Cryptobiometrics for the Generation of Cancellable Symmetric and Asymmetric Ciphers with Perfect Secrecy



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction. The Objectives of Security, Cryptography, and Biometrics
2. Cryptobiometrics and Ways of Obtaining Keys
- Variability: Biometric data varies, whereas cryptography calls for exact and invariable data, as only one change in one bit of the key invalidates its identification and utility.
- Irreversibility: Cryptobiometric keys are not pure biometric data, which usually remain permanent and immutable in each human being, and are never to be obtained in a direct manner, which would oblige the need to revoke them (thus not permitting their later use) in the case of being compromised. Instead, they are generated as the result of some type of secure and irreversible mathematical transformation using that pure data.
- Cancellability: Biometric data are inexhaustible as, from them, many different keys can be generated as required. Thus, from a given biometric feature (iris, fingerprint, face, odor, gait, and so on), one is able to extract as many keys (of different lengths) as desired, according to the different applications.
- Irrevocability: In spite of the possibility of canceling cryptobiometric keys, our genuine biometric data can still be used, as they cannot be revoked.
- Unlinkability: Even if an attacker knows many keys, be it proceeding from the same or from a different pattern, they cannot obtain the original biometric datum.
- Reliability: Biometrics seeks an acceptable reliability average value, depending on the application and situation, between false rejection rate and false acceptance rate, while looking for the most possible reduced values. However, we always speak of the maximum probability of acceptance, rejection, or identification.
- Biometric bit-length: At present, symmetric cryptographic keys of order 10–10 and asymmetric keys of order 10–10 are required. However, not all biometric features (e.g., the iris is better than the fingerprint, and the latter better than typing patterns) enable us to extract such a number of bits, due to extraction difficulties, environmental variability, errors, and so on; or, they may (for reasons intrinsic to the very biometric feature) be highly variable in different samples and circumstances. It is, therefore, necessary to find better mathematical techniques which are capable of extracting a sufficient number of representative bits.
- Key-release: The key is totally detached with respect to the biometric pattern. It is not really regarded as a cryptobiometrics system; the comparison between the identified or verified external biometric capture and the pattern saved releases a cryptographic key that has no relation whatsoever to the biometric datum. It is of no interest and is cited here only as a proposal previous to the two following methods.
- Key-binding: Departing from a key that has no relation with the biometric datum, a complete monolithic cohesion is realized a posteriori between the biometric pattern and the key.The development of this model started with Soutar, Roberge, Stojanov, Gilroy, and Kumar [14,15]. The procedure, originating from the ideas patented by Tomko, Soutar, and Schmidt [16,17] and by Tomko and Stoianov [18], involves the use of correlation functions in the phase of processing, followed by carrying out binding with the key, generating (ad hoc) a lookup table from the key’s bits and a series of points in the pattern image.Juels and Wattemberg [19] introduced the so-called “fuzzy commitment,” where the key corresponds to a codeword generated after a process of correction of errors, and it later applies the binding with the value obtained from the biometric datum. The differential of bits with a new entry is corrected using error-correcting codes. In this model, the scheme of Hao, Anderson, and Daugman [5] was applied to the iris; some important improvements were added, such as the concatenation of diverse error-correcting codes (Hadamard and Reed–Solomon). Apart from that, using the iris, similar fuzzy commitment schemes have been made in other modalities (e.g., fingerprint, face, and so on) [20,21,22].Goh and Ngo [23], in turn, applied quantification transformations (projections) in facial biometry to generate random information streams.Juels and Sudan [24] developed the “fuzzy vault” over the model “fuzzy commitment,” the practical application of which has been shown by Clancy, Kiyavash, and Lin [25]. It generates a polynomial from the key, with no relation with the biometric data, where the characteristics of the subject are placed in particular points of the polynomial, followed by the insertion of masking data. This scheme has been later applied in numerous biometric categories: fingerprint, iris, palms of hands, face, and so on [26,27,28,29], improving its design [30].On the other hand, Dodis, Ostrovsky, Reyzin, and Smith [31] theoretically developed the so-called “fuzzy extractor/secure sketch,” with which they were able to extract quasi-random information from a biometric input, which was shown to be tolerant to variations and errors.Linnartz and Tuyls [32] proposed the “shielding functions” model in a theoretical manner, where the key and the biometric data were operated upon by these functions, thereby generating support data (or “helper data”) that could be later used to generate the key again, in the case of authenticated input data.On the other hand, Van der Veen, Kevenaar, Schrijen, Akkermans, and Zuo [33] followed the “fuzzy commitment” model together with “helper data,” already introduced theoretically by Tuyls and Goseling [34] and later by Verbitskiy and Denteneer [35].“Password hardening,” proposed by Monrose, Reiter, Li, and Wetzel, adds biometric information to a previous password [38,39,40,41]; the Teoh, Ngo, and Goh BioHashing scheme [23,42,43,44,45] also falls within the key-binding classification.More recently, the work of Iida and Kiya has focused on error-correcting codes and fuzzy commitment schemes for JPEG image [46]. The different methodology of Malarvizhi, Selvarani, and Raj uses fuzzy logic and adaptive genetic algorithms [47]. It is also worth mentioning the proposal of Liew, Shaw, Li and Yang, who made use of Bernoulli mapping and chaotic encryption [48]; and the use of face and fingerprint biometrics along with watermarking and hyper-chaotic maps by Abdul, Nafea, and Ghouzali [49].Another approach is that of Priya, Kathigaikumar, and Mangai, who used random bits mixed in an AES cipher [50]. Asymmetric encryption and irrevocability were used by Barman, Samanta, and Chattopadhyay [51]. The fuzzy extractor with McEliece encryption, which is resistant to quantum attacks, was proposed by Kuznetsov, Kiyan, Uvarova, Serhiienko, and Smirnov [52]. In the work of Chang, Garg, Hasan, and Mishra, a cancelable multi-biometric authentication fuzzy extractor has been proposed, where a novel bit-wise encryption scheme irreversibly transforms a biometric template to a protected one using a secret key generated from another biometric template [53].We also note the works of Damasevicius, Maskeliunas, Kazanavicius, and Wozniak, who used data from electroencephalography and Bose–Chaudhuri–Hocquenghem error-correcting codes [54]. Olanrewaju, Oyebiyi, Misra, Maskeliunas, and Damasevicius [55] used the same type of correction codes with Principal Component Analysis and fast Chebyshev transform hashing for ear biometrics. Some other works have discarded the use of error-correcting codes, such as that of Chai, Goi, Tay, and Jin, where an alignment-free and cancelable iris key binding scheme was constructed through the use of a non-invertible transform [56]. Finally, another work used another type of biometrics which is not very common: key binding with finger vein [57].
- Key-generation: The key is extracted from the biometric pattern.The first proposal in this area was the patent of Bodo [58], where the cryptographic key was obtained fully from the biometric data, even though it posed cancellability and security problems related to the theft of data specific to the subject.An improvement was proposed by Davida, Frankel, Matt, and Peralta [59,60], which generated the key from the hash function over the biometric data after the correction of errors.Other approaches and proposals have been designed using the quantification and intervals of biometric features, such as those of Vielhauer, Steinmetz, and Mayerhofer [61] or Feng and Wah [62].Drahanský, in turn, obtained the key from quantification and the use of graphs [63].Other authors have utilized the combined use of quantification and “fuzzy extractors/secure sketches” as key generators [64,65,66].More recently, the proposal of Aness and Chen used discriminative binary feature learning and quantization [67], and Yuliana, Wirawan, and Suwadi [68] combined pre-processing with multi-level quantization. Furthermore, Chen, Wo, Xie, Wu, and Han improved quantization techniques against leakage and similarity-based attacks [69].With regards to cancellability, a crucial aspect of the works of Ratha, Connell, Zuo, and Bolle [70,71], and later, of Savvides, Kumar, and Khosla [72], introduced biometric cancellability, proposing systems that protect the original biometric data. Along with the above, the closest in time was the study of Trivedi, Thounaojam, and Pal [73], or those who used symmetric cryptography, such as Barman, Samanta, and Chattopadhyay [74]. A secured feature matrix from the template and AES cipher was used by Gaddam and Lal [75]. We also note the novel approach using random slopes of Kaur and Khanna [76], and the technique for achieving cancellability through geometric triangulation and steganography of Neethu and Akbar [77]. The work of Punithavathi and Subbiah [78] introduced partial DCT-based cancellability for IoT applications. In key-binding, cancellability and revocability are naturally simpler; however, in key-generation, the situation is not as easy or simple.
3. Voice Biometry
3.1. Introduction
3.1.1. Speech Recognition
3.1.2. Voice Recognition Techniques
- (1)
- Template Matching: A maximum accuracy or maximum likelihood is sought between the samples previously stored as a voice template and the new voice sample input. This is called the speaker-dependent model.
- (2)
- Feature Analysis: This is also called the speaker-independent model, as it searches for characteristics within human discourse, and from them, it searches for similarities among the input speakers compared to the stored data in the system.
3.2. Methodology
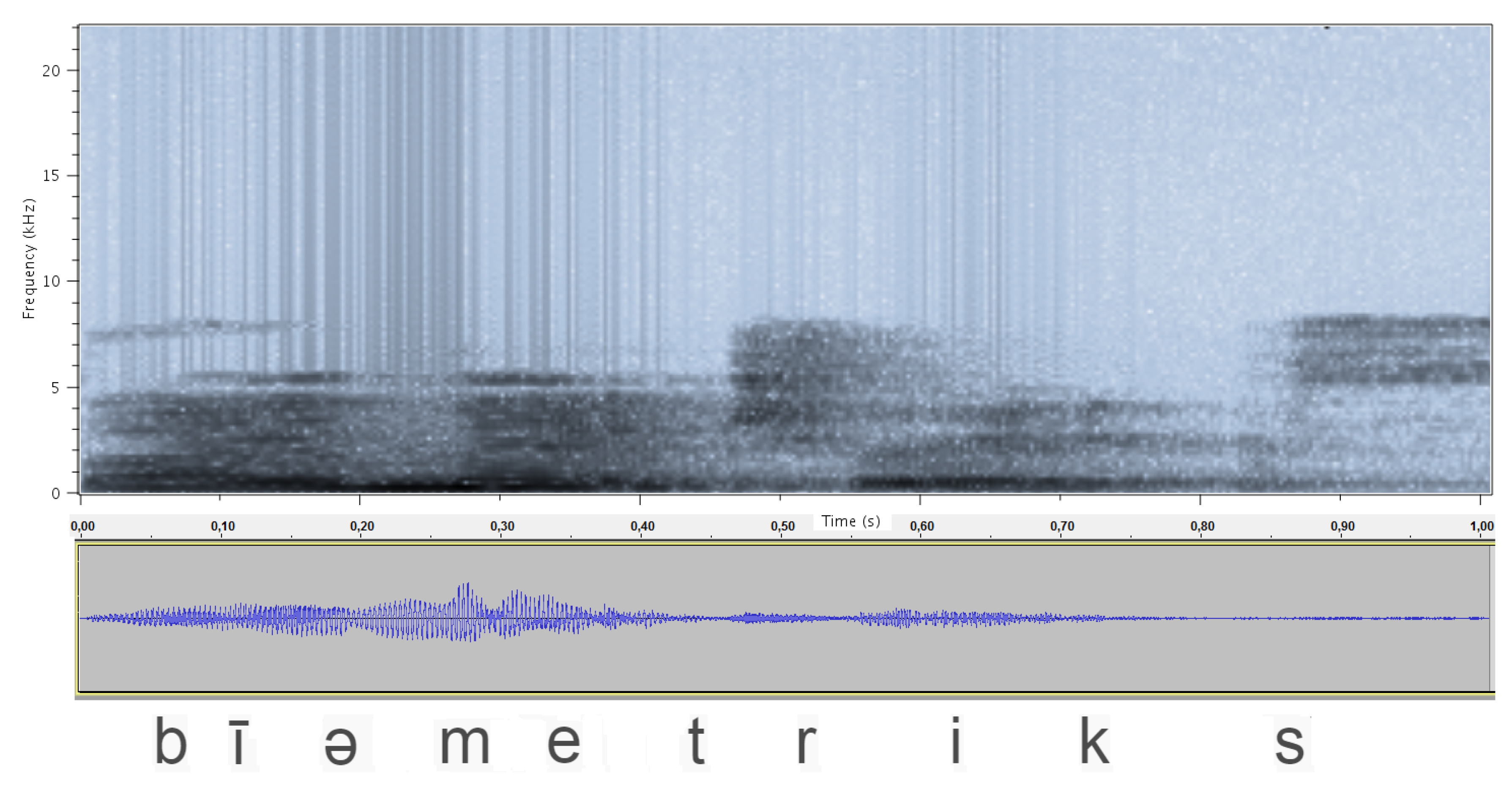
3.2.1. Spectral Analysis of Frequencies
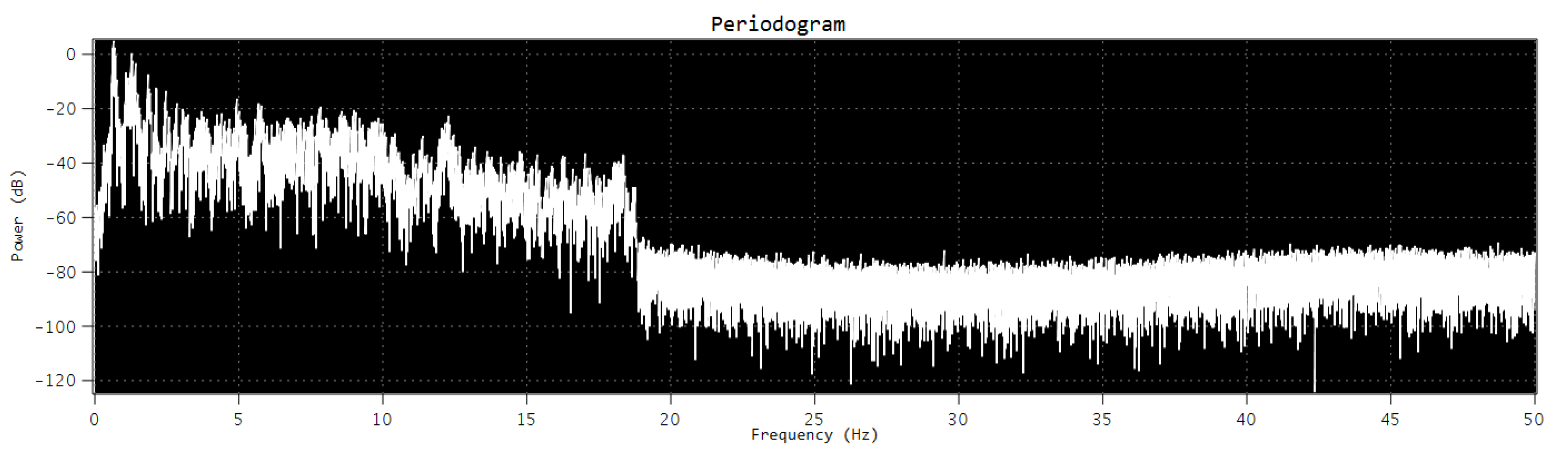
3.2.2. Periodogram of the Signal
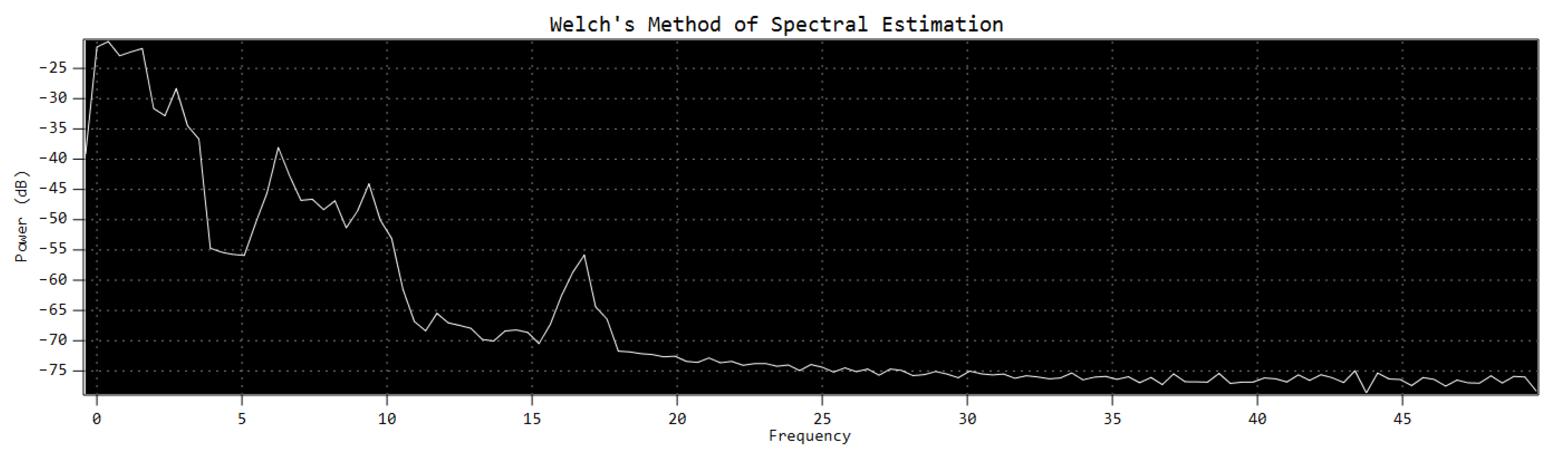
3.2.3. Welch Method
- Dividing the signal (overlapping segments).
- Windowing and FFT.
- Averaging.
- Dividing the signal (overlapping segments). We divide the signal into overlapping segments. We consider overlapped samples herein.
- Windowing and FFT. We use an efficient algorithm for computing the DFT, known as fast Fourier transform (FFT); a Hamming window with an FFT size of and normalization constant , obtained from the window ; and the size of the FFT.As the window is not rectangular, it is technically referred not to as a periodogram, but instead, a modified periodogram.
- Averaging. The average and normalized values are calculated from the vectorized values of the overlapped fragments of the windowed and FFT-processed signal.
4. Proposed Model
4.1. Schemes of Ciphers
4.2. Protocols
- User A generates their own template , which we can consider to be a binary vector of any length, .
- A also generates a random value , a binary vector .
- The binary values and are adjusted to the right, where options can be given. Then, the following is calculated:being the outputs of the hash functions and of binary length h.
- Over-randomization:
- (a)
- User A generates a random number of length (normally, the output of a hash function is lower in length than the order of our elements, for security reasons).
- (b)
- A generates a set of h different values from the set .
- (c)
- Calculate the perfect substitution transposition cipher of length .
- Depending on the element e that we are considering, we can have the following cases:
- (a)
- generates a prime number: Here, user A carries out prime, where is a procedure to generate a prime number—applying the usual methods of generation through primality tests—from : using its value (if it is already prime), the next closest prime, or a strong prime.
- (b)
- generates an element of G, generally , , , : In this case, we do not have to make any changes in e; in any case, calculate its modular value in G.
- (c)
- generates a point of an elliptic curve: Here, user A carries out , with being a procedure to generate , the x coordinate of a point J located on the elliptic curve, such that .
- User A generates their own template , which we can consider to be a binary vector of any length, .
- User B generates their own template , again a binary vector of any length, .
- A also generates a random value , a binary vector .
- B also generates a random value , a binary vector .
- The binary values and are adjusted to the right, where options can be given. Then, the following is calculated:those being the outputs of the hash functions and of binary length h.
- The binary values and are adjusted to the right, where options can be given. Then, the following is calculatedbeing the outputs of the hash functions and of binary length h.
- Over-randomization:
- (a)
- User A generates a random value with the length of the symmetric key t; generally, (normally, the output of a hash function is higher in length than the order of our element K).
- (b)
- User B generates a random value with the length of the symmetric key t; generally (normally, the output of a hash function is higher in length than the order of our element K).
- (c)
- A generates a set of t different values from the set .
- (d)
- B generates a set of t different values from the set .
- (e)
- User A applies the perfect substitution transposition cipher of length t.
- (f)
- User B applies the perfect substitution transposition cipher of length t.
- User A sends B the vector , using the asymmetric cryptography of a cryptobiometrically generated key.
- User B sends A the vector , using the asymmetric cryptography of a cryptobiometrically generated key.
- Both users apply .
4.3. Main Elements of the Protocols
4.4. Security Analysis
- Irreversibility: Given an output of our system, an eventual attacker cannot reconstruct (similar with or ), the genuine biometric data.As we examine below, this aspect is achieved by the security properties of the first sub-system of hash functions and the subsequent sub-system of over-randomization with perfect encryption.
- Cancellability: From an input , , or , we can generate as many outputs as we want.This property is achieved, in the scenario of asymmetric ciphers, through all those initial moments in which the parameters of the cryptographic scheme must be generated, on which all the encrypted communications subsequently take place, by the random values , , and . The binary length of is n, and is the binary length of . On the other hand, with , we have the h-element variations of elements (with repetition not allowed), , as possible options. Thus, the number of possible options is given by .In the scenario of symmetric ciphers, cancellability is achieved by the random values , , and (similarly , , and ). The binary length of is n, and t is the binary length of .On the other hand, with we have, as possible options, the h-element variations of t elements with repetition not allowed . Thus, the number of possible options for the user A is given by .
- Irrevocability: The elements obtained for the schemes of ciphers can be changed, when necessary, and the biometric data of the initial template, , , or , can be used together with new random values, masking the template, which can be used permanently and irrevocably.
- Unlinkability: For a single biometric sample , , or , we should be able to generate different outputs in a way such that it is not feasible to determine whether those outputs belong to a single subject or not.The proof of this is that, although the template is the same, as it originates from biological and/or behavioral aspects of a subject, the random variables of the system, as well as the properties of the hash functions (one-way or pre-image resistance, resistance to second pre-image, and collision resistance), and the perfect secret property of the over-randomization sub-system, by which the probability a posteriori that the original text is x if the ciphered text is y, is identical to the probability a priori that the original text is x.
- Pre-image resistance: this property means that H is a one-way function, and so, for a randomly chosen , it is hard to find, given , an such that .
- Second pre-image resistance: given , it is hard to find such that .
- Collision resistance: it is hard to find a pair , , such that .
- -
- The probability distribution on K is uniform.
- -
- For every and every , there exists a unique such that .
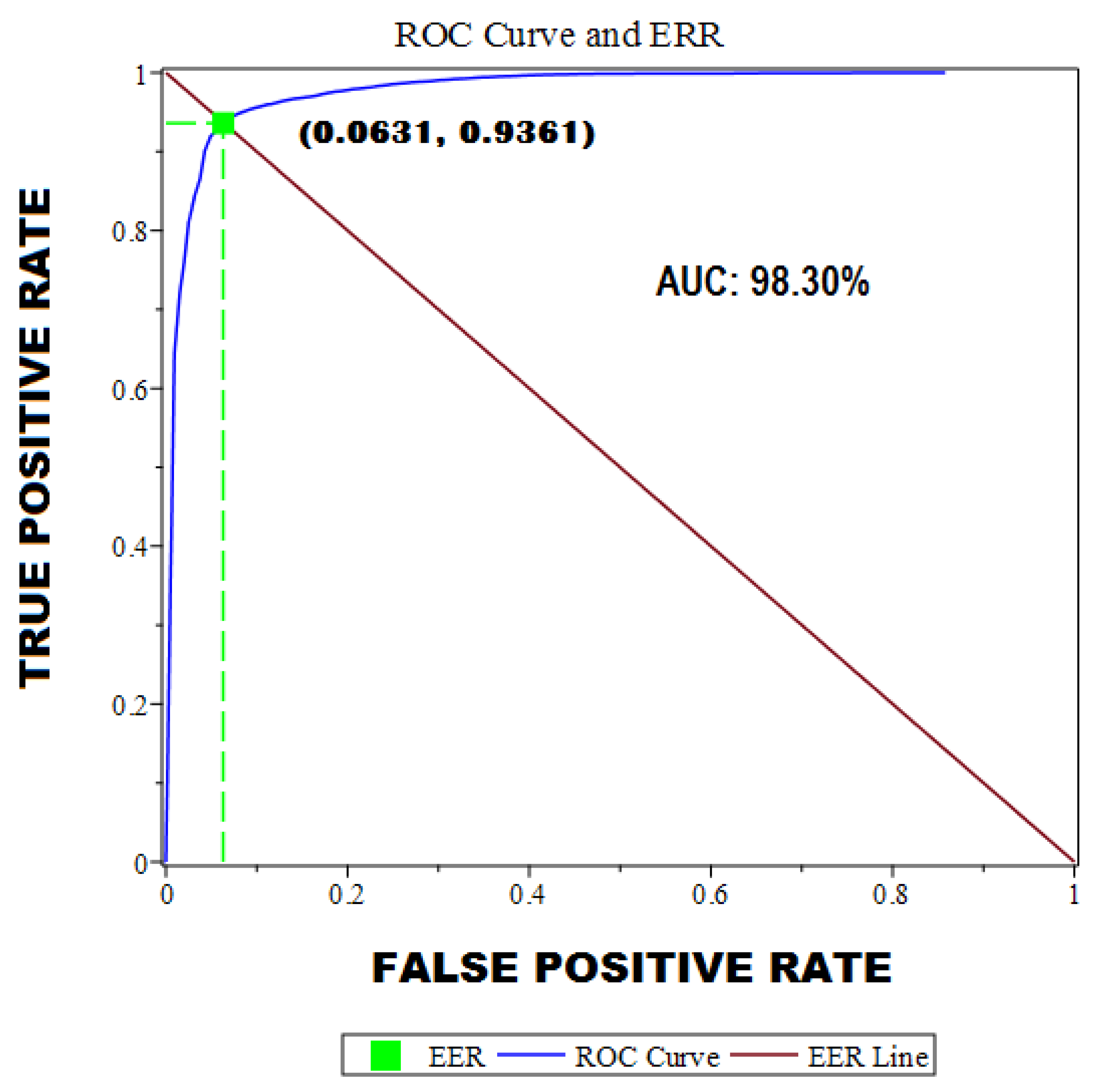
5. Experiments
Generation of Fundamental Elements of Cryptographic Schemes
- (a)
- (with a high prime and A any integer);
- (b)
- (with a high prime and B any integer);
- (c)
- (with a high prime and C any integer).
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Parker, D.B. Toward a New Framework for Information Security. In The Computer Security Handbook; Bosworth, S., Kabay, M.E., Eds.; John Wiley & Sons: New York, NY, USA, 2002; pp. 27–48. [Google Scholar]
- Parker, D.B. Fighting Computer Crime; John Wiley & Sons: New York, NY, USA, 1998. [Google Scholar]
- Jara Vera, V.; SánchezÁvila, C. La Criptobiometría y la Redefinición de los Conceptos de Persona e Identidad como Claves para la Seguridad. Proc. DESEi+d 2013, 583–590. [Google Scholar]
- Hao, F.; Anderson, R.; Daugman, J. Combining Crypto with Biometrics Effectively. IEEE Trans. Comput. 2006, 55, 1081–1088. [Google Scholar]
- Kanade, S.; Petrovska-Delacrétaz, D.; Dorizzi, B. Enhancing Information Security and Privacy by Combining Biometrics with Cryptography. Synth. Lect. Inf. Secur. Privacy Trust 2012, 3, 1–140. [Google Scholar] [CrossRef][Green Version]
- Rathgeb, C.; Uhl, A. A Survey on Biometric Cryptosystems and Cancelable Biometrics. EURASIP J. Inf. Secur. 2011, 3, 1–25. [Google Scholar] [CrossRef]
- Campisi, P. Security and Privacy in Biometrics; Springer: London, UK, 2013. [Google Scholar]
- Ngo, D.C.L.; Teoh, A.B.J.; Hu, J. Biometric Security; Cambridge Scholars Publishing: New Castle upon Tyne, UK, 2015. [Google Scholar]
- Rane, S.; Wang, Y.; Draper, S.C.; Ishwar, P. Secure Biometrics: Concepts, Authentication Architectures, and Challenges. IEEE Signal Process. Mag. 2013, 30, 51–64. [Google Scholar] [CrossRef]
- Bhanu, B.; Kumar, A. Deep Learning for Biometrics; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Marcel, S.; Nixon, M.S.; Fierrez, J.; Evans, N. Handbook of Biometric Anti-Spoofing: Presentation Attack Detection; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Gomez-Barrero, M.; Galbally, J. Reversing the Irreversible: A Survey on Inverse Biometrics. Comput. Secur. 2020, 90, 101700. [Google Scholar] [CrossRef]
- Soutar, C.; Roberge, D.; Stojanov, S.A.; Gilroy, R.; Vijaya Kumar, B.V.K. Biometric Encryption Using Image Processing. Proc. SPIE Opt. Secur. Counterfeit Deterrence Tech. 1998, 3314, 178–188. [Google Scholar]
- Soutar, C.; Roberge, D.; Stojanov, S.A.; Gilroy, R.; Vijaya Kumar, B.V.K. Biometric Encryption-Enrollment and Verification Procedures. Proc. SPIE Opt. Secur. Counterfeit Deterrence Tech. 1998, 3386, 24–35. [Google Scholar]
- Tomko, G.J.; Soutar, C.; Schmidt, G.J. Fingerprint Controlled Public Key Cryptographic System. U.S. Patent 5541994, 30 July 1996. [Google Scholar]
- Tomko, G.J.; Soutar, C.; Schmidt, G.J. Biometric Controlled Key Generation. U.S. Patent 5680460, 21 October 1997. [Google Scholar]
- Tomko, G.J.; Stoianov, A. Method and Apparatus for Securely Handling a Personal Identification Number or Cryptographic Key Using Biometric Techniques. U.S. Patent 5712912, 27 January 1998. [Google Scholar]
- Juels, A.; Wattenberg, M. A Fuzzy Commitment Scheme. In Proceedings of the 6th ACM Conference on Computer and Communications Security, Kent Ridge Digital Labs, Singapore, 2–4 November 1999; pp. 28–36. [Google Scholar]
- Teoh, A.B.J.; Kim, J. Secure Biometric Template Protection in Fuzzy Commitment Scheme. IEICE Electron. Express 2007, 4, 724–730. [Google Scholar] [CrossRef]
- Tong, V.; Sibert, H.; Lecoeur, J.; Girault, M. Biometric Fuzzy Extractors Made Practical: A Proposal Based on Fingercodes. In Advances in Biometrics; Springer: Berlin/Heidelberg, Germany, 2007; pp. 604–613. [Google Scholar]
- Ao, M.; Li, S. Near Infrared Face Based Biometric Key Binding. In Advances in Biometrics; Springer: Berlin/Heidelberg, Germany, 2009; pp. 376–385. [Google Scholar]
- Goh, A.; Ngo, D.C.L. Computation of Cryptographic Keys from Face Biometrics. In Communications and Multimedia Security. Advanced Techniques for Network and Data Protection; Springer: Berlin/Heidelberg, Germany, 2003; pp. 1–13. [Google Scholar]
- Juels, A.; Sudan, M. A Fuzzy Vault Scheme. Des. Codes Cryptogr. 2006, 38, 237–257. [Google Scholar] [CrossRef]
- Clancy, T.; Kiyavash, N.; Lin, D. Secure Smartcardbased Fingerprint Authentication. In Proceedings of the 2003 ACM SIGMM Workshop on Biometrics Methods and Applications, Berkley, CA, USA, 2–8 November 2003; pp. 45–52. [Google Scholar]
- Lee, Y.; Bae, K.; Lee, S.; Park, K.; Kim, J. Biometric Key Binding: Fuzzy Vault Based on Iris Images. In Proceedings of the International Conference on Biometrics; Springer: Berlin/Heidelberg, Germany, 2007; pp. 800–808. [Google Scholar]
- Wu, X.; Wang, K.; Zhang, D. A Cryptosystem Based on Palmprint Feature. In Proceedings of the 19th Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Wu, Y.; Qiu, B. Transforming a Pattern Identifier into Biometric Key Generators. In Proceedings of the IEEE International Conference on Multimedia and Expo, Suntec City, Singapore, 19–23 July 2010; pp. 78–82. [Google Scholar]
- Uludag, U.; Jain, A.K. Fuzzy Fingerprint Vault. In Proceedings of the Biometrics: Challenges Arising from Theory to Practice, Cambridge, UK, 22–27 August 2004; pp. 13–16. [Google Scholar]
- Moon, D.; Choi, W.Y.; Moon, K.; Chung, Y. Fuzzy Fingerprint Vault Using Multiple Polynomials. In Proceedings of the IEEE 13th International Symposium on Consumer Electronics, Kyoto, Japan, 9–11 June 2009; pp. 290–293. [Google Scholar]
- Dodis, Y.; Ostrovsky, R.; Reyzin, L.; Smith, A. Fuzzy Extractors: How to Generate Strong Keys from Biometrics and Other Noisy Data. In Proceedings of the Eurocrypt, Advances in Cryptology; Springer; Berlin/Heidelberg, Germany, 2004; pp. 523–540. [Google Scholar]
- Linnartz, J.; Tuyls, P. New Shielding Functions to Enhance Privacy and Prevent Misuse of Biometric Templates. In Proceedings of the 4th Audio- and Video-Based Biometric Person Authentication, Guildford, UK, 9–11 June 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 393–402. [Google Scholar]
- Veen, M.; Kevenaar, T.; Schrijen, G.; Akkermans, T.; Zuo, F. Face Biometrics with Renewable Templates. In Proceedings of the 8th Security, Steganography, and Watermarking of Multimedia Contents (SSWMC), San Jose, CA, USA, 16–19 January 2006; pp. 205–216. [Google Scholar]
- Tuyls, P.; Goseling, J. Capacity and Examples of Template-Protecting Biometric Authentication Systems. In Proceedings of the Biometric Authentication; Springer: Berlin/Heidelberg, Germany, 2004; pp. 158–170. [Google Scholar]
- Tuyls, P.; Verbitskiy, E.; Goseling, J.; Denteneer, D. Privacy Protecting Biometric Authentication Systems: An Overview. In Proceedings of the 12th European Signal Processing Conference (EUSIPCO), Vienna, Austria, 6–10 September 2015. [Google Scholar]
- Jain, A.; Nandakumar, K.; Nagar, A. Biometric Template Security. EURASIP J. Adv. Signal Process. 2008, 2008, 1–7. [Google Scholar] [CrossRef]
- Huang, Y.; Malka, L.; Evans, D.; Katz, J. Efficient Privacy-Preserving Biometric Identification. In Proceedings of the 18th Network and Distributed System Security Conference (NDSSC), San Diego, CA, USA, 6–9 February 2011; pp. 1–14. [Google Scholar]
- Monrose, F.; Reiter, M.; Li, Q.; Wetzel, S. Cryptographic Key Generation from Voice. In Proceedings of the 2001 IEEE Symposium on Security and Privacy, Oakland, CA, USA, 12–16 May 2001; pp. 1–12. [Google Scholar]
- Monrose, F.; Reiter, M.; Li, Q.; Wetzel, S. Using Voice to Generate Cryptographic Keys. In Odyssey; 2001; pp. 237–242. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.11.1062&rep=rep1&type=pdf (accessed on 8 September 2020).
- Monrose, F.; Reiter, M.; Wetzel, S. Password Hardening Based on Keystroke Dynamics. Int. J. Inf. Secur. 2002, 1, 69–83. [Google Scholar] [CrossRef][Green Version]
- Monrose, F.; Reiter, M.; Li, Q.; Lopresti, D.; Shih, C. Toward Speech-Generated Cryptographic Keys on Resource-Constrained Devices. In Proceedings of the 11th USENIX Security Symposium, San Francisco, CA, USA, 5–9 August 2002; pp. 283–296. [Google Scholar]
- Teoh, A.B.J.; Ngo, D.C.L.; Goh, A. Biohashing: Two Factor Authentication Featuring Fingerprint Data and Tokenised Random Number. Pattern Recognit. 2004, 37, 2245–2255. [Google Scholar]
- Teoh, A.B.J.; Goh, A.; Ngo, D.C.L. Random Multispace Quantization as an Analytic Mechanism for Biohashing of Biometric and Random Identity Inputs. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1892–1901. [Google Scholar] [CrossRef]
- Teoh, A.B.J.; Ngo, D.C.L.; Goh, A. Personalised Cryptographic Key Generation Based on Facehashing. Comput. Secur. 2004, 23, 606–614. [Google Scholar] [CrossRef]
- Ngo, D.C.L.; Teoh, A.B.J.; Goh, A. Biometric Hash: High-Confidence Face Recognition. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 771–775. [Google Scholar] [CrossRef]
- Iida, K.; Kiya, H. Secure and Robust Identification Based on Fuzzy Commitment Scheme for JPEG Image. In Proceedings of the IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Nara, Japan, 1–3 June 2016; pp. 1–5. [Google Scholar]
- Malarvizhi, N.; Selvarani, P.; Raj, P. Adaptive Fuzzy Genetic Algorithm for Multi Biometric Authentication. Comput. Sci. Multimed. Tools Appl. 2019, 79, 9131–9144. [Google Scholar] [CrossRef]
- Liew, C.Z.; Shaw, R.; Li, L.; Yang, Y. Survey on Biometric Data Security and Chaotic Encryption Strategy with Bernoulli Mapping. In Proceedings of the International Conference on Medical Biometrics, Shenzhen, China, 30 May–1 June 2014; pp. 174–180. [Google Scholar]
- Abdul, W.; Nafea, O.; Ghouzali, S. Combining Watermarking and Hyper-Chaotic Map to Enhance the Security of Stored Biometric Templates. Comput. J. 2020, 63, 479–493. [Google Scholar] [CrossRef]
- Priya, S.S.S.; Kathigaikumar, P.; Mangai, N.M.S. Mixed Random 128 Bit Key Using Fingerprint Features and Binding Key for AES Algorithm. In Proceedings of the International Conference on Contemporary Computing and Informatics (IC3I), Mysore, India, 27–29 November 2014; pp. 1226–1230. [Google Scholar]
- Barman, S.; Samanta, D.; Chattopadhyay, S. Revocable Key Generation from Irrevocable Biometric Data for Symmetric Cryptography. In Proceedings of the 2015 Third International Conference on Computer, Communication, Control and Information Technology (C3IT), Hooghly, India, 7–8 February 2015; pp. 1–4. [Google Scholar]
- Kuznetsov, A.; Kiyan, A.; Uvarova, A.; Serhiienko, R.; Smirnov, V. New Code Based Fuzzy Extractor for Biometric Cryptography. In Proceedings of the International Scientific-Practical Conference Problems of Infocommunications. Science and Technology (PIC S&T), Kharkiv, Ukraine, 9–12 October 2018; pp. 119–124. [Google Scholar]
- Chang, D.; Garg, S.; Hasan, M.; Mishra, S. Cancelable Multi-Biometric Approach Using Fuzzy Extractor and Novel Bit-Wise Encryption. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3152–3167. [Google Scholar] [CrossRef]
- Damasevicius, R.; Maskeliunas, R.; Kazanavicius, E.; Wozniak, M. Combining Cryptography with EEG Biometrics. Comput. Intell. Neurosci. 2018, 2018, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Olanrewaju, L.; Oyebiyi, O.; Misra, S.; Maskeliunas, R.; Damasevicius, R. Secure Ear Biometrics Using Circular Kernel Principal Component Analysis, Chebyshev Transform Hashing and Bose-Chaudhuri-Hocquenghem Error-Correcting Codes. Signal Image Video Process. 2020, 14, 847–855. [Google Scholar] [CrossRef]
- Chai, T.Y.; Goi, B.M.; Tay, Y.H.; Jin, Z. A New Design for Alignment-Free Chaffed Cancelable Iris Key Binding Scheme. Symmetry 2019, 11, 164. [Google Scholar] [CrossRef]
- Mohsin, A.H.; Zaidan, A.A.; Zaidan, B.B.; Albahri, O.S.; Ariffin, S.A.B.; Alemran, A.; Enaizan, O.; Shareef, A.H.; Jasim, A.N.; Jalood, N.S.; et al. Finger Vein Biometrics: Taxonomy Analysis, Open Challenges, Future Directions, and Recommended Solution for Decentralised Network Architectures. IEEE Access 2020, 8, 9821–9845. [Google Scholar] [CrossRef]
- Bodo, A. Method for Producing a Digital Signature with Aid of a Biometric Feature. German Patent 4243908 A1, 30 June 1994. [Google Scholar]
- Davida, G.I.; Frankel, Y.; Matt, B.J. On Enabling Secure Applications through Off-Line Biometric Identification. In Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, USA, 3–6 May 1998; pp. 148–157. [Google Scholar]
- Davida, G.I.; Frankel, Y.; Matt, B.J.; Peralta, R. On the Relation of Error Correction and Cryptography to an Offline Biometric Based Identification Scheme. In Proceedings of the International Workshop on Coding and Cryptography (WCC), Paris, France, 11–14 January 1999; pp. 129–138. [Google Scholar]
- Vielhauer, C.; Steinmetz, R.; Mayerhofer, A. Biometric Hash Based on Statistical Features of Online Signatures. In Proceedings of the 16th International Conference on Pattern Recognition (ICPR), Quebec City, QC, Canada, 11–15 August 2002. [Google Scholar]
- Feng, H.; Wah, C.C. Private Key Generation from On-Line Hand-written Signatures. Inf. Manag. Comput. Secur. 2002, 10, 159–164. [Google Scholar] [CrossRef]
- Drahanský, M. Biometric Security Systems Fingerprint Recognition Technology. Ph.D. Thesis, Dept. Information Technology, Brno University of Technology, Brno, Czech Republic, 2005. [Google Scholar]
- Li, Q.; Guo, M.; Chang, E.C. Fuzzy Extractors for Asymmetric Biometric Representations. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, Alaska, 23–28 June 2008; pp. 1–6. [Google Scholar]
- Li, Q.; Chang, E.C. Robust, Short and Sensitive Authentication Tags Using Secure Sketch. In Proceedings of the 8th Workshop on Multimedia and Security, Geneva, Switzerland, 26–27 September 2006; pp. 56–61. [Google Scholar]
- Sutcu, Y.; Li, Q.; Memon, N. Protecting Biometric Templates with Sketch: Theory and Practice. IEEE Trans. Inf. Forensics Secur. 2007, 2, 503–512. [Google Scholar] [CrossRef]
- Anees, A.; Chen, Y.P.P. Discriminative Binary Feature Learning and Quantization in Biometric Key Generation. Pattern Recognit. 2018, 77, 289–305. [Google Scholar] [CrossRef]
- Yuliana, M.; Wirawan, S. A Simple Secret Key Generation by Using a Combination of Pre-Processing Method with a Multilevel Quantization. Entropy 2019, 21, 192. [Google Scholar] [CrossRef]
- Chen, Y.; Wo, Y.; Xie, R.; Wu, C.; Han, G. Deep Secure Quantization: On Secure Biometric Hashing against Similarity-Based Attacks. Signal Process. 2019, 154, 314–323. [Google Scholar] [CrossRef]
- Ratha, N.K.; Connell, J.H.; Bolle, R.M. Enhancing Security and Privacy in Biometrics-Based Authentication Systems. IBM Syst. J. 2001, 40, 614–634. [Google Scholar] [CrossRef]
- Zuo, J.; Ratha, N.K.; Connell, J.H. Cancelable Iris Biometric. In Proceedings of the 19th International Conference on Pattern Recognition (ICPR), Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]
- Savvides, M.; Kumar, B.V.; Khosla, P. Cancelable Biometric Filters for Face Recognition. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR), Cambridge, UK, 26 August 2004; pp. 922–925. [Google Scholar]
- Trivedi, A.K.; Thounaojam, D.M.; Pal, S. Non-Invertible Cancellable Fingerprint Template for Fingerprint Biometric. Comput. Secur. 2020, 90, 101690. [Google Scholar] [CrossRef]
- Barman, S.; Samanta, D.; Chattopadhyay, S. Approach to Cryptographic Key Generation from Fingerprint Biometrics. Int. J. Biometr. 2015, 7, 226–248. [Google Scholar] [CrossRef]
- Gaddam, S.V.K.; Lal, M. Efficient Cancellable Biometric Key Generation Scheme for Cryptography. Int. J. Netw. Secur. 2010, 11, 57–65. [Google Scholar]
- Kaur, H.; Khanna, P. Random Slope Method for Generation of Cancelable Biometric Features. Pattern Recognit. Lett. 2019, 126, 31–40. [Google Scholar] [CrossRef]
- Neethu, C.; Ali Akbar, N. Revocable Session Key Generation Using Combined Fingerprint Template. In Proceedings of the International Conference on Control, Power, Communication and Computing Technologies (ICCPCCT), Kannur, India, 23–24 March 2018; pp. 584–588. [Google Scholar]
- Punithavathi, P.; Subbiah, G. Partial DCT-Based Cancelable Biometric Authentication with Security and Privacy Preservation for IoT Applications. Multimed. Tools Appl. 2019, 78, 1–28. [Google Scholar] [CrossRef]
- González-Rodríguez, J.; Torre-Toledano, D.; Ortega-García, J. Voice Biometrics. In Handbook of Biometrics; Jain, A.K., Flynn, P., Ross, A.A., Eds.; Springer: Boston, MA, USA, 2008; pp. 151–170. [Google Scholar]
- Quatieri, T.F. Discrete-Time Speech Signal Processing: Principles and Practice; Pearson Education: Lexington, MA, USA, 2008. [Google Scholar]
- Varile, G.B.; Cole, R.; Cole, R.A.; Zampolli, A.; Mariani, J.; Uszkoreit, H.; Zaenen, A. Survey of the State of the Art in Human Language Technology; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Beigi, H. Fundamentals of Speaker Recognition; Springer: New York, NY, USA, 2011. [Google Scholar]
- Saquib, Z.; Salam, N.; Nair, R.P.; Pandey, N.; Joshi, A. A Survey on Automatic Speaker Recognition Systems. Commun. Comput. Inf. Sci. 2010, 123, 134–145. [Google Scholar]
- Tirumala, S.S.; Shahamiri, S.R.; Garhwal, A.S.; Wang, R. Speaker Identification Features Extraction Methods: A Systematic Review. Expert Syst. Appl. 2017, 90, 250–271. [Google Scholar] [CrossRef]
- Meng, Z.; Altaf, M.U.B.; Juang, B.H.F. Active Voice Authentication. Digit. Signal Process. 2020, 101, 1–39. [Google Scholar] [CrossRef]
- Singh, A.P.; Nath, R.; Kumar, S. A Survey: Speech Recognition Approaches and Techniques. In Proceedings of the 5th IEEE Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON), Gorakhpur, India, 2–4 November 2018; pp. 1–4. [Google Scholar]
- Stoica, P.; Moses, R. Spectral Analysis of Signals; Prentice Hall: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Marple, S.L. Digital Spectral Analysis with Applications; Prentice Hall: Englewood Cliffs, NJ, USA, 1987. [Google Scholar]
- Oppenheim, A.V.; Schafer, R.W. Discrete-Time Signal Processing; Prentice Hall: Englewood Cliffs, NJ, USA, 1989. [Google Scholar]
- Welch, P.D. The Use of Fast Fourier Transform for the Estimation of Power Spectra: A Method Based on Time Averaging over Short, Modified Periodograms. IEEE Trans. Audio Electroacoust. 1967, 15, 70–73. [Google Scholar] [CrossRef]
- Stoica, P.; Moses, R. Introduction to Spectral Analysis; Prentice Hall: Englewood Cliffs, NJ, USA, 1989; pp. 52–54. [Google Scholar]
- European Union Agency for Network and Information Security (ENISA). Algorithms, Key Size and Parameters Report; ENISA: Heraklion, Greece, 2014. [Google Scholar]
- Rivest, R.; Shamir, A.; Adleman, L. A Method for Obtaining Digital Signatures and Public-Key Cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Elgamal, T. A Public Key Cryptosystem and a Signature Scheme Based on Discrete Logarithms. IEEE Trans. Inf. Theory 1985, 31, 469–472. [Google Scholar] [CrossRef]
- Miller, V.S. Use of Elliptic Curves in Cryptography. In Proceedings of the Crypto, Advances in Cryptology; Springer; Berlin/Heidelberg, Germany, 1985; pp. 417–426. [Google Scholar]
- Koblitz, N. A Course in Number Theory and Cryptography; Springer: New York, NY, USA, 1987. [Google Scholar]
- Paillier, P. Public-Key Cryptosystems Based on Composite Degree Residuosity Classes. In Proceedings of the EUROCRYPT, Advances in Cryptology; Springer; Berlin/Heidelberg, Germany, 1999; pp. 223–238. [Google Scholar]
- Diffie, W.; Hellman, M. New Directions in Cryptography. IEEE Trans. Inf. Theory 1976, 22, 644–654. [Google Scholar] [CrossRef]
- Merkle, R.C. Secure Communications over Insecure Channels. Commun. ACM 1978, 21, 294–299. [Google Scholar] [CrossRef]
- O’Higgins, B.; Diffie, W.; Strawczynski, L.; Hoog, R. Encryption and ISDN—A Natural Fit. In Proceedings of the International Switching Symposium (ISS), Phoenix, AZ, USA, 15–21 March 1987; pp. 863–869. [Google Scholar]
- Certicom Research. Standards for Efficient Cryptography, SEC 1: Elliptic Curve Cryptography; Certicom: Waterloo, ON, Canada, 2009; pp. 56–60. [Google Scholar]
- Canetti, R.; Krawczyk, H. Analysis of Key-Exchange Protocols and their Use for Building Secure Channels. Proc. Eurocrypt Adv. Cryptol. 2001, 2045, 453–474. [Google Scholar]
- National Institute of Standards and Technology (NIST). Advanced Encryption Standard (AES). FIPS 197; NIST: Gaithersburg, MD, USA, 2001. [Google Scholar]
- National Institute of Standards and Technology (NIST). Data Encryption Standard (DES). FIPS 46; NIST: Gaithersburg, MD, USA, 1977. [Google Scholar]
- Singh, M.; Singh, R.; Ross, A. A Comprehensive Overview of Biometric Fusion. Inf. Fusion 2019, 52, 187–205. [Google Scholar] [CrossRef]
- Bloom, B.H. Space/Time Trade-offs in Hash Coding with Allowable Errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Gómez-Barrero, M.; Rathgeb, C.; Li, G.; Ramachandra, R.; Galbally, J.; Bush, C. Multi-Biometric Template Protection Based on Bloom Filters. Inf. Fusion 2018, 42, 37–50. [Google Scholar] [CrossRef]
- Rathgeb, C.; Busch, C. Cancelable Multi-Biometrics: Mixing Iris-Code Based on Adaptative Bloom Filters. Comput. Secur. 2014, 42, 1–12. [Google Scholar] [CrossRef]
- Ding, Y.; Rattani, A.; Ross, A. Bayesian Belief Models for Integrating Match Scores with Liveness and Quality Measures in a Fingerprint Verification System. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; Volume 4, pp. 1–8. [Google Scholar]
- Liu, Y.; Yan, J.; Ouyang, W. Quality Aware Network for Set to Set Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4694–4703. [Google Scholar]
- National Institute of Standards and Technology (NIST). Secure Hash Standard (SHS); FIPS 180-4; NIST: Gaithersburg, MD, USA, 2015. [Google Scholar]
- Rivest, R. The MD5 Message-Digest Algorithm; RFC. 1321; Massachusetts Institute of Technology, Laboratory for Computer Science: Cambridge, MA, USA, 1992. [Google Scholar]
- National Institute of Standards and Technology (NIST). Recommendation for Applications Using Approved Hash Algorithms.; SP 800-107; NIST: Gaithersburg, MD, USA, 2012. [Google Scholar]
- National Institute of Standards and Technology (NIST). Research Results on SHA-1 Collisions. CSRC; NIST: Gaithersburg, MD, USA, 2017. [Google Scholar]
- National Institute of Standards and Technology (NIST). NIST Selects Winner of Secure Hash Algorithm (SHA-3) Competition; NIST: Gaithersburg, MD, USA, 2012. [Google Scholar]
- National Institute of Standards and Technology (NIST). SHA-3 Standard: Permutation-Based Hash and Extendable-Output Functions; FIPS 202; NIST: Gaithersburg, MD, USA, 2015. [Google Scholar]
- Mendel, F.; Nad, T.; Schläffer, M. Improving Local Collisions: New Attacks on Reduced SHA-256. Proc. Eurocrypt Adv. Cryptol. 2013, 7881, 262–278. [Google Scholar]
- Dobraunig, C.; Eichlseder, M.; Mendel, F. Analysis of SHA-512/224 and SHA-512/256. Proc. Asiacrypt Adv. Cryptol. 2015, 9453, 612–630. [Google Scholar]
- Khovratovich, D.; Rechberger, C.; Savelieva, A. Bicliques for Preimages: Attacks on Skein-512 and the SHA-2 Family. In Proceedings of the 19th International Workshop on Fast Software Encryption, Washington, DC, USA, 19–21 March 2012; pp. 244–263. [Google Scholar]
- Morawiecki, P.; Pieprzyk, J.; Srebrny, M. Rotational Cryptanalysis of Round-Reduced Keccak. In Proceedings of the 21st International Workshop on Fast Software Encryption, London, UK, 3–5 March 2014; pp. 241–262. [Google Scholar]
- Amy, M.; Di Matteo, O.; Gheorghiu, V.; Mosca, M.; Parent, A.; Schanck, J. Estimating the Cost of Generic Quantum Pre-image Attacks on SHA-2 and SHA-3. Sel. Areas Cryptogr. 2017, 10532, 317–337. [Google Scholar]
- ECRYPT II; eBACS. ECRYPT Benchmarking of Cryptographic Systems. Available online: http://bench.cr.yp.to (accessed on 28 May 2020).
- Miller, F. Telegraphic Code to Insure Privacy and Secrecy in the Transmission of Telegrams; C.M. Cornwell: New York, NY, USA, 1882. [Google Scholar]
- Bellovin, S.M. Frank Miller: Inventor of the One-Time Pad. Cryptologia 2011, 35, 203–222. [Google Scholar] [CrossRef]
- Vernam, G.S. Secret Signaling System. U.S. Patent 1310719 A, 22 July 1919. [Google Scholar]
- Shannon, C.E. Communication Theory of Secrecy Systems. Bell Syst. Tech. J. 1949, 28, 656–715. [Google Scholar] [CrossRef]
- Crandall, R.; Pomerance, C.B. Prime Numbers: A Computational Perspective; Springer Science & Business Media: New York, NY, USA, 2005. [Google Scholar]
- Lenstra, H. Factoring Integers with Elliptic Curves. Ann. Math. 1987, 126, 649–673. [Google Scholar] [CrossRef]
- Bellare, M.; Rogaway, P. Introduction to Modern Cryptography; Mihir Bellare and Phillip Rogaway: San Diego, CA, USA, 1997–2005. [Google Scholar]
- Cramer, R.; Shoup, V. A Practical Public Key Cryptosystem Provably Secure against Adaptive Chosen Ciphertext Attack. In Advances in Cryptology; Springer: Berlin/Heidelberg, Germany, 1998; pp. 13–25. [Google Scholar]
- Mozilla.org. Common Voice. Available online: https://voice.mozilla.org (accessed on 23 July 2020).





© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jara-Vera, V.; Sánchez-Ávila, C. Cryptobiometrics for the Generation of Cancellable Symmetric and Asymmetric Ciphers with Perfect Secrecy. Mathematics 2020, 8, 1536. https://doi.org/10.3390/math8091536
Jara-Vera V, Sánchez-Ávila C. Cryptobiometrics for the Generation of Cancellable Symmetric and Asymmetric Ciphers with Perfect Secrecy. Mathematics. 2020; 8(9):1536. https://doi.org/10.3390/math8091536
Chicago/Turabian StyleJara-Vera, Vicente, and Carmen Sánchez-Ávila. 2020. "Cryptobiometrics for the Generation of Cancellable Symmetric and Asymmetric Ciphers with Perfect Secrecy" Mathematics 8, no. 9: 1536. https://doi.org/10.3390/math8091536
APA StyleJara-Vera, V., & Sánchez-Ávila, C. (2020). Cryptobiometrics for the Generation of Cancellable Symmetric and Asymmetric Ciphers with Perfect Secrecy. Mathematics, 8(9), 1536. https://doi.org/10.3390/math8091536