlation and random individual effects (C.2)
, assuming : test for random individual effects, allowing for spatial and serial correlation (C.3)
An early application of the
conditional test for spatial correlation in RE panels with serially correlated errors, based on a prototype of the R code, appeared at the same SEA conference as the [
75] paper and was later published as (see 0.290 [
66]). Production versions of the test resulted in the function
bsjktest with J and C.1-3 appearing in the new
splm package for R [
62].
In the following we illustrate a possible specification search based on performing the joint test—which will obviously reject—and, most importantly, all three conditional tests from the [
75] paper, which will give indications on whether any of the three possible effects (random, serial or spatial) is absent:

Although all three the conditional tests reject, the p-values make it very clear that the strongest effect is the spatial correlation, then the individual heterogeneity; lastly, there is also evidence of serial correlation but this is much weaker.
4.5. Endogeneity in Static Panel Data Models
As we mentioned early, the initial contribution to the application of GM methods for spatial panels dates back to [
86]. The y considered a panel data model involving a first order spatially autoregressive disturbance term that, in turn, allowed for an error component structure in the innovations. The proposed methodology was based on an extension of the moment conditions put forth from the same authors in the context of a cross-sectional model. A few years later while considering a spatial panel version of the Hausman test, ref. [
70] extended the estimation procedure to a Cliff and Ord type model including the spatial lag of the dependent variable as well as a spatially lagged one-way error component model. The y implemented instrumental variables estimation under both the fixed and the random effects specifications. However, Piras [
88] noted that they were not taking full advantage of the six moment conditions derived in [
86] since they were using only a subset of those moment conditions.As a consequence, ref. [
88] suggested an improvement that included all six moment conditions in [
86]. The approach taken by [
88] followed more closely the fixed and between effects two stage least squares estimator for spatial panel models proposed by [
89]. (This was in turn an extension of the [
90] error component 2SLS estimator to a spatial panel model.) The function
spgm implements the procedure described in [
88] with the extra feature of considering additional (other than the spatial lag) endogenous variables.
Table 12 compares results from the “classical" error component two stage least square (EC2SLS) in [
90] and the spatial version of the EC2SLS. The first model can be obtained by setting both
lag and
error arguments to
FALSE and specifying endogenous variables along with instruments. To obtain the second model the user has to include both spatial lag and error parameters. The data set to produce
Table 12 where presented in
Section 2.4 and relates to an economic model of crime estimated by [
17]. Keep in mind that [
17] had a genuine concern about the endogeneity of police per-capita ad the probability of arrest. The refore, those two variables are instrumented using per-capita tax revenue and a mix of different types of offense. The spatial lag parameter at the bottom of the second column in
Table 12 is positive and statistically significant and then justifies the spatial specification. The spatial connection are driven from the fact that counties with high (low) levels of crime are generally clustered. This may be due to some sort of copy-cat policies occurring within the counties.

6. Conclusions
This paper was dedicated to a review of the functionality for spatial econometric methods available in the R system for statistical computing, in the light of the historical developments of methods, mostly following a chronological order and hinting when appropriate at implementations in different software environments. It addressed estimators and tests for: spatial econometric models on cross sectional data, both based on ML and on GM; spatial panel models with either correlated or independent unobserved heterogeneity; spatial panel models with possibly endogenous explanatory variables. The methods have been presented through empirical examples based on four well-known and historically relevant datasets. At the end of the paper, several active areas of development are hinted at.
Although some specific areas of spatial econometric modelling have been covered in recent books—cross-sectional methods in [
3] (Appendix B), panel data in [
138] (Ch. 10)—this is the first comprehensive review addressing the development of spatial methods in R in a historical perspective and trying to cover all relevant functionality in both the cross-sectional and the panel domain.
R is considered the lingua franca of statistical computing. As such, most available statistical functionality is available under form of R packages, including very powerful optimization features. Moreover, the R system offers a wide range of tools for dealing with spatial data, including mapping and automated computing of spatial weights. Therefore, although there are several other viable and powerful options, R is arguably the ideal development environment for spatial regression modelling. Finally, two aspects that need to be taken into consideration are that R, unlike other software, is open-source and cross-platform.
The R infrastructure described in the paper is entirely open source and packaged into the standard, user-friendly and documented packages so that it is ready for the perusal of empirical researchers. The paper itself is entirely replicable in its computational aspects, based on open source code and data from the R project. As such, it complies with the reproducibility requirements of Peng [
139], the “gold standard of full replication”, as providing “a detailed log of every action taken by the computer” which can be reproduced by anybody on any system.



















 and the spatial lag model (SLM):
and the spatial lag model (SLM):














 the encompassing models’ results confirming the preference for a spatial error specification, given that the spatial lag coefficient is not significant.
the encompassing models’ results confirming the preference for a spatial error specification, given that the spatial lag coefficient is not significant.











{kind=link}
{kind=link}
{kind=link}
{kind=link}