1. Introduction
With the advent of the big data era, various sectors are actively exploring the tremendous potential of data. In clinical diagnostics, accurately estimating the survival time of patients is a critical concern for both patients and healthcare professionals. Survival analysis is usually applied to address this issue, with the Cox proportional hazards model [
1] serving as a classic tool having long played an important role in evaluating disease risks and predicting patients’ survival time. However, due to its relatively simple structure, the traditional Cox proportional hazards model is limited in its ability to capture complex relationships among influencing factors [
2]. To overcome this limitation, Kvamme et al. [
3] proposed a hybrid model that integrates the Cox proportional hazards model with a neural network. This approach retains the advantages of the Cox model while leveraging deep learning techniques to capture complex nonlinear relationships, thereby improving the prediction accuracy. Nevertheless, the above studies predominantly relied on all data being stored in a certain central location.
Due to the decentralized and sensitive nature of healthcare data, such data are often isolated across different institutions, complicating effective sharing and integration [
4]. Federated learning, as an emerging distributed machine learning framework, offers the possibility to solve this problem. Federated learning allows different “centers”, a term used in this context to refer to medical institutions, to jointly train models without directly sharing the original data, thus enabling data collaboration while protecting privacy [
5]. Jung et al. [
6] proposed the LAFD framework, which consists of two parts: LFL-DFALS and AFL-LMTGR. LFL-DFALS reduces the computational and communication costs during the federated learning training process through direct feedback alignment and layer sampling. AFL-LMTGR handles the problem of stragglers through local model training and gradient rebalancing while ensuring data privacy. Amit Khanna et al. [
7] explored how to utilize federated learning to accelerate the drug development for Parkinson’s disease. They achieved this by effectively sharing and analyzing data while protecting patients’ privacy. They emphasized the potential of digital health technologies in improving the assessment and monitoring of Parkinson’s disease. Amandeep Singh Bhatia et al. [
8] proposed a federated learning framework based on quantum tensor networks, named FedQTN, for processing medical image data, demonstrating significant improvements in model performance while ensuring privacy. G. Yue et al. [
9] introduced a specificity-aware federated learning framework that employs an adaptive aggregation mechanism (AdapAM) and a dynamic feature fusion strategy (DFFS) to deal with the model specificity and class imbalance issues in medical image classification. Although federated learning provides a new approach for data privacy protection, it also has some security risks. Studies by Zhu et al. [
10] and Geiping et al. [
11] demonstrated that local data can be inferred by analyzing parameter gradients, which implies that relying solely on federated learning is not sufficient to fully protect data privacy.
Currently, differential privacy, as a rigorous privacy protection model, achieves a balance between privacy protection and model performance by adding noise to the data and is a primary means of privacy protection within the federated learning framework [
12]. The user-level differential privacy federated learning framework proposed by Geyer et al. [
13] was further optimized by Zhao et al. [
14] and Nuria et al. [
15]. For the federated averaging algorithm (FedAvg), noise is added during the model aggregation stage to implement differential privacy. Subsequently, Abadi et al. [
16] achieved significant improvement in differential privacy algorithms by proposing an adaptive noise addition mechanism that dynamically adjusts noise levels according to the sensitivity of model parameters. Dwork et al. [
17] provided a significant basis for understanding the theoretical boundaries of the privacy–utility trade-off. Rieke et al. [
18] focused on differential privacy protection in the medical field, where sensitive information such as genetic sequences and medical histories is prevalent. They proposed a hierarchical privacy protection strategy that processes the features of medical data with different sensitivity levels during the data preprocessing stage, applying strict differential privacy to genetic data while employing relatively looser protections for clinical symptom data. This strategy effectively protects patients’ privacy and improves the accuracy of disease prediction models. The Adap DPFL scheme proposed by Fu et al. [
19] adaptively clips the gradients according to the gradient heterogeneity of training parameters and adds decreasing noise based on the gradient convergence. Experimental results indicated that this scheme outperforms previous methods on real datasets. The AdaDpFed algorithm proposed by Zhao et al. [
20] is an adaptive federated differential privacy protocol designated for a non-independent and identically distributed environment. It can adaptively adjust perturbation parameters, client aggregation, and sampling size according to individual data distribution changes. The proof of convergence indicates the convergence rate of
, and comparative experiments show that its performance is superior to other advanced protocols, providing an effective privacy protection solution for federated learning in such environment. The adaptive privacy protection framework proposed by Hu et al. [
21] considers dynamic allocation of privacy budgets, focusing on the impact of weight changes in the input layer on model performance to dynamically adjust privacy budgets. However, the above methods did not consider the historical information of gradients and the impact of all parameter changes on the performance of data models during the training process.
To address these limitations, this paper proposes an adaptive differential privacy framework applicable to the deep learning Cox model in a federated learning environment. Our contributions are as follows.
We integrate deep learning, differential privacy, and the Cox proportional hazards model into a federated learning framework, proposing a novel privacy-preserving method for survival analysis. By ensuring data privacy, it addresses challenges such as uneven data distribution, difficulties in data sharing, and limited computational resources, thereby effectively supporting medical research and clinical decision making.
We comprehensively consider both the degree of dispersion and the magnitude of the absolute values of all weights. For weights that change significantly or have higher absolute values during the training process, we propose to add less noise; conversely, more noise can be added.
We quantify the impact of weight changes in different layers on model performance and allocate privacy budgets adaptively based on the impact of weight. This enables us to maintain the performance of the model as much as possible while protecting privacy.
The rest of this paper is organized as follows: In
Section 2, we discuss the Cox-MLP algorithm based on federated learning with differential privacy. In
Section 3, we introduce the methods for implementing adaptive privacy budget allocation in federated learning (FL).
Section 4 and
Section 5 present the experimental evaluation and results, and
Section 6 gives the summary and conclusions.
2. Model and Notation
In this section, we delve into the integration of federated learning algorithms with differential privacy into the Cox-MLP model. First, we give some notations in
Table 1.
In parametric models, the essence of data privacy fundamentally resides in the protection of model parameters. We consider a federated learning system comprising N centers, where each center i () manages a local dataset with samples. The survival times are denoted by , where . Here, represents the true survival time, and denotes the censoring time. The censoring indicators are given by , with serving as the indicator function to distinguish between observed and censored survival times. Additionally, represents the covariates associated with center i, where .
2.1. Cox-MLP Model
We first consider that, in the traditional Cox model, it is assumed that the relationship between the log hazard ratio and the covariates is linear. The hazard function of center
i [
1] is
where
is the baseline hazard function,
is the relative hazard function, the covariate
is the covariate that affects the survival time, and
is the parameter vector. The likelihood function of center
i is
However, in complex problems, the Cox model will fail to meet the precision requirements. We consider achieving precise fitting of complex structures through neural networks. Katzman et al. [
22] indicate that the Cox model combined with deep neural networks has better flexibility and outperforms the traditional Cox model in terms of the concordance index.
Similar to Kvamm et al. [
3], we process the entire dataset in batches and introduce weights
. Then the risk set
is restricted to only include the individuals in the current batch, which is denoted as
. At this time, the partial likelihood function and the loss function of the traditional Cox model of center
i are redefined as
For the combination of neural networks and the Cox proportional hazards model, after determining the loss function, the aim is to enhance the robustness of parameter estimation. A penalty term as (
5) is incorporated to constrain the complexity of the model. This leads to a more precise estimation of
,
The proportionality assumption of the Cox model is quite strict. However, the neural network parameterized Cox model cannot relax this constraint. To avoid this limitation, it is common to group the data according to categorical covariates and apply the stratified version of the Cox model [
23]. Kvamm et al. [
3] proposed an innovative method that does not require grouping, making the relative risk function
depend on the covariates
and time
t, thus constructing a more flexible interaction model of center
i Model (
6) is regarded as a non-proportional relative risk model under dynamic covariate adjustment, and thus the loss function of center
i is redefined as
The above loss function still needs to take the penalty term (
5) into consideration. By combining the Cox model with neural networks to estimate parameters and performing iterative optimization on the loss function (
7), the parameter estimate
is obtained. Furthermore, the cumulative baseline hazard rate is accurately estimated through the Breslow estimator as
If it is necessary to evaluate the survival probability of patients, the survival function can be characterized by the cumulative baseline hazard rate as
2.2. Federated Learning
Federated learning is a distributed machine learning framework designed to enable the training of local models using datasets distributed across multiple centers. These locally trained models are then aggregated to collaboratively construct a global model. Throughout the training process, only model parameters are exchanged among the participating centers, while the local datasets
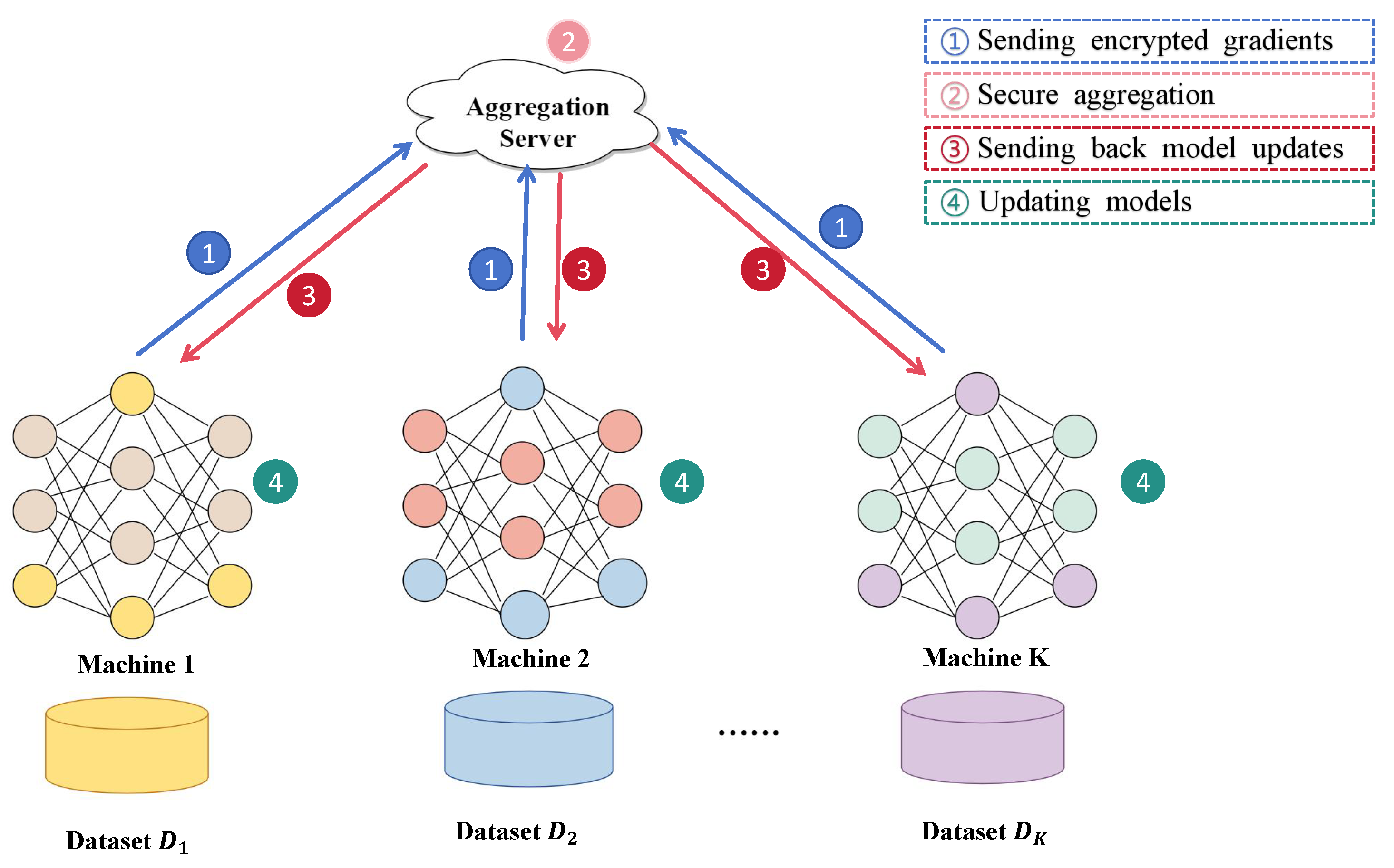
remain securely stored at their respective sources. This approach ensures the privacy of local data, enhances data security, and significantly mitigates the risk of privacy breaches. A typical federated learning system is illustrated in
Figure 1. In this setup, centers with identical attribute spaces collaborate under the coordination of a parameter aggregation server to optimize and develop a high-performing global model [
16].
Within this architecture, the algorithm iteratively processes data until predefined convergence criteria are met, or until the maximum number of iterations or training time is reached.The process of the federated learning algorithm we consider is shown in Algorithm 1.
| Algorithm 1 Federated learning algorithm |
| Input: Server: Initial global model , total rounds T |
| Centers: Local datasets , local epochs E |
| Output: Optimized global model |
| for round do |
| Server executes: |
| Broadcast current global model to all centers |
| Centers parallel execute: |
| Local training: |
| Initialize local model: |
| for epoch to E do |
| Split into batches of size B |
| for each batch do |
| |
| |
| Server aggregates: |
| Receive updates |
| Compute weighted average: |
| |
| end |
2.3. Differential Privacy
In this paper, we primarily focus on global differential privacy within the specific context of federated learning. The implementation of the Laplacian mechanism [
20] is relatively intricate within this framework, whereas the Gaussian mechanism is considered more suitable due to its advantageous additivity property. We emphasize differential privacy under the Gaussian mechanism. To introduce the mechanism, we first briefly discuss the concept of (
,
)-approximate differential privacy.
Definition 1 (
-approximate differential privacy).
For neighboring datasets that differ in exactly one data record, there exists an algorithm g that its any output satisfies the inequalitythen the algorithm g satisfies differential privacy, where denotes the probability of an event occurring, e is the natural base, and ε is a privacy budget. Approximate differential privacy introduces an additional privacy parameter, , compared with strict differential privacy. This parameter controls the failure rate of differential privacy: the smaller the value, the higher the privacy. In general, a smaller value of will be taken to improve the usability of the algorithm under the same privacy protection conditions.
Definition 2 (Gaussian mechanism).
The core concept of the Gaussian mechanism is to achieve differential privacy protection by adding a random noise that follows a specific Gaussian distribution to the output result of a function. For a given dataset D and an arbitrary function , where the global sensitivity of g is , the algorithmsatisfies differential privacy with 3. The Cox-MLP Based on FL with Differential Privacy
We consider the client–server architecture of the federated learning system, whose structure is shown in
Figure 1. In such a system,
N centers with the same attribute space, with the coordination and assistance of the parameter aggregation server [
24], jointly collaborate to optimize the loss
To ensure the privacy of individual data during the training process, similar to Wei [
25], we adopt the differential privacy mechanism when uploading parameters from centers to the server. Specifically, to achieve
differential privacy, that is, for neighboring datasets
D and
with exactly one different data record, any output result
Y (
) of the algorithm
g satisfies inequality
. We need to add noise from the normal distribution
to each parameter. The calculation formula for the standard deviation of the noise is
where
c is a constant, and
.
L represents the maximum number of exposure times during the process of uploading local parameters to the server, and
is the global sensitivity. If
C is the clipping scale of the gradient during the training process in the center, and the minimum value among the data amounts contained in each center is
m, then the sensitivity
. However, Wei [
24] shows that as the times of iterations increases, the risk of privacy leakage will also increase. Therefore, it is necessary to perturb the parameters before the centers upload them, and then the server aggregates the received parameters. In order to maintain the global (
)-differential privacy, the server also needs to add Gaussian noise to the parameters according to the training process and then distribute the randomly perturbed parameters to each center. The added noise follows the following normal distribution
, where the standard deviation
is calculated according to the global iteration number
T and the number of centers participating in the training
N as
In this manner, the Cox-MLP model demonstrates its superiority in not only fitting complex data relationships better but also protecting data privacy throughout the entire distributed training process. During the training process, the noise added for privacy protection will inevitably affect the performance of the model. To alleviate this problem, we then propose a method based on weight importance to dynamically adjust the magnitude of the noise in differential privacy.
3.1. Adaptive Differential Privacy Based on Layer Sensitivity (LS-ADP)
To balance privacy protection and model performance, in this paper, we propose two methods based on weight importance. The key to the method lies in quantifying the impact of each layer’s weights on the model performance and dynamically adjusting the magnitude of the noise in differential privacy according to this metric.
We consider adopting the idea of random perturbation. Our method evaluates the impact of each weight change on the model’s performance and adjusts the privacy budget allocation strategy dynamically based on this evaluation.
To reduce the computational load, instead of adding random perturbations to each weight
, we apply the same random noise to all weights in a layer, and add the same random perturbation to all the weights in this layer. Then we calculate the change in the model performance to evaluate the impact of the weight change in this layer. Specifically, after the local training is completed, we first calculate the evaluation index value
p of the model without random perturbations as a benchmark. Under the condition that other weights remain unchanged, we add random noise
to all the weights
in the
i-th layer of the model to obtain the weights
, that is,
where
,
, and
represents the number of weights in the
i-th layer.
c is a constant, and
, ensuring that the Gaussian mechanism satisfies
-DP requirements.
L is the maximum times of exposures during the process of uploading local parameters to the server.
is the global sensitivity,
is the privacy budget, and
is the probability of privacy leakage. Through the perturbed model, to re-evaluate the model performance, new evaluation index values
(
) are obtained, where
K is the number of layers of weights in the neural network. Calculate the performance change by
to measure the impact of weight changes in this layer on model performance. The numerator
quantifies the absolute change in performance caused by the perturbation. This value reflects the sensitivity of the model performance to changes in that particular layer. Based on
, the privacy budget of weights in the
ith layer can be obtained as
where
represents the total privacy budget. If
is relatively large, it indicates that even a slight change in the weights of this layer will lead to a significant change on the model performance. Therefore, a larger privacy budget should be allocated to the weights of this layer so that less noise will be added. Conversely, if
is relatively small, it means that the change in the weights of the layer causes a minor impact on the model performance. Thus, a smaller privacy budget is allocated; that is, more noise can be added.
3.2. Random One-Layer Weighted Differential Privacy Algorithm (ROW-DP)
During the training process of neural networks, the gradient descent method is commonly employed to update the weights. Weights that have a significant impact on the model performance usually undergo relatively large changes. Therefore, we take the degree of dispersion of each weight during the local iteration process as an evaluation indicator to assess its importance. Commonly used metrics include variance (Var), standard deviation (Std), range (Range), interquartile range (IQR), and mean absolute error (MAE). Furthermore, some weights may already be near optimal at initialization, exhibiting low dispersion and potentially being underestimated in their contribution to model performance.
To this end, a comprehensive importance measure
for the
j-th weight
of the
i-th layer is defined as
where
represents the measures of dispersion of the weight
, which indicates how much the weight fluctuates during the local iterations.
, with
m denoting the number of local iterations, and
is the absolute value of the weight obtained from the last local iteration. Larger magnitudes can contribute more significantly to the model’s predictions. Based on the value of
, an adaptive privacy budget allocation can be achieved. Specifically, the privacy budget allocated to the weight
is
where
represents the total privacy budget. If
is relatively large, it indicates that the change of
has a significant impact on the model performance. Therefore, a larger privacy budget should be allocated to this weight, and less noise should be added. Conversely, a larger privacy budget should be allocated if
is relatively small.
When employing the above strategy for privacy protection, if weighted noise is added to the weights of all nodes, excessive noise may be added to the weights of some nodes, resulting in an unstable fitting process. Based on this, we propose a random one weighted layer method (ROW-DP) on top of the original algorithm. That is, the weights of one layer of the neural network are randomly selected to conduct the above adaptive privacy budget allocation, while the same Gaussian-mechanism differential privacy noise is added to the weights of other layers, enabling our algorithm to possess better stability during the training process while increasing randomness. The privacy budget allocation is as
where
is the number of weights contained in the layer.
In this way, it can not only effectively protect data privacy but also minimize the impact of privacy protection measures on the model’s predictive performance. This adaptive noise addition strategy can achieve a balance between privacy protection and model utility. The specific steps are as shown in Algorithm 2, as detailed below, with the proofs provided in
Appendix A.
| Algorithm 2 Adaptive hierarchical differential privacy optimization framework |
| Input: Server: Initial global model , total rounds T |
| Centers: Local datasets ,local epochs E |
| Output: Optimized global model |
| for round do |
| Server executes: |
| Broadcast current global model to all centers |
| Centers parallel execute: |
| Local training: |
| Initialize local model: |
| for epoch to E do |
| Split into batches of size B |
| for each batch do |
| |
| For each weight in the neural network : |
| Calculate according to (14) or (16). |
| . |
| |
| End |
| End |
| Server aggregates: |
| Receive updates |
| Compute weighted average: |
| |
| The noise variance is calculated by (13), |
| end |
In the next section, we will validate the performance of our algorithm on both simulated and real datasets, comparing it with the NbAFL algorithm. NbAFL assigns equal privacy budgets to each weight before aggregation and broadcasting, without considering the differences between weights. Our algorithm, on the other hand, takes into account the importance of each weight, resulting in better performance in the numerical experiments.
4. Simulation Studies
In this section, we employ simulated data generation to validate the efficacy of our algorithm. We randomly generate the variables and from normal distributions, from a binomial distribution, and from uniform distributions, forming the covariate vector . Subsequently, we sample survival times from the hazard function and censored times from , resulting in data with a 30% censored rate.
For the simulation setup, we assume a baseline hazard function
and parameters
, with
. We generate 50,000 data points and partition them into a training set (70%) and a testing set (30%). We allocate average privacy budgets of 0.6, 0.7, 0.8, and 0.9 to the weights. Using centers
and global iterations
, we train our model using both the random one-layer weighted differential privacy (ROW-DP) and the adaptive differential privacy based on layer sensitivity (LS-ADP) algorithms. To assess the performance of our proposed algorithm, we conducted 100 independent experiments and compared the results with the NbAFL algorithm [
25]. The NbAFL algorithm ensures privacy protection by assigning an equal privacy budget to each weight during both the upload and broadcast phases. Furthermore, we used the Cox-MLP algorithm [
22] without differential privacy (Npdp) as a baseline for comparison.
Given the complexities inherent in neural networks, the coefficients associated with each covariate cannot be directly obtained. Therefore, we primarily evaluate our model using the Brier Score and the Integrated Negative Log-Likelihood (INLL). The Brier Score (BS), which ranges from 0 to 1, measures the Mean Squared Error (MSE) between the predicted survival probabilities and the true survival status, with 0 indicating perfect prediction and 1 indicating no predictive value. In survival analysis, for each time point t, the Negative Log-Likelihood gauges the discrepancy between the model’s predicted survival probability and the observed outcome. The Integrated Negative Log-Likelihood, by integrating the Negative Log-Likelihood over all time points, provides a comprehensive evaluation metric, where a lower value implies superior model performance.
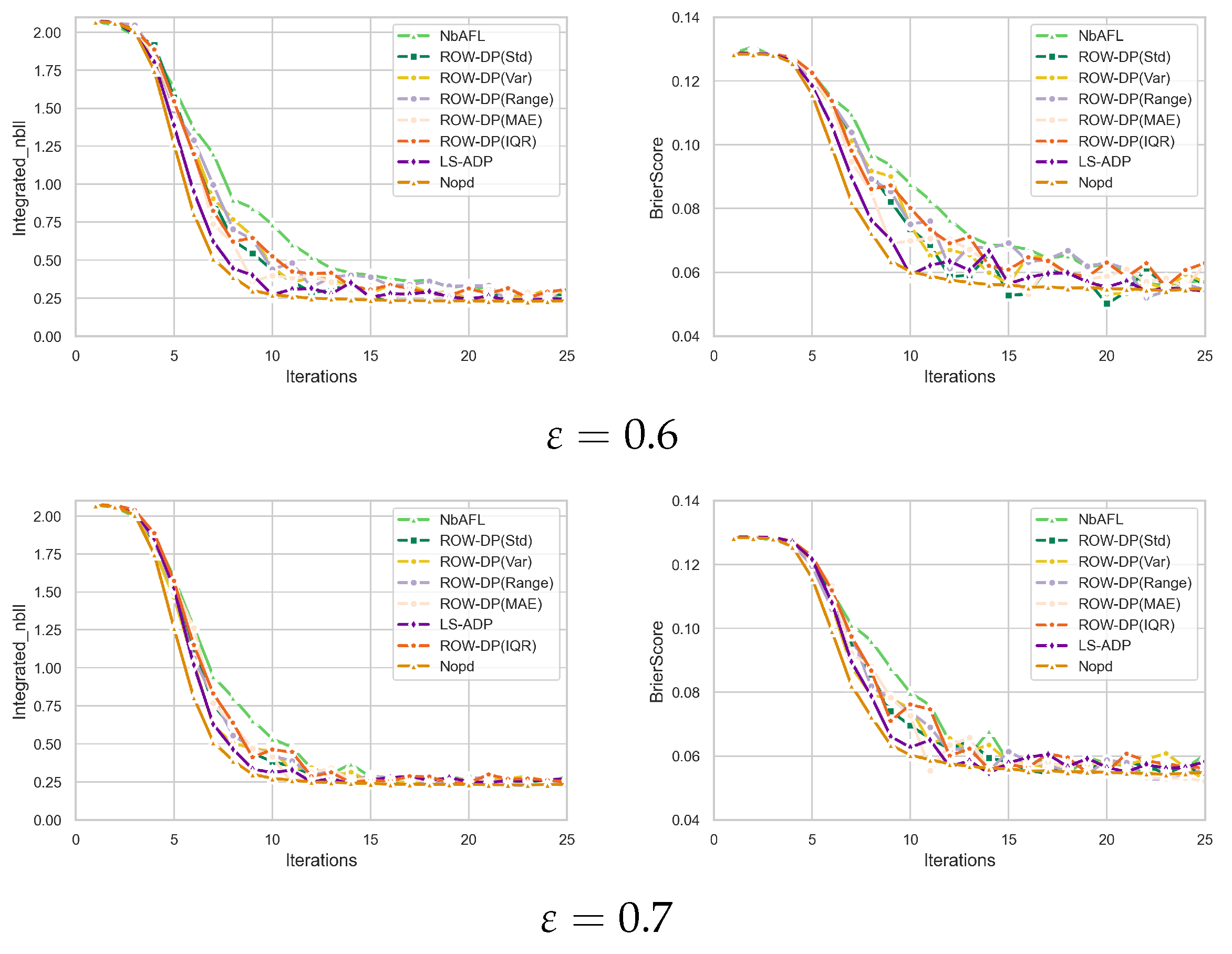
Figure 2 and
Table 2 and
Table 3 demonstrate that an increase in privacy budget leads to a gradual reduction in noise added during training, and then the influence of differential privacy on models diminishes progressively. Notably, when
≥ 0.8, the difference in INLL between ROW-DP/LS-ADP and Nopd narrows to within 0.5%, validating that the impact of DP on model performance becomes negligible at this stage. Under a low privacy budget (
= 0.6), the LS-ADP method achieves an INLL of 0.2560 and a BS of 0.0551, which are notably superior to NbAFL’s INLL of 0.2753 and BS of 0.0592. This performance advantage is primarily attributable to LS-ADP’s incorporation of weight importance, which enables a more nuanced and refined allocation of the privacy budget. ROW-DP, by employing random single-layer weighting, concentrates noise on layers with lower sensitivity, thereby reducing perturbations to critical parameters. For example, ROW-DP(Var) achieves an INLL of 0.2681 at
= 0.6, representing a 2.6% (0.2681 vs. 0.2753)) improvement over NbAFL. LS-ADP, which dynamically adjusts noise based on layer sensitivity, further optimizes the allocation of the privacy budget. At
= 0.6, LS-ADP’s BS is reduced by 3.2% (from 0.0569 to 0.0551) compared with ROW-DP(Var), indicating that its finer control over the distribution of noise provides a distinct advantage. The impact of different dispersion measurement methods on the performance of ROW-DP is significant. For example, at
= 0.7, ROW-DP(MAE) achieves an INLL of 0.2683, which is 5.196 higher than ROW-DP(Std)(0.2553), indicating that MAE is more sensitive to noise. In contrast, ROW-DP(IQR) achieves an INLL of 0.2365 at
= 1, which is close to Nopd (0.2309), suggesting that IQR effectively balances noise and model performance under high privacy budgets. This phenomenon suggests that selecting robust dispersion metrics, such as IQR, can further enhance the algorithm’s performance under stringent privacy constraints. Moreover, across all privacy budgets tested, ROW-DP and LS-ADP exhibited performance comparable to or superior to the NbAFL algorithm. Particularly with smaller privacy budgets, when noise levels are higher, ROW-DP and LS-ADP significantly surpass the NbAFL algorithm. This phenomenon can be primarily attributed to an enhanced privacy allocation strategy that mitigates the effects of differential privacy on the performance of the model.
5. A Real Example of LS-ADP and ROW-DP
To validate the utility of our algorithm, we utilize real-world data, the Free Light Chain (FLCHAIN) dataset compiled by T. Therneau et al. The FLCHAIN dataset encompasses 7874 entries, including 9 covariates, as well as survival time and survival status information at the last known contact for each patient. Additionally, 28% of these data points feature censored survival times. Initial data preprocessing includes handling missing covariate values through multiple imputation and subsequent standardization.
To gauge the effectiveness of our algorithm, we employ the C-index, as proposed by Harrell et al. [
26]. This index measures the proportion of patient pairs for whom all available predictions align with actual outcomes, indicating the proportion of patients with lower predicted risks who actually exhibit longer survival times. However, the presence of censored data within the dataset can render certain patient pairs ineligible for C-index computation. Specifically, such pairs are deemed unusable and excluded if both patients are censored or if one patient’s censored time precedes the other’s survival time. The C-index ranges from 0 to 1, with 0.5 suggesting model performance equivalent to random guessing, indicating a lack of predictive ability beyond chance. For predictive evaluation, the dataset is randomly divided into an 80% training set and a 20% test set. The average privacy budgets are 3, 4, 5, and 7, and the experiment was conducted 100 times.
Table 4 and
Figure 3 demonstrate that the addition of noise in differential privacy diminishes with an increasing privacy budget, which leads to a decreasing influence on model performance and a more stable convergence of the C-index. A comparison of various noise addition methods reveals that, in experiments utilizing instance survival data, the performance discrepancy between the NbAFL and ROW-DP algorithms is negligible. LS-ADP achieves 1.7% higher C-index than NbAFL at
(0.7627 vs. 0.7361), narrowing to 0.3% at
(0.7701 vs. 0.7676). For
, all algorithms reach
of Nopd’s performance (0.7701). LS-ADP maintains a
C-index across all
, outperforming ROW-DP variants by 2.1–5.3%. In contrast, the LS-ADP algorithm achieves superior performance, particularly in terms of convergence speed and stability when applied across diverse privacy budgets. Notably, when the privacy budget is low, the advantages of LS-ADP become more pronounced, enabling the accommodation of a higher-performance model while ensuring adequate privacy protection.
6. Conclusions
In this paper, we propose a novel privacy budget allocation mechanism. Relying on the relationship between historical changes in parameters and the model performance, we develop a new federated learning algorithm with differential privacy. The innovation of it lies in achieving adaptive privacy budget allocation based on the relationship between parameter changes and model performance. Our results demonstrate that, while maintaining a fixed total privacy budget, both proposed methods effectively balance the trade-off between global differential privacy protection and global model performance. Notably, under smaller privacy budgets, the ROW-DP and LS-ADP algorithms outperform existing methods, such as NbAFL, which lack well-considered differential privacy budget allocation mechanisms, in metrics such as Integrated Negative Log-Likelihood and Brier Score. Furthermore, LS-ADP demonstrates superior accuracy and stability, making it more suitable for scenarios requiring high model performance. On the other hand, ROW-DP, with its simplicity and lower computational overhead, is better suited for resource-constrained applications. The distinctive characteristics of these two methods offer flexible solutions to meet different practical demands. However, this study does not fully address the adaptability of privacy budget allocation in more complex network structures and in scenarios involving non-independent and identically distributed (Non-IID) data. Currently, the differential privacy protection mechanisms we are discussing are far from sufficient for ensuring privacy protection. Attackers may carry out membership inference attacks, model inversion attacks, attribute inference attacks, data re-identification attacks, and data poisoning attacks. Overall, although research on Cox-MLP differential privacy provides a powerful tool for protecting specific models, in the face of various potential privacy threats, we still need to comprehensively utilize multiple technical means (such as encryption, secure multi-party computation, and access control) to build a more comprehensive and robust data protection system. These limitations will be explored and addressed in future research.
Author Contributions
Conceptualization, J.N.; project administration, J.N.; methodology, J.N. and R.H.; formal analysis, J.N.; software, R.H. and J.N.; validation, J.N., R.H. and Q.Z.; visualization, W.L. and Q.Z.; writing—original draft, J.N., Q.Z., R.J., R.H. and W.L.; writing—review and editing, D.C., H.L., R.H. and J.N.; supervision, D.C.; resources, D.C. and H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key R&D Program of China (Grant No. 2022YFA1003701); Open Research Fund of Yunnan Key Laboratory of Statistical Modeling and Data Analysis, Yunnan University (Grant No. SMDAYB2023004); and Research and Innovation Project for Exempt Postgraduate Students, Yunnan University (Grant No. TM-23236998).
Data Availability Statement
The data presented in this study are available on request from the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Proofs
The appendices provide a proof demonstrating the satisfaction of differential privacy by Algorithm 2.
We establish the proof that Algorithm 2 adheres to differential privacy. However, prior to presenting the proof, it is essential to introduce the following Lemma A1.
Lemma A1. During the aggregation of federated learning models, the clipping scale of model gradients is denoted by C, while the amount of local data at the central hub is m. There are a total of N central hubs, each with equal aggregate weights. The global sensitivity of the model is expressed as Assume that the total privacy budget is ; for each weight between neural network nodes, the privacy budget assigned to each is , resulting in , where , and M represents the total number of weights.
Leveraging Lemma A1, the global differential privacy sensitivity is . For a given weight , during the noise addition for differential privacy, we have the process , with as the Gaussian noise added.
Given the objective function as a real-valued function,
, where
and
represent L1 and L2 sensitivities, respectively. Hence,
, so that
, and Equation (
A2) can be equivalently written as
hence, the condition
is required, where
. Consequently, strict differential privacy adherence is not feasible, leading to the adoption of approximate differential privacy, which allows for a degree of privacy leakage. From
, we obtain
to manage the risk of privacy leakage within
, ensuring that
Considering the symmetry of the normal distribution, we set
, which leads to
Define
and
, which implies that
These results simplify to
Substituting
into Equation (
A3) yields
Let
; then Equation (
A5) is equivalent to
For the first equation in (
A6), if
, with
,
,
, and
,
. For the second equation in (
A6),
, given
,
, we have
. Since
, to make
valid, we require
. Thus,
which is
; thus,
. Then,
Thus,
, and
, implying
holds true. That is, when
,
,
is valid. Furthermore, it can be said that
is valid, satisfying approximate differential privacy.
Therefore, for Algorithm 2, given that the added noise
is independently and identically distributed, for all weights in the neural network, there exists
so Algorithm 2 achieves (
)-differential privacy.
References
- Cox, D.R. Regression Models and Life-Tables. J. R. Stat. Soc. Ser. B Methodol. 1972, 34, 187–220. [Google Scholar] [CrossRef]
- Therneau, T.M.; Grambsch, P.M. Modeling survival data: Extending the Cox model. In Statistics for Biology and Health; Springer: New York, NY, USA, 2000. [Google Scholar]
- Kvamme, H.; Borgan, Ø.; Scheel, I. Time-to-event prediction with neural networks and Cox regression. J. Mach. Learn. Res. 2019, 20, 1–30. [Google Scholar]
- Yin, L.; Feng, J.; Xun, H.; Sun, Z.; Cheng, X. A privacy-preserving federated learning for multiparty data sharing in social IoTs. IEEE Trans. Netw. Sci. Eng. 2021, 8, 2706–2718. [Google Scholar]
- Xu, J.; Glicksberg, B.S.; Su, C.; Walker, P.; Bian, J.; Wang, F. Federated learning for healthcare informatics. J. Healthc. Inform. Res. 2021, 5, 1–19. [Google Scholar] [PubMed]
- Jung, K.; Baek, I.; Kim, S.; Chung, Y.D. LAFD: Local—Differentially Private and Asynchronous Federated Learning with Direct Feedback Alignment. IEEE Access 2023, 11, 86754–86769. [Google Scholar] [CrossRef]
- Khanna, A.; Adams, J.; Antoniades, C.; Bloem, B.R.; Carroll, C.; Cedarbaum, J.; Cosman, J.; Dexter, D.T.; Dockendorf, M.F.; Edgerton, J.; et al. Accelerating Parkinson’s Disease drug development with federated learning approaches. NPJ Park. Dis. 2024, 10, 225. [Google Scholar]
- Bhatia, A.S.; Neira, D.E.B. Federated learning with tensor networks: A quantum AI framework for healthcare. Mach. Learn. Sci. Technol. 2024, 5, 045035. [Google Scholar] [CrossRef]
- Yue, G.; Wei, P.; Zhou, T.; Song, Y.; Zhao, C.; Wang, T.; Lei, B. Specificity-Aware Federated Learning with Dynamic Feature Fusion Network for Imbalanced Medical Image Classification. IEEE J. Biomed. Health Inform. 2024, 28, 6373–6383. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Liu, Z.; Han, S. Deep leakage from gradients. Adv. Neural Inf. Process. Syst. 2019, 32, 1–11. [Google Scholar]
- Geiping, J.; Bauermeister, H.; Dröge, H.; Moeller, M. Inverting gradients-how easy is it to break privacy in federated learning? Adv. Neural Inf. Process. Syst. 2020, 33, 16937–16947. [Google Scholar]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical Secure Aggregation for Privacy-Preserving Machine Learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1132–1147. [Google Scholar]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially Private Federated Learning: A Client Level Perspective. arXiv 2017, arXiv:1712.07557. [Google Scholar]
- Zhao, C.X.; Sun, Y.; Wang, D.G. Federated learning with Gaussian differential privacy. In Proceedings of the IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 296–301. [Google Scholar]
- Rodríguez-Barroso, N.; Stipcich, G.; Jiménez-López, D.; Ruiz-Millán, J.A.; Martínez-Cámara, E.; González-Seco, G.; Luzón, M.V.; Veganzones, M.A.; Herrera, F. Federated Learning and Differential Privacy: Software tools analysis, the Sherpa.ai FL framework and methodological guidelines for preserving data privacy. Inf. Fusion 2020, 64, 270–292. [Google Scholar] [CrossRef]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletari, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with federated learning. NPJ Digit. Med. 2020, 3, 1–7. [Google Scholar]
- Fu, J.; Chen, Z.; Han, X. Adap DP-FL: Differentially Private Federated Learning with Adaptive Noise. In Proceedings of the 2022 IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Wuhan, China, 9–11 December 2022; pp. 1–6. [Google Scholar]
- Zhao, Z.; Sun, Y.; Bashir, A.K.; Lin, Z. AdaDpFed: A Differentially Private Federated Learning Algorithm with Adaptive Noise on Non-IID Data. IEEE Trans. Consum. Electron. 2024, 70, 2536–2545. [Google Scholar]
- Hu, J.; Wang, Z.; Shen, Y.; Lin, B.; Sun, P.; Pang, X.; Liu, J.; Ren, K. Shield Against Gradient Leakage Attacks: Adaptive Privacy-Preserving Federated Learning. IEEE/ACM Trans. Netw. 2023, 32, 1407–1422. [Google Scholar] [CrossRef]
- Katzman, J.L.; Shaham, U.; Cloninger, A.; Bates, J.; Jiang, T.; Kluger, Y. DeepSurv: Personalized treatment recommender system using a Cox proportional hazards deep neural network. BMC Med. Res. Methodol. 2018, 18, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Klein, J.P.; Moeschberger, M.L. Survival Analysis: Techniques for Censored and Truncated Data, 2nd ed.; Springer: New York, NY, USA, 2003. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar]
- Harrell, F.E.; Lee, K.L.; Mark, D.B. Multivariable prognostic models: Issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat. Med. 1996, 15, 361–387. [Google Scholar] [PubMed]
Figure 1.
Client–server architecture.
Figure 1.
Client–server architecture.
Figure 2.
Under different privacy budgets ( = 0.6, 0.7, 0.8, 0.9, 1.0), Integrated Negative Log-Likelihood and Brier Score for Cox-MLP (Nopd) algorithm, LS-ADP algorithm, and ROW-DP algorithm based on five discrete degree measurement methods (Var, Range, Std, MAE, IQR).
Figure 2.
Under different privacy budgets ( = 0.6, 0.7, 0.8, 0.9, 1.0), Integrated Negative Log-Likelihood and Brier Score for Cox-MLP (Nopd) algorithm, LS-ADP algorithm, and ROW-DP algorithm based on five discrete degree measurement methods (Var, Range, Std, MAE, IQR).
Figure 3.
Function of C-index of interaction count using seven different colors to represent various privacy budget allocation methods.
Figure 3.
Function of C-index of interaction count using seven different colors to represent various privacy budget allocation methods.
Table 1.
Notations.
| Notation | Description | Notation | Description |
|---|
| N | Number of centers | | Number of weights in the i-th layer |
| Local dataset of center i | | Perturbed weights after adding random noise to the i-th layer |
| Number of samples in center i’s dataset | | Global sensitivity |
| Matrix of covariates associated with samples in center i’s dataset | | Privacy budget parameter |
| Vector of survival times for each sample in center i’s dataset | | Probability of privacy leakage |
| Vector of censoring indicators for each sample in center i’s dataset | | New evaluation index values |
| Censoring time for sample j at center i | K | Number of layers of weights in the neural network |
| Parameter vector | | Privacy budget of weights in the ith layer |
| Baseline hazard function | | The jth weight of the ith layer |
| Risk set restricted to only include individuals in the current batch | | Measures of dispersion of the weight |
| Weight of dataset of Cox-MLP | m | Number of local iterations |
| Regularization parameter | | Weight value obtained from the last local iteration |
| T | Total number of training rounds | | Absolute value of the local weight |
| Learning rate for updates | | Variance of the noise added to the weights |
| Random noise added to the i-th layer’s weights | | Weight assigned to the update from center i |
Table 2.
Integrated Negative Log-Likelihood for Cox-MLP (Nopd), LS-ADP, and ROW-DP algorithms under different privacy budgets () based on five dispersion measurement methods (Var, Range, Std, MAE, IQR).
Table 2.
Integrated Negative Log-Likelihood for Cox-MLP (Nopd), LS-ADP, and ROW-DP algorithms under different privacy budgets () based on five dispersion measurement methods (Var, Range, Std, MAE, IQR).
| Privacy Budget | 0.6 | 0.7 | 0.8 | 0.9 | 1 |
|---|
| NbAFL | 0.2753 | 0.2613 | 0.2581 | 0.2446 | 0.2359 |
| ROW-DP(Std) | 0.2726 | 0.2553 | 0.2541 | 0.2498 | 0.2476 |
| ROW-DP(Var) | 0.2681 | 0.2596 | 0.2572 | 0.2530 | 0.2456 |
| ROW-DP(Range) | 0.2686 | 0.2594 | 0.2567 | 0.2464 | 0.2455 |
| ROW-DP(MAE) | 0.2692 | 0.2683 | 0.2593 | 0.2515 | 0.2450 |
| ROW-DP(IQR) | 0.2690 | 0.2600 | 0.2554 | 0.2528 | 0.2365 |
| LS-ADP | 0.2560 | 0.2551 | 0.2550 | 0.2464 | 0.2455 |
| Nopd | 0.2309 | 0.2309 | 0.2309 | 0.2309 | 0.2309 |
Table 3.
Brier Score log-likelihood for Cox-MLP(Nopd), LS-ADP, and ROW-DP algorithms under different privacy budgets () based on five dispersion measurement methods (Var, Range, Std, MAE, IQR).
Table 3.
Brier Score log-likelihood for Cox-MLP(Nopd), LS-ADP, and ROW-DP algorithms under different privacy budgets () based on five dispersion measurement methods (Var, Range, Std, MAE, IQR).
| Privacy Budget | 0.6 | 0.7 | 0.8 | 0.9 | 1 |
|---|
| NbAFL | 0.0592 | 0.0572 | 0.0549 | 0.0548 | 0.0542 |
| ROW-DP(Std) | 0.0577 | 0.0560 | 0.0553 | 0.0543 | 0.0545 |
| ROW-DP(Var) | 0.0569 | 0.0562 | 0.0555 | 0.0552 | 0.0546 |
| ROW-DP(Range) | 0.0576 | 0.0567 | 0.0553 | 0.0548 | 0.0547 |
| ROW-DP(MAE) | 0.0561 | 0.0558 | 0.0553 | 0.0548 | 0.0543 |
| ROW-DP(IQR) | 0.0569 | 0.0569 | 0.0545 | 0.0545 | 0.0544 |
| LS-ADP | 0.0551 | 0.0547 | 0.0542 | 0.0543 | 0.0543 |
| Nopd | 0.0540 | 0.0540 | 0.0540 | 0.0540 | 0.0540 |
Table 4.
C-index log-likelihood for Cox-MLP(Nopd), LS-ADP, and ROW-DP algorithms under different privacy budgets () based on five dispersion measurement methods (Var, Range, Std, MAE, IQR).
Table 4.
C-index log-likelihood for Cox-MLP(Nopd), LS-ADP, and ROW-DP algorithms under different privacy budgets () based on five dispersion measurement methods (Var, Range, Std, MAE, IQR).
| Privacy Budget | 3 | 4 | 5 | 7 |
|---|
| NbAFL | 0.7361 | 0.7560 | 0.7656 | 0.7676 |
| Std | 0.7301 | 0.7484 | 0.7538 | 0.7550 |
| Var | 0.7292 | 0.7438 | 0.7433 | 0.7573 |
| Range | 0.7251 | 0.7522 | 0.7530 | 0.7568 |
| MAE | 0.7231 | 0.7485 | 0.7515 | 0.7599 |
| LS-ADP | 0.7627 | 0.7653 | 0.7678 | 0.7701 |
| IQR | 0.7248 | 0.7515 | 0.7585 | 0.7593 |
| Nopd | 0.7701 | 0.7701 | 0.7701 | 0.7701 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}
{kind=link}