1. Introduction
Let us first consider a simple linear inverse problem as the following form:
where
is the solution of the problem to be approximated,
and
are known and
is an additive noise vector. Such problems (
1) arise in various applications such as the image and signal processing problems, astrophysical problems and data classification problems.
Further, one of their well-known applications is the problem of approximating the original image from the observed blurred and noisy image which is known as the image restoration problem. In this problem, and b represent the original image, blur operator and observed image, respectively.
The purpose of the image restoration problem is to minimize the additive noise in which the classical estimator is the least squares (LS) given as follows:
where
is
-norm. However, this model still has some ill-conditions in the case that the least square solution has a huge norm which is thus meaningless. In 1977, Tikhonov and Arsenin [
1] improved this ill-posed problem by introducing the regularization techniques which are known as the Tikhonov regularization (TR) model and it is of the following form:
for some regularization parameter
and Tikhonov matrix
L.
On the other hand, another successful regularization method for improvement of Tikhonov regularization is known as the least absolute shrinkage and selection operator (LASSO) which was introduced by Tibshirani (1996). The method is to find a solution
where
is
-norm. The LASSO can be applied to regression problems and image restoration problems (see [
2,
3] for examples).
For solving (
3) and (
4), we extend them to a general naturally formulation, that is, the problem of finding the minimizer of sum of two functions:
In order to solve (
5), we assume the following:
We here denote the set of all solutions of above problem by
. It is well-known that the solution of (
5) can be reformulated as the problem of finding a zero-solution
such that
where
is the subdifferential of function
g and
is the gradient operator of function
h (see [
4] for more details). Moreover, the problem (
6) can be solved by using the proximal gradient technique which was presented by Parikh and Boyd [
5], i.e., if
is a solution of (
6), then it is a fixed point of a forward-backward operator
T defined by
for
. The operator
is called the proximity operator with respect to
and function
g. We know that
T is a nonexpansive mapping whenever
. It is easily seen that
is an example of the resolvent of
, that is,
, see
Section 2 for more details.
We have seen from above fact that fixed point theory plays very important role in solving and developing of the image and signal processing problems which can be applied to solving many real-world problems in digital image processing such as medical image and astronomy as well as image processing for security sections. Fixed point theory focuses on two important problems. The first one is an existence problem of a solution of many kind of real-world problems while the other problem is a problem of how to approximate such solutions of the interested problems. For the past two decades, a lot of fixed point iteration processes were introduced and studied to solving many practical problems. It is well-known by Banach Contraction Principle that every contraction map from a complete metric space X into itself has a unique fixed point.
A mapping T from a metric space into itself is called a contraction if there is a such that for all .
It is well-known that the Picard iteration process, defined by
and
converges to a unique fixed point
of
T.
It is observed that when in above inequality, we have a new nonlinear mapping, called nonexpansive mapping. This type of mapping plays a crucial role to solving many optimization problems and economics.
From now on, we would like to provide some background concerning various iteration methods for finding a fixed point of nonexpansive and other nonlinear mappings.
Mann [
6] was the first who introduced a modified iterative method known as Mann iteration process in Hilbert space
H as follows:
,
where
is a real sequence in
. In 1974, Ishikawa extended Mann iteration, called the Ishikawa iteration process, by the following method: For an initial point
,
where
,
. Agarwal et al. employed the idea of the Ishikawa method to introduce S-iteration process as follows: For an initial point
,
where
and
are sequences in
. They showed that the convergence behavior of S-iteration is better than that of Mann and of Ishikawa iterations.
Because Mann iteration obtained only weak convergence (see [
7] for more details). In 2000, Moufafi [
8] introduced a well-known viscosity approximation was defined as follows: For
,
where
and
f is a contraction mapping. Under some suitable control conditions, he proved that
converges strongly to a fixed point of
T, when
T is a nonexpansive mapping. Recently, authors in [
9] proposed the viscosity-based inertial forward-backward algorithm (VIFBA), for solving (
5) by finding a common fixed point of an infinite family
of forward-backward operators. For initial points
, they define their method as follows:
where
f is a contraction mapping on
H and
are sequences in
. Here, the inertial term is represented by the term
which was firstly introduced by Nesterov [
10]. This algorithm is also applied to solve the regression and recognition problems.
In 2009, Beck and Teboulle introduced a fast iterative shrinkage-thresholding algorithm (FISTA) which was defined by
where
for
and the initial points
and
. Moreover, they applied their algorithm to the image restoration problems (see [
3] for more details). It is pointed out from this work that the LASSO model is a suitable model for image restoration problems.
Motivated and inspired by all of these researches going on in this direction, in this paper, we introduce a new accelerated algorithm for finding a common fixed point of a family of nonexpansive mappings in Hilbert spaces based on the concept of inertial forward-backward, of Mann and of viscosity algorithms. Then a strong convergence theorem is established under some control conditions. Moreover, we apply the main results to solving image restoration problems and compare efficiency of our proposed algorithm with others. The presented results in this work also improve some well-known results in the literature.
This paper is organized as follows: In
Section 2, Preliminaries, we recall some definitions and the useful facts which will be used in the later sections. We prove and analyze a strong convergence of the proposed algorithm in
Section 3, Main Results. In the next section,
Section 4 (Applications), we apply our main result to solving image restoration problems. Finally, the last section,
Section 5 (Conclusions), is the summary of our work.
2. Preliminaries
Throughout this paper, we let
H be a real Hilbert space with inner product
and norm
. Let
be a sequence in
H. We use
stands for
converges strongly to
x and
stands for
converges weakly to
x. Let
be a mapping from a nonempty closed convex subset of
H into itself. A fixed point of
T is a point
such that
. The set of all fixed points of
T is denoted by
, that is,
A mapping
is said to be
L-Lipschitzian, if there exists a constant
such that
If , then T is said to be a nonexpansive mapping. It is well-known that if T is nonexpansive, then is closed and convex.
We call a mapping
a contraction, if there exists a constant
such that
Here, we say that f is a k-contraction mapping.
Let . The domain of A is the set and the range of A is the set . The inverse of A is denoted by is defined as follows: if and only if . The graph of A is denoted by and .
An operator is said to be monotone if A monotone operator A on H is said to be maximal if the graph of A is not properly contained in any graph of other monotone operators on H. It is well-known that A is maximal if and only if for and ,
Moreover, A is a maximally monotone operator if and only if for every , where I is an identity operator. We also know that the subdifferential of a proper lower semicontinuous convex function is a nice example of a maximal monotone.
For a function
. The subdifferential
of
g at
, with
, is the set
. We take by convention
, if
. If
, the set of proper lower semicontinuous convex functions from
H to
, then
is maximally monotone (see [
11] for more details).
For a maximally monotone operator A and , the resolvent of A for is defined to be a single-valued operator , where . It is well-known that is a nonexpansive mapping and , where and it is called the set of all zero (or null) points of A.
Let
be a multi-valued mapping and
a single-valued nonlinear mapping. The quasi-variational inclusion problem is the problem of finding a point
such that
The set of all solutions of the problem (
12) is denoted by
A classical method for solving the problem (
12) is the forward-backward method [
12,
13,
14] which was first introduced by Combettes and Hirstoaga [
15] in the following manner:
and
where
. Moreover, we have from [
16], if
A is a maximally monotone operator and
B is an
L-Lipschitz continuous, then
Definition 1. Letand. The proximity operator of parameter λ of g atis denoted byand it is defined by It is well-known that if
, then
, that is, the proximity operator is an example of resolvent operator. Moreover, if
, then
where sign is a signum function (see [
4] for more details).
The following basic definitions and well-known results are also needed for proving our main results.
Lemma 1. ([17,18]) Let H be a real Hilbert space. Forand any arbitrary real number λ in, the following hold: - 1.
;
- 2.
;
- 3.
.
The identity in Lemma 1(3) implies that the following equality holds:
for all
and
with
.
Let
C be a nonempty closed convex subset of a Hilbert space
H. We know that for each element
, there exists a unique point in
C, say
, such that
Such a mapping
is called the metric projection of
H onto
C. It is well-known that
is a nonexpansive mapping. Moreover,
can be characterized by the following inequality
holds for all
and
(see [
19] for more details).
We next recall the following properties which are useful for proving our main result, we refer to [
20,
21].
Let
and
be families of nonexpansive mappings of
H into itself such that
, where
is the set of all common fixed points of
. We say that
satisfies NST-condition(I) with
if for each bounded sequence
such that
, it follows
In particular, if consists of one mapping T, i.e., , then is said to satisfy NST-condition(I) with T.
Lemma 2. Letbe a family of nonexpansive mappings of H into itself anda nonexpansive mapping with. One always has, ifsatisfies NST-condition(I) with T, thenalso satisfies NST-condition(I) with T, for any subsequencesof positive integers.
Proof. Let
be a bounded sequence such that
as
. Take
. Define the sequence
by
Then
is bounded. Moreover, we have that
due to
u is a fixed point of
for all
. By the NST-condition(I) with T on
, we obtain that
Thus, satisfies NST-condition(I) with T. ☐
Proposition 1. ([22]) Let H be a Hilbert space. Letbe a maximally monotone operator andan L-Lipschitz operator, where. Let, wherefor alland let, wherewith. Thensatisfies the NST-condition(I) with T. The following lemmas are crucial for proving our main results.
Lemma 3. ([23]) Let H be a real Hilbert space anda nonexpansive mapping with. Then the mappingis demiclosed at zero, i.e., for any sequencesin H such thatandimply. Lemma 4. ([24,25]) Let,be sequences of nonnegative real numbers,a sequence in [0,1] anda sequence of real numbers such thatfor allIf the following conditions hold: - 1.
;
- 2.
;
- 2.
.
Then.
Lemma 5. ([26]) Letbe a sequence of real numbers that does not decrease at infinity in the sense that there exists a subsequenceofwhich satisfiesfor all. Define the sequenceof integers as follows:wheresuch that. Then the following hold: - 1.
and;
- 2.
andfor all.
3. Main Results
In this section, we first give a new algorithm for finding a common fixed point of a family of nonexpansive mappings in a real Hilbert space. We then prove its strong convergence under some suitable conditions.
We now propose a new accelerated algorithm for approximating a solution of our common fixed point problem as the following.
Let H be a real Hilbert space. Let be a family of nonexpansive mappings on H into itself. Let f be a k-contraction mapping on H with and let and .
We next prove the convergence of the sequence generated by Algorithm 1. To this end, we assume that the algorithm does not stop after finitely many iterations.
| Algorithm 1: NAVA (New Accelerated Viscosity Algorithm). |
Initialization: Take . Choose .
For :
Set
Compute |
Theorem 1. Letbe a family of nonexpansive mappings anda nonexpansive mapping such that. Suppose thatsatisfies NST-condition(I) with T. Letbe the sequence generated by Algorithm 1 such that the following additional conditions hold:
- 1.
;
- 2.
;
- 3.
;
- 4.
;
- 5.
;
- 6.
and,
for some positive real numbers. Then the sequenceconverges strongly to, where.
Proof. Let
be such that
. First of all, we show that
is bounded. By the definition of
and of
, we have
and
From (
16) and (
17), we also have that
According to the definition of
and the assumption (5), we have
Then there exists a positive constant
such that
This implies is bounded and so are and .
Indeed, we have that for all
,
By Lemma 1(2), (
14) and (
17) we have
It follows from (
19) with
that
Since
there exists a positive constant
such that
From the inequality (
21), we derive that for all
,
where
. From above inequality, we set
and
So, we obtain
for all
.
Now, we consider two cases for the proof as follows:
Case 1. Suppose that there exists a natural number
such that the sequence
is nonincreasing. Hence,
converges due to it is bounded from below by 0. Using the assumption (6), we get that
. From Lemma 4, we next claim that
Coming back to the definition of
, by Lemma 1(3), one has that
Using the facts that (
14), (
17), (
19) and (
24) yield
It implies that for all
,
It follows from the assumptions (2), (3), (4), (6) and the convergence of the sequences
and of
that
According to
satisfies NST-condition(I) with T, we obtain that
From the definition of
and of
, we obtain
and
Using (
27) and (
30) with the assumption (6), we have
which implies
So, there exists a subsequence
of
such that
Since
is bounded, there exists a subsequence
of
such that
for some
. Without loss of generality, we may assume that
and
From (
28) and (
29), we derive
and hence,
It implies by Lemma 3 that
. Since
, we get
. Moreover, using
and (
15), we obtain
It implies from (
37) with the fact of
that
. Coming back to (
23), using Lemma 4, we conclude that
.
Case 2. Suppose that the sequence
is not a monotonically decreasing sequence for some
large enough. Set
So, there exists a subsequence
of
such that
for all
. In this case, we define
by
By Lemma 5, we have that
for all
. That is,
As in Case 1, we can conclude that for all
,
and hence,
Similarly to the proof of Case 1, we get
and
as
, and hence
We next show that
Put
Without loss of generality, there exists a subsequence
of
such that
converges weakly to some point
and
By Lemma 2, one has
satisfies NST-condition(I) with T. So, according to the equality (
38),
, we obtain that
which implies, by (
39) and Lemma 3 again, that
. Since
, we get
. Moreover, using
and (
15), we obtain
Since
and
, as in the proof of Case 1, we have that for all
,
It follows by the fact that
and (
45) that
and hence
as
. It implies by (
42) that
as
.
Hence . The proof is completed. ☐
As a direct consequence of Theorem 1, by using Proposition 1, we obtain the following corollary.
Corollary 1. Let H be a real Hilbert space. Letbe a maximally monotone operator andan L-Lipschitz operator, where. Let , wherefor alland let, wherewith. Suppose that. Let f be a k-contraction mapping on H with. Letbe a sequence in H generated by Algorithm 1 under the same conditions of parameters as in Theorem 1. Thenconverges strongly to, where.
Proof. Since and are nonexpansive for each , we can conclude that the sequence converges strongly to by using Proposition 1 and Theorem 1. ☐
4. Applications
In this section, we first begin with presenting the algorithm obtained from our main results. We investigate throughout this section under the following setting.
- ⧫
H is a real Hilbert space;
- ⧫
is a differentiable and convex function with an L-Lipschitz continuous gradient where ;
- ⧫
;
- ⧫
;
- ⧫
f is a k-contraction mapping on H with ;
- ⧫
and with ;
- ⧫
and .
The algorithm we propose in this context has the following formulation.
We next prove the strong convergence of the sequence generated by our proposed algorithm.
Theorem 2. Letbe a sequence generated by Algorithm 2 under the same conditions of parameters as in Theorem 1. Thenconverges strongly to.
| Algorithm 2: AVFBA (Accelerated Viscosity Forward-Backward Algorithm). |
Initialization: Take . Choose .
For :
Set
Compute |
Proof. In Corollary 1, we set and . So, A is a maximal operator. Then we obtain the required result directly by Corollary 1. ☐
We next discuss some experiment results by using our proposal algorithm to solving the image restoration problem. The image restoration problem (
2) can be related to
where
is the original image,
b is the observed image and
A represents the blurring operator. In this situation, we choose the regularization parameter
. For this example, we look at the 256 × 256 Schonbrunn palace (original image). We use a Gausssian blur of size 9 × 9 and standard deviation
to create the blurred and noisy image (observed image). These two images are given as in
Figure 1.
In 2009, Thung and Raveendran [
27] introduced Peak Signal-to-Noise Ratio (PSNR) to measure a quality of restored images for each
as the following:
where
the Mean Square Error for the original image
x. We note that a higher PSNR shows a higher quality for deblurring image.
In Theorem 2, we set and and choose the Lipschitz constant L of the gradient which is the maximum value of eigenvalues of the matrix .
Let us begin with the first experiment. We study convergence behavior of our method by considering the following six different cases:
| Parameters | Case (a) | Case (b) | Case (c) | Case (d) | Case (e) | Case (f) |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| | | | | | |
| 0.5 | 0.5 | 0.5 | 0.5 | 0.09 | 0.99 |
It is clear that these control parameters satisfy all conditions of Theorem 2. In this experiment, we take
. By Theorem 2, the sequence
converges to the original image and its convergence behavior for each case is shown by the values of PSNR as seen in
Table 1.
The second experiment is to consider the behavior of the sequence
for each case of contraction mappings
. We consider the following four different cases as follows:
| Case (1) | |
| Case (2) | |
| Case (3) | |
| Case (4) | |
We choose the parameters as follows:
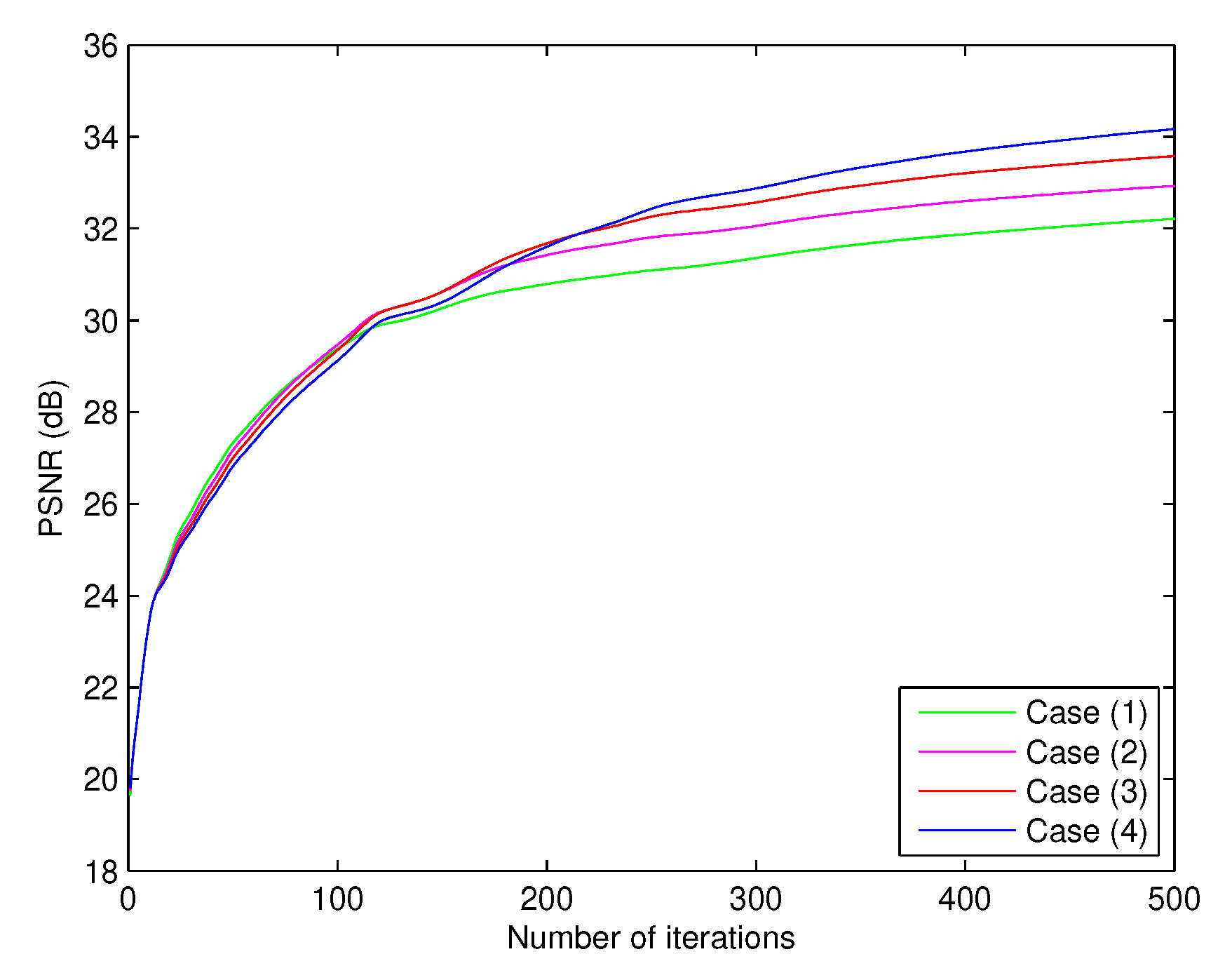
Here then
From
Table 2, we get the values of PSNR at
of each case which equal to 32.212326, 32.929758, 33.580650 and 34.170032, respectively. We also observe from
Table 2 and
Figure 2 that when
k is close to 1, the value of PSNR is higher than those of smaller
k.
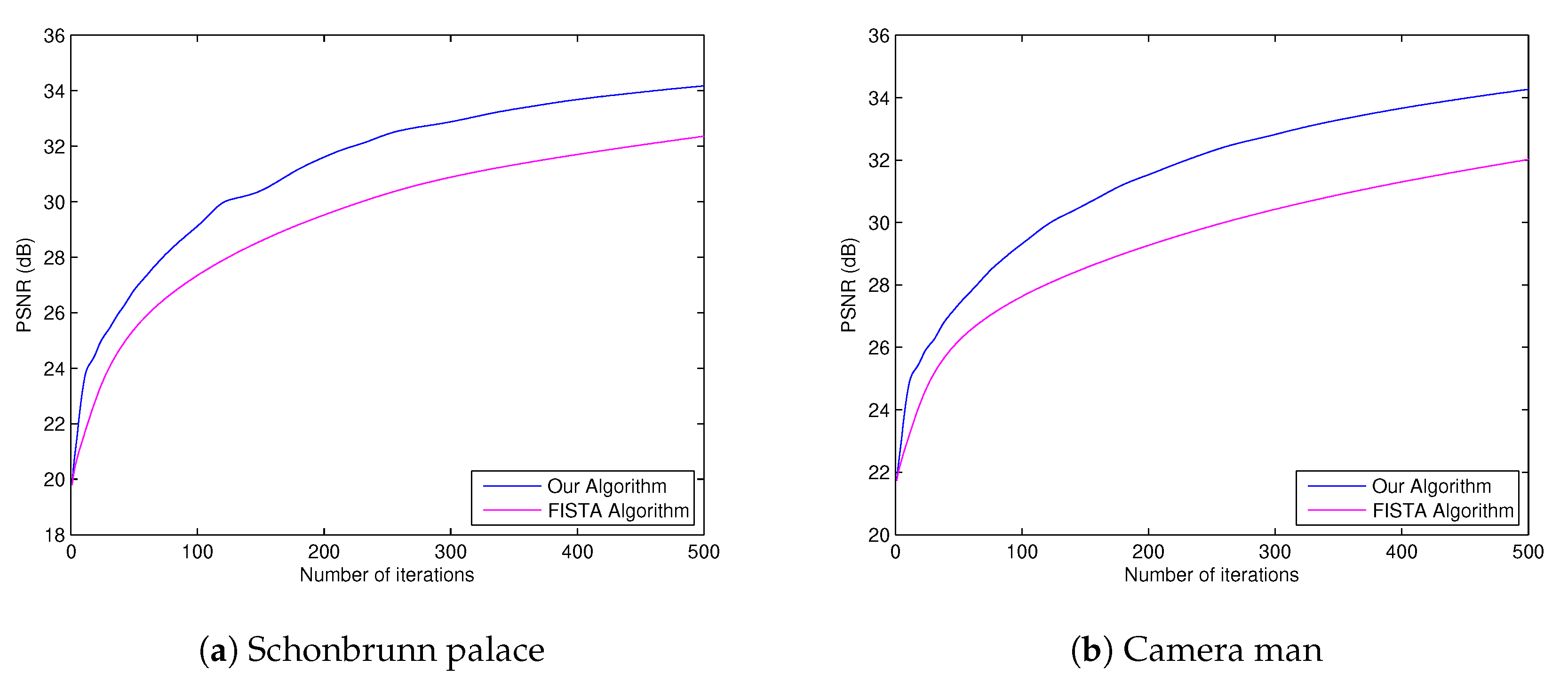
On the other hand, the other experiment is to compare the quality of image restored by our algorithm and the quality of image restored by FISTA method [
3]. Here, all parameters in Theorem 2 were the same as the previous experiment and we used
.
For FISTA method [
3], we set
where the parameter
Then we obtain the PSNR values of our algorithm and of FISTA as seen in
Table 3 and
Table 4, and
Figure 3. The restoration images at 500th iteration of both algorithms are also presented in
Figure 4.
Our experiments show that our algorithm gives a better performance in restoring the blurred image than that of FISTA [
3].







{kind=link}
{kind=link}
{kind=link}
{kind=link}