Abstract
In this paper, three-step Taylor expansion, which is equivalent to third-order Taylor expansion, is used as a mathematical base of the new descent method. At each iteration of this method, three steps are performed. Each step has a similar structure to the steepest descent method, except that the generalized search direction, step length, and next iterative point are applied. Compared with the steepest descent method, it is shown that the proposed algorithm has higher convergence speed and lower computational cost and storage.
1. Introduction
We start our discussion by considering the unconstrained minimization problem:
where f is an n-dimensional continuously differentiable function.
Most effective optimization procedures include some basic steps. At iteration k, where the current is , they do the following:
- 1.
- Specify the initial starting vector ,
- 2.
- Find an appropriate search direction ,
- 3.
- Specify the convergence criteria for termination,
- 4.
- Minimize along the direction to find a new point from the following equation
where is a positive scalar called the step size. The step size is usually determined by an optimization process called a line search (usually inexactly) such as Wolfe-line search, Goldstein-line search or Armijo-line search
where is a constant control parameter. For more information on the line search strategy, readers can refer to [1,2,3,4,5,6,7]. In addition, some researchers have introduced suitable algorithms which defined without a line search method that can be seen in the literature [8,9,10]. Appropriate choices for an initial starting point have a positive effect on computational cost and speed of convergence.
The numerical optimization of general multivariable objective functions differs mainly in how they generate the search directions. A good search direction should reduce the objective function’s value so that
Such a direction is a descent direction and satisfies the following requirement at any point
where the dot indicates the inner product of two vectors and .
The choice of search direction is typically based on some approximate model of the objective function f which is obtained by the Taylor series [11]
where and are replaced with and , respectively.
For instance, a linear approximation (first order Taylor expansion) of the objective function
can be used which concludes the following direction
This is referred to as the steepest descent method [4]. The overall results on the convergence of the steepest descent method can be found in [4,12,13]. More practical applications of the steepest descent method are discussed in [10,14,15,16].
Unlike gradient methods which use first order Taylor expansion, Newton method uses a second order Taylor expansion of the function about the current design point; i.e., a quadratic model
which yields Newton direction
Although the Newton method is below the quadratic rate of convergence, it requires the computation and storage of some matrices associated with the Hessian of the objective function. Moreover, the Newton method can only be utilized if the Hessian matrix is positive definite [4].
The purpose of this paper is to provide a descent algorithm which can exploit more information about the objective function without the need to store large matrices such as the Hessian matrix. In order to construct a desired model of the objective function, we propose a three-step discretization method based on three-step Taylor expansion that is used in [17,18,19] as follows
Hence, using these steps of Formula (5) in the approximation of a function around gives a third-order accuracy with .
On the other hand, we can say that these steps of Formula (5) are derived by applying a factorization process to the right side of Equation (6) as follows
where the symbol is the identity operator. Now, by removing the terms appearing in and using the Taylor series properties, the first internal bracket in Equation (7) shows , the second internal bracket shows and the last one shows .
Jiang and Kawahara [17] are the pioneers who used this formula to solve unsteady incompressible flows governed by the Navier-Stokes equations. In their method, the discretization in time is performed before the spatial approximation by means of Formula (5) with respect to the time. In comparison with the Equation (6), Formula (5) does not contain any new higher-order derivatives. Moreover, it reduces the demand of smoothness of the function, gives the superior approximation of the function and presents some stability advantages in multidimensional problems [17]. The Formula (5) is useful in solving non-linear partial differential equations, hyperbolic problems, multi-dimensional and coupled equations.
In this article, we utilize Formula (5) to obtain a descent direction that satisfies the inequality of Equation (3) and then modify the Armijo-rule in the line search method to achieve an appropriate step size. Finally, Equation (1) is utilized to obtain a sequence that reduces the value of the function. Since all equations of the three-step discretization process involve only the first order derivative of the function, the proposed method is a member of gradient methods such as the steepest descent method. However, numerical results demonstrate that the current method works better than the steepest descent method.
The organization of the paper is as follows. In Section 2, there is a brief review of the gradient-type algorithms and their applications. In Section 3, the three-step discretization algorithm and its fundamental properties are described. In Section 4, we show how the proposed algorithm converges globally. Some noteworthy numerical examples are presented in Section 5. Finally, Section 6 provides conclusions of the study.
2. Related Work
This section provides an overview of previous research on the gradient-type methods.
2.1. Steepest Descent Method
Gradient descent is among the most popular algorithms to perform optimization. The steepest descent method, which can be traced back to Cauchy in 1847 [20], has a rich history and is regarded as the simplest and best-known gradient method. Despite its simplicity, the steepest descent method has played a major role in the development of the theory of optimization. Unfortunately, the classical steepest descent method which uses the exact line search procedure in determining the step size is known for being quite slow in most real-world problems and is therefore not widely used. Recently, several modifications to the steepest descent method have been presented to overcome its weakness. Mostly, these modifications propose effective trends in choosing the step length. Barzilai and Borwein (BB method) [21] presented a new choice of step length through the two-point step size
where and .
Although their method did not guarantee the monotonic descent of the residual norms, the BB method was capable of performing quite well for high dimensional problems. The results of Barzilai and Borwein have encouraged many researchers to modify the steepest descent method. For instance, Dai and Fletcher in 2005 [22] used a new gradient projection method for box-constrained quadratic problems with the step length
where and is some prefixed integer.
Hassan et al. in 2009 [23] were motivated by the BB method and presented a Monotone gradient method via the Quasi-Cauchy relation. They discover a step length formula that approximates the inverse of Hessian using the Quasi-Cauchy equation which retains the monotonic property for every repetition. Leong et al. in 2010 [24] suggested a fixed step gradient type method to improve the BB method and it is recognized as the Monotone gradient method via the weak secant equation. In the Leong method, the approximation is stored using a diagonal matrix depending on the modified weak secant equation. Recently, Tan et al. in 2016 [25] applied the Barzilai and Borwein step length to the stochastic gradient descent and stochastic variance gradient algorithms.
Plenty of attention has also been paid to the theoretical properties of the BB method. Barzilai and Borwein [21] proved that the BB method has an R-superlinear convergence when the dimension is just two. For the general n-dimensional strong convex quadratic function, this method is also convergent and the convergence rate is R-linear [26,27]. Recently, Dai [28] presented a novel analysis of the BB method for two-dimensional strictly convex quadratic functions and showed that there is a superlinear convergence step in at most three consecutive steps.
Another modification method that implemented the choice of an efficient step length was proposed by Yuan [29]. He has suggested a new step size for the steepest descent method. The desired formula for the new was obtained through an analysis of two-dimensional problems. In his proposed algorithm, this new step size was used in even iterations and the exact line search was used in odd iterations. Unlike the BB method, Yuan’s method possesses the monotonic property. For a constant k Yuan’s step size is defined as follows
where and are computed through the exact line search.
In addition to these mentioned modification algorithms, there is various literature which used different improvement style for the steepest descent method. For example, Manton [30] derived algorithms which minimize a cost function with the constraint condition by reducing the dimension of the optimization problem by reformulating the optimization problem as an unconstrained one on the Grassmann manifold. Zhou and Feng [10] proposed the steepest descent algorithm without the line search for the p-Laplacian problem. In their method, the search direction is the weighted preconditioned steepest descent one, and, with the exception of the first iteration, the step length is measured by a formula.
2.2. Newton Method
The steepest descent method lacks second derivative information, causing inaccuracy. Thus, some researchers have used a more effective method which is identified as the Newton method. Newton’s work was done in the year 1669, but it was published a few years later. For each iteration of the Newton method, we will need to compute the second derivative called the Hessian of a given function. It is difficult to calculate Hessian manually, especially when differentiation gets complicated. This will need a lot of computing effort and, in some cases, the second derivation cannot be computed analytically. Even for some simpler differentiation, it may be time-consuming. In addition, considerable storage space is needed to store the computed Hessian and this is computationally expensive. For example, if we have a Hessian with n dimensions, we will have storage space to store the Hessian [31].
2.3. Conjugate Gradient Methods
Another gradient descent method is the conjugate gradient method. The conjugate gradient method has been considered an effective numerical method for solving large-scale unconstrained optimization problems because it does not need the storage of any matrices. The search direction of the conjugate gradient method is defined by
where is a parameter which characterizes the conjugate gradient method. There are many articles on how to get . The Hestenes-Stiefel (HS) [32] and Fletcher-Reeves (FR) [33] are well-known formulas for obtaining this parameter which is respectively given by
The global convergence properties of these methods have been shown in many research papers; for example, [34]. The classical conjugate gradient methods only include the first derivative of the function. In this decade, in order to incorporate the second-order information about the objective function into conjugate gradient methods, many researchers have proposed conjugate gradient methods based on secant conditions. Dai and Liao [35] proposed a conjugate gradient method based on the secant condition and proved its global convergence property. Kobayashi et al. [36] proposed conjugate gradient methods based on structured secant conditions for solving nonlinear least squares problems. Although numerical experiments of the previous research show the effectiveness of these methods for solving large-scale unconstrained optimization problems, these methods do not necessarily satisfy the descent condition. In order to overcome this deficiency, various authors present modifications of the conjugate gradient methods. For example, Zhang et al. [37] presented a modification to the FR method such that the direction generated by the modified method provides a descent direction. Sugiki et al. [38] proposed three-term conjugate gradient methods based on the secant conditions which always satisfy the sufficient descent condition.
3. New Descent Algorithm
In this section, we show how equations in Formula (5) can be used to propose the three-step discretization method and give its pseudo-code. The following regularity of is assumed in the following:
Assumption 1.
We assume with Lipschitz continuous gradient, i.e., there exists such that
The substitution for in Formula (5) yields:
3.1. Three-Step Discretization Algorithm
Three steps are performed throughout this algorithm. Actually, in the steepest descent method, there is not an intermediate step between the computation of and . However, in the proposed method, we impose an intermediate step between and . In other words, is computed from the first step and is computed from the third step. The second step is an intermediate step that uses as the starting point and produces the new point such as . The forms the starting point for the last step which results in . The structure of the proposed algorithm is characterized as follows.
The main goal of this algorithm is that the value of the objective function declines during all three steps. If the same direction is applied to all three steps, it will be a non-descent direction in at least one of the steps. Therefore, we need to consider each of the steps separately. Moreover, if the point is employed in the first step of Formula (8), the point will be achieved by the third step of Formula (8).
To determine which step of Formula (8) is performing, we use the super-index j. At each upgrading index k, the index j adopts only values , and , respectively. During the kth iteration of the main algorithm, directions , , and are used in the first, second and third step, respectively. The points , , and are used as starting points in the first, second and third step, respectively. The proper steps size , , and are obtained from the first, second and last step, respectively. Details are explained as follows.
The first step of Formula (8) can be rewritten in the following form
The direction should be chosen in such a way that provides the greatest reduction in so that
Hence, the direction of the first step is calculated similarly to the process of finding steepest descent direction [4]. So, in the first step of Formula (8), we choose
Next, we must determine a proper step size for the first step. In this article, to find the step size, we use the backtracking algorithm with an Armijo-line search. Considering the first step of Formula (8), the general Armijo condition of Equation (2) can be modified as follows
Therefore, the implementation of the backtracking algorithm with Equation (9) provides the proper step size, , and the following point
We use as a starting point for the second step of Formula (8).
We can rewrite the second step as follows:
Now the direction should satisfy the descent requirement of Equation (3) at the point, , i.e.,
By using a similar analysis for finding the steepest descent direction and using Equation (10) we have
After determining the direction , we should find a proper step size. In the second step, we modify general Armijo condition of Equation (2) as follows
We use Equation (12) in the backtracking algorithm to find the proper step size, , and the following point
We use the point as a starting point in the last step of Formula (8).
Now, we have the following result in the third step
where the Equation (11) gives . The direction is obtained from
Also, according to the last step of Formula (8), the last step of the presented algorithm uses the general Armijo condition of Equation (2). With replacement and we have
Utilization of the Equation (14) in the backtracking algorithm gives the proper step size, , and the following point
After obtaining , we go back to the first step of Formula (8). In fact, forms a starting point in the first step of Formula (8), i.e.,
This process will continue until the stop condition is attained.
The ensuing result is achieved by considering the fact that each step in the presented method deals with a descent direction.
Therefore, implementation of this method concludes that .
The pseudo-code of the three-step discretization method with backtracking Armijo line-search is provided in the Algorithm 1.
| Algorithm 1 Pseudo-code of the three-step discretization method |
 |
3.2. Theoretical Analysis of the Three-Step Discretization Algorithm
As mentioned above, the steepest descent method uses only the gradient of the function and the Newton method uses the second order derivatives of the objective function. In this section, we explain about the objective function information included in the proposed algorithm.
Let
After implementation of the three-step discretization algorithm at and using Equations (10) and (13), the following form of Formula (8) will be obtained
Now consider the third order Taylor series expansion of at , i.e.,
According to the first equation of Formula (17), we have
Now if we take the gradient of the Equation (20), the following equation is achieved.
A comparison between Equations (18) and (22) implies that in terms of Taylor expansion, which includes second order derivatives, Equation (22) does not consist of the following statement
and in terms of Taylor expansion, which includes third order derivatives, the Equation (22) only includes
The above analysis concludes that the three-step discretization algorithm includes information about the value of the objective function, gradient of the function, second order and third order derivatives of the objective function. However, it does not contain all the information of the second and third order derivatives of the objective function.
4. Convergence
In this section, we prove the convergence of this method. The following theorem shows that the modified Armijo-line search at the first step of Formula (8) stops after a finite number of steps.
Theorem 1.
Suppose that the function f satisfies in Assumption 1 and let be a descent direction at . Then, for fixed
- (i)
- the modified Armijo conditionis satisfied for all , where
- (ii)
- for fixed the step size generated by the backtracking algorithm with modified Armijo condition (9) terminates with
Proof of Theorem 1.
First, we prove the first part of the theorem. Since is a Lipschitz continuous function and according to Taylor expansion:
where .
To prove the second part we use to show , i.e.,
Now, we know from the first part that the modified Armijo-line search will stop as soon as . If satisfies Equation (9) then . Otherwise, in the last line search iteration, we have:
The combination of these two cases will present the main result. ☐
There is a similar analysis of Theorem 1 which says that the backtracking algorithm with modified Armijo-line search in the second and third step of Formula (8) ends in a finite number of steps.
Theorem 2.
Let the function f satisfy Assumption 1 and be a descent direction at . Then, for fixed
- (i)
- the modified Armijo conditionis satisfied for all , where
- (ii)
- for fixed the step size generated by the backtracking algorithm with modified Armijo condition of Equation (12) terminates with
Proof of Theorem 2.
The proof process is similar to the Theorem 1. ☐
Theorem 3.
Let the function f satisfy Assumption 1 and be a descent direction at . Then, for fixed
- (i)
- the Armijo conditionis satisfied for all , where
- (ii)
- for fixed the step size generated by the backtracking algorithm with Armijo condition of Equation (14) terminates with
Proof of Theorem 3.
Proof process is similar to the Theorem 1. ☐
Theorem 4.
(Global convergence of the three-step discretization algorithm)
Suppose that the function f satisfies Assumption 1 and is a descent direction at for . Then, for the iterates generated by the three-step discretization algorithm, one of the following situations occurs,
- (i)
- , for some and ,
- (ii)
- ,,
- (iii)
- ,.
Proof of Theorem 4.
Assume (i) and (ii) are not satisfied, then the third case should be proved.
At first, according to Equations (10), (13), (15) and (16) and by considering modified Armijo conditions we have
where and for are obtained through the backtracking algorithm with modified Armijo conditions in the first, second and third step of Formula (8), respectively. Since is a descent direction at , is a descent direction at and is a descent direction at for , from Equations (3) and (24) we have
and then
According to Theorems 1–3, backtracking algorithm with modified Armijo conditions terminates with
Let . If
then from the Theorem 1 we have
and
Thus, from the Equation (25) it follows
Since , the following equation is achieved.
In another case, if
according to Theorem 1 we have
The following equation is obtained by replacement with in the Equation (26).
There is a similar analysis for and . Generally, we obtain
Finally, the Equation (27) is equivalent to
☐
In the Theorem 4, in the first case, a stationary point is found during a finite number of steps. In the second case, the function is unbounded below and a minimum does not exist. In the third case, then for , which means the implementation of all three steps in the three-step discretization method get closer to the stationary point.
5. Numerical Experiments
In this section, we consider some numerical results for the three-step discretization method. We use MATLAB 2016 (R2016b, MathWorks, Natick, MA, USA). The stopping rule for the Algorithm 1 is designed to decrease the gradient norm to . Parameters c and are fixed and , respectively. We set up the parameter throughout the entire algorithm. The numerical comparisons include:
- Iterative numbers (denote by NI) for attaining the same stopping criterion .
- Evaluation numbers of f (denote by Nf)
- Evaluation numbers of (denote by Ng)
- Difference between the value of the function at the optimal point and the value of the function at the last calculated point as the accuracy of the method; i.e., .

Table 1.
Test problems of general objective functions.
In Table 1 is the following function:
where the optimal solution is and [41] . Also, , and are the test functions 28, 33 and 34 in the [42], respectively.
The numerical results of some of the functions in the Table 1 are reported in the following tables. Table 2 shows iterative numbers (NI), Table 3 compares the Nf, Table 4 compares the Ng and Table 5 presents the error. We compare our method with the steepest descent method, the FR method and the conjugate gradient method in [37] which we refer to as the Zhang method. The letter “F” in the tables shows that the corresponding method did not succeed in approaching the optimal point. The FR method has the most failure modes since it did not produce a descent direction. In comparison with the steepest descent method, the proposed method has fewer iterations and fewer function and gradient evaluations. Also, the proposed method shows good agreement with the conjugate gradient method in [37].
Table 2.
Iteration numbers (NI) for different methods.
Table 3.
The number of function evaluations (Nf) for different methods.
Table 4.
The number of gradient evaluations (Ng) for different methods.
Table 5.
Accuracy (error) for different methods.
Also, we use the performance profiles in [43] to compare the performance of the considered methods. If the performance profile of a method is higher than the performance profiles of the other methods, then this method performed better than the other methods.
Figure 1a,b and Figure 2a,b show the performance profiles measured in accordance with CPU time, NI, Nf and Ng, respectively. From the viewpoint of CPU time and the number of iterations (NI), we observe in Figure 1 that the three-step discretization method is successful. The proposed method works better than the steepest descent method. Although the FR method is rapid and accurate, it has not led to descent direction in many cases. Therefore, the graph of FR method placed lower than the graph of the steepest descent method for .
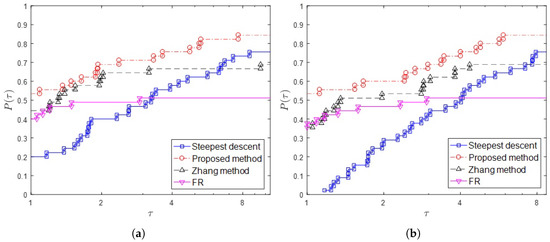
Figure 1.
Performance profiles based on CPU time (a) and the number of iterations (NI) (b) for 45 functions in the Table 1.
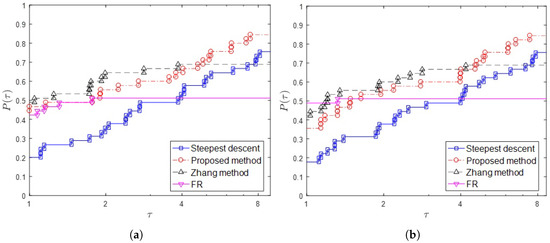
Figure 2.
Performance profiles based on the number of function evaluations (Nf) (a) and the number of gradient evaluations (Ng) (b) for 45 functions in the Table 1.
From the viewpoint of the number of function evaluations (Nf) and the number of gradient evaluations (Ng), Figure 2 shows that the Zhang method needs fewer computational costs. In this figure the proposed method almost comparable with the Zhang method. Also, for the proposed method is superior to other methods.
6. Conclusions
Based on three-step Taylor expansion and Armijo-line search, we propose the three-step discretization algorithm for unconstrained optimization problems. The presented method uses some information of the objective function which exists in the third-order Taylor series while there is no requirement to calculate higher order derivatives. The global convergence of the proposed algorithm is proved. Some numerical experiments are conducted on the proposed algorithm. In comparison with the steepest descent method, the numerical performance of the proposed method is superior.
Author Contributions
All authors contributed significantly to the study and preparation of the article. They have read and approved the final manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ahookhosh, M.; Ghaderi, S. On efficiency of nonmonotone Armijo-type line searches. Appl. Math. Model. 2017, 43, 170–190. [Google Scholar] [CrossRef]
- Andrei, N. A new three-term conjugate gradient algorithm for unconstrained optimization. Numer. Algorithms 2015, 68, 305–321. [Google Scholar] [CrossRef]
- Edgar, T.F.; Himmelblau, D.M.; Lasdon, L.S. Optimization of Chemical Processes; McGraw-Hill: New York, NY, USA, 2001. [Google Scholar]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer Verlag: New York, NY, USA, 2006. [Google Scholar]
- Shi, Z.J. Convergence of line search methods for unconstrained optimization. Appl. Math. Comput. 2004, 157, 393–405. [Google Scholar] [CrossRef]
- Vieira, D.A.G.; Lisboa, A.C. Line search methods with guaranteed asymptotical convergence to an improving local optimum of multimodal functions. Eur. J. Oper. Res. 2014, 235, 38–46. [Google Scholar] [CrossRef]
- Yuan, G.; Wei, Z.; Lu, X. Global convergence of BFGS and PRP methods under a modified weak Wolfe-Powell line search. Appl. Math. Model. 2017, 47, 811–825. [Google Scholar] [CrossRef]
- Wang, J.; Zhu, D. Derivative-free restrictively preconditioned conjugate gradient path method without line search technique for solving linear equality constrained optimization. Comput. Math. Appl. 2017, 73, 277–293. [Google Scholar] [CrossRef]
- Zhou, G. A descent algorithm without line search for unconstrained optimization. Appl. Math. Comput. 2009, 215, 2528–2533. [Google Scholar] [CrossRef]
- Zhou, G.; Feng, C. The steepest descent algorithm without line search for p-Laplacian. Appl. Math. Comput. 2013, 224, 36–45. [Google Scholar] [CrossRef]
- Koks, D. Explorations in Mathematical Physics: The Concepts Behind an Elegant Language; Springer Science: New York, NY, USA, 2006. [Google Scholar]
- Dennis, J.E., Jr.; Schnabel, R.B. Numerical Methods for Unconstrained Optimization and Nonlinear Equations; SIAM: Philadelphia, PA, USA, 1996. [Google Scholar]
- Otmar, S. A convergence analysis of a method of steepest descent and a two-step algorothm for nonlinear ill–posed problems. Numer. Funct. Anal. Optim. 1996, 17, 197–214. [Google Scholar] [CrossRef]
- Ebadi, M.J.; Hosseini, A.; Hosseini, M.M. A projection type steepest descent neural network for solving a class of nonsmooth optimization problems. Neurocomputing 2017, 193, 197–202. [Google Scholar] [CrossRef]
- Yousefpour, R. Combination of steepest descent and BFGS methods for nonconvex nonsmooth optimization. Numer. Algorithms 2016, 72, 57–90. [Google Scholar] [CrossRef]
- Gonzaga, C.C.; Schneider, R.M. On the steepest descent algorithm for quadratic functions. Comput. Optim. Appl. 2016, 63, 523–542. [Google Scholar] [CrossRef]
- Jiang, C.B.; Kawahara, M. A three-step finite element method for unsteady incompressible flows. Comput. Mech. 1993, 11, 355–370. [Google Scholar] [CrossRef]
- Kumar, B.V.R.; Kumar, S. Convergence of Three-Step Taylor Galerkin finite element scheme based monotone schwarz iterative method for singularly perturbed differential-difference equation. Numer. Funct. Anal. Optim. 2015, 36, 1029–1045. [Google Scholar]
- Kumar, B.V.R.; Mehra, M. A three-step wavelet Galerkin method for parabolic and hyperbolic partial differential equations. Int. J. Comput. Math. 2006, 83, 143–157. [Google Scholar] [CrossRef]
- Cauchy, A. General method for solving simultaneous equations systems. Comp. Rend. Sci. 1847, 25, 46–89. [Google Scholar]
- Barzilai, J.; Borwein, J.M. Two-point step size gradient methods. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Dai, Y.H.; Fletcher, R. Projected Barzilai-Borwein methods for large-scale box-constrained quadratic programming. Numer. Math. 2005, 100, 21–47. [Google Scholar]
- Hassan, M.A.; Leong, W.J.; Farid, M. A new gradient method via quasicauchy relation which guarantees descent. J. Comput. Appl. Math. 2009, 230, 300–305. [Google Scholar] [CrossRef]
- Leong, W.J.; Hassan, M.A.; Farid, M. A monotone gradient method via weak secant equation for unconstrained optimization. Taiwan. J. Math. 2010, 14, 413–423. [Google Scholar] [CrossRef]
- Tan, C.; Ma, S.; Dai, Y.; Qian, Y. Barzilai-Borwein step size for stochastic gradient descent. In Proceedings of the 30th Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Raydan, M. On the Barzilai and Borwein choice of steplength for the gradient method. IMA J. Numer. Anal. 1993, 13, 321–326. [Google Scholar] [CrossRef]
- Dai, Y.H.; Liao, L.Z. R-linear convergence of the Barzilai and Borwein gradient method. IMA J. Numer. Anal. 2002, 26, 1–10. [Google Scholar] [CrossRef]
- Dai, Y.H. A New Analysis on the Barzilai-Borwein Gradient Method. J. Oper. Res. Soc. China 2013, 1, 187–198. [Google Scholar] [CrossRef]
- Yuan, Y. A new stepsize for the steepest descent method. J. Comput. Appl. Math. 2006, 24, 149–156. [Google Scholar]
- Manton, J.M. Modified steepest descent and Newton algorithms for orthogonally constrained optimisation: Part II The complex Grassmann manifold. In Proceedings of the Sixth International Symposium on Signal Processing and its Applications (ISSPA), Kuala Lumpur, Malaysia, 13–16 August 2001. [Google Scholar]
- Shan, G.H. Gradient-Type Methods for Unconstrained Optimization. Bachelor’s Thesis, University Tunku Abdul Rahman, Petaling Jaya, Malaysia, 2016. [Google Scholar]
- Hestenes, M.R.; Stiefel, M. Methods of conjugate gradients for solving linear systems. J. Res. Natl. Bur. Stand. 1952, 49, 409–436. [Google Scholar] [CrossRef]
- Fletcher, R.; Reeves, C.M. Function minimization by conjugate gradients. Comput. J. 1964, 7, 149–154. [Google Scholar] [CrossRef]
- Hager, W.W.; Zhang, H. A survey of nonlinear conjugate gradient methods. Pac. J. Optim. 2006, 2, 35–58. [Google Scholar]
- Dai, Y.H.; Liao, L.Z. New conjugacy conditions and related nonlinear conjugate gradient methods. Appl. Math. Optim. 2001, 43, 87–101. [Google Scholar] [CrossRef]
- Kobayashi, M.; Narushima, M.; Yabe, H. Nonlinear conjugate gradient methods with structured secant condition for nonlinear least squares problems. J. Comput. Appl. Math. 2010, 234, 375–397. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.; Li, D. Global convergence of a modified Fletcher-Reeves conjugate gradient method with Armijo-type line search. Numer. Math. 2006, 104, 561–572. [Google Scholar] [CrossRef]
- Sugiki, K.; Narushima, Y.; Yabe, H. Globally convergent three-term conjugate gradient methods that use secant conditions and generate descent search directions for unconstrained optimization. J. Optim. Theory Appl. 2012, 153, 733–757. [Google Scholar] [CrossRef]
- Jamil, M.; Yang, X.S. A literature survey of benchmark functions for global optimization problems. Int. J. Math. Model. Numer. Optim. 2013, 4, 150–194. [Google Scholar]
- Molga, M.; Smutnicki, C. Test Functions for Optimization Needs, 2005. Available online: http://www.robertmarks.org/Classes/ENGR5358/Papers/functions.pdf (accessed on 30 June 2013).
- Papa Quiroz, E.A.; Quispe, E.M.; Oliveira, P.R. Steepest descent method with a generalized Armijo search for quasiconvex functions on Riemannian manifolds. J. Math. Anal. Appl. 2008, 341, 467–477. [Google Scholar] [CrossRef]
- Moré, J.J.; Garbow, B.S.; Hillstrome, K.E. Testing unconstrained optimization software. ACM Trans. Math. Softw. 1981, 7, 17–41. [Google Scholar]
- Dolan, E.D.; Moré, J.J. Benchmarking optimization software with performance profiles. Math. Program. Ser. A 2002, 91, 201–213. [Google Scholar]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).