1. Introduction
In most networks, some vertices are more central than the others. To model this intuitive feeling, centrality indices were introduced. The first mathematical concept of centrality of graphs was introduced almost 150 years ago by Jordan [
1]. There are many ways to provide a measure of the relative “importance” of a node in a network, where the different motivations lead to different centrality measures that were developed in several areas of science.
Node centrality. A social network is typically represented as a graph, where individuals are represented as vertices, and the relationships between pairs of individuals as edges. In the paper, we will freely interchange the terms vertex/node and graph/network, without any meaningful difference.
Various vertex-based measures of centrality have been proposed to determine the relative importance of a vertex within a graph. Arguably, the most common branch of centrality indices is based on the distance between the nodes of the network. Some of the standard centrality indices from this branch are degree, betweenness, closeness, and eccentricity. Among other measures of node centrality, a few of the better known in network analysis are: eigenvector centrality, Google PageRank, Katz centrality, Alpha centrality, and others. For detailed definitions and discussions on various centrality indices, we refer the reader to [
2,
3,
4].
Another concept of vertex centrality, the
personalization, was introduced in 2003 (see [
5]), and is a measure that shows how central an individual is according to a given subset
R (group of important people) in a given social network. In 2005, the
subgraph centrality [
6] was introduced, which characterizes the participation of each node in all subgraphs in a network and is calculated from the spectra of the adjacency matrix of the network. Recently, Bell [
7] introduced the concept called the
subgroup centrality, where centrality (of one vertex) is calculated only on a restricted set of vertices. The most basic centrality measure is the degree of a vertex, which we study in this paper.
In 1999, Everett and Borgatti [
8] introduced the concept of
group centrality which enables researchers to answer questions such as, “How central is the engineering department in the informal influence network of this company?” or, “Among middle managers in a given organization, which are more central, men or women?” With these measures, we can also solve the inverse problem: given a network of ties among organization members, how can we form a team that is maximally central? In [
8], the authors introduced group centrality for measures of degree, closeness, and betweenness centrality, which we use in this paper. In 2006, another important group centrality measure motivated by the
key players problem was introduced (see [
9]). In 2011, Miyano et al. [
10] discussed the problem of finding the best group for the so-called
k-vertex maximum domination problem (or
, in short), which in fact corresponds to maximizing the group degree centrality (introduced in 1999 [
8]), where the score is further increased by a constant
k.
Freeman’s centralization. In his study, Freeman [
11] realized that despite all of the vertex-centrality indices defined up to that point, there was a need for a normalization which could measure the
relative importance of a given vertex in a network and would be based on any chosen centrality index. Hence, he defined a
centralization measure based on normalized variance in vertex centrality of any chosen centrality measure, with an aim to allow a comparison of distinct networks on the basis of their highest vertex-centralization scores. One may also consider his approach as another type of vertex-centrality, which measures the extent to how some vertex in a network stands out from others in terms of a given centrality index. Every centrality measure can have its own centralization measure. In order to calculate centralization for some vertex measure
in a given graph
G, we first define
When there is no risk of confusion regarding the network G, we write instead of .
In the same paper, Freeman remarked that the centralizations of degree centrality, betweenness centrality, and closeness centrality achieve their maximum if, and only if
G is a star. The statement was later proved in detail by Everett, Sinclair, and Dankelmann [
12]. In order to compare centralization values of different graphs with possibly different sizes, in the definition of centralization, Freeman used a normalized formula, where the normalizing divisor is based on the theoretically largest centrality variance in any graph from a given class
of graphs [
11]:
Following Freeman’s approach, the group centralization notion was introduced in [
13], which brings us to the focus of this paper.
2. Group Degee Centrality and Centralization
Let
be the family of all graphs on
n vertices, let
, and let
. According to [
8], the group degree centrality is defined as
where
stands for the set of vertices adjacent to
v in
G. Also observe that introducing an isolated vertex to a group has zero contribution towards its group degree centrality. Such a vertex will never be considered in the optimal group
S, unless
S already dominates the non-isolated vertices of
G. For easier notation, we will thus only consider graphs without isolated vertices. Given a graph
G and integer
k, let
be one of the sets from
that achieves the maximum value of group degree centrality, that is,
. Observe that
also takes the maximum value for group degree centralization. Whenever the graph
G or the value
k are known from the context, we omit the subscript from the notations of centrality, centralization, and similarly simplify the optimal group label to
.
As defined in [
11,
13],
stands for the group degree centralization. Define
, and observe
According to Freeman [
11], the denominator is needed to normalize centralization, and in turn achieve better relative comparison. Indeed, notice that such normalized values will never exceed value 1. Clearly, as we already mentioned,
is maximized whenever
is maximized, and by Krnc et al. [
13] we have that the maximum value of the denominator corresponds to the star graph
and a maximizing set
corresponds to any
k-set containing the center of the star. In
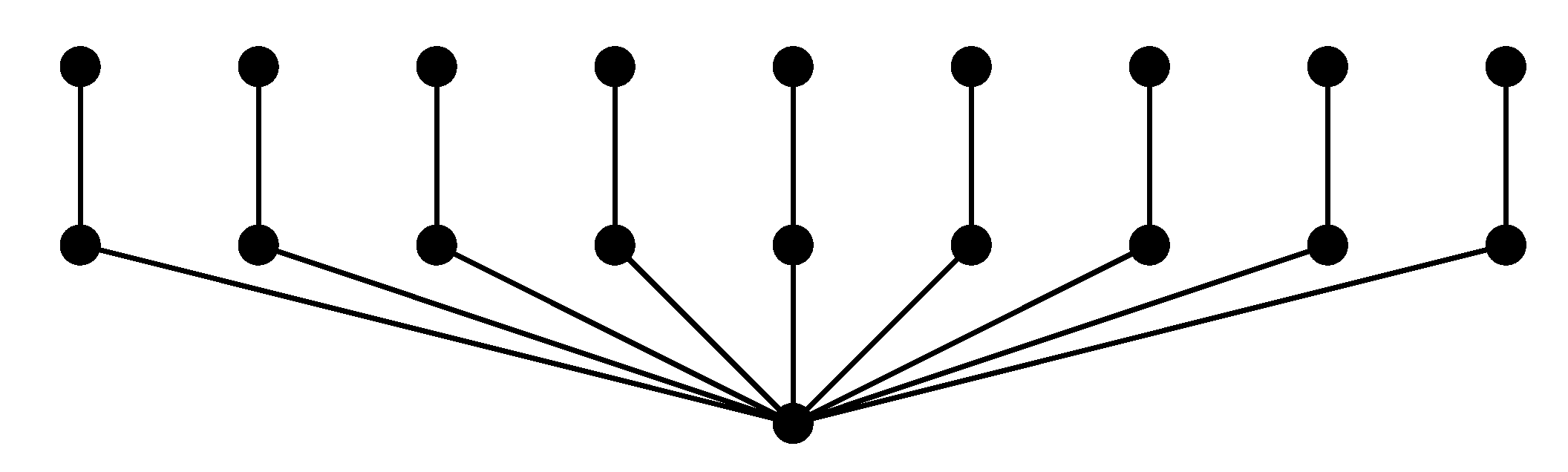
Figure 1 the group degree centralization is presented of a particular graph.
Given a graph
G, define the
maximizing group size to be the positive integer, such that
where
G is known from the context, and we also write
. Notice that
achieves the maximum value for group degree centralization as well.
In what follows, we optimize the procedure of calculating the group degree centrality for a given graph and an input integer k. We start by calculating the denominator of the group degree centralization.
Lemma 1. Let G be a star on n vertices. Then, Proof. Denote the center of the star by
c, partition the sets of
into parts
and
depending on whether or not they contain the vertex
c as a member, and observe that the group degree centrality of members of these parts equals to
and 1, respectively. As
, the claim follows by:
□
In the following proposition, we use a classical graph theoretical approach of double counting to show that the sum
from (
1) can be computed efficiently.
Proposition 1. Let G be a graph on n vertices, and let be a positive integer. It holds that In particular, can be computed in time.
Proof. For each vertex
, define its contribution
to be the number of
k-sets that dominate
v, that is,
By the double counting argument, it follows that
Thus, we conclude
which can be computed in
time, traversing all vertices once. □
We join the results from Lemma 1 and Proposition 1 to further develop (
1), and claim the following.
Theorem 1. For a given graph G on n vertices and a group of its vertices S of size k, the group degree centralization can be evaluated as which can be computed in time.
It is easy to see that finding
can hence be computed in
, by traversing over all
k-tuples and computing group degree centrality at each iteration. However, as
k grows, this may not be a feasible approach. As shown below, for an input value of
k, determining
is
-hard. First, recall how the set
S of cardinality
k is said to be
k-
dominating whenever
Proposition 2. The problem that determines a set for a given input graph G and an integer k is -hard.
Proof. We prove the claim by reducing a well-known
-problem of determining the existence of a
k-dominating set to our problem of finding
. Let us assume that there exists a polynomial algorithm for finding a
k-set
, such that
Now, observe that the existence of a
k-dominating set is equivalent to the property
As group degree centrality of a given fixed set can be computed in polynomial time , it is clear that the set provides an answer regarding the existence of a k-dominating set. □
In the last section, we present an efficient algorithm for calculating group degree centrality scores for all group sizes.
3. Greedy Computation of Degree Centrality
By Proposition 2, it is NP-hard to determine the group with the biggest degree centrality. In this section, we present a greedy approach (Algorithm 1) to identify k-sets which are close to achieving the biggest group degree centrality for a given network, for , and describe how one can obtain the corresponding group degree centralization values. Both procedures are described in Algorithms 2 and 3, respectively. We also discuss the corresponding approximability and time complexity.
The greedy algorithm presented here behaves in a natural way:
| Algorithm 1 An outline of the greedy algorithm for group degree centrality. |
Input: Graph G
Output: An ordering S of whose prefixes correspond to approximations of sets maximizing group degree centrality. A list L of corresponding group degree centrality values.
1: Let .
2: Maintain all vertices from in ordered buckets, labeled by their contribution towards the group degree centrality to set S.
3: Among , append a vertex from a bucket with the biggest label to S.
4: Go to Line 2, unless .
5: Return S. |
In what follows, we describe the important elements of the algorithm. In the next subsection, we present Algorithm 1 in more detail, such as Algorithm 2. The majority of Algorithm 2 deals with step two of the above pseudocode—maintaining all vertices from
in ordered buckets, labeled by their contribution towards the group degree centrality to set
S. For efficient implementation of those transitions, we utilised a particular directed graph as a dynamically changing data structure, which enabled us to achieve a linear running time. In the following two subsections, we consider the centralization and complexity, and the approximability analysis as well.
| Algorithm 2 Greedy approach to finding a group with the maximum degree centralization. |
Input: Graph G.
Output: An ordering S of whose prefixes correspond to approximations of sets maximizing group degree centrality. A list L of corresponding group degree centrality values.
1: Initialize lists and .
2: Initialize as the directed instance of graph G.
3: Partition to buckets according to value .
4: for all do ▹ Main loop
5: Append a vertex v from maximal bucket to S.
6: Append to L.
7: for all do
8: for all do
9: Remove from . ▹ update buckets
10: end for
11: end for
12: Remove v from . ▹ update buckets
13: end for
14: ReturnS and L. |
| Algorithm 3 Computing Freeman group degree centralization values. |
Input: Graph G.
Output: An ordering S of whose prefixes correspond to approximations of sets maximizing group degree centrality. A list of corresponding group degree centralization values.
1: Let S and L the lists obtained by Algorithm 2 on input G.
2: Initialize an empty list .
3: for all do
4: Compute . ▹ see Proposition 1
5: Append 2.3 to . ▹ see Theorem 1
6: end for
7: Return S and . |
3.1. The Directed Graph Structure for Implementation
In this subsection, we consider Algorithm 1, which we implement by using a directed graph as a data structure. The corresponding implementation is described as Algorithm 2. The algorithm returns an ordering of , whose prefixes correspond to approximations of sets maximizing group degree centrality, together with a list L of corresponding group degree centrality values. Define . We start with an empty list S, and in each iteration, we append a vertex to S which maximizes the contribution towards the current group degree value. The added group degree contributions are then accordingly appended to the list L, and this process is repeated as k increases towards the graph order n.
We describe the state after each iteration k by maintaining a directed graph on the vertex-set , where whenever
At the initialization (i.e., when S is empty), the initial graph contains all of the edges of G in both directions (line 2). Denote by our digraph in all iterations of the main loop. For a given vertex , let its contribution towards the group degree centrality be defined as . Then, the following holds:
Proposition 3. Let , at the beginning of -th iteration. Then, its contribution equals Proof. First, note that each out-neighbour of v clearly increments the degree-centrality score by one. Since we assume v was initially not an isolated vertex, it is dominated by whenever . In the case when , that is, when vertex v is not dominated by any other vertex from , it is clear that vertex v did not contribute towards the value of , so we conclude that the contribution simply equals to .
To conclude the proof, it remains to consider the case when . Note that in this case vertex, v was already contributing towards . Since this is not the case after adding v to , we have to subtract one from the overall total group degree score. □
It is important to point out that we keep the vertices with the same contribution within the same bucket, and maintain this bucket-structure across all iterations, so it is easy to identify the vertex v, maximizing its contribution. The main loop hence consists of greedily selecting a vertex v which maximizes the group degree centrality contribution, appending it to S (line 5), then appending the corresponding group degree centrality value to L (line 6), and finally updating the directed graph (lines 7–10). This maintenance of is done by removing v from , and by removing edges towards all the newly dominated vertices, that is, towards vertices in .
3.2. Obtaining Freeman Group Degree Centralization
In order to obtain corresponding values of Freeman’s group degree centralization, we need to normalize group degree centrality scores from Algorithm 2, which is described in Algorithm 3. To determine the sum of all group degree centralities over all
k-sets, we apply Proposition 1, for arbitrary value of
k. Together with Lemma 1, this suffices to finalize (
2) from Theorem 1.
3.3. Complexity and Approximability Analysis
A careful reader may notice a similarity between our greedy approach with the classical greedy appriximation algorithm for MAX COVERAGE or MAX
k-VERTEX DOMINATION problems (see [
10,
14]). While this greedy approach gives an approximation ratio of
for both mentioned algorithms, any such constant is not attainable for the
k-group degree centrality. We now describe the approximability and time complexity of Algorithms 2 and 3, summarised in Theorem 2.
Theorem 2. Given a graph G on n vertices and m edges, the greedy algorithm for k-group degree centrality over all set sizes altogether runs in linear time and achieves the k-group degree centrality value of at least , where is the maximizing k-group degree centrality of G.
Proof. We first deal with the time complexity for Algorithm 2. It is easy to see that the execution of lines outside of the main for-loop takes time. For the main for-loop, first note that performing decrementation of a bucket for any vertex takes a constant time. It is also important to observe that any (directed) edge may be identified in a constant time (i.e., lies at up to second neighbourhood of v), and is removed once only. The removal of arbitrary edge causes the decrementation of buckets at u, and sometimes also at w. The total number of steps performed by both for-loops in lines 7 and 8 is hence within , and so the overall time complexity of Algorithm 2 is .
Regarding Algorithm 3, we focus on the complexity of the main for-loop. In particular, line 4 can be computed in
time, by traversing all vertices and looking at their degrees (see Proposition 1). After this, line 5 is simply a calculation of (
2) from Theorem 1, which is performed in
. Thus, the overall time complexity of computing the group degree centralization for all values of
k is
. Note however that if one is interested in an approximation for a single set-size
k, this can be done in
by executing Algorithm 3 for the specified value of
k only.
Let
be the set maximizing
k-group degree centrality, let
, and let
be the corresponding value of
. For
, assume that Algorithm 2 selects vertices
in the
i-th step, and define
where additionally, we set
and
. Notice that
denotes the contribution of
, and
tells us how far we are from the optimal value at the
i-th step.
Claim.Let . Then, .
Proof. It is enough to show that there exists a vertex with at least neighbors not in . To this end, observe that at least vertices from are not contained in . Since , there must exist a vertex adjacent to at least of those vertices of .
When our algorithm chooses , the group degree centrality will increase for at least , and may additionally decrease by 1 in case was already dominated before, which concludes the proof of this claim. □
By the above claim, we have
where
. Thus, we get
which together with
and
, gives
□
4. Concluding Remarks and Future Work
With respect to the important branches of the centrality theory, we seek to identify the most central group of nodes in a network, (without fixing the group size in advance). Despite numerous centrality measures, only few are designed to reflect this issue, among them being group
centralization measures (see Krnc et al. [
13]). We focused on a particular type of group centralization, namely group degree centralization, as it is the simplest one to deal with. The precise calculation of the problem was shown to be infeasible for large networks, and a sub-quadratic approximation algorithm which computes centralization scores over all group sizes was described and analyzed.
To further justify group degree centralization, it would be most interesting to test the performance of this algorithm on some real-world networks. It is worth noting that Algorithm 2 is not deterministic—indeed, there can be several possibilities in choosing a vertex with the largest contribution. Nevertheless, there exist networks where neither of the possible executions of Algorithm 2 will result in a set which maximizes group degree centrality (for example, see
Figure 2).
Additionally, while in this paper we only study the group degree centralization, one should ask similar algorithmic questions for the group centralization of some other centrality indices. One could also consider modifying Freeman’s centralization and consider a different type of normalization for group centrality measures which could preferably be more efficient to calculate.


{kind=link}
{kind=link}

