An Integrated Decision Approach with Probabilistic Linguistic Information for Test Case Prioritization


 , ,
, ,
Abstract
1. Introduction
1.1. Literature Review on TCP
1.2. Research Challenges in TCP
- Uncertainty in preference elicitation is not properly handled in TCP.
- Preference information from different software personnel is not presented holistically for better TCP. A flexible structure to depict the views holistically is lacking in the state-of-the-art models.
- Weights of criteria that are conflicting and competing with each other are not calculated systematically by capturing DMs’ hesitation. Besides, the attitude of DMs is also not taken into consideration during weight calculation.
- The nature of criteria is not considered during the prioritization of test cases, affecting the decision process. Besides, broad rank values are missing in the state-of-the-art models that could promote proper backup management.
1.3. Contributions of the Integrated Approach
- PLI [8] is adopted as the preference structure that handles uncertainty better and provides a holistic view of the data from different software personnel. This concept resolves the first and second challenges.
- An attitude-based entropy measure is proposed with PLI for criteria weight calculation that would capture DMs’ hesitation and consider the attitude of DMs during preference elicitation. This resolves the third challenge.
- Further, an evaluation based on distance from an average solution (EDAS) approach is extended to PLI for rational prioritization of test cases. The approach considers the nature of criteria during the ranking of test cases and produces broad rank values that promote effective backup management. This resolves the fourth challenge.
- Finally, the integrated approach is exemplified with a real case study of test case prioritization in a software project. The advantages and weaknesses of the introduced method are discussed by comparing it with diverse TCP models.
1.4. Outline of This Paper
2. Preliminaries
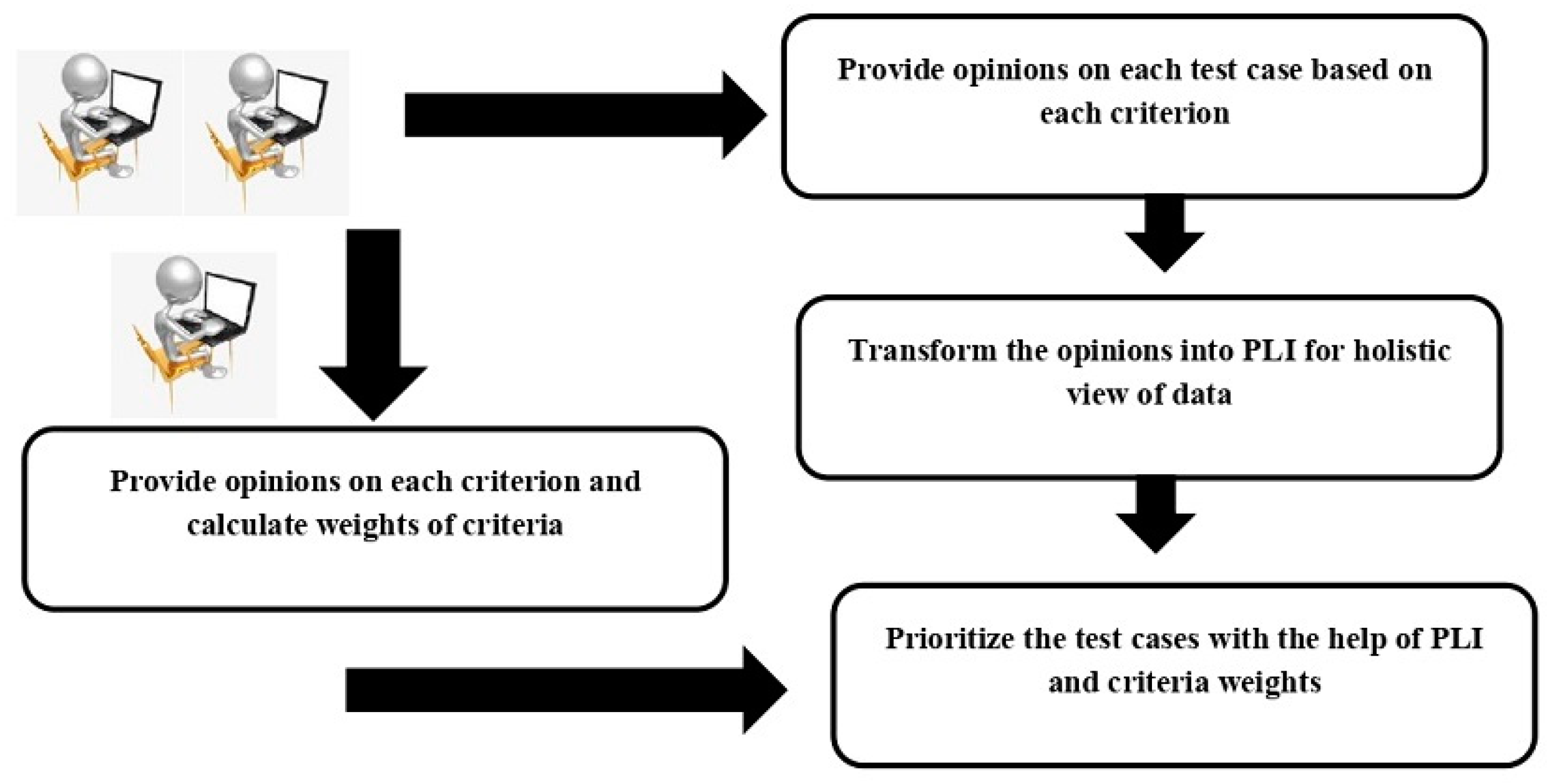
3. Proposed Integrated Model for TCP
3.1. Data Transformation to PLI
3.2. Attitude-Based Entropy Measure
3.3. PLI-Based EDAS Method
4. Numerical Example—TCP in an SME
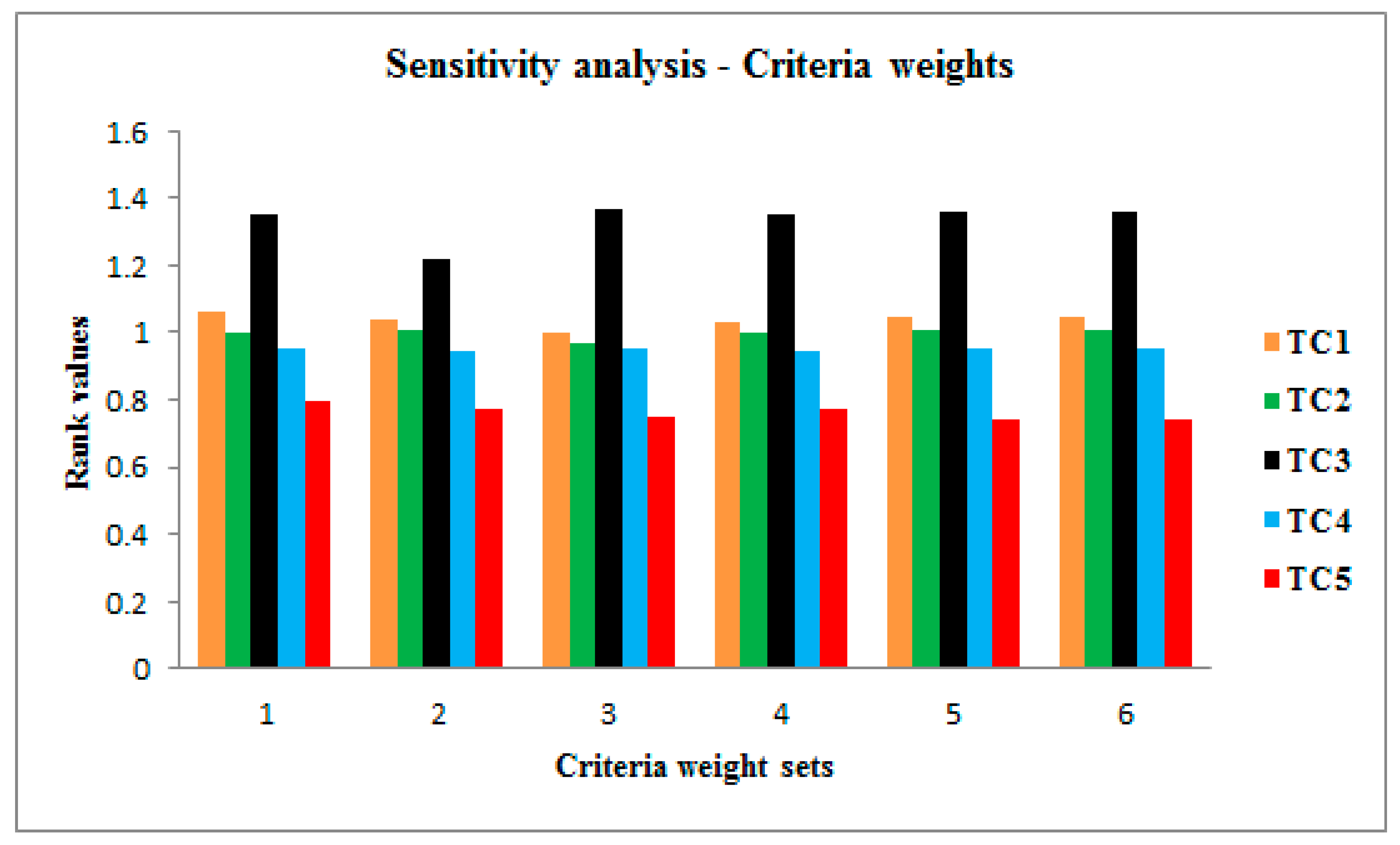
5. Comparative Investigation with Existing Models
- The preference structure used in the paper for TCP is an innovative and flexible structure that only allows experts to share complex linguistic expressions and associate occurrence probability to each term. This enhances uncertainty handling and rational MCDM by providing a holistic view of the data from different experts.
- Criteria considered for evaluating TCP are competing and conflicting with each other, hence, weights are systematically calculated to mitigate bias and capture hesitation better.
- Moreover, test cases are prioritized systematically with broad rank values to make backup plans easily.
- Information loss is mitigated by avoiding the transformation of data that promotes rational prioritization of test cases.
- The proposed model also reduces the computational overhead by not acquiring additional data from experts in the form of constraints.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviations | Expansions |
|---|---|
| MCDM | Multi-criteria decision-making |
| DM | Decision-makers |
| LTS | Linguistic term set |
| HFLTS | Hesitant fuzzy linguistic term set |
| PLTS | Probabilistic linguistic term set |
| PLI | Probabilistic linguistic information |
| RT | Regression testing |
| TCM | Test case minimization |
| TCP | Test case prioritization |
| TCS | Test case selection |
| RTCP | Regression test case prioritization |
| AGCS | Additional greedy method call sequence |
| TCPCI | Test case prioritization in continuous integration |
| SLR | Systematic literature review |
| EDAS | Evaluation based on distance from the average solution |
- (P1).
- if and only if ;
- (P2).
- when and ;
- (P3).
- if and satisfy or ;
- (P4).
- if and only if ).
- Given that and based on Equation (5), normalizing the values gives 0 and 1. In addition, . Thus, .
- Given that and based on the binary entropic measure, .
- If , . From the formulation, it is evident that , hence, . The second part may also be proved in a similar fashion.
- By binary entropic measure, it is clear that . By taking complement, we get . Thus, . All four properties are proved. (P2) and (P4) adopt a binary entropic measure formulation for deriving efficient proofs. □
References
- Triantaphyllou, E.; Shu, B. Multi-criteria decision making: An operations research approach. Encycl. Electr. Electron. Eng. 1998, 15, 175–186. [Google Scholar]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning-I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E. Linguistic decision analysis: Steps for solving decision problems under linguistic information. Fuzzy Sets Syst. 2000, 115, 67–82. [Google Scholar] [CrossRef]
- Rodriguez, R.M.; Martinez, L.; Herrera, F. Hesitant fuzzy linguistic term sets for decision making. IEEE Trans. Fuzzy Syst. 2012, 20, 109–119. [Google Scholar] [CrossRef]
- Torra, V. Hesitant Fuzzy Sets. Int. J. Intell. Syst. 2010, 25, 529–539. [Google Scholar] [CrossRef]
- Alcantud, J.C.R.; Santos-García, G.; Peng, X.; Zhan, J. Dual extended hesitant fuzzy sets. Symmetry 2019, 11, 714. [Google Scholar] [CrossRef]
- Liao, H.; Xu, Z.; Herrera-Viedma, E.; Herrera, F. Hesitant Fuzzy Linguistic Term Set and Its Application in Decision Making: A State-of-the-Art Survey. Int. J. Fuzzy Syst. 2018, 20, 2084–2110. [Google Scholar] [CrossRef]
- Pang, Q.; Wang, H.; Xu, Z. Probabilistic linguistic term sets in multi-attribute group decision making. Inf. Sci. 2016, 369, 128–143. [Google Scholar] [CrossRef]
- Liu, P.; Li, Y. Multi-attribute decision making method based on generalized maclaurin symmetric mean aggregation operators for probabilistic linguistic information. Comput. Ind. Eng. 2019, 131, 282–294. [Google Scholar] [CrossRef]
- Liu, P.; Teng, F. Some Muirhead mean operators for probabilistic linguistic term sets and their applications to multiple attribute decision-making. Appl. Soft Comput. J. 2018, 68, 396–431. [Google Scholar] [CrossRef]
- Lin, M.; Xu, Z. Probabilistic linguistic distance measure and their applications in multi-critieria group decision-making. In Soft Computing Applications for Group Decision-Making and Consensus Modeling; Springer: Berlin, Germany, 2017; pp. 411–440. [Google Scholar]
- Krishankumar, R.; Ravichandran, K.; Ahmed, M.; Kar, S.; Tyagi, S. Probabilistic Linguistic Preference Relation-Based Decision Framework for Multi-Attribute Group Decision Making. Symmetry 2018, 11, 2. [Google Scholar] [CrossRef]
- Sivagami, R.; Ravichandran, K.S.; Krishankumar, R.; Sangeetha, V.; Kar, S.; Gao, X.Z.; Pamucar, D. A scientific decision framework for cloud vendor prioritization under probabilistic linguistic term set context with unknown/partialweight information. Symmetry 2019, 11, 682. [Google Scholar] [CrossRef]
- Zhang, X.; Xing, X. Probabilistic Linguistic VIKOR Method to Evaluate Green Supply Chain Initiatives. Sustainability 2017, 9, 1231. [Google Scholar] [CrossRef]
- Gou, X.; Xu, Z. Novel basic operational laws for linguistic terms, hesitant fuzzy linguistic term sets and probabilistic linguistic term sets. Inf. Sci. 2016, 372, 407–427. [Google Scholar] [CrossRef]
- Liao, H.; Mi, X.; Xu, Z. A survey of decision-making methods with probabilistic linguistic information: Bibliometrics, preliminaries, methodologies, applications and future directions. Fuzzy Optim. Decis. Mak. 2020, 19, 81–134. [Google Scholar] [CrossRef]
- Zhao, Y.; Serebrenik, A.; Zhou, Y.; Filkov, V.; Vasilescu, B. The impact of continuous integration on other software development practices: A large-scale empirical study. In Proceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering, Urbana, IL, USA, 30 October–3 November 2017; pp. 60–71. [Google Scholar] [CrossRef]
- Jiang, B.; Chan, W.K. Testing and debugging in continuous integration with bud- get quotas on test executions. In Proceedings of the IEEE International Conference on Software Quality, Reliability and Security, Vienna, Austria, 1–3 August 2016; pp. 439–447. [Google Scholar] [CrossRef]
- Haghighatkhah, A.; Mäntylä, M.; Oivo, M.; Kuvaja, P. Test prioritization in continuous integration environments. J. Syst. Softw. 2018, 146, 80–98. [Google Scholar] [CrossRef]
- Yoo, S.; Harman, M. Regression testing minimization, selection and prioritization: A Survey. Softw. Test. Verif. Reliab. 2012, 22, 67–120. [Google Scholar] [CrossRef]
- Rothermel, G.; Untch, R.H.; Harrold, M.J. Test case prioritization: An empirical study. In Proceedings of the 15th IEEE International Conference on Software Maintenance (ICSM’99), Oxford, UK, 30 August–3 September 1999; pp. 179–188. [Google Scholar]
- Li, Z.; Harman, M.; Hierons, R.M. Search algorithms for regression test case prioritization. IEEE Trans. Softw. Eng. 2007, 33, 225–237. [Google Scholar] [CrossRef]
- Jiang, B.; Zhang, Z.; Chan, W.K.; Tse, T. Adaptive random test case prioritization. In Proceedings of the 24th IEEE/ACM International Conference on Automated Software Engineering (ASE’09), Auckland, New Zealand, 6–20 November 2009; pp. 233–244. [Google Scholar]
- Mei, H.; Hao, D.; Zhang, L.; Zhang, L.; Zhou, J.; Rothermel, G. A static approach to prioritizing junit test Cases. IEEE Trans. Softw. Eng. 2012, 38, 1258–1275. [Google Scholar] [CrossRef]
- Saha, R.K.; Zhang, L.; Khurshid, S.; Perry, D.E. An information retrieval approach for regression test prioritization based on program changes. In Proceedings of the 37th IEEE/ACM IEEE International Conference on Software Engineering (ICSE’15), Florence, Italy, 16–24 May 2015; pp. 268–279. [Google Scholar]
- Hao, D.; Zhang, L.; Zhang, L.; Rothermel, G.; Mei, H. A unified test case prioritization approach. ACM Trans. Softw. Eng. Methodol. 2014, 24, 10:1–10:31. [Google Scholar] [CrossRef]
- Hao, D.; Zhang, L.; Zang, L.; Wang, Y.; Wu, X.; Xie, T. To be optimal or not in test-case prioritization. IEEE Trans. Softw. Eng. 2016, 42, 490–505. [Google Scholar] [CrossRef]
- Tahvili, B.S.; Bohlin, M. Test Case Prioritization Using Multi Criteria Decision Making Methods. Dan. Soc. Oper. Res. 2016, 26, 9–11. [Google Scholar]
- Zhang, L.; Hao, D.; Zhang, L.; Rothermel, G.; Mei, H. Bridging the gap between the total and additional test-case prioritization strategies. In Proceedings of the 2013 International Conference on Software Engineering (ICSE’13), San Francisco, CA, USA, 18–26 May 2013; pp. 192–201. [Google Scholar]
- Wang, S.; Nam, J.; Tan, L. QTEP: Quality-aware test case prioritization. In Proceedings of the 11th Joint Meeting on Foundations of Software Engineering (ESEC/FSE’17), Paderborn, Germany, 4–8 September 2017; pp. 523–534. [Google Scholar]
- Zhu, H.; Hall, P.A.V.; May, J.H.R. Software unit test coverage and adequacy. ACM Comput. Surv. 1997, 29, 366–427. [Google Scholar] [CrossRef]
- Huang, R.; Sun, W.; Xu, Y.; Chen, H.; Towey, D.; Xia, X. A survey on adaptive random testing. IEEE Trans. Softw. Eng. 2019. [Google Scholar] [CrossRef]
- Pradhan, D.; Wang, S.; Ali, S.; Yue, T.; Liaaen, M. Employing Rule Mining and Multi-Objective Search for Dynamic Test Case Prioritization. J. Syst. Softw. 2019, 153, 86–104. [Google Scholar] [CrossRef]
- Shrivathsan, A.D.; Ravichandran, K.S.; Krishankumar, R.; Sangeetha, V.; Kar, S.; Ziemba, P.; Jankowski, J. Novel Fuzzy Clustering Methods for Test Case Prioritization in Software Projects. Symmetry 2019, 11, 1400. [Google Scholar] [CrossRef]
- Khatibsyarbini, M.; Isa, M.A.; Jawawi, D.N.A.; Tumeng, R. Test case prioritization approaches in regression testing: A systematic literature review. Inf. Softw. Technol. 2018, 93, 74–93. [Google Scholar] [CrossRef]
- Banias, O. Test case selection-prioritization approach based on memoization dynamic programming algorithm. Inf. Softw. Technol. 2019, 115, 119–130. [Google Scholar] [CrossRef]
- Chi, J.; Yu, Q.; Zheng, Q.; Yang, Z.; Jin, W.; Cui, D.; Liu, T. Relation-based test case prioritization for regression testing. J. Syst. Softw. 2020, 163, 110539. [Google Scholar] [CrossRef]
- Lima, J.A.P.; Vergilio, S.R. Test Case Prioritization in Continuous Integration Environments: A Systematic Mapping Study. Inf. Softw. Technol. 2020, 106268. [Google Scholar] [CrossRef]
- Huang, R.; Zhang, Q.; Towey, D.; Sun, W.; Chen, J. Regression test case prioritization by code combinations coverage. J. Syst. Softw. 2020, 169, 110712. [Google Scholar] [CrossRef]
- Mahdieh, M.; Mirian-Hosseinabadi, S.H.; Etemadi, K.; Nosrati, A.; Jalali, S. Incorporating fault-proneness estimations into coverage-based test case prioritization methods. Inf. Softw. Technol. 2020, 121, 106269. [Google Scholar] [CrossRef]
- Xie, W.; Xu, Z.; Ren, Z.; Wang, H. Probabilistic Linguistic Analytic Hierarchy Process and Its Application on the Performance Assessment of Xiongan New Area. Int. J. Inf. Technol. Decis. Mak. 2018, 16, 1–32. [Google Scholar] [CrossRef]
- Yuan, J.; Luo, X. Approach for multi-attribute decision making based on novel intuitionistic fuzzy entropy and evidential reasoning. Comput. Ind. Eng. 2019, 135, 643–654. [Google Scholar] [CrossRef]
- Verma, R. Multiple attribute group decision-making based on order-α divergence and entropy measures under q-rung orthopair fuzzy environment. Int. J. Intell. Syst. 2020, 35, 718–750. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Z.; Liao, H.; Xu, Z.S. ELECTRE II method to deal with probabilistic linguistic term sets and its application to edge computing. Nonlinear Dyn. 2019, 96, 2125–2143. [Google Scholar] [CrossRef]
- Xu, G.L.; Wan, S.P.; Dong, J.Y. An Entropy-Based Method for Probabilistic Linguistic Group Decision Making and its Application of Selecting Car Sharing Platforms. Informatica 2020, 31, 621–658. [Google Scholar] [CrossRef]
- Ghorabaee, M.K.; Zavadskas, E.K.; Olfat, L.; Turskis, Z. Multi-Criteria Inventory Classification Using a New Method of Evaluation Based on Distance from Average Solution (EDAS). Informatica 2015, 26, 435–451. [Google Scholar] [CrossRef]
- Karaşan, A.; Kahraman, C. A novel interval-valued neutrosophic EDAS method: Prioritization of the United Nations national sustainable development goals. Soft Comput. 2018, 22, 4891–4906. [Google Scholar] [CrossRef]
- Peng, X.; Liu, C. Algorithms for neutrosophic soft decision making based on EDAS, new similarity measure and level soft set. J. Intell. Fuzzy Syst. 2017, 32, 955–968. [Google Scholar] [CrossRef]
- Mishra, A.R.; Mardani, A.; Rani, P.; Zavadskas, E.K. A novel EDAS approach on intuitionistic fuzzy set for assessment of health-care waste disposal technology using new parametric divergence measures. J. Clean. Prod. 2020, 122807. [Google Scholar] [CrossRef]
- Liang, Y. An EDAS method for multiple attribute group decision-making under intuitionistic fuzzy environment and its application for evaluating green building energy-saving design projects. Symmetry 2020, 12, 484. [Google Scholar] [CrossRef]
- Feng, X.; Wei, C.; Liu, Q. EDAS Method for Extended Hesitant Fuzzy Linguistic Multi-criteria Decision Making. Int. J. Fuzzy Syst. 2018, 20, 2470–2483. [Google Scholar] [CrossRef]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. A group decision making model dealing with comparative linguistic expressions based on hesitant fuzzy linguistic term sets. Inf. Sci. 2013, 241, 28–42. [Google Scholar] [CrossRef]
- Liu, Y.; Rodríguez, R.M.; Alcantud, J.C.R.; Qin, K.; Martínez, L. Hesitant linguistic expression soft sets: Application to group decision making. Comput. Ind. Eng. 2019, 136, 575–590. [Google Scholar] [CrossRef]




| Test Cases | Criteria for Evaluation | |||||
|---|---|---|---|---|---|---|
| Experts | Criteria | |||||
|---|---|---|---|---|---|---|
| Test Cases | PDA | NDA | Rank Values |
|---|---|---|---|
| 1 | 0.05515 | 1.0552 | |
| 0 | 1 | 1 | |
| 0.9204 | 0.4290 | 1.3494 | |
| 0.7415 | 0.2089 | 0.9504 | |
| 0.7973 | 0 | 0.7973 |
| Factors | TCP Models | |||
|---|---|---|---|---|
| Proposed | Pradhan et al. [33] | Shrivatsan et al. [34] | Banias [36] | |
| Data | PLI | Crisp data | Fuzzy data | Objective and subjective data |
| Weight calculation | Entropy measure | n/a | Not calculated; directly obtained | n/a |
| Prioritization method | EDAS approach | Rule mining and MO search | WASPAS method | Dynamic programming |
| Uncertainty | Handled effectively | Not captured | Slightly handled | Slightly handled |
| Data view | A holistic view of data from different experts | n/a | Fuzzified view of data | Human decisions are considered with objective values |
| Information overhead | No extra information is required | Partial information is needed—constrained | No extra information is required | Partial information is needed—constrained |
| Experts’ hesitation | Captured effectively by using deviation measure | n/a | Not captured | Not captured |
| Information loss | Handled effectively | n/a | Not properly handled as linguistic data is transformed | n/a |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shrivathsan, A.D.; Krishankumar, R.; Mishra, A.R.; S. Ravichandran, K.; Kar, S.; Badrinath, V. An Integrated Decision Approach with Probabilistic Linguistic Information for Test Case Prioritization. Mathematics 2020, 8, 1857. https://doi.org/10.3390/math8111857
Shrivathsan AD, Krishankumar R, Mishra AR, S. Ravichandran K, Kar S, Badrinath V. An Integrated Decision Approach with Probabilistic Linguistic Information for Test Case Prioritization. Mathematics. 2020; 8(11):1857. https://doi.org/10.3390/math8111857
Chicago/Turabian StyleShrivathsan, A. D., R. Krishankumar, Arunodaya Raj Mishra, K. S. Ravichandran, Samarjit Kar, and V. Badrinath. 2020. "An Integrated Decision Approach with Probabilistic Linguistic Information for Test Case Prioritization" Mathematics 8, no. 11: 1857. https://doi.org/10.3390/math8111857
APA StyleShrivathsan, A. D., Krishankumar, R., Mishra, A. R., S. Ravichandran, K., Kar, S., & Badrinath, V. (2020). An Integrated Decision Approach with Probabilistic Linguistic Information for Test Case Prioritization. Mathematics, 8(11), 1857. https://doi.org/10.3390/math8111857