A Short-Patterning of the Texts Attributed to Al Ghazali: A “Twitter Look” at the Problem

Abstract
1. Introduction and Problem Formulation
1.1. Abu Hamid Al Ghazali
1.2. Authorship Attribution
1.3. Paper Contribution
- Adapting a Convolutional Neural Network (CNN) model intended to recognize anonymous authorship using short text patterns;
- Performing detailed analysis of the authorship of creations attributed to Al Ghazali, confirming the reliability of the suggested model;
- Discovering a short pattern structure in two famous works, Mishakat al-Anwa and Tahafut al-Falasifa, indicating that they very likely to belong to the Pseudo-Ghazali category (merely attributed to Al Ghazali);
- Suggesting a new signal-like text representation to study stylistic text characteristics from the signal processing standpoint.
2. Proposed Method
2.1. Arab Words Embedding
2.2. Convolutional Neural Networks
- l—the length of the training sequences;
- l0—the data batch size;
- , the sizes of the 1D convolution kernels;
- s—the stride size;
- Q—the number of feature maps (kernels having sizes ;
- N0—, the number of neurons in the last fully connected layer;
- Emb—an embedding method into R|V|×d (where the columns correspond to the separate words).
2.3. Handling of Imbalanced Training Data
- Balancing routine (D1, D2, F1, F)
- Input parameters:
- D1 and D2—the datasets under consideration;
- F1—the undersampling rate;
- F—the multiplying rate.
- Procedure:
- Undersample a sample S1 from D1 with the undersampling rate F1* |D1|;
- F* F1 times replicate D2 and get S2;
- Return S1 and S2.
2.4. Preprocessing
- Remove all punctuation marks, English letters, special characters, and digits;
- Remove tashkeel;
- Remove longation;
- Normalization:
- ○
- Replace (‘وو’, ‘و’), (‘يي’, ‘ي’), and (‘اا’, ‘ا’);
- ○
- Remove diacritics.
2.5. Procedure
| Algorithm 1. The proposed procedure’s pseudocode. |
|
3. Numerical Study
3.1. Material
- The source collection (Cl0) contains text from Al Ghazali’s most significant work, Iḥyāʾ ʿulūm al-dīn, downloaded from the site http://ghazali.org/ihya/ihya.htm as a collection of 41 files with a total size of 8.5 MB;
- The alternative collection (Cl1) include the following texts, with a total size of 1.0 MB:
- Al-Ajwiba al-Ghazzāliyya fi ’l-masāʾil al-ukhrawiyya*;
- Al-Durra Al-Fakhira*;
- Al-Risala al-Ladunniyya*;
- Ayyuhal Walad*;
- Khulasa al-Tasanif fi al-Tasawwuf*;
- Ma’arij al-quds fi madarij ma’rifat al-nafs*;
- Miʿraj al-salikin*;
- Risalat al-Tayr*;
- Sirr al-ʻālamayn wa-kashf mā fī al-dārayn*.
- The test collection is composed of the following:
- Texts agreed upon as written by Al Ghazali;
- Al-Mankhul min Taliqat al-Usul* (an anchor);
- Al Mustasfa min ilm al-Usul*;
- Fada’ih al-Batiniyya wa Fada’il al-Mustazhiriyy*;
- Faysal at-Tafriqa Bayna al-Islam wa al-Zandaqa*;
- Kitab al-iqtisad fi al-i’tiqad*;
- Kitab Iljam Al- Awamm an Ilm Al-Kalam*;
- Tahafut al-Falasifa.
- Texts agreed upon as not written by Al Ghazali (Pseudo-Ghazali):
- 8.
- Ahliyi al-Madnun bihi ala ghayri*;
- 9.
- Kimiya-yi Sa’ādat* (an anchor);
- A book with questionable authorship: Mishakat al-Anwar (Niche of Lights) (http://ghazali.org/books/mishkat-al-anwar.doc).
3.2. Experiment Setup
- Niter–the number of iterations = 20;
- Cl0–the source collection (labeled as 0);
- Cl1–the alternative collection (labeled as 1);
- Cl2–the tested collection;
- l–the length of the training sequences = 128;
- F1–the undersampling rate = 2;
- F–the multiplying rate = 3;
- Emb–the words embedding method (the AraVec CBOW 300 dimensional representation, trained on the Wikipedia corpus);
- Accuracy threshold = 0.96;
- Silhouette threshold = 0.75;
- The network (Net) parameters:
- ✓
- T–the number of kernels (3);
- ✓
- H–the sizes of the 1D convolution kernels (3,6,12);
- ✓
- s–the stride size (1);
- ✓
- Q–the number of feature maps (filters) = 500;
- ✓
- N0–the number of neurons in the fully conned layer = 512;
- ✓
- l0–the data batch size = 50;
- ✓
- Pooling size = 500;
- ✓
- Learning rate = 0.01;
- ✓
- Momentum = 0.9;
- ✓
- Decay = 1;
- ✓
- Dropout rate = 0.5;
- ✓
- Number of epoch = 10;
- ✓
- Activation function = relu;
- ✓
- Loss = Categorical cross-entropy;
- ✓
- Cross-validation split = 0.25;
- ✓
- Output size = 2;
- ✓
- Optimizer = Adam;
- ✓
- Metric = Accuracy.
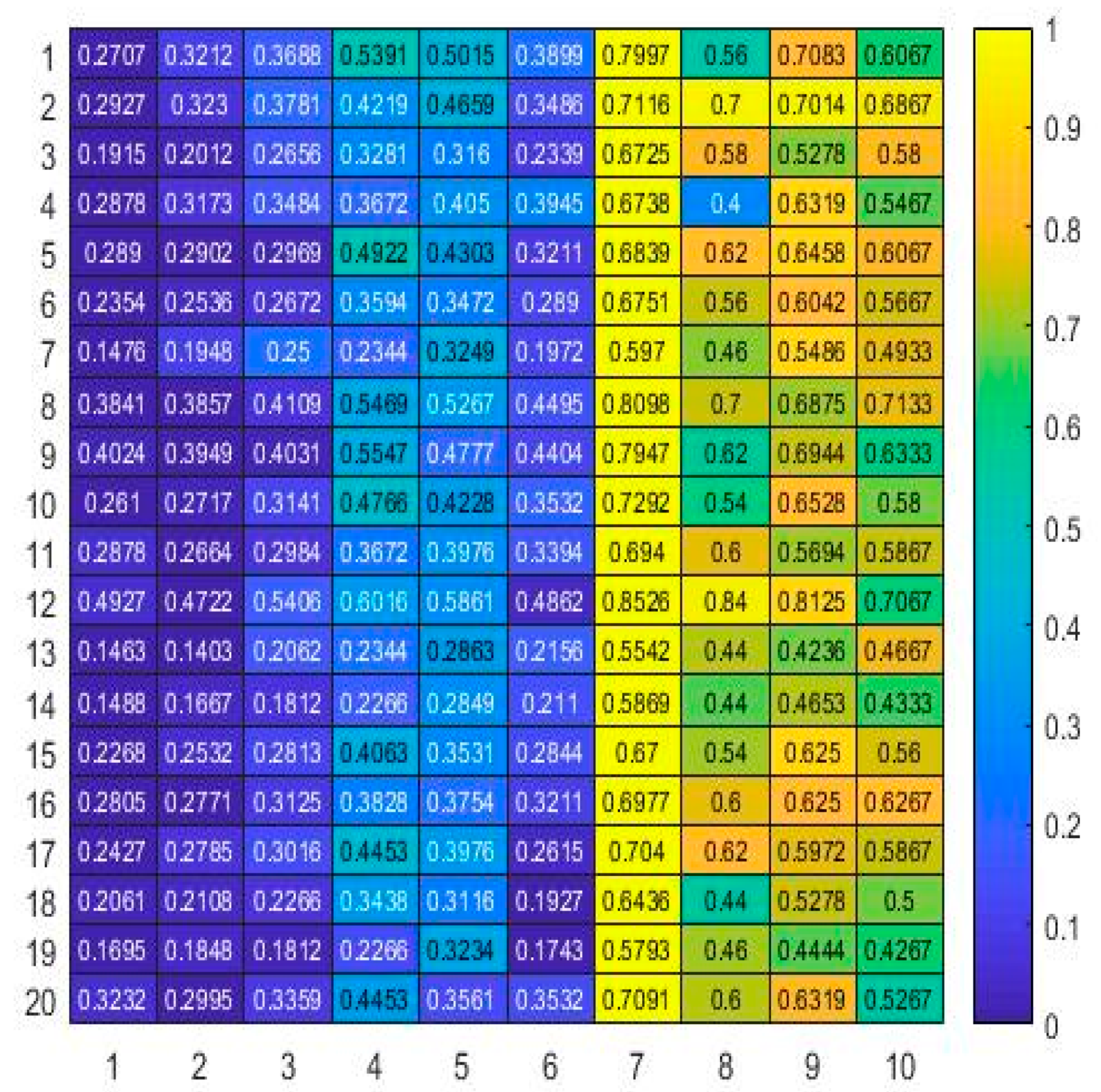
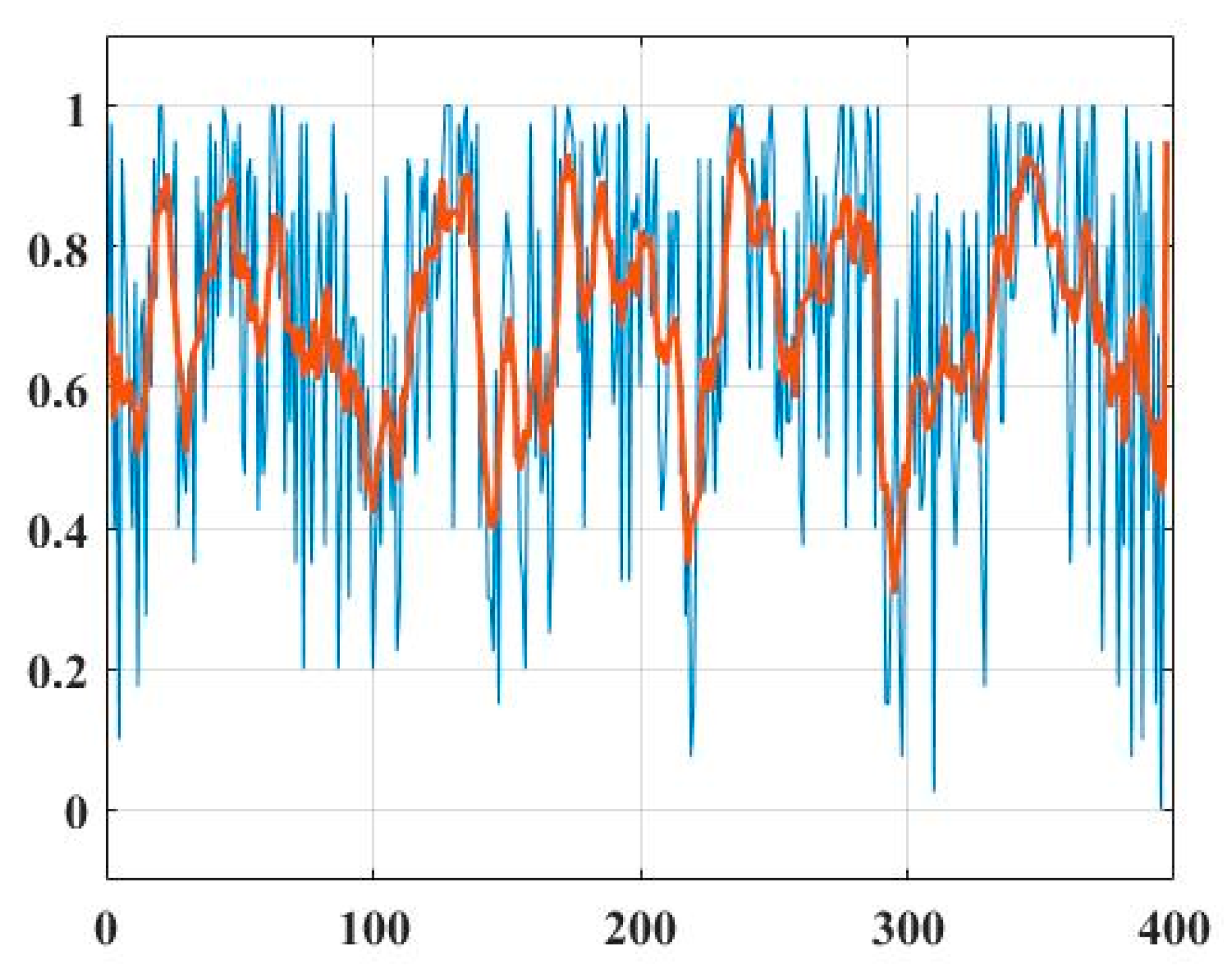
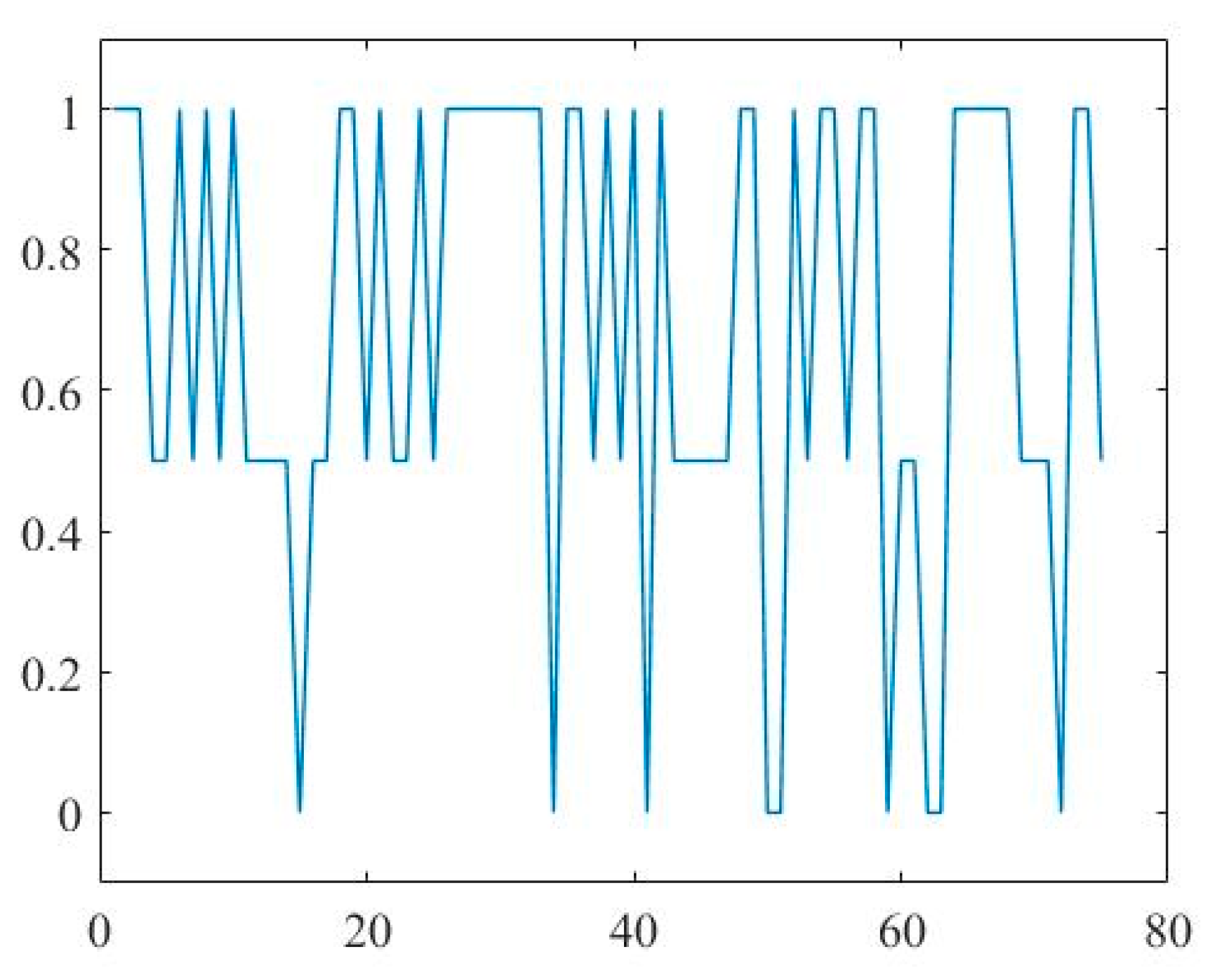
3.3. Results
4. Conclusions and Discussion
Funding
Conflicts of Interest
References
- Hunt, J. The Pursuit of Learning in the Islamic World, 610–2003; McFarland: Jefferson, NC, USA, 2004. [Google Scholar]
- Watt, W.M. Al-Ghazālī, Muslim Jurist, Theologian, and Mystic; Encyclopædia Britannica, Inc.: Chicago, IL, USA, 2020; Available online: https://www.britannica.com/biography/al-Ghazali (accessed on 1 November 2020).
- Watt, W.M. The Faith and Practice of Al-Ghazali; Revised Edition; Oneworld Publications: London, UK, 1 February 2000. [Google Scholar]
- Watt, W.M. Ghazali/Abu/Hamed/Mohammad, II, III; Encyclopedia Iranica: New York, NY, USA; pp. 1–12, In Print.
- Wensinck, A.J. Ghazali’s Mishkat al-Anwar (Niche of Lights). In Semietische Studien: Uitde Nalatenschap; A.W. Sijthoff’s Uitgeversmaatschappij, N.V.: Leiden, The Netherlands, 1941. [Google Scholar]
- Wensinck, A.J. On the Relation between Ghazali’s Cosmology and His Mystiscism. In Mededeelingen der Koninklijke Akademie van Wetenschappen, Afdeeling Letterkunde 75; Series A 6; Noord-Hollandsche Uitgevers-Maatschappij: Groningen, The Netherlands, 1993; pp. 183–209. [Google Scholar]
- Alred, J.; Brusaw, C.; Oliu, W. Handbook of Technical Writing, 9th ed.; St. Martin’s Press: New York, NY, USA, 2008. [Google Scholar]
- Amelin, K.S.; Granichin, O.N.; Kizhaeva, N.; Volkovich, Z. Patterning of writing style evolution by means of dynamic similarity. Pattern Recognit. 2018, 77, 45–64. [Google Scholar] [CrossRef]
- Koppel, M.; Schler, J.; Argamon, S. Computational methods in authorship attribution. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 9–26. [Google Scholar] [CrossRef]
- Goldberg, Y. A Primer on Neural Network Models for Natural Language Processing. arXiv 2015, arXiv:1510.00726. [Google Scholar] [CrossRef]
- Goldberg, Y.; Hirst, G.; Liu, Y.; Zhang, M. Neural Network Methods for Natural Language Processing. Synth. Lect. Hum. Lang. Technol. 2017, 10, 1–309. [Google Scholar] [CrossRef]
- Prasha, S.; Sebastian, S.; Fabio, G.; Manuel, M.; Paolo, M.; Thamar, S. Convolutional Neural Networks for Authorship Attribution of Short Texts, 6. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 2, pp. 669–674. [Google Scholar]
- Aydoğan, M.; Karci, A. Spelling Correction with the Dictionary Method for the Turkish Language Using Word Embeddings. Eur. J. Sci. Technol. 2020, 57–63. [Google Scholar] [CrossRef]
- Aydoğan, M.; Karci, A. Turkish Text Classification with Machine Learning and Transfer Learning. In Proceedings of the 2019 International Artificial Intelligence and Data Processing Symposium (IDAP), Malatya, Turkey, 21–22 September 2019; pp. 1–6. [Google Scholar]
- Aydoğan, M.; Karci, A. Improving the accuracy using pre-trained word embeddings on deep neural networks for Turkish text classification. Phys. A Stat. Mech. Its Appl. 2020, 541, 123288. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.; Islam, S.R.; Ali, A.; Attique, M.; Imran, M.; Kwak, K.S. An intelligent healthcare monitoring framework using wearable sensors and social networking data. Future Gener. Comput. Syst. 2021, 114, 23–43. [Google Scholar]
- Farman, A.; Daehan, K.; Pervez, K.; Shaker, E.; Amjad, A.; Sana, U.; Kye Hyun, K.; Kyung-Sup, K. Transportation sentiment analysis using word embedding and ontology-based topic modeling. Knowl. Based Syst. 2019, 174, 27–42, ISSN 0950-7051. [Google Scholar]
- Watt, W.M. A Forgery in al-Ghazali’s Mishkat? J. Royal Asiat. Soc. 1949, 5–22. Available online: https://www.ghazali.org/articles/watt-1949.pdf (accessed on 1 November 2020). [CrossRef]
- Harris, Z. Distributional structure. Word 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems 26, Proceedings of theTwenty-Seventh Conference on Neural Information Processing Systems NIPS, Lake Tahoe, NV, USA, 5–10 December 2013; Neural Information Processing Systems Foundation, Inc.: San Diego, CA, USA, 2013. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Pennington., J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. FastText.zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Soliman, A.B.; Eissa, K.; El-Beltagy, S.R. AraVec: A set of Arabic Word Embedding Models for use in Arabic NLP. In Proceedings of the Third International Conference On Arabic Computational Linguistics, ACLING 2017, Dubai, UAE, 5–6 November 2017; Shaalan, K., El-Beltagy, S.R., Eds.; Elsevier: Amsterdam, The Netherlands, 2017; Volume 117, pp. 256–265. [Google Scholar]
- Garidner, W.H.T. Al-Ghazali’s Mishkat al-Anwar and the Ghazali Problem. Der Islam 1914, 5, 121–153. [Google Scholar]
- Landolt, H. Ghazali and ‘Religionswissenschaft’: Some Notes on the Mishkat al-Anwar for Professor Charles, J. Adams. Asiatische Studien 1991, 45, 1–72. [Google Scholar]
- Treiger, A. Monism and Monotheism in al-Ghazali’s Mishkat al-Anwar. J. Quranic Stud. 2007, 9, 1–27. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Chunks | Total Size | |
|---|---|---|
| 1 | 26 | 32.2 |
| 2 | 95 | 108.9 |
| 3 | 10 | 14.8 |
| 4 | 33 | 39.6 |
| 5 | 49 | 53.9 |
| 6 | 269 | 365.4 |
| 7 | 131 | 169.5 |
| 8 | 7 | 9.2 |
| 9 | 174 | 28.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Volkovich, Z. A Short-Patterning of the Texts Attributed to Al Ghazali: A “Twitter Look” at the Problem. Mathematics 2020, 8, 1937. https://doi.org/10.3390/math8111937
Volkovich Z. A Short-Patterning of the Texts Attributed to Al Ghazali: A “Twitter Look” at the Problem. Mathematics. 2020; 8(11):1937. https://doi.org/10.3390/math8111937
Chicago/Turabian StyleVolkovich, Zeev. 2020. "A Short-Patterning of the Texts Attributed to Al Ghazali: A “Twitter Look” at the Problem" Mathematics 8, no. 11: 1937. https://doi.org/10.3390/math8111937
APA StyleVolkovich, Z. (2020). A Short-Patterning of the Texts Attributed to Al Ghazali: A “Twitter Look” at the Problem. Mathematics, 8(11), 1937. https://doi.org/10.3390/math8111937