Given the above mentioned issue, we provide ARA solutions to AC. We focus first on modelling the adversary’s problem in the operation phase. We present the classification problem faced by
C as a Bayesian decision analysis problem in
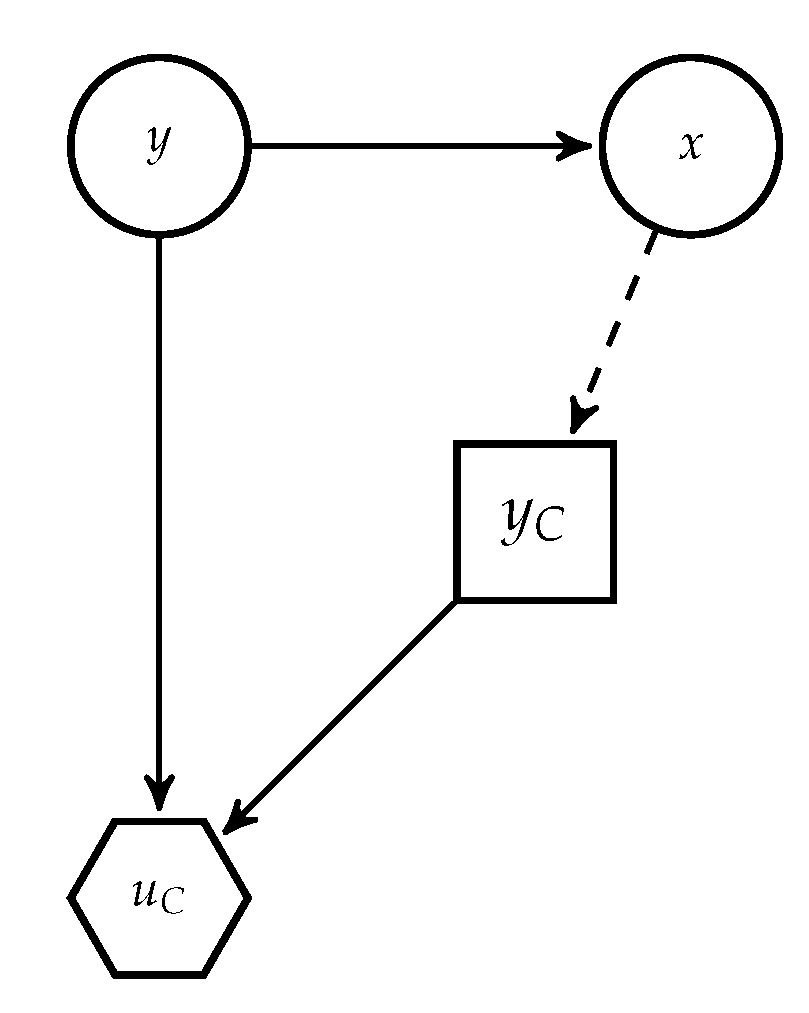
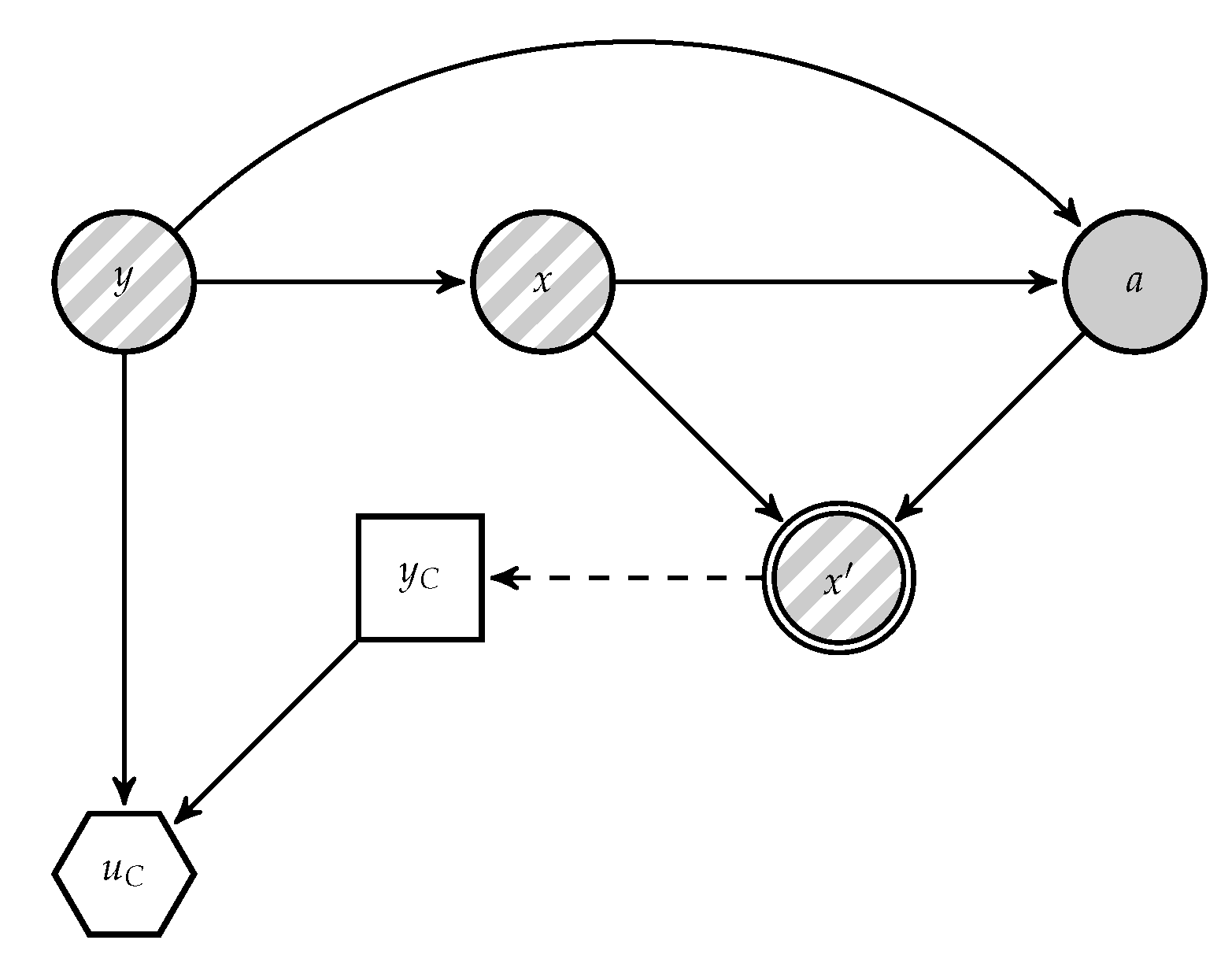
Figure 3, derived from
Figure 2. In it,
A’s decision appears as random to the classifier, since she does not know how the adversary will attack the data. For notational convenience, when necessary we distinguish between random variables and realisations using upper and lower case letters, respectively; in particular, we denote by
X the random variable referring to the original instance (before the attack) and
that referring to the possibly attacked instance.
will indicate an estimate of
z.
4.1. The Case of Generative Classifiers
Suppose first that a generative classifier is required. As training data is clean by assumption, we can estimate (modelling the classifier’s beliefs about the class distribution) and (modelling her beliefs about the feature distribution given the class when A is not present). In addition, assume that when C observes , she can estimate the set of original instances x potentially leading to the observed . As later discussed, in most applications this will typically be a very large set. When the feature space is endowed with a metric d, an approach to approximate would be to consider for a certain threshold .
Given the above, when observing
the classifier should choose the class with maximum posterior expected utility (
7). Applying Bayes formula, and ignoring the denominator, which is irrelevant for optimisation purposes, she must find the class
In such a way,
A’s modifications are taken into account through the probabilities
. At this point, recall that the focus is restricted to integrity violation attacks. Then,
and problem (
8) becomes
Note that should we assume full common knowledge, we would know
A’s beliefs and preferences and, therefore, we would be able to solve his problem exactly: when
A receives an instance
x from class
, we could compute the transformed instance. In this case,
would be 1 just for the
x whose transformed instance coincides with that observed by the classifier and 0, otherwise. Inserting this in (
9), we would recover Dalvi’s formulation (
5). However, common knowledge about beliefs and preferences does not hold. Thus, when solving
A’s problem we have to take into account our uncertainty about his elements and, given that he receives an instance
x with label
, we will not be certain about the attacked output
. This will be reflected in our estimate
which will not be 0 or 1 as in Dalvi’s approach (stage 3). With this estimate, we would solve problem (
9), summing
over all possible originating instances, with each element weighted by
.
To estimate these last distributions, we resort to
A’s problem, assuming that this agent aims at modifying
x to maximise his expected utility by making
C classify malicious instances as innocent. The decision problem faced by
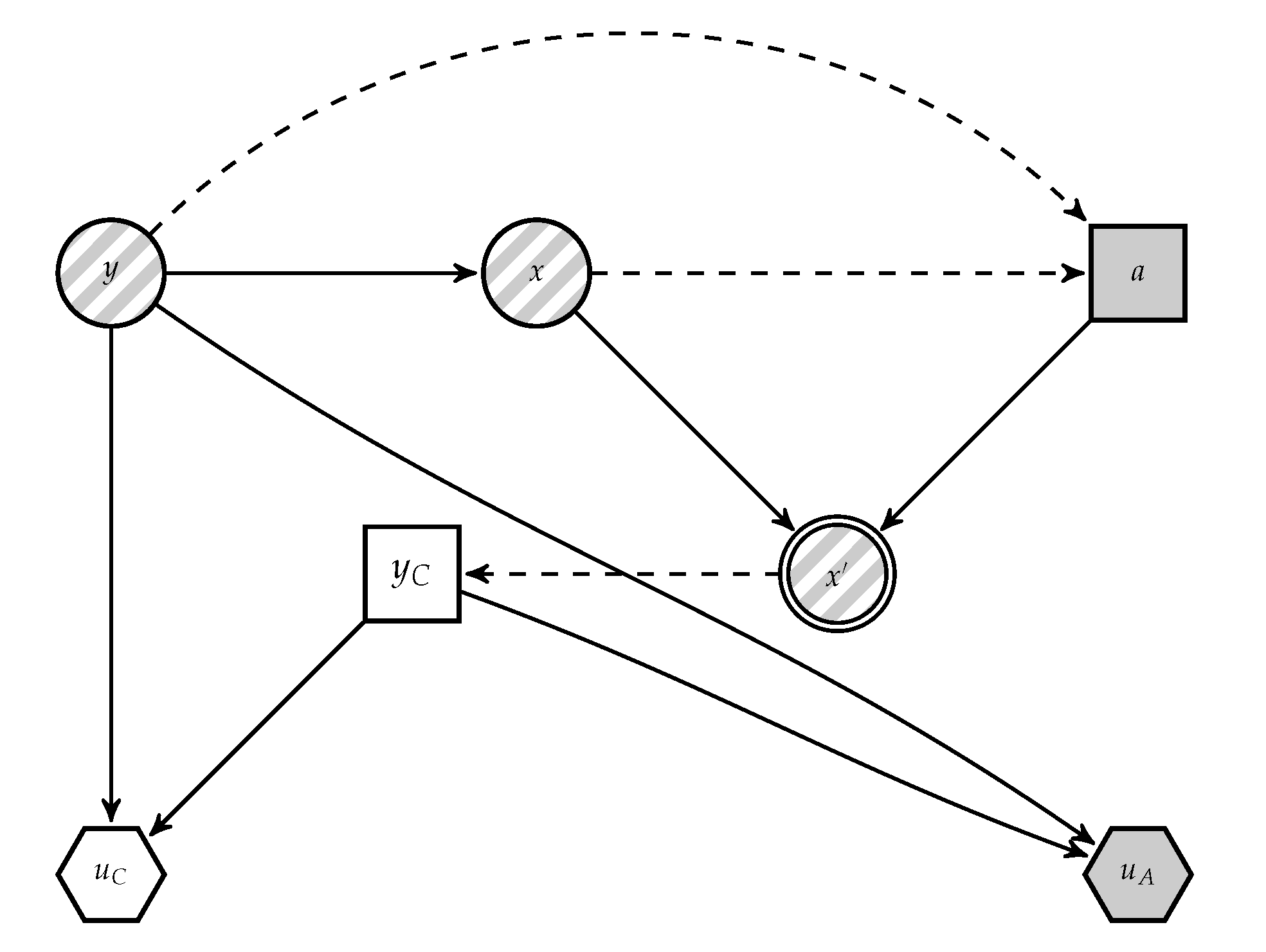
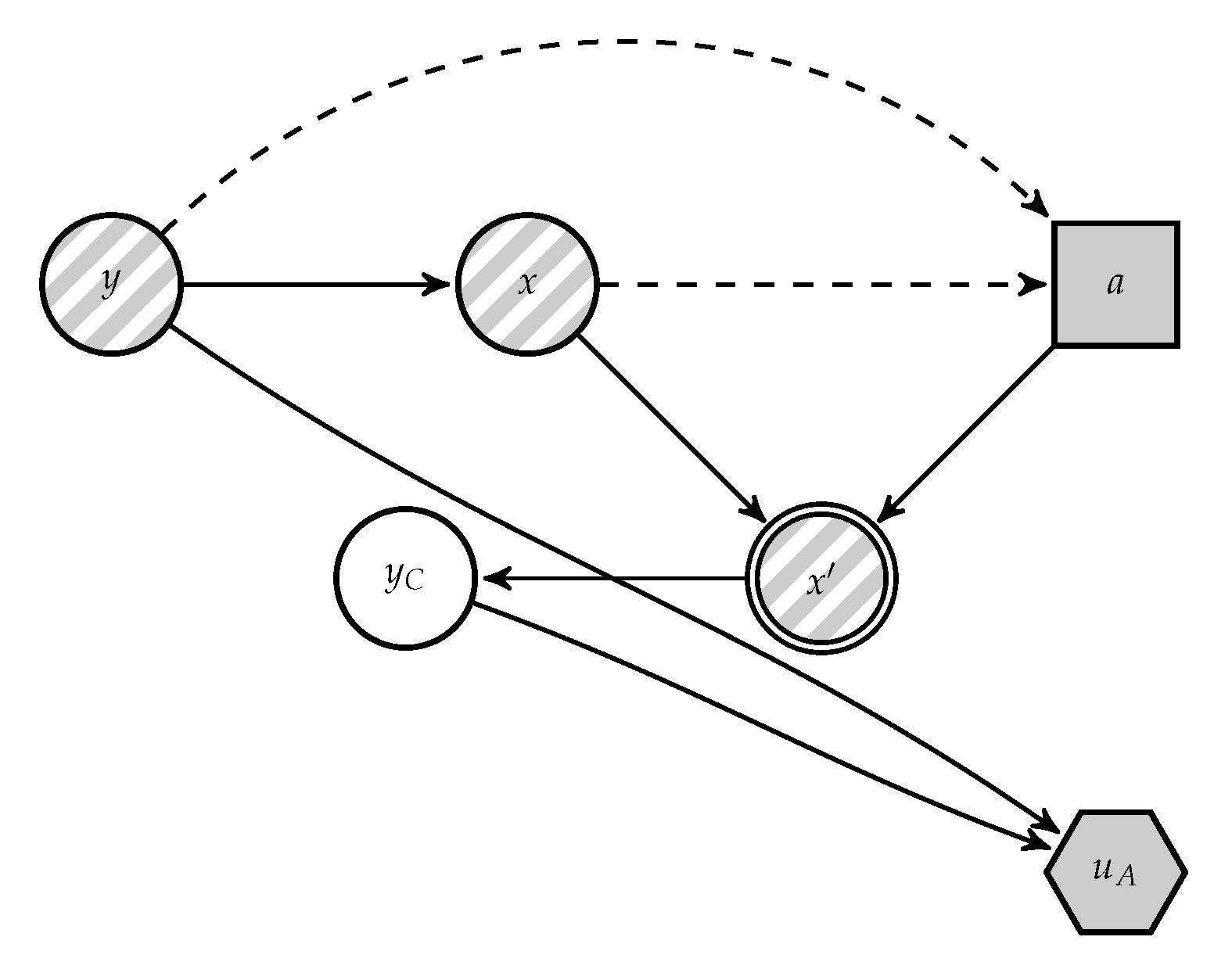
A is presented in
Figure 4, derived from
Figure 2. In it,
C’s decision appears as an uncertainty to
A.
To solve the problem, we need
, which models
A’s beliefs about
C’s decision when she observes
. Let
p be the probability
that
A concedes to
C saying that the instance is malicious when she observes
. Since
A will have uncertainty about it, let us model its density using
with expectation
. Then, upon observing an instance
x of class
,
A would choose the data transformation maximising his expected utility:
where
is the attacker’s utility when the defender classifies an instance of class
as one of class
.
However, the classifier does not know the involved utilities
and probabilities
from the adversary. Let us model such uncertainty through a random utility function
and a random expectation
. Then, we could solve for the random attack, optimising the random expected utility
We then use such distribution and make (assuming that the set of attacks is discrete, and similarly in the continuous case)
which was the missing ingredient in problem (
9). Observe that it could be the case that
, i.e., the attacker does not modify the instance.
Now, without loss of generality, we can associate utility 0 with the worst consequence and 1 with the best one, having the other consequences intermediate utilities. In
A’s problem, his best consequence holds when the classifier accepts a malicious instance as innocent (he has opportunities to continue with his operations) while the worst consequence appears when the defender stops an instance (he has wasted effort in a lost opportunity), other consequences being intermediate. Therefore, we adopt
and
. Then, the Attacker’s random optimal attack would be
Modelling
is more delicate. It entails strategic thinking and could lead to a hierarchy of decision making problems, described in [
43] in a simpler context. A heuristic to assess it is based on using the probability
that
C assigns to the instance received being malicious assuming that she observed
z, with some uncertainty around it. As it is a probability,
r ranges in
and we could make
, with mean
and variance
as perceived.
has to be tuned depending on the amount of knowledge
C has about
A. Details on how to estimate
r are problem dependent.
In general, to approximate
we use Monte Carlo (MC) simulation drawing
K samples
,
from
, finding
and estimating
using the proportion of times in which the result of the random optimal attack coincides with the instance actually observed by the defender:
It is easy to prove, using arguments in [
44], that (
12) converges almost surely to
. In this, and other MC approximations considered, recall that the sample sizes are essentially dictated by the required precision. Based on the Central Limit Theorem [
45], MC sums approximate integrals with probabilistic bounds of the order
where
N is the MC sum size. To obtain a variance estimate, we run a few iterations and estimate the variance, then choose the required size based on such bounds.
Once we have an approach to estimate the required probabilities, we implement the scheme described through Algorithm 1, which reflects an initial training phase to estimate the classifier and an operational phase which performs the above once a (possibly perturbated) instance
is received by the classifier.
| Algorithm 1 General adversarial risk analysis (ARA) procedure for AC. Generative |
Input: Training data , test instance . Output: A classification decision . Training Train a generative classifier to estimate and End Training Operation Read . Estimate for all . Solve Output . End Operation
|
4.2. The Case of Discriminative Classifiers
With discriminative classifiers, we cannot use the previous approach as we lack an estimate of
. Alternatively, assume for the moment that the classifier knows the attack that she has suffered and that this is invertible in the sense that she may recover the original instance
. Then, rather than classifying based on (
6), as an adversary unaware classifier would do, she should classify based on
However, she actually has uncertainty about the attack
a, which induces uncertainty about the originating instance
x. Suppose we model our uncertainty about the origin
x of the attack through a distribution
with support over the set
of reasonable originating features
x. Now, marginalising out over all possible originating instances, the expected utility that the classifier would get for her classification decision
would be
and we would solve for
Typically, the expected utilities (
13) are approximated by MC using a sample
from
. Algorithm 2 summarises a general procedure.
| Algorithm 2 General ARA procedure for AC. Discriminative |
Input: Monte Carlo size N, training data , test instance . Output: A classification decision . Training Based on , train a discriminative classifier to estimate . End Training Operation Read Estimate and Draw sample from . Find Output End Operation
|
To implement this approach, we need to be able to estimate
and
or, at least, sample from such distribution. A powerful approach samples from
by leveraging approximate Bayesian computation (ABC) techniques, [
46]. This requires being able to sample from
and
, which we address first.
Estimating
is done using training data, untainted by assumption. For this, we can employ an implicit generative model, such as a generative adversarial network [
47] or an energy-based model [
48]. In turn, sampling from
entails strategic thinking. Notice first that
We easily generate samples from
, as we can estimate those probabilities based on training data as in
Section 2.1. Then, we can obtain samples from
sampling
first; next, if
return
x or, otherwise, sample
. To sample from the distribution
, we model the problem faced by the attacker when he receives instance
x with label
.The attacker will maximise his expected utility by transforming instance
x to
given by (
10). Again, associating utility 0 with the attacker’s worst consequence and 1 with the best one; and modelling our uncertainty about the attacker’s estimates of
using random expected probabilities
, we would look for random optimal attacks
as in (
11). By construction, if we sample
and solve
is distributed according to
which was the last ingredient required.
Once with these two sampling procedures, we generate samples from
with ABC techniques. This entails generating
,
and accepting
x if
, where
is a distance function defined in the space of features and
is a tolerance parameter. The
x generated in this way is distributed approximately according to the desired
. However, the probability of generating samples for which
decreases with the dimension of
. One possible solution replaces
by
, a set of summary statistics that capture the relevant information in
; then, the acceptance criterion would be replaced by
. The choice of summary statistics is problem specific. We sketch the complete ABC sampling procedure in Algorithm 3, to be integrated within Algorithm 2 in its drawing sample command.
| Algorithm 3 ABC scheme to sample from within Algorithm 2 |
Input: Observed instance , data model , , , family of statistics s. Output: A sample approximately distributed according to . whiledo Sample Sample if then else Sample Compute end if Compute end while Output x
|









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
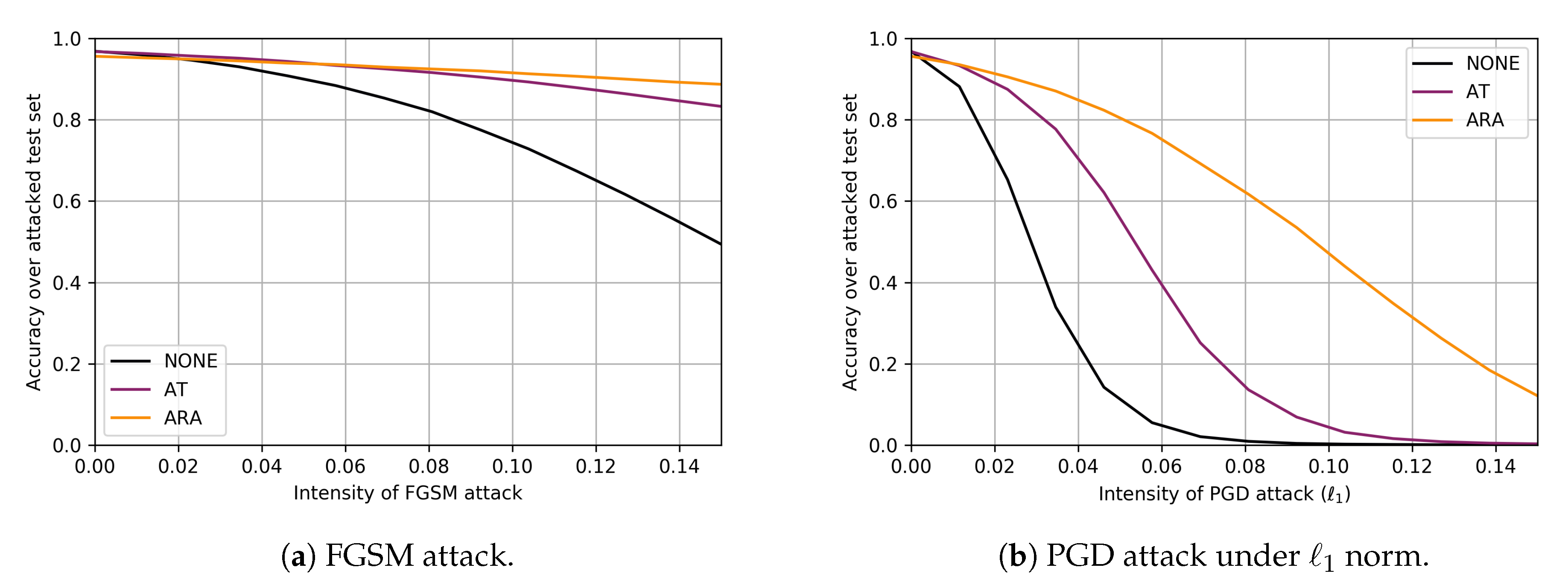{kind=link}