1. Introduction
In this paper, we shall be concerned with time-homogeneous continuous-time Markov chains
that take values in a bivariate state space
, for integers
with
and
, and have an irreducible infinitesimal generator
with block-tridiagonal representation
where the sub-matrices
are of dimension
, for
, i.e., from any state
, process
can access only states
with
and
, whence
can change its value by
only. These Markov chains are referred to as finite quasi-birth-death (QBD) processes, being its first variable
called the level, and the second one
the phase; see e.g. Gaver et al. [
1]. They are capable of modeling, in a unified and algorithmically tractable manner, relevant systems, such as queueing models (Baumann and Sandmann [
2]; Gun and Makowski [
3]; Perel and Yechiali [
4]; Ye and Li [
5]), communication networks (Artalejo and Gómez-Corral [
6]; Artalejo and Lopez-Herrero [
7]), reliability and manufacturing systems (Chakravarthy and Gómez-Corral [
8]; Moghaddass et al. [
9]), and epidemic models (Amador and Gómez-Corral [
10]; Artalejo et al. [
11]; Economou et al. [
12]; Gamboa and Lopez-Herrero [
13]), among others.
The properties of finite QBD processes have been studied extensively in continuous and discrete time. For a comprehensive discussion, see, e.g., the monograph of Latouche and Ramaswami (Chapter 10 in Reference [
14]) and references therein. Most of the theoretical work so far carried out in this setting is concerned with the stationary probability vector. More concretely, Hajek [
15] observes that, under certain conditions for the underlying transition matrices, the stationary vector of a finite level-independent QBD process has a mixed matrix-geometric form; for a related numerical method that exploits invariant subspace computations, see the paper by Akar et al. [
16]. Gaver et al. (Section 2 in Reference [
1]) use linear level reduction, which is a refined probabilistic justification for block-Gaussian elimination (Latouche and Ramaswami (Remark 10.1.6 in Reference [
14]); Stewart [
17]). Ye and Li [
5] (see also Latouche and Ramaswami (Section 10.2 in Reference [
14])) propose an efficient computational approach, termed folding algorithm, which is seen to be a form of odd-even reduction, and Naoumov [
18] presents an algebraically matrix-multiplicative approach for a finite QBD process.
-type and
-type
-factorizations are used by Li and Cao (Section 3.1 in Reference [
19]) in an attempt to clarify the relations among those results in Gaver et al. [
1], Hajek [
15], and Naoumov [
18]. Elhafsi and Molle [
20] present a matrix-geometric expression for the stationary vector of a finite level-independent QBD process in terms of a set of rate matrices and compare their solution with several existing solution methods, including the approaches of de Nitto Persone and Grassi [
21], Gun and Makowski [
3], and Hajek [
15], and a more general solution of Le Boudec [
22] for upper block Hessenberg matrices. Other approaches are related to the group inverse (da Silva Soares and Latouche [
23]) and the matrix continued fraction algorithm (Baumann and Sandmann [
24]).
Despite their simplicity and their success in stochastic modeling, there have been few contributions dealing with random descriptors different from the stationary probability vector in the theory of finite QBD processes. Gaver et al. (Sections 3–4 in Reference [
1]) use Laplace-Stieltjes transforms of first-passage times from level
to level
, where the
th level is defined as
, to derive a product-form expression for the Laplace-Stieltjes transform of the first-passage time from level
to higher levels
, with
, and similar results for the first-passage times to lower levels. An up-integral functional is defined in the paper by Li and Cao [
19,] (Section 4) and explicit expressions for the Laplace transforms of its conditional distributions and moments are written in terms of the underlying
R- and
G-measures. Li and Sheng [
25] propose and implement a generalized folding algorithm for transient analysis of a finite QBD process, which entails the solution of
, where
is a predetermined boundary condition vector, and present comprehensive numerical examples on transient queueing behavior with correlated arrivals. Based on the
R- and
G-measures, Shin [
26] derives an algorithm for computing the fundamental matrix of a finite QBD process with absorbing states and shows how the resulting algorithm can be applied to absorption probabilities, sojourn time distributions, the busy period and the stationary vector in the multiprogramming model discussed by Neuts [
27] (pp. 245–253) and the
retrial queue with finite orbit capacity (Artalejo and Gómez-Corral (Chapter 4 in Reference [
28])). Recently, Gómez-Corral and López-García [
29] use matrix calculus and exploit the specific structure of the infinitesimal generator
in (1) to provide the sensitivities and the elasticities of finite QBD processes with respect to model parameters, with special emphasis on first-passage times to level
and hitting probabilities, the maximum level visited by the process before reaching states in level
and the stationary vector, and illustrate the approach by means of applying multi-type versions of the susceptible-infective (SI) and susceptible-infective-susceptible (SIS) epidemic models to the spread of antibiotic-sensitive and antibiotic-resistant bacterial strains in a hospital ward.
The objective of this paper was to complement the work of Gaver et al. [
1] by showing here that, in the spirit of algorithmic probability, the fundamental ideas of Gaver et al. [
1] extend beyond the stationary distribution and first-passage times to higher and lower levels, and apply to more complex descriptors arising from epidemic models. The methods we shall follow in this paper are suggested by some related work of Amador et al. [
30], Baumann and Sandmann [
31], Lefèvre and Simon [
32], and Neuts [
33], where, for instance, the random length of an outbreak and the final size of the epidemic in SIR-type and SIS-type epidemic models correspond to the absorption time and the hitting probabilities in a suitably defined absorbing QBD process, and related block-structured Markov processes. In order to simplify the presentation throughout the paper, we shall assume that
is the initial state of process
, for phases
, which is related to an invasion time in the spread of a disease.
The paper is organized as follows. In
Section 2, we derive recursive expressions for the hitting probabilities of restricted versions of process
. In
Section 3, we characterize the probability laws of the number of upcrossings from level
to states in
, for a predetermined threshold
, and the total time spent at states in higher levels before reaching states in level
. In
Section 4, we study the random area under the trajectory of the integer-valued random variable
before process
visits states in
for the first time. Numerical examples are given in
Section 5 in the setting of varicella-zoster virus infections, and concluding remarks follow in
Section 6.
2. First-Passage Times to Higher Levels and Restricted Hitting Probabilities
Let us consider the first-passage time
to level
from state
, for a predetermined integer
, and the first-passage time
to level
from state
, with
. For phases
, we let
denote the
restricted hitting probability
which is related to the dynamics of process
evolving on those sample paths satisfying
.
Remark 1. Note that the probability law of (respectively, ) corresponds to the conditional distribution of the random variable defined in Section 3 of Reference [1] with and (respectively, defined in Section 4 of Reference [1] with ), given that . A product-form expression for the Laplace-Stieltjes transform of and recursive relations for its expectation (respectively, the expectation of ) can be then obtained from Equations (3.9) and (3.12)–(3.14) (respectively, (4.4)–(4.6)) of Reference [1]. In order to derive expressions for the restricted hitting probabilities
, it is useful to consider an auxiliary absorbing process
that takes values in the state space
, where 0 and
K are assumed to be absorbing states and
is a class of transient states. The infinitesimal generator of
has the block-structured form
where the column vector
is the null vector of order
a,
denotes transposition, the sub-matrix
is obtained from
by removing rows and columns associated with states in
and
, the column vectors
and
have the form
and the column vector
is the unit vector of order
a. It is clear that, starting from states in
, the process
defined by (2) is the restriction of process
to the states in
before the first entrance into states in
. In particular, it is found that
where
is a row vector of order
a, in which entries are all equal to 0, except the
bth entry which equals 1. The proof of (3) is based on the fact that the transition function
of process
is given by
which yields
by taking the limit as
, since the sub-matrix
is stable and the real parts of its eigenvalues are all strictly negative.
By appealing to statement (b) of Lemma 1 in the paper by Gaver et al. [
1], it is noted that the matrix
records expected total times that process
spends at states in
before
visits states in either
or
for the first time, provided that
starts from any initial state in
. Furthermore, a slight modification of statement (c) of Lemma 1 in Reference [
1] permits to establish that, by denoting by
the matrix recording infinitesimal rates associated with transitions to states in
from
, the matrix
consists of first passage probabilities to level
, given that
starts from any state in
.
This means that the
th row of
consists of the restricted hitting probabilities
, for phases
, and consequently, recursive relations for these probabilities can be derived from Theorem 4.2.4 of the book by Hunter [
34] by observing that
can be written in terms of the sub-matrix
.
Theorem 1. For a predetermined integer and an initial state with , the restricted hitting probability is specified byfor phases , whereMoreover, the sub-matrices , for integers , are given by , whereand satisfywith and . This has the following immediate consequence.
Corollary 1. For a predetermined integer and an initial state with , .
Theorem 1 and Corollary 1 suggest an algorithmic solution to compute the restricted hitting probabilities
and the probability
by using Equations (4) and (5) recursively; see Algorithm A1 (
Appendix A).
Remark 2. For the sake of completeness, we note that the restricted hitting probability , for any initial state with and , can be similarly derived from the probabilistic interpretation of the matrix , in such a way thatfor phases , where we denote by the -th entry of matrix . Therefore, a general version of Algorithm A1 (Appendix A) can be written by exploiting the block-structured form of in (5), which is left to the interested reader. 3. Number of Upcrossings and Sojourn Times
We shall examine here the number of upcrossings from states in level to level (i.e., the number of times the level variable increases its value from to K) and the total time that process spends at states in before the first entrance of into states in , provided that is the initial state.
We note that these descriptors can have different interpretations depending on the particular QBD process of interest. For example, in an epidemic model (see
Section 5), if the level
consists of states in which exactly
K infected hosts are present in the population, the number
of upcrossings is equivalent to the number of times the threshold number
K of infected hosts is reached during a given outbreak. This can be relevant when, in particular,
K represents a threshold level of infectives at which some mitigation strategies are implemented, or when
K represents a maximum number of infectives for whom there is actual capacity in the healthcare system to deal with. In these scenarios, it is also relevant to quantify the total amount of time
that the epidemic stays at or above level
, which would quantify the time during which the mitigation strategies are in place, as a measure of cost, or the time period during which the healthcare capacity is exceeded.
To begin with, we establish the connection between and the numbers of upcrossings from level to level before a visit to , provided that is the initial state, for phases and integers .
Theorem 2. For a predetermined integer and an initial state with , the mass function of the number of upcrossings is given by the probabilitieswhere the probabilities , for phases , can be expressed asIn these expressions, the probabilities , for phases , satisfywhere if , and if , and is the probability that, starting from state , process visits the state when it enters level for the first time. Proof. Let us consider what must happen in order for the event , for integers , to occur. Conditioning on the first entrance of into before a visit to , the process is forced to return to level , starting from states in , by means of upcrossings from to before a visit to and a number of downcrossings from to , which are not relevant for the event to occur. Then, we may obtain (7) by conditioning on the state visited by in its first entrance into , starting from , avoiding . Note that, in the special case , process must enter level , starting from , before moving up to , which occurs with probability , by Corollary 1.
Equation (8) is similarly obtained by conditioning on the state visited by process in its first entrance into level , starting from state , whereas (9) is derived from the above argument by replacing the initial state by . This completes the proof. □
In evaluating the sequence
of first-passage probabilities, we may observe that they correspond to the absorption probabilities into states in level
in an auxiliary absorbing process
that, starting from
, takes values in the state space
and has the following block-structured infinitesimal generator:
where
and the sub-matrix
is obtained from
by removing rows and columns associated with states in
. Specifically, it is readily seen that the matrix
consists of first-passage probabilities to states in level
, provided that process
starts from states in
. This yields
for phases
and
, where
,
is the Kronecker’s delta, and the matrices
and
are given by
Algorithm A2 (
Appendix B) uses the above recursive relations and iteratively computes probabilities
, for phases
and
, by observing that the matrix
is initially assigned the matrix
.
The probability generating function
of
can be derived from (7)–(9) and is given by
for
, where the generating functions
, for phases
, satisfy
for
, with
for
and phases
. By differentiating these equalities successively with respect to
z and setting
, we may obtain the column vectors
of factorial moments
as follows:
where the
-th entry of matrix
is given by
, for phases
and
, and the column vectors
are obtained iteratively from the equality
with
. In this equality, the
-th entry of
and the
-th entry of
are specified by the probabilities
in (10) and
in (6), respectively, for phases
and
.
Let us now turn to the probability law of the random variable
. The probability law of
has the discrete contribution
since
, and a continuous contribution, which is linked the restricted Laplace-Stieltjes transform
for
.
By conditioning on the first state visited in
before a visit to
, it is seen that
for
, where
is the total time that process
spends at states in
before a visit to
, provided that
is the initial state, and
is the restricted Laplace-Stieltjes transform of the first-passage time
to level
, provided that
is the initial state and the first state visited in level
is
, for phases
and
. Note that
is a defective random variable with
.
Theorem 3 tells us how to compute the column vectors , for , with th entry given by , for , in terms of the Laplace-Stieltjes transforms of the first-passage time to level , provided that is the initial state and the first state visited by process in level is , for phases and , and integers . From now on we denote by the -th entry of the sub-matrix and by the -th entry of sub-matrix , for phases and , and integers .
Theorem 3. For phases , the column vector is determined from the equalityfor , where the column vector is evaluated, starting from , from the relations , for , and the matrices and the column vectors satisfyfor integers . Proof. By conditioning on the first state visited by process
after leaving
, it is found that
for phases
and
, and the sequences of Laplace-Stieltjes transforms
, for phases
and integers
with
, satisfy
By using the column vectors
, for
, with entries
, for
and integers
, the above equations can be rewritten in matrix form as
for phases
and integers
, from which the theorem follows by block-Gaussian elimination. □
In a similar manner to (11), the Laplace-Stieltjes transform of
can be expressed as
for
and phases
, where
is the restricted Laplace-Stieltjes transform of
on the sample paths of
verifying
. From Equations (11)–(13) and the relation
for phases
, it is seen that the column vector
with entries
, for
, is given by
for
, with
where the
-th entry of the matrix
records the Laplace-Stieltjes transform
of
, for
and
, and the
th entry of the column vector
is given by
, for
. We may also observe that the matrix
has the form
where the column vectors
, for
, can be derived from Theorem 3; see Algorithm A3 (
Appendix C).
From (14) and (15), it is found that the following relations hold for the column vectors
, with
:
with
, so that the
kth moment of the random variable
is given by
for phases
. We only briefly indicate here that the matrix
is derived from (12) by differentiating
k times with respect to
s and evaluating at
. Moreover, it can be readily evaluated from
, as shown in Algorithm A4 (
Appendix C).
5. An Application to Varicella-Zoster Virus Infections
We illustrate our analysis by focusing here on a mathematical model for varicella-zoster virus in a nursing home. Varicella-zoster virus (VZV) causes chickenpox (varicella) and shingles (herpes zoster). In childhood, chickenpox disease produces itchy blisters but rarely causes serious problems. However, in adults who have not suffered the disease as children, chickenpox can lead to serious complications. After primary infection, VZV can remain dormant within dorsal root ganglia for life, and it can reactivate depending on a number of factors including the host immune system. Herpes zoster is the reactivation of VZV. Factors associated with recurrent disease include, among others, aging, immunosupression, intrauterine exposure to VZV, or having had varicella at a young age. Shingles is characterized by a rash of blisters, and it can be very painful but is not life-threatening. Varicella is highly contagious because the transmission occurs by direct contact, by air (coughing and sneezing) and by areosolization of virus from skin lesions. A person with active herpes zoster can transmit the VZV, through direct contact, to a person who never had chickenpox; we refer the reader to Reference [
38] for a flow diagram showing the different stages for an individual during an outbreak.
Our interest is in illustrating the applicability of our methodology by focusing on a Markovian model for the spread of VZV infection in a closed population, such as a nursing home for elderly people, subject to repeated outbreaks. The mathematical model assumes an homogeneous and finite population with constant size N, where residents who die or abandon the nursing home are immediately replaced by the admission of a new resident, reflecting high demand for nursing resources. Newly admitted residents are assumed to be either susceptible or asymptomatic, but never showing signs or symptoms of varicella or herpes zoster. We define the continuous-time Markov chain , where , and represent the number of varicella infectious (i.e., residents infected and infectious with varicella), zoster infectious (i.e., residents showing dermal rash of herpes zoster) and asymptomatic (i.e., residents with dormant VZV) residents at time t. Since we assume constant population size, it is clear that the number of susceptible residents is given by .
We assume that recovery times, as well as transmission times and the inter-event times for all other events in this process are exponentially distributed and mutually independent, leading to the Markovian hypothesis. We make the following further assumptions:
Varicella infectious residents recover at rate .
Zoster infectious residents recover at rate .
Residents are removed (either by dying or abandoning the nursing facility) at rate .
Newly admitted residents are (asymptomatically) infected with probability q.
Transmission between susceptible and varicella infectious residents occurs at rate , while transmission between susceptible and zoster infectious residents occurs at rate .
Reactivation of zoster for asymptomatic residents occurs at rate .
These hypotheses lead to a number of state transitions for process
with infinitesimal rates
for any states
and
with
. We point out that some events are omitted here since they are
unobserved by process
, meaning that they do not cause a change of state (e.g., if an asymptomatic resident dies and a newly admitted asymptomatic resident arrives, which occurs with rate
but does not affect the state of the process).
The continuous-time Markov chain
is defined on the state space
Even though process
is three-dimensional (while process
in
Section 1 is two-dimensional), one can obtain a QBD formulation for process
by organizing
in levels as
with
, for integers
. The
ith level
is written as
, where
, so that the number of states in sub-level
is
, and
This organization of states in terms of levels and sub-levels, as well as the transitions described above, leads to the following block-tridiagonal representation for the infinitesimal generator of
:
We note that this tridiagonal structure means that process
is a finite QBD process, so that our arguments in
Section 2,
Section 3,
Section 4 and
Section 5 directly apply. Variable
in
is the level, representing the number of varicella infectious individuals at any given time. The phase
in our original process
in
Section 1 has a bivariate representation here
. These phases are organized in terms of sub-levels as described above. In particular, one orders sub-levels inside
as
while states inside each sub-level
are ordered as
Thus, the first
phase (denoted by
in
Section 1) in level
is equivalent to the pair
, while the last phase is the
one which corresponds to
, since the number of phases in each level
(denoted by
in
Section 1) is given by
The organization of phases for each level in terms of sub-levels means that sub-matrices are given as follows:
For
, sub-matrix
is associated with jumps of process
from states in level
to states in level
. In particular, it is given by
Matrices
consist of transition rates from sub-level
to sub-level
and are given in
Appendix E. We can deal separately with the case
, for which
For
, sub-matrix
is related to transitions from level
to level
and has the structured form
where matrices
consist of transition rates from states in sub-level
to states in sub-level
, for
, and are detailed in
Appendix E. It is worth noting the particular case
, which leads to the single-element matrix
.
For
, sub-matrix
corresponds to transitions from states in level
to states in level
and is given by
where matrices
contain transition rates from states in sub-level
to states in sub-level
, and are given in
Appendix E. It is worth noting the particular case
, which leads to matrix
For process , the parameter values in our numerical experiments have been chosen according to the following assumptions:
- (i)
We consider a long-term nursing facility where the average length of stay of residents is 800 days (i.e.,
years) [
39,
40] and set
years
.
- (ii)
Residents recover from varicella after an average of 7 days [
38]; thus, we set
years
.
- (iii)
The average recovery time for herpes zoster is 20 days [
38], so we set
years
.
- (iv)
Based on existing data for the reactivation rate for zoster [
38,
41,
42], we set
years
.
- (v)
Since it is estimated that around
of adults in the USA carry VZV and are at risk of developing herpes zoster [
41], and a similar percentage is estimated for other countries in temperate climates [
43], we explore values
in our numerical results.
- (vi)
Varicella is highly infectious, but the particular transmissibility depends on a number of factors [
38,
41,
42,
43] (e.g., amount of contact in the nursing facility, control strategies in place, such as cohorting of staff and residents, etc). Thus, we will explore two parameter values
. In particular, we set
to broadly represent a situation where the nursing home has a range of control strategies in place when the outbreak starts, while
represents the situation where no control strategies are in place. Note that the value
is selected by assuming a basic reproduction number
, in accordance with estimated results for VZV transmission displayed in Reference [
44].
Finally, herpes zoster is transmitted significantly less than varicella itself [
41], but its particular transmission rate has not been precisely quantified to the best of our knowledge, so we explore values
in our numerical results.
For purely illustrative purposes, we consider a nursing home with
residents and focus on four different scenarios which vary in potential initial conditions and which allow us to carry out a sensitivity analysis of the summary statistics described in
Section 2,
Section 3 and
Section 4 on the parameter values discussed above. In particular, these scenarios are specified as follows:
Scenario 1.Outbreak initiated by a varicella infectious resident and prevalence of asymptomatics given by , i.e., initial condition .
Scenario 2.Outbreak initiated by a zoster infectious resident and prevalence of asymptomatics given by , i.e., initial condition .
Scenario 3.Outbreak initiated by a varicella infectious resident and prevalence of asymptomatics given by , i.e., initial condition .
Scenario 4.Outbreak initiated by a zoster infectious resident and prevalence of asymptomatics given by , i.e., initial condition .
For each scenario, our interest is in computing, by means of the analysis in
Section 2,
Section 3 and
Section 4, the following summary statistics:
The probability of reaching level (that is, K varicella infectious residents in the nursing home) before reaching level (end of the varicella outbreak), for different values of K.
The mean number of upcrossings to level .
The proportion of expected time that the process stays at or above level (so, with K or more varicella infectious residents).
The ratio , which represents the area under the curve of varicella infectives normalized by the total amount of time units that N residents stay in the nursing home during the varicella outbreak.
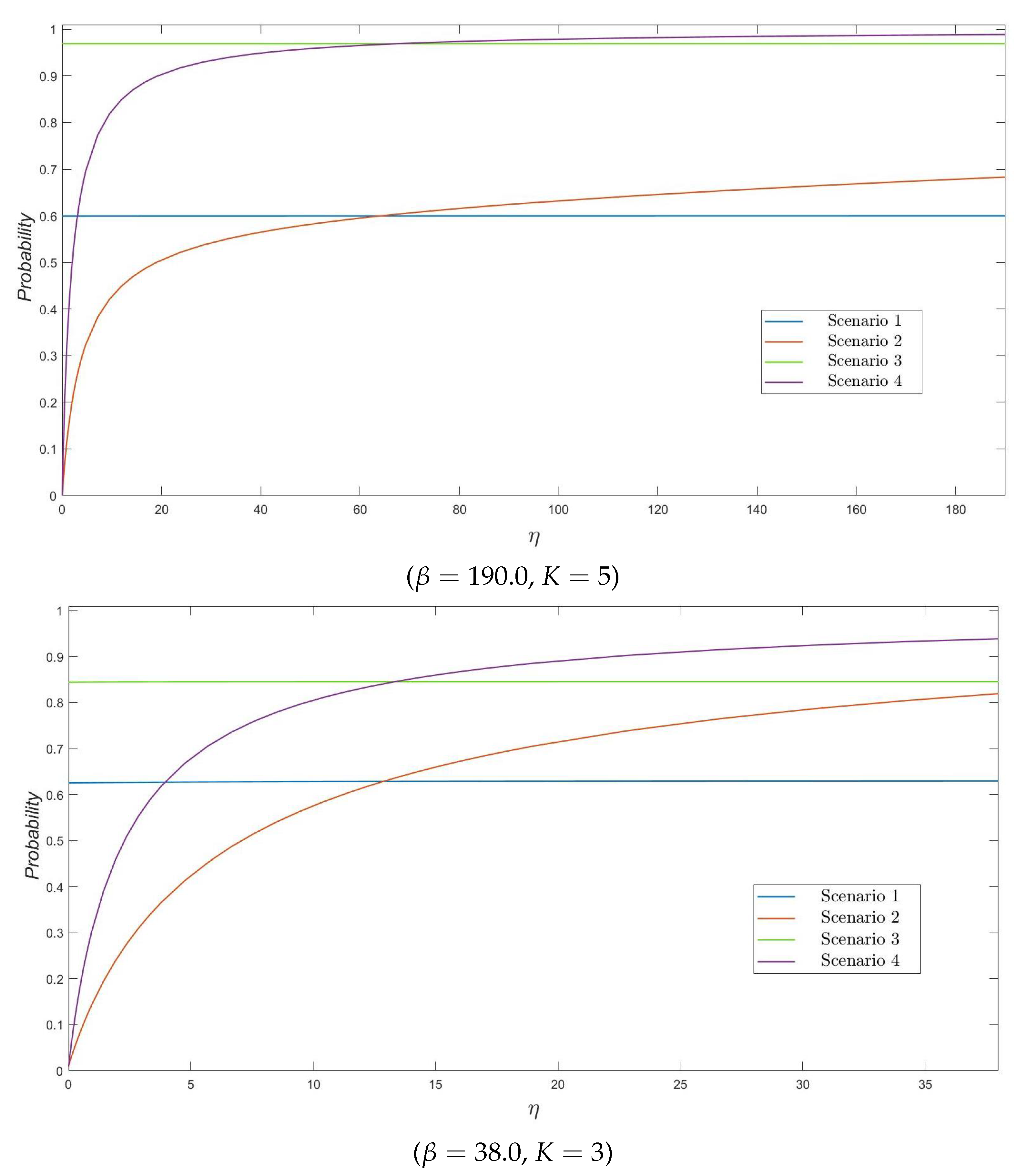
In
Figure 1, we plot the probability
of reaching a particular threshold value
K of varicella infectives (which might represent, for example, a particular number of infectives which would trigger the implementation of particular control strategies in the nursing home), for
,
and versus different values of
, for Scenarios 1–4. It is clear that this probability, for those scenarios related to a varicella infective starting the outbreak (Scenarios 1 and 3), does not significantly depend on the reactivation rate
of zoster infection as one would expect (since the initially infectious resident is a varicella infective). For Scenarios 2 and 4, in which a zoster infective starts the outbreak, the probability of reaching
K varicella infective residents sharply increases for initially increasing values of
(better allowing for the initially infective zoster to transmit before recovering), and then slowly stabilizes. On the other hand, it is worth noting that, due to the highly infectious nature of VZV, the maximum number of varicella infective residents reached before the end of the outbreak –not explicitly computed here, but which clearly affects the probability of reaching the particular threshold levels
and
– directly depends on the number of susceptible residents in the nursing home when the outbreak starts. This number of susceptibles directly depends on parameter
q (
in Scenarios 1 and 2, leading to 4 susceptible residents;
in Scenarios 3 and 4, leading to 9 susceptible residents) and directly explains the asymptotic behavior of curves observed in
Figure 1 for
and 5.
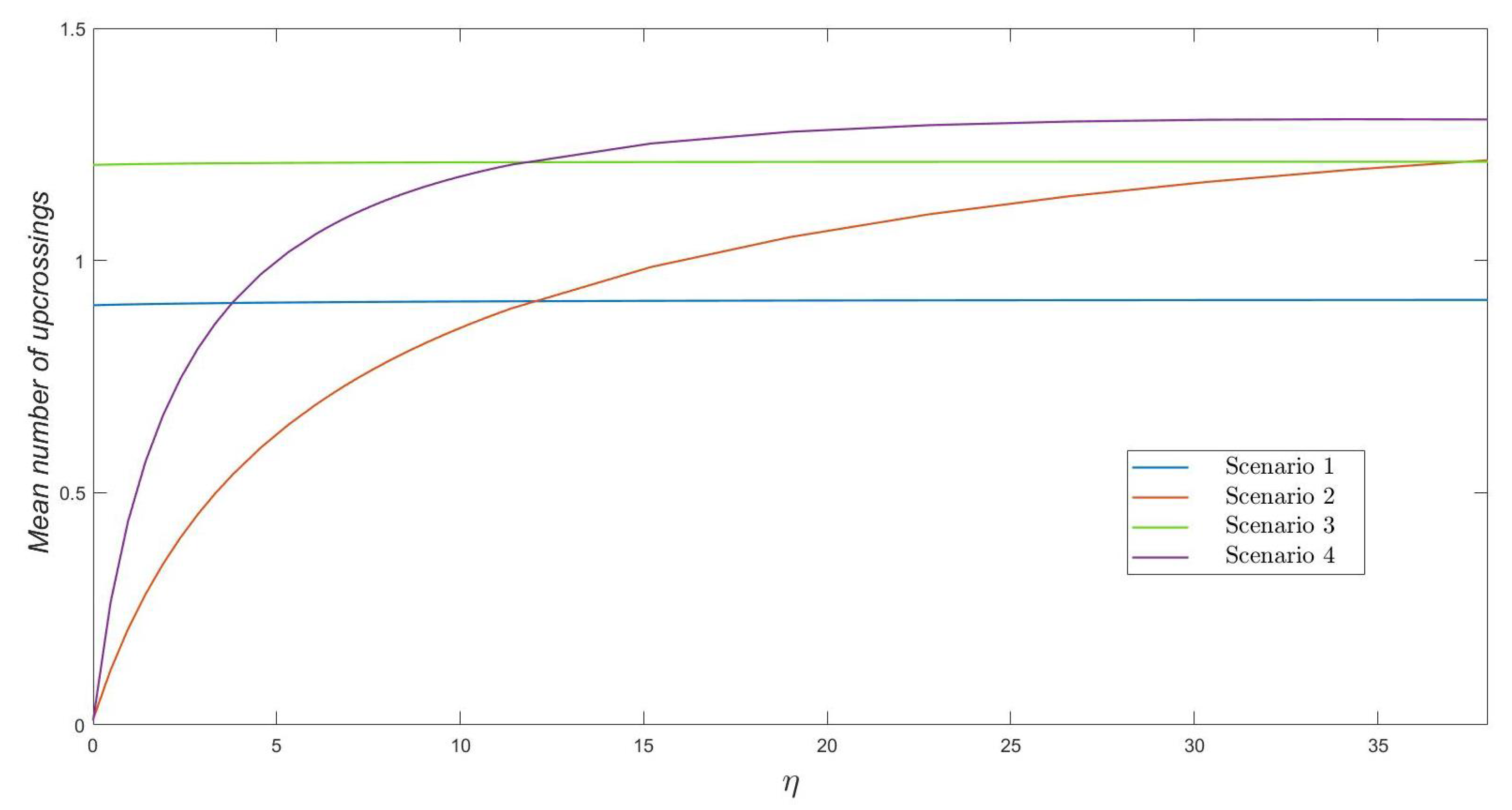
In
Figure 2, we plot the mean number of upcrossings to level
, for
, as a function of
. We note that we always obtain, regardless of the parameters varied here, a relatively small mean number of upcrossings (e.g., less than
in all scenarios). We point out that a mean number of upcrossings significantly below 1 means that the threshold number
of varicella infective residents is not actually reached in most of the stochastic realizations of process
. This happens, for example, when a zoster infective resident starts the outbreak and there are control measures in place, so that the transmissibility of herpes zoster is low (i.e., relatively small values of
in
Figure 2). For large enough values of
, or for those scenarios in which a varicella infective resident starts the outbreak, a mean number of upcrossings relatively close to 1 illustrates how level
with
is in fact reached during the early stages of the outbreak (i.e., while the number of infective residents is increasing over early times, moving towards its peak beyond
). Values of
slightly above 1 illustrate the stochasticity of the epidemic process under analysis and might be explained by stochastic contributions from some particular realizations of the process (for example, if process
reaches
varicella infective residents, and one of these residents recovers before another infection immediately occurs, moving the process to level
before visiting level
again, and causing then two upcrossings).
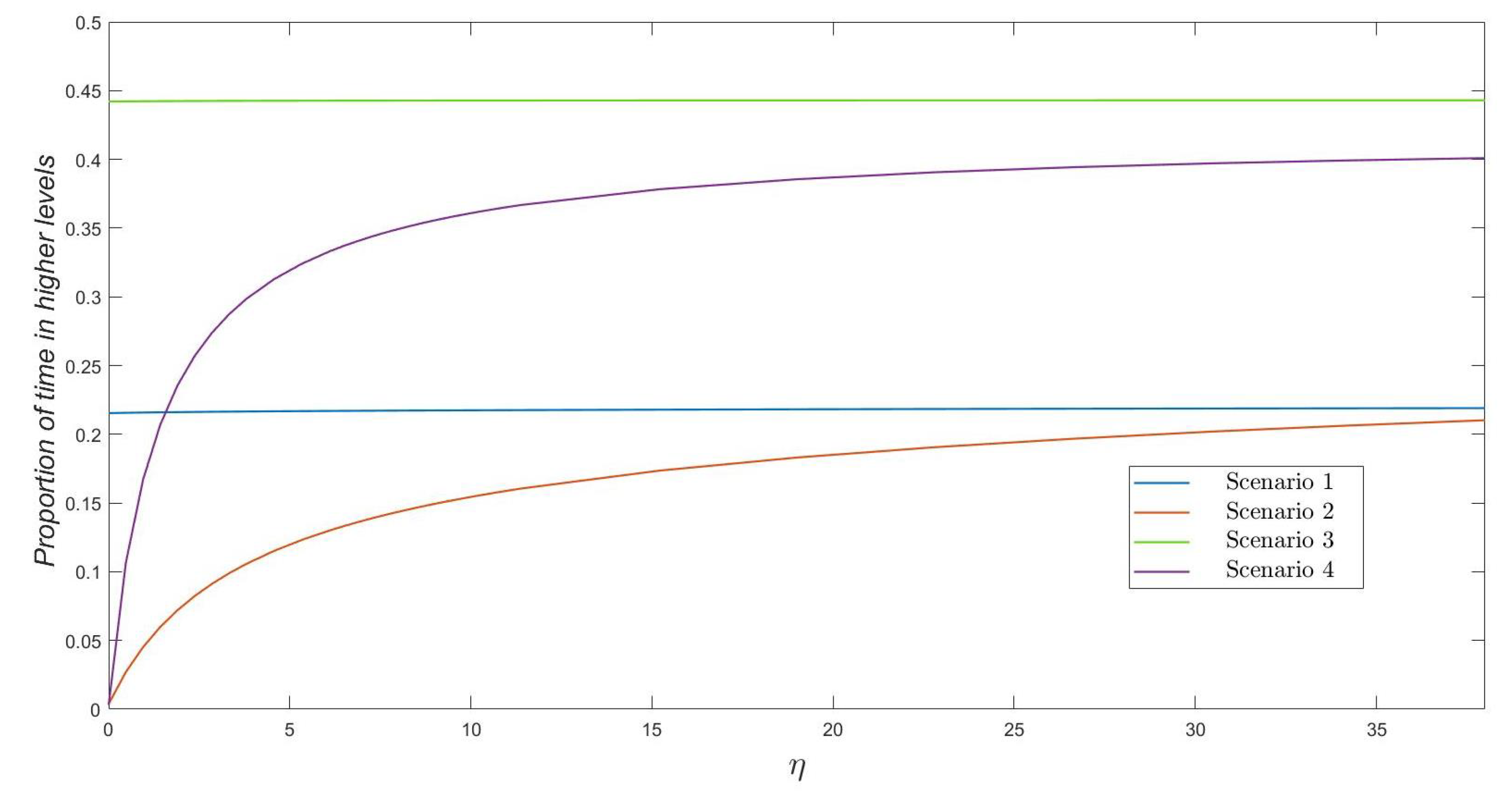
In
Figure 3, we plot the proportion of expected time
that the process
stays at or above level
. This might be of interest since, for example, if
K varicella infective residents represent an alert or warning level from which the nursing home needs to incur in some particular costs per unit time (e.g., particular enhanced control measures), the quantity
would become an implicit quantification of this cost. We plot
for a nursing home with some control strategies initially in place (so
), and for
for illustrative purposes. The proportion of expected time spent above level
directly depends on who starts the outbreak (from either a varicella infective resident or a zoster infective resident) in the first place, the number of susceptible residents in the nursing home (
versus
) and the zoster infectivity rate
. Proportions near to zero for Scenarios 2 and 4 and small values of
are explained by the fact that level
is likely not reached in these situations. On the other hand, for increasing values of the infectivity rate
, the proportion of expected time spent above level
directly depends on how many susceptible residents stay in the nursing home (which allows for larger epidemic peaks beyond
to be reached, likely leading to larger intervals of time until the epidemic curve decreases—by recoveries of infective residents—and goes again below level
). Similar comments explain the behavior of Scenarios 1 and 3, but, in these, the impact of parameter
is negligible since a varicella infective resident starts the outbreak.
In
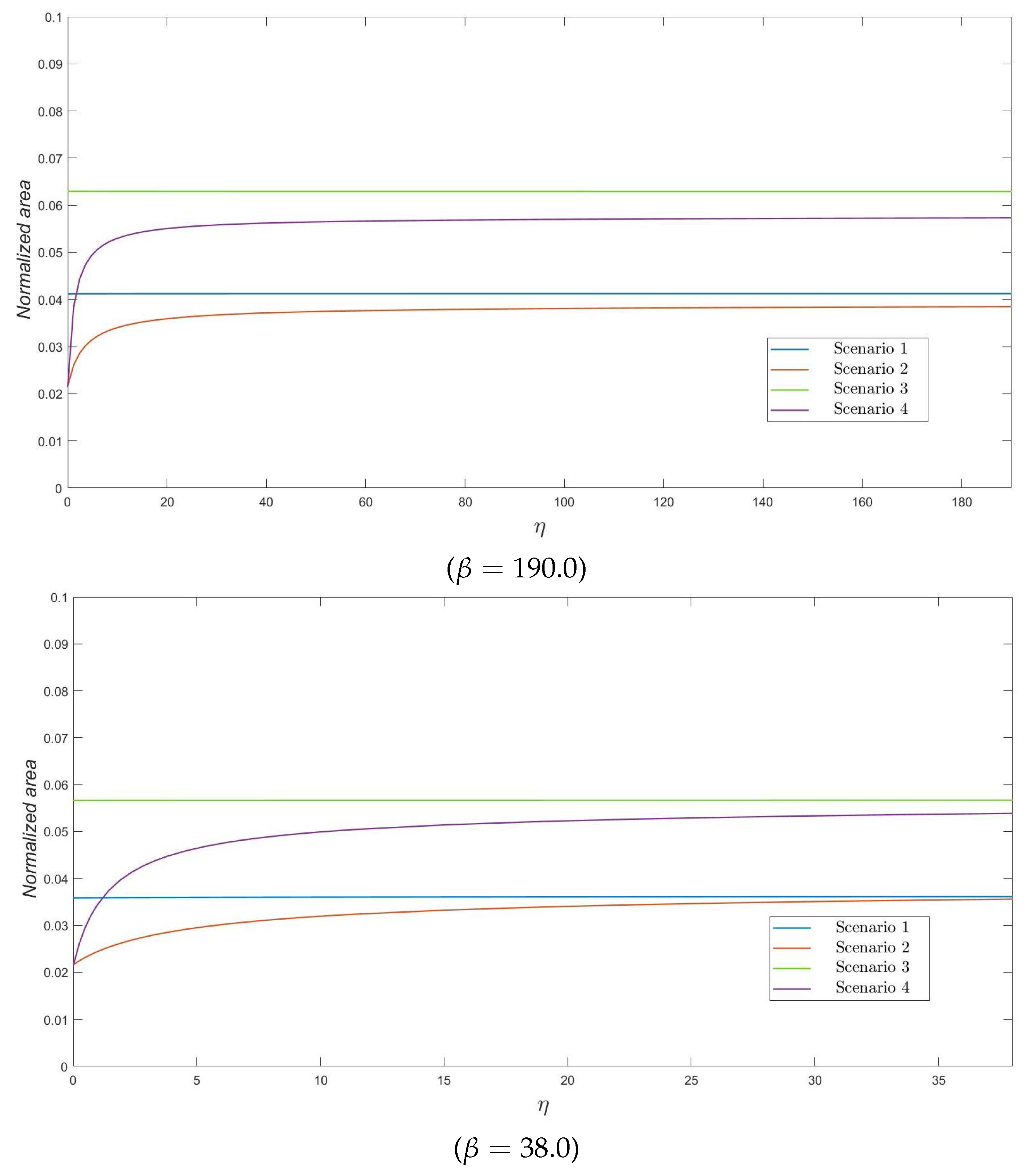
Figure 4, the interest is in the ratio
, which represents the area under the curve of varicella infectious residents normalized by the total amount of time units that
N residents stay at the nursing home during the varicella outbreak. We note here that this descriptor can be seen as a measure of cost, if, for example, the nursing home incurs in some costs per infective resident and per unit of time they remain infected. The behavior of this descriptor is similar to that observed in previous plots, whence we do not repeat preceding observations. However, we should emphasize here that the normalized area under the number of infectives is always less than the
of the total cost during the outbreak –measured in terms of
–, in such a way that the smallest and the highest values of the ratio
correspond to Scenarios 2 and 3, respectively, in our numerical experiments.
6. Conclusions
In this paper, we extended the theory of finite QBD processes, given by Gaver et al. [
1] by studying a number of random descriptors of interest which are defined inspired in their application to epidemic models, namely first-passage times and hitting probabilities to higher levels, number of upcrossings, and sojourn times, as well as the area under the level trajectory. We noted that these descriptors can have specific meanings when focusing on epidemic models: first-passage times and hitting probabilities can, for example, relate to the duration of an outbreak and the size of the epidemic, respectively; the number of upcrossings to a particular high level can represent the number of instances a particular threshold number of infectives is reached (which might lead to the introduction of particular control measures), while the area under the level trajectory can be translated into the area under the curve of infectives, a descriptor that has been analyzed before in the theory of mathematical epidemiology due to its potential interpretation in terms of the cost of a given outbreak. Although our results have been derived under the assumption that the finite QBD process is irreducible, they also hold under the less restrictive condition that
is accessible from the class
of communicating states.
In order to analyze these stochastic descriptors or summary statistics, we considered auxiliary bi-dimensional absorbing processes in which infinitesimal generators are described in terms of levels and phases, and we presented a block-structured form of these generators. We were able to exploit this structure to determine recursive relations involving sub-matrices of these infinitesimal generators, in order to compute the quantities of interest in an iterative and efficient way. Our algorithmic solution involves recursive procedures and block-Gaussian elimination, whence the computational complexity of Algorithms A1–A6 (
Appendix A,
Appendix B,
Appendix C and
Appendix D) can be written in a similar manner to the computational complexity of the linear level reduction algorithm of Gaver et al. [
1], and Algorithms 1.A–3.A of Gómez-Corral and López-García [
29]. This makes the memory requirements of Algorithms A1–A6, especially for storing auxiliary matrices in Algorithm A1, very demanding even for moderate values of
N depending of the number of phases per level.
To illustrate the applicability of both our analytical and computational results, we have presented a numerical study of an epidemic model for the transmission of varicella-zoster virus within a nursing home. There is clearly future work to be done on the joint distribution of the random vector
, where
is the maximum number of residents who are simultaneously varicella infectious (i.e., the maximum of the level variable) and
is the time taken to reach this maximum number during an outbreak, and on how to relate herd immunity to the phase variable in the study of vaccination strategies in the context of varicella-zoster virus infections. Among other interesting problems to be addressed in epidemic models are also the extension to a population with variable size or the assumption of non-exponential events. These would lead to QBD processes with infinitely many possible values of the level variable and/or the phase variable, and piecewise-deterministic Markov processes, respectively. In these frameworks, the study of the stochastic descriptors analyzed in
Section 2,
Section 3 and
Section 4 should require an analytical treatment and related numerical procedures that will be substantially different from those used in this paper; in particular, the analysis of first-passage times and sojourn times could benefit from the approach described by Dolgopyat and Goldsheid [
45], who obtain necessary and sufficient conditions for the existence of the density of the invariant measure for random walks when the environment is ergodic in both the transient and recurrent regimes. Another aspect that deserves further exploration is how the finite-dimensional linear algebra ideas in
Section 2 and
Section 3 could be replaced by some suitable extension to the QBD case of the Karlin-McGregor orthogonal polynomial/spectral representation by translating the arguments in Reference [
46,
47,
48] for discrete time processes to continuous time.




{kind=link}
{kind=link}
{kind=link}
{kind=link}



