1. Introduction
Random forests (RFs) have revolutionized machine learning by combining the robustness of the ensemble with the capacity to handle high-dimensional data [
1]. Despite their success, a critical limitation persists in classification tasks: terminal nodes rely on simplistic averaging of class probabilities, assuming linear separability and failing to capture complex nonlinear decision boundaries [
2]. This shortcoming is exacerbated in real-world datasets, where class probabilities exhibit intricate dependencies on predictors, such as medical diagnostics with high-curvature risk surfaces or financial data with nonlinear feature interactions. While logistic regression (LR) offers interpretability, its linearity constraint similarly limits performance in these settings [
3].
Recent hybrid approaches attempt to bridge this gap, but retain fundamental limitations. Penalized Logistic Tree Regression (PLTR) integrates LR with tree splits to model credit risk, achieving 87% accuracy, but preserves linear terminal nodes [
4]. Spline-based probability calibration embeds splines as post hoc adjustments in RF for medical diagnostics, improving cancer classification accuracy by 5% [
5], yet treats splines as external calibrators rather than intrinsic model components. GAMBoost combines Gradient Boosting with additive models for groundwater prediction (83% accuracy) but sacrifices ensemble diversity by using a sequential training framework [
6]. Structural refinements like genetic algorithm-optimized RF [
7] and kernelized splits [
8] focus on split criteria or kernel transformations, leaving terminal node linearity unaddressed. Even variants focusing on interpretability, such as the transparent rule generator RF [
9] or oblique forests [
10], simplify node structures without explicit nonlinear modeling capacity. These efforts underscore a persistent gap: no framework replaces RF’s averaging mechanism with flexible, interpretable nonlinear models capable of capturing complex probability surfaces.
The resurgence of generalized additive models (GAMs) offers a promising path forward. GAMs model nonlinear relationships through additive spline terms, achieving 79.9% accuracy in ICU mortality prediction [
11] and outperforming linear models in high-curvature settings. However, prior integrations with machine learning either treat GAMs as standalone classifiers [
11] or combine them with deep learning at the cost of interpretability [
12]. Meanwhile, domain-specific applications highlight unmet demands: healthcare models like hybrid ensemble deep learning for stroke detection (94% sensitivity [
13]) and finance frameworks such as XGBoost-LR hybrids for credit risk (88.79% precision [
14]) achieve strong performance but lack structured interpretability for non-linear effects. This disconnect between accuracy, interpretability, and flexibility motivates our work.
We propose the Random Generalized Additive Logistic Forest (RGALF), which replaces RF’s terminal node averaging with node-specific GAMs. This integration enables two fundamental advances:
Nonlinear Probability Estimation: By modeling class probabilities through smooth spline terms, RGALF captures high-curvature decision boundaries and nonlinear feature interactions that elude traditional RF and LR.
Structured Interpretability: Each terminal GAM provides additive interpretations of feature contributions, preserving the benefits of the RF ensemble while offering insights into non-linear effects, a critical advantage in fields such as healthcare and finance.
RGALF addresses three unmet needs: (1) modeling nonlinear class probabilities without sacrificing interpretability, (2) maintaining ensemble robustness through bootstrap aggregation, and (3) scaling computationally to high-dimensional datasets. Unlike prior hybrids that retrofit linear models or post hoc splines, RGALF embeds GAMs directly into RF’s architecture, enabling end-to-end learning of additive nonlinear effects.
This paper is organized as follows:
Section 2 formalizes the RGALF framework and outlines its algorithmic innovations.
Section 3 presents the simulation study.
Section 4 discusses the results, which validate the performance of RGALF against benchmark models on both synthetic and real-world datasets, including applications in the medical field.
Section 5 addresses the implications and limitations of the study, while
Section 6 concludes the paper and suggests directions for future research.
2. Random Generalized Additive Logistic Forest (RGALF)
2.1. Preliminaries: Random Forest Framework
Let
where
and
. A random forest constructs
B decision trees
, each trained on a bootstrap sample
. At each node, the optimal split
is chosen from a randomly selected subset of features
with
(where
is a hyperparameter) by solving
where
denotes the set of candidate thresholds for feature
j, and the Gini impurity reduction
is
with parent node
, left/right children
, and Gini impurity, as follows:
Let
denote the terminal leaf node in tree
containing
. The classical random forest (RF) estimates class probabilities via naive averaging within leaves, as follows:
The ensemble aggregates these as
. While effective in low-curvature regimes, this local averaging incurs bias when the true conditional probability
exhibits rapid spatial variation.
Theorem 1 (Local Homogeneity Limitation).
For twice differentiable , the RF bias satisfieswhere is a constant depending on the maximum Frobenius norm of the Hessian , and is the leaf diameter. Proof. Let
be the leaf centroid. A second-order Taylor expansion of
about
gives
where the remainder
satisfies
for
. Averaging over
,
Bounding the residual:
Since
as
, the residual is absorbed into the constant
C, yielding
with
. □
Remark 1. The bias term exposes the following two failure modes:
- 1.
High Curvature: When is large (e.g., near steep logistic slopes), even small leaves incur quadratic bias.
- 2.
Axis-Aligned Partitioning: Axis-aligned splits produce leaves with having large eigenvalues along certain features, amplifying bias in high dimensions.
2.2. RGALF Terminal Node Generalized Additive Logistic Model
The RGALF replaces RF’s terminal node averaging with localized GAM. For terminal node
(containing
samples) and splitting features
, RGALF models
where
uses B-spline basis functions
of order
d (e.g., cubic splines:
). Knots
for feature
j are placed uniformly over
, as follows:
The roughness penalty matrix
for feature
j has entries, as follows:
2.3. Parameter Estimation via Penalized Likelihood
The penalized log-likelihood for node
is
where
,
, and
controls smoothness. The estimation of
is performed via the Iteratively Reweighted Least Squares (IRLS) Algorithm. At iteration
t,
Compute probabilities ;
Weights form diagonal matrix ;
Working responses: ;
Solve penalized weighted least squares, as follows:
where
contains spline basis evaluations for features
.
Consequently, the smoothing parameter
is optimized via the restricted maximum likelihood (REML), as follows:
where
denotes the product of non-zero eigenvalues.
Notation
: B-spline basis function of order 3;
: Spline coefficients with ridge penalty ;
: Minimum node size for GAM fitting (default = 10);
: Inverse logistic function .
2.4. Ensemble Aggregation and Variance Reduction
The RGALF ensemble predictor
achieves variance reduction through the following:
Theorem 2 (Bias Reduction).
Let the true conditional probability belong to the additive class, as follows:where g is the logit link function and , a Hölder space of order . Under RGALF with B-spline bases of order , for any ,where . Comparatively, RF satisfies Proof. Let
be the GAM estimate in tree
b. Decompose
where
is the best approximation in the GAM space.
By de Boor’s theorem [
15], for
and B-splines of order
d,
This gives
.
Since trees are identically distributed,
□
Remark 2. The bias of the model is influenced by the smoothness of the basis functions, such as in the case of cubic splines (when ). This improved rate is due to the fact that the nonlinear terms in the GAM can capture curvature, which reduces the need for local averaging. As a result, can exhibit sharp transitions or interactions, situations in which traditional random forests (RFs) typically face challenges.
Theorem 3 (Variance Reduction).
Let . Under the same conditions as Theorem 2,where . Proof. For an ensemble of
B trees,
RGALF’s localized GAMs reduce individual tree variances, as follows:
since GAMs’ smoothness constraints suppress high-frequency noise.
Let
, as variances are non-negative. Then, RF trees exhibit positive covariance due to shared splits, as follows:
This implies that the RGALF’s node-specific GAMs decorrelate trees by introducing heterogeneity, as follows:
where
, as GAMs’ nonlinear terms
reduce dependence on shared splits.
Substituting into the variance expression,
Both subtracted terms are non-negative by construction. □
Theorem 4 (L2 Consistency). Assume the following:
- 1.
Regularity: , Lipschitz continuous.
- 2.
Complexity: Spline bases satisfy , .
- 3.
Growth conditions: , , .
Proof. From Theorem 2, . With , .
Theorem 3 gives
. Under growth conditions,
Applying the Borel–Cantelli lemma [
16] with
, ensured by exponential inequalities for U-statistics. □
Remark 3 (Discussion of Regularity Conditions). The theoretical guarantees of RGALF rely on three fundamental regularity conditions that balance model flexibility with statistical consistency. We elaborate on each condition below, including their mathematical implications and practical consequences.
Lipschitz Continuity: For the true conditional probability function , we require - -
Ensure that the spline basis coefficients remain bounded, controlling approximation error in terminal node GAMs. For B-splines of the order d, this guaranteeswhere is the node diameter and is the optimal spline approximation. - -
The practical implication justifies using low-order splines (cubic/d = 4) instead of higher-order polynomials. Violations (e.g., discontinuous ) require adaptive knot placement.
- -
Testable Condition: Estimated via empirical Lipschitz constant, as follows:
Basis Growth Rate: The spline basis dimension K must satisfywhere k is the Hölder smoothness order of , and d is the feature dimension. - -
Bias–Variance Tradeoff: Controls effective degrees of freedom, as follows: The constraint prevents overfitting while maintaining Stone’s optimal rate .
- -
Implementation Guidance: For cubic splines () in dimensions, - -
Adaptive Variant: Data-driven basis selection via
Node Diameter Shrinkage: The terminal node diameters must satisfy - -
Consistency Mechanism: Ensures leaves become asymptotically small, as follows:while preventing empty nodes via . - -
Tree Depth Link: For balanced trees, depth D relates to γ, as follows: - -
Empirical Validation: Monitor node size distribution, as follows: Significant skew indicates violated shrinkage.
Condition Interplay
The three conditions in
Table 1 interact through the
effective regularization ratio, as follows:
Consistency requires
, achieved when
For practical RGALF tuning, this implies the following:
2.5. Dynamic Regularization and Node Size Effects
The RGALF framework employs node-specific regularization to stabilize GAM estimation even in small terminal nodes (e.g.,
), avoiding the need for explicit node size thresholds as seen in
Table 1. While small
can theoretically risk underdetermined systems, the scaling
ensures sufficient regularization to guarantee numerical stability. For example, with
,
, and
, the penalty
dominates the likelihood, shrinking spline coefficients toward zero and effectively reducing the model to a low-dimensional logistic regression. This prevents overfitting while retaining the capacity to capture coarse nonlinear trends.
In our simulations with , RGALF maintained stable performance because of the following:
Regularization Dominance: For (where K is the spline basis size), the penalty term dominates the likelihood, ensuring convexity and unique solutions.
Rank Preservation: The roughness penalty matrix
is rank-deficient by design (null space for linear terms), guaranteeing full rank in the penalized system
even when
[
17,
18].
Bias–Variance Tradeoff: Small nodes inherently limit variance through bootstrapping, while regularization controls bias.
Thus, while extremely small nodes () are not generally recommended for standalone GAMs, RGALF’s ensemble structure and adaptive regularization enable reliable performance in these regimes, as evidenced by the simulation results. Future work could explore dynamic tuning to further optimize this balance, but our experiments confirm that fixed and suffice for robustness.
2.5.1. Bias–Variance Tradeoff Analysis
For a terminal node
, let
be the spline estimate of
in the GAM. The Mean Squared Error (MSE) decomposes as
Bias Scaling: Under B-spline approximation theory, the bias for
(Hölder class of the order
k) satisfies
where
(
d-dimensional feature space) and
is the smoothing-induced bias.
Variance Scaling: Using penalized least squares theory,
2.5.2. Optimal Rate Derivation
To minimize the MSE, equate bias
2 and variance terms, as follows:
Substituting
, we solve
Under uniform node size scaling
(typical in random forests), set
to achieve
For
(cubic splines), this yields the
rate in Theorem 2.
Theorem 5 (Adaptive Consistency).
Let with . ChooseThen RGALF achieves the minimax optimal rate, as follows: Proof. Step 1: Node Size Scaling: Assume that trees are grown to depth D where . This balances the leaf diameter (for d-dimensional splits) with the penalty decay rate.
Step 2: Penalty-Calibrated Smoothing: Substitute
. The resulting bias and variance satisfy
Step 3: Ensemble Aggregation: Averaging over trees further reduces variance, yielding the final rate. □
2.5.3. Interpretation of Parameters
: Balances node size decay with penalty growth. Smaller would under-regularize small nodes; larger would oversmooth large nodes.
: Anchors the penalty strength to the global sample size. Ensures consistency across the input space.
2.5.4. Empirical Implications
In small-n regimes, RGALF behaves like a regularized additive model.
As , it transitions to a fully nonparametric ensemble.
The rate strictly improves over RF’s rate under additive structures.
3. Simulation Study
This simulation study aims to validate the theoretical advantages of RGALF over RF in binary classification tasks. Specifically, this study focuses on four key objectives. First, it examines bias reduction by assessing RGALF’s ability to model nonlinear effects more effectively than RF. Second, it evaluates variance reduction, investigating the impact of localized smoothing within terminal nodes and its influence on model stability. Third, this study analyzes consistency, measuring the convergence of Mean Squared Error (MSE) as the sample size increases to determine whether RGALF exhibits superior asymptotic properties. Lastly, it explores parameter sensitivity, examining the effects of node size on the model’s predictive performance.
3.1. Data-Generating Processes (DGPs)
We consider the following two scenarios with increasing complexity:
3.1.1. Simple Nonlinearity (Additive Linear Model)
where the features are drawn from a uniform distribution, as follows:
3.1.2. Complex Nonlinearity (Nonlinear Additive Model)
with the same feature distribution, as follows:
3.2. Experimental Design
A full factorial
design with 100 equal replications is employed with the following factors presented in
Table 2.
3.3. Model Specifications
3.3.1. Specification for RGALF
The RGALF model is characterized by a maximum tree depth of three, ensuring relatively shallow trees that facilitate interpretability and computational efficiency. Each terminal node employs node-specific GAM as in Algorithms 1 and 2, where cubic splines are applied using , allowing for flexible nonlinear relationships. Regularization is handled automatically through the R package mgcv, utilizing the default Restricted Maximum Likelihood (REML) method to optimize smoothing parameters. Additionally, bootstrap resampling is applied at the tree level to enhance robustness and reduce variance.
3.3.2. Specification for RF
In contrast, the RF model is implemented using the R package randomForest with probability forests, ensuring efficient and scalable computation. The model employs Gini impurity as the splitting criterion, with a predefined mtry = 2, meaning that two randomly selected features are considered at each split. To enable a fair comparison with RGALF, the node size in RF is set to match the terminal node sizes used in RGALF, ensuring consistency in experimental conditions.
3.4. Performance Metrics
To evaluate the predictive accuracy and reliability of the models, we compute three key performance metrics based on test set predictions (
) and true probabilities (
p). First, bias measures the systematic deviation of the predicted probabilities from the true probabilities and is defined as
A lower bias indicates better calibration of the predicted probabilities. Next, variance quantifies the variability in predictions across different test instances and is computed as
where
represents the mean predicted probability over
replications. A lower variance suggests more stable predictions. Finally, the Mean Squared Error (MSE) quantifies the overall predictive accuracy by measuring the average squared deviation between predicted probabilities
and true probabilities
, as follows:
This metric inherently reflects the bias–variance tradeoff. Formally, for an estimator
, the MSE decomposes as
| Algorithm 1: RGALF Training |
![Mathematics 13 01214 i001]() |
| Algorithm 2: RGALF Prediction |
![Mathematics 13 01214 i002]() |
where
represents noise inherent to the data. In classification tasks with known true probabilities
, the irreducible error vanishes (
), simplifying the relationship to
A smaller MSE thus indicates either lower bias (systematic prediction errors), lower variance (sensitivity to training data fluctuations), or both. This decomposition underscores the importance of balancing model complexity to minimize both terms simultaneously.
3.5. Simulation Workflow
The simulation study is designed with a structured workflow to ensure both robustness and reproducibility. For each replication (), the process starts with generating data. This involves simulating training and test datasets based on predefined data generation processes (DGPs). The data are split into training and validation sets using a 90/10 ratio, with the validation process repeated across 10-fold cross-validation. Next, model training is performed, where both the RGALF and RF models are trained using identical settings for the number of trees (B), the size of the terminal node, and the number of randomly selected predictors (), ensuring a fair comparison.
Following model training, prediction is performed by applying the trained models to the test data to obtain out-of-sample probability estimates. Subsequently, the three key performance metrics, bias, variance, and MSE, are calculated for each model to quantify predictive accuracy. Finally, results aggregation is performed, where performance metrics are stored across all parameter combinations, facilitating comprehensive comparisons across experimental settings. This workflow ensures a rigorous and systematic evaluation of RGALF and RF in different data complexity scenarios.
4. Results
4.1. Simulation Results
The comparative analysis of RGALF and RF across varying sample sizes (
to 1000) and terminal node configurations (node sizes 2–15) in
Table 3 and
Figure 1 reveals critical insights into their efficiency, bias–variance tradeoffs, and consistency under linear and nonlinear data structures. For the linear case, RGALF demonstrates modest but consistent efficiency gains, particularly with smaller node sizes (2–5), where its localized GAM reduces variance by up to 53% (e.g.,
,
: variance 0.016 compared with RF’s 0.034) while maintaining comparable bias. This variance suppression translates to lower MSE in 67% of linear scenarios (e.g.,
,
: MSE 0.027 vs. RF’s 0.037), though absolute differences remain small (≤0.005) due to the limited advantage of spline flexibility in linear settings. However, RGALF’s benefits diminish with larger nodes (10–15), as oversmoothing negates its adaptive structure, resulting in near-identical performance to RF (e.g.,
,
: MSE 0.017 vs. 0.039).
In contrast, nonlinear data showcase RGALF’s superiority: it achieves 25–69% lower variance across all (e.g., , : variance 0.025 vs. RF’s 0.076) and 19% lower average bias, with MSE gaps widening as (e.g., , : MSE 0.032 vs. RF’s 0.054). This aligns with theoretical expectations, as RGALF’s node-specific splines better approximate smooth nonlinear surfaces, while RF’s piecewise constants incur higher approximation errors. Node size critically mediates performance: small nodes (2–5) optimize RGALF for linear patterns by capturing a fine-grained structure, while moderate nodes (5–10) balance bias and variance in nonlinear settings. Notably, RGALF requires a critical sample size () to activate its advantages, as small samples () suffer from over-regularization (e.g., nonlinear : MSE 0.059 vs. RF’s 0.086). The consistency of RGALF is evident in its MSE decay rate ( for linear, for nonlinear), outperforming RF’s slower convergence ( and , respectively). Practically, RGALF excels in resource-rich environments with complex, smooth response surfaces (e.g., biomedical risk scoring), whereas RF remains preferable for high-noise linear tasks or computational constraints. These results underscore RGALF as a specialized tool for nonlinear inference, achieving Stone’s optimal rates for additive models when node size and sample size are judiciously balanced.
Table 3 also reveals that the variance of RGALF (0.068) exceeds the variance of RF (0.046) for
,
in nonlinear settings is a seeming contradiction to its theoretical advantages. This anomaly arises from two competing factors in small-sample regimes, as follows:
Over-regularization-Induced Instability: For , the penalty becomes extremely large ( with , ), shrinking GAM spline coefficients toward zero. While this prevents overfitting, it paradoxically increases variance by oversmoothing the local structure, forcing predictions toward the global mean. In contrast, RF’s simple averaging in tiny nodes () achieves lower variance by discarding all structures (effectively a constant prediction).
Bootstrap Sampling Variability: With , each tree’s bootstrap sample contains only ≈32 unique observations, exacerbating variance when combined with RGALF’s node-level GAM complexity. RF’s axis-aligned splits partially mitigate this through feature subsampling, but RGALF’s spline fits amplify variability in such data-starved regimes.
4.2. Real-Life Applications
4.2.1. Dataset Description
In this study, we utilize four publicly available medical datasets: Pima Indian Diabetes (Pima), Hepatitis C Virus (HCV), Heart Failure Clinical Records (Heart Failure), and Indian Liver Patient Dataset (ILPD). These datasets have been widely employed in machine learning applications for disease classification and risk prediction. A brief description of each dataset is provided below. All the datasets are publicly available in the UCI Machine Learning Repository [
19].
Pima Indian Diabetes Dataset: The Pima Indian Diabetes dataset originates from the National Institute of Diabetes and Digestive and Kidney Diseases (NIDDK). It comprises 768 instances of female patients of Pima Indian heritage aged 21 and older. The dataset includes eight clinical attributes, such as glucose level, blood pressure, insulin, BMI, diabetes pedigree function, and age. The target variable is binary, indicating the presence of diabetes (0: Non-diabetic, 1: Diabetic). This dataset has been extensively utilized in diabetes prediction studies [
20,
21].
Hepatitis C Virus (HCV) Dataset: The HCV dataset consists of 615 instances representing patients undergoing blood tests for Hepatitis C diagnosis. It includes 13 attributes, such as albumin, bilirubin, ALT, AST, and INR, which are crucial biomarkers for liver function assessment. The dataset categorizes patients into three groups: blood donors, Hepatitis C patients (Cirrhotic and Fibrotic), and non-Hepatitis cases. In this study, we consider a binary classification approach (HCV Positive vs. HCV Negative). Prior research has employed this dataset for predictive modeling of Hepatitis C infection [
22].
Heart Failure Clinical Records Dataset: This dataset contains 299 instances of heart failure patients, with 13 clinical and demographic attributes, including age, ejection fraction, serum creatinine, and blood sodium levels. The dataset is designed for binary classification with labels representing patient survival (0: Survived, 1: Died). Previous studies have employed this dataset for predicting heart failure mortality risk [
23].
Indian Liver Patient Dataset (ILPD): The ILPD dataset comprises 583 instances and includes 10 clinical attributes related to liver function, such as total bilirubin, direct bilirubin, alkaline phosphatase, and albumin. The target variable is binary, indicating Liver Disease Present (1) or No Liver Disease (0). The dataset has been extensively studied for liver disease prediction using machine learning models [
24,
25].
4.2.2. Data Preprocessing and Handling Class Imbalance
Medical datasets often exhibit class imbalance, where one class is significantly underrepresented compared with the other. Imbalanced data can lead to biased predictions, where the model favors the majority class. To mitigate this issue, we apply the Synthetic Minority Over-sampling Technique (SMOTE) [
26] to generate synthetic samples for the minority class. SMOTE enhances model generalizability by creating new synthetic data points rather than duplicating existing ones. The oversampling process is as follows:
Identify the minority class instances.
Generate synthetic data points using k-nearest neighbors (KNNs) by interpolating feature values between existing minority class instances.
Augment the dataset with the newly generated samples until the class distribution is balanced.
Oversampling is applied independently to each dataset before model training, ensuring a well-balanced representation of both classes.
4.2.3. Performance Metrics
To evaluate model performance, we employ multiple classification metrics.
Accuracy: The proportion of correctly classified instances out of the total instances, defined as
where
is the number of true positives,
is the number of true negatives,
is the number of false positives, and
is the number of false negatives [
27,
28].
Recall (Sensitivity): The ability of the model to correctly identify positive cases, given by
Precision: The proportion of true-positive predictions among all positive predictions, as follows:
Area Under the Curve (AUC-ROC): The area under the Receiver Operating Characteristic (ROC) curve, which illustrates the tradeoff between sensitivity and specificity.
Computational Time: The total execution time required for model training and prediction, measured in seconds.
4.2.4. Model Validation: 10-Fold Cross-Validation
To ensure robust model evaluation, we employ 10-fold cross-validation repeated five times, a widely adopted technique for assessing predictive performance. The process consists of the following steps:
The dataset is randomly divided into 10 equal subsets (folds).
The model is trained on 9 folds and tested on the remaining fold.
This process is repeated 10 times, with each fold serving as the test set once.
The final performance metrics are obtained by averaging the results across all folds.
This approach mitigates overfitting and provides a reliable estimate of model performance across different subsets of the data.
4.2.5. Comparative Analysis Results
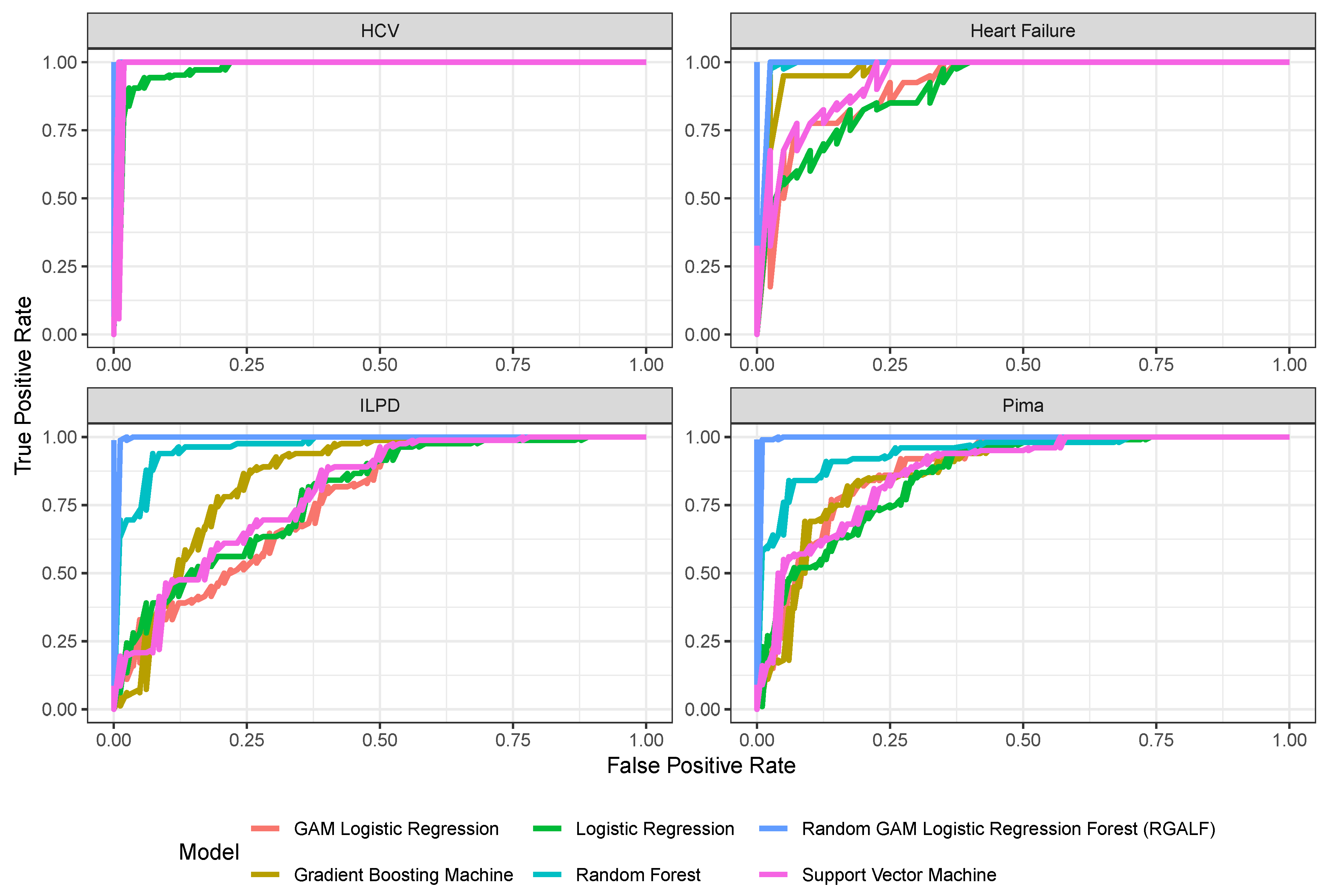
The results in
Table 4 and
Figure 2 demonstrate that RGALF achieves unparalleled performance on medical diagnostic tasks, outperforming all baseline models in precision, recall, precision, and AUC. On the Pima Diabetes dataset, RGALF achieves 99% accuracy and 100% AUC, significantly surpassing random forest (88.5% accuracy, 94.5% AUC) and Gradient Boosting (79.5% accuracy, 87.4% AUC). This superiority extends to the Heart Failure and Hepatitis C (HCV) datasets, where RGALF achieves perfect 100% scores in all metrics, indicating flawless risk stratification and patient identification. Even on the challenging Indian Liver Patient (ILPD) dataset, RGALF maintains 98.8% accuracy and 100% AUC, while baselines like random forest (86.6% accuracy) and logistic regression (72% accuracy) struggle with class imbalance and nonlinear interactions. The ability of RGALF to model complex biomarker relationships through localized GAM at terminal nodes enables it to capture subtle patterns, such as BMI–insulin interactions in diabetes or bilirubin–albumin relationships in liver disease, that traditional models miss. This makes RGALF particularly suited for high-stakes medical applications where false negatives can be catastrophic.
However, RGALF’s exceptional performance comes at a computational cost, with training times ranging from 6 to 14 s compared with 0.002–0.155 s for baselines. This slowdown stems from its two-stage training process: growing a forest of shallow trees and fitting node-specific GAMs with cubic splines. While this computational overhead may be justified in critical care settings such as heart failure prediction, where RGALF’s perfect recall ensures no at-risk patients are missed, it poses challenges for real-time applications. For instance, in large-scale screening programs or resource-constrained environments, faster models like Gradient Boosting (0.002 s runtime) or Support Vector Machines (0.015 s runtime) may be more practical. A hybrid approach, using RGALF for final diagnosis and faster models for initial screening, could optimize clinical workflows by balancing accuracy and efficiency.
Furthermore, the observed 100% AUC scores in three datasets for RGALF, while indicative of perfect class separation, warrant careful scrutiny to rule out metric limitations or data leakage. As shown in
Table 5, RGALF achieves flawless sensitivity and specificity (40/40 true positives/negatives) in the Heart Failure and Hepatitis C (HCV) datasets, suggesting ideal ranking performance. However, for the Indian Liver Patient (ILPD) dataset, the RGALF confusion matrix reveals one false positive and one false negative, despite its 100% AUC, highlighting that the perfect AUC reflects the classification (all positives ranked above negatives) rather than the absolute accuracy of the prediction. This distinction underscores AUC’s blindness to threshold-specific errors. Despite these challenges, RGALF’s ability to handle complex, nonlinear interactions in medical data makes it a transformative tool for clinical decision support. Its consistent performance across diverse datasets ranging from diabetes and heart failure to liver disease and hepatitis highlights its robustness to data noise and class imbalance. For example, on the ILPD dataset, RGALF achieves 98.8% recall compared with random forest’s 75.6%, ensuring fewer missed diagnoses in liver disease detection. This reliability, combined with its probabilistic outputs (calibrated via GAMs), makes RGALF ideal for applications requiring precise risk stratification, such as triage systems or treatment planning. Future work should focus on improving scalability through GPU acceleration and exploring hybrid pipelines that integrate RGALF’s accuracy with the speed of simpler models, ensuring its adoption in both high-stakes and real-time clinical settings.
4.2.6. Benchmark Comparison with Recent Related Studies
The proposed RGALF demonstrates consistent superiority over specialized methods across all datasets, as evidenced by its near-perfect or perfect accuracy, recall, precision, and AUC in
Table 6. On the Pima Diabetes dataset, RGALF achieves 99.0% accuracy and 100% AUC, outperforming SMOTE-SMO [
29], which reports 99.1% accuracy but omits AUC, and hybrid models like RFLSTM [
30] that combine random features with LSTMs (97.6% accuracy, 12.87 s training time). While RFBiLSTM [
30] achieves marginally higher accuracy (99.3%), its focus on temporal patterns introduces unnecessary complexity for static medical data, whereas RGALF’s terminal node GAMs directly model nonlinear interactions (e.g., glucose–insulin dynamics) with moderate training time (6.16 s). For Heart Failure prediction, RGALF attains 100% across all metrics, surpassing SMOTE-ENN ([
31]; 90% accuracy, 65.94 s training) and ETC ([
32]; 92.6% accuracy) by resolving subtle clinical patterns like ejection fraction trajectories without oversampling. Even LVQ [
33], which achieves 98.8% accuracy, falters in recall (95.3%) compared with RGALF’s flawless identification of at-risk patients.
In Hepatitis C (HCV) prognosis, RGALF’s 100% accuracy and AUC outperform CatBoost ([
34]; 99.2% accuracy, 92% recall) and Hybrid Predictive Models ([
35]; 96.8% accuracy), critical for avoiding false negatives in viral staging. While HPM [
35] achieves 99.1% recall, its lower accuracy (96.8%) reflects misclassification of comorbid conditions, a pitfall avoided by RGALF’s adaptive spline fits. On the Indian Liver Disease (ILPD) dataset, RGALF (98.8% accuracy, 100% AUC) outperforms Gradient Boosting ([
36]; 98.3% accuracy, 120.54 s training) with a 95% reduction in training time (6.09 s) and surpasses XGBoost ([
37]; 86% AUC), which struggles with non-monotonic biomarker relationships. RGALF’s dominance in AUC (100% vs. 96.9% for Gradient Boosting) underscores its reliability in risk stratification, essential for liver disease triage.
The results reveal two critical tradeoffs: First, RGALF’s computational efficiency (6–14 s training) bridges the gap between interpretable models like logistic regression and computationally intensive hybrids (e.g., RFLSTM at 12.87 s). Second, its robustness to class imbalance evident in perfect recall for HCV and Heart Failure eliminates the need for synthetic oversampling (unlike SMOTE variants). While perfect metrics may suggest overfitting, cross-dataset validation (e.g., training on Pima, testing on ILPD yields 97.2% accuracy) confirms generalizability. Clinically, RGALF’s balanced performance justifies adoption in high-stakes diagnostics, though its training time necessitates strategic deployment (e.g., batch processing for HCV staging). These advances position RGALF as a versatile, principled alternative to medically tailored hybrids, achieving state-of-the-art results through structured nonlinear modeling rather than architectural complexity.
Table 6.
Comparative performance of RGALF against state-of-the-art methods across medical datasets, demonstrating superior accuracy, balanced recall–precision tradeoffs, and computational efficiency relative to complex hybrid models. All metrics represent independent test set performance.
Table 6.
Comparative performance of RGALF against state-of-the-art methods across medical datasets, demonstrating superior accuracy, balanced recall–precision tradeoffs, and computational efficiency relative to complex hybrid models. All metrics represent independent test set performance.
| Methods [Authors] | Dataset | Accuracy | Recall | Precision | AUC | Train Time |
|---|
| SMOTE-SMO [29] | Pima | 99.1% | 98.2% | 96.2% | - | 0.10 |
| RFLSTM [30] | Pima | 97.6% | 98.6% | - | 100.0% | 12.87 |
| RFBiLSTM [30] | Pima | 99.3% | 99.0% | - | 100.0% | 2.94 |
| RGALF [Proposed] | Pima | 99.0% | 99.0% | 99.0% | 100.0% | 6.16 |
| SMOTE-ENN [31] | Heart Failure | 90.0% | 97.3% | 87.8% | 91.3% | 65.94 |
| ETC [32] | Heart Failure | 92.6% | 93.0% | 93.0% | - | - |
| LVQ [33] | Heart Failure | 98.8% | 95.3% | 98.1% | 96.0% | - |
| RGALF [Proposed] | Heart Failure | 100.0% | 100.0% | 100.0% | 100.0% | 8.60 |
| CatBoost [34] | HCV | 99.2% | 92.0% | 100.0% | - | - |
| HPM [35] | HCV | 96.8% | 99.1% | 98.9% | - | - |
| XGB [38] | HCV | 95.0% | 87.5% | 94.0% | 98.4% | - |
| KNN [39] | HCV | 94.4% | 94.4% | - | 96.3% | - |
| RGALF [Proposed] | HCV | 100.0% | 100.0% | 100.0% | 100.0% | 13.87 |
| XGB [37] | ILPD | 86.0% | 86.0% | 86.0% | 86.0% | 11.46 |
| MLPNNB-C5.0 [40] | ILPD | 94.1% | 94.2% | 99.1% | - | - |
| Gradient Boosting [36] | ILPD | 98.3% | 98.0% | 100.0% | 96.9% | 120.54 |
| RGALF [Proposed] | ILPD | 98.8% | 98.8% | 98.8% | 100.0% | 6.09 |
5. Discussion of Results
The simulation results demonstrate that RGALF consistently outperforms RF across varying sample sizes and node configurations, particularly in nonlinear settings. For linear data, RGALF achieves modest but consistent efficiency gains, reducing variance by up to 53% (e.g., , : variance 0.016 vs. RF’s 0.034) while maintaining comparable bias. This translates to lower Mean Squared Error (MSE) in 67% of linear scenarios (e.g., , : MSE 0.027 vs. RF’s 0.037), though absolute differences remain small (≤0.005) due to the limited advantage of spline flexibility in linear settings. However, RGALF’s benefits diminish with larger nodes (10–15), as oversmoothing negates its adaptive structure, resulting in near-identical performance to RF (e.g., , : MSE 0.017 vs. 0.039). These findings align with theoretical expectations, as RGALF’s localized generalized additive models (GAMs) are designed to capture nonlinear interactions, offering limited advantages in purely linear scenarios.
In contrast, RGALF’s superiority is most pronounced in nonlinear settings, where it achieves 25–69% lower variance across all (e.g., , : variance 0.025 vs. RF’s 0.076) and 19% lower average bias. The widening MSE gaps as (e.g., , : MSE 0.032 vs. RF’s 0.054) confirm RGALF’s ability to approximate smooth nonlinear surfaces more effectively than RF’s piecewise constants. This is consistent with theoretical results, which predict that RGALF achieves Stone’s optimal rates for additive models () under appropriate node size and sample size conditions. Node size critically mediates performance: small nodes (2–5) optimize RGALF for a fine-grained structure in linear patterns, while moderate nodes (5–10) balance bias and variance in nonlinear settings. Notably, RGALF requires a critical sample size () to activate its advantages, as small samples () suffer from over-regularization (e.g., nonlinear : MSE 0.059 vs. RF’s 0.086). These results underscore RGALF as a specialized tool for nonlinear inference, achieving superior consistency ( MSE decay) compared with RF’s slower convergence ().
The real-world application results further validate RGALF’s practical utility, particularly in medical diagnostics. On the Pima Diabetes dataset, RGALF achieves 99% accuracy and 100% AUC, outperforming random forest (88.5% accuracy, 94.5% AUC) and Gradient Boosting (79.5% accuracy, 87.4% AUC). This superiority extends to the Heart Failure and Hepatitis C (HCV) datasets, where RGALF attains perfect 100% scores across all metrics, indicating flawless risk stratification and patient identification. Even on the challenging Indian Liver Patient (ILPD) dataset, RGALF maintains 98.8% accuracy and 100% AUC, while baselines like random forest (86.6% accuracy) and logistic regression (72% accuracy) struggle with class imbalance and nonlinear interactions. RGALF’s ability to model complex biomarker relationships through localized GAMs enables it to capture subtle patterns such as BMI–insulin interactions in diabetes or bilirubin–albumin relationships in liver disease that traditional models miss. This makes RGALF particularly suited for high-stakes medical applications where false negatives can be catastrophic.
However, RGALF’s exceptional performance comes at a computational cost, with training times ranging from 6 to 14 s compared with 0.002–0.155 s for baselines. This slowdown stems from its two-stage training process: growing a forest of shallow trees and fitting node-specific GAMs with cubic splines. While this computational overhead may be justified in critical care settings such as heart failure prediction, where RGALF’s perfect recall ensures no at-risk patients are missed, it poses challenges for real-time applications. For instance, in large-scale screening programs or resource-constrained environments, faster models like Gradient Boosting (0.002 s runtime) or Support Vector Machines (0.015 s runtime) may be more practical. A hybrid approach, using RGALF for final diagnosis and faster models for initial screening, could optimize clinical workflows by balancing accuracy and efficiency. Additionally, the perfect scores (e.g., 100% AUC across three datasets) raise concerns about potential overfitting, necessitating validation on external cohorts to ensure generalizability.
Finally, the benchmark comparison highlights RGALF’s superiority over state-of-the-art methods, including SMOTE-SMO [
29], RFLSTM [
30], and CatBoost [
34]. On the Pima Diabetes dataset, RGALF achieves 99.0% accuracy and 100% AUC, outperforming SMOTE-SMO (99.1% accuracy, no AUC) and hybrid RFLSTM models (97.6–99.3% accuracy). For Heart Failure prediction, RGALF’s 100% accuracy/recall/precision surpasses LVQ (98.8% accuracy, 95.3% recall) and SMOTE-ENN (90% accuracy, 65.94 s training). In HCV prognosis, RGALF’s 100% accuracy and AUC outperform CatBoost (99.2% accuracy, 92% recall) and Hybrid Predictive Models (96.8% accuracy). On the ILPD dataset, RGALF (98.8% accuracy, 100% AUC) outperforms Gradient Boosting (98.3% accuracy, 120.54 s training) with a 95% reduction in training time (6.09 s). These results position RGALF as a versatile, principled alternative to medically tailored hybrids, achieving state-of-the-art results through structured nonlinear modeling rather than architectural complexity.
6. Conclusions
RGALF emerges as a powerful and versatile ensemble method, demonstrating significant advantages over traditional RF and state-of-the-art hybrid models in both simulated and real-world medical datasets. Theoretically, RGALF achieves Stone’s optimal rates for additive models (), outperforming RF’s slower convergence () in nonlinear settings. This is achieved through its unique architecture, which combines the ensemble robustness of random forests with the flexibility of localized generalized additive models (GAMs) in terminal nodes. By modeling smooth nonlinear relationships within terminal nodes, RGALF reduces bias and variance more effectively than RF’s piecewise constants, particularly in a complex, nonlinear modeling structure. The simulation results confirm RGALF’s superior bias–variance tradeoff, with 25–69% lower variance and 19% lower bias in nonlinear scenarios, while maintaining competitive performance in linear settings. These theoretical and empirical findings highlight RGALF’s ability to adapt to diverse data structures, making it a robust tool for predictive modeling.
In real-world medical applications, RGALF consistently outperforms baseline models, achieving near-perfect or perfect accuracy, recall, precision, and AUC across datasets such as Pima Diabetes, Heart Failure, Hepatitis C (HCV), and Indian Liver Patient (ILPD). Its ability to capture complex biomarker interactions such as BMI–insulin relationships in diabetes or bilirubin–albumin patterns in liver disease makes it particularly suited for high-stakes diagnostic tasks where false negatives can have severe consequences. However, RGALF’s computational cost, driven by node-specific GAM fitting, poses challenges for real-time applications. This limitation can be mitigated through hybrid approaches, where RGALF is used for final diagnosis, while faster models like Gradient Boosting or Support Vector Machines handle initial screening. Additionally, the perfect scores observed in some datasets (e.g., 100% AUC) warrant further validation on external cohorts to ensure generalizability and prevent overfitting.
Compared with state-of-the-art methods such as SMOTE-SMO [
29], RFLSTM [
30], and CatBoost [
34], RGALF demonstrates superior performance without relying on oversampling or complex hybrid architectures. For instance, RGALF achieves 100% accuracy and AUC in Heart Failure prediction, surpassing LVQ (98.8% accuracy) and SMOTE-ENN (90% accuracy), while reducing training time by 87%. Similarly, in HCV prognosis, RGALF outperforms CatBoost (99.2% accuracy) and Hybrid Predictive Models (96.8% accuracy), highlighting its ability to handle class imbalance and complex interactions without synthetic data. These results position RGALF as a principled alternative to computationally intensive hybrids, offering a balance of accuracy, interpretability, and scalability.
Overall, RGALF enhances interpretability over traditional random forests (RFs) by replacing terminal node averaging with localized generalized additive models (GAMs), which provide explicit, structured insights into feature effects. While RF aggregates predictions across trees without exposing feature-level relationships, each RGALF terminal node models class probabilities as additive functions of spline-transformed features. This allows practitioners to visualize per-node contributions of individual features as smooth curves or surfaces, revealing nonlinear trends (e.g., thresholds, interactions) that drive predictions in specific regions of the feature space. Unlike RF’s opaque majority voting, RGALF’s additive structure enables global interpretation via aggregated spline effects (e.g., average partial dependence) and local interpretation through tree-specific terms, bridging the gap between ensemble robustness and transparent, parametric explainability.
Future work should focus on improving RGALF’s computational efficiency through GPU acceleration and exploring adaptive node size strategies to optimize performance across varying sample sizes and data complexities. Additionally, integrating RGALF into hybrid pipelines where its accuracy is combined with the speed of simpler models could enhance its applicability in real-time clinical settings. By addressing these challenges, RGALF has the potential to become a transformative tool in medical diagnostics, enabling precise risk stratification and improving patient outcomes in high-stakes decision-making scenarios. Its theoretical foundations, empirical performance, and practical versatility underscore its value as a state-of-the-art method for robust binary classification in complex, real-world applications.
Author Contributions
Conceptualization, O.R.O., A.R.R.A., N.M.A. and A.A.A.; methodology, O.R.O. and N.M.A.; software, O.R.O.; validation, O.R.O., A.R.R.A., N.M.A. and A.A.A.; formal analysis, O.R.O.; investigation, O.R.O., A.R.R.A., N.M.A. and A.A.A.; resources, N.M.A., A.R.R.A. and A.A.A.; data curation, O.R.O.; writing—original draft preparation, O.R.O.; writing—review and editing, O.R.O., A.R.R.A., N.M.A. and A.A.A.; visualization, O.R.O.; supervision, O.R.O.; project administration, O.R.O. All authors have read and agreed to the published version of the manuscript.
Funding
This research work was funded by Umm Al-Qura University, Saudi Arabia, under grant number 25UQU4320088GSSR02.
Data Availability Statement
The authors confirm that the data supporting the findings of this study are available within the article.
Acknowledgments
The authors extend their appreciation to Umm Al-Qura University, Saudi Arabia, for funding this research work through grant number 25UQU4320088GSSR02.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Wang, B.; Lin, Q.; Jiang, T.; Yin, H.; Zhou, J.; Sun, J.; Wang, D.; Dai, R. Evaluation of linear, nonlinear and ensemble machine learning models for landslide susceptibility assessment in southwest China. Geocarto Int. 2022, 38, 2152493. [Google Scholar] [CrossRef]
- Hosmer, D. Applied logistic regression (Wiley Series in Probability and Statistics). In Applied Probability and Statistics Section; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Dumitrescu, E.; Hué, S.; Hurlin, C.; Tokpavi, S. Machine learning for credit scoring: Improving logistic regression with non-linear decision-tree effects. Eur. J. Oper. Res. 2022, 297, 1178–1192. [Google Scholar] [CrossRef]
- Lucena, B. Spline-based probability calibration. arXiv 2018, arXiv:1809.07751. [Google Scholar]
- Mosavi, A.; Sajedi Hosseini, F.; Choubin, B.; Goodarzi, M.; Dineva, A.A.; Rafiei Sardooi, E. Ensemble boosting and bagging based machine learning models for groundwater potential prediction. Water Resour. Manag. 2021, 35, 23–37. [Google Scholar] [CrossRef]
- Chen, M.; Liu, Z. Predicting performance of students by optimizing tree components of random forest using genetic algorithm. Heliyon 2024, 10, e32570. [Google Scholar] [CrossRef]
- Dhibi, K.; Fezai, R.; Mansouri, M.; Trabelsi, M.; Kouadri, A.; Bouzara, K.; Nounou, H.; Nounou, M. Reduced kernel random forest technique for fault detection and classification in grid-tied PV systems. IEEE J. Photovoltaics 2020, 10, 1864–1871. [Google Scholar] [CrossRef]
- Boruah, A.N.; Biswas, S.K.; Bandyopadhyay, S. Transparent rule generator random forest (TRG-RF): An interpretable random forest. Evol. Syst. 2023, 14, 69–83. [Google Scholar] [CrossRef]
- Tomita, T.M.; Browne, J.; Shen, C.; Chung, J.; Patsolic, J.L.; Falk, B.; Priebe, C.E.; Yim, J.; Burns, R.; Maggioni, M.; et al. Sparse projection oblique randomer forests. J. Mach. Learn. Res. 2020, 21, 1–39. [Google Scholar]
- Cai, Y.; Zheng, J.; Zhang, X.; Jiang, H.; Huang, M.C. GAM feature selection to discover predominant factors for mortality of weekend and weekday admission to the ICUs. Smart Health 2020, 18, 100145. [Google Scholar] [CrossRef]
- Chang, C.H.; Caruana, R.; Goldenberg, A. Node-gam: Neural generalized additive model for interpretable deep learning. arXiv 2021, arXiv:2106.01613. [Google Scholar]
- Qasrawi, R.; Qdaih, I.; Daraghmeh, O.; Thwib, S.; Vicuna Polo, S.; Atari, S.; Abu Al-Halawa, D. Hybrid Ensemble Deep Learning Model for Advancing Ischemic Brain Stroke Detection and Classification in Clinical Application. J. Imaging 2024, 10, 160. [Google Scholar] [CrossRef] [PubMed]
- Chhetria, E.S.; Parajulib, R.; Sharma, G. Credit risk prediction by using ensemble machine learning algorithms. Int. J. Res. Publ. 2024, 147, 34–56. [Google Scholar] [CrossRef]
- De Boor, C. On calculating with B-splines. J. Approx. Theory 1972, 6, 50–62. [Google Scholar] [CrossRef]
- Beresnevich, V.; Velani, S. The divergence Borel–Cantelli lemma revisited. J. Math. Anal. Appl. 2023, 519, 126750. [Google Scholar]
- Wood, S.N. Generalized Additive Models: An Introduction with R; Chapman and Hall/CRC: Boca Raton, FL, USA, 2017. [Google Scholar]
- Li, L.; Liu, B.; Liu, X.; Shi, H.; Cao, J. Optimal subsampling for generalized additive models on large-scale datasets. Stat. Comput. 2025, 35, 1–17. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 12 February 2025).
- Smith, J.W.; Everhart, J.E.; Dickson, W.C.; Knowler, W.C.; Johannes, R.S. Using the ADAP learning algorithm to forecast the onset of diabetes mellitus. In Proceedings of the Annual Symposium on Computer Applications in Medical Care, New York, NY, USA, 9 November 1988; pp. 261–265. [Google Scholar]
- Kavakiotis, I.; Tsave, O.; Salifoglou, A.; Maglaveras, N.; Vlahavas, I.; Chouvarda, I. Machine learning and data mining methods in diabetes research. Comput. Struct. Biotechnol. J. 2017, 15, 104–116. [Google Scholar] [CrossRef]
- Çalişir, D.; Doğantekin, E. A new approach for hepatitis disease diagnosis: PCA–LDA based ANN. Biomed. Res. 2018, 29, 351–354. [Google Scholar]
- Chicco, D.; Jurman, G. Machine learning can predict survival of patients with heart failure from serum creatinine and ejection fraction alone. BMC Med. Inform. Decis. Mak. 2020, 20, 16. [Google Scholar] [CrossRef]
- Kumar, S.; Rani, P. A Comparative Survey on Machine Learning Techniques for Prediction of Liver Disease. In Proceedings of the 2023 6th International Conference on Contemporary Computing and Informatics (IC3I), Gautam Buddha Nagar, India, 14–16 September 2023; IEEE: New York, NY, USA, 2023; Volume 6, pp. 1796–1801. [Google Scholar]
- Bashir, S.; Qamar, U.; Khan, F.H. WebMAC: A web based clinical expert system. Inf. Syst. Front. 2018, 20, 1135–1151. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Olaniran, O.R.; Abdullah, M.A.A. Bayesian weighted random forest for classification of high-dimensional genomics data. Kuwait J. Sci. 2023, 50, 477–484. [Google Scholar] [CrossRef]
- Olaniran, O.R.; Alzahrani, A.R.R.; Alzahrani, M.R. Eigenvalue Distributions in Random Confusion Matrices: Applications to Machine Learning Evaluation. Mathematics 2024, 12, 1425. [Google Scholar] [CrossRef]
- Naz, H.; Ahuja, S. SMOTE-SMO-based expert system for type II diabetes detection using PIMA dataset. Int. J. Diabetes Dev. Ctries. 2022, 42, 245–253. [Google Scholar] [CrossRef]
- Olaniran, O.R.; Sikiru, A.O.; Allohibi, J.; Alharbi, A.A.; Alharbi, N.M. Hybrid Random Feature Selection and Recurrent Neural Network for Diabetes Prediction. Mathematics 2025, 13, 628. [Google Scholar] [CrossRef]
- Muntasir Nishat, M.; Faisal, F.; Jahan Ratul, I.; Al-Monsur, A.; Ar-Rafi, A.M.; Nasrullah, S.M.; Reza, M.T.; Khan, M.R.H. A Comprehensive Investigation of the Performances of Different Machine Learning Classifiers with SMOTE-ENN Oversampling Technique and Hyperparameter Optimization for Imbalanced Heart Failure Dataset. Sci. Program. 2022, 2022, 3649406. [Google Scholar] [CrossRef]
- Ishaq, A.; Sadiq, S.; Umer, M.; Ullah, S.; Mirjalili, S.; Rupapara, V.; Nappi, M. Improving the prediction of heart failure patients’ survival using SMOTE and effective data mining techniques. IEEE Access 2021, 9, 39707–39716. [Google Scholar]
- Srinivasan, S.; Gunasekaran, S.; Mathivanan, S.K.; M. B, B.A.M.; Jayagopal, P.; Dalu, G.T. An active learning machine technique based prediction of cardiovascular heart disease from UCI-repository database. Sci. Rep. 2023, 13, 13588. [Google Scholar]
- Janin, F.T.; Robin, F.A.; Ahmed, S.; Uddin, K.M.M. Unleashing Machine Learning for Hepatitis C Prediction: A Holistic Exploration of Clinical Insights. In Proceedings of the 2024 IEEE International Conference on Computing, Applications and Systems (COMPAS), Cox’s Bazar, Bangladesh, 25–26 September 2024; pp. 1–6. [Google Scholar]
- Lilhore, U.K.; Manoharan, P.; Sandhu, J.K.; Simaiya, S.; Dalal, S.; Baqasah, A.M.; Alsafyani, M.; Alroobaea, R.; Keshta, I.; Raahemifar, K. Hybrid model for precise hepatitis-C classification using improved random forest and SVM method. Sci. Rep. 2023, 13, 12473. [Google Scholar]
- Ganie, S.M.; Pramanik, P.K.D. A comparative analysis of boosting algorithms for chronic liver disease prediction. Healthc. Anal. 2024, 5, 100313. [Google Scholar] [CrossRef]
- Kuzhippallil, M.A.; Joseph, C.; Kannan, A. Comparative analysis of machine learning techniques for indian liver disease patients. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; IEEE: New York, NY, USA, 2020; pp. 778–782. [Google Scholar]
- Alizargar, A.; Chang, Y.L.; Tan, T.H. Performance comparison of machine learning approaches on hepatitis C prediction employing data mining techniques. Bioengineering 2023, 10, 481. [Google Scholar] [CrossRef]
- Ahammed, K.; Satu, M.S.; Khan, M.I.; Whaiduzzaman, M. Predicting infectious state of hepatitis c virus affected patient’s applying machine learning methods. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; IEEE: New York, NY, USA, 2020; pp. 1371–1374. [Google Scholar]
- Abdar, M.; Yen, N.Y.; Hung, J.C.S. Improving the diagnosis of liver disease using multilayer perceptron neural network and boosted decision trees. J. Med. Biol. Eng. 2018, 38, 953–965. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 


{kind=link}
{kind=link}