SE-IYOLOV3: An Accurate Small Scale Face Detector for Outdoor Security

Abstract
1. Introduction
2. SE-IYOLOV3 Model
2.1. Improved YOLOV3 Model
2.1.1. Improved Anchor Box Algorithms
2.1.2. Change the Loss Function
2.1.3. Improved Prediction Layer Scale
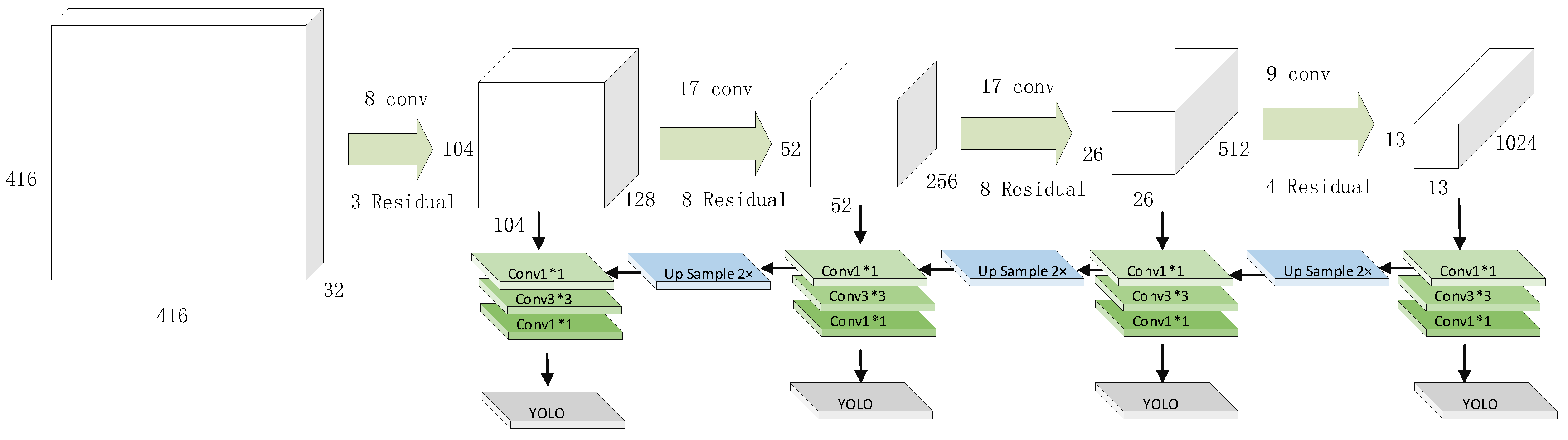
2.2. SE-IYOLOV3
3. Experimental Results
3.1. Datasets
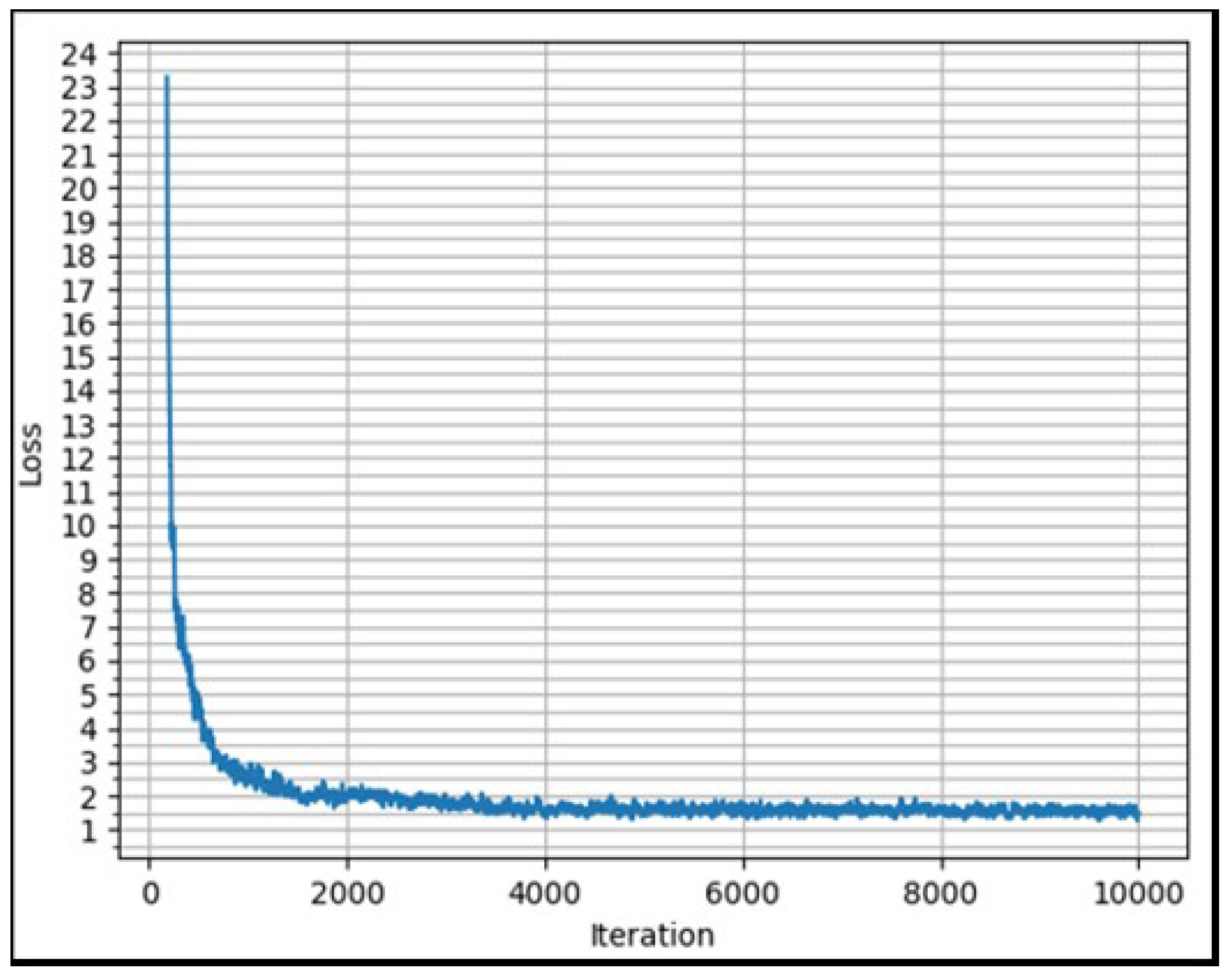
3.2. Convergence Verification of Improved YOLOV3 Embedded SENet Structure Model
3.3. The Impact of Different Improvement Strategies on the Average IOU
3.4. Comparison of Different Detection Models
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liao, S.; Jain, A.K.; Li, S.Z. A Fast and Accurate Unconstrained Face Detector. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 38, 211–223. [Google Scholar] [CrossRef] [PubMed]
- Zhao, x.; Liang, X.; Zhao, C.; Tang, M.; Wang, J. Real-Time Multi-Scale Face Detector on Embedded Devices. Sensors 2019, 19, 2158. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Jing, Y.; Deng, J.; Liu, Q. FaceHunter: A multi-task convolutional neural network based face detector. Signal Process. Image Commun. 2016, 47, 476–481. [Google Scholar]
- Zhang, C.; Zhang, Z. Improving multiview face detection with multi-task deep convolutional neural networks. In Proceedings of the 2014 IEEE Winter Conference on Applications of Computer Vision (WACV), Steamboat Springs, CO, USA, 24–26 March 2014. [Google Scholar]
- Kramer, R.S.; Mohamed, S.; Hardy, S.C. Unfamiliar Face Matching With Driving Licence and Passport Photographs. Perception 2019, 48, 175–184. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [PubMed]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Lu, Z.; Jiang, X.; Kot, A. A novel LBP-based Color descriptor for face recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2017), New Orleans, LA, USA, 5–9 March 2017; pp. 1857–1861. [Google Scholar]
- Lan, R.; Zhou, Y.; Tang, Y. Quaternionic Local Ranking Binary Pattern: A Local Descriptor of Color Images. IEEE Trans. Image Process. 2016, 25, 566–579. [Google Scholar] [CrossRef] [PubMed]
- Lan, R.; Zhou, Y. Quaternion-Michelson Descriptor for Color Image Classification. IEEE Trans. Image Process. 2016, 25, 5281–5292. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Stateline, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the BMVC 2015, Swansea, UK, 7–10 September 2015; p. 6. [Google Scholar]
- Jiang, H.; Learned-Miller, E. Face detection with the faster R-CNN. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 650–657. [Google Scholar]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. How far are we from solving pedestrian detection? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1259–1267. [Google Scholar]
- Najibi, M.; Samangouei, P.; Chellappa, R.; Davis, L.S. Ssh: Single stage headless face detector. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4875–4884. [Google Scholar]
- Li, H.; Lin, Z.; Shen, X.; Brandt, J.; Hua, G. A convolutional neural network cascade for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5325–5334. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Dong, Y.; Su, H.; Wu, B.; Li, Z.; Liu, W.; Zhang, T.; Zhu, J. Efficient Decision-based Black-box Adversarial Attacks on Face Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 7714–7722. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Lan, R.; Zhou, Y.; Liu, Z.; Luo, X. Prior Knowledge-Based Probabilistic Collaborative Representation for Visual Recognition. IEEE Trans. Cybern. 2018. [Google Scholar] [CrossRef] [PubMed]
- Lan, R.; Sun, L.; Liu, Z.; Lu, H.; Su, Z.; Pang, C.; Luo, X. Cascading and Enhanced Residual Networks for Accurate Single Image Super-resolution. IEEE Trans. Cybern. 2019. [Google Scholar] [CrossRef]
- Guo, Q.; Dong, Y.; Guo, Y.; Bai, H. MSFD: Multi-Scale Receptive Field Face Detector. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1869–1874. [Google Scholar]
- Wang, Z.; Zheng, L.; Li, Y.; Wang, S. Linkage Based Face Clustering via Graph Convolution Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 1117–1125. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Moran, J.; Haibo, L.; Zhongbo, W.; Miao, H.; Zheng, C.; Bin, H. Improved YOLO V3 Algorithm and Its Application in Small Target Detection. Acta Opt. Sin. 2019, 39, 0715004. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, OR, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 4700–4708. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Tjin, G.; Flores-Figueroa, E.; Duarte, D.; Straszkowski, L.; Scott, M.; Khorshed, R.A.; Purton, L.E.; Celso, C.L. Imaging methods used to study mouse and human HSC niches: Current and emerging technologies. Bone 2018, 119, S8756328218301765. [Google Scholar] [CrossRef] [PubMed]
- Nowozin, S. Optimal Decisions from Probabilistic Models: The Intersection-over-Union Case. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Yang, S.; Ping, L.; Chen, C.L.; Tang, X. WIDER FACE: A Face Detection Benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Deng, J.; Guo, J.; Zafeiriou, S. Single-Stage Joint Face Detection and Alignment. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CSRModule | Output Feature Map Size |
|---|---|
| 1 * CSR | 208 * 208 * 64 |
| 2 * CSR | 104 * 104 * 128 |
| 8 * CSR | 52 * 52 * 256 |
| 8 * CSR | 26 * 26 * 512 |
| 4 * CSR | 13 * 13 * 1024 |
| Program Name | Percentage |
|---|---|
| YOLOV3 | 78.56 |
| IYOLOV3-B | 84.12 |
| IYOLOV3-P | 82.88 |
| IYOLOV3-E | 81.37 |
| SE-IYOLOV3 | 85.98 |
| Models | Improved Anchor Box | Improved Prediction Layer | SENet Added | Precision % | Recall % | Detection Speed (ms) |
|---|---|---|---|---|---|---|
| R-CNN [13] | ✕ | ✕ | ✕ | 68.5 | 54.2 | 1300 |
| FAST-RCNN [15] | ✕ | ✕ | ✕ | 82.6 | 69.4 | 700 |
| Faster RCNN [16] | ✕ | ✕ | ✕ | 86.4 | 76.3 | 350 |
| Single Stage Joint [40] | ✕ | ✕ | ✕ | 92.1 | 87.8 | 510 |
| YOLOV3 [25] | ✕ | ✕ | ✕ | 75.6 | 63.4 | 230 |
| IYOLOV3-B | ✓ | ✕ | ✕ | 90.5 | 86.1 | 360 |
| IYOLOV3-P | ✕ | ✓ | ✕ | 90.1 | 88.2 | 340 |
| SE-IYOLOV3 | ✓ | ✓ | ✓ | 92.3 | 89.6 | 460 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, Z.; Yang, R.; Lan, R.; Liu, Z.; Luo, X. SE-IYOLOV3: An Accurate Small Scale Face Detector for Outdoor Security. Mathematics 2020, 8, 93. https://doi.org/10.3390/math8010093
Deng Z, Yang R, Lan R, Liu Z, Luo X. SE-IYOLOV3: An Accurate Small Scale Face Detector for Outdoor Security. Mathematics. 2020; 8(1):93. https://doi.org/10.3390/math8010093
Chicago/Turabian StyleDeng, Zhenrong, Rui Yang, Rushi Lan, Zhenbing Liu, and Xiaonan Luo. 2020. "SE-IYOLOV3: An Accurate Small Scale Face Detector for Outdoor Security" Mathematics 8, no. 1: 93. https://doi.org/10.3390/math8010093
APA StyleDeng, Z., Yang, R., Lan, R., Liu, Z., & Luo, X. (2020). SE-IYOLOV3: An Accurate Small Scale Face Detector for Outdoor Security. Mathematics, 8(1), 93. https://doi.org/10.3390/math8010093