Abstract
The unit-Rayleigh distribution is a one-parameter distribution with support on the unit interval. It is defined as the so-called unit-Weibull distribution with a shape parameter equal to two. As a particular case among others, it seems that it has not been given special attention. This paper shows that the unit-Rayleigh distribution is much more interesting than it might at first glance, revealing closed-form expressions of important functions, and new desirable properties for application purposes. More precisely, on the theoretical level, we contribute to the following aspects: (i) we bring new characteristics on the form analysis of its main probabilistic and reliability functions, and show that the possible mode has a simple analytical expression, (ii) we prove new stochastic ordering results, (iii) we expose closed-form expressions of the incomplete and probability weighted moments at the basis of various probability functions and measures, (iv) we investigate distributional properties of the order statistics, (v) we show that the reliability coefficient can have a simple ratio expression, (vi) we provide a tractable expansion for the Tsallis entropy and (vii) we propose some bivariate unit-Rayleigh distributions. On a practical level, we show that the maximum likelihood estimate has a quite simple closed-form. Three data sets are analyzed and adjusted, revealing that the unit-Rayleigh distribution can be a better alternative to standard one-parameter unit distributions, such as the one-parameter Kumaraswamy, Topp–Leone, one-parameter beta, power and transmuted distributions.
Keywords:
unit-Rayleigh distribution; hazard rate function; incomplete moments; order statistics; estimation MSC:
62G07; 62C05; 62E20
1. Introduction
In many applied scenarios, we are often confronted with the uncertainty of a phenomenon that can be quantified in a bounded range of values. For the sake of accuracy, proper modeling should take this information into account. As an immediate example, it is natural to model characteristics of the proportion type as a random variable (rv) with values in the “unit interval ”, thus following a certain unit distribution, i.e., distribution with support . The unit-distributions are of particular interest because of the following argues: (i) any rv X with bounded support of the form , with , can be rescaled on as , and thus Y follows a certain unit-distribution, (ii) the unit-distributions allow us to define general and simple families of continuous distributions through the composition techniques; if denotes a cumulative distribution function (cdf) of a rv following a unit-distribution and denotes the cdf of any continuous distribution with support denoted by A, then a valid cdf is given as , , defining a certain family of distributions with support A (see [1] as pioneer reference, as well as [2] for a complete survey in this regard), and (iii) the unit-distributions play a central role to define regression models having some characteristic with unit-interval values (see [3] for the definitions of such regression models and [4] for a focus on the one of most popular of them: the beta regression model).
Among the most useful unit-distributions with various number of parameters, there are the power distribution, beta distribution, Johnson distribution by [5], Topp–Leone distribution by [6], Kumaraswamy distribution by [7], unit-gamma distribution by [8,9], unit-logistic distribution by [10], simplex distribution by [11], unit-Birnbaum–Saunders distribution by [12], exponentiated Kumaraswamy distribution by [13], exponentiated Topp–Leone distribution by [14], unit-Weibull distribution by [15,16], unit-Gompertz by [17], unit-Lindley distribution by [18], unit-inverse Gaussian distribution by [19], composite quantile distributions by [20], unit-generalized half normal distribution by [21], and unit modified Burr-III distribution by [22].
In this paper, we concentrate on a simple one-parameter unit distribution, called the unit-Rayleigh distribution. Technically, this distribution is not new; it corresponds to a special case of the unit-Weibull distribution introduced in [15], and it is briefly presented as such in this reference. However, new researches on the unit-Rayleigh distribution have yielded interesting and surprising mathematical fruits that we share in this paper. Specifically, we provide: (i) new motivations of considering this special distribution, (ii) new characteristics on the form analysis of the corresponding probability density function (pdf) (with a closed form for the mode) and hazard rate function (hrf), revealing an unexpected fitting capability of the unit-Rayleigh model, (iii) new stochastic ordering results involving the power distribution and some unlisted distributions of potential interest, (iv) new manageable expressions and approximations of the incomplete and probability-weighted moments involving the complementary error function, (v) some basics on the distributional properties of the order statistics including discussions on their moments, (vi) a simple expression for the reliability coefficient which is useful for estimation purposes, (vii) a tractable expression and approximation of the so-called Tsallis entropy and (viii) some bivariate extensions of the unit-Rayleigh distribution for two-dimensional modeling objectives. On the practical side, we analyze three different data sets, showing that the unit-Rayleigh distribution can be a better alternative to standard one-parameter unit distributions, such as the one-parameter Kumaraswamy, Topp–Leone, one-parameter beta, power and transmuted distributions.
2. The Unit-Rayleigh Distribution
This section discusses some new facts regarding the primary essence of the unit-Rayleigh distribution.
2.1. Main Lines of the Study
The block diagram in Figure 1 resumes the main lines of the study.
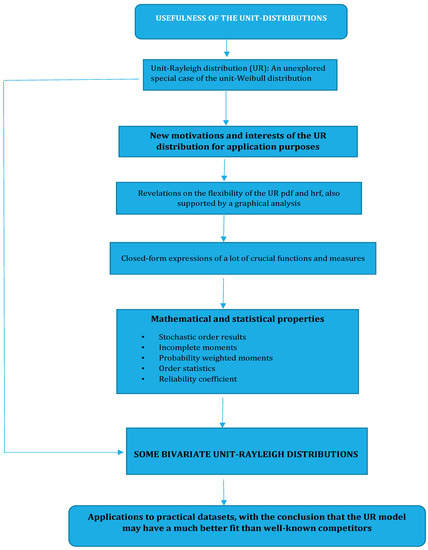
Figure 1.
Block diagram on the main lines of this study.
2.2. Corresponding Functions
As the basis, the unit-Rayleigh distribution is associated with the cdf given as
where , and for and for . Thus defined, it is a special case of the unit-Weibull distribution introduced by [15] with shape parameter equal to 2. By construction, the unit-Rayleigh distribution is the distribution of the rv , where Y denotes an rv following the Rayleigh distribution with scale parameter , i.e., with cdf , with , and otherwise. The Rayleigh distribution also corresponds to the chi-squared distribution with two degrees of freedom. The basics and properties of this distribution can be found in [23].
As a new fact, the unit-Rayleigh distribution is also the distribution of the rv , where Z denotes a rv following the Benini distribution with truncated parameter equal to 1, i.e., with cdf , with , and otherwise. The Benini distribution is a long tail distribution that can be viewed as a generalization of the Pareto distribution. We may refer to the former work of [24].
Based on , the pdf of the unit-Rayleigh distribution is given as
and for . The shape properties of this function are fundamental to evaluate the capability of the unit-Rayleigh model to fit data. This aspect will be discussed later.
The survival function is obtained by
and for and for , the cumulative hrf is specified as
and for and for , and the hrf is given as
and for . The shape properties of the hrf are precious indicators on some features of the unit-Rayleigh model. This point will be discussed later.
We end this part by specifying the quantile function of the unit-Rayleigh distribution obtained as
2.3. Analysis of the cdf
Basically, is an increasing and derivable function with respect to x for . We can express it as a function of the power distribution cdf as
where for , for and for . The following inequalities can be deduced: For any , we have , and for , the reverse inequality holds: .
In addition, we can remark that is a decreasing function with respect to ; by setting , for any , we have
This inequality reveals a basic first-order stochastic dominance of the unit-Rayleigh distribution.
Moreover, one can note that, for any ,
implying that is a convex function with respect to .
2.4. Analysis of the pdf
In this section, we analyze as described in (2), also performing a mode(s) analysis. Such a global analysis has been performed in [16] for the unit-Weibull distribution, in full generality. Here, we provide more specific details on this aspect for the unit-Rayleigh distribution, including the expression of the mode and its comportment when varied.
As an alpha remark, let us note that, for any ,
with the equivalence when . Since it is positive, the function is not monotonic; the points 0 and 1 are not modes of . Now, for , we have
Therefore, a critical point for , say , satisfies and . After developments, we get
Let us now study the nature of this critical point. For any , we have
Since , the sign of is the one of
After developments, we obtain . We conclude that the point as defined by (5) is a maximum for the function ; it is the (unique) mode of the unit-Rayleigh distribution. Therefore, the pdf of the unit-Rayleigh distribution is “more or less bell shape”.
Let us now discuss the behavior of this mode. By setting , we have
implying that is an increasing function with respect to . Furthermore, we have
meaning that the mode can take all the values of the interval . This result indicates a certain flexibility of the unit-Rayleigh distribution regarding its mode. A graphical illustration of the possible shapes of is provided in Figure 2, considering the following values for : , , , and 4.
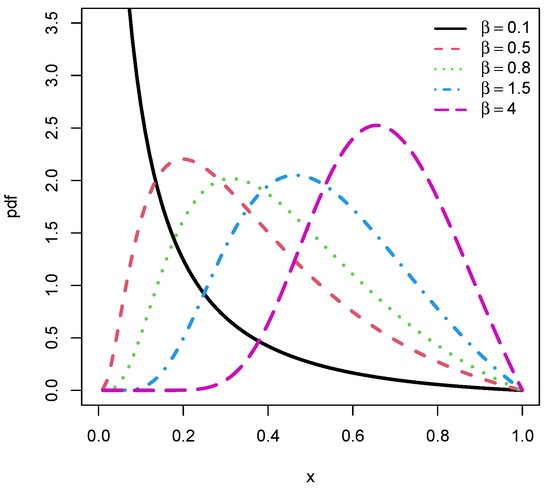
Figure 2.
Several curves of the pdf of the unit-Rayleigh distribution.
We see in Figure 2 the “more or less bell shape” of the pdf, with an increasing mode according to . Note that the black curve, corresponding to the pdf defined with , is “highly spiked”; the increasing curve does not appear in the figure because it is too sharp. In some senses, this graphical analysis completes the one performed in ([15] Figure 1, last subfigure).
2.5. Analysis of the hrf
In this section, we analyze as specified in (3). As far as we know, this aspect has been explored only graphically in ([15] Figure 2, last subfigure). Some new facts are discussed below. Firstly, for any , we have
with the equivalence when . Since is positive, the point 0 is a minimum for . Now, for , we have
where
being the difference of two positive functions.
In view of the denominator term, a critical point for , say , satisfies and . The study of this equation is not obvious from the analytical side. As a result, we propose some alternative arguments showing that the hrf can have various forms.
Firstly, due the presence of the in factor of the first term, by dominance, for any , we have . This implies the existence of a such that, for , we have and, a fortiori, . Hence, for , is an increasing function with respect to x. Now, assume that is small, say . Then, standard equivalences gives
and the equivalence function is equal to 0 if . Therefore, in the case where is small enough, at least one critical point exists. This new fact reveals that the hrf is not only an increasing function, as one can think at first sight of ([15] Figure 2, last subfigure); non monotonic shapes are possible for “small or not too small” .
We illustrate this new fact by some plots of in Figure 2, considering the following values for : , , , and .
We see in Figure 3 that the hrf can be increasing with convex and concave properties. For the black line corresponding to the hrf defined with , a bathtub shape is observed. These observations confirm the flexible hazard rate of the unit-Rayleigh distribution.
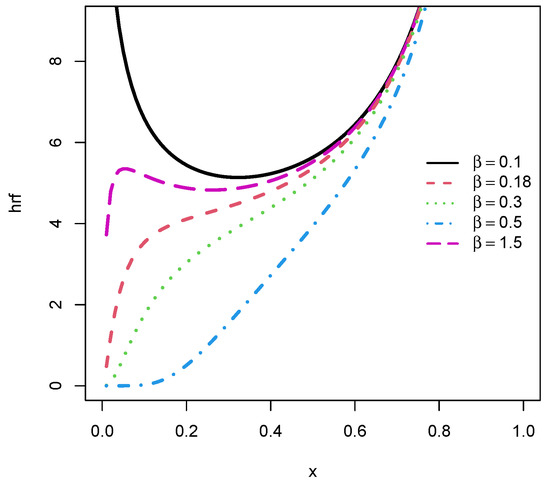
Figure 3.
Several curves of the hrf of the unit-Rayleigh distribution.
3. New Results
More mathematical results are developed in this section, all new.
3.1. Stochastic Order Results
We have already presented some stochastic order results involving the cdfs of the unit-Rayleigh and power distributions. More technical ones are described in the result below.
Proposition 1.
The following inequality holds:
where
- for , for and for ,
- for , for and for ,
both being cdfs of unit-distributions.
Proof.
The inequalities are immediate for and . For , we can express as . The desired result is a consequence of the following well-known inequalities: For , we have . The claims that and are valid cdfs are proved below. We have , , both are derivable for with, for ,
This concludes the proof of Proposition 1. ☐
As far as we know, the cdfs and described in Proposition 1 are not listed in the literature. They can be of independent interest for purposes out of the scope of this paper (modelling of proportion-type characteristics, constructions of new general families of continuous distributions, etc.).
3.2. Incomplete Moments
The incomplete moments of the unit-Rayleigh remain unexplored. We now fill this gap by providing their analytical expressions via comprehensive functions.
Proposition 2.
Let r be a nonnegative integer and X be a rv following the unit-Rayleigh distribution. Then, the r-th incomplete moment of X at is given as
where denotes the indicator function over an event A and is the complementary error function defined by , with .
Proof.
We recall that the unit-Rayleigh distribution corresponds to the one of the rv , where Y is a rv following the Rayleigh distribution with scale parameter , i.e., with pdf , with , and otherwise. Therefore, we have
By applying the change of variable , that is , and performing some calculus, we obtain
The result of Proposition 2 is obtained. ☐
From Proposition 2, by taking , we obtain with . The r-th raw moments of X can be derived as
We thus rediscover the formula in ([15] Subsection 2.2).
In addition, the incomplete moments of X allow us to define an arsenal of interesting measures and functions involving the unit-Rayleigh distribution, such as mean deviations, mean residual life function, variance residual life function, reversed mean residual life function, Zenga curve, and so on. The complete list can be found in the book of [25], among others.
For approximation purposes of the incomplete moments of X, for any , we can use the well-known expression and approximation of the function erfc(a) given as
where J denotes a large integer. Let us mention that some more simple approximations of exist, with the assumptions that x is “small enough” or “large enough” (see [26]). On the other side, is implemented in all the modern mathematical softwares, making the computations of straightforward.
The following result presents a new and simple series expansion of the incomplete moments, with direct integration; no existing results on is used. It thus provides an alternative expression to the one presented in Proposition 2.
Proposition 3.
Under the setting of Proposition 2, for any , the following series expansion holds:
where is the incomplete upper gamma function defined by , with .
Proof.
By making the change of variable as defined as (4), we get
By applying the Taylor series expansion of the exponential function, we obtain
Now, the change of variable yields
The proof of Proposition 3 follows from the above equalities. ☐
From Proposition 3, by taking with the convention in the sum, we rediscover , with . The r-th raw moments of X can be derived as
where is the standard gamma function defined by , with .
The following simple finite sum approximation holds:
where J denotes a large integer.
3.3. Probability Weighted Moments
The probability-weighted moments can be viewed as generalizations of raw moments. They appear quite naturally when we deal with the raw moments of order statistics. The closed forms of the probability weighted moments for the unit-Rayleigh distribution are given below.
Proposition 4.
Let r and s be two nonnegative integers and X be a rv following the unit-Rayleigh distribution. Then, the -th probability weighted moment of X is given as
being the complementary error function.
Proof.
First of all, based on (1) and (2), let us notice that
where denotes the pdf of a rv Z following the unit-Rayleigh distribution with scale parameter . Therefore
Owing to Proposition 2 with instead of and , we have
By combining the two equalities above, we conclude the proof of Proposition 4. ☐
Clearly, we have . The probability-weighted moments will find applications in the next section.
3.4. Order Statistics
The modeling of several physical systems involved the use of order statistics. In this section, the basic properties of the order statistics of the unit-Rayleigh distribution are discussed. The theory and details on order statistics in a general setting can be found in [27].
First, based on a well-known distributional result of order statistics, (1) and (2), the pdf of the u-th order statistic of X in a random sample of size n from the unit-Rayleigh distribution, say , is
In particular, for the minimum and maximum order statistics, we get
and
respectively. The raw moments of can be simply expressed via the probability weighted moments of the former unit-Rayleigh distribution. Indeed, from the first expression of in (6) and the binomial formula, we can write
and the r-th raw moment of is specified by
where, by Proposition 4,
From the raw moments of , several measures can be derived such as the skewness and kurtosis coefficients, L-moments, allowing to define the L-scale, L-skewness and L-kurtosis, among others.
3.5. Reliability Coefficient
The reliability coefficient allows us to study the behavior of various random systems. It is defined as the probability that a hierarchy exists between two characteristics of the system with unknown values a priori. All the details can be found in [28]. Here, we show that the reliability coefficient can be expressed in a simple manner for the unit-Rayleigh distribution.
Proposition 5.
Let U and V be two independent rvs following the unit-Rayleigh distribution with scale parameters β and , respectively. Then, the corresponding reliability coefficient is defined by and
Proof.
Let be the cdf of U, be the pdf of V and be the pdf of the unit-Rayleigh distribution with scale parameter . Then, we have
This proved Proposition 5. ☐
From Proposition 5, we clearly have for , for , and for . The simple expression of R is useful for statistical aims. In particular, by the invariance property, maximum likelihood estimates of the parameters and , say and , respectively, provide the maximum likelihood estimate for R given as
3.6. Tsallis Entropy
Commonly, the Tsallis entropy is a measure of randomness of a random variable. One can refer to the study of [29] for discussions on the roles of various entropy measures in applied sciences, including the Tsallis entropy. The following result concerns a series expansion of this entropy measure in the context of the unit-Rayleigh distribution.
Proposition 6.
Let and . Then, the Tsallis entropy of a random variable X following the unit-Rayleigh distribution can be expressed as
Proof.
We only need to treat the integral term in the definition of . Owing to (2), we have
Therefore, by making the change of variable , i.e., , and by introducing a rv Y following the Rayleigh distribution with scale parameter , we get
Now, by using the Taylor series expansion of the exponential function and the following well-known moment properties of the Rayleigh distribution: For any , , we have
By putting the above equalities together, we obtain
The desired result follows by substituting this series expansion into the former definition of . ☐
From Proposition 6, the following approximation holds:
where J is a large enough integer.
3.7. Some Bivariate Unit-Rayleigh Distributions
Now, we present some motivated ideas to construct bivariate unit-Rayleigh distributions, which are of interest for the modelling of conjoint characteristics with values on the unit interval. In order to keep a control on the structure of the marginal rvs, we propose to use the special probabilistic functions called copulas (see [30]).
As a first approach, we can define the Farlie-Gumbel-Morgenstern unit-Rayleigh distribution by the following cdf:
where , and are defined as (1) with the scale parameters and , respectively. Hence, for , we have
By taking , the marginal rvs are independent.
Similarly, one can also define a bivariate unit-Rayleigh distribution by using the Clayton copula. Thus, we can define the Clayton unit-Rayleigh distribution by the following cdf:
where and , and are defined as (1) with the scale parameters and , respectively. Thus, for , we have
As the last example, we can define the Gumbel unit-Rayleigh distribution by the following cdf:
where , and are defined as (1) with the scale parameters and , respectively. Hence, for , we have
These bivariate extensions generate bivariate models that may be useful in the analysis of compositional data with values over , involving proportions and/or percentages. Concrete applications can be found in chemistry, demography, geology, high throughput sequencing and survey. Estimation of the model parameters can be performed via the multivariate likelihood estimation method (see [31]). The detail on the statistical analysis of compositional data can be found in [32,33].
4. Applications
This section shows the applicability behavior of the unit-Rayleigh distribution in a data analysis framework, which has not received a particular attention in [15] or [16]. We estimate the parameter by the maximum likelihood method, as done in [15] but by putting the shape parameter equal to 2; it is not to be estimated. In this case, from n observations of a rv following the unit-Rayleigh distribution, say , the maximum likelihood estimate of is defined by
Based on (1)–(3), the estimated cdf, pdf and hrf are obtained by substituting by in their own expressions.
Thus, with the maximum likelihood method, we aim to compare the fit behavior of the unit-Rayleigh distribution with those of the following well-known one-parameter competitors.
- the one-parameter Kumaraswamy (Ku) distribution (or special Lehmann type II power distribution) defined by the cdf given asfor and for , with . See [7].
- the Topp–Leone (TL) distribution defined by the cdf specified byfor and for , where . See [6].
- the one-parameter beta (B) distribution defined by the cdf given asfor and for , where and , .
- the power (P) distribution defined by the cdf expressed byfor and for , where .
- the transmuted (TM) distribution defined by the cdf expressed byfor and for , where . We may refer to [34] all the characteristics of the transmuted distribution.
These distributions can be assimilated to semi-parametric statistical models for adjustment purposes. The following classical criteria are used to compare the fits: minus estimated log-likelihood , consistent Akaike information criterion (CAIC), Hannan–Quinn information criterion (HQIC), Akaike information criterion (AIC), Bayesian information criterion (BIC), Cramer-von Mises criterion (W) and Anderson–Darling criterion (A) are computed. The lower the values of these criteria, the better the fit. The R software developed by [35] is used, with the help of the R function goodness.fit function from the package AdequacyModel (see [36]).
Data with values into can be of various natures, including percentages or proportions. Based on positive data , one can suppose that a phenomenon can be modeled by a random variable U with estimation of the upper bound of its theoretical support by or any reasonable larger value. Then, we can consider the random variable which has support into . In all the situations, we can recover the distribution of U by multiplication with m a posteriori. In the next, three data sets are considered. The first two data sets used the previous schema, and the third one contains proportions-like data initially communicated with values in .
First, we consider data of times to infection of kidney dialysis patients in months, as described by [37]. The “times of infection” data set is: {2.5, 2.5, 3.5, 3.5, 3.5, 4.5, 5.5, 6.5, 6.5, 7.5, 7.5, 7.5, 7.5, 8.5, 9.5, 10.5, 11.5, 12.5, 12.5, 13.5, 14.5, 14.5, 21.5, 21.5, 22.5, 22.5, 25.5, 27.5}. Now, we make a normalization operation by divided these data by 30, to get data between 0 and 1. The transformed data set becomes: {0.08333333, 0.08333333, 0.11666667, 0.11666667, 0.11666667, 0.15000000, 0.18333333, 0.21666667, 0.21666667, 0.25000000, 0.25000000, 0.25000000, 0.25000000, 0.28333333, 0.31666667, 0.35000000, 0.38333333, 0.41666667, 0.41666667, 0.45000000, 0.48333333, 0.48333333, 0.71666667, 0.71666667, 0.75000000, 0.75000000, 0.85000000, 0.91666667}.
The second data set concerns the failure times of the air conditioning system of an airplane (in hours), as reported in [38]. These “failure times” data set is: {23, 261, 87, 7, 120, 14, 62, 47, 225, 71, 246, 21, 42, 20, 5, 12, 120, 11, 3, 14, 71, 11, 14, 11, 16, 90, 1, 16, 52, 95}. Again, we make a normalization operation by dividing these data by 265, to get data between 0 and 1. That is, we work with the following data set: {0.086792453, 0.984905660, 0.328301887, 0.026415094, 0.452830189, 0.052830189, 0.233962264, 0.177358491, 0.849056604, 0.267924528, 0.928301887, 0.079245283, 0.158490566, 0.075471698, 0.018867925, 0.045283019, 0.452830189, 0.041509434, 0.011320755, 0.052830189, 0.267924528, 0.041509434, 0.052830189, 0.041509434, 0.060377358, 0.339622642, 0.003773585, 0.060377358, 0.196226415, 0.358490566}.
The third data set is about the maximum flood levels of a particular river in Pennsylvania in millions of cubic feet per second (mlcf/s). It is reported in [39]. With this unity of measure, the data are of proportion type, belonging to . These “flood levels” data set is: {0.265, 0.269, 0.297, 0.315, 0.3235, 0.338, 0.379, 0.379, 0.392, 0.402, 0.412, 0.416, 0.418, 0.423, 0.449, 0.484, 0.494, 0.613, 0.654, 0.74}
The data sets are basically analyzed in Table 1.

Table 1.
Descriptive analysis for the times of infection, failure times and flood levels data sets.
Table 1 indicates that the time of infection data set is right-skewed, with small dispersion and negative kurtosis. This point means that the curve of the unknown pdf behind these data is flatter than a normal pdf. Concerning the failure times data set, we can say that is “significantly” right-skewed, with small dispersion and “significant” kurtosis. For the flood levels data set, we can say that is right-skewed, with small dispersion and slightly positive kurtosis.
So the nature of the three data sets differs in numerous aspects. This is also illustrated through the corresponding boxplots in Figure 4, presenting different quantiles characteristics. Note that some extreme points are present.
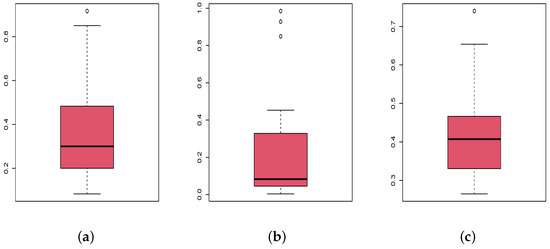
Figure 4.
Boxplots of the (a) times of infection data set, (b) failure times data set and (c) flood levels data set.
We complete the first statistical analysis by the total time on test (TTT) plots of the three data sets in Figure 5, Figure 6 and Figure 7, respectively.
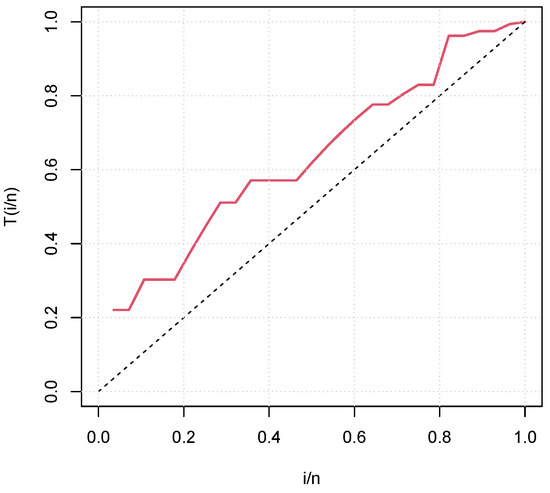
Figure 5.
Total time on test (TTT) plot of the times of infection data set.
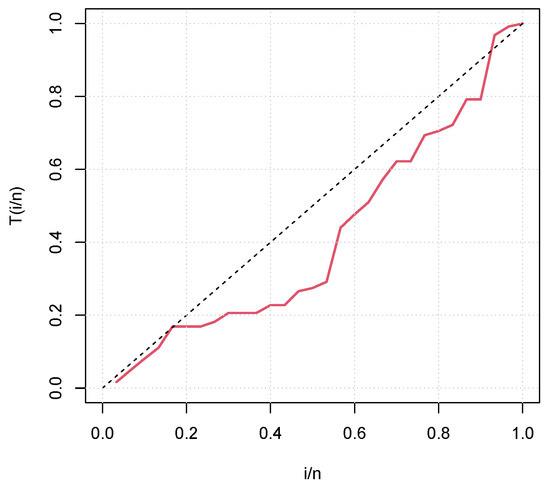
Figure 6.
TTT plot of the failure times data set.
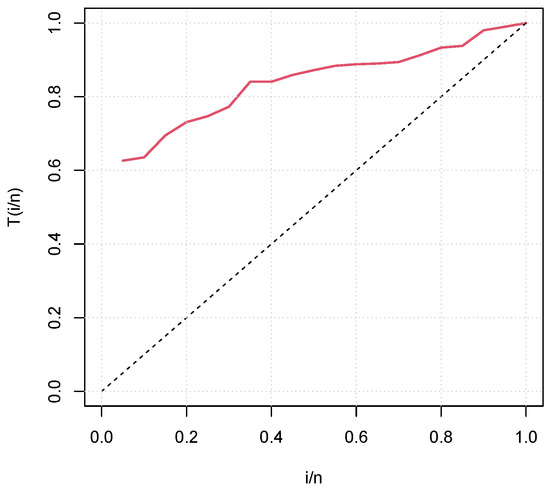
Figure 7.
TTT plot of the flood levels data set.
From Figure 5, we see that the TTT curve is concave, which corresponds to an increasing failure intensity for the times of infection data set. Figure 6 shows that the TTT curve is convex, then concave, suggesting a U-shape failure intensity for the failure times data set. In Figure 7, the TTT curve is concave, indicating an increasing failure intensity for the flood levels data set. Thus, these TTT plots highlighted the different nature of the failure intensity of these three data sets. It should also be noted that the increasing and U-shaped failure intensities are covered by the unit-Rayleigh model, which makes it suitable for more suitable analyzes of these data sets.
The quality of fit measurements for the models, as well as the maximum likelihood estimates (MLEs) and standard errors (SEs) of the parameters involved are collected in Table 2, Table 3 and Table 4 for the times of infection, failure times and flood levels data sets, respectively.
Table 2.
Criteria and goodness-of-fit measures, maximum likelihood estimates (MLEs) and standard errors (SEs) for the times of infection data set.
Table 3.
Criteria and goodness-of-fit measures, MLEs and SEs for the failure times data set.
Table 4.
Criteria and goodness-of-fit measures, MLEs and SEs for the flood level data set.
From Table 2, Table 3 and Table 4, the unit-Rayleigh model can be considered as the best model for the three data sets, because it has the smallest values for the CAIC, HQIC, AIC, BIC, W and A statistics. Figure 8, Figure 9 and Figure 10 confirm this claim through a graphical approach. In them, we plot the estimated pdfs over the adequate histograms for the times of infection, failure times and flood levels data sets, respectively.
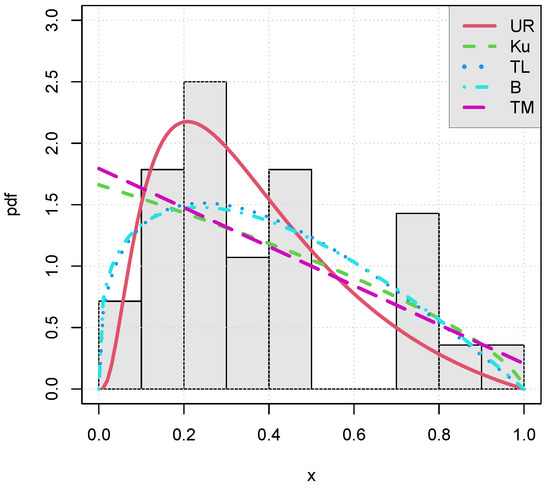
Figure 8.
Plots of the estimated pdfs of the considered models for the times of infection data set.
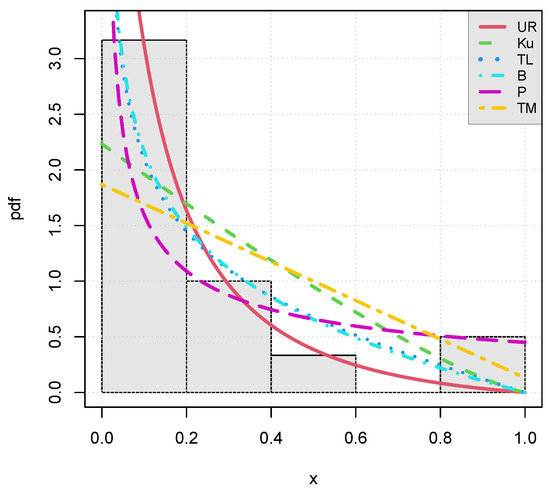
Figure 9.
Plots of the estimated pdfs of the considered models for the failure times data set.
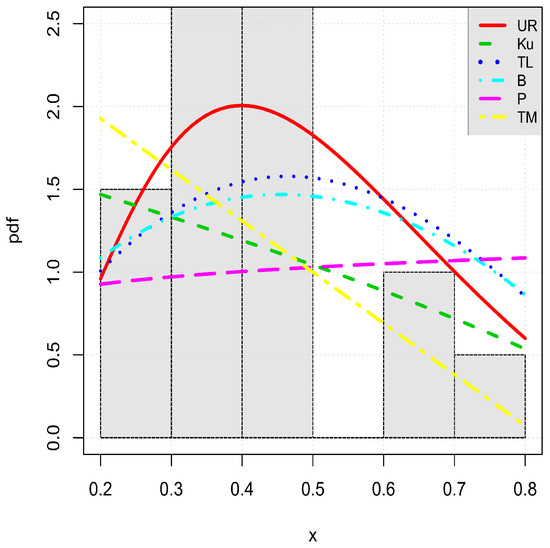
Figure 10.
Plots of the estimated pdfs of the considered models for the flood level data set.
As anticipated, Figure 8, Figure 9 and Figure 10 show the nice fits of the unit-Rayleigh model, which has captured the main characteristics of the data contrary to most of the competitors.
We complete this graphical analysis by plotting the estimated hrfs of the unit-Rayleigh model only in Figure 11, Figure 12 and Figure 13.
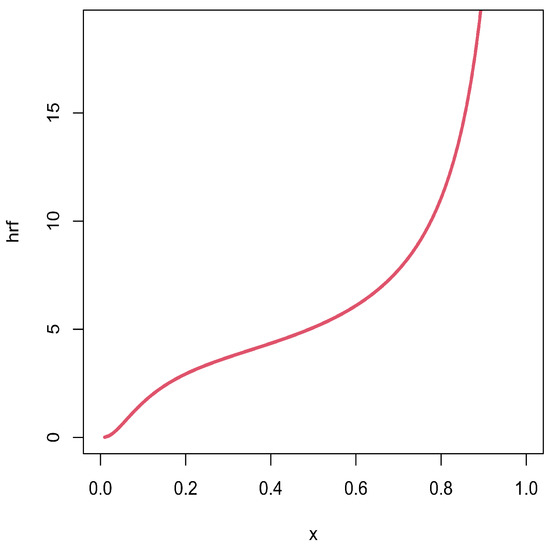
Figure 11.
Plots of the estimated hrfs for the times of infection data set.
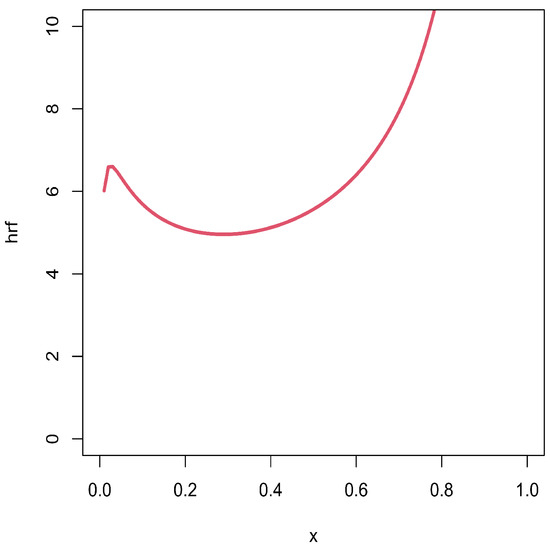
Figure 12.
Plots of the estimated hrfs for the failure times data set.
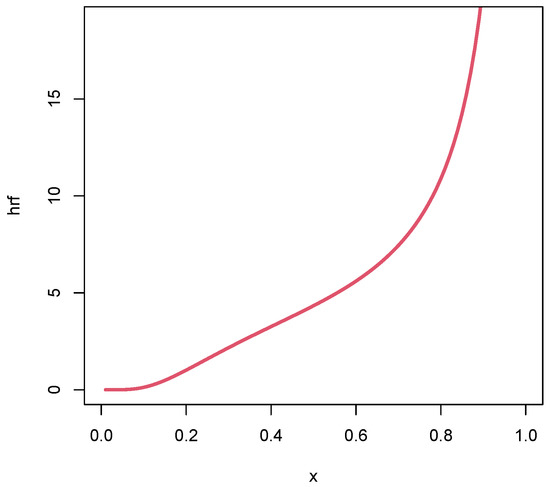
Figure 13.
Plots of the estimated hrfs for the flood levels data set.
As expected with the TTT plot in Figure 5, Figure 11 shows an increasing estimated hrf of the unit-Rayleigh model for the times of infection data set. Figure 12 indicates a U-shape estimated hrf for the failure time data set, which is coherent with the observation done in Figure 6. Figure 13 reveals an increasing estimated hrf for the flood levels data set, as anticipated in Figure 7. We thus see the importance of the possible U-shape of the hrf of the unit-Rayleigh distribution as evoked above for such a modelling.
All the preceding points highlight the undeniable capacities of the unit-Rayleigh model in the adjustment of various data. A possible continuation of this work may be the use of the unit-Rayleigh distribution for the construction of general families of distributions, through composition techniques or others, the construction of regression models including characteristics with values on the unit interval through an appropriated link function (see [40]). The presented bivariate versions of the unit-Rayleigh distribution can have applications in the treatment of compositional data with values over (see [32]). All of these research scopes remain to be developed; we leave it for future investigations.
5. Conclusions
In this article, we have shown that the unit-Rayleigh distribution is not only a special case of the unit-Weibull distribution like many others, discussing specific motivations, interests, theoretical results, and practical benefits. In particular, numerous important functions and measures have closed-form expressions that can be useful for various probability and statistical purposes. The most relevant theoretical facts was a detailed analysis of the main functions, results on some stochastic ordering, the expressions of the incomplete and probability weighted moments, as well as those of the Tsallis entropy and reliability coefficient, various properties on the order statistics, and a list of potential bivariate extensions. An applied work has shown how the unit-Rayleigh distribution can be used in practice, with a quite simple estimation of the unique unknown parameter by the maximum likelihood technique. Based on three real data sets, we have proved empirically that it can be superior to other well-reputed one-parameter unit distributions, namely the one-parameter Kumaraswamy, Topp–Leone, one-parameter beta, power and transmuted distributions. We hope that this study will be able to convince applied statisticians, and readers in general, that the unit-Rayleigh distribution can be used effectively in different fields dealing with unit data.
Author Contributions
R.B, C.C., F.J., M.E., A.A., M.Z.and S.A.; Writing—review—editing, M-H.T. All authors have read and agreed to the published version of the manuscript.
Funding
The Deanship of Scientific Research (DSR) at King Abdulaziz University, Jeddah, Saudi Arabia funded this project, under grant no. (FP-186-42).
Acknowledgments
We would like to thank all three reviewers and the academic editor for their interesting comments on the article, greatly improving it in this regard. This project was funded by the Deanship of Scientific Research (DSR) at King Abdulaziz University, Jeddah, Saudi Arabia funded this project, under grant no. (FP-186-42). The authors, therefore, acknowledge with thanks to DSR technical and financial support.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Al-Hussaini, E.K. Composition of cumulative distribution functions. J. Stat. Theory Appl. 2012, 11, 333–336. [Google Scholar]
- Tahir, M.H.; Cordeiro, G.M. Compounding of distributions: A survey and new generalized classes. J. Stat. Distrib. Appl. 2016, 3, 13. [Google Scholar] [CrossRef]
- Kieschnick, R.; McCullough, B.D. Regression analysis of variates observed on (0,1): Percentages, proportions and fractions. Stat. Model. 2003, 3, 193–213. [Google Scholar] [CrossRef]
- Ferrari, S.; Cribari-Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 2004, 31, 799–815. [Google Scholar] [CrossRef]
- Johnson, N.L. Systems of frequency curves generated by methods of translation. Biometrika 1949, 36, 149–176. [Google Scholar] [CrossRef] [PubMed]
- Topp, C.W.; Leone, F.C. A Family of J-shaped frequency functions. J. Am. Stat. Assoc. 1955, 50, 209–219. [Google Scholar] [CrossRef]
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Grassia, A. On a family of distributions with argument between 0 and 1 obtained by transformation of the Gamma distribution and derived compound distributions. Aust. J. Stat. 1977, 19, 108–114. [Google Scholar] [CrossRef]
- Tadikamalla, P.R. On a family of distributions obtained by the transformation of the gamma distribution. J. Stat. Comput. Simul. 1987, 13, 209–214. [Google Scholar] [CrossRef]
- Tadikamalla, P.R.; Johnson, N.L. Systems of frequency curves generated by transfor- mations of logistic variables. Biometrika 1982, 69, 461–465. [Google Scholar] [CrossRef]
- Barndorff-Nielsen, O.; Jorgensen, B. Some parametric models on the Simplex. J. Multivar. Anal. 1991, 39, 106–116. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.; Dey, S. The unit-Birnbaum-Saunders distribution with applications. Chil. J. Stat. 2018, 9, 47–57. [Google Scholar]
- Lemonte, A.J.; Barreto-Souza, W.; Cordeiro, G.M. The exponentiated Kumaraswamy distribution and its log-transform. Braz. J. Probab. Stat. 2013, 27, 31–53. [Google Scholar] [CrossRef]
- Pourdarvish, A.; Mirmostafaee, S.M.T.K.; Naderi, K. The exponentiated Topp-Leone distribution: Properties and application. J. Appl. Environ. Biol. 2015, 5, 251–256. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Ghitany, M.E. The unit-Weibull distribution and associated inference. J. Appl. Probab. Stat. 2018, 13, 1–22. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Fernandes, L.B.; de Oliveira, R.P.; Ghitany, M.E. The unit-Weibull distribution as an alternative to the Kumaraswamy distribution for the modeling of quantiles conditional on covariates. J. Appl. Stat. 2020, 47, 954–974. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.; Dey, S. Unit-Gompertz distribution with applications. Statistica 2019, 79, 25–43. [Google Scholar]
- Mazucheli, J.; Menezes, A.F.B.; Chakraborty, S. On the one parameter unit-Lindley distribution and its associated regression model for proportion data. J. Appl. Stat. 2019, 46, 700–714. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Mazucheli, J.; Menezes, A.F.B.; Alqallaf, F. The unit-inverse Gaussian distribution: A new alternative to two-parameter distributions on the unit interval. Commun. Stat. Theory Methods 2019, 48, 3423–3438. [Google Scholar] [CrossRef]
- Rodrigues, J.; Bazán, J.L.; Suzuki, A.K. A flexible procedure for formulating probability distributions on the unit interval with applications. Commun. Stat. Theory Methods 2020, 49, 738–754. [Google Scholar] [CrossRef]
- Korkmaz, M.C. The unit generalized half normal distribution: A new bounded distribution with inference and applications. UPB Sci. Bull. Ser. Appl. Math. Phys. 2020, 82, 133–140. [Google Scholar]
- Haq, M.A.; Hashmi, S.; Aidi, K.; Ramos, P.L.; Louzada, F. Unit modified Burr-III distribution: Estimation, characterizations and validation test. Ann. Data Sci. 2020. [Google Scholar] [CrossRef]
- Weisstein, E.W. Rayleigh Distribution, From MathWorld—A Wolfram Web Resource. 2020. Available online: https://mathworld.wolfram.com/RayleighDistribution.html (accessed on 30 October 2020 ).
- Benini, R. I diagrammi a scala logaritmica (a proposito della graduazione per valore delle successioni ereditarie in Italia, Francia e Inghilterra). G. Degli Econ. Serie II 1905, 16, 222–231. [Google Scholar]
- Cordeiro, G.M.; Silva, R.B.; Nascimento, A.D.C. Recent Advances in Lifetime and Reliability Models; Bentham Sciences Publishers: Sharjah, UAE, 2020. [Google Scholar] [CrossRef]
- Decker, D.L. Computer evaluation of the complementary error function. Am. J. Phys. 1975, 43, 833–834. [Google Scholar] [CrossRef]
- David, H.A.; Nagaraja, H. Order Statistics, 3rd ed.; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Surles, J.G.; Padgett, W.J. Inference for reliability and stress-strength for a scaled Burr-type X distribution. Lifetime Data Anal. 2001, 7, 187–200. [Google Scholar] [CrossRef]
- Amigo, J.M.; Balogh, S.G.; Hernandez, S. A brief review of generalized entropies. Entropy 2018, 20, 813. [Google Scholar] [CrossRef]
- Nelsen, R.B. An Introduction to Copulas, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Casella, G.; Berger, R.L. Statistical Inference; Brooks/Cole Publishing Company: Bel Air, CA, USA, 1990. [Google Scholar]
- Aitchison, J. The Statistical Analysis of Compositional Data; Chapman and Hall: London, UK, 1986; 416p. [Google Scholar]
- Pawlowsky-Glahn, V.; Egozcue, J.J.; Tolosana-Delgado, R. Modeling and Analysis of Compositional Data; Wiley: New York, NY, USA, 2015. [Google Scholar]
- Shaw, W.T.; Buckley, I.R. The alchemy of probability distributions: beyond Gram-Charlier expansions, and a skew-kurtotic-normal distribution from a rank transmutation Map. arXiv 2009, arXiv:0901.0434. [Google Scholar]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2005; ISBN 3-900051-07-0. Available online: http://www.R-project.org (accessed on 30 October 2020 ).
- Marinho, P.R.D.; Silva, R.B.; Bourguignon, M.; Cordeiro, G.M.; Nadarajah, S. AdequacyModel: An R package for probability distributions and general purpose optimization. PLoS ONE 2019, 14, e0221487. [Google Scholar] [CrossRef]
- Klein, J.P.; Moeschberger, M.L. Survival Analysis: Techniques for Censored and Truncated Data; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Linhart, H.; Zucchini, W. Model Selection; Wiley: New York, NY, USA, 1986. [Google Scholar]
- Dumonceaux, R.; Antle, C.E. Discrimination between the lognormal and Weibull distributions. Technometrics 1973, 15, 923–926. [Google Scholar] [CrossRef]
- Bonat, W.H.; Ribeiro, P.J., Jr.; Zeviani, W.M. Regression models with responses on the unit interval: specification, estimation and comparison. Biom. Braz. J. 2012, 30, 415–431. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).