An Interval Type-2 Fuzzy Similarity-Based MABAC Approach for Patient-Centered Care


Abstract
:1. Introduction
- There are several motivations for using IT2FNs. First, common fuzzy numbers, such as triangular fuzzy numbers and generalized type-2 fuzzy numbers, have some limitations regarding directly dealing with uncertain information. In practical applications, the same linguistic term may represent different meanings for different people. IT2FNs give DMs greater freedom in the determination of the membership function, and it can better describe and deal with inaccurate information. Second, compared with GT2FNs, IT2FNs have lower computational complexity. Therefore, IT2FNs is applied to develop the new algorithm to solve the medical treatment selection decision-making problem in a patient-centered environment.
- Considering the existing interval type-2 fuzzy similarity measures, there are some limitations for some particular sets. Therefore, we propose a new similarity, which represents the degree of closeness between two IT2FNs. Moreover, we not only present a new property of the similarity measure, but it also overcomes the drawback of other existing interval type-2 fuzzy similarity measures. Through a large number of comparative experiments, the advantages of the proposed interval type-2 fuzzy similarity are confirmed. Thereby, the proposed similarity algorithm is more scientific and effective.
- Due to the computational complexity of the interval type-2 fuzzy similarity, we need a simpler and more straightforward approach to making decisions. Compared to other decision-making methods, MABAC is more simplified and straightforward. MABAC is applied to solve the computational complexity of IT2FNs and interval type-2 fuzzy similarity, which is helpful to improve the performance of the interval type-2 fuzzy similarity in practice. Moreover, in order to optimize the composition of the proposed algorithm and improve the efficiency and accuracy of the calculation process, we propose a similarity-based MABAC method. The proposed method is less complex and more straightforward than the other methods.
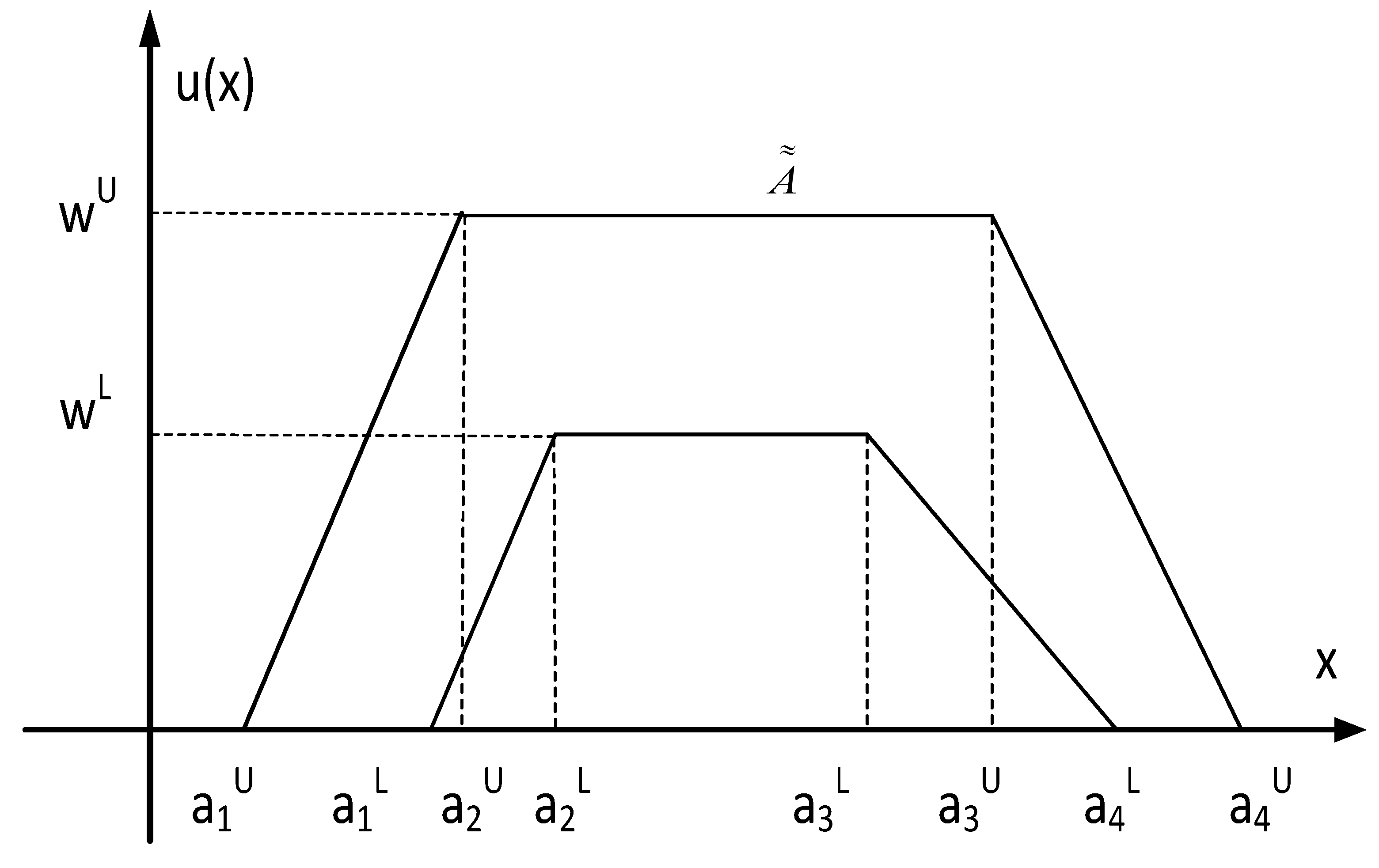
2. Preliminaries
3. New Similarity Measures for Interval Type-2 Fuzzy Numbers
3.1. The New Similarity Measures
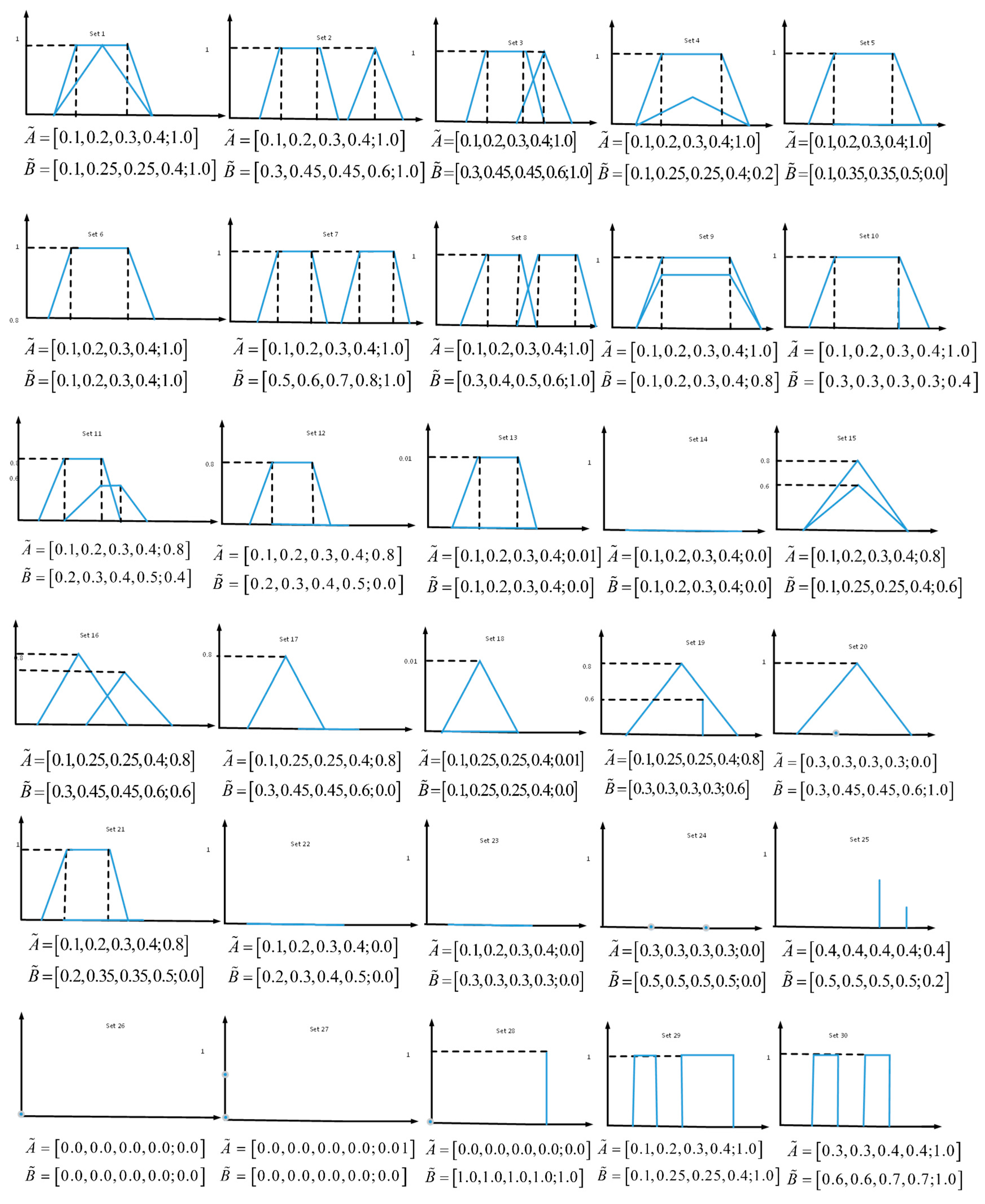
3.2. Experimental Results and Analysis
- From sets 9, 13, 15, 18, and 27 of Figure 2 and Table 1, we can see that the graphical representations of these sets were different, but looking at the calculation results of the method of Reference [35], the degree of similarity between and were equal to 1. However, from the results of Table 1, the degree of our proposed similarity was not equal to 1. This is in line with our intuition. Therefore, this proves that our method is better than that found in Reference [35].
- From sets 22 and 23 of Figure 2 and Table 1, as shown in Figure 2, the height and area of these geometric figures were equal to 0, but their perimeters are different. This means that the two type-2 fuzzy numbers were different. However, from Reference [38], the results from Table 1 were equal. Furthermore, our proposed similarity measure gives different results for these two type-2 fuzzy sets. This is more in line with human intuition. Hence, this shows that our method is superior to the method of Reference [38].
- From sets 24 and 26 of Figure 2 and Table 1, we can see that and have the same shape, perimeter, and height. However, according to the methods of References [30,32,36,37], it is difficult to obtain the similarity between and and unreasonable results are obtained. Moreover, from set 27, according to the results of the method of References [30,37], we find that the similarity was equal to 0. However, the similarity of geometrical figures was almost equal. Instead, the similarity of our methods was equal to 0.9928. This proves that our proposed similarity measure is more reasonable.
- From set 28 of Figure 2 and Table 1, we know that and were two completely different type-2 fuzzy numbers. Therefore, the similarity of our proposed method was equal to 0. However, from the calculation results of Reference [36], the results were unreasonable. Hence, our method is superior that found in Reference [36].
- From sets 29 and 30 of Figure 2 and Table 1, according to Reference [39], we can see that the result of the similarity measure of and were the same, but their graphical representation shows that they were different. In contrast, the results of the similarity of our methods were different. Therefore, our proposed method shows better performance.
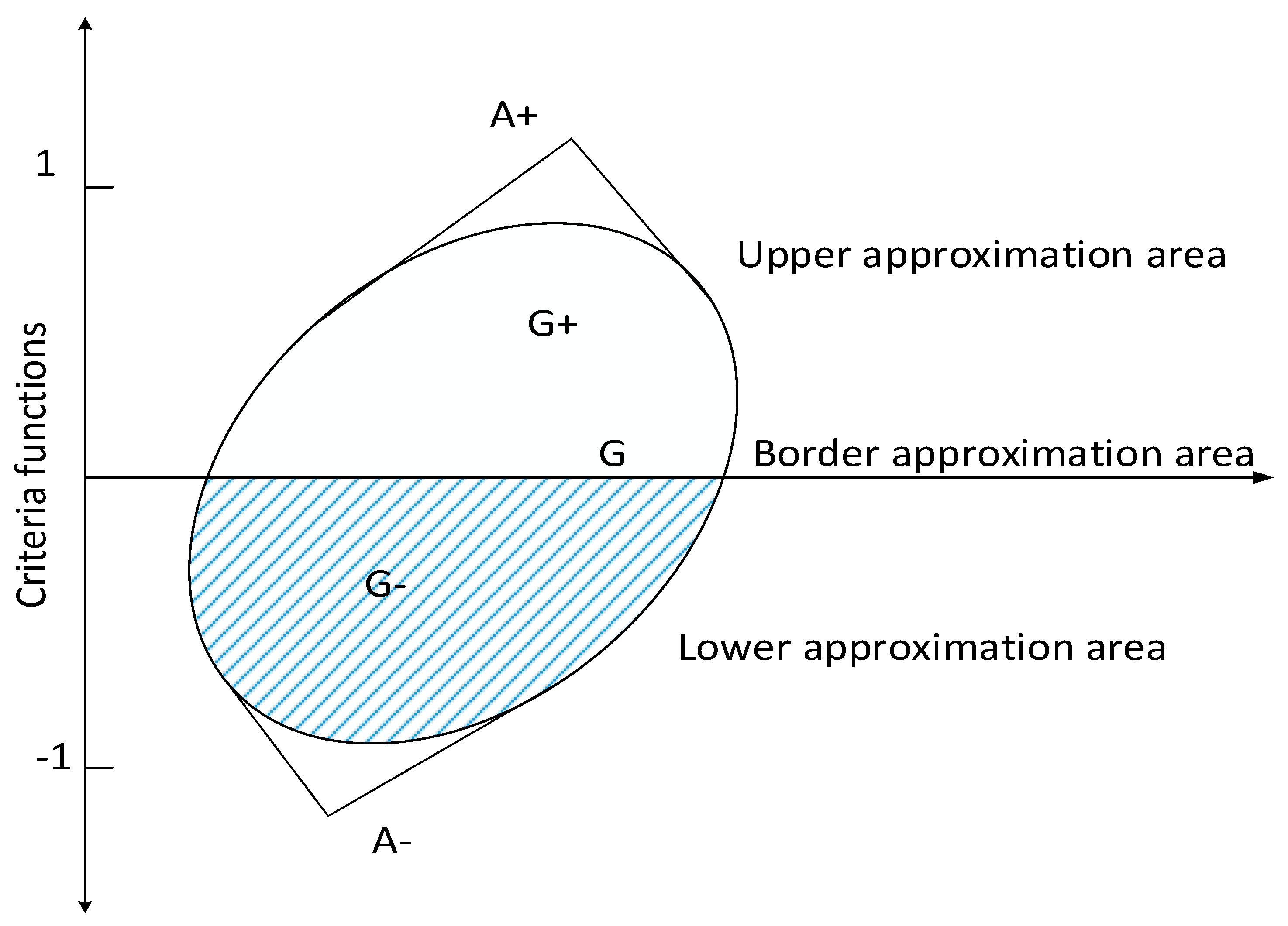
4. An Interval Type-2 Fuzzy Similarity-Based MABAC Approach in MCDM
5. Application in Selecting Medical Treatment
5.1. Problem Description
5.2. Illustration of the Modified MABAC Approach
5.3. Comparison Analysis and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Redman, R.W. Patient-centered care: An unattainable ideal? Res. Theory Nurs. Pract. 2004, 18, 11. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Chen, D.; Liang, P. A Novel Interval Three-Way Concept Lattice Model with Its Application in Medical Diagnosis. Mathematics 2019, 7, 103. [Google Scholar] [CrossRef]
- Pelzang, R. Time to learn: Understanding patient-centred care. Br. J. Nurs. 2010, 19, 912–917. [Google Scholar] [CrossRef] [PubMed]
- Steiger, N.J.; Balog, A. Realizing patient-centered care: Putting patients in the center, not the middle. Front. Health Serv. Manag. 2010, 26, 15–25. [Google Scholar] [CrossRef]
- Epstein, R.M. The science of patient-centered care. J. Fam. Pract. 2000, 49, 805–807. [Google Scholar] [PubMed]
- Mccormack, B.; Mccance, T.V. Development of a framework for person-centred nursing. J. Adv. Nurs. 2006, 56, 472–479. [Google Scholar] [CrossRef]
- Lutz, B.J.; Bowers, B.J. Patient-centered care: Understanding its interpretation and implementation in health care. Res. Theory Nurs. Pract. 2000, 14, 165–183; discussion 183–187. [Google Scholar]
- Lee, Y.Y.; Lin, J.L. Do patient autonomy preferences matter? Linking patient-centered care to patient-physician relationships and health outcomes. Soc. Sci. Med. 2010, 71, 1811–1818. [Google Scholar] [CrossRef]
- Edwards, M.; Davies, M.; Edwards, A. What are the external influences on information exchange and shared decision-making in healthcare consultations: A meta-synthesis of the literature. Patient Educ. Couns. 2009, 75, 37–52. [Google Scholar] [CrossRef]
- Qin, J.; Liu, X. Multi-attribute group decision making using combined ranking value under interval type-2 fuzzy environment. Inf. Sci. 2015, 297, 293–315. [Google Scholar] [CrossRef]
- Qin, J.; Liu, X.; Pedrycz, W. An extended VIKOR method based on prospect theory for multiple attribute decision making under interval type-2 fuzzy environment. Knowl. Based Syst. 2015, 86, 116–130. [Google Scholar] [CrossRef]
- Wang, J.Q.; Peng, J.J.; Zhang, H.Y.; Chen, X.H. Outranking approach for multi-criteria decision-making problems with hesitant interval-valued fuzzy sets. Soft Comput. 2017. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Zhang, H.Y.; Wang, J.Q. Discussing incomplete 2-tuple fuzzy linguistic preference relations in multi-granular linguistic MCGDM with unknown weight information. Soft Comput. 2017, 20, 958–969. [Google Scholar] [CrossRef]
- Peng, H.-G.; Wang, X.-K.; Wang, T.-L.; Wang, J.-Q. Multi-criteria game model based on the pairwise comparisons of strategies with Z-numbers. Appl. Soft Comput. 2019, 74, 451–465. [Google Scholar] [CrossRef]
- Sun, R.; Hu, J.; Chen, X. Novel single-valued neutrosophic decision-making approaches based on prospect theory and their applications in physician selection. Soft Comput. 2019, 23, 211–225. [Google Scholar] [CrossRef]
- Liang, P.; Hu, J.; Liu, Y.; Chen, X. Public resources allocation using an uncertain cooperative game among vulnerable groups. Kybernetes 2018. [Google Scholar] [CrossRef]
- Yang, Y.; Hu, J.; Liu, Y.; Chen, X. Alternative selection of end-of-life vehicle management in China: A group decision-making approach based on picture hesitant fuzzy measurements. J. Clean. Prod. 2019, 206, 631–645. [Google Scholar] [CrossRef]
- Zadeh, L.A. The Concept of a Linguistic Variable and its Application to Approximate Reasoning—I. Inf. Sci. 1974, 8, 199–249. [Google Scholar] [CrossRef]
- Yang, Y.; Hu, J.; Liu, Y. Doctor recommendation based on an intuitionistic normal cloud model considering patient preferences. Cogn. Comput. 2018. [Google Scholar] [CrossRef]
- Castillo, O.; Amador-Angulo, L.; Castro, J.R.; Garcia-Valdez, M. A comparative study of type-1 fuzzy logic systems, interval type-2 fuzzy logic systems and generalized type-2 fuzzy logic systems in control problems. Inf. Sci. 2016, 354, 257–274. [Google Scholar] [CrossRef]
- Sanchez, M.A.; Castillo, O.; Castro, J.R. Generalized Type-2 Fuzzy Systems for controlling a mobile robot and a performance comparison with Interval Type-2 and Type-1 Fuzzy Systems. Expert Syst. Appl. 2015, 42, 5904–5914. [Google Scholar] [CrossRef]
- Yang, Y.; Hu, J.; Sun, R.; Chen, X. Medical tourism estinations prioritization using group decision making method with neutrosophic fuzzy preference relations. Sci. Iran. Trans. E Ind. Eng. 2018, 25, 3744–3764. [Google Scholar]
- Hu, J.; Zhang, X.; Yang, Y.; Liu, Y.; Chen, X. New doctors ranking system based on VIKOR method. Int. Trans. Oper. Res. 2018. [Google Scholar] [CrossRef]
- Castillo, O.; Cervantes, L.; Soria, J.; Sanchez, M.; Castro, J.R. A Generalized Type-2 Fuzzy Granular Approach with Applications to Aerospace. Inf. Sci. Int. J. 2016, 354, 165–177. [Google Scholar] [CrossRef]
- Ontiveros-Robles, E.; Melin, P.; Castillo, O. Comparative analysis of noise robustness of type 2 fuzzy logic controllers. Kybernetika 2018, 54, 175–201. [Google Scholar] [CrossRef]
- Cervantes, L.; Castillo, O. Type-2 fuzzy logic aggregation of multiple fuzzy controllers for airplane flight control. Inf. Sci. 2015, 324, 247–256. [Google Scholar] [CrossRef]
- Cazarez-Castro, N.R.; Aguilar, L.T.; Castillo, O. Designing Type-1 and Type-2 Fuzzy Logic Controllers via Fuzzy Lyapunov Synthesis for nonsmooth mechanical systems. Eng. Appl. Artif. Intell. 2012, 25, 971–979. [Google Scholar] [CrossRef]
- Li, J.; Wang, J.Q.; Hu, J.H. Interval-valued n-person cooperative games with satisfactory degree constraints. Cent. Eur. J. Oper. Res. 2018. [Google Scholar] [CrossRef]
- Ji, P.; Zhang, H.Y.; Wang, J.Q. A Fuzzy Decision Support Model With Sentiment Analysis for Items Comparison in e-Commerce: The Case Study of PConline.com. IEEE Trans. Syst. Man Cybern. Syst. 2018. [Google Scholar] [CrossRef]
- Wei, S.H.; Chen, S.M. A new approach for fuzzy risk analysis based on similarity measures of generalized fuzzy numbers. Expert Syst. Appl. 2009, 36, 589–598. [Google Scholar] [CrossRef]
- Chen, S.M.; Chen, J.H. A new method for ranking generalized fuzzy numbers for handling fuzzy risk analysis problems. In Proceedings of the Joint Conference on Information Sciences, JCIS 2006, Kaohsiung, Taiwan, 8–11 October 2006; pp. 1196–1199. [Google Scholar]
- Chen, J.H.; Chen, S.M. A new method to measure the similarity between Interval-valued fuzzy numbers. In Proceedings of the International Conference on Machine Learning and Cybernetics, Hong Kong, China, 19–22 August 2007; pp. 1123–1126. [Google Scholar]
- Wang, G.; Li, X. Correlation and information energy of interval-valued fuzzy numbers. Fuzzy Sets Syst. 1999, 103, 169–175. [Google Scholar] [CrossRef]
- Sanchez, M.A.; Castillo, O.; Castro, J.R. Information granule formation via the concept of uncertainty-based information with Interval Type-2 Fuzzy Sets representation and Takagi–Sugeno–Kang consequents optimized with Cuckoo search. Appl. Soft Comput. 2015, 27, 602–609. [Google Scholar] [CrossRef]
- Chen, S. New methods for subjective mental workload assessment and fuzzy risk analysis. Cybern. Syst. 1996, 27, 449–472. [Google Scholar] [CrossRef]
- Chen, S.J.; Chen, S.M. A new method to measure the similarity between fuzzy numbers. In Proceedings of the 10th IEEE International Conference on Fuzzy Systems, Melbourne, Australia, 2–5 December 2001; pp. 208–214. [Google Scholar]
- Hejazi, S.R.; Doostparast, A.; Hosseini, S.M. An improved fuzzy risk analysis based on a new similarity measures of generalized fuzzy numbers. Expert Syst. Appl. 2011, 38, 9179–9185. [Google Scholar] [CrossRef]
- Patra, K.; Mondal, S.K. Fuzzy risk analysis using area and height based similarity measure on generalized trapezoidal fuzzy numbers and its application. Appl. Soft Comput. 2015, 28, 276–284. [Google Scholar] [CrossRef]
- Cui, W.; Xu, Z. A method for fuzzy risk analysis based on the new similarity of trapezoidal fuzzy numbers. In Proceedings of the IEEE International Conference on Granular Computing, Nanchang, China, 17–19 August 2009; pp. 113–116. [Google Scholar]
- Yang, Y.; Hu, J.; Liu, Y.; Chen, X. A multi-period hybrid decision support model for medical diagnosis and treatment based on similarities and three-way decision theory. Expert Syst. 2019. [Google Scholar] [CrossRef]
- Pamucar, D.; Cirovic, G. The selection of transport and handling resources in logistics centers using multi-attributive border approximation area comparison (MABAC). Expert Syst. Appl. 2015, 42, 3016–3028. [Google Scholar] [CrossRef]
- Sun, R.; Hu, J.; Zhou, J.; Chen, X. A hesitant fuzzy linguistic projection-based MABAC method for patients’ prioritization. Int. J. Fuzzy Syst. 2018, 20, 2144–2160. [Google Scholar] [CrossRef]
- Xue, Y.X.; You, J.X.; Lai, X.D.; Liu, H.C. An interval-valued intuitionistic fuzzy MABAC approach for material selection with incomplete weight information. Appl. Soft Comput. 2016, 38, 703–713. [Google Scholar] [CrossRef]
- Peng, X.; Yang, Y. Pythagorean fuzzy choquet integral based MABAC method for multiple attribute group decision making. Int. J. Intell. Syst. 2016, 31, 989–1020. [Google Scholar] [CrossRef]
- Singh, N.; Tyagi, K. Ranking of services for reliability estimation of SOA system using fuzzy multicriteria analysis with similarity-based approach. Int. J. Syst. Assur. Eng. Manag. 2017, 8, 317–326. [Google Scholar] [CrossRef]
- Hu, Y.C. Nonadditive similarity-based single-layer perceptron for multi-criteria collaborative filtering. Neurocomputing 2014, 129, 306–314. [Google Scholar] [CrossRef]
- Greenfield, S.; Chiclana, F.; Coupland, S.; John, R. The Collapsing Method of Defuzzification for Discretised Interval Type-2 Fuzzy Sets. Inf. Sci. 2007, 179, 2055–2069. [Google Scholar] [CrossRef]
- Chen, S.M.; Yang, M.W.; Lee, L.W.; Yang, S.W. Fuzzy multiple attributes group decision-making based on ranking interval type-2 fuzzy sets. Expert Syst. Appl. Int. J. 2017, 44, 1665–1673. [Google Scholar]
- Chen, S.J.; Chen, S.M. Fuzzy risk analysis based on the ranking of generalized trapezoidal fuzzy numbers. Inf. Sci. 2007, 26, 1–11. [Google Scholar] [CrossRef]
- Gong, Y.; Hu, N.; Zhang, J.; Liu, G.; Deng, J. Multi-attribute group decision making method based on geometric Bonferroni mean operator of trapezoidal interval type-2 fuzzy numbers. Comput. Ind. Eng. 2015, 81, 167–176. [Google Scholar] [CrossRef]
- Chenabc, T.Y. The extended QUALIFLEX method for multiple criteria decision analysis based on interval type-2 fuzzy sets and applications to medical decision making. Eur. J. Oper. Res. 2013, 226, 615–625. [Google Scholar]
- Wan, S.P.; Wang, Q.Y.; Dong, J.Y. The extended VIKOR method for multi-attribute group decision making with triangular intuitionistic fuzzy numbers. Knowl. Based Syst. 2013, 52, 65–77. [Google Scholar] [CrossRef]
- Liu, P. An extended TOPSIS method for multiple attribute group decision making based on generalized interval-valued trapezoidal fuzzy numbers. J. Comput. Anal. Appl. 2011, 6, 766–776. [Google Scholar]
- Vahdani, B.; Jabbari, A.H.K.; Roshanaei, V.; Zandieh, M. Extension of the ELECTRE method for decision-making problems with interval weights and data. Int. J. Adv. Manuf. Technol. 2010, 50, 793–800. [Google Scholar] [CrossRef]
- Vahdani, B.; Hadipour, H. Extension of the ELECTRE method based on interval-valued fuzzy sets. Soft Comput. 2011, 15, 569–579. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sets | Chen (1996) [35] | Chen and Chen (2001) [36] | Chen and Chen (2007) [32] | Wei and Chen (2009) [30] | Cui and Xu (2010) [39] | Hejazi et al. (2011) [37] | Patra and Mondal (2015) [38] | The Proposed Method |
|---|---|---|---|---|---|---|---|---|
| 1 | 0.975 | 0.8357 | 0.9499 | 0.9499 | 0.9627 | 0.9004 | 0.9506 | 0.9386 |
| 2 | 0.6 | 0.3086 | 0.5846 | 0.5846 | 0.6194 | 0.5555 | 0.585 | 0.6039 |
| 3 | 0.8 | 0.5486 | 0.7794 | 0.7794 | 0.8072 | 0.7407 | 0.78 | 0.7870 |
| 4 | 0.975 | 0.1671 | 0.2859 | 0.2859 | 0.8434 | 0.0644 | 0.5021 | 0.4160 |
| 5 | 0.9 | - | 0.1583 | 0.1583 | 0.7704 | 0 | 0.36 | 0.3149 |
| 6 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 7 | 0.6 | 0.36 | 0.6 | 0.6 | 0.6211 | 0.6 | 0.6 | 0.6211 |
| 8 | 0.8 | 0.64 | 0.8 | 0.8 | 0.8126 | 0.8 | 0.8 | 0.8106 |
| 9 | 1 | 0.8 | 0.8248 | 0.8248 | 0.9652 | 0.668 | 0.88 | 0.8332 |
| 10 | 0.9 | 0.4397 | 0.3167 | 0.3167 | 0.8626 | 0.0996 | 0.54 | 0.4958 |
| 11 | 0.9 | 0.6075 | 0.7093 | 0.7093 | 0.8933 | 0.2624 | 0.684 | 0.6584 |
| 12 | 0.9 | - | 0.1920 | 0.1920 | 0.8039 | 0 | 0.378 | 0.4092 |
| 13 | 1 | - | 0.9820 | 0.9820 | 0.9983 | 0 | 0.994 | 0.8829 |
| 14 | 1 | - | 1 | 1 | 1 | - | 1 | 1 |
| 15 | 1 | 0.75 | 0.7834 | 0.7834 | 0.9702 | 0.5979 | 0.885 | 0.8467 |
| 16 | 0.8 | 0.48 | 0.6267 | 0.6267 | 0.8057 | 0.4783 | 0.708 | 0.7701 |
| 17 | 0.8 | - | 0.1760 | 0.1760 | 0.7509 | 0 | 0.432 | 0.3999 |
| 18 | 1 | - | 0.9825 | 0.9825 | 0.9985 | 0 | 0.9943 | 0.8831 |
| 19 | 0.9 | 0.76 | 0.5939 | 0.5939 | 0.9231 | 0.3653 | 0.756 | 0.7748 |
| 20 | 0.9 | - | 0 | 0 | 0.8287 | 0 | 0.486 | 0.3237 |
| 21 | 0.9 | - | 0.1920 | 0.1920 | 0.8039 | 0 | 0.468 | 0.4092 |
| 22 | 0.9 | - | 0.9 | 0.9 | 0.9053 | - | 0.9 | 0.9053 |
| 23 | 0.9 | - | 0 | 0 | 0.9276 | - | 0.9 | 0.9276 |
| 24 | 0.8 | - | - | - | 0.8106 | - | 0.8 | 0.8106 |
| 25 | 0.8 | 0.4 | 0.4 | 0.4 | 0.8 | 0.225 | 0.4 | 0.8110 |
| 26 | 1 | - | - | - | 1 | - | 1 | 1 |
| 27 | 1 | - | 0 | 0 | 0.9978 | 0 | 0.995 | 0.9928 |
| 28 | 0 | - | 0 | 0 | 0 | 0 | 0 | 0 |
| 29 | 0.7 | 0.6518 | 0.28 | 0.6222 | 0.7166 | 0.5012 | 0.63 | 0.6443 |
| 30 | 0.7 | 0.6206 | 0.28 | 0.7 | 0.7166 | 0.7 | 0.7 | 0.7158 |
| Importance | Rating | Corresponding IT2FNs |
|---|---|---|
| Absolutely low (AL) | Absolutely poor (AP) | [(0.0,0.0,0.0,0.0;1.0),(0.0,0.0,0.0,0.0;1.0)] |
| Very low (VL) | Very poor (VP) | [(0.0075,0.0075,0.015,0.0525;0.8),(0.0,0.0,0.02,0.07;1.0)] |
| Low (L) | Poor (P) | [(0.0875,0.12,0.16,0.1825;0.8),(0.04,0.10,0.18,0.23;1.0)] |
| Medium low (ML) | Medium poor (MP) | [(0.2325,0.255,0.325,0.3575;0.8),(0.17,0.22,0.36,0.42;1.0)] |
| Medium (M) | Fair (F) | [(0.4025,0.4525,0.5375,0.5675;0.8),(0.32,0.41,0.58,0.65;1.0)] |
| Medium high (MH) | Medium good (MG) | [(0.65,0.6725,0.7575,0.79;0.8),(0.58,0.63,0.80,0.86;1.0)] |
| High (H) | Good (G) | [(0.7825,0.815,0.885,0.9075;0.8),(0.72,0.78,0.92,0.97;1.0)] |
| Very high (VH) | Very good (VG) | [(0.9475,0.985,0.9925,0.9925;0.8),(0.93,0.98,1.0,1.0;1.0)] |
| Absolutely high (AH) | Absolutely good (AG) | [(1.0,1.0,1.0,1.0;1.0),(1.0,1.0,1.0,1.0;1.0)] |
| Insulin injection therapy (A1) |
| (1) A very high survival rate |
| (2) The possibility of a reactive hypoglycemia |
| (3) The possibility of an allergic shock as a complication |
| (4) About a 40% probability of a cure |
| (5) No pain/discomfort during treatment |
| (6) Health insurance covers most of the expenses, with a low out-of-pocket expense |
| (7) Do not need hospitalization |
| (8) A significantly high probability of a recurrence |
| (9) A good prognosis for the patient’s self-care ability |
| Stem cell transplant therapy (A2) |
| (1) A high survival rate |
| (2) There are no obvious side effects |
| (3) The low possibility of diabetic nephropathy and retinopathy |
| (4) A very high probability of a cure |
| (5) There is some pain/discomfort during treatment |
| (6) Health insurance covers some of the expenses, with a moderately higher out-of-pocket expense |
| (7) A moderate hospitalization |
| (8) A low probability of a recurrence |
| (9) A moderate prognosis for the patient’s self-care capacity |
| Gastric bypass surgery (A3) |
| (1) A high survival rate |
| (2) The possibility of a stomach paralysis |
| (3) The possibility of a ketoacidosis or hypertonic coma |
| (4) A high probability of a cure |
| (5) There is some pain/discomfort during treatment |
| (6) Low coverage by the patient’s health insurance and very high out-of-pocket expenses |
| (7) A slightly shorter hospitalization than A2 |
| (8) A low probability of a recurrence |
| (9) A moderate prognosis for the patient’s self-care capacity |
| Criteria | Importance Weights | Treatment Options | ||
|---|---|---|---|---|
| A1 | A2 | A3 | ||
| C1 (survival rate) | AH | VG | G | G |
| C2 (severity of the side effects) | L | F | G | F |
| C3 (severity of the complications) | ML | P | MG | P |
| C4 (probability of a cure) | AH | MP | VG | G |
| C5 (discomfort index of the treatment) | VL | VG | P | P |
| C6 (cost) | M | G | MP | AP |
| C7 (number of days of hospitalization) | VH | AG | MP | F |
| C8 (probability of a recurrence) | H | AP | G | G |
| C9 (self-care capacity) | MH | G | F | F |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|---|---|
| A1 | 0.1778 | 0.0529 | 0 | 0.6465 | 0.0158 | 0.3658 | 0 | 0.6526 | 0.2317 |
| A2 | 0 | 0.0073 | 0.1339 | 0 | 0 | 0.1069 | 0.2099 | 0 | 0 |
| A3 | 0 | 0.0362 | 0 | 0.1178 | 0.0158 | 0 | 0.4122 | 0 | 0 |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | |
|---|---|---|---|---|---|---|---|---|---|
| A1 | 0 | 0.0287 | 0.1339 | 0 | 0 | 0 | 0.4122 | 0 | 0 |
| A2 | 0.1178 | 0.0604 | 0 | 0.6465 | 0.0158 | 0.2589 | 0.2023 | 0.6526 | 0.2317 |
| A3 | 0.1778 | 0.0406 | 0.1339 | 0.5287 | 0.0002 | 0.3658 | 0 | 0.6526 | 0.2317 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, J.; Chen, P.; Yang, Y. An Interval Type-2 Fuzzy Similarity-Based MABAC Approach for Patient-Centered Care. Mathematics 2019, 7, 140. https://doi.org/10.3390/math7020140
Hu J, Chen P, Yang Y. An Interval Type-2 Fuzzy Similarity-Based MABAC Approach for Patient-Centered Care. Mathematics. 2019; 7(2):140. https://doi.org/10.3390/math7020140
Chicago/Turabian StyleHu, Junhua, Panpan Chen, and Yan Yang. 2019. "An Interval Type-2 Fuzzy Similarity-Based MABAC Approach for Patient-Centered Care" Mathematics 7, no. 2: 140. https://doi.org/10.3390/math7020140
APA StyleHu, J., Chen, P., & Yang, Y. (2019). An Interval Type-2 Fuzzy Similarity-Based MABAC Approach for Patient-Centered Care. Mathematics, 7(2), 140. https://doi.org/10.3390/math7020140