Algorithms and Data Structures for Sparse Polynomial Arithmetic


Abstract
1. Introduction
Contributions and Paper Organization
2. Background
2.1. Notation and Nomenclature
2.2. Addition and Multiplication
| Algorithm 1addPolynomials (a,b) ; return |
|
| Algorithm 2heapMultiplyPolynomials(a,b) ; return |
|
3. Division with Remainder
3.1. Naïve Division with Remainder
| Algorithm 3dividePolynomials(a,b) , ; return such that where or does not divide any term in r (r is reduced with respect to the Gröbner basis ). |
|
3.2. Heap-Based Division with Remainder
| Algorithm 4heapDividePolynomials(a,b) , , ; return such that where or does not divide any term in r (r is reduced with respect to the Gröbner basis ). |
|
4. Pseudo-Division
4.1. Naïve Pseudo-Division
| Algorithm 5pseudoDividePolynomials(a,b) , , ; return and such that , with . |
|
- Case 1: and . Here, because we are still computing quotient terms, . Thus,
- Case 2: and
4.2. Heap-Based Pseudo-Division
| Algorithm 6heapPseudoDividePolynomials(a,b) , , , ; return and such that , with . |
|
5. Multi-Divisor Division and Pseudo-Division
| Algorithm 7TriangularSetNormalForm (a,) Given , , with and , returns and such that , with r is reduced (in the Gröbner bas) with respect to the Lazard triangular set . |
|
| Algorithm 8TriangularSetPseudoDivide (a,) Given , , with and for , returns and such that , where r is reduced with respect to . |
|
6. Data Structures
6.1. A Sparse Distributed Polynomial Data Structure
6.2. A Sparse Polynomial Data Structure for Viewing Polynomials Recursively
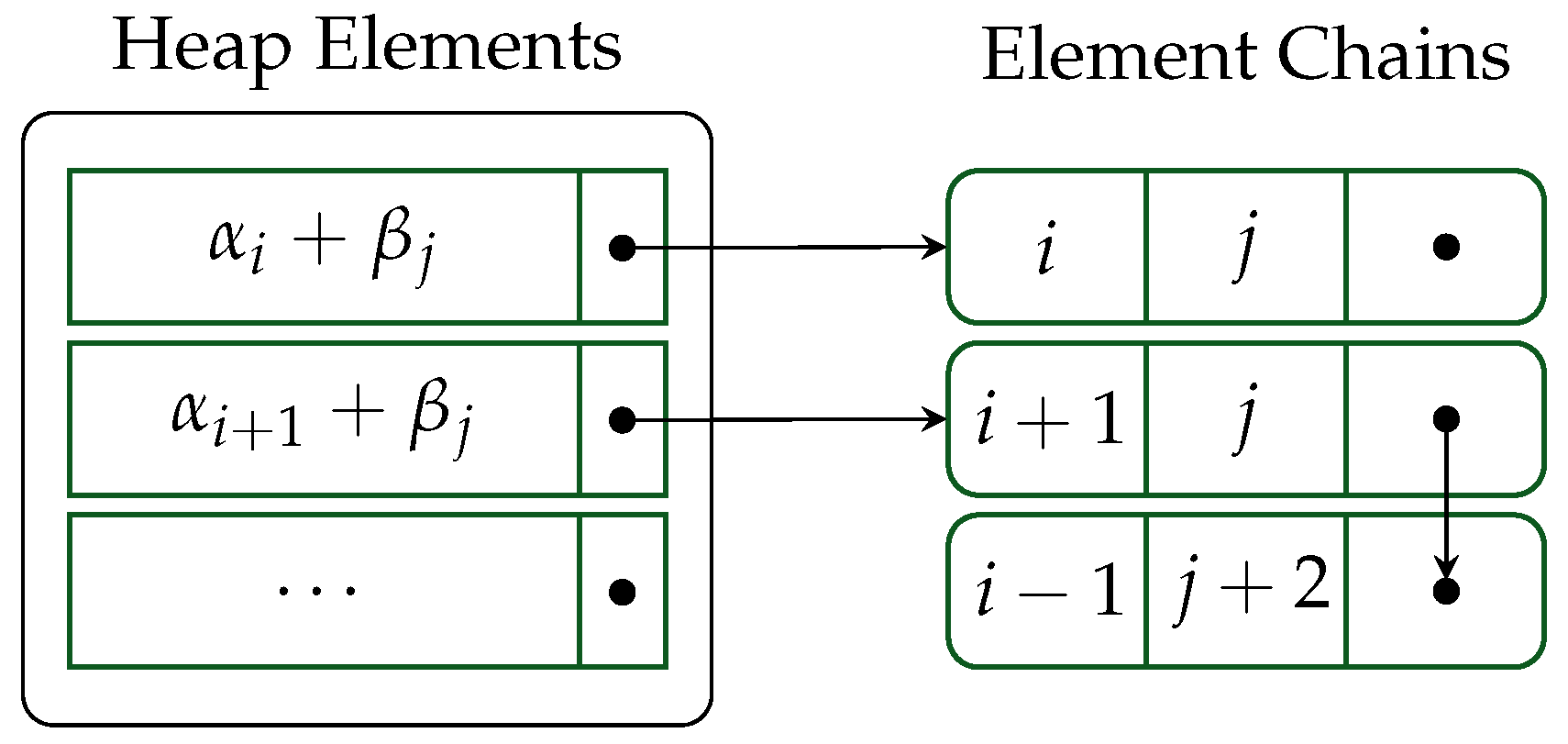
6.3. Heaps Optimized for Polynomial Multiplication
7. Implementation
7.1. In-Place Addition and Subtraction
7.2. Multiplication
7.3. Division with Remainder
7.4. Pseudo-Division
7.5. Multi-Divisor (Pseudo-)Division
8. Experimentation and Discussion
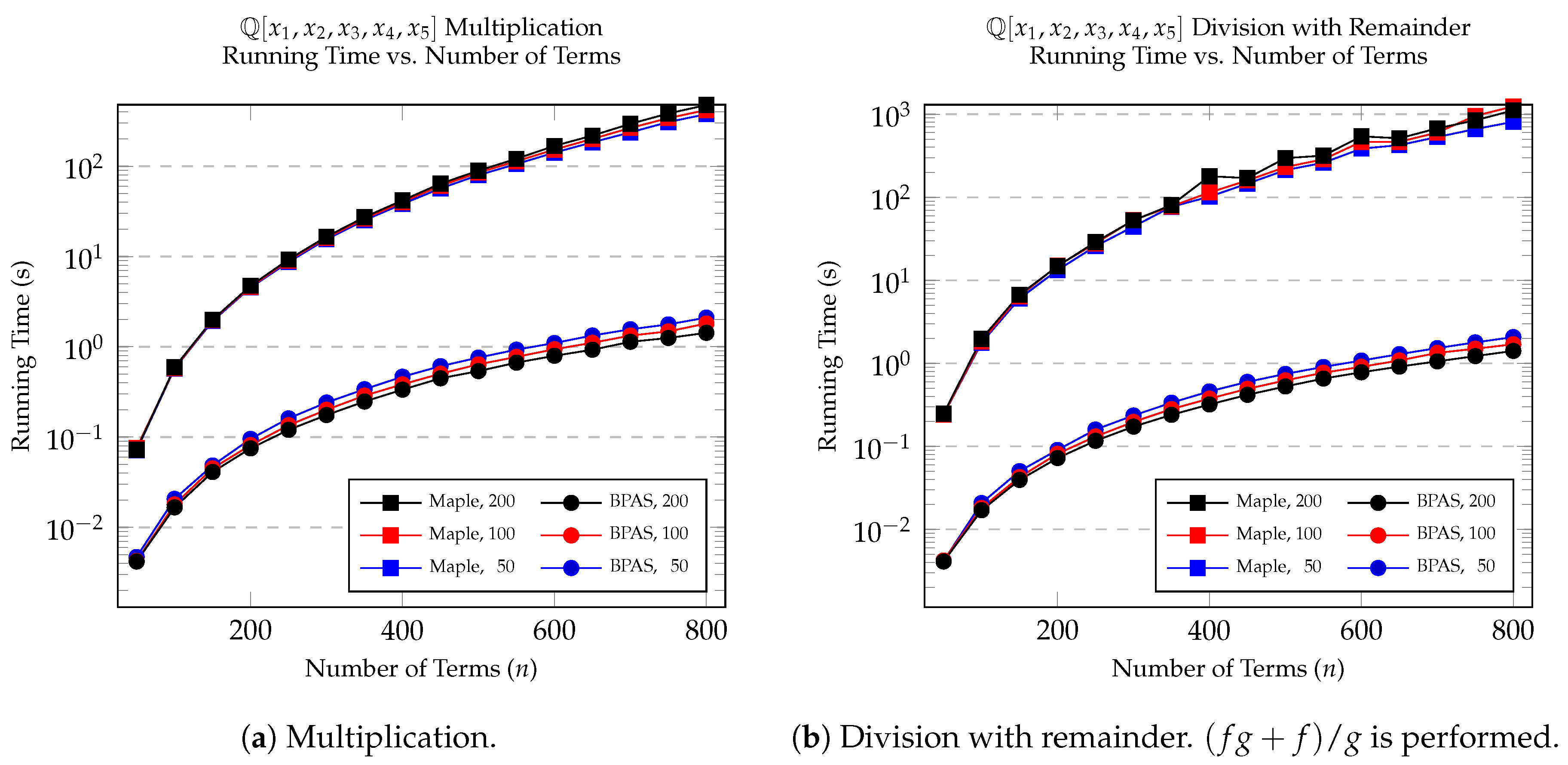
8.1. Multiplication and Division with Remainder
8.2. Pseudo-Division
8.3. Multi-Divisor Division and Pseudo-Division
8.4. Structured Problems
9. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Hall, A.D., Jr. The ALTRAN system for rational function manipulation-a survey. In Proceedings of the Second ACM Symposium on Symbolic and Algebraic Manipulation, Los Angeles, CA, USA, 23–25 March 1971; ACM: New York, NY, USA, 1971; pp. 153–157. [Google Scholar]
- Martin, W.A.; Fateman, R.J. The MACSYMA system. In Proceedings of the Second ACM Symposium on Symbolic and Algebraic Manipulation, Los Angeles, CA, USA, 23–25 March 1971; ACM: New York, NY, USA, 1971; pp. 59–75. [Google Scholar]
- Hearn, A.C. REDUCE: A user-oriented interactive system for algebraic simplification. In Symposium on Interactive Systems for Experimental Applied Mathematics, Proceedings of the Association for Computing Machinery Inc. Symposium, Washington, DC, USA, 1 August 1967; ACM: New York, NY, USA, 1967; pp. 79–90. [Google Scholar]
- Van der Hoeven, J.; Lecerf, G. On the bit-complexity of sparse polynomial and series multiplication. J. Symb. Comput. 2013, 50, 227–254. [Google Scholar] [CrossRef]
- Arnold, A.; Roche, D.S. Output-Sensitive Algorithms for Sumset and Sparse Polynomial Multiplication. In Proceedings of the ISSAC 2015, Bath, UK, 6–9 July 2015; pp. 29–36. [Google Scholar] [CrossRef]
- Monagan, M.B.; Pearce, R. Sparse polynomial division using a heap. J. Symb. Comput. 2011, 46, 807–822. [Google Scholar] [CrossRef]
- Gastineau, M.; Laskar, J. Highly Scalable Multiplication for Distributed Sparse Multivariate Polynomials on Many-Core Systems. In Proceedings of the CASC, Berlin, Germany, 9–13 September 2013; pp. 100–115. [Google Scholar]
- Hennessy, J.L.; Patterson, D.A. Computer Architecture: A Quantitative Approach, 4th ed.; Morgan Kaufmann: San Francisco, CA, USA, 2007. [Google Scholar]
- Wulf, W.A.; McKee, S.A. Hitting the memory wall: Implications of the obvious. ACM SIGARCH Comput. Archit. News 1995, 23, 20–24. [Google Scholar] [CrossRef]
- Asadi, M.; Brandt, A.; Moir, R.H.C.; Moreno Maza, M. Sparse Polynomial Arithmetic with the BPAS Library. In Proceedings of the Computer Algebra in Scientific Computing—20th International Workshop (CASC 2018), Lille, France, 17–21 September 2018; pp. 32–50. [Google Scholar] [CrossRef]
- Chen, C.; Moreno Maza, M. Algorithms for computing triangular decomposition of polynomial systems. J. Symb. Comput. 2012, 47, 610–642. [Google Scholar] [CrossRef]
- Asadi, M.; Brandt, A.; Chen, C.; Covanov, S.; Mansouri, F.; Mohajerani, D.; Moir, R.H.C.; Moreno Maza, M.; Wang, L.X.; Xie, N.; et al. Basic Polynomial Algebra Subprograms (BPAS). 2018. Available online: http://www.bpaslib.org (accessed on 16 May 2019).
- Frigo, M.; Leiserson, C.E.; Prokop, H.; Ramachandran, S. Cache-Oblivious Algorithms. ACM Trans. Algorithms 2012, 8, 4. [Google Scholar] [CrossRef]
- Leiserson, C.E. Cilk. In Encyclopedia of Parallel Computing; Springer: Boston, MA, USA, 2011; pp. 273–288. [Google Scholar] [CrossRef]
- Moreno Maza, M.; Xie, Y. Balanced Dense Polynomial Multiplication on Multi-Cores. Int. J. Found. Comput. Sci. 2011, 22, 1035–1055. [Google Scholar] [CrossRef]
- Chen, C.; Covanov, S.; Mansouri, F.; Moreno Maza, M.; Xie, N.; Xie, Y. Parallel Integer Polynomial Multiplication. arXiv 2016, arXiv:1612.05778. [Google Scholar]
- Covanov, S.; Mohajerani, D.; Moreno Maza, M.; Wang, L.X. Big Prime Field FFT on Multi-core Processors. In Proceedings of the ISSAC, Beijing, China, 15–18 July 2019; ACM: New York, NY, USA, 2019. [Google Scholar]
- Monagan, M.B.; Pearce, R. Parallel sparse polynomial multiplication using heaps. In Proceedings of the ISSAC, Seoul, Korea, 29–31 July 2009; pp. 263–270. [Google Scholar]
- Monagan, M.; Pearce, R. Parallel sparse polynomial division using heaps. In Proceedings of the PASCO, Grenoble, France, 21–23 July 2010; ACM: New York, NY, USA, 2010; pp. 105–111. [Google Scholar]
- Biscani, F. Parallel sparse polynomial multiplication on modern hardware architectures. In Proceedings of the 37th International Symposium on Symbolic and Algebraic Computation, Grenoble, France, 22–25 July 2012; ACM: New York, NY, USA, 2012; pp. 83–90. [Google Scholar]
- Gastineau, M.; Laskar, J. Parallel sparse multivariate polynomial division. In Proceedings of the PASCO 2015, Bath, UK, 10–12 July 2015; pp. 25–33. [Google Scholar] [CrossRef]
- Popescu, D.A.; Garcia, R.T. Multivariate polynomial multiplication on gpu. Procedia Comput. Sci. 2016, 80, 154–165. [Google Scholar] [CrossRef]
- Ewart, T.; Hehn, A.; Troyer, M. VLI–A Library for High Precision Integer and Polynomial Arithmetic. In Proceedings of the International Supercomputing Conference, Leipzig, Germany, 16–20 June 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 267–278. [Google Scholar]
- Johnson, S.C. Sparse polynomial arithmetic. ACM SIGSAM Bull. 1974, 8, 63–71. [Google Scholar] [CrossRef]
- Li, X.; Moreno Maza, M.; Schost, É. Fast arithmetic for triangular sets: From theory to practice. J. Symb. Comput. 2009, 44, 891–907. [Google Scholar] [CrossRef]
- Sedgewick, R.; Wayne, K. Algorithms, 4th ed.; Addison-Wesley: Boston, MA, USA, 2011. [Google Scholar]
- Cox, D.A.; Little, J.; O’shea, D. Ideals, Varieties, and Algorithms, 2nd ed.; Springer: New York, NY, USA, 1997. [Google Scholar]
- Von zur Gathen, J.; Gerhard, J. Modern Computer Algebra, 2nd ed.; Cambridge University Press: New York, NY, USA, 2003. [Google Scholar]
- Gastineau, M.; Laskar, J. Development of TRIP: Fast Sparse Multivariate Polynomial Multiplication Using Burst Tries. In Proceedings of the Computational Science—ICCS 2006, 6th International Conference, Reading, UK, 28–31 May 2006; Part II. pp. 446–453. [Google Scholar] [CrossRef]
- Monagan, M.; Pearce, R. The design of Maple’s sum-of-products and POLY data structures for representing mathematical objects. ACM Commun. Comput. Algebra 2015, 48, 166–186. [Google Scholar] [CrossRef]
- Granlund, T.; Gmp Development Team. GNU MP 6.0 Multiple Precision Arithmetic Library; Samurai Media Limited: Surrey, UK, 2015. [Google Scholar]
- Monagan, M.; Pearce, R. Polynomial division using dynamic arrays, heaps, and packed exponent vectors. In Proceedings of the CASC 2007, Bonn, Germany, 16–20 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 295–315. [Google Scholar]
- Gonnet, G.H.; Munro, J.I. Heaps on heaps. SIAM J. Comput. 1986, 15, 964–971. [Google Scholar] [CrossRef]
- Brandt, A. High Performance Sparse Multivariate Polynomials: Fundamental Data Structures and Algorithms. Master’s Thesis, The University of Western Ontario, London, ON, Canada, 2018. [Google Scholar]
- Huang, B.C.; Langston, M.A. Practical in-place merging. Commun. ACM 1988, 31, 348–352. [Google Scholar] [CrossRef]
- Katajainen, J.; Pasanen, T.; Teuhola, J. Practical in-place mergesort. Nord. J. Comput. 1996, 3, 27–40. [Google Scholar]
- Dalkilic, M.E.; Acar, E.; Tokatli, G. A simple shuffle-based stable in-place merge algorithm. Procedia Comput. Sci. 2011, 3, 1049–1054. [Google Scholar] [CrossRef]
- Waterloo Maple Inc. Maple 2017—The Essential Tool for Mathematics; Waterloo Maple Inc.: Waterloo, ON, Canada, 2017. [Google Scholar]
- Gastineau, M.; Laskar, J. TRIP: A Computer Algebra System Dedicated to Celestial Mechanics and Perturbation Series. ACM Commun. Comput. Algebra 2011, 44, 194–197. [Google Scholar] [CrossRef]
- Bosma, W.; Cannon, J.; Playoust, C. The Magma algebra system. I. The user language. J. Symb. Comput. 1997, 24, 235–265. [Google Scholar] [CrossRef]
- Decker, W.; Greuel, G.M.; Pfister, G.; Schönemann, H. Singular 4-1-1—A Computer Algebra System for Polynomial Computations. 2018. Available online: http://www.singular.uni-kl.de (accessed on 15 March 2019).
- The PARI Group, Univ. Bordeaux. PARI/GP Version 2.3.3. 2008. Available online: http://pari.math.u-bordeaux.fr/ (accessed on 15 March 2019).
- Hart, W.; Johansson, F.; Pancratz, S. FLINT: Fast Library for Number Theory. V. 2.4.3. Available online: http://flintlib.org (accessed on 15 March 2019).
- Shoup, V. NTL: A Library for Doing Number Theory. Available online: www.shoup.net/ntl/ (accessed on 15 March 2019).
- Monagan, M.B.; Pearce, R. Sparse polynomial multiplication and division in Maple 14. ACM Commun. Comput. Algebra 2010, 44, 205–209. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operation | d | Coef. Bound | BPAS | Maple | ||
|---|---|---|---|---|---|---|
| Time (s) | Memory (MiB) | Time (s) | Memory (MiB) | |||
| Multiplication | 4 | 1 | 4.28 | 172.11 | 1.78 | 79.31 |
| 4 | 64 | 8.22 | 353.27 | 9.58 | 810.23 | |
| 5 | 64 | 155.51 | 2481.37 | 221.71 | 5569.25 | |
| Division | 4 | 64 | 7.84 | 353.29 | 6.465 | 816.03 |
| 5 | 64 | 154.08 | 2509.42 | 124.37 | 5583.50 | |
| Multiplication | 12 | 1 | 3.61 | 702.14 | 2.835 | 439.21 |
| 12 | 32 | 7.62 | 1878.96 | 52.80 | 4026.29 | |
| 15 | 32 | 51.61 | 8605.52 | 1114.23 | 18,941.05 | |
| Division | 12 | 32 | 8.09 | 1919.28 | 10.35 | 4033.57 |
| 15 | 32 | 57.09 | 8627.16 | 58.906 | 18,660.94 | |
| Division | 1,000,000 | 1 | 0.18 | 38.59 | 1.505 | 164.54 |
| 10,000,000 | 1 | 1.87 | 522.65 | 23.63 | 1102.21 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asadi, M.; Brandt, A.; Moir, R.H.C.; Moreno Maza, M. Algorithms and Data Structures for Sparse Polynomial Arithmetic. Mathematics 2019, 7, 441. https://doi.org/10.3390/math7050441
Asadi M, Brandt A, Moir RHC, Moreno Maza M. Algorithms and Data Structures for Sparse Polynomial Arithmetic. Mathematics. 2019; 7(5):441. https://doi.org/10.3390/math7050441
Chicago/Turabian StyleAsadi, Mohammadali, Alexander Brandt, Robert H. C. Moir, and Marc Moreno Maza. 2019. "Algorithms and Data Structures for Sparse Polynomial Arithmetic" Mathematics 7, no. 5: 441. https://doi.org/10.3390/math7050441
APA StyleAsadi, M., Brandt, A., Moir, R. H. C., & Moreno Maza, M. (2019). Algorithms and Data Structures for Sparse Polynomial Arithmetic. Mathematics, 7(5), 441. https://doi.org/10.3390/math7050441