Feasibility of Automatic Seed Generation Applied to Cardiac MRI Image Analysis


Abstract
1. Introduction
- It is representative of the field of medical imaging where data collection and annotation are very expensive, while tasks within the field show large variation.
- It is a basic step in several cardiac descriptors, such as ejection fraction and heart chamber volumes.
- The underlying modality (MRI) presents more challenging features than other modalities, such as reduced resolution and a lower signal-to-noise ratio. Moreover, it is also a radiation-free imaging modality.
- Is it feasible to automate GrowCut by automatically generating seeds?
- How is GrowCut’s performance affected by noisy seeds and seed size?
- We experimentally show the feasibility of automatically generating seeds in the context of a popular interactive image segmentation algorithm, GrowCut [19]. To this end, we also propose a random walk-based method of simulating seeds, which allows the control of seed properties (such as precision and size).
- We propose a method of automatically generating seeds for the task of the whole-heart segmentation of magnetic resonance imaging (MRI) scans.
2. Background
2.1. MRI Whole-Heart Segmentation
2.2. Cellular Automata and GrowCut
- The labels encode the desired segments of the image. At any point, the set of cells having a specific label determines the corresponding pixels of the specific segment.
- The strength of a cell is a value bounded to , which weakly corresponds to the confidence of the algorithm in the label of the cell. Strengths are used by the algorithm to make decisions relating to label propagation between neighboring cells. Usually, the cells corresponding to the seeds have a maximum strength of one.
- The feature value is an image feature associated with the cell. Most commonly, this is the grey intensity or RGB vector of the pixel corresponding to the cell.
| Algorithm 1 Classical GrowCut algorithm applied on an input image I. |
|
2.3. Band-Based GrowCut
2.4. Unsupervised GrowCut
3. Seeds for Image Segmentation
3.1. Automatic Seeds
3.2. Seeds in Controlled Experiments
- A random walk of size that evolves along the foreground.
- A random walk of size that evolves along the background.
4. Seed Generation for MRI Whole-Heart Segmentation
4.1. Task Invariants
- OOI centeredness: the object of interest (the heart) is positioned near the center of the image, having similar scale across images.
- OOI local brightness: OOI is represented by higher gray intensity in its immediately local area.
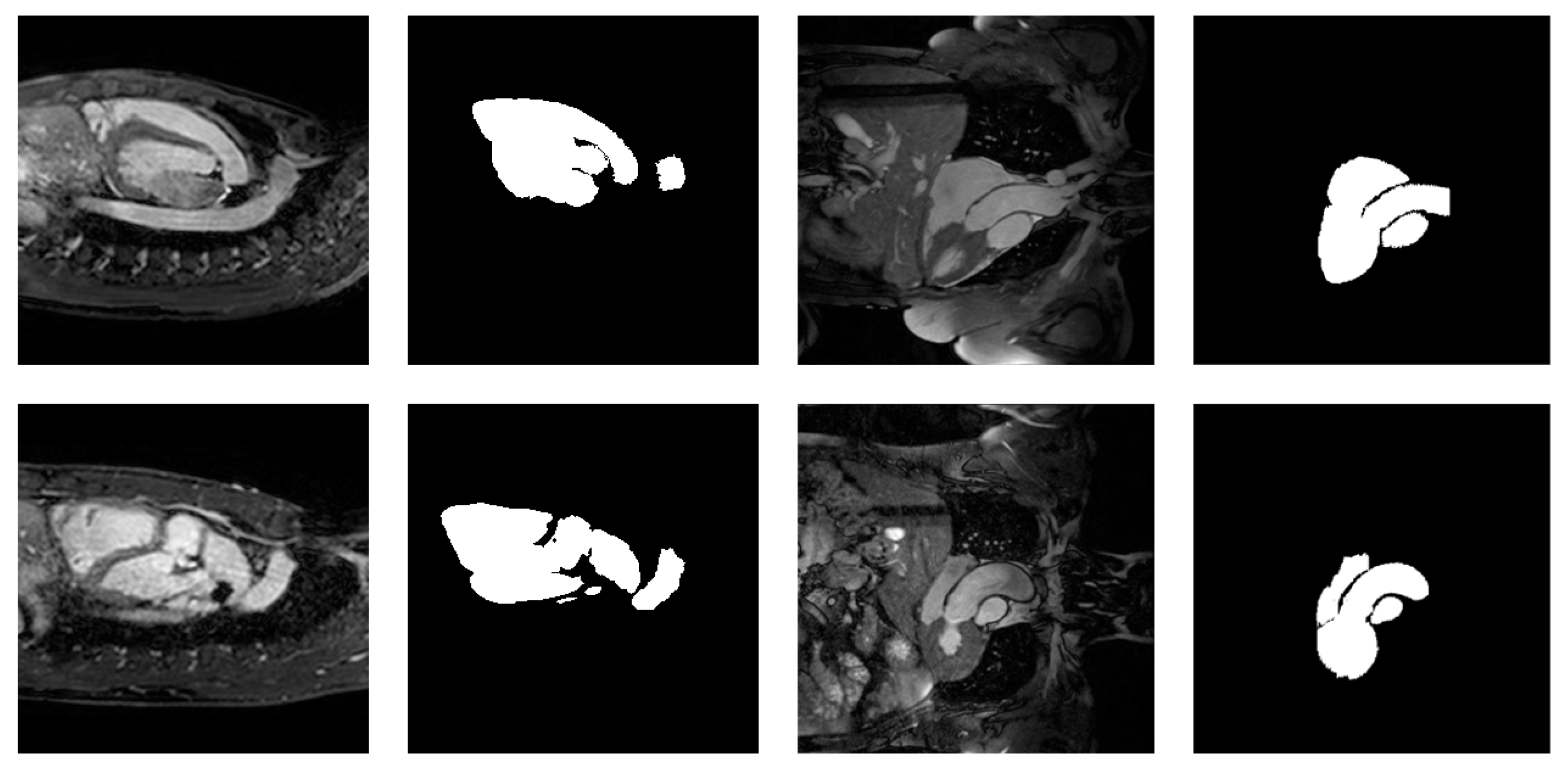
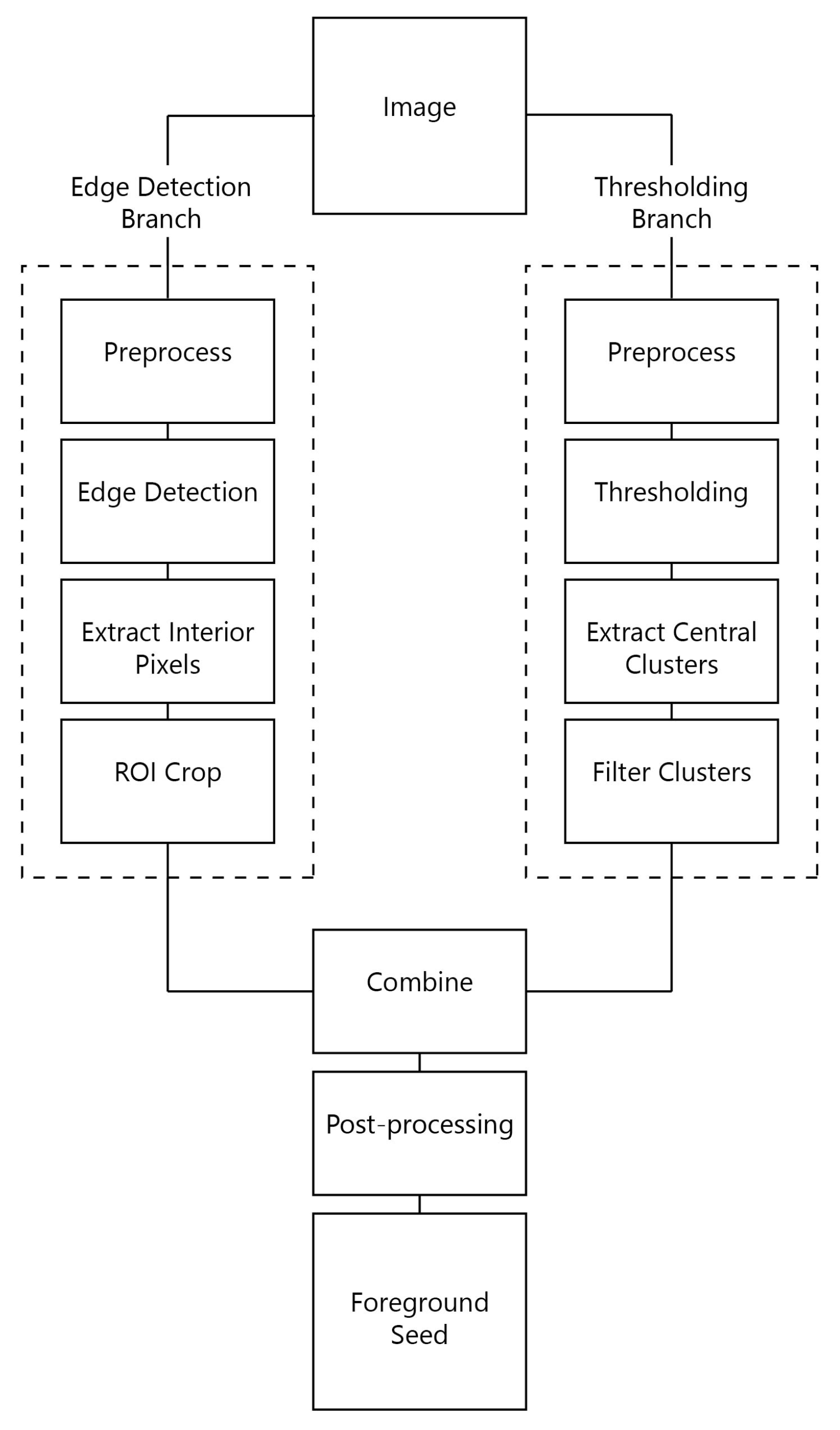
4.2. Method Pipeline
4.3. Method Details
4.4. Computational Complexity
- n is the number of pixels in the input image
- k is the number of iterations for which the algorithm is run
- is the cardinality of the neighborhood system used; e.g., this is eight for GrowCut and 13 for BGC (five extra random remote neighbors)
- is the dimension of the image feature representation. This is one in our case (grayscale images), but can be larger if other feature spaces are used (e.g., texture descriptors or deep learning-based representations).
5. Experiments and Results
- Effects of seed size and seed precision on the segmentation performance (Section 5.4).
- Evaluation of the proposed seed generation method, contrasted with a similar technique from the literature and unsupervised GrowCut (Section 5.5).
5.1. Data
5.2. Algorithm Parameters
5.3. Seeds
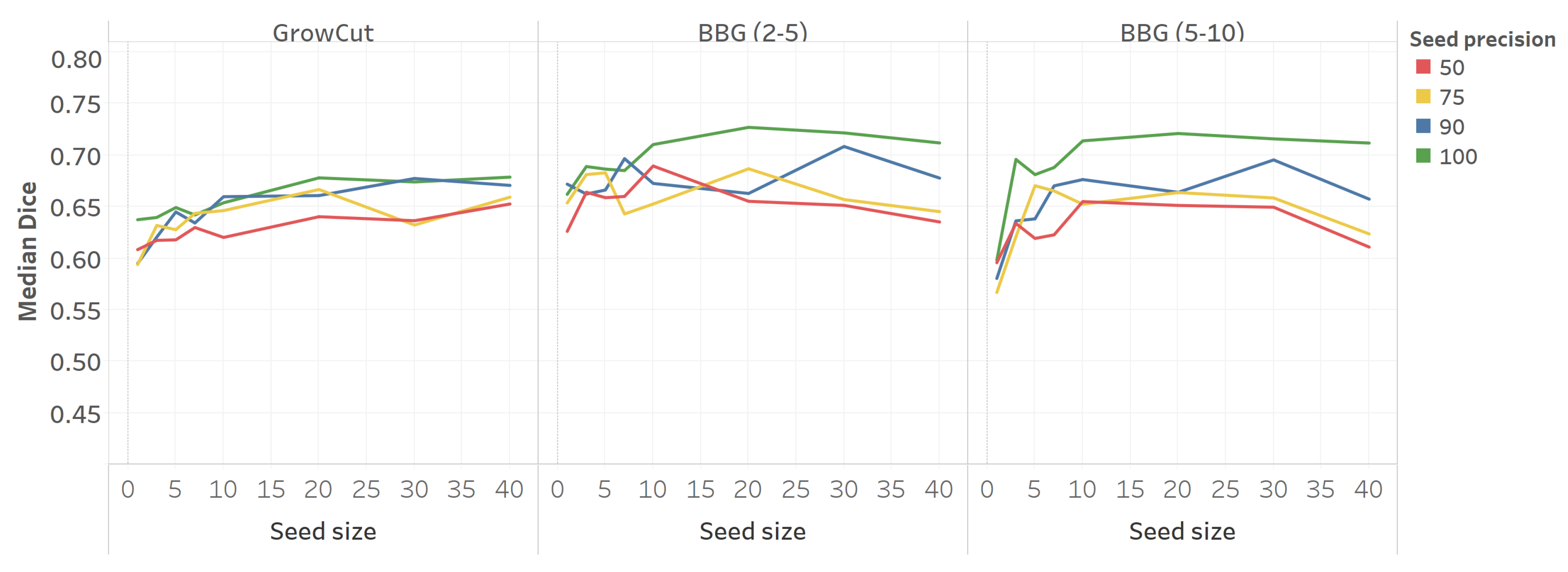
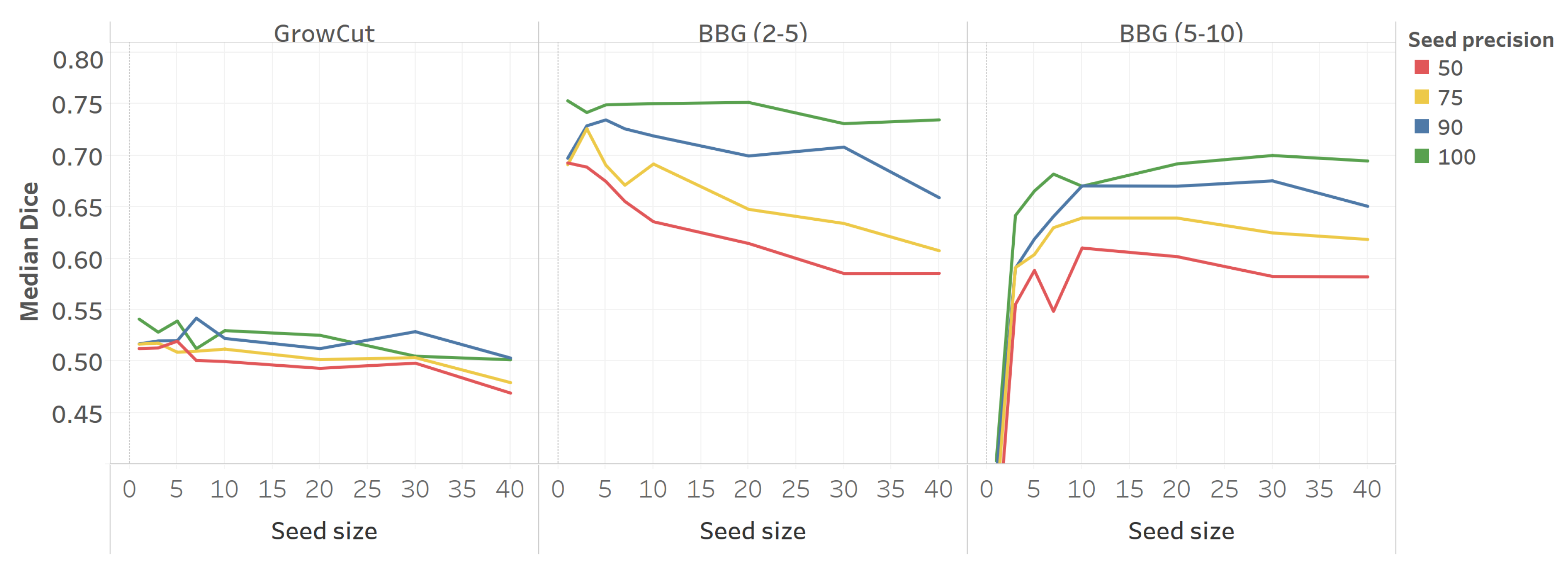
5.4. Seed Generation Feasibility
5.5. Evaluation of the Proposed Method
5.5.1. Feature- and Texture-Based Seeding
- Multiple seed pixels: We adapted the method to select multiple pixels, rather than just one. This was achieved by selecting the top pixels sorted by the cost value used by the original method. In our experiments, we used 300 seed pixels.
- Background seed: Since the method does not produce any background seed, we used the same generator as for our method (i.e., a 1 px square sitting 25 px from the border of the image).
- Different cost function weights: FTS works by computing a cost function and selecting the top pixel in the ROI according to it. The cost function has three components: spatial centrality (spatial distance to the center of the ROI), feature distance (distance in the feature space from the ROI mean feature vector), neighborhood homogeneity (sum of feature distances from the neighbors of a pixel). In our experiments, if we balanced all these components to have the same weight and scale, we obtained seeds that were centered around the center of the ROI, since the spatial centrality component dominated the entire cost function. In order to escape this, we explored different weights for the cost components and fixed them to 0.2 (spatial centrality), 0.7 (feature distance), and 0.1 (neighborhood homogeneity).
5.5.2. Unsupervised GrowCut
5.5.3. Evaluation
5.6. Discussion
6. Conclusions
- Investigate the interaction between different seed properties and segmentation performance, both in supervised and imperfect precision regimes.
- Design more sophisticated computer vision methods for a better control over the proposed seed properties.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Masood, S.; Sharif, M.; Masood, A.; Yasmin, M.; Raza, M. A survey on medical image segmentation. Curr. Med. Imaging Rev. 2015, 11, 3–14. [Google Scholar] [CrossRef]
- Zaitoun, N.M.; Aqel, M.J. Survey on image segmentation techniques. Procedia Comput. Sci. 2015, 65, 797–806. [Google Scholar] [CrossRef]
- Hosny, A.; Parmar, C.; Quackenbush, J.; Schwartz, L.H.; Aerts, H.J. Artificial intelligence in radiology. Nat. Rev. Cancer 2018, 18, 500. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Summers, R.M. Machine learning and radiology. Med. Image Anal. 2012, 16, 933–951. [Google Scholar] [CrossRef] [PubMed]
- Giger, M.L. Machine learning in medical imaging. J. Am. Coll. Radiol. 2018, 15, 512–520. [Google Scholar] [CrossRef] [PubMed]
- Santos, M.K.; Ferreira Júnior, J.R.; Wada, D.T.; Tenório, A.P.M.; Barbosa, M.H.N.; Marques, P.M.d.A. Artificial intelligence, machine learning, computer-aided diagnosis, and radiomics: Advances in imaging towards to precision medicine. Radiol. Bras. 2019, 52, 387–396. [Google Scholar] [CrossRef]
- Chan, S.; Siegel, E.L. Will machine learning end the viability of radiology as a thriving medical specialty? Br. J. Radiol. 2019, 92, 20180416. [Google Scholar] [CrossRef]
- Fritz, S.; See, L.; Perger, C.; McCallum, I.; Schill, C.; Schepaschenko, D.; Duerauer, M.; Karner, M.; Dresel, C.; Laso-Bayas, J.C.; et al. A global dataset of crowdsourced land cover and land use reference data. Sci. Data 2017, 4, 170075. [Google Scholar] [CrossRef]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Spera, E.; Furnari, A.; Battiato, S.; Farinella, G.M. EgoCart: A Benchmark Dataset for Large-Scale Indoor Image-Based Localization in Retail Stores. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Zhang, C.; Harrison, P.A.; Pan, X.; Li, H.; Sargent, I.; Atkinson, P.M. Scale Sequence Joint Deep Learning (SS-JDL) for land use and land cover classification. Remote Sens. Environ. 2020, 237, 111593. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Li, Y.; Bao, Y.; Yan, W.; Fang, Z.; Lu, H. Contextual deconvolution network for semantic segmentation. Pattern Recognit. 2020, 101, 107152. [Google Scholar] [CrossRef]
- Jaware, T.; Khanchandani, K.; Badgujar, R. A novel hybrid atlas-free hierarchical graph-based segmentation of newborn brain MRI using wavelet filter banks. Int. J. Neurosci. 2020, 130, 499–514. [Google Scholar] [CrossRef] [PubMed]
- Mathew, A.R.; Anto, P.B. Tumor detection and classification of MRI brain image using wavelet transform and SVM. In Proceedings of the 2017 International Conference on Signal Processing and Communication (ICSPC), Tamil Nadu, India, 28–29 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 75–78. [Google Scholar]
- Isensee, F.; Jaeger, P.F.; Full, P.M.; Wolf, I.; Engelhardt, S.; Maier-Hein, K.H. Automatic cardiac disease assessment on cine-MRI via time-series segmentation and domain specific features. In International Workshop on Statistical Atlases and Computational Models of the Heart; Springer: Quebec City, QC, Canada, 2017; pp. 120–129. [Google Scholar]
- Ranschaert, E.R.; Morozov, S.; Algra, P.R. Artificial Intelligence in Medical Imaging: Opportunities, Applications and Risks; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Forsyth, D.A.; Ponce, J. Computer Vision: A Modern Approach; Prentice Hall Professional Technical Reference; ACM: New York, NY, USA, 2002. [Google Scholar]
- Vezhnevets, V.; Konouchine, V. GrowCut—Interactive Multi-Label N-D Image Segmentation By Cellular Automata. In Proceedings of the Graphicon. Russian Academy of Sciences, Novosibirsk Akademgorodok, Russia, 20–24 June 2005; pp. 1–7. [Google Scholar]
- Zhao, F.; Xie, X. An overview of interactive medical image segmentation. Ann. BMVA 2013, 2013, 1–22. [Google Scholar]
- Zhuang, X.; Shen, J. Multi-scale patch and multi-modality atlases for whole-heart segmentation of MRI. Med. Image Anal. 2016, 31, 77–87. [Google Scholar] [CrossRef]
- Bernard, O.; Lalande, A.; Zotti, C.; Cervenansky, F.; Yang, X.; Heng, P.A.; Cetin, I.; Lekadir, K.; Camara, O.; Ballester, M.A.G.; et al. Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: Is the problem solved? IEEE Trans. Med. Imaging 2018, 37, 2514–2525. [Google Scholar] [CrossRef]
- Zhuang, X.; Li, L.; Payer, C.; Štern, D.; Urschler, M.; Heinrich, M.P.; Oster, J.; Wang, C.; Smedby, Ö.; Bian, C.; et al. Evaluation of algorithms for multi-modality whole-heart segmentation: An open-access grand challenge. Med. Image Anal. 2019, 58, 101537. [Google Scholar] [CrossRef]
- Payer, C.; Štern, D.; Bischof, H.; Urschler, M. Multi-label whole-heart segmentation using CNNs and anatomical label configurations. In International Workshop on Statistical Atlases and Computational Models of the Heart; Springer: Berlin/Heidelberg, Germany, 2017; pp. 190–198. [Google Scholar]
- Wang, C.; Smedby, Ö. Automatic whole-heart segmentation using deep learning and shape context. In International Workshop on Statistical Atlases and Computational Models of the Heart; Springer: Quebec City, QC, Canada, 2017; pp. 242–249. [Google Scholar]
- Galisot, G.; Brouard, T.; Ramel, J.Y. Local probabilistic atlases and a posteriori correction for the segmentation of heart images. In International Workshop on Statistical Atlases and Computational Models of the Heart; Springer: Quebec City, QC, Canada, 2017; pp. 207–214. [Google Scholar]
- Heinrich, M.P.; Oster, J. MRI whole-heart segmentation using discrete nonlinear registration and fast non-local fusion. In International Workshop on Statistical Atlases and Computational Models of the Heart; Springer: Quebec City, QC, Canada, 2017; pp. 233–241. [Google Scholar]
- Joyce, T.; Chartsias, A.; Tsaftaris, S. Deep Multi-Class Segmentation without Ground-Truth Labels; Medical Imaging with Deep Learning; University of Edinburgh: Edinburgh, UK, 2018. [Google Scholar]
- Cordero-Grande, L.; Vegas-Sánchez-Ferrero, G.; Casaseca-de-la Higuera, P.; San-Román-Calvar, J.A.; Revilla-Orodea, A.; Martín-Fernández, M.; Alberola-López, C. Unsupervised 4D myocardium segmentation with a Markov Random Field based deformable model. Med. Image Anal. 2011, 15, 283–301. [Google Scholar] [CrossRef]
- Oksuz, I.; Mukhopadhyay, A.; Dharmakumar, R.; Tsaftaris, S.A. Unsupervised myocardial segmentation for cardiac BOLD. IEEE Trans. Med. Imaging 2017, 36, 2228–2238. [Google Scholar] [CrossRef]
- Mukhopadhyay, A.; Oksuz, I.; Bevilacqua, M.; Dharmakumar, R.; Tsaftaris, S.A. Unsupervised myocardial segmentation for cardiac MRI. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 12–20. [Google Scholar]
- Von Neumann, J. Theory of Self-Reproducing Automata; Burks, A.W., Ed.; University of Illinois Press: Urbana, IL, USA, 1966. [Google Scholar]
- Gershenson, C.; Rosenblueth, D. Modeling self-organizing traffic lights with elementary cellular automata. Comput. Res. Repos. 2009, 2017. [Google Scholar] [CrossRef]
- Kita, E.; Toyoda, T. Structural design using cellular automata. Struct. Multidiscip. Optim. 2000, 19, 64–73. [Google Scholar] [CrossRef]
- Chang, C.L.; Zhang, Y.j.; Gdong, Y.Y. Cellular automata for edge detection of images. In Proceedings of the 2004 International Conference on Machine Learning and Cybernetics (IEEE Cat. No. 04EX826), Shanghai, China, 26–29 August 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 6, pp. 3830–3834. [Google Scholar]
- Marginean, R.; Andreica, A.; Diosan, L.; Balint, Z. Butterfly effect in chaotic image segmentation. Entropy 2020, in press. [Google Scholar]
- Ghosh, P.; Antani, S.; Long, L.R.; Thoma, G.R. Unsupervised Grow-Cut: Cellular Automata-Based Medical Image Segmentation. In Proceedings of the 2011 IEEE First International Conference on Healthcare Informatics, Imaging and Systems Biology, San Jose, CA, USA, 26–29 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 40–47. [Google Scholar]
- Marinescu, I.A.; Bálint, Z.; Diosan, L.; Andreica, A. Dynamic autonomous image segmentation based on Grow Cut. In Proceedings of the 26th European Symposium on Artificial Neural Networks (ESANN 2018), Bruges, Belgium, 25–27 April 2018; pp. 67–72. [Google Scholar]
- Marginean, R.; Andreica, A.; Diosan, L.; Bálint, Z. Autonomous Image Segmentation by Competitive Unsupervised GrowCut. In Proceedings of the 2019 21st International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 4–7 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 313–319. [Google Scholar]
- Melouah, A.; Layachi, S. Overview of Automatic seed selection methods for biomedical images segmentation. Int. Arab. J. Inf. Technol. 2018, 15, 499–504. [Google Scholar]
- Adams, R.; Bischof, L. Seeded region growing. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 641–647. [Google Scholar] [CrossRef]
- Mehnert, A.; Jackway, P. An improved seeded region growing algorithm. Pattern Recognit. Lett. 1997, 18, 1065–1071. [Google Scholar] [CrossRef]
- Poonguzhali, S.; Ravindran, G. A complete automatic region growing method for segmentation of masses on ultrasound images. In Proceedings of the 2006 International Conference on Biomedical and Pharmaceutical Engineering, Kuala Lumpur, Malaysia, 11–14 December 2016; IEEE: Piscataway, NJ, USA, 2006; pp. 88–92. [Google Scholar]
- Shan, J.; Cheng, H.D.; Wang, Y. A novel automatic seed point selection algorithm for breast ultrasound images. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–4. [Google Scholar]
- Al-Faris, A.Q.; Ngah, U.K.; Isa, N.A.M.; Shuaib, I.L. Breast MRI tumour segmentation using modified automatic seeded region growing based on particle swarm optimization image clustering. In Soft Computing in Industrial Applications; Springer: Berlin/Heidelberg, Germany, 2014; pp. 49–60. [Google Scholar]
- Al-Faris, A.Q.; Ngah, U.K.; Isa, N.A.M.; Shuaib, I.L. Computer-aided segmentation system for breast MRI tumour using modified automatic seeded region growing (BMRI-MASRG). J. Digit. Imaging 2014, 27, 133–144. [Google Scholar] [CrossRef]
- Wu, J.; Poehlman, S.; Noseworthy, M.D.; Kamath, M.V. Texture feature based automated seeded region growing in abdominal MRI segmentation. In Proceedings of the 2008 International Conference on BioMedical Engineering and Informatics, Sanya, Hainan, China, 28–30 May 2008; IEEE: Piscataway, NJ, USA, 2008; Volume 2, pp. 263–267. [Google Scholar]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Durlak, J.A. How to select, calculate, and interpret effect sizes. J. Pediatr. Psychol. 2009, 34, 917–928. [Google Scholar] [CrossRef]
- Field, A. Discovering Statistics Using IBM SPSS Statistics; Sage: Thousand Oaks, CA, USA, 2013.
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Branch | Stage | Complexity |
|---|---|---|
| Edge | CLAHE | |
| Edge | Canny | |
| Edge | Move + crop | |
| Thresholding | Otsu | |
| Thresholding | Connected components | |
| Thresholding | Filter + extract central component | |
| Thresholding | Dilation | |
| Post-process | Intersection | |
| Post-process | Intensity filter |
| GrowCut | BBG (2–5) | BBG (5–10) | |
|---|---|---|---|
| Seed size | 0.0002 | 0.0002 | 0.0018 |
| Precision | 0.0040 | 0.0149 | 0.0104 |
| GrowCut | BBG (2–5) | BBG (5–10) | |
|---|---|---|---|
| Seed size | 0.0026 | 0.0142 | 0.0919 |
| Precision | 0.0019 | 0.0339 | 0.0182 |
| Contour Seed (Ours) | FTS (Haralick) | UGC | |||||
|---|---|---|---|---|---|---|---|
| GrowCut | BBG (2–5) | BBG (5–10) | GrowCut | BBG (2–5) | BBG (5–10) | ||
| MMWHS | 0.65 | 0.76 | 0.76 | 0.58 | 0.61 | 0.61 | 0.40 |
| imATFIB | 0.42 | 0.70 | 0.71 | 0.51 | 0.67 | 0.64 | 0.14 |
| Contour Seed (Ours) | FTS (Haralick) | UGC | |||||
|---|---|---|---|---|---|---|---|
| GrowCut | BBG (2–5) | BBG (5–10) | GrowCut | BBG (2–5) | BBG (5–10) | ||
| MMWHS | [0.62, 0.72] | [0.70, 0.79] | [0.69, 0.78] | [0.54, 0.65] | [0.58, 0.68] | [0.56, 0.69] | [0.46, 0.45] |
| imATFIB | [0.37, 0.45] | [0.67, 0.73] | [0.67, 0.73] | [0.42, 0.56] | [0.58, 0.70] | [0.54, 0.67] | [0.09, 0.20] |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mărginean, R.; Andreica, A.; Dioşan, L.; Bálint, Z. Feasibility of Automatic Seed Generation Applied to Cardiac MRI Image Analysis. Mathematics 2020, 8, 1511. https://doi.org/10.3390/math8091511
Mărginean R, Andreica A, Dioşan L, Bálint Z. Feasibility of Automatic Seed Generation Applied to Cardiac MRI Image Analysis. Mathematics. 2020; 8(9):1511. https://doi.org/10.3390/math8091511
Chicago/Turabian StyleMărginean, Radu, Anca Andreica, Laura Dioşan, and Zoltán Bálint. 2020. "Feasibility of Automatic Seed Generation Applied to Cardiac MRI Image Analysis" Mathematics 8, no. 9: 1511. https://doi.org/10.3390/math8091511
APA StyleMărginean, R., Andreica, A., Dioşan, L., & Bálint, Z. (2020). Feasibility of Automatic Seed Generation Applied to Cardiac MRI Image Analysis. Mathematics, 8(9), 1511. https://doi.org/10.3390/math8091511