1. Introduction
Group decision-making (GDM) is concerned with choosing the most adequate option among several potential options. While a straightforward strategy for solving a GDM problem is to reach a decision without the agreement of the participants, a more inclusive one consists in making a decision with a general agreement among them [
1]. Since a unanimous agreement might be difficult to reach, a partial agreement may be preferable to make a decision [
2,
3,
4]. The level of agreement is expected to be higher in cooperative environments. Scientific or medical decisions where participants are willing to share their knowledge are examples of such environments [
5,
6,
7]. In contrast, lower levels of agreement are expected in non-cooperative environments where participants are reluctant to share their knowledge (e.g., political or economical decisions) [
5,
8,
9]. In situations where some participants have more expertise than others, the agreement on the decision might be highly influenced by the expertise of such participants [
10,
11,
12].
Bearing in mind that participants of a GDM problem might have access to multiple sources of information [
1,
13,
14,
15], models that manage homogeneous [
16,
17,
18] and heterogeneous information [
13,
19,
20,
21] in GDM can be found in the literature. Models handling homogeneous information often represent the attribute values characterizing the options through a single domain (e.g., numerical, interval-valued or linguistic domain). In contrast, models handling heterogeneous information usually transform different domains into one to handle those values [
19]. Nevertheless, a single domain does not guarantee an agreement on which aspects or attributes of the options should be considered in their evaluation. This is the case when a heterogeneous group of participants, i.e., participants having different levels of knowledge, areas of expertise and personal backgrounds, differ in their opinions [
22]. For instance, consider an editorial team, consisting of an agronomist, an economist and an editor, trying to reach an agreement on the articles (potential options) to be published in a special issue on ecological and safe transport of agricultural products. The agronomist might focus on aspects (attributes) like agricultural crop categories (‘soil’, ‘wheat’, ‘corn’, etc.) during the evaluation of the articles. The economist might pay attention to aspects like ‘costs’ and ‘delivery time’. Finally, the editor might focus on aspects like ‘originality’, ‘relevance’ and ‘linguistic quality’.
A modular approach to handle heterogeneous information has been proposed in [
23]. In that approach, the participants may carry out their own selection of attributes to perform their evaluations. However, this approach does not consider situations where the participants share their attributes to solve a GDM problem. Such a situation has been studied in [
24]. In that work, the authors define a flexible attribute-set group decision-making (FAST-GDM) problem in which the participants may be suggested to refocus their attention on a shared collection of attributes that were initially observed by some persons, but unobserved by others.
In FAST-GDM two processes can be identified: a consensus reaching process (CRP) and a selection process (SP). During the CRP, the participants try to agree on the most suitable option(s) with a satisfactory level of consensus [
1,
25,
26]. If a satisfactory level of consensus is reached, a SP starts by selecting the option(s) according to the preferences of the participants [
14,
16]. To quantify the level of consensus in a CRP, a moderator can be supported by indices, e.g., a concordance index between the evaluations given by the participants [
27]. In the case of FAST-GDM, the usability of several theoretical concordance indices has been studied in [
28].
Designing CRPs for the participants to perform evaluations with a high level of consensus in FAST-GDM is a key challenge. To address this challenge, a novel variant of the CRP proposed in [
24] is described in this paper. The variant, called flexible attribute-set consensus reaching by exchange of the most influential samples (FAST-CR-XMIS), aims at increasing the level of consensus by additionally exchanging the most influential samples identified by the participants (experts or non-experts) during the evaluation process. Such samples are well-known by the participants according to their individual experiences and are regarded as relevant cases to put the evaluated options in context. For instance, if the above-mentioned agronomist might recall an old article included in a previous special issue on ecological and safe transport of agricultural products, which is intrinsically connected to a new article. The agronomist might then use the old article to contextualize the evaluation of the new article. In this regard, the idea behind FAST-CR-XMIS is that, after exchanging the most influential samples, the participants’ understandings about the problem will become better attuned to each other and, thus, the collective level of consensus will be increased.
To model and handle the previous idea, a mathematical framework based on augmented intuitionistic fuzzy sets (AIFSs) [
29] is used within FAST-CR-XMIS. As will be shown in the next section, the FAST-GDM problem is mathematically modeled using this framework. Thus, FAST-CR-XMIS makes use of this framework to, e.g., quantify the level of consensus among the evaluations performed during a CRP.
In addition to increasing the level of consensus, a key advantage of FAST-CR-XMIS is that it may be used to perform recurrent CRPs, where a particular group (or panel) of participants is established to carry out periodic evaluations in a given GDM problem. In this case, since the participants’ understanding about the problem will become better attuned to each other after the first CRP, forthcoming CRPs are expected to be even more efficient.
To show how FAST-CR-XMIS works, a computerized simulation of a CRP in which a given number of participants try to reach an agreement on the category of newswire stories is presented in
Section 4. Before, in
Section 2 the definitions and formal notations that are used throughout the paper are introduced. Next, a comprehensive explanation of the novel FAST-CR-XMIS algorithm is presented in
Section 3. The results of the simulation are presented in
Section 5 and a discussion about these is presented in
Section 6. Finally, the paper concludes in
Section 7 with some future research directions.
2. Preliminaries
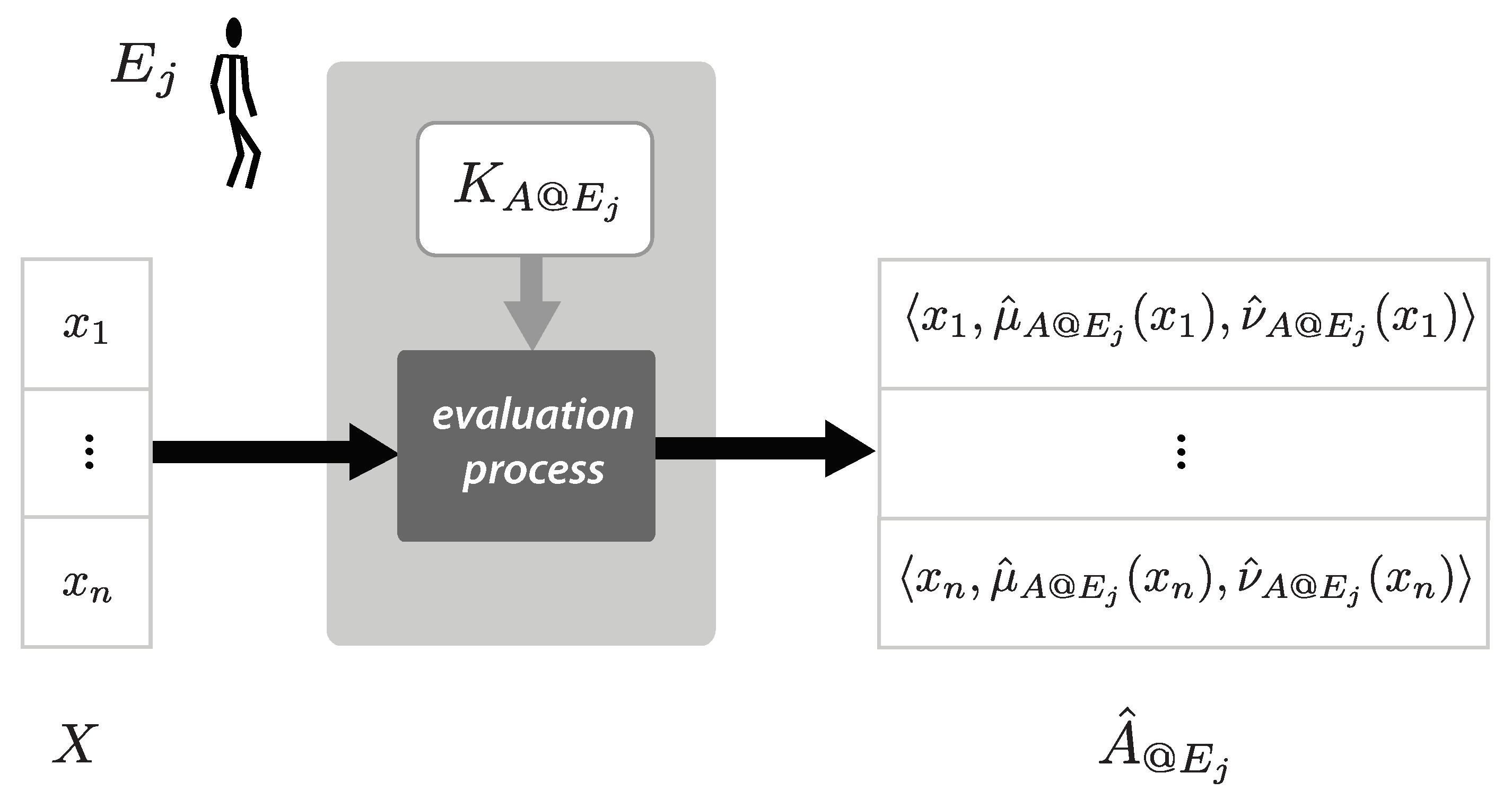
As has been mentioned above, group decision-making is usually understood as a process by which a group of experts (Since participants in GDM are considered to have some expertise on the subject under discussion, hereafter the term ‘experts’ is used for referring to them.) try to reach a collective decision about potential solutions for a particular problem. During that process, each expert evaluates the potential solutions, called options, according to his/her knowledge or experience. Mathematically, such evaluations can be described as follows:
Consider a discrete collection consisting of the potential solutions for a given problem, as well as a collection consisting of the suitable options for this problem. Consider also a collection representing a group of experts who have been asked to evaluate the level to which each option satisfies a proposition p having the canonical form ‘ IS A’ meaning is member of A and hence is considered a suitable option.
In the framework of fuzzy set theory [
30], the evaluation of the level to which
satisfies
p performed by an expert
can be characterized by a membership grade
, which is a number in the unit interval
where 0 and 1 respectively represent the lowest and the highest membership level. Hence, the evaluations of the options performed by
can be denoted by a fuzzy set of suitable options, say
, such that
Notice that, in this framework the evaluation of p is considered as being a matter of degree, i.e., the evaluation of p is not limited to the lowest and the highest membership levels, but all the values in between.
In circumstances where
hesitates about the level to which
satisfies
p, such an evaluation can be better described in the framework of intuitionistic fuzzy sets (IFSs) [
31,
32]. In this framework, the evaluation can be characterized by an IFS element
, in which the components
and
respectively represent the levels of membership and nonmembership of
to the IFS
. Thus, the evaluations performed by
can be denoted by an IFS, say
, such that
where
represents the consistency condition. A hesitation margin defined by
has been proposed to represent the hesitation of
during the evaluation of the membership and nonmembership levels [
31,
32].
In situations where a heterogeneous group of experts try to find a collective decision, experts might like to express not only the level to which
satisfies
p, but also the reasons justifying that level. That is, experts might like to perform contextualized evaluations of
p. Such contextualized evaluations can be described in the augmented framework proposed in [
29]. In this framework, a contextualized evaluation of the level to which
satisfies
p carried out by an expert
can be characterized by an augmented appraisal degree (AAD). An AAD, say
, is a pair
, whose components denote the level
to which
satisfies
p, as well as the particular collection (More specifically this collection might be represented by a list, a set, a multi-set, among others.)
of the
’s features that have been relevant to the evaluation according to the knowledge about
A possessed by
, further denoted by
.
The augmentation of IFS elements by means of AADs has also been proposed in [
29]. An augmented IFS element
consists of both a membership AAD
and a nonmembership AAD
. While the meaning of
is the same as described above,
is a pair
whose components denote the level
to which
dissatisfies
p and the collection
of the
’s features considered by
for quantifying the nonmembership level. Hence, the contextualized evaluations performed by
can be denoted by an augmented IFS (AIFS) (The terms Atanassov insuitionistic fuzzy set (AIFS) and augmented Atanassov intuitionistic fuzzy set (AAIFS) are also found in the literature. ), say
, such that
As can be noticed, the condition
has been inherited from the original definition of an IFS. A depiction of the contextualized evaluations performed by
characterized as an AIFS is shown in
Figure 1.
In [
24], the authors make use of the above-mentioned characterization to define a FAST-GDM problem as follows:
Let
be an AIFS representing the contextualized evaluations given by an expert
, and let
be an AIFS representing the computed overall collective evaluation of the group of experts. Let also
be a function, named concordance index, that is used for computing the level of concordance between
and
such that it obtains a maximum value when the concordance between them is the highest. Under these considerations, a FAST-GDM problem runs into finding the most suitable option(s) with a general agreement among the experts. That is, finding the most suitable option(s) in such a way that the aggregation of the concordance indices (e.g., the average
where
m denotes the number of experts) is maximized.
A way to compute a concordance index between the individual and collective evaluations is by means of a function
that computes the similarity between the AIFSs that represent those evaluations [
28], i.e., the concordance index between
and
can be computed through the expression
.
Functions that compute the similarity between two IFSs, say
J and
A, have been proposed in [
28] to compute the concordance index between the individual and collective evaluations. Among those functions, one can find the following proposed in [
33]:
and
where
is the complement of
A, i.e.,
represents the Hamming distance between
A and
J, i.e.,
and
It is worth mentioning that the flat operator,
, which turns an AIFS into an IFS by excluding the feature collections contained in each of its elements [
28], can be used for converting
and
into IFSs
J and
A respectively.
The above-mentioned concepts are used in the next section to describe a novel variant of the method for reaching consensus in FAST-GDM problems proposed in [
24].
3. Increasing the Concordance by Exchanging the Most Influential Samples
As indicated in
Section 1, a CRP and a SP are commonly used for solving a FAST-GDM problem [
24]. During the CRP, each expert is first asked to evaluate the options. Then, the collective evaluations and the level of consensus are computed. If the computed level is not enough and asking the experts to perform a new round of evaluations is possible, the experts are given feedback on their evaluations and the CRP starts all over again. If the computed level is enough, the selection of the best suitable option(s) based on the computed collective evaluations is performed during the SP. Otherwise, the experts are notified that no consensus has been reached. The novel FAST-CR-XMIS, which aims at increasing the level of consensus in a CRP, is described in this section.
3.1. Idea behind FAST-CR-XMIS
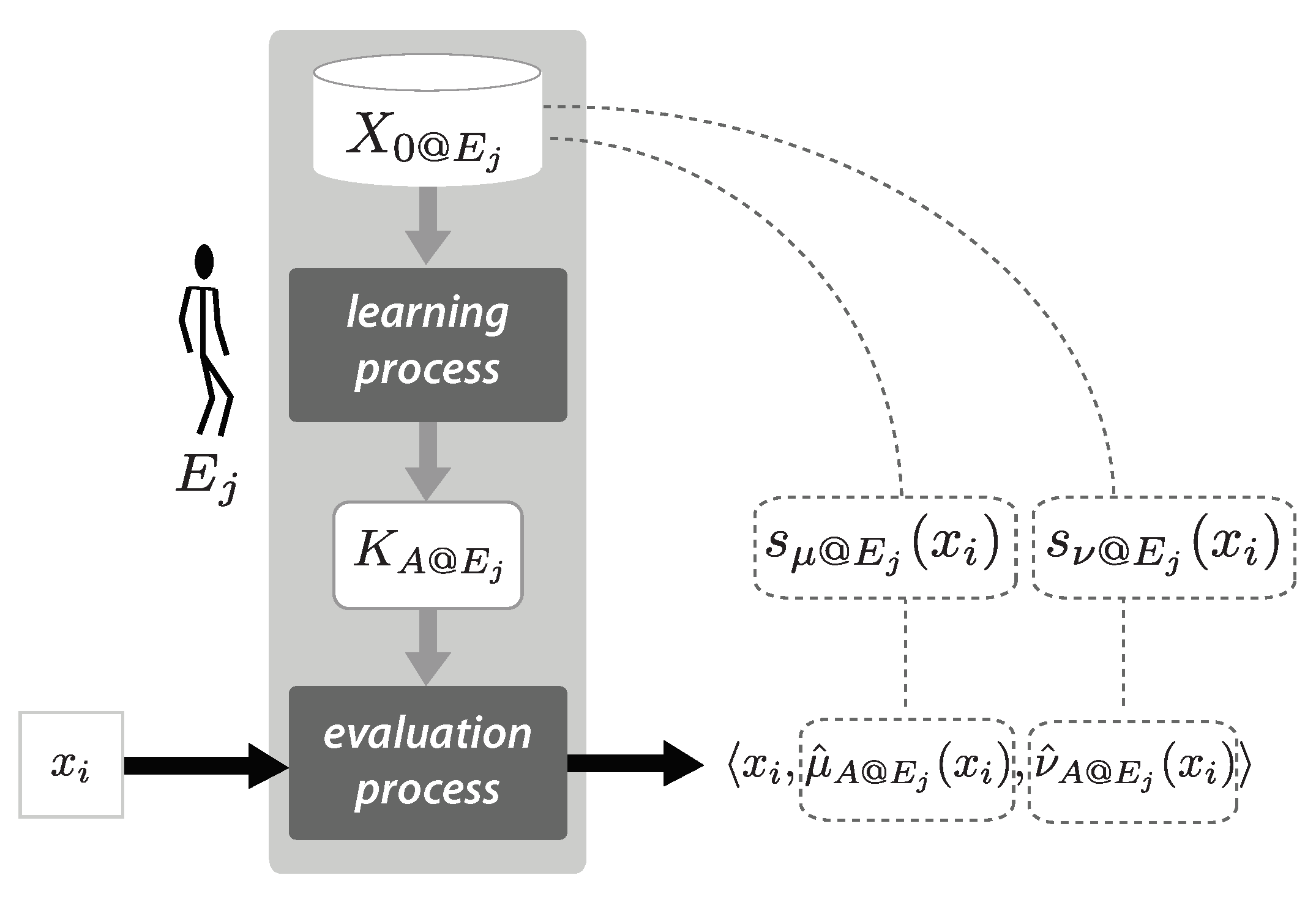
During the evaluation of an option, an expert can recall one or more samples that show what he/she understands as suitable (or unsuitable) options for a given problem. Since such samples have an influence on his/her evaluation, the expert can use them to put the evaluation in context –cf. [
34,
35] where similar ideas have been used to handle subjective evaluations carried out by persons with different background. For instance,
Figure 2 depicts a case in which an expert, say
, considers
as a good sample to put the evaluation of
satisfying the proposition ‘
IS
A’ in context, which is reflected in the AAD
. In this case,
also considers that
is a good sample to contextualize the evaluation of the level to which
dissatisfies ‘
IS
A’, which is reflected in the AAD
. Notice that
and
are part of the training collection
used by
to acquire the knowledge
about the (collection
A of) suitable options. This knowledge is then used during the evaluation of the potential options included in a collection
.
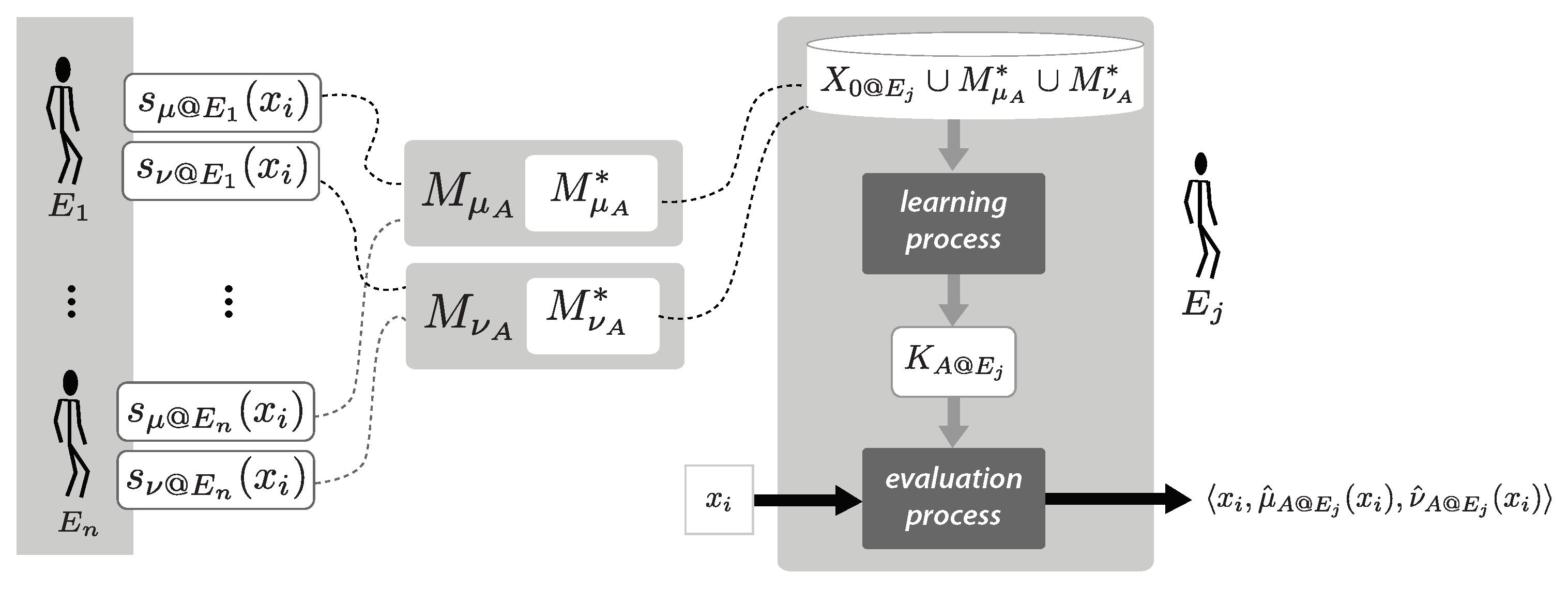
The samples and detected by are included into two collections, and , along with the samples detected by other experts. These collections of influential samples can be shared among the experts in such a way that the experts can study those samples and choose some of them to update their knowledge models.
In that regard, the idea behind FAST-CRP-XMIS is for experts to use their updated knowledge models to perform a new round of evaluations. Since the updated knowledge models of all the experts might be more aligned to each other after the exchange of the influential samples, an increment of the level of consensus among the new evaluations is expected. This idea is depicted in
Figure 3. Notice that, after a round of contextualized evaluations, each expert
can use the collections
and
, which are subsets of
and
respectively, along with the training collection
to update his/her knowledge
–here, the use of
and
reflect the fact that
might put his/her attention only on some of the samples included in
and
for updating his/her knowledge. After that,
can use the updated knowledge to perform a new evaluation of the level to which
satisfies ‘
IS
A’.
3.2. FAST-CR-XMIS Algorithm
The above-mentioned idea is implemented in Algorithm 1. The algorithm takes the same inputs used by the algorithm FAST-CR proposed in [
24], i.e., a collection of experts (
E), a collection of potential solutions (
X), a consensus threshold (
) and the maximum number of iterations (
) that is allowed while trying to reach consensus. Like FAST-CR, FAST-CR-XMIS tries to obtain (a collection of) contextualized evaluations (
) so that the computed level of consensus is greater than or equal to the required consensus threshold (
). FAST-CR-XMIS returns a collection of collective evaluations and a flag that indicates whether a consensus has been reached or not.
Like in FAST-CR, four logical phases are identified in FAST-CR-XMIS: characterization, aggregation, quantification and feedback. In the characterization phase the evaluations performed by the experts (see Line 6) are characterized as AIFSs (see Lines 7–8). Such evaluations are aggregated and, then, included into the collection of collective evaluations during the aggregation phase (see Lines 10–15). The collective level of consensus is computed during the quantification phase (see Line 16). The experts are given feedback on their evaluations through the feedback phase (see Lines 26–30).
In addition to those four phases, a fifth assembling phase is considered in FAST-CR-XMIS (see Lines 18–25). During this phase, the most influential samples and detected by each expert are included into the collections and respectively.
Even though the main difference between FAST-CR-XMIS and FAST-CR is the assembling phase, another difference exists in the feedback phase. In FAST-CR, each expert is notified with a suggestion on how to modify the evaluation of taking into account the collection of ’s attributes and , which are respectively part of the AADs and of the AIFS element . In contrast, in FAST-CR-XMIS each expert is additionally notified with a suggestion on how to modify the evaluation of considering the most influential samples detected for : while is offered in the case of the level to which is a suitable option (see Line 29), is offered in the case of the level to which is an unsuitable option (see Line 30). It is worth mentioning that the suggestions to modify the evaluations of in FAST-CR-XMIS are based on the most influential samples included in and , which complement to the aggregated collections of attributes included in and . Thus, the experts can choose between selecting the samples to update their understandings or using the values of the attributes to modify a specific evaluation.
Regarding the interpretation of the notification, while suggests that should increase to an extent , the expression suggests that should decrease to the same extent. Likewise, while suggests that should increase to an extent , the expression indicates that should decrease to the same extent.
Even though it is not explicitly mentioned in Algorithm 1, the study of the most influential samples and the update of the knowledge models carried out by each expert are expected to happen before a new round of evaluations. As previously stated, each expert might use the samples in and , which are subsets of of and respectively, for updating the knowledge models. In this regard, since different knowledge models exist, each of them having specific update mechanisms, handling them all is outside the scope of this paper. However, an example that illustrates how those knowledge models work and can be updated is provided in the simulation presented in the next section.
| Algorithm 1:FAST-CR-XMIS. |
 |
4. Simulation
In this section, a computerized simulation of a CRP in which a configurable number of experts try to reach consensus on the category of newswire stories is described. This simulation has been created to show how the novel FAST-CR-XMIS can help to increase the level of consensus among the participants in FAST-GDM problems.
As mentioned in
Section 2, an AIFS
can be used for denoting the contextualized evaluations of a collection
of potential options (newswire stories) satisfying the proposition ‘
belongs to category
A’, which are performed by an expert
according to the knowledge
that the expert has on how a typical story in category
A looks like (see
Figure 1). Since such an AIFS is used inside Algorithm 1, a learning process and an evaluation process are needed to obtain
and
respectively. For the sake of illustration, the learning process and the augmented evaluation process applied in explainable support vector machine classification (XSVMC) [
36] have been used for this simulation–other techniques like those proposed in [
37] can also be applied.
To develop the simulation, a collection consisting of 21578 newswire stories provided by Reuters, Ltd., named Reuters-21578 [
38], has been used. Among those newswire stories, 5108 stories related to one or more categories in
acq, corn, earn, grain, ship, wheat} were distributed among a configurable number of
m experts (
) to build a training collection
for each expert
where
. For instance,
Table 1 shows the distribution of newswire stories among experts
,
and
(i.e.,
). Notice that the number of stories assigned to
differs from
and
to imitate by some means the heterogeneity of this group.
To obtain a knowledge model , the XSVMC learning process requires each of the stories in being associated with a label that indicates whether the story belongs to the category A. Thus, to obtain, e.g., , which represents the knowledge about the category corn possessed by , the articles in were labeled following an ‘one-versus-the-rest’ strategy, i.e., the stories belonging to corn were labeled as positive examples, while the stories that do not belong to this category were labeled as negative examples.
To obtain a collection of contextualized evaluations , the XSVMC evaluation process requires a knowledge model and a collection X consisting of the stories subject to evaluation. Hence, to simulate the evaluations of the level to which the stories in X belong to the category corn performed by , along with X were used as input in the XSVMC evaluation process. The main advantage of using XSVMC for the simulation is that the XSVMC evaluation process makes use of the most influential support vectors to contextualize the evaluations and, thus, it makes the obtention of the most influential samples (i.e., newswire stories) easier (see Lines 21–25 in Algorithm 1).
To compute the concordance index between the collection
consisting of the evaluations performed by
and the collection
consisting of the collective evaluations, Equations (
5)–(
8) have been used in the simulation–the interested reader is referred to [
39] for an open-source implementation of these concordance indices in FAST-GDM problems. If the computed collective concordance index is less than the required level of consensus in a particular round (see Line 16 in Algorithm 1), the most influential samples are incorporated into the training collections and a new XSVMC learning process is performed for each expert before the next round of evaluations is initiated (see
Figure 3).
To measure the effect of the updated (knowledge) models on the level of consensus, the collective concordance indices and , corresponding to the first and last rounds respectively, were computed in 420 simulated FAST-CR-XMIS processes. Each category , each number of experts and 10 different test collections, say , each containing between 15 and 19 newswire stories, were used as input of these FAST-CR-XMIS processes. The results are presented in the next section.
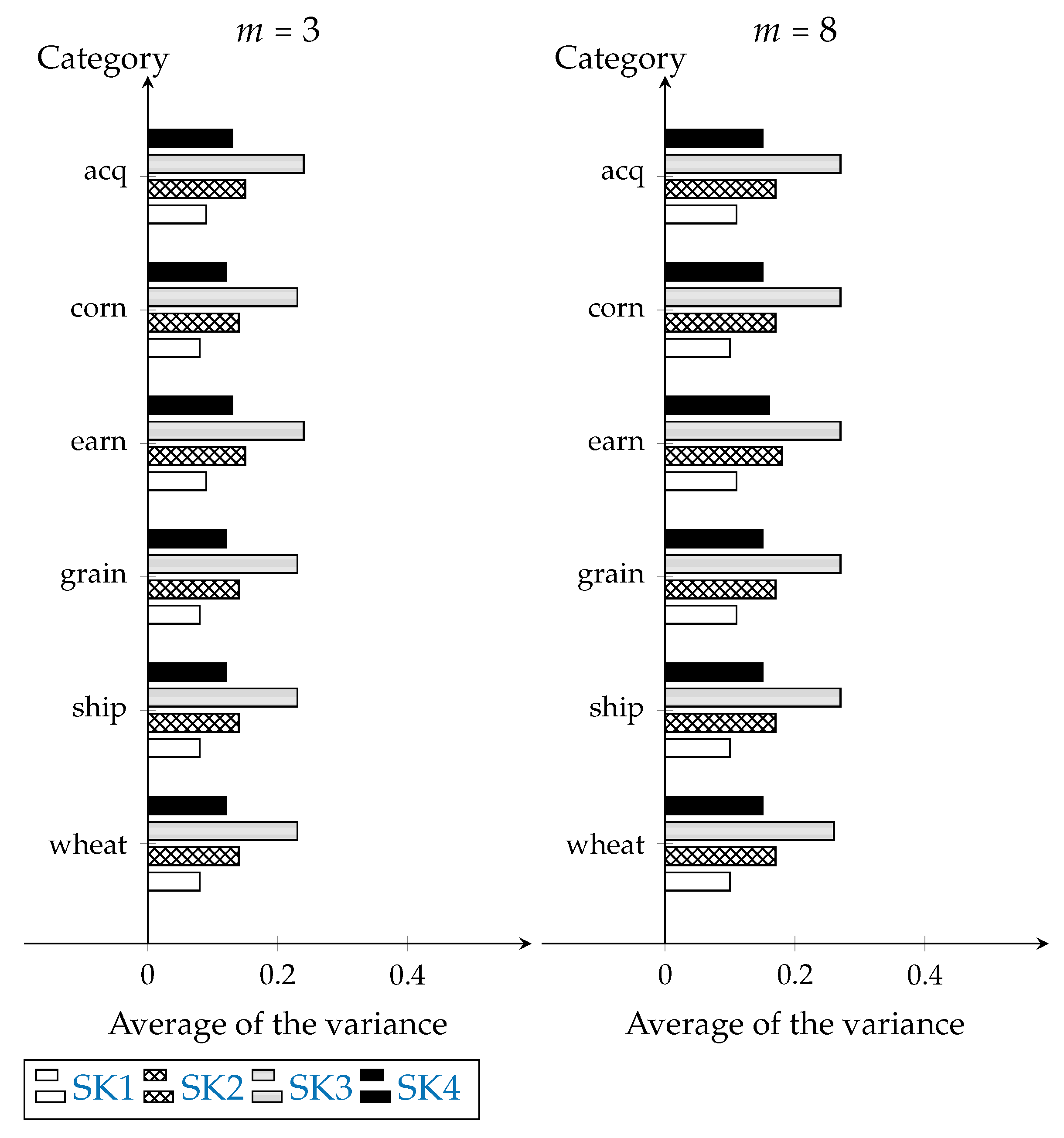
5. Experimental Results
The averages
and
of the computed collective concordance indices
and
per category corresponding to the FAST-CR-XMIS processes simulated with
and
experts are shown in
Table 2 and
Table 3 respectively–the tables corresponding to the FAST-CR-XMIS processes simulated with 2, 4, 5, 6 and 7 experts are shown in
Appendix A. In these tables, the collective concordance computed with SK1 (cf. Equation (
5)), SK2 (cf. Equation (
6)), SK3 (cf. Equation (
7)), and SK4 (cf. Equation (
8)) are listed. For example, the average of the collective concordance indices computed with SK1 after completing the first and last rounds of the FAST-CR-XMIS process simulated to reach consensus on the category corn with
experts are
and
respectively (see
Table 2). In this case, the percent variance is computed by
. Notice that, independently of the function used to compute the concordance indices, the percent variance is positive for each category.
Such positive increments of the concordance indices are also depicted in
Figure 4. Notice that the increments of the concordance indices in FAST-CR-XMIS processes simulated with 8 experts are greater than the increments of the concordance indices in FAST-CR-XMIS processes simulated with 3 experts. Bear in mind that the higher the concordance the higher the consensus.
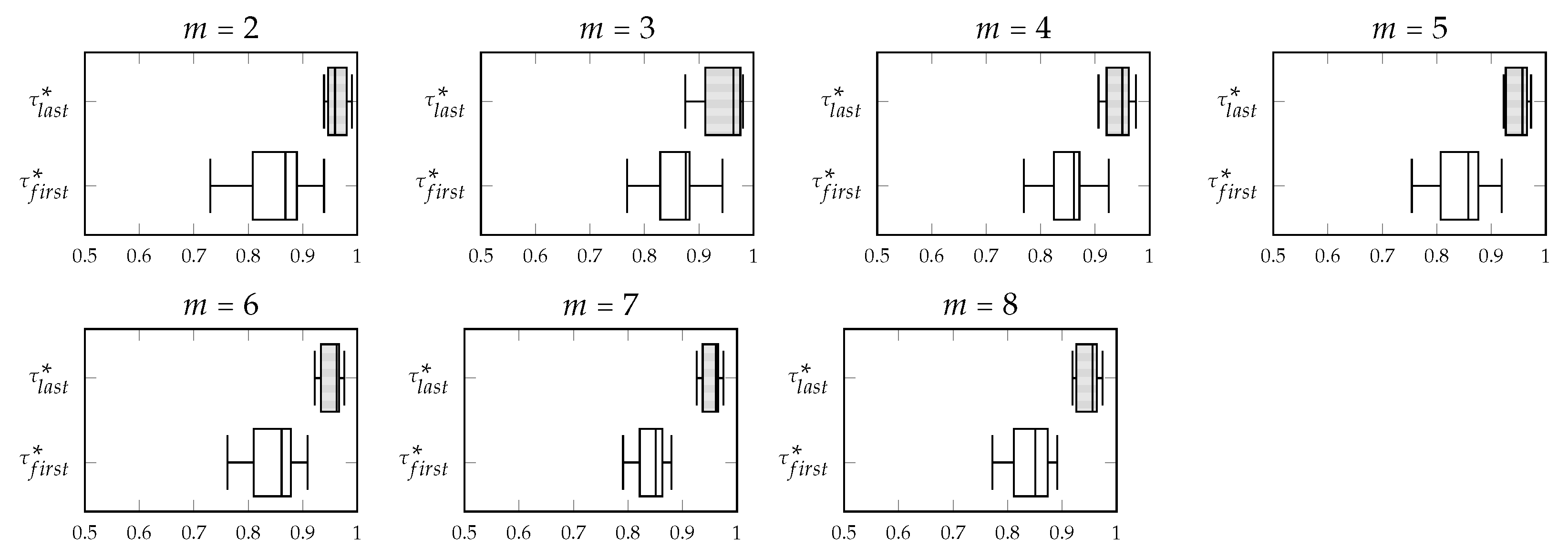
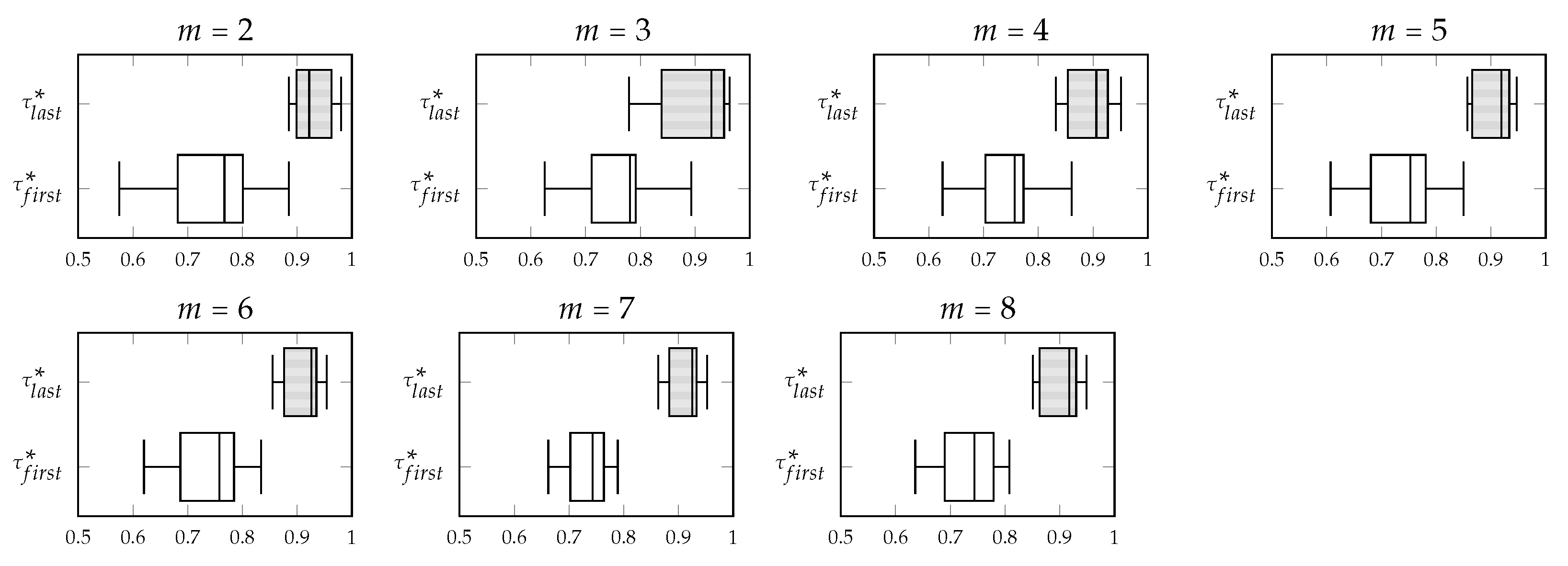
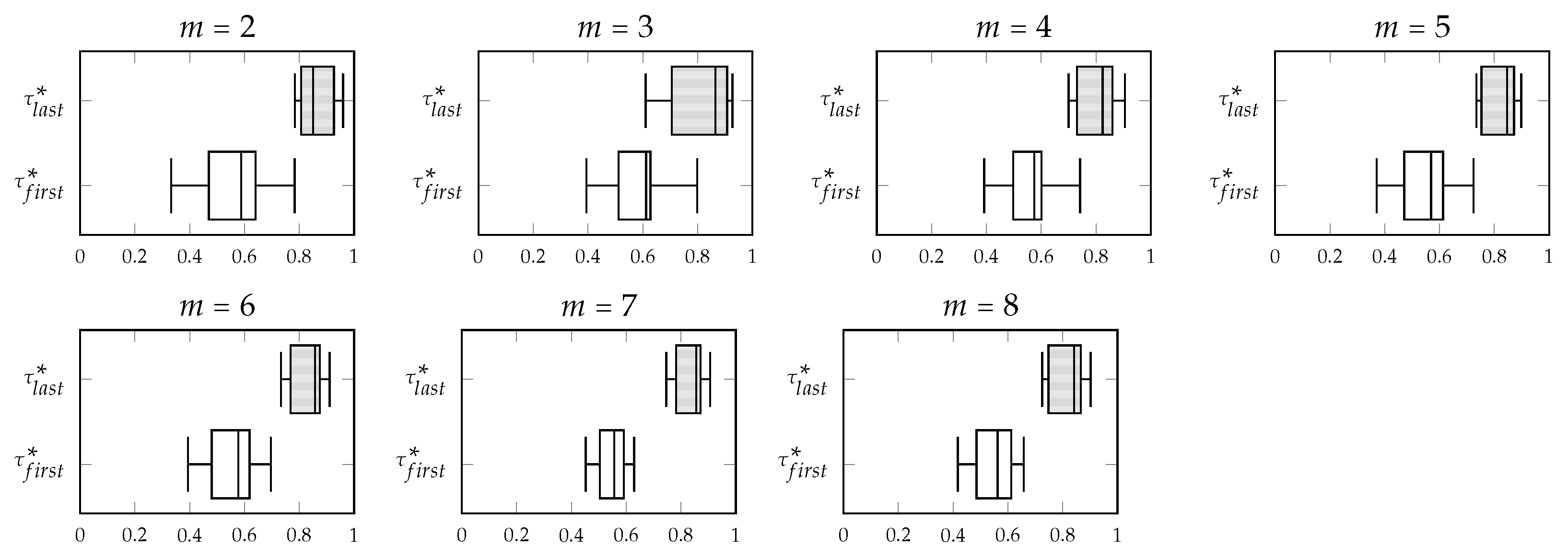
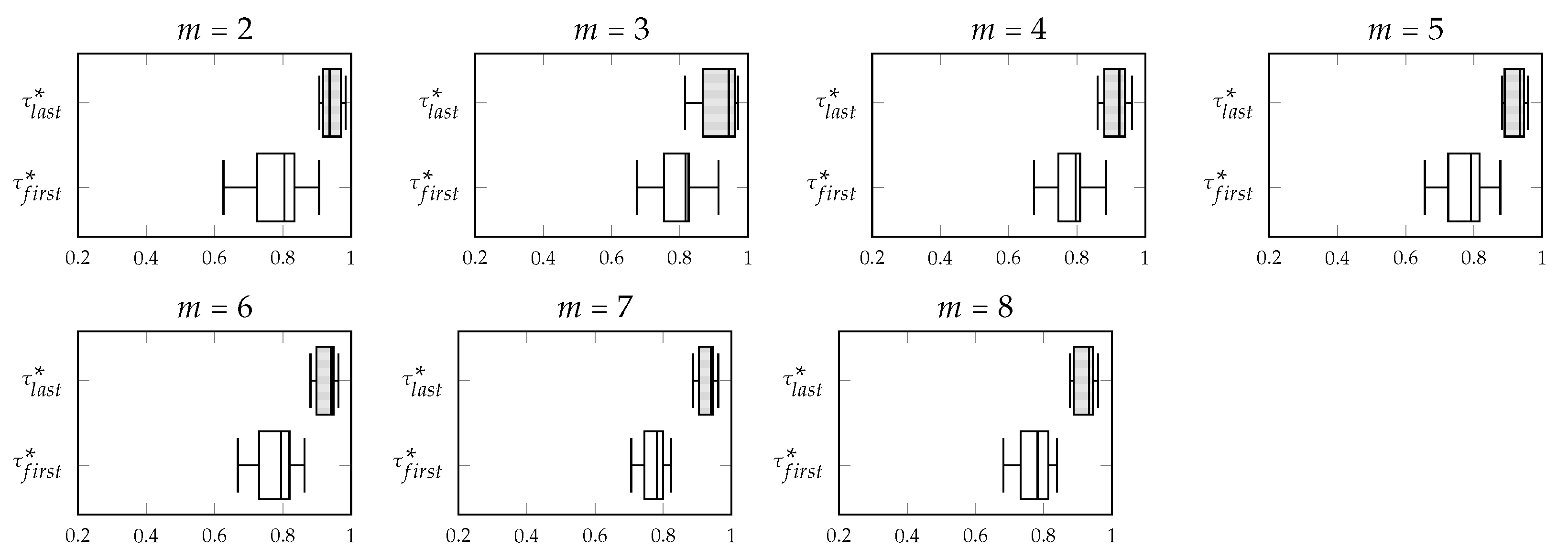
Figure 5,
Figure 6,
Figure 7 and
Figure 8 show, in that order, the variation of the concordance indices
and
computed with SK1, SK2, SK3 and SK4 in FAST-CR-XMIS processes about the category corn simulated with different numbers of experts (
). Notice that, regardless the function used to compute the concordance indices, in general the variation of
is less than the variation of
.
Table 4 shows the results of the t-test for the null hypothesis “the average of the collective concordance indices is the same after performing a simulated FAST-CR-XMIS process.” Notice that the t-values are statistically significant (
). This indicates that the concordance indices
and
are significantly different from each other after performing the simulated FAST-CR-XMIS processes.
7. Conclusions
A novel algorithm for reaching consensus in FAST-GDM problems has been proposed in this paper. The algorithm, named FAST-CR-XMIS, aims at increasing the level of consensus in CRPs where participants are open to reconsider their evaluations after studying the most influential samples that have been identified and shared by other participants.
In FAST-CR-XMIS, participants can perform contextualized evaluations of the potential options to solve a FAST-GDM problem. By means of this kind of evaluations, participants can express not only the level to which a potential option is deemed to be suitable, but also the reasons that justify that level. Since such contextualized evaluations are mathematically represented by AIFSs, the participants can express not only positive but also negative aspects during a CRP.
The results of simulated CRPs suggest that FAST-CR-XMIS can increase the level of consensus among the participants. However, these findings may be somewhat limited by the assumption of a cooperative scenario where participants are willing to share their experiences and update their understandings. Further research should be undertaken to confirm the applicability of FAST-CR-XMIS to scenarios where participants are reluctant to share their experiences.
The applicability of FAST-CR-XMIS to recurrent CRPs in which a given group of experts is organized for carrying out periodical evaluations is also considered and suggested as future work.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







