Towards a Better Basis Search through a Surrogate Model-Based Epistasis Minimization for Pseudo-Boolean Optimization



Abstract
1. Introduction
2. Backgrounds and Test Problems
2.1. Basis
- Linear independence property: for every finite subset of B and every in , if , then necessarily
- Spanning property: it is possible to choose in and in B such that for every vector v in V.
2.2. Epistasis
2.3. How to Calculate Epistasis
2.4. Deep Learning
2.5. Surrogate Model
2.6. Test Problems
3. Prior Work on Searching Basis
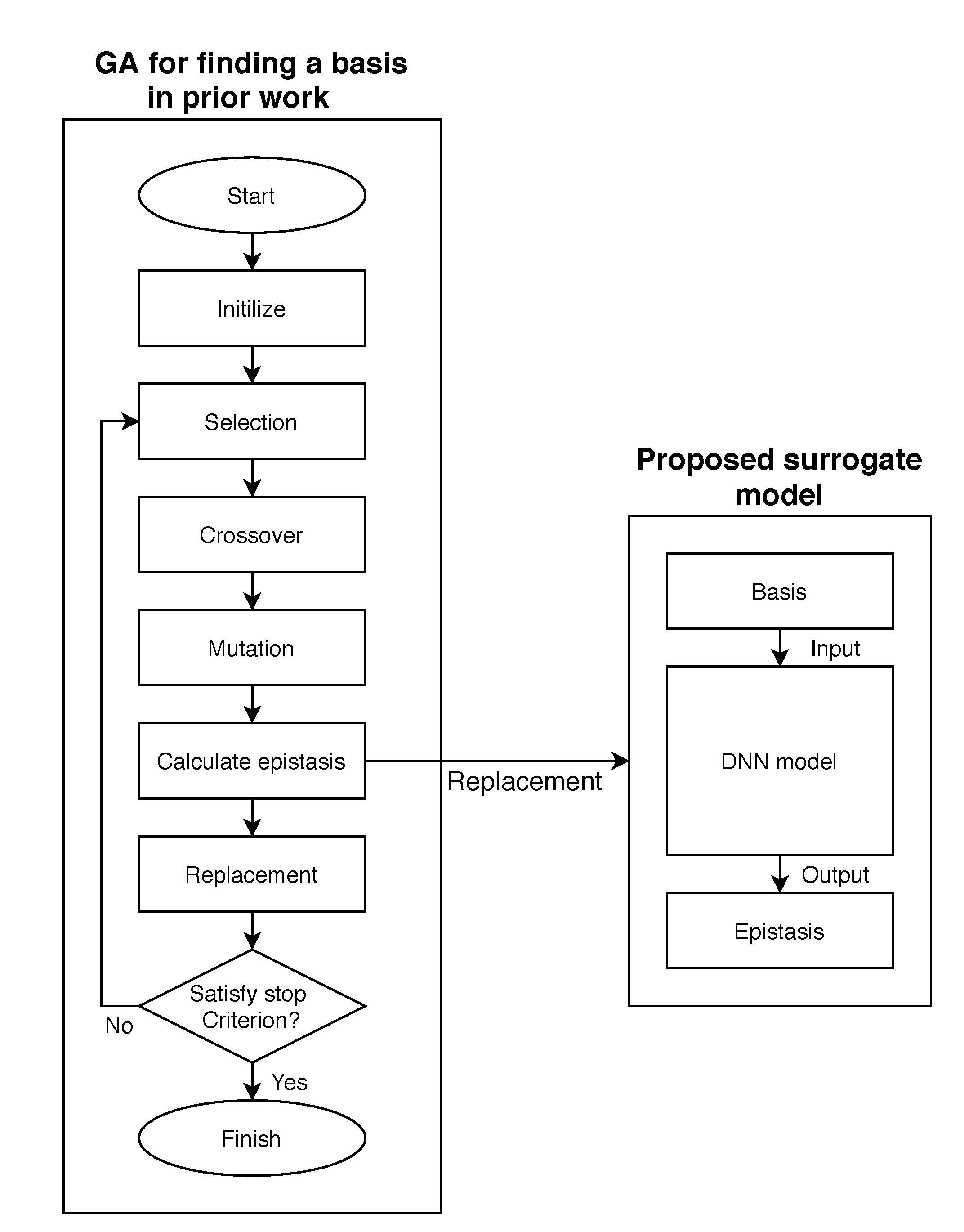
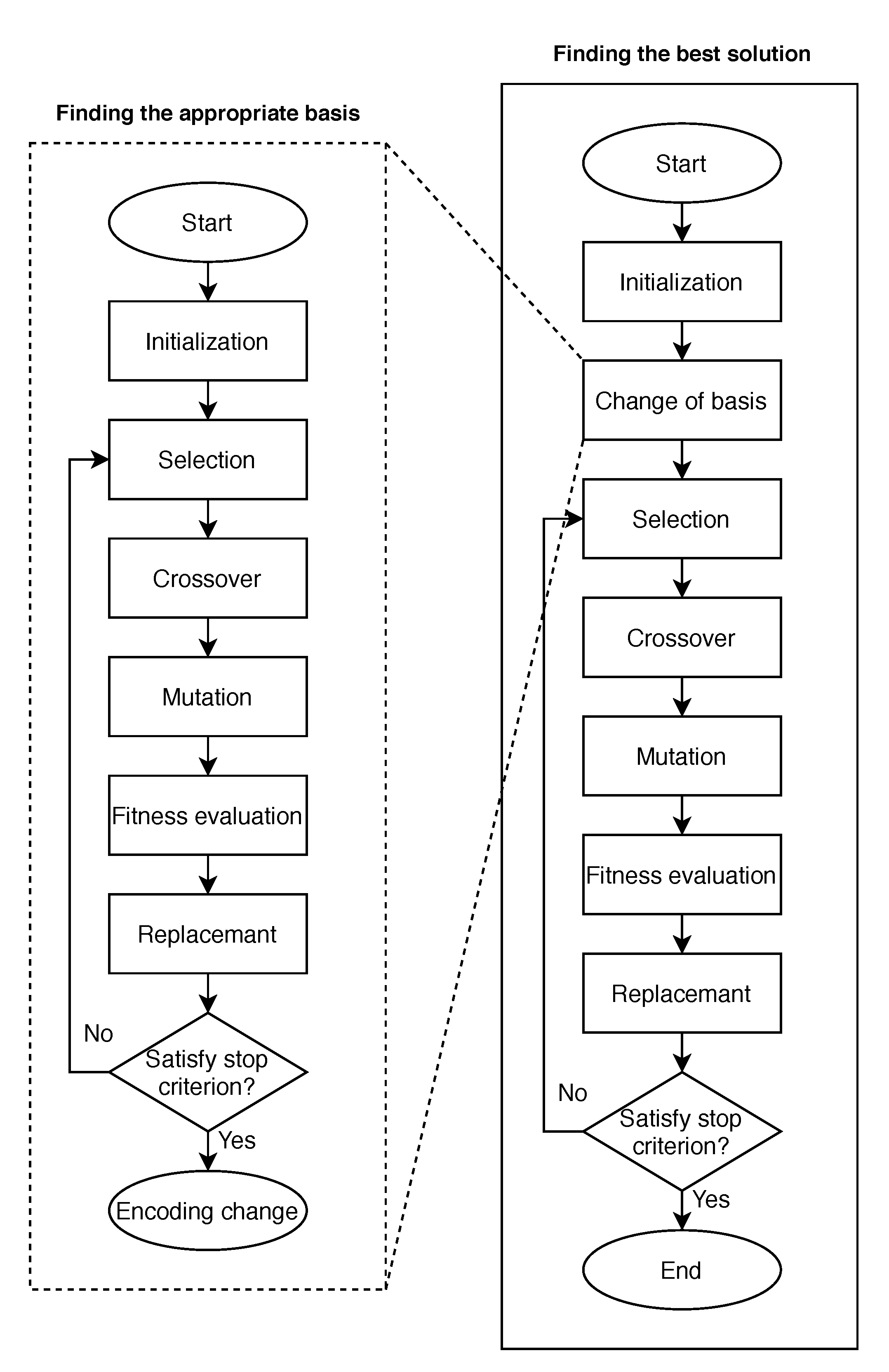
3.1. Basis Searching with a Meta-GA
3.2. Epistasis-based Basis Evaluation
4. Proposed Method Based on Surrogate Model
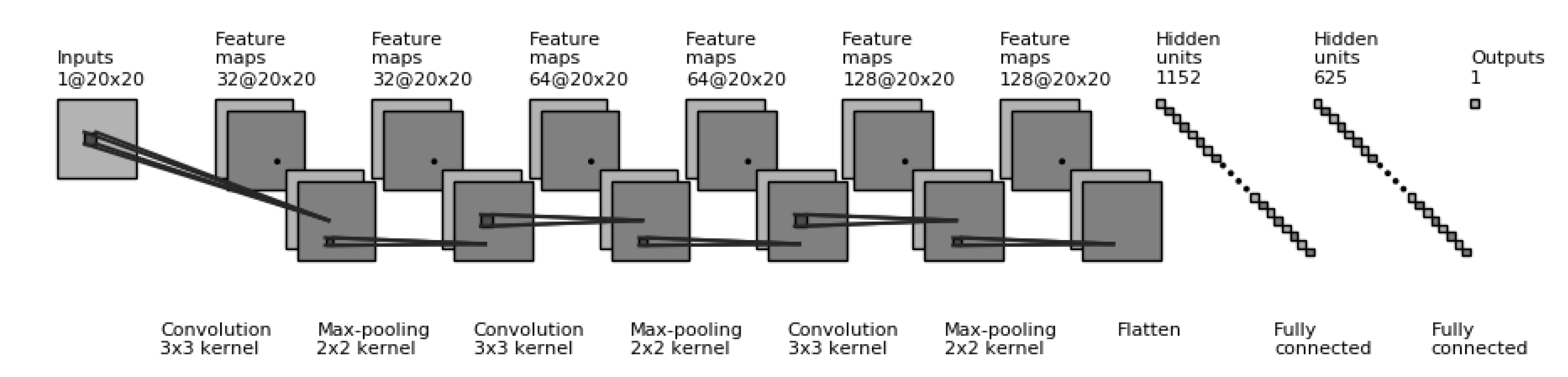
4.1. Surrogate Model-Based Epistasis Estimation Using Deep Learning
4.2. A Genetic Algorithm with Our Surrogate Model
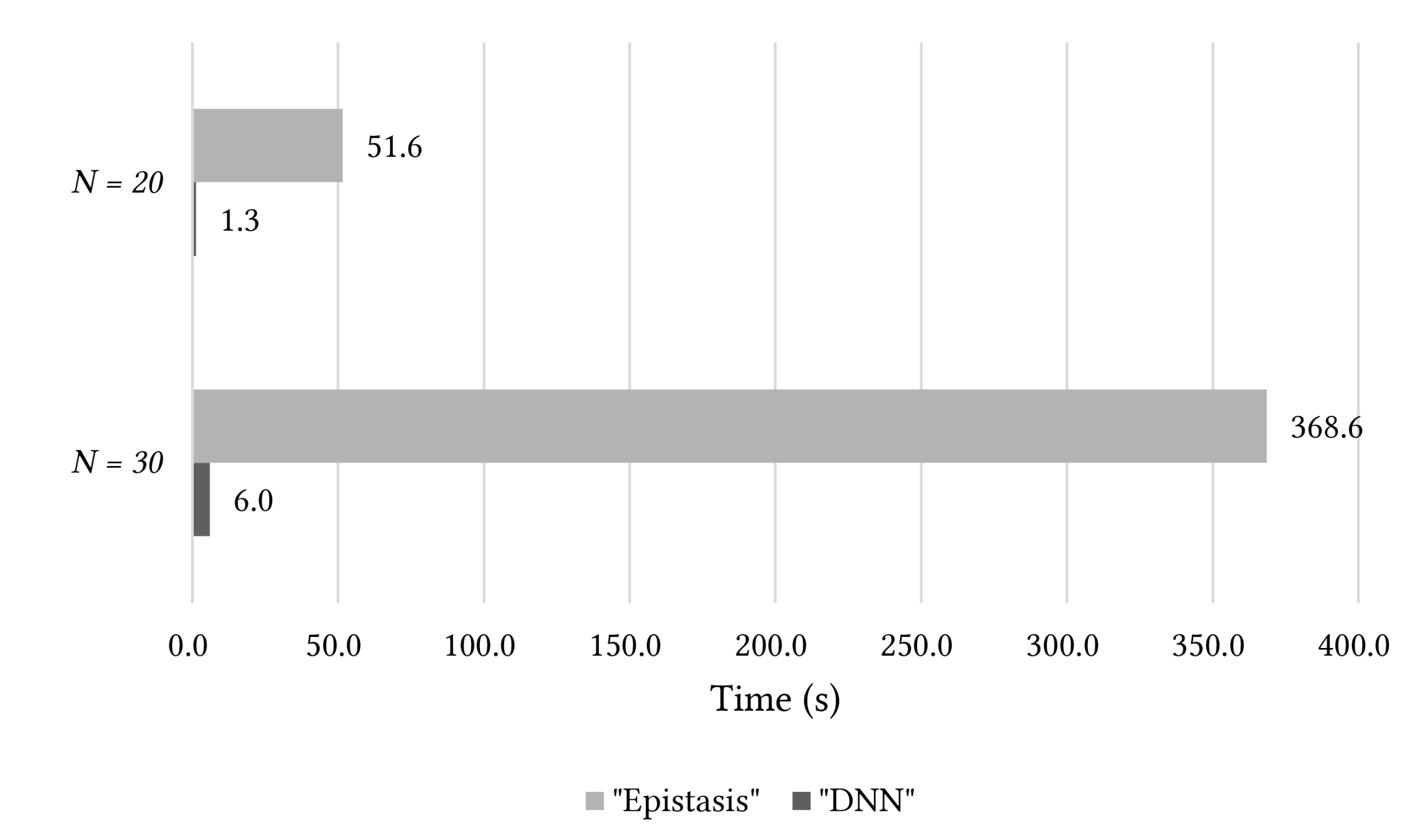
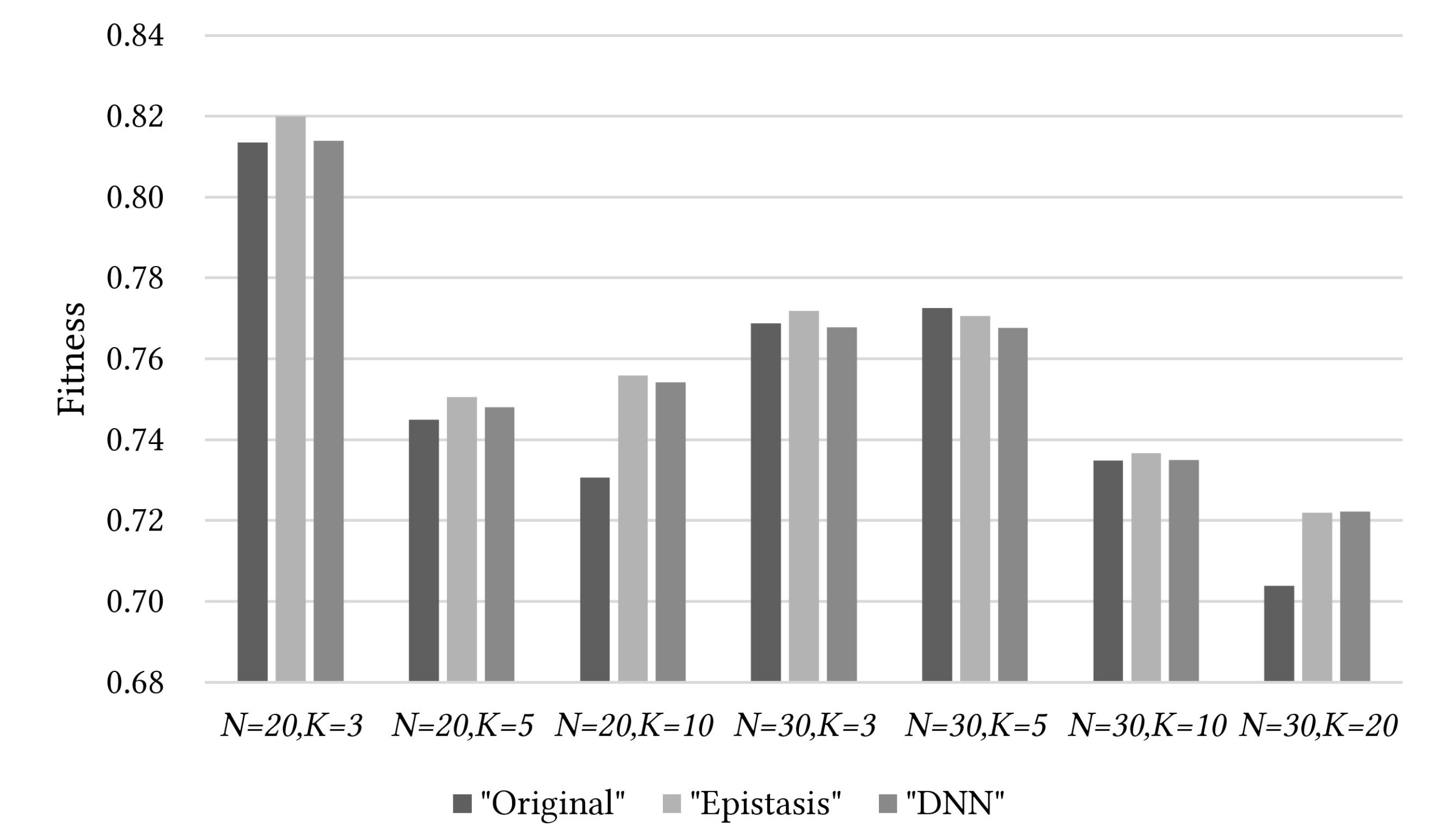
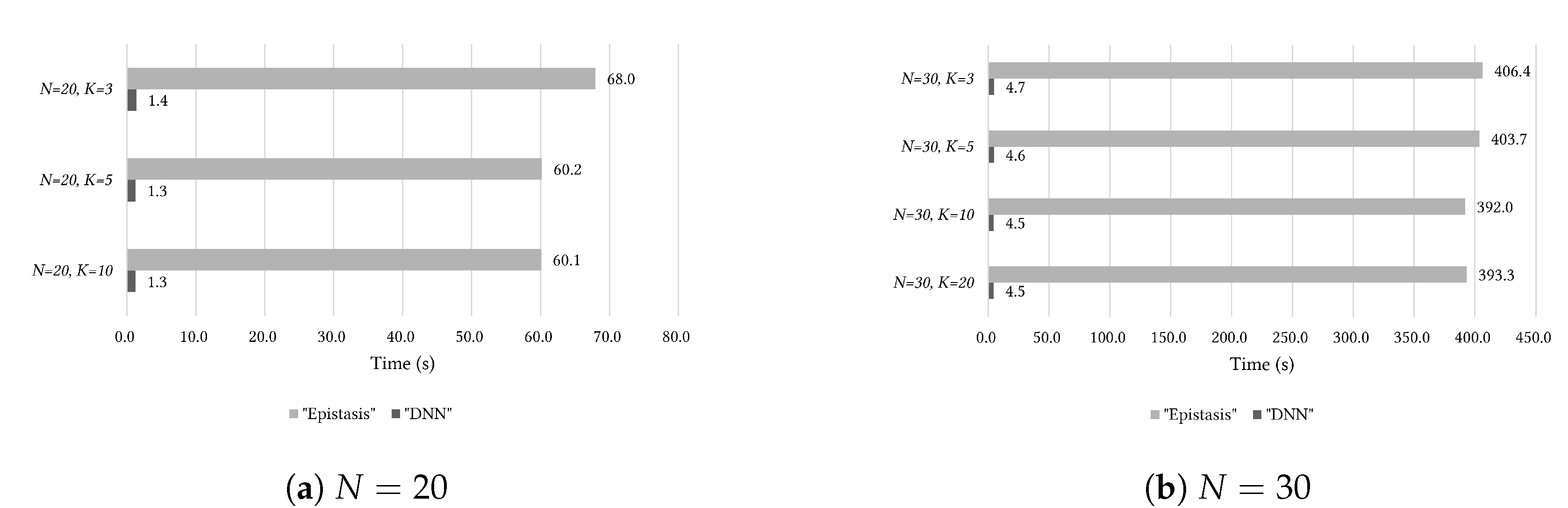
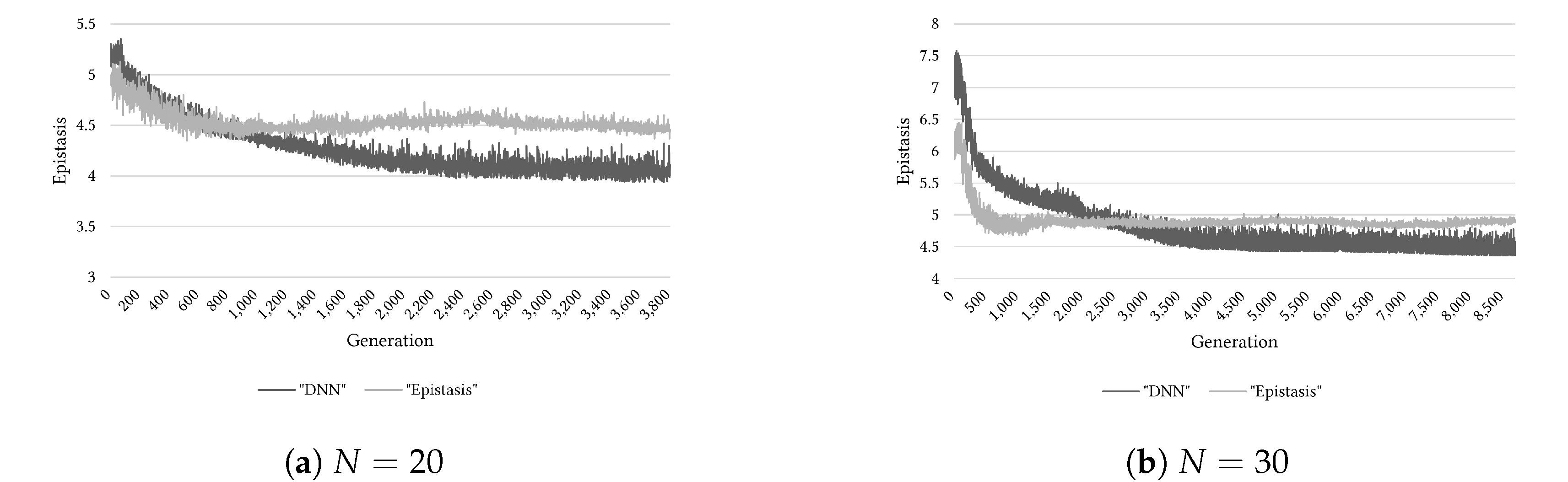
5. Results of Experiments and Discussion
5.1. Test Environments and Dataset
5.2. Results
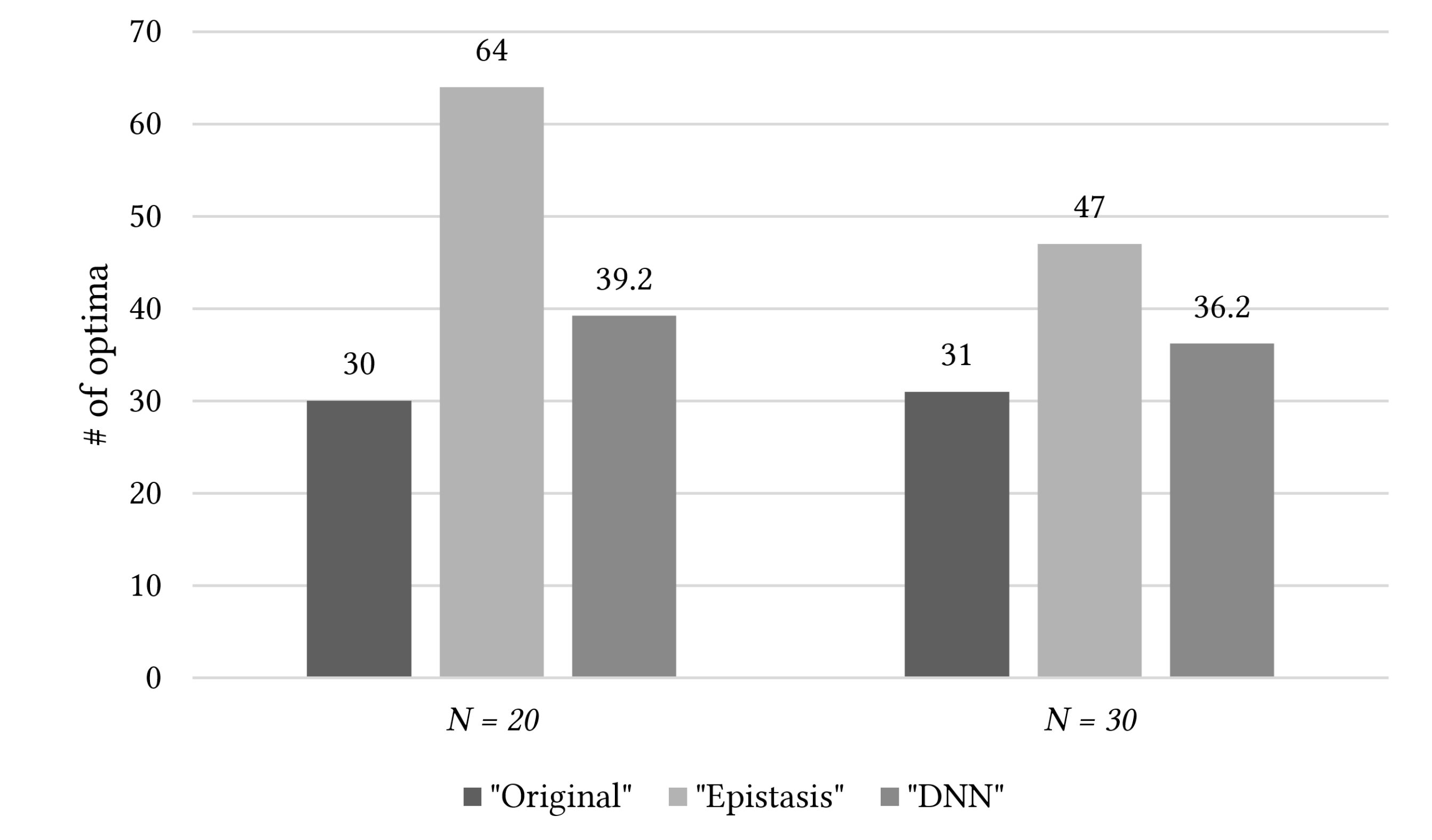
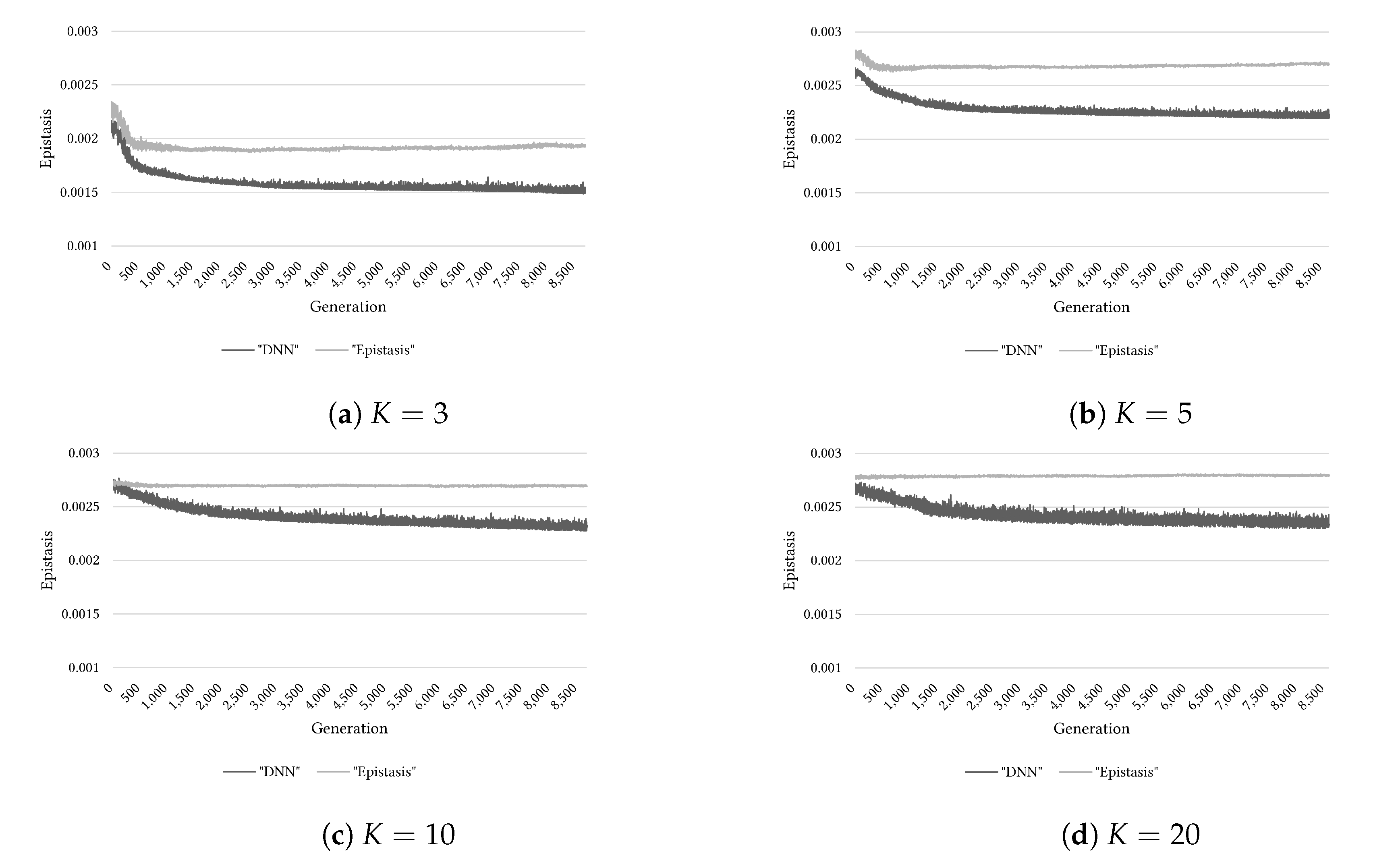
5.3. Epistasis Estimation Based on Basis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tripathy, R.K.; Bilionis, I. Deep UQ: Learning deep neural network surrogate models for high dimensional uncertainty quantification. J. Comput. Phys. 2018, 375, 565–588. [Google Scholar] [CrossRef]
- Pfrommer, J.; Zimmerling, C.; Liu, J.; Kärger, L.; Henning, F.; Beyerer, J. Optimisation of manufacturing process parameters using deep neural networks as surrogate models. Procedia CiRP 2018, 72, 426–431. [Google Scholar] [CrossRef]
- Mbarek, R.; Tmar, M.; Hattab, H. Vector space basis change in information retrieval. Computación y Sistemas 2014, 18, 569–579. [Google Scholar] [CrossRef]
- Mbarek, R.; Tmar, M.; Hattab, H. A new relevance feedback algorithm based on vector space basis change. In International Conference on Intelligent Text Processing and Computational Linguistics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 355–366. [Google Scholar]
- Seo, K.; Hyun, S.; Kim, Y.H. An edge-set representation based on a spanning tree for searching cut space. IEEE Trans. Evol. Comput. 2014, 19, 465–473. [Google Scholar] [CrossRef]
- Kim, Y.H.; Yoon, Y. Effect of changing the basis in genetic algorithms using binary encoding. KSII Trans. Internet Inf. Syst. 2008, 2. [Google Scholar] [CrossRef]
- Reeves, C.R.; Wright, C.C. Epistasis in genetic algorithms: An experimental design perspective. In Proceedings of the International Conference on Genetic Algorithms, Pittsburgh, PA, USA, 15–19 July 1995; pp. 217–224. [Google Scholar]
- Naudts, B.; Kallel, L. A comparison of predictive measures of problem difficulty in evolutionary algorithms. IEEE Trans. Evol. Comput. 2000, 4, 1–15. [Google Scholar] [CrossRef]
- Lee, J.; Kim, Y.H. Importance of finding a good basis in binary representation. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Kyoto, Japan, 15–19 July 2018; pp. 49–50. [Google Scholar]
- Lee, J.; Kim, Y.H. Epistasis-based basis estimation method for simplifying the problem space of an evolutionary search in binary representation. Complexity 2019. [Google Scholar] [CrossRef]
- Meyer, C.D. Matrix Analysis and Applied Linear Algebra; Siam: Philadelphia, PA, USA, 2000; Volume 71. [Google Scholar]
- Hirsch, M.W.; Devaney, R.L.; Smale, S. Differential Equations, Dynamical Systems, and Linear Algebra; Academic Press: Cambridge, MA, USA, 1974; Volume 60. [Google Scholar]
- Davidor, Y. Epistasis variance: Suitability of a representation to genetic algorithms. Complex Syst. 1990, 4, 369–383. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Smolensky, P. Information Processing in Dynamical Systems: Foundations of Harmony Theory; Technical Report; Colorado Univ at Boulder Dept of Computer Science: Boulder, CO, USA, 1986. [Google Scholar]
- Ong, Y.S.; Nair, P.B.; Keane, A.J. Evolutionary optimization of computationally expensive problems via surrogate modeling. AIAA J. 2003, 41, 687–696. [Google Scholar] [CrossRef]
- Sreekanth, J.; Datta, B. Multi-objective management of saltwater intrusion in coastal aquifers using genetic programming and modular neural network based surrogate models. J. Hydrol. 2010, 393, 245–256. [Google Scholar] [CrossRef]
- Eason, J.; Cremaschi, S. Adaptive sequential sampling for surrogate model generation with artificial neural networks. Comput. Chem. Eng. 2014, 68, 220–232. [Google Scholar] [CrossRef]
- Lim, D.; Jin, Y.; Ong, Y.S.; Sendhoff, B. Generalizing surrogate-assisted evolutionary computation. IEEE Trans. Evol. Comput. 2009, 14, 329–355. [Google Scholar] [CrossRef]
- Amouzgar, K.; Bandaru, S.; Ng, A.H. Radial basis functions with a priori bias as surrogate models: A comparative study. Eng. Appl. Artif. Intell. 2018, 71, 28–44. [Google Scholar] [CrossRef]
- Kattan, A.; Galvan, E. Evolving radial basis function networks via GP for estimating fitness values using surrogate models. In Proceedings of the IEEE Congress on Evolutionary Computation, Brisbane, Australia, 10–15 June 2012. [Google Scholar]
- Lange, K.; Hunter, D.R.; Yang, I. Optimization transfer using surrogate objective functions. J. Comput. Graph. Stat. 2000, 9, 1–20. [Google Scholar]
- Manzoni, L.; Papetti, D.M.; Cazzaniga, P.; Spolaor, S.; Mauri, G.; Besozzi, D.; Nobile, M.S. Surfing on fitness landscapes: A boost on optimization by Fourier surrogate modeling. Entropy 2020, 22, 285. [Google Scholar] [CrossRef]
- Yu, D.P.; Kim, Y.H. Predictability on performance of surrogate-assisted evolutionary algorithm according to problem dimension. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Prague, Czech Republic, 13–17 July 2019; pp. 91–92. [Google Scholar]
- Verel, S.; Derbel, B.; Liefooghe, A.; Aguirre, H.; Tanaka, K. A surrogate model based on Walsh decomposition for pseudo-Boolean functions. In International Conference on Parallel Problem Solving from Nature; Springer: Berlin/Heidelberg, Germany, 2018; pp. 181–193. [Google Scholar]
- Leprêtre, F.; Verel, S.; Fonlupt, C.; Marion, V. Walsh functions as surrogate model for pseudo-Boolean optimization problems. In Proceedings of the Genetic and Evolutionary Computation Conference, Prague, Czech Republic, 13–17 July 2019; pp. 303–311. [Google Scholar]
- Swingler, K. Learning and searching pseudo-Boolean surrogate functions from small samples. Evol. Comput. 2020, 28, 317–338. [Google Scholar] [CrossRef]
- Zhu, Y.; Zabaras, N. Bayesian deep convolutional encoder–decoder networks for surrogate modeling and uncertainty quantification. J. Comput. Phys. 2018, 366, 415–447. [Google Scholar] [CrossRef]
- Zhu, Y.; Zabaras, N.; Koutsourelakis, P.S.; Perdikaris, P. Physics-constrained deep learning for high-dimensional surrogate modeling and uncertainty quantification without labeled data. J. Comput. Phys. 2019, 394, 56–81. [Google Scholar] [CrossRef]
- Karavolos, D.; Liapis, A.; Yannakakis, G.N. Using a surrogate model of gameplay for automated level design. In Proceedings of the 2018 IEEE Conference on Computational Intelligence and Games (CIG), Maastricht, The Netherlands, 14–17 August 2018; pp. 1–8. [Google Scholar]
- Melo, A.; Cóstola, D.; Lamberts, R.; Hensen, J. Development of surrogate models using artificial neural network for building shell energy labelling. Energy Policy 2014, 69, 457–466. [Google Scholar] [CrossRef]
- Kourakos, G.; Mantoglou, A. Pumping optimization of coastal aquifers based on evolutionary algorithms and surrogate modular neural network models. Adv. Water Resour. 2009, 32, 507–521. [Google Scholar] [CrossRef]
- Kim, H.J.; Kim, Y.H. A Surrogate Model Using Deep Neural Networks for Optimal Oil Skimmer Assignment. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Cancun, Mexico, 8–12 July 2020; pp. 39–40. [Google Scholar]
- Kauffman, S.A.; Weinberger, E.D. The NK model of rugged fitness landscapes and its application to maturation of the immune response. J. Theor. Biol. 1989, 141, 211–245. [Google Scholar] [CrossRef]
- Weinberger, E.D. NP Completeness of Kauffman’S NK Model, a Tuneably Rugged Fitness Landscape; Santa Fe Institute Technical Reports; Santa Fe Institute: Santa Fe, NM, USA, 1996. [Google Scholar]
- Yoon, Y.; Kim, Y.H. A mathematical design of genetic operators on GLn(ℤ2). Math. Probl. Eng. 2014, 2014. [Google Scholar] [CrossRef]
- Wagner, R.A.; Fischer, M.J. The string-to-string correction problem. J. ACM (JACM) 1974, 21, 168–173. [Google Scholar] [CrossRef]
- Kim, Y.H.; Lee, J.; Kim, Y.H. Predictive model for epistasis-based basis evaluation on pseudo-Boolean function using deep neural networks. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Prague, Czech Republic, 13–17 July 2019; pp. 61–62. [Google Scholar]
- Kim, Y.H.; Kim, Y.H. Finding a better basis on binary representation through DNN-based epistasis estimation. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Cancun, Mexico, 8–12 July 2020; pp. 229–230. [Google Scholar]
- Dahl, G.E.; Sainath, T.N.; Hinton, G.E. Improving deep neural networks for LVCSR using rectified linear units and dropout. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 8609–8613. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | DNN Value | CNN Value |
|---|---|---|
| Learning rate | 0.001 | 0.001 |
| Epoch | 1000 | 1000 |
| Dropout rate | 0.5 | 0.5 |
| Loss function | RMSE | RMSE |
| Optimizer | “Adam” | “Adam” |
| Number of layers | 5 | N/A |
| Number of neurons per layer | N/A |
| Problems | Deduplication | DNN | CNN | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Actual | Estimated | Ratio (%) | Time (s) | Actual | Estimated | Ratio (%) | Time (s) | ||||
| Before | After | Average | Average | Average | Average | ||||||
| Variant- OneMax | 6400 | 1863 | 0.74 | 21.5 | 0.88 | 36.0 | |||||
| 14,400 | 2291 | 0.72 | 24.7 | 0.63 | 60.1 | ||||||
| 40,000 | 9767 | 0.23 | 103.8 | 0.36 | 680.1 | ||||||
| - landscape | 6400 | 1403 | 2.26 | 18.8 | 2.32 | 31.5 | |||||
| 6400 | 1141 | 0.53 | 18.4 | 1.62 | 28.9 | ||||||
| 6400 | 1527 | 0.09 | 18.4 | 0.43 | 32.5 | ||||||
| 14,400 | 2124 | 1.51 | 22.0 | 1.17 | 58.9 | ||||||
| 14,400 | 2822 | 1.01 | 23.9 | 0.71 | 72.2 | ||||||
| 14,400 | 3609 | 0.21 | 25.5 | 0.27 | 94.2 | ||||||
| 14,400 | 4039 | 1.03 | 26.3 | 0.83 | 105.7 | ||||||
| 40,000 | 9816 | 7.12 | 107.1 | 1.91 | 651.9 | ||||||
| CPU | Intel® CoreTM i7-6850K CPU @ 3.60 GHz |
| GPU | NVIDIA GeForce GTX 1080 Ti × 4 |
| RAM | 64 GB |
| Operating system | Ubuntu 18.04 LTS |
| Programing language (version) | Python (3.7) |
| Trial | Variant-OneMax | |
|---|---|---|
| 1 | 35 | 25 |
| 2 | 42 | 48 |
| 3 | 17 | 25 |
| 4 | 24 | 31 |
| 5 | 51 | 24 |
| 6 | 49 | 70 |
| 7 | 36 | 48 |
| 8 | 30 | 41 |
| 9 | 55 | 3 |
| 10 | 53 | 47 |
| Average | 39.2 | 36.2 |
| N, K | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1 | Average | 0.8169 | 0.7445 | 0.7487 | 0.7714 | 0.7655 | 0.7313 | 0.7209 |
| Best | 0.8250 | 0.7613 | 0.7814 | 0.7763 | 0.7952 | 0.7791 | 0.7549 | |
| 2 | Average | 0.8154 | 0.7433 | 0.7572 | 0.7663 | 0.7658 | 0.7388 | 0.7210 |
| Best | 0.8250 | 0.7613 | 0.7855 | 0.7763 | 0.7873 | 0.7745 | 0.7627 | |
| 3 | Average | 0.8141 | 0.7467 | 0.7550 | 0.7625 | 0.7683 | 0.7358 | 0.7240 |
| Best | 0.8250 | 0.7613 | 0.7855 | 0.7763 | 0.7952 | 0.8048 | 0.7615 | |
| 4 | Average | 0.8130 | 0.7533 | 0.7595 | 0.7718 | 0.7643 | 0.7337 | 0.7217 |
| Best | 0.8250 | 0.7613 | 0.7855 | 0.7763 | 0.7897 | 0.7802 | 0.7526 | |
| 5 | Average | 0.8165 | 0.7560 | 0.7563 | 0.7706 | 0.7720 | 0.7338 | 0.7244 |
| Best | 0.8250 | 0.7613 | 0.7855 | 0.7763 | 0.7952 | 0.7804 | 0.7726 | |
| 6 | Average | 0.8137 | 0.7504 | 0.7573 | 0.7700 | 0.7701 | 0.7322 | 0.7215 |
| Best | 0.8250 | 0.7613 | 0.7855 | 0.7763 | 0.7952 | 0.8034 | 0.7627 | |
| 7 | Average | 0.8158 | 0.7463 | 0.7529 | 0.7630 | 0.7701 | 0.7373 | 0.7244 |
| Best | 0.8250 | 0.7613 | 0.7814 | 0.7763 | 0.7952 | 0.7717 | 0.7715 | |
| 8 | Average | 0.8094 | 0.7461 | 0.7540 | 0.7671 | 0.7719 | 0.7323 | 0.7215 |
| Best | 0.8250 | 0.7613 | 0.7855 | 0.7763 | 0.7952 | 0.7855 | 0.7590 | |
| 9 | Average | 0.8091 | 0.7429 | 0.7540 | 0.7678 | 0.7582 | 0.7400 | 0.7216 |
| Best | 0.8250 | 0.7613 | 0.7855 | 0.7763 | 0.7876 | 0.7844 | 0.7525 | |
| 10 | Average | 0.8150 | 0.7501 | 0.7475 | 0.7679 | 0.7706 | 0.7341 | 0.7210 |
| Best | 0.8250 | 0.7613 | 0.7855 | 0.7763 | 0.7952 | 0.7749 | 0.7541 | |
| Total | Average | 0.8139 | 0.7480 | 0.7542 | 0.7678 | 0.7677 | 0.7349 | 0.7222 |
| Best | 0.8250 | 0.7613 | 0.7855 | 0.7763 | 0.7952 | 0.8048 | 0.7726 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.-H.; Yoon, Y.; Kim, Y.-H. Towards a Better Basis Search through a Surrogate Model-Based Epistasis Minimization for Pseudo-Boolean Optimization. Mathematics 2020, 8, 1287. https://doi.org/10.3390/math8081287
Kim Y-H, Yoon Y, Kim Y-H. Towards a Better Basis Search through a Surrogate Model-Based Epistasis Minimization for Pseudo-Boolean Optimization. Mathematics. 2020; 8(8):1287. https://doi.org/10.3390/math8081287
Chicago/Turabian StyleKim, Yong-Hoon, Yourim Yoon, and Yong-Hyuk Kim. 2020. "Towards a Better Basis Search through a Surrogate Model-Based Epistasis Minimization for Pseudo-Boolean Optimization" Mathematics 8, no. 8: 1287. https://doi.org/10.3390/math8081287
APA StyleKim, Y.-H., Yoon, Y., & Kim, Y.-H. (2020). Towards a Better Basis Search through a Surrogate Model-Based Epistasis Minimization for Pseudo-Boolean Optimization. Mathematics, 8(8), 1287. https://doi.org/10.3390/math8081287