1. Introduction
Over the past decades, the use of sensor networks has experienced a fast development encouraged by the wide range of potential applications in many areas, since they usually provide more information than traditional single-sensor communication systems. So, important advances have been achieved concerning the estimation problem in networked stochastic systems and the design of multisensor fusion techniques [
1]. Many of the existing fusion estimation algorithms are related to conventional systems (see e.g., [
2,
3,
4,
5], and the references therein), where the sensor measured outputs are affected only by additive noises and each sensor transmits its outputs to the fusion center over perfect connections.
However, in a network context, usually the restrictions of the physical equipment or the uncertainties in the external environment, inevitably cause problems in both the sensor outputs and the transmission of such outputs, that can worsen dramatically the quality of the fusion estimators designed without considering these drawbacks [
6]. Multiplicative noise uncertainties and missing measurements are some of the random phenomena that usually arise in the sensor measured outputs and motivate the design of new estimation algorithms (see e.g., [
7,
8,
9,
10,
11], and references therein).
Furthermore, when the sensors send their measurements to the processing center via a communication network some additional network-induced phenomena, such as random delays or measurement losses, inevitably arise during this transmission process, which can spoil the fusion estimators performance and motivate the design of fusion estimation algorithms for systems with one (or even several) of the aforementioned uncertainties (see e.g., [
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24], and references therein). All the above cited papers on signal estimation with random transmission delays assume independent random delays at each sensor and mutually independent delays between the different sensors; in [
25] this restriction was weakened and random delays featuring correlation at consecutive sampling times were considered, thus allowing to deal with some common practical situations (e.g., those in which two consecutive observations cannot be delayed).
It should be also noted that, in many real-world problems, the measurement noises are usually correlated; this occurs, for example, when all the sensors operate in the same noisy environment or when the sensor noises are state-dependent. For this reason, the fairly conservative assumption that the measurement noises are uncorrelated is commonly weakened in many of the aforementioned research papers on signal estimation. Namely, the optimal Kalman filtering fusion problem in systems with noise cross-correlation at consecutive sampling times is addressed, for example, in [
19]; also, under different types of noise correlation, centralized and distributed fusion algorithms for systems with multiplicative noise are obtained in [
11,
20], and for systems where the measurements might have partial information about the signal in [
7].
In this paper, covariance information is used to address the distributed and centralized fusion estimation problems for a class of linear networked stochastic systems with multiplicative noises and missing measurements in the sensor measured outputs, subject to transmission random one-step delays. It is assumed that the sensor measurement additive noises are one-step autocorrelated and cross-correlated, and the Bernoulli variables describing the measurement delays at the different sensors are correlated at the same and consecutive sampling times. As in [
25], correlated random delays in the transmission are assumed to exist, with different delay rates at each sensor; however, the proposed observation model is more general than that considered in [
25] since, besides the random delays in the transmission, multiplicative noises and missing phenomena in the measured outputs are considered; also cross-correlation between the different sensor additive noises is taken into account. Unlike [
7,
8,
9,
10,
11] where multiplicative noise uncertainties and/or missing measurements are considered in the sensor measured outputs, in this paper random delays in the transmission are also assumed to exist. Hence, a unified framework is provided for dealing simultaneously with missing measurements and uncertainties caused by multiplicative noises, along with random delays in the transmission and, hence, the proposed fusion estimators have wide applicability. Recursive algorithms for the optimal linear distributed and centralized filters under the least-squares (LS) criterion are derived by an innovation approach. Firstly, local estimators based on the measurements received from each sensor are obtained and then the distributed fusion filter is generated as the LS matrix-weighted linear combination of the local estimators. Also, a recursive algorithm for the optimal linear centralized filter is proposed. Finally, it is important to note that, even though the state augmentation method has been largely used in the literature to deal with the measurement delays, such method leads to a significant rise of the computational burden, due to the increase of the state dimension. In contrast to such approach, the fusion estimators proposed in the current paper are obtained without needing the state augmentation; so, the dimension of the designed estimators is the same as that of the original state, thus reducing the computational cost compared with the existing algorithms based on the augmentation method.
The rest of the paper is organized as follows. The multisensor measured output model with multiplicative noises and missing measurements, along with the transmission random one-step delay model, are presented in
Section 2. The distributed fusion estimation algorithm is derived in
Section 3, and a recursive algorithm for the centralized LS linear filtering estimator is proposed in
Section 4. The effectiveness of the proposed estimation algorithms is analyzed in
Section 5 by a simulation example and some conclusions are drawn in
Section 6.
Notation: The notation throughout the paper is standard. and denote the n-dimensional Euclidean space and the set of all real matrices, respectively. For a matrix A, the symbols and denote its transpose and inverse, respectively; the notation represents the Kronecker product of the matrices . If the dimensions of vectors or matrices are not explicitly stated, they are assumed to be compatible with algebraic operations. In particular, I denotes the identity matrix of appropriate dimensions. The notation indicates the minimum value of two real numbers . For any function , depending on the time instants k and s, we will write for simplicity; analogously, will be written for any function , depending on the sensors i and j. Moreover, for an arbitrary random vector , we will use the notation , where is the mathematical expectation operator. Finally, denotes the Kronecker delta function.
2. Problem Formulation and Model Description
This paper is concerned with the LS linear filtering estimation problem of discrete-time stochastic signals from randomly delayed observations coming from networked sensors using the distributed and centralized fusion methods. The signal measurements at the different sensors are affected by multiplicative and additive noises, and the additive sensor noises are assumed to be correlated and cross-correlated at the same and consecutive sampling times. Each sensor output is transmitted to a local processor over imperfect network connections and, due to network congestion or some other causes, random one-step delays may occur during this transmission process; in order to model different delay rates in the transmission from each sensor to the local processor, different sequences of correlated Bernoulli random variables with known probability distributions are used.
In the distributed fusion method, each local processor produces the LS linear filter based on the measurements received from the sensor itself; afterwards, these local estimators are transmitted to the fusion center over perfect connections, and the distributed fusion filter is generated by a matrix-weighted linear combination of the local LS linear filtering estimators using the mean squared error as optimality criterion. In the centralized fusion method, all measurement data of the local processors are transmitted to the fusion center, also over perfect connections, and the LS linear filter based on all the measurements received is obtained by a recursive algorithm.
Next, we present the observation model and the hypotheses on the signal and noise processes necessary to address the estimation problem.
2.1. Signal Process
The distributed and centralized fusion filtering estimators will be obtained under the assumption that the evolution model of the signal to be estimated is unknown and only information about its mean and covariance functions is available; specifically, the following hypothesis is required:
Hypothesis 1. The -dimensional signal process has zero mean and its autocovariance function is expressed in a separable form, where are known matrices.
Note that, when the system matrix
in the state-space model of a stationary signal is available, the signal autocovariance function is
and Hypothesis 1 is clearly satisfied taking, for example,
and
. Similarly, if
, the covariance function can be expressed as
where
, and Hypothesis 1 is also satisfied taking
and
. Furthermore, Hypothesis 1 covers even situations where the system matrix in the state-space model is singular, although a different factorization must be used in those cases (see e.g., [
21]). Hence, Hypothesis 1 on the signal autocovariance function covers both stationary and non-stationary signals, providing a unified context to deal with a large number of different situations and avoiding the derivation of specific algorithms for each of them.
2.2. Multisensor Measured Outputs
Consider
m sensors, whose measurements obey the following equations:
where
is the measured output of the
i-th sensor at time
k, which is transmitted to a local processor by unreliable network connections, and
,
are known time-varying matrices of suitable dimensions. For each sensor
is a Bernoulli process describing the missing phenomenon,
is a scalar multiplicative noise, and
is the measurement noise.
The following hypotheses on the observation model given by Equation (
1) are required:
Hypothesis 2. The processes , , are independent sequences of independent Bernoulli random variables with know probabilities .
Hypothesis 3. The multiplicative noises , , are independent sequences of independent scalar random variables with zero means and known second-order moments; we will denote .
Hypothesis 4. The sensor measurement noises , are zero-mean sequences with known second-order moments defined by: From Hypothesis 2, different sequences of independent Bernoulli random variables with known probabilities are used to model the phenomenon of missing measurements at each sensor; so, when , which occurs with known probability , the state is present in the measurement coming from the i-th sensor at time k; otherwise, and the state is missing in the measured output from the i-th sensor at time k, which means that such observation only contains additive noise with probability . Although these variables are assumed to be independent from sensor to sensor, such condition is not necessary to deduce either the centralized estimators or the local estimators, but only to obtain the cross-covariance matrices of the local estimation errors, which are necessary to determine the matrix weights of the distributed fusion estimators. Concerning Hypothesis 3, it should be noted that the multiplicative noises involved in uncertain systems are usually gaussian noises. Finally, note that the conservative hypothesis of independence between different sensor measurement noises has been weakened in Hypothesis 4, since such independence assumption may be a limitation in many real-world problems; for example, when all the sensors operate in the same noisy environment, the noises are usually correlated, or even some sensors may have the same measurement noises.
2.3. Observation Model with Random One-Step Delays
For each
, assume that the measured outputs of the different sensors,
,
, are transmitted to the local processors through unreliable communication channels and, due to network congestion or some other causes, random one-step delays with different rates are supposed to exist in these transmissions. Assuming that the first measurement is always available and considering different sequences of Bernoulli random variables,
,
, to model the random delays, the observations used in the estimation are described by:
From Equation (
2) it is clear that
means that
; that is, the local processor receives the data from the
i-th sensor at the sampling time
k. When
, then
, meaning that the measured output at time
k is delayed and the previous one
is used for the estimation. These Bernoulli random variables modelling the delays are assumed to be one-step correlated, thus covering many practical situations; for example, those in which consecutive observations transmitted through the same channel cannot be delayed, or situations where there are some sort of links between the different communications channels. Specifically, the following hypothesis is assumed:
Hypothesis 5. , are sequences of Bernoulli random variables with known means, . It is assumed that and are independent for , and the second-order moments, and are also known.
Finally, the following independence hypothesis is also required:
Hypothesis 6. For , the processes , , , and are mutually independent.
In the following proposition, explicit expressions for the autocovariance functions of the transmitted and received measurements, that will be necessary for the distributed fusion estimation algorithm, are derived.
Proposition 1. For , the autocovariance functions and are given by: Proof. From Equations (
1) and (
2), taking into account Hypotheses 1–6, the expressions given in Equation (
3) are easily obtained. ☐
3. Distributed Fusion Linear Filter
In this section, we address the distributed fusion linear filtering problem of the signal from the randomly delayed observations defined by Equations (
1) and (
2), using the LS optimality criterion. In the distributed fusion method, each local processor provides the LS linear filter of the signal
based on the measurements from the corresponding sensor, which will be denoted by
; afterwards, these local filters are transmitted to the fusion center where the distributed filter,
, is designed as a matrix-weighted linear combination of such local filters. First, in
Section 3.1, for each
, a recursive algorithm for the local LS linear filter,
, will be deduced. Then, in
Section 3.2, the derivation of the cross-correlation matrices between any two local filters,
,
, will be detailed. Finally, in
Section 3.3, the distributed fusion filter weighted by matrices,
, will be generated from the local filters by applying the LS optimality criterion.
3.1. Local LS Linear Filtering Recursive Algorithm
To obtain the signal LS linear filters based on the available observations from each sensor, we will use an innovation approach. For each sensor , the innovation at time k, which represents the new information provided by the k-th observation, is defined by , where is the LS linear estimator of based on the previous observations, , with .
As it is known (see e.g., [
26]), the innovations,
, constitute a zero-mean white process, and the LS linear estimator of any random vector
based on the observations
, denoted by
, can be calculated as a linear combination of the corresponding innovations,
; namely
where
denotes the covariance matrix of
.
This general expression for the LS linear estimators along with the Orthogonal Projection Lemma (OPL), which guarantees that the estimation error is uncorrelated with all the observations or, equivalently, that it is uncorrelated with all the innovations, are the essential keys to derive the proposed recursive local filtering algorithm.
Taking into account Equation (
4), the first step to obtain the signal estimators is to find an explicit formula for the innovation
or, equivalently, for the observation predictor
.
Using the following alternative expression for the observations
given by Equation (
2),
and taking into account the independence hypotheses on the model, it is easy to see that:
Now, taking into account that
is uncorrelated with
for
, and using Equation (
4) for
, we obtain that:
where
Equation (
6) for the one-stage observation predictor is the starting point to derive the local recursive filtering algorithm presented in Theorem 1; this algorithm provide also the filtering error covariance matrices,
, which measure the accuracy of the estimators
when the LS optimality criterion is used.
Theorem 1. Under Hypotheses 1–6, for each single sensor node , the local LS linear filter, and the corresponding error covariance matrix, , are given by:and:where the vectors and the matrices are recursively obtained from:and the matrices satisfy: The innovations , and their covariance matrices, , are given by:and: The coefficients , , are calculated as: Finally, the matrices are given in Equation (
3)
and , are obtained by: Proof. The local filter
will be obtained from the general expression given in Equation (
4), starting from the computation of the coefficients:
The independence hypotheses and the separable structure of the signal covariance assumed in Hypothesis 1 lead to
, with
given by Equation (
15). From Equation (
6) for
we have:
Hence, using now Equation (
4) for
and
, the filter coefficients are expressed as:
which guarantees that
, with
given by:
Therefore, by defining
and
, Equation (
7) for the filter follows immediately from Equation (
4), and Equation (
8) is obtained by using the OPL to express
, and applying Hypothesis 1 and Equation (
7).
The recursive Equations (
9) and (
10) are directly obtained from the corresponding definitions, taking into account that
which, in turn, from Equation (
16), leads to Equation (
11) for
.
From now on, using that
and Equation (
15), the expression for the observation predictor given by Equation (
6) will be rewritten as follows:
From Equation (
17), Equation (
12) for the innovation is directly obtained and, applying the OPL to express its covariance matrix as
, the following identity holds:
Now, using again Equation (
17), and taking Equation (
11) into account, it is deduced that
and, since
and
, Equation (
13) for
is obtained.
To complete the proof, the expressions for
, with
given in Equation (
5), are derived using that
is uncorrelated with
. Consequently,
, and Equation (
14) for
is directly obtained from Equations (
1), (
2) and (
5), using the hypotheses stated on the model.
Next, using Equation (
4) for
in
, we have:
To compute the first expectation involved in this formula, we write:
and we apply the OPL to rewrite
, thus obtaining that
; then, by expressing
and using Equations (
11) and (
17), it follows that
The second expectation in Equation (
18) is easily computed taking into account that, from the OPL, it is equal to
and using Equation (
17).
So the proof of Theorem 1 is completed. ☐
3.2. Cross-Correlation Matrices between Any Two Local Filters
To obtain the distributed filtering estimator, the cross-correlation matrices between any pair of local filters must be calculated; a recursive formula for such matrices is derived in the following theorem (the notation in this theorem is the same as that used in Theorem 1).
Theorem 2. Under Hypotheses 1–6, the cross-correlation matrices between two local filters, , , are calculated by:with satisfying:where are given by:and for , satisfy: The innovation cross-covariance matrices are obtained as:where , are given by: The coefficients , are computed by: Finally, the matrices , and , are given in Equations (
3)
and (
15)
, respectively. Proof. Equation (
19) for
is directly obtained using Equation (
7) for the local filters and defining
.
Next, we derive the recursive formulas to obtain the matrices
, which clearly satisfy Equation (
20) just by using Equation (
9) and defining
.
For later derivations, the following expression of the one-stage predictor of
based on the observations of sensor
i will be used; this expression is obtained from Equation (
5), taking into account that
, and defining
:
As Equation (
17) is a particular case of Equation (
26), for
, hereafter we will also refer to it for the local predictors
.
By applying the OPL, it is clear that
and, consequently, we can rewrite
; then, using Equation (
26) for both predictors, Equation (
21) is easily obtained. Also, Equation (
22) for
, is immediately deduced from Equation (
9), just defining
.
To obtain Equation (
23), first we apply the OPL to express
. Then, using Equation (
26) for
and
, and the definitions of
and
, we have:
so Equation (
23) is obtained taking into account that
and
as it has been shown in the proof of Theorem 1.
Equation (
24) for
with
, is obtained from
, and using Equation (
26) in
.
Finally, the reasoning to obtain Equation (
25) for the coefficients
is also similar to that used to derive
in Theorem 1, so it is omitted and the proof of Theorem 2 is then completed. ☐
3.3. Derivation of the Distributed LS Fusion Linear Filter
As it has been mentioned previously, a matrix-weighted fusion linear filter is now generated from the local filters by applying the LS optimality criterion. The distributed fusion filter at any time k is hence designed as a product, , where is the vector constituted by the local filters, and is the matrix obtained by minimizing the mean squared error, .
As it is known, the solution of this problem is given by
and, consequently, the proposed distributed filter is expressed as:
with
, where
are the cross-correlation matrices between any two local filters given in Theorem 2.
The distributed fusion linear filter weighted by matrices is presented in the following theorem.
Theorem 3. Let denote the vector constituted by the local LS filters given in Theorem 1, and , with given in Theorem 2. Then, the distributed filtering estimator, , and the error covariance matrix, , are given by:and: Proof. As it has been discussed previously, Equation (
28) is immediately derived from Equation (
27), since the OPL guarantees that
. Equation (
29) is obtained from
, using Hypothesis 1 and Equation (
28). Then, Theorem 3 is proved. ☐
5. Numerical Simulation Example
In this section, a numerical example is shown to examine the performance of the proposed distributed and centralized filtering algorithms and how the estimation accuracy is influenced by the missing and delay probabilities. Let us consider that the system signal to be estimated is a zero-mean scalar process, , with autocovariance function which is factorizable according to Hypothesis 1 just taking, for example, and
Sensor measured outputs. The measured outputs of this signal are assumed to be provided by three different sensors and described by Equation (
1):
where
, and ,
The processes , , are independent sequences of independent Bernoulli random variables with constant and identical probabilities for the three sensors .
is a zero-mean Gaussian white process with unit variance.
The additive noises , are defined as , where , , , and is a zero-mean Gaussian white process with unit variance.
Note that there are only missing measurements in sensors 1 and 2, and both missing measurements and multiplicative noise in sensor 3. Also, it is clear that the additive noises , are only correlated at the same and consecutive sampling times, with
Observations with transmission random one-step delays. Next, according to our theoretical observation model, it is supposed that, at any sampling time
, the data transmissions are subject to random one-step delays with different rates and such delays are correlated at consecutive sampling times. More precisely, let us assume that the available measurements
are given by:
where the variables
modeling this type of correlated random delays are defined using two independent sequences of independent Bernoulli random variables,
,
, with constant probabilities,
, for all
; specifically, we define
for
, and
It is clear that the sensor delay probabilities are time-invariant: , for , and . Moreover, the independence of the sequences , , together with the independence of the variables within each sequence, guarantee that the random variables and are independent if , for any . Also, it is clear that, at each sensor, the variables are correlated at consecutive sampling times and , for and . Finally, we have that is independent of , but correlated with at consecutive sampling times, with and .
Let us observe that, for each sensor , if , then ; this fact guarantees that, when the measurement at time k is delayed, the available measurement at time is well-timed. Therefore, this correlation model covers those situations where the possibility of consecutive delayed observations at the same sensor is avoided.
To illustrate the feasibility and analyze the effectiveness of the proposed filtering estimators, the algorithms were implemented in MATLAB, and a hundred iterations were run. In order to measure the estimation accuracy, the error variances of both distributed and centralized fusion estimators were calculated for different values of the probability of the Bernoulli random variables which model the missing measurements phenomena, and for several values of the delay probabilities, , obtained from several values of . Let us observe that the delay probabilities, , for , are the same if is used instead of ; for this reason, only the case was analyzed.
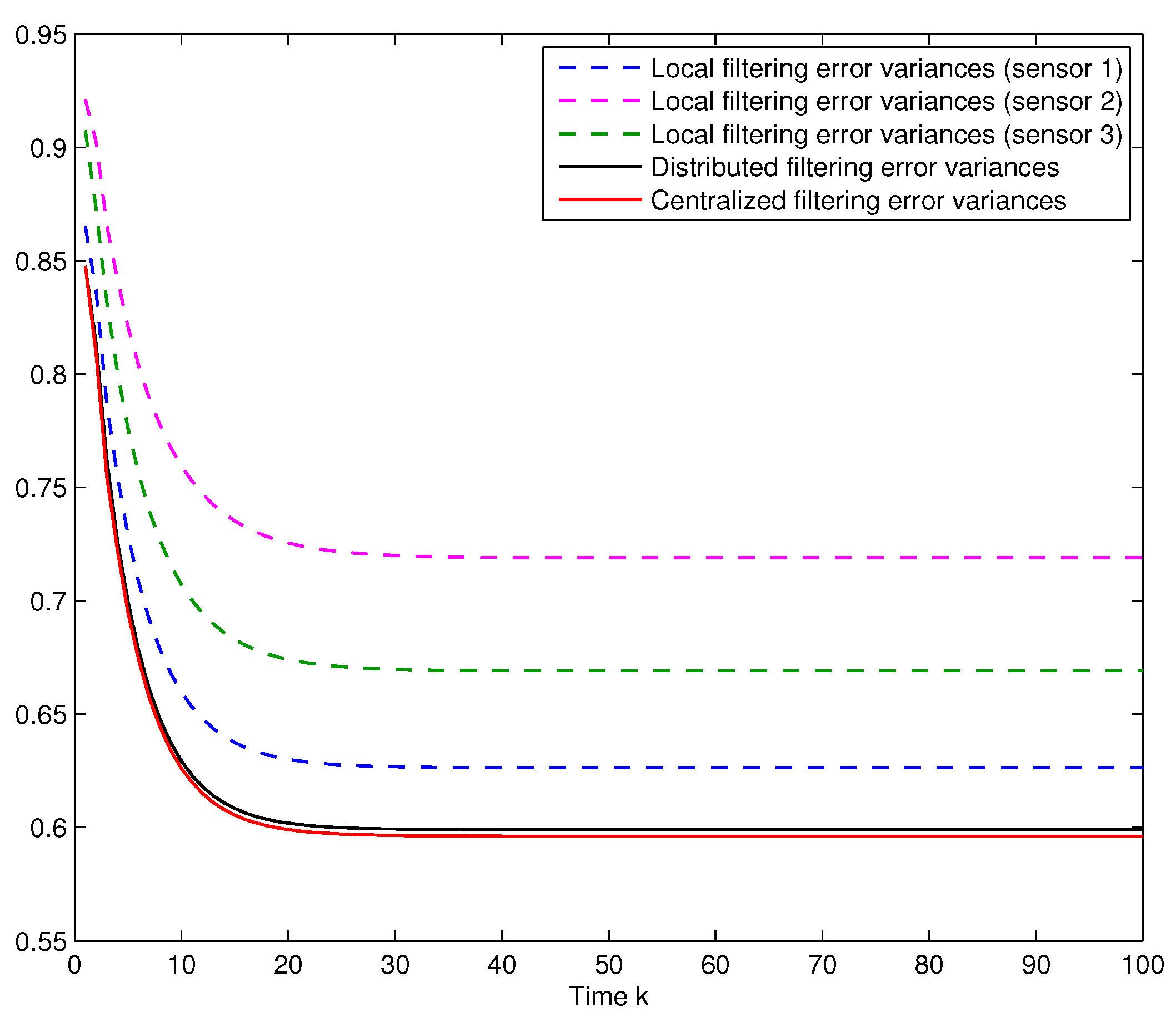
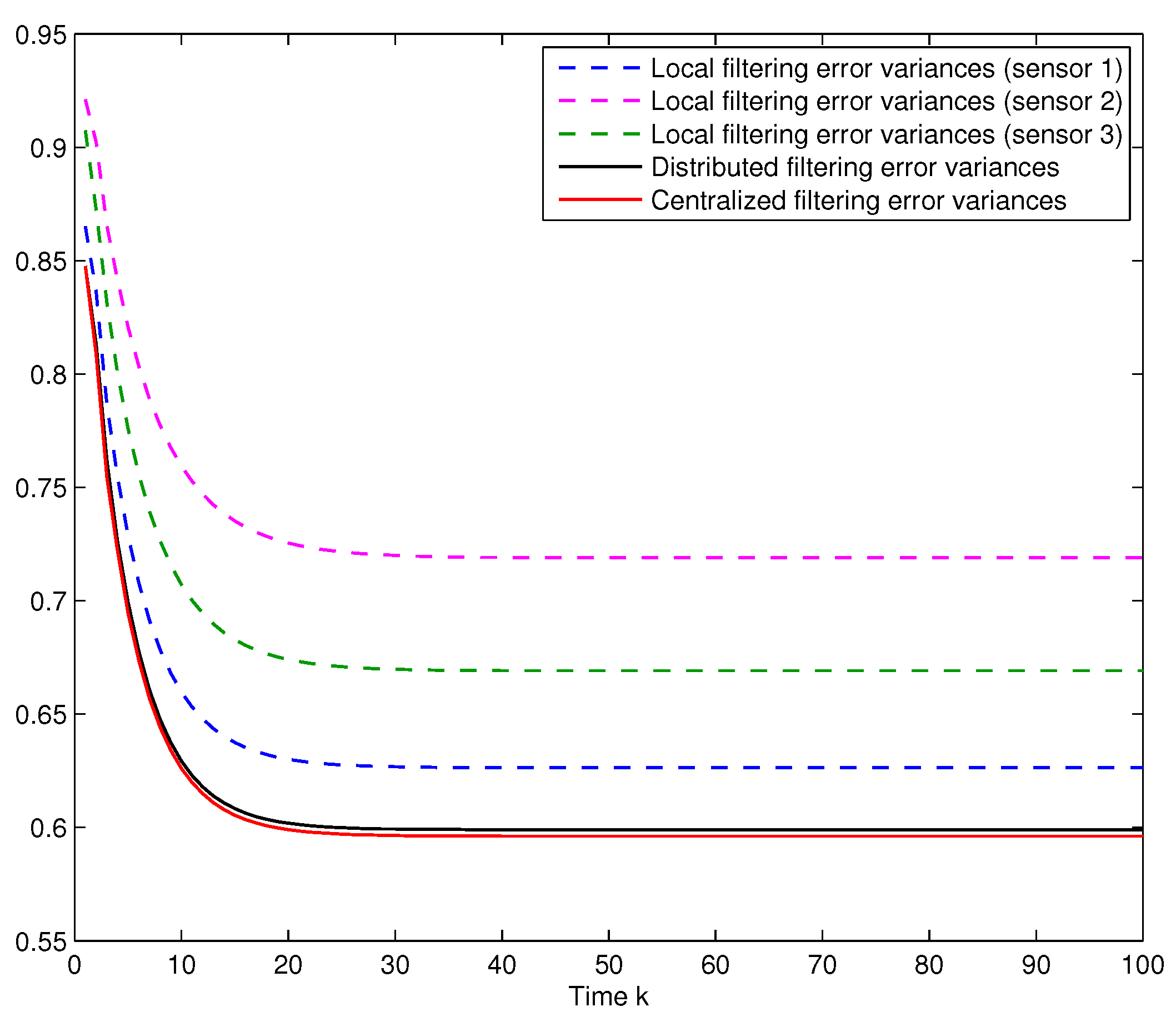
Performance of the local and fusion filtering algorithms. Let us assume that
, and consider the same delay probabilities,
, for the three sensors obtained when
,
. In
Figure 1, the error variances of the local, distributed and centralized filters are compared; this figure shows that the error variances of the distributed fusion filtering estimator are lower than those of every local estimator, but slightly greater than those of the centralized one. However, this slight difference is compensated by the fact that the distributed fusion structure reduces the computational cost and has better robustness and fault tolerance. Analogous results are obtained for other values of the probabilities
and
.
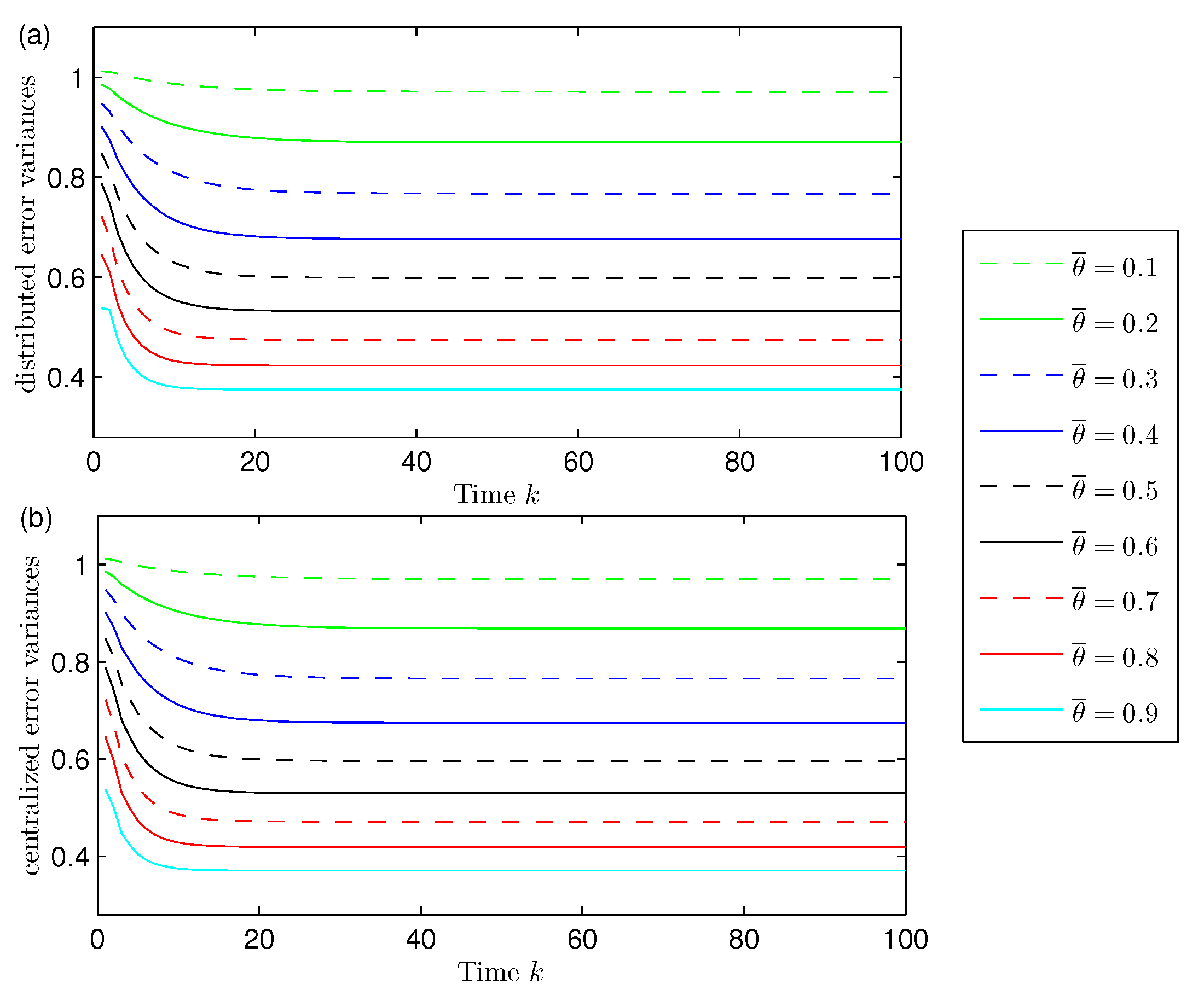
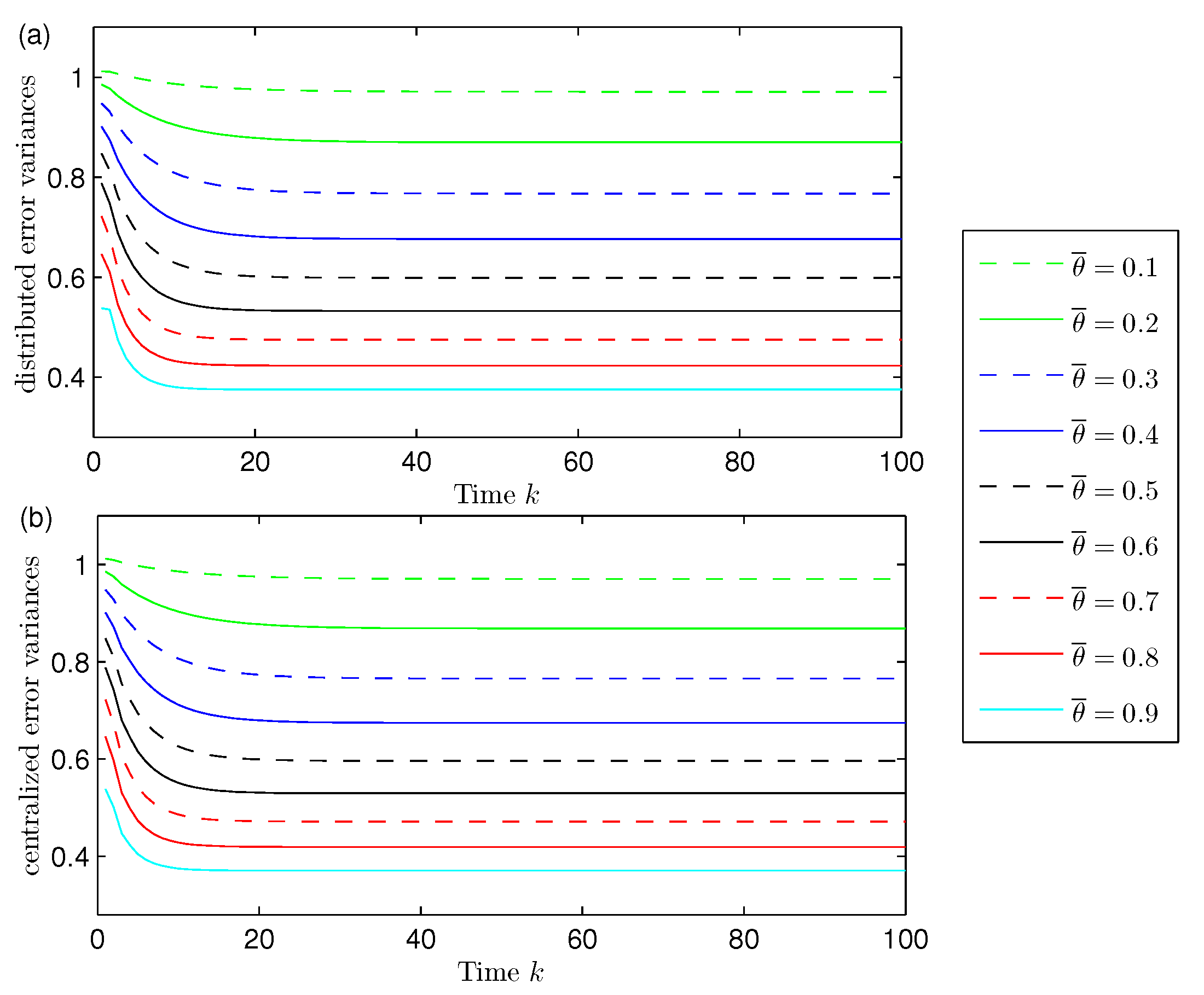
Influence of the missing measurements. Considering again
,
, in order to show the effect of the missing measurements phenomena, the distributed and centralized filtering error variances are displayed in
Figure 2 for different values of the probability
; specifically, when
is varied from 0.1 to 0.9. In this figure, both graphs (corresponding to the distributed and centralized fusion filters, respectively) show that the performance of the filters becomes poorer as
decrease, which means that, as expected, the performance of both filters improves as the probability of missing measurements,
, decreases. This figure also confirms that both methods, distributed and centralized, have approximately the same accuracy for the different values of the missing probabilities, thus corroborating the previous comments.
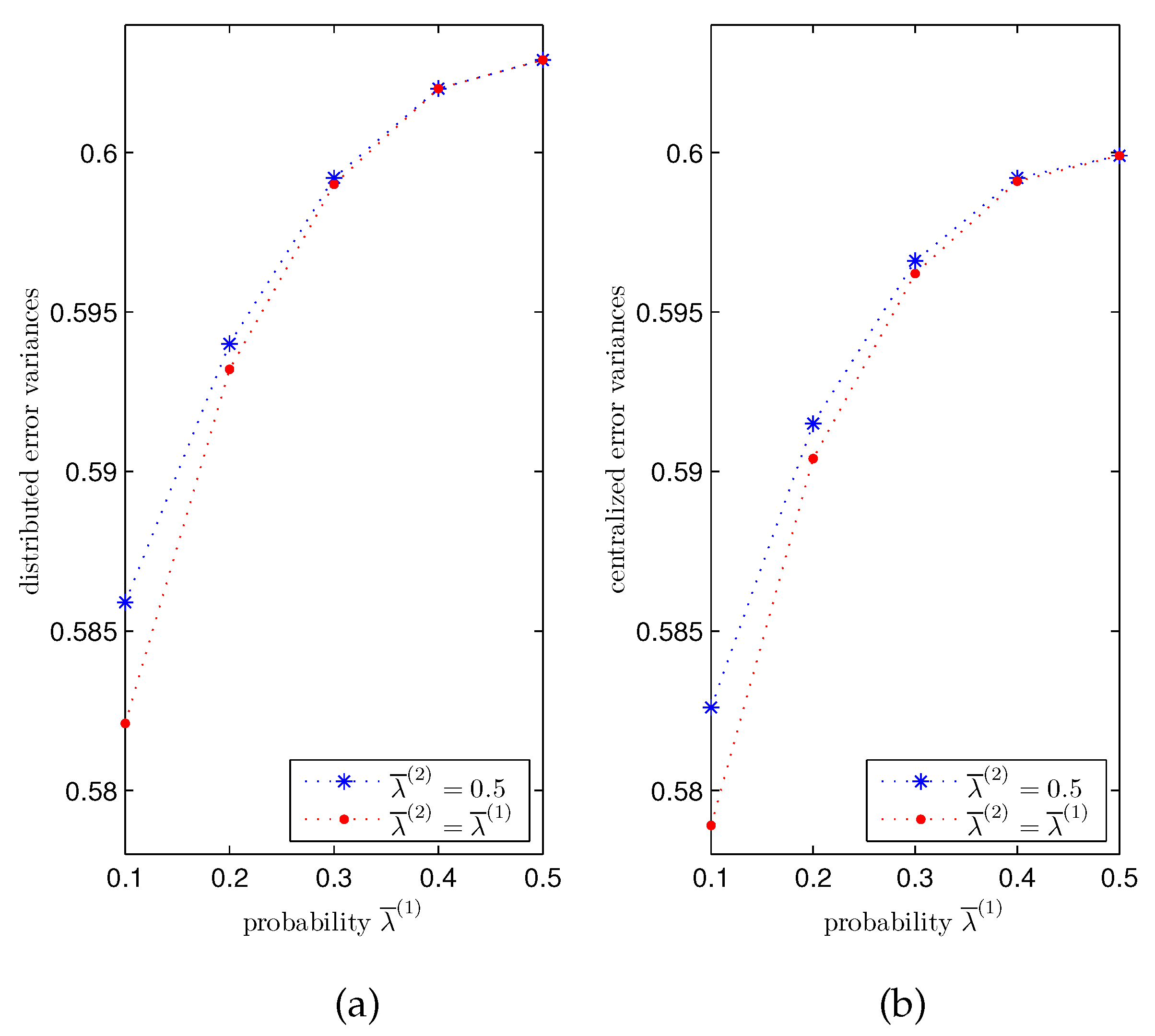
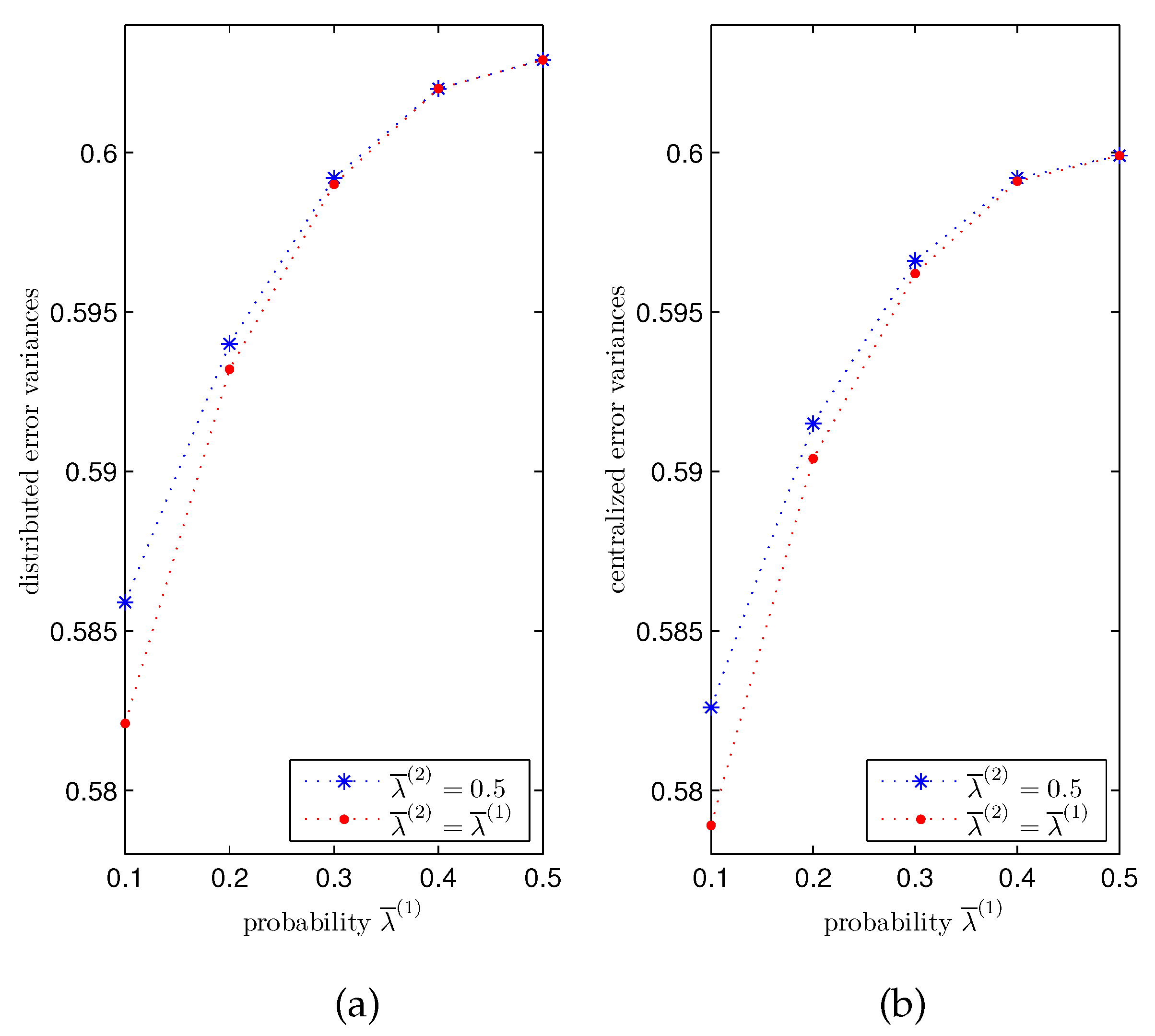
Influence of the transmission delays. For
, different values for the probabilities
,
, of the Bernoulli variables modelling the one-step delay phenomenon in the transmissions from the sensors to the local processors have been considered to analyze its influence on the performance of the distributed and centralized fusion filters. Since the behavior of the error variances is analogous for all the iterations, only the results at a specific iteration (
) are displayed here. Specifically,
Figure 3 shows a comparison of the filtering error variances at
in the following cases:
- (I)
Error variances versus , when . In this case, the values , , , and , lead to the values and , respectively, for the delay probabilities of sensors 1 and 3, whereas the delay probability of sensor 2 is constant and equal to .
- (II)
Error variances versus
, when
. Now, as in
Figure 2, the delay probabilities of the three sensors are equal, and they all take the aforementioned values.
Figure 3 shows that the performance of the distributed and centralized estimators is indeed influenced by the probability
and, as expected, better estimations are obtained as
becomes smaller, due to the fact that the delay probabilities,
, decrease with
. Moreover, this figure shows that the error variances in case (II) are less than those of case (I). This is due to the fact that, while the delay probabilities of the three sensors are varied in case (II), only two sensors vary their delay probabilities in case (I); since the constant delay probability of the other sensor is assumed to take its greatest possible value, this figure confirms that the estimation accuracy improves as the delay probabilities decrease.
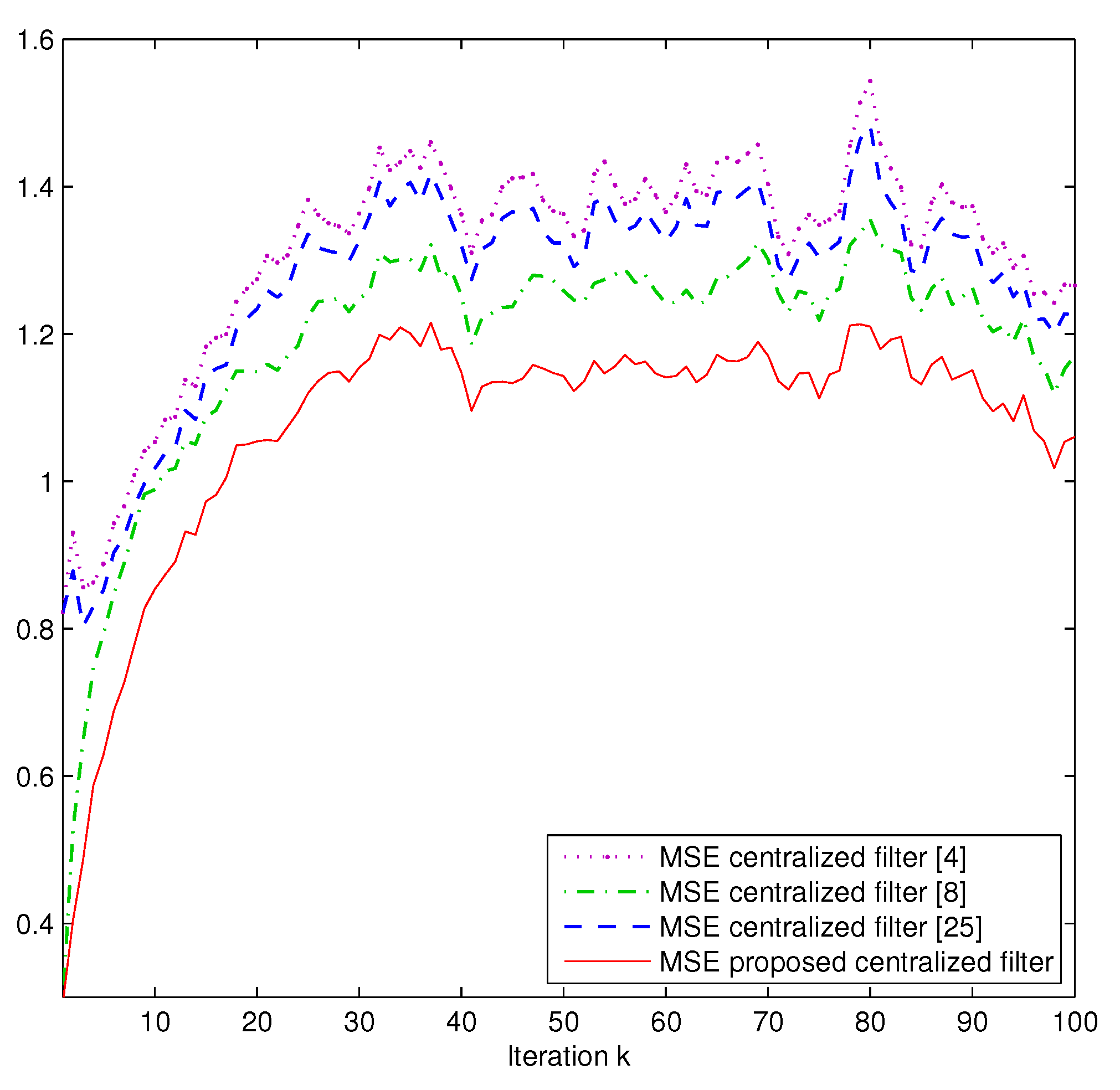
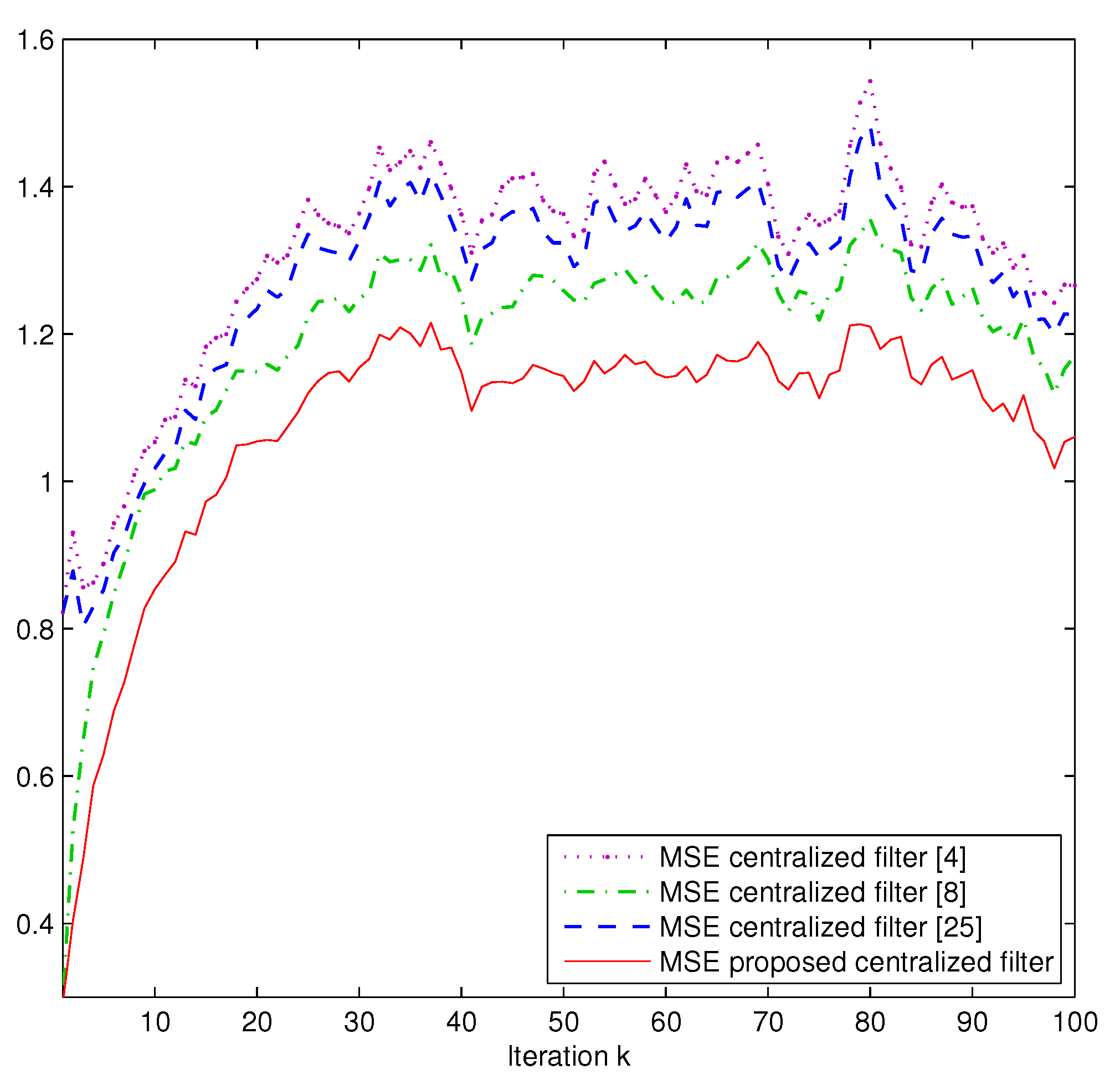
Comparison. Next, we present a comparative analysis of the proposed centralized filter and the following ones:
- -
The centralized Kalman-type filter [
4] for systems without uncertainties.
- -
The centralized filter [
8] for systems with missing measurements.
- -
The centralized filter [
25] for systems with correlated random delays.
Assuming the same probabilities
and
as in
Figure 1, and using one thousand independent simulations, the different centralized filtering estimates are compared using the mean square error (MSE) at each sampling time
k, which is calculated as
where
denotes the
s-th set of artificially simulated data and
is the filter at the sampling time
k in the
s-th simulation run. The results are displayed in
Figure 4, which shows that: (a) the proposed centralized filtering algorithm provides better estimations than the other filtering algorithms since the possibility of different simultaneous uncertainties in the different sensors is considered; (b) the centralized filter [
8] outperforms the filter [
25] since, even though the latter accommodates the effect of the delays during transmission, it does not take into account the missing measurement phenomenon in the sensors; (c) the filtering algorithm in [
4] provides the worst estimations, a fact that was expected since neither the uncertainties in the measured outputs nor the delays during transmission are taken into account.
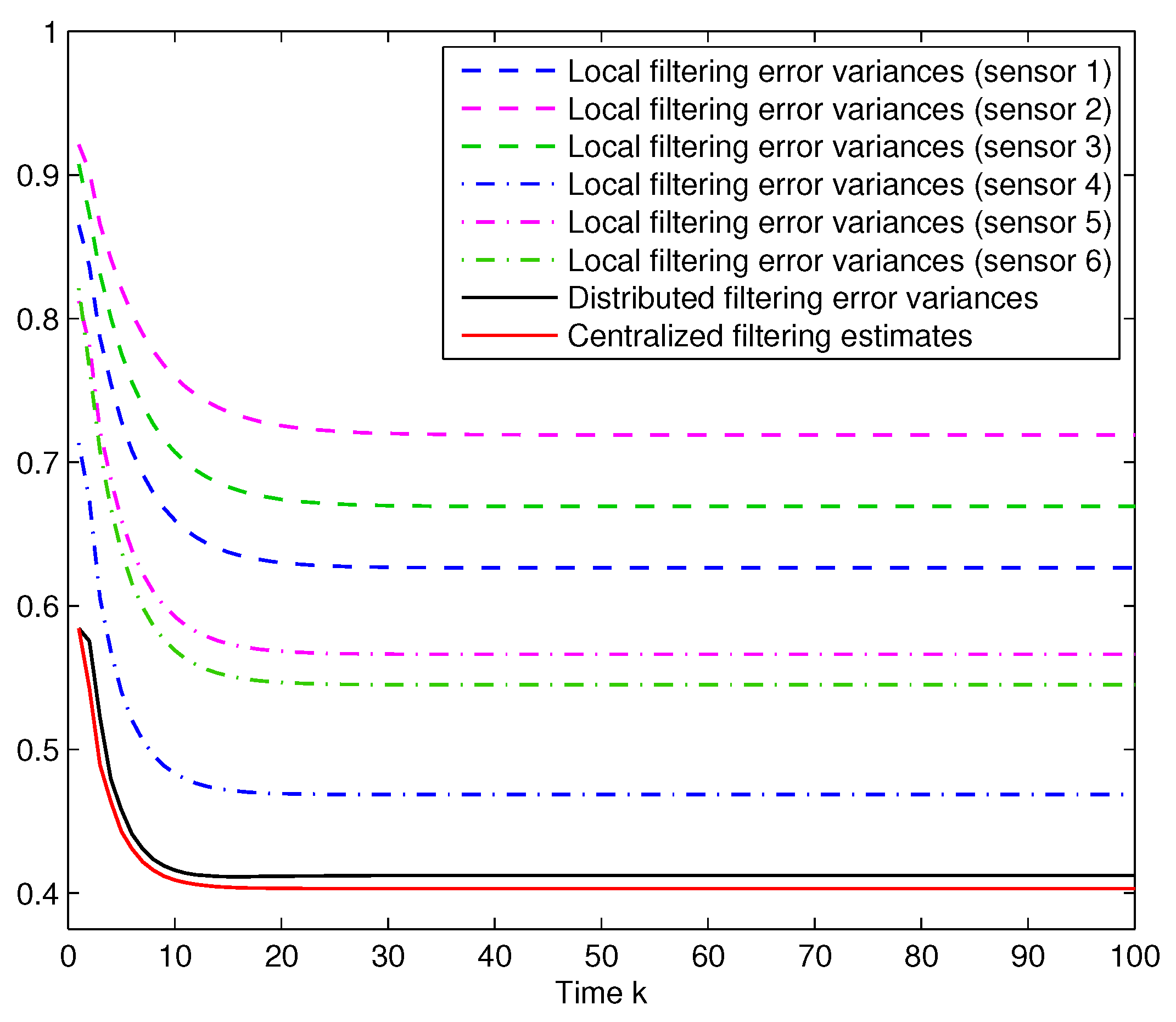
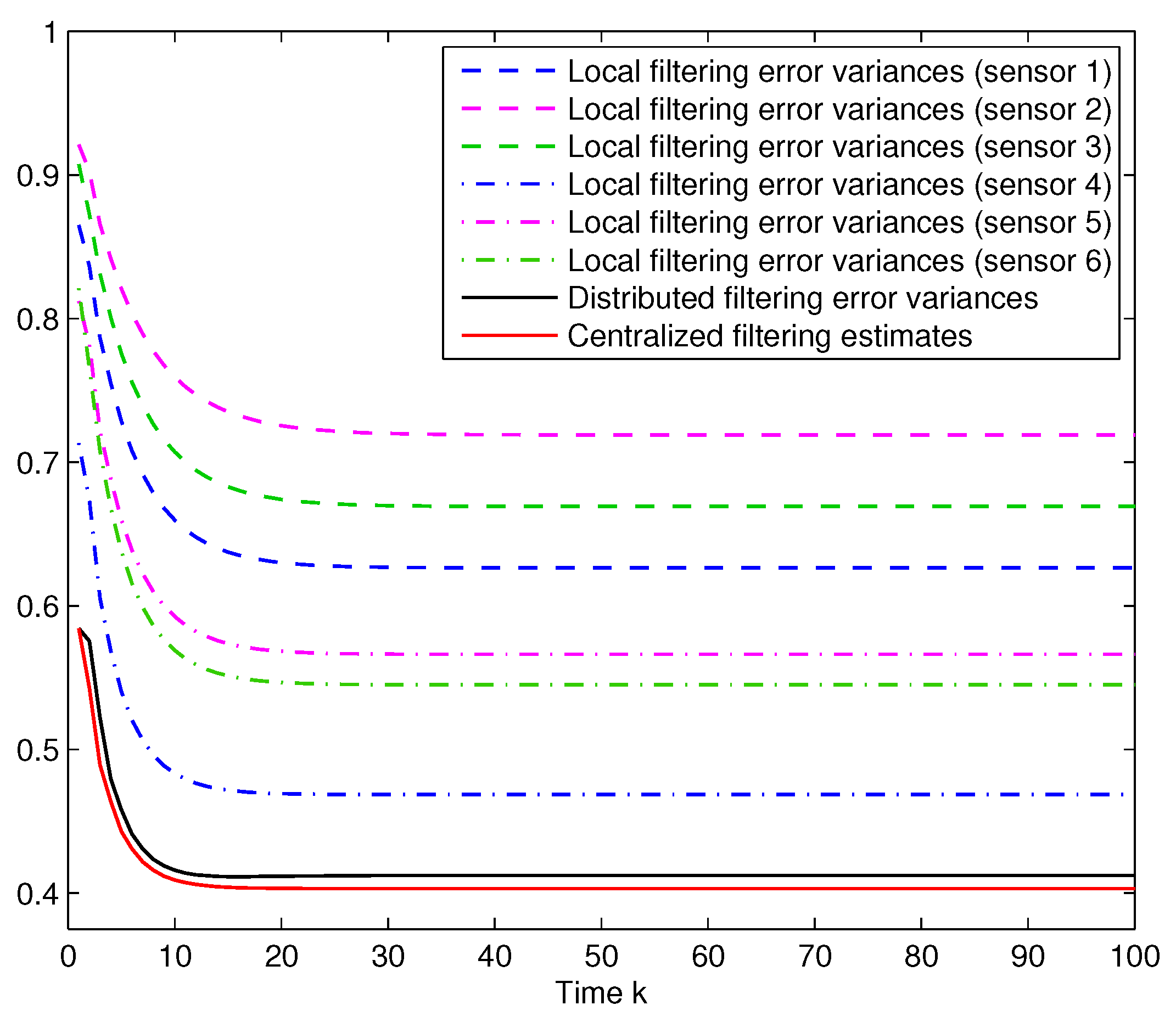
Six-sensor network. Finally, according to the anonymous reviewers suggestion, the feasibility of the proposed estimation algorithms is tested for a larger number of sensors. More specifically, three additional sensors are considered with the same characteristics as the previous ones, but a probability
,
, for the Bernoulli random variables modelling the missing measurements phenomena. The results are shown in
Figure 5, from which similar conclusions to those from
Figure 1 are deduced.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}