Abstract
Object detection is a fundamental task in computer vision, aiming to identify and localize objects of interest within an image. Over the past two decades, the domain has changed profoundly, evolving into an active and fast-moving field while simultaneously becoming the foundation for a wide range of modern applications. This survey provides a comprehensive review of the evolution of 2D generic object detection, tracing its development from traditional methods relying on handcrafted features to modern approaches driven by deep learning. The review systematically categorizes contemporary object detection methods into three key paradigms: one-stage, two-stage, and transformer-based, highlighting their development milestones and core contributions. The paper provides an in-depth analysis of each paradigm, detailing landmark methods and their impact on the progression of the field. Additionally, the survey examines some fundamental components of 2D object detection such as loss functions, datasets, evaluation metrics, and future trends.
Keywords:
object detection; deep learning; convolutional neural networks; transformer; computer vision MSC:
68T45; 68U05; 68U10; 65D18; 68T07
1. Introduction
Object detection is a fundamental task in computer vision that involves two sub-tasks: the localization and classification of objects belonging to predefined categories of interest. Object detection can be formally described as follows. Let be an RGB image of height H and width W, and let C denote the total number of classes of interest. The goal is to identify all instances of these classes in I by predicting a set of bounding boxes, each paired with a class label and a confidence score. Specifically, the detector outputs a set where are the coordinates of the bounding box, is the predicted class and is the model’s confidence in the prediction (see Figure 1).
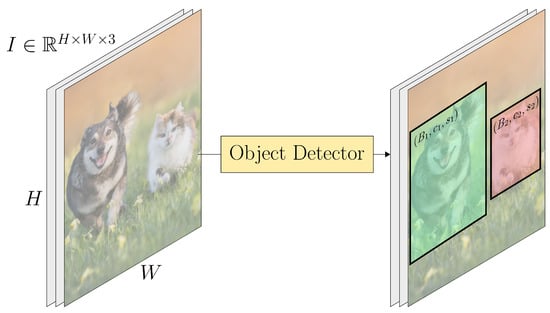
Figure 1.
Object detection pipeline. The model processes an input image and detects instances of predefined object classes (here, dog and cat), predicting bounding boxes, class labels, and confidence scores.
Over the last twenty-five years, object detection has undergone significant transformations following the broader advancements in computer vision as a whole. In its early stages, object detection relied on manually crafted features, such as Histogram of Oriented Gradients (HOG) [1], Scale-Invariant Feature Transform (SIFT) [2,3], and others. Early detectors, such as Viola–Jones [4,5], though impressive for their time, faced challenges like high computational costs and limited generalization capabilities. The success of convolutional neural networks (CNNs) with the introduction of AlexNet [6] in 2012 marked a definitive shift toward deep learning-based methods for object detection and, more broadly, for computer vision. The introduction of R-CNN (Regions with CNN features) [7] in 2014, and the subsequent R-CNN series, exemplified this shift. The deep learning era has been marked by an unprecedented emergence and growth of various object detection methods, driven by increasing computational capabilities, the availability of large-scale datasets, and advancements in other vision tasks. Various detector paradigms and families have since established themselves, as outlined in the milestone timeline shown in Figure 2. Modern object detection frameworks are predominantly categorized into three paradigms: two-stage, one-stage, and transformer-based detectors.
- Two-stage: these detectors, epitomized by the R-CNN [7] series, decouple the region proposal generation from classification and location refinement.
- One-stage: prioritizing inference speed and efficiency, detectors such as YOLO [8] and SSD [9] streamline the detection pipeline by eliminating the proposal generation stage.
- Transformer-based: exemplified by DETR [10], these detectors rely on the self-attention mechanism introduced in transformer architecture [11] to capture global context across the entire image, and they currently define the dominant trend in state-of-the-art 2D object detection.
In the following sections, this survey reviews the evolution of 2D generic object detection, analyzing its main paradigms, tracing their historical development, and systematically structuring key advancements in the field.
In summary, this survey presents the following key contributions: (1) It provides a comprehensive historical perspective on 2D object detection, tracing its evolution from handcrafted feature-based methods to modern deep learning-based approaches. (2) It presents a systematic categorization of deep learning-based object detection methods into three major paradigms—two-stage, one-stage, and transformer-based detectors—highlighting their milestones and technical advancements. (3) It provides an in-depth analysis of core components of object detection, including loss functions, datasets, and evaluation metrics. (4) It identifies open research challenges, including generalization across domains, scalability to novel object categories without extensive labeled data, and computational efficiency, which are further explored in Section 3.4. These contributions aim to provide a structured reference for researchers, consolidating the historical development and technical evolution in 2D object detection.
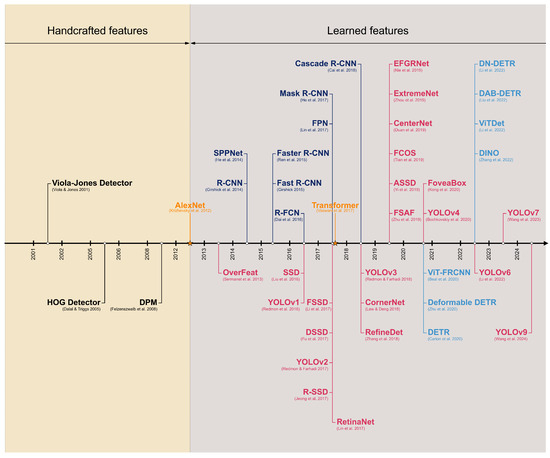
Figure 2.
Milestones of 2D generic object detection. AlexNet [6] marks the transition from traditional methods, based on handcrafted features, to deep learning-based approaches, based on learned features. Among the latter, three distinct colors identify the paradigms examined in this survey: blue for two-stage detectors, red for one-stage detectors, and light blue for transformer-based detectors, based on the transformer architecture [11], represented on the timeline. Milestone detectors in this figure: Viola–Jones Detector [4,5], HOG Detector [1], DPM [12], R-CNN [7], SPPNet [13], Fast R-CNN [14], Faster R-CNN [15,16], R-FCN [17], FPN [18], Mask R-CNN [19], Cascade R-CNN [20,21], OverFeat [22], SSD [9], DSSD [23], R-SSD [24], FSSD [25], RefineDet [26], EFGRNet [27], ASSD [28], RetinaNet [29], CornerNet [30], CenterNet [31], ExtremeNet [32], FCOS [33], FoveaBox [34], FSAF [35], YOLOv1 [8], YOLOv2 [36], YOLOv3 [37], YOLOv4 [38], YOLOv6 [39], YOLOv7 [40], YOLOv9 [41], DETR [10], Deformable DETR [42], DAB-DETR [43], DN-DETR [44], DINO [45], ViT-FRCNN [46], ViTDet [47].
Figure 2.
Milestones of 2D generic object detection. AlexNet [6] marks the transition from traditional methods, based on handcrafted features, to deep learning-based approaches, based on learned features. Among the latter, three distinct colors identify the paradigms examined in this survey: blue for two-stage detectors, red for one-stage detectors, and light blue for transformer-based detectors, based on the transformer architecture [11], represented on the timeline. Milestone detectors in this figure: Viola–Jones Detector [4,5], HOG Detector [1], DPM [12], R-CNN [7], SPPNet [13], Fast R-CNN [14], Faster R-CNN [15,16], R-FCN [17], FPN [18], Mask R-CNN [19], Cascade R-CNN [20,21], OverFeat [22], SSD [9], DSSD [23], R-SSD [24], FSSD [25], RefineDet [26], EFGRNet [27], ASSD [28], RetinaNet [29], CornerNet [30], CenterNet [31], ExtremeNet [32], FCOS [33], FoveaBox [34], FSAF [35], YOLOv1 [8], YOLOv2 [36], YOLOv3 [37], YOLOv4 [38], YOLOv6 [39], YOLOv7 [40], YOLOv9 [41], DETR [10], Deformable DETR [42], DAB-DETR [43], DN-DETR [44], DINO [45], ViT-FRCNN [46], ViTDet [47].
2. 2D Object Detectors
2.1. Handcrafted Features
Early pioneering works in the field of object detection, dating back to the early 2000s, relied heavily on handcrafted features, i.e., manually designed characteristics used to extract discriminative information from objects. Examples of feature extraction methods include Integral Image [4,5], Histogram of Oriented Gradients (HOG) [1], Scale-Invariant Feature Transform (SIFT) [2,3], and others. These features were combined with traditional classification models like the Support Vector Machine (SVM) (and its generalizations such as LSVM [12], SO-SVM [48,49]), or AdaBoost [50]. Notable examples of that time include the Viola–Jones detector [4,5], HOG-based detectors [1], and the deformable part-based model (DPM) [12].
- Viola–Jones Detector
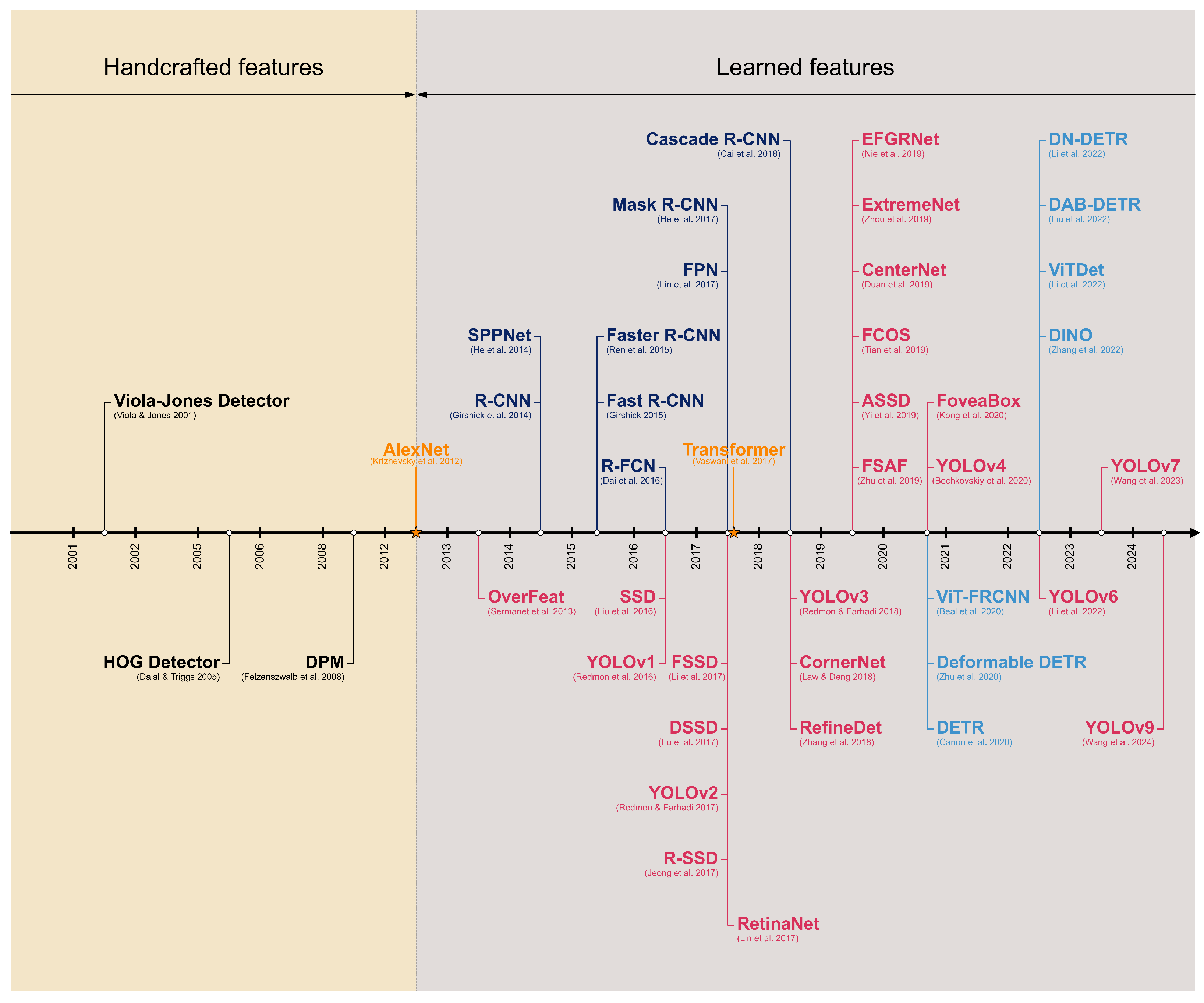
In 2001, P. Viola and M. J. Jones achieved the real-time detection of human faces for the first time without any auxiliary information (e.g., skin color segmentation, image differencing) [4,5]. The detector was at least 15 times faster than the best algorithms of its time ([51,52,53,54,55]) under comparable detection accuracy: operating on pixel single grayscale images, frontal upright faces were detected at 15 FPS on a conventional 700 MHz Intel Pentium III. The Viola–Jones detector employs a direct approach to detection, specifically, a sliding window technique: scanning all potential positions and scales within an image to identify whether any sub-window contains a human face. Three main advancements characterize their work. The first is the introduction of a new image representation called Integral Image, which allows the rectangular features (see Figure 3) used by the detector to be computed in a very efficient way; each pixel sub-window of the image has associated over 180,000 rectangular features. The second is a learning algorithm based on AdaBoost [50], which selects a small set of previous features and yields extremely efficient classifiers. The third contribution is a method for combining increasingly more complex classifiers in a 38-stage cascade, which allows background regions of the image to be quickly discarded while spending more computation on promising object-like regions. The authors trained their detection system on 4916 hand-labeled faces, randomly crawled on the web, and tested it on the MIT+CMU frontal face test set [52]. Subsequently, the authors successfully adapted their method to pedestrian detection, as detailed in their later work [56].

Figure 3.
On the left: the first and second rectangular features selected by AdaBoost [50] in Viola–Jones detector [4,5]. The two features are shown in the top row and then overlaid on a typical training face in the bottom row. On the right: an example detection obtained using the deformable part-based model (DPM) [12]. The model consists of a coarse template (blue rectangle), several higher-resolution part templates (yellow rectangles), and a spatial model that defines the relative location of each part.
- HOG
In 2005, N. Dalal and B. Triggs presented the Histogram of Oriented Gradients (HOG) feature descriptor [1]. HOG descriptors are reminiscent of edge orientation histograms [57,58], SIFT descriptors [3], and shape contexts [59]. The approach consists of dividing the image into a grid of uniform spatial regions, each being pixels and called cells, for each cell accumulating a local 1D histogram (nine orientation bins of 0°–180°) of unsigned gradient ( kernels) directions or edge orientations over the pixels of the cell; the combined histogram entries constitute the feature representation. Moreover, to enhance the illumination invariance, local contrast L2-Hys normalization is applied to each cell using larger spatial regions, each being pixel and called blocks; these normalized descriptor blocks are the HOG descriptors. The detection system is completed by covering a pixels detection window with a dense and overlapping grid of HOG descriptors and feeding the combined feature vector to a soft linear SVM. In terms of efficiency, the detector was able to process a pixel image in less than a second. The authors’ interests were mainly focused on human detection and, in particular, on pedestrian detection, though the descriptor performs equally well for other shape-based object classes: they tested their detection system on the MIT pedestrian test set [60,61] and on INRIA, a new pedestrian dataset introduced by the authors.
The HOG feature descriptor has been the basis of numerous subsequent detectors such as DPM [12,62], as well as other approaches that combine HOG with LBP [63,64,65], detectors based on related descriptors such as HSC [66], and others [67,68].
- Deformable Part-Based Model (DPM)
In 2008, P. Felzenszwalb et al. presented DPM [12]. The basic concept of part-based models is that objects can be modeled by parts in a deformable configuration [69,70,71,72,73,74,75,76,77,78]. In particular, in the DPM context, a model for an object consists of a global root filter, covering an entire detection window, and several part models: each part model specifies a spatial model and a part filter (see Figure 3). The spatial model defines a set of allowed placements for a part relative to a detection window and a deformation cost for each placement. The score of a detection window is the score of the root filter on the window plus the sum over parts of the maximum, over placements of that part, of the part filter score on the resulting sub-window minus the deformation cost. Both root and part filters are scored by computing the dot product between a filter and a sub-window of the HOG-based [1] feature pyramid. The features for the part filters are computed at twice the spatial resolution of the root filter. The model is defined at a fixed scale, and the objects are detected by searching over an image pyramid [79]. The training process makes use of a generalization of SVMs, called latent variable SVM (LSVM), a reformulation of MI-SVM [80] in terms of latent variables. When DPM was introduced, it became the new state of the art in object detection: teams led by Felzenszwalb were joint winners of the VOC-2008 [81] and VOC-2009 [82] challenges, and it will be the reference method until VOC-2012 [83].
Later, the star-structured deformable part models in [12] were further improved in numerous subsequent papers: in [84], a mixture of deformable part-based models, built on the pictorial structures framework (see [73,75]), was introduced to overcome the limits of a single deformable model: the score of a mixture model at a particular position and scale is the maximum over components of the score of that component model at the given location. In [62], the authors built a cascade for deformable part-based models using a hierarchy of models defined by an ordering of the original model’s parts; the algorithm prunes partial hypotheses using PAA (Probably Approximately Admissible) thresholds on their scores. This approach achieved a significant increase in efficiency, yielding a speedup of approximately 22 times. The cascade algorithm applies to star-structured and grammar models (see [85]). R. Girshick further developed object detection with grammar models in [86,87]. DPM has inspired numerous works in later years, such as [88,89,90,91,92] and UDS [93].
Other pioneering detectors of that period were based on SIFT [2,3] descriptors, such as [94] and ESS [95], or on their generalizations, such as the color-SIFT descriptors [96] used in Selective Search [97], or PCA-SIFT descriptors [98]. Still, other detectors used additional feature extractors such as Integral Channel Features (ICFs) [99,100,101] or Haar-like wavelets [60,61,102,103], shape contexts descriptors [59], Hough transform [104,105,106] or Regionlets representation [107], or extensive combinations of different features, as in Oxford-MKL [108]. However, while these traditional detectors effectively addressed early challenges in object detection and yielded impressive results for their time, they also encountered significant limitations, including high computational complexity and restricted generalization capabilities.
2.2. Learned Features
Pioneering works in neural network-based detection date back to the early 1990s and were primarily focused on face detection. In 1994, R. Vaillant et al. [109] presented a face detection system based on a convolutional neural network. In subsequent years, 1995, 1996, and 1998, H. A. Rowley et al. [52,110,111] used neural networks to detect upright frontal faces in an image pyramid. The true turning point occurred in 2012 with the introduction of AlexNet by A. Krizhevsky et al. [6]; their deep convolutional neural network won the ILSVRC-2012 [112], significantly outperforming traditional approaches. AlexNet’s success demonstrated the potential of deep learning for image classification, marking the beginning of its application to other vision tasks, including object detection, where traditional methods were simultaneously reaching their performance limits. In the following sections, deep learning-based detectors have been divided into three main categories: one-stage, two-stage, and transformer-based detectors.
2.2.1. Two-Stage Detectors
Two-stage detectors are a class of object detectors that separate the detection process into two distinct stages. In the first stage, the model generates region proposals, i.e., regions in the image likely to contain objects. These proposals are then passed to the second stage, where they are refined for both classification and localization, determining the object class and bounding box coordinates.
R-CNN Series
Among two-stage detectors, the most influential family is the R-CNN series; this series began in 2014 with R-CNN by R. Girshick et al. [7] which was among the earliest applications of deep learning to object detection and, of these early works, stands out as the most significant. In the following sections, the milestones of this family will be discussed in detail.
- R-CNN
In 2014, R. Girshick et al. proposed R-CNN (Regions with CNN features) [7]. R-CNN consists of three modules, as shown in Figure 4. The first step is to generate around 2000 class-independent bottom-up region proposals using Selective Search [97,113]: these proposals, which are of arbitrary scale and size, define the set of candidate detections available to the detector. The second step is feature extraction: AlexNet [6], pre-trained on ILSVRC-2012 [112] and then fine-tuned on specific proposals, is used to extract a feature vector from each region proposal, cropped and warped to the network input size. The fine tuning is a -way classification problem, with C object classes, plus one for background. The third step classifies each region using class-specific linear SVMs: the presence or absence of an object within each region is predicted. At this stage, at test time, a class-specific greedy NMS (Non-maximum Suppression) is applied to all scored regions. Finally, to improve the localization performance, additional class-specific bounding-box regressors are applied to refine the bounding boxes of detected objects, using CNN proposal features.
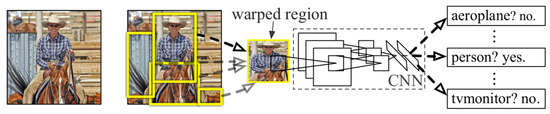
Figure 4.
The architecture of R-CNN [7], which, in order, takes an input image, extracts around 2000 bottom-up region proposals, computes features for each proposal using a backbone, and then classifies each region using class-specific linear SVMs.
R-CNN can be considered a significant milestone in the object detection field: it proves that pre-training CNN on a large classification dataset and then fine-tuning it on domain-specific data can greatly enhance performance on downstream tasks such as detection. Despite that, the main drawback is efficiency, affecting both the training phase, which involves a lengthy multi-stage procedure, and especially the inference phase.
- SPPNet
In 2014, in the same year as R-CNN [7], K. He et al. presented the Spatial Pyramid Pooling Network (SPPNet) [13]. The authors were the first to introduce an SPP layer in the context of CNNs in order to remove the fixed-size constraint of the network. Spatial pyramid pooling (SPP) [114,115], which can be considered an extension of the Bag-of-Words (BoW) model [116], partitions the image into divisions from finer to coarser levels, and aggregates local features in them. SPP is able to generate a fixed-length output regardless of the input size. In the context of object detection, SPPNet [13] can be used to extract feature maps from the entire image only once, possibly at multiple scales. The SPP layer is then applied to each candidate window of the feature maps to pool a fixed-length representation of this window. In other words, the proposed method extracts window-wise features from regions of the feature maps, while R-CNN [7] extracts directly from image regions. Because time-consuming convolutions are applied only once, rather than for each region proposal, this approach can run orders of magnitude faster than R-CNN [7].
Although SPPNet [13] has improved detection speed, it still requires multi-stage training; moreover, to speed up and simplify the training, it fine-tunes only the fully connected layers while fixing the convolutional layers, which may limit the overall accuracy.
- Fast R-CNN
In 2015, R. Girshick proposed Fast R-CNN [14]. The idea is to fix the disadvantages of R-CNN [7] and SPPNet [13], while improving their speed and accuracy. Fast R-CNN takes as input an image and multiple regions of interest (RoIs). The network first processes the whole image with several convolutional and max pooling layers to produce a convolutional feature map. Then, for each object proposal, a RoI pooling layer extracts a fixed-length feature vector from the feature map. Each feature vector is fed into a sequence of fully connected layers that finally branch into two output layers: one that produces softmax probability estimates over C object classes plus a catch-all background class, and another layer that outputs four real-valued numbers for each of the C object classes. Each set of four values encodes refined bounding-box positions for one of the C classes. The RoI pooling layer converts features inside any valid region of interest into a small feature map with a fixed spatial extent by dividing the RoI window into a grid of sub-windows and applying max pooling to each sub-window. Pooling is applied independently to each feature map channel, as in standard max pooling.
Fast R-CNN has several advantages, including faster single-stage training through feature sharing and a multi-task loss, along with a faster inference. However, its detection speed is still limited by the object proposal process, motivating the development of methods such as Faster R-CNN [15,16] to integrate proposal generation within the network.
- Faster R-CNN
In 2015, shortly after Fast R-CNN [14], S. Ren et al. presented Faster R-CNN [15,16] to overcome the dependency on region proposal algorithms. At that time, region proposal algorithms had become the real bottleneck of object detection pipelines at the test stage: methods like Selective Search [97,113], based on grouping super-pixels, or more recent ones, such as EdgeBoxes [117], based on sliding windows, still consume as much time as the detection network and both rely on CPU computation, not taking advantage of GPUs. Faster R-CNN is composed of two modules: the first module is a deep fully convolutional network (FCN) [118], called region proposal network (RPN), which proposes regions, and the second module is Fast R-CNN [14] that uses the proposed regions. The idea is that the convolutional feature maps used by region-based detectors can also be used for generating region proposals. To generate regions, the RPN slides over the convolutional feature map output by the last shared convolutional layer, taking as input an spatial window. Each sliding window is mapped to a lower-dimensional feature and then fed into two sibling fully connected layers, a box regression layer and a box-classification layer. The RPN can be trained end to end specifically for the task of generating detection proposals. Furthermore, the RPNs introduced a novel scheme for addressing multiple scales and aspect ratios: anchor boxes. Specifically, the k proposals predicted by RPN, where k is the number of maximum possible proposals, are parameterized relative to k reference boxes, called anchors. An anchor is centered at the sliding window in question and is associated with a scale and aspect ratio. This approach is translation invariant, both in terms of the anchors and in terms of the functions that compute proposals relative to the anchors. Because of this multi-scale design based on anchors, convolutional features are computed on a single-scale image.
Faster R-CNN has profoundly influenced subsequent advancements in object detection, serving as the foundation for numerous extensions and refinements. For instance, by replacing the default VGG-16 [119] with ResNet-101 [120] and making other improvements, such as iterative box regression, context, and multi-scale testing, K. He et al. [120] obtained an ensemble model, which won the MS-COCO [121] 2015 and ILSVRC-2015 [112] object detection competitions. Subsequent works and improvements include Faster R-CNN by G-RMI [122], Faster R-CNN with TDM (top-down modulation) [123], Faster R-CNN with FPN [18], and Faster R-CNN with DCR (Decoupled Classification Refinement) [124]. Additionally, A. Shrivastava et al. [125] proposed to enhance the Faster R-CNN framework by integrating semantic segmentation for top-down contextual priming and iterative feedback.
- R-FCN
In 2016, J. Dai et al. presented R-FCN (Region-based Fully Convolutional Network) [17], a framework designed to improve the speed and efficiency of Faster R-CNN [15,16] by making all the learnable layers convolutional. Specifically, following Faster R-CNN [15,16], R-FCN extracts candidate regions using the region proposal network (RPN), which is a fully convolutional architecture in itself. The last convolutional layer produces a bank of position-sensitive score maps for each category: these score maps correspond to a spatial grid describing relative spatial positions and, partially inspired by [126], allows translation variance to be incorporated into FCN [118]. R-FCN ends with a position-sensitive RoI pooling layer which aggregates the score maps and generates scores for each RoI. With end-to-end training, the RoI layer shepherds the last convolutional layer to learn specialized position-sensitive score maps, with no convolutional/fully connected layers following, enabling nearly cost-free region-wise computation and speeding up both training and inference. At training time, OHEM (Online Hard Example Mining) [127] is adopted.
Subsequent works based on R-FCN include D-RFCN (Deformable R-FCN) [128], an enhancement of R-FCN based on Deformable Convolutional Network (DCNv1) [128] and deformable PSROI, D-RFCN + SNIP (Scale Normalization for Image Pyramids) [129], and LH R-CNN (Light Head R-CNN) [130] which reduces the cost in R-FCN by applying separable convolution to reduce the number of channels in the feature maps before RoI pooling.
- FPN
In 2017, T.-Y. Lin et al. proposed FPN (Feature Pyramid Network) [18], a framework designed to improve multi-scale object detection in a computationally efficient manner. Before FPN, feature pyramids built upon image pyramids [79] were the basic and standard solution in recognition systems to detect objects on different scales [79]. Computing features for each level of an image pyramid has obvious limitations in terms of memory and inference time; for these reasons, detectors like Fast R-CNN [14] and Faster R-CNN [15,16] avoid image pyramids by default. FPN addresses this challenge and computes multi-scale feature representations by leveraging the inherent pyramidal feature hierarchy of convolutional neural networks. FPN takes a single-scale image of an arbitrary size as input, and outputs proportionally sized feature maps at multiple levels, in a fully convolutional fashion. The strategy is general-purpose, and it is independent of the backbone architecture. The FPN builds the pyramid using three components: a bottom-up pathway, a top-down pathway, and lateral connections. The bottom-up pathway is the feed-forward computation of the backbone, which computes a feature hierarchy consisting of feature maps at several scales. The top-down pathway up-samples spatially coarser, but semantically stronger, feature maps from higher pyramid levels. These features are then enhanced with features from the bottom-up pathway via lateral connections: each lateral connection merges by element-wise addition feature maps of the same spatial size from the bottom-up pathway (after a convolutional layer to reduce channel dimensions) and the top-down pathway.
Over the years, numerous generalizations of the Feature Pyramid Network (FPN) have been proposed, including PFPNet [131], NAS-FPN [132], Auto-FPN [133], -FPN [134], and AugFPN [135].
- Mask R-CNN
In 2017, K. He et al. presented Mask R-CNN [19]. Mask R-CNN is an intuitive extension of Faster R-CNN [15,16] to handle instance segmentation [126,136,137,138,139,140,141,142]. Mask R-CNN adopts the same two-stage procedure, with an identical first stage (RPN). In the second stage, Mask R-CNN adds a third branch to predict segmentation masks (see Figure 5) on each region of interest (RoI), in parallel with the two branches for classification and bounding box regression. The additional mask output is distinct from the class and box outputs, requiring the extraction of much finer spatial layout of an object. Specifically, the mask branch has a -dimensional output for each RoI, which encodes C binary masks of resolution , one for each of the C classes. This pixel-to-pixel behavior requires the RoI features to be precisely aligned to preserve the explicit per-pixel spatial correspondence; the RoIPool (RoI pooling) layer, introduced in Fast R-CNN [14], or RoIWarp, introduced in MNC [141], overlooked this alignment issue. To address this, the authors proposed a novel RoIAlign layer that removes the harsh quantization of RoIPool, properly aligning the extracted features with the input. At test time, the mask branch is applied to the top 100 RoIs after NMS, adding a overhead compared to Faster R-CNN [15,16].

Figure 5.
Mask R-CNN results on the MS-COCO [121] dataset. For each image, masks are shown in color, along with the corresponding bounding boxes, category labels, and confidence scores.
- Cascade R-CNN
In 2018, Z. Cai et al. presented Cascade R-CNN [20,21], a multi-stage extension of R-CNN [7] that frames the bounding box regression task as a cascade regression problem, inspired by the works of cascade pose regression [143] and face alignment [144,145]. Cascade R-CNN uses a sequence of detectors trained with increasing IoU thresholds, to be sequentially more selective against close false positives. The cascade of R-CNN stages are trained sequentially, using the output of one stage to train the next; this is motivated by the observation that a bounding box regressor trained with a particular IoU tends to produce bounding boxes of higher IoU. Unlike earlier bootstrapping methods used in detectors such as Viola–Jones [4,5] or DPM [84], the resampling procedure does not aim to mine hard negatives. Instead, starting from proposals generated by the RPN in the first stage, it seeks to find a good set of close false positives for training the next stage, by adjusting bounding boxes. When operating in this manner, the number of positive examples remains roughly constant across successive stages, mitigating the overfitting, since positive examples are plentiful at all levels; additionally, the detectors of the deeper stages are optimized for higher IoU thresholds. At inference, the same cascade procedure is applied, enabling a closer match between the object proposals and the detector quality of each stage.
Other Two-Stage Detectors and Enhancements
The R-CNN series has been highly influential, inspiring a wide range of additional contributions that extend and specialize the milestones presented above. Notable examples include MR-CNN (Multi-Region CNN) [146], which captures object features across multiple regions and integrates semantic segmentation-aware features, and DeepID-Net [147], which introduces a deformation-constrained pooling layer and a specialized pre-training scheme. MS-CNN [148] combines multi-scale proposal generation with detection, HyperNet [149] introduces a Hyper Feature representation, and ION (Inside-Outside Net) [150] leverages context and multi-scale knowledge. A-Fast-RCNN (Adversarial Fast R-CNN) [151] enhances Fast R-CNN [14] by using an adversarial network to generate challenging examples with occlusions and deformations, IoU-Net [152] learns to predict the IoU between each detected bounding box and the matched ground truth, and TridentNet (Trident Network) [153] introduces a parallel multi-branch architecture with shared transformation parameters but with different receptive fields. Introduced in 2019, Libra R-CNN [154] addresses sample, feature, and objective imbalances, and, in the same year, X. Zhu et al. applied DCNv2 (Deformable ConvNets v2) [155], an improvement over DCNv1 [128], to Faster R-CNN [15,16] and Mask R-CNN [19]. In 2021, P. Sun et al. presented Sparse R-CNN [156] which replaces the traditional dense set of proposals with a fixed-length sparse set. Further contributions in the R-CNN series, or methods enhancing its framework, include SDS [136], R-CNN minus r [157], GBD-Net [158], NoC [159], MultiPath [160], AC-CNN [161], CoupleNet [162], MegDet [163], Feature Selective [164], PANet [165], OR-CNN [166], RelationNet [167], ME R-CNN [168], AutoFocus [169], DATNet [170], TSD [171], DetectoRS [172], and others [173].
Moreover, the R-CNN series includes several cascade-based approaches, in addition to Cascade R-CNN [20,21]. HTC (Hybrid Task Cascade) [174] improves Cascade Mask R-CNN [20,21] by proposing a new cascade architecture which combines box and mask branches for a joint multi-stage processing, while Cascade RCNN-RS [175] proposes a rescaled family of Cascade R-CNN [20,21] with improved speed–accuracy trade-offs. Other cascade-based approaches include CRAFT [176] and CC-Net [177].
Efforts to improve the performance of region proposal networks (RPNs) and the quality of region proposals include Cascade RPN [178], GA-RPN [179], LocNet [180], Attend Refine Repeat in AttractioNet [181], Subcategory-aware RPN [182], SharpMask [140], and others [183].
Other works following the two-stage paradigm, but not directly tied to the R-CNN series, include MultiBox [184] and its improvement MSC-MultiBox [185], FeatureEdit [186], and Deep Regionlets [187]. Beyond these, some two-stage detectors have also explored anchor-free paradigms, as detailed below.
- Anchor-Free Two-Stage Detectors
Although anchor-free methods are predominantly associated with one-stage detectors, some two-stage approaches have also adopted anchor-free paradigms. A detailed introduction to anchor-free methods, along with their categorization into keypoint-based and center-based, can be found in Section Anchor-Free Detectors.
Among keypoint-based detectors, DeNet, introduced by L. Tychsen-Smith et al. in 2017 [188], generates RoIs without using anchor boxes. Specifically, it first determines how likely it is each location belongs to either the top-left, top-right, bottom-left, or bottom-right corner of a bounding box and subsequently generates RoIs by enumerating all possible corner combinations, following the standard two-stage approach to classify each RoI. Other notable keypoint-based methods include Grid R-CNN [189], which replaces the standard regression branch with a grid-guided localization mechanism, and RPDet [190], which introduces RepPoints (Representative Points), a finer representation of objects as a set of sample points useful for both localization and recognition. In 2020, K. Duan et al. proposed CPN (Corner Proposal Network) [191] which first extracts a number of object proposals by finding potential corner keypoint combinations and then assigns a class label to each proposal by a standalone classification stage.
Among center-based detectors, in 2019, Z. Zhong et al. [192] proposed a text detection framework in which the anchor-based RPN in Faster R-CNN [15,16] is replaced with an anchor-free region proposal network (AF-RPN). In 2021, X. Zhou et al. introduced CenterNet2 [193], a probabilistic two-stage extension of the one-stage framework CenterNet [194].
We conclude this section on anchor-free methods by highlighting one additional approach. In 2021, H. Qiu et al. presented CrossDet [195], later extended to CrossDet++ [196], an anchor-free multi-stage object detection framework that diverges from traditional keypoint-based or center-based approaches by using a novel cross line representation: objects are represented as a set of horizontal and vertical cross lines, designed to capture continuous object information.
2.2.2. One-Stage Detectors
One-stage detectors are a class of object detection methods that streamline the detection pipeline by predicting both object locations and categories in a single step, bypassing the need for region proposal generation typical of two-stage detectors. Their single-step design makes them faster and more efficient in most cases. Among the earliest implementations of the one-stage paradigm are DetectorNet [197] and OverFeat [22], both introduced in 2013. DetectorNet [197] splits the input image into a coarse grid and frames the detection task as a regression problem to object bounding box masks; it adopts AlexNet [6] as backbone. We now discuss OverFeat [22] in more detail.
- OverFeat
In 2013, P. Sermanet et al. presented OverFeat [22], a unified framework for classification, localization, and detection. OverFeat can be considered one of the first one-stage object detectors and among the earliest attempts to integrate CNNs into an object detection pipeline. The backbone architecture is similar to AlexNet [6] but with differences, including non-overlapping pooling regions and the removal of contrast normalization. At each spatial location, the detection pipeline predicts bounding boxes, class labels, and confidence scores using a combination of a classifier and a regressor, which share the same feature extraction layers. At test time, OverFeat adopts a multi-scale and sliding window approach: by passing up to six scales of the original image through the network, it evaluates multiple contextual views. Bounding box predictions at any location and scale are combined via a greedy merge strategy, designed to be more robust to false positives than traditional NMS. Additionally, the authors perform negative training on the fly by selecting a few interesting negative examples per image, such as random or most offending ones. The architecture is available in two variants, fast and accurate, differing mainly in the stride of the first convolution, the number of stages, and the number of feature maps. OverFeat was the winner of the ILSVRC-2013 [112] localization competition and ranked third in the detection competition; in post-competition work, it achieved a new state of the art in this category.
OverFeat anticipates more successful one-stage architectures, such as SSD [9] and YOLO [8], but its reliance on sequential training for the classifier and regressor presents a significant drawback compared to later models.
SSD Series
Among one-stage detectors, one of the most influential families is the SSD series; this series was introduced in 2016 with the development of SSD (Single Shot MultiBox Detector) by W. Liu et al. [9], marking the first major success of the one-stage approach in deep learning-based object detection. SSD stood out as a landmark in efficiency and speed, paving the way for subsequent advancements in the one-stage detection paradigm. In the following sections, the milestones of this family will be discussed in detail.
- SSD
In 2016, W. Liu et al. presented SSD (Single Shot MultiBox Detector) [9]. SSD is based on a single feed-forward convolutional network that produces a fixed-size collection of bounding boxes and scores for the presence of object class instances in those boxes, followed by NMS. The SSD architecture, shown in Figure 6, extends a backbone network by appending additional convolutional layers; these layers progressively decrease in size and enable predictions at multiple scales. Each added feature layer uses its own set of convolutional filters to produce a fixed set of detections. The authors associate a set, typically six, of default bounding boxes with each feature map cell for multiple feature maps at the network’s top. At each feature map cell, the network predicts the offsets relative to the default box shapes in the cell and the per-class scores that indicate the presence of a class instance in each of those boxes. These default boxes are similar to the anchor boxes introduced in Faster R-CNN [15,16], but they are applied to feature maps of different resolutions. This multi-reference and multi-resolution approach efficiently discretizes the space of possible output box shapes. For a input, SSD can achieve 59 FPS on an NVIDIA Titan X.
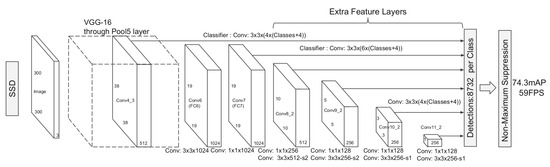
Figure 6.
SSD architecture: SSD adds several feature layers to the end of a backbone, which predict the offsets to default boxes of different scales and aspect ratios, along with their associated confidence scores.
The primary innovation of SSD lies in its ability to detect objects at multiple scales across different network layers, unlike earlier detectors that perform detection exclusively on their top layers. Several extensions and improvements have been proposed to address specific challenges of SSD, which will be detailed in the following methods.
- DSSD
In 2017, C.-Y. Fu et al. presented DSSD (Deconvolutional Single Shot Detector) [23], an extension of SSD [9], designed to introduce additional context. DSSD draws inspiration from encoder–decoder architectures, often referred to as hourglass models for their wide–narrow–wide structure, which have proven effective in tasks such as semantic segmentation [198] and human pose estimation [199]. Building on SSD, DSSD introduces several key modifications. First, it replaces the VGG-16 [119] backbone with ResNet-101 [120], in order to improve accuracy. Second, the prediction module incorporates an additional residual block in each prediction layer, inspired by insights from MS-CNN [148]. Third, to integrate more high-level context, DSSD adds deconvolution layers to the original SSD architecture, effectively forming an asymmetric hourglass structure; these extra deconvolution layers increase the resolution of feature map layers. To strengthen the features, the authors adopt the skip connections from the hourglass model [199]. Unlike a standard hourglass network, DSSD employs a shallow decoder stage to maintain inference efficiency and because decoder layers must be trained from scratch, since no pre-trained models that include a decoder stage were available. Finally, a deconvolution module, inspired by SharpMask [140], is added to integrate information from earlier feature maps and the deconvolution layers. DSSD demonstrates significant improvements over SSD, particularly in detecting small objects, but this comes at the cost of reduced speed.
- R-SSD
In 2017, J. Jeong et al. presented R-SSD (Rainbow Single Shot Detector) [24], an extension of SSD [9], designed to address two key limitations. First, SSD treats each layer in the feature pyramid independently, considering only one layer for each scale, which neglects the relationships between different scales and, thus, the same object can be detected in multiple scales. Second, SSD is suboptimal in detecting small objects, a challenge also targeted by DSSD [23]. R-SSD introduces a novel feature map concatenation scheme, called rainbow concatenation, to address these issues. This is achieved by simultaneously performing lower-layer pooling and upper-layer deconvolution to create feature maps with an explicit relationship between different layers; batch normalization [200,201] is applied before concatenation to normalize feature values and mitigate scale differences across layers. By using the concatenated features, detection is performed considering all the cases where the object’s size is smaller or larger than the specific scale and it is expected that an object of a specific size is detected only in the most appropriate layer in the feature pyramid. In addition, the low-layer features, with limited representation power, are enriched by higher-layer features, resulting in good representation power for small object detection as in DSSD [23] but without much computational overhead: by rainbow concatenation, each layer in the feature pyramid has the same number of feature maps, and thus weights can be shared for different classifier networks in different layers. Furthermore, the number of channels in the feature pyramid is increased to enhance small object detection.
- FSSD
In 2017, Z. Li et al. presented FSSD (Feature Fusion Single Shot Multibox Detector) [25], an extension of SSD [9], which incorporates a lightweight and efficient feature fusion module. The idea is to appropriately fuse the different-level features at once and generate a feature pyramid from the fused features. Specifically, starting from SSD300 with a VGG-16 [119] backbone, FSSD excludes feature maps whose spatial size is smaller than , as they contain limited information for fusion. The remaining source layers are first reduced in feature dimension using a convolutional layer and then resized to match the spatial size of the feature map from conv (), using max pooling for down-sampling and bilinear interpolation for up-sampling. After resizing, concatenation, preferred over element-wise summation, is performed: batch normalization [200] is then applied to normalize the feature values. The resulting fused feature map is used to generate a feature pyramid, used as in SSD [9] to generate object detection results.
FSSD demonstrates several advantages over SSD [9]. Firstly, FSSD reduces the probability of repeatedly detecting parts of an object or merging multiple objects into one. Secondly, FSSD performs better on small objects by retaining their location information and context (shown to be fundamental [173]), which SSD struggles with due to its reliance on shallow layers whose receptive field is too small to observe the larger context information. In terms of inference time, since FSSD adds additional layers to the SSD model, it consumes approximately extra time.
- RefineDet
In 2018, S. Zhang et al. proposed RefineDet [26], an extension of SSD [9] that combines the advantages of one-stage and two-stage object detectors. Specifically, RefineDet introduces three key components: the ARM (Anchor Refinement Module), the ODM (Object Detection Module), and the TCB (Transfer Connection Block), which links the ARM and the ODM. The ARM filters out easy negative anchor boxes, reducing the search space for the classifier and mitigating the foreground–background class imbalance. It also coarsely adjusts the locations and sizes of anchors to provide a better initialization for the subsequent regressor in the ODM. The ODM is composed of the outputs of TCBs followed by the prediction layers, and takes the refined anchors from the ARM to regress accurate object locations and predict multi-class labels. The TCBs convert features of different layers from the ARM into the form required by the ODM, so that the ODM can share features from the ARM. TCBs are applied only to feature maps associated with anchors. Moreover, TCBs integrate large-scale context by adding high-level features to the transferred features to improve detection accuracy. RefineDet employs a two-step cascaded regression strategy through the ARM and ODM, mimicking the refinement process of two-stage detectors while maintaining the efficiency of the one-stage approach. This design allows RefineDet to achieve significant improvements in localization accuracy, especially for small objects.
- EFGRNet
In 2019, J. Nie et al. presented EFGRNet [27], a framework designed to enhance SSD [9] by jointly addressing the challenges of multi-scale detection and class imbalance without compromising its characteristic speed. EFGRNet introduces two key components: a feature enrichment (FE) scheme and a cascaded refinement scheme. The FE scheme captures multi-scale contextual information using a Multi-Scale Contextual Feature (MSCF) module. Inspired by ResNeXt [202] and HRGAN [203], the MSCF module employs a split–transform–aggregate strategy with dilated convolutions [204]. The output of MSCF is passed to the cascaded refinement scheme. The cascaded refinement scheme comprises two cascaded modules. First, the objectness module (OM) enriches the SSD features, performs class-agnostic binary classification, and generates an initial box regression. Then, the Feature Guided Refinement Module (FGRM) takes the outputs of the OM, generates an objectness map, refines the features and uses them to predict the final multi-class classification and bounding-box regression.
- ASSD
In 2019, J. Yi et al. presented ASSD (Attentive Single Shot Multibox Detector) [28], an extension of SSD [9] that enhances detection accuracy by incorporating an attention unit, inspired by the self-attention mechanism introduced for sequence transduction problems in the transformer [11]. In sequence transduction, the self-attention mechanism draws global dependencies between the input and output sequences by an attention function, which maps a query and a set of key–value pairs to an output. The ASSD’s approach can be viewed as a similar query problem that estimates the relevant information from the input features in order to build global pixel-level feature correlations. In the attention unit, the feature map at a given scale s is linearly transformed into three different feature spaces: , , and . An attention map , computed as the softmax-normalized matrix multiplication of and , captures the long-range dependencies of features at all positions and highlights the relevant parts of the feature map. The attention unit is completed with a matrix multiplication between and the attention map , obtaining an update feature map as the weighted sums of individual features at each location; finally, the result is added back to the input feature map . ASSD places the attention units between each feature map and the prediction module, where the box regression and object classification are performed.
- Other works in the SSD series
The SSD series has inspired a variety of extensions and improvements. In 2017 [205] and in a subsequent version in 2019 [206], Z. Shen et al. presented DSOD (Deeply Supervised Object Detector), an object detection framework based on SSD that can be trained from scratch, by adopting key principles such as deep supervision [207]. In 2017, in addition, they introduced GRP-DSOD [208], which enhances DSOD by integrating Gated Recurrent Feature Pyramids. ESSD (Extended Single Shot Detector) [209] enhances SSD by extending the semantic information of its shallow layers through an extension module. RFBNet (Receptive Field Block Net) [210] incorporates a Receptive Field Block to generate more discriminative and robust features. DES (Detection with Enriched Semantics) [211] enriches the features within the SSD framework by incorporating a semantic segmentation branch and a global activation module, while Features-Fused SSD [212] and FFE-SSD (Feature Fusion and Enhancement for SSD) [213] both enhance SSD by introducing multi-level feature fusion to improve small object detection. Further contributions enhancing the SSD framework include RRC [214], PFPNet [131], LFIP-SSD [215], M2Det [216], and PSSD [217].
- RetinaNet
In 2017, T.-Y. Lin et al. presented RetinaNet [29], a milestone among one-stage detectors for its innovative approach to addressing class imbalance, a key challenge preventing one-stage detectors from achieving state-of-the-art accuracy. Two-stage detectors, such as R-CNN-based detectors, address class imbalance through a two-stage cascade and sampling heuristics such as a fixed foreground-to-background ratio (1:3) or OHEM (Online Hard Example Mining) [127]. In contrast, one-stage detectors must process a much larger set of candidate object locations, usually –, that densely cover spatial positions, scales, and aspect ratios. Traditional solutions like bootstrapping [110,218] or hard example mining [4,62,127] proved ineffective as easily classified background examples still dominate training and can degrade the model. The authors proposed a new loss function, called focal loss, a dynamically scaled cross-entropy loss. The scaling factor decays to zero as confidence in the correct class increases and automatically down-weights the contribution of easy examples during training, enabling the model to focus on hard examples. By integrating this loss function into the training process, the authors introduced their architecture, RetinaNet. RetinaNet is composed of a backbone network, a modified ResNet-FPN [18,120], and two task-specific fully convolutional sub-networks: one predicts the probability of object presence at each spatial position for each of the A anchors and C object classes while the second regresses offsets from each anchor box.
In 2019, RetinaMask [219] enhanced RetinaNet with various improvements, including the integration of instance mask prediction, a self-adjusting Smooth L1 loss, and the addition of extra hard examples during training. In the same year, Retina U-Net [220] extended RetinaNet by integrating with U-Net [221] and adopting segmentation supervision to enhance medical object detection. In 2021, RetinaNet-RS [175] proposed a rescaled family of RetinaNet, with improved speed–accuracy trade-offs.
Anchor-Free Detectors
SSD-based detectors, RetinaNet [29], and the previously introduced R-CNN-based detectors are collectively referred to as anchor-based detectors, as they rely on predefined boxes with fixed sizes and aspect ratios. In SSD [9], these are called default boxes while Faster R-CNN [15,16] refers to them as anchor boxes. These predefined boxes serve as initial references, and the detector predicts the offsets relative to these anchors to refine the object locations. Despite their effectiveness, anchor-based detectors exhibit several drawbacks.
- Positive/negative imbalance: since this class of detectors is trained to classify whether each anchor box sufficiently overlaps with a ground truth box, achieving a high recall rate requires dense placement of anchor boxes on the input image. As a result, only a tiny fraction of anchor boxes will overlap with the ground truth, creating a significant imbalance between positive and negative samples, which further slows down training.
- Hyperparameters: the use of anchor boxes introduces many hyperparameters, such as the number of anchors, and the sizes and aspect ratios. As shown in [29] or [15,16], the detection performance is highly sensitive to these design choices and therefore needs to be properly tuned. The tuning of these hyperparameters typically involves ad hoc heuristics and statistics computed from a training/validation set [29,36], and becomes particularly challenging when combined with multi-scale architectures. However, design choices optimized for a particular dataset may not always generalize well to other applications, thus limiting generality [222].
- Shape variation: because the scales and aspect ratios of anchor boxes are kept fixed, anchor-based detectors face difficulties in handling object candidates with large shape variations, particularly for small objects.
- IoU: at training phase, anchor-methods rely on the IoU to define positive/negative samples, which introduces additional computation and hyperparameters for an object detection system [179].
To overcome these limitations, anchor-free detectors have been proposed as an alternative approach. Unlike anchor-based methods, anchor-free detectors eliminate the need for predefined anchor boxes. Anchor-free detectors can be categorized into keypoint-based detectors and center-based approaches, presented below.
Keypoint-Based Detectors
Anchor-free keypoint-based detectors represent objects using multiple predefined or self-learned keypoints, such as the center, corners, or extreme points, which are then grouped to predict bounding boxes, as shown in Figure 7. A representative example of this approach is CornerNet [30], which detects object bounding boxes by identifying their top-left and bottom-right corners.

Figure 7.
The three images show anchor-free keypoint-based methods which use different combinations of keypoints (red circles) and then group them for bounding box prediction. A pair of corners, a triplet of keypoints, and extreme points on the object are respectively used in CornerNet [30], CenterNet [31], and ExtremeNet [32].
- CornerNet
In 2018, H. Law and J. Deng presented CornerNet [30], an anchor-free detector that represents objects using pairs of keypoints: the top-left and bottom-right corners of the bounding box (see Figure 7). CornerNet introduces corner pooling, a novel pooling layer that helps a convolutional network to better localize the corners of bounding boxes. Corner pooling takes in two feature maps: for the top-left corner, at each pixel location it max-pools all feature vectors to the right from the first feature map, max-pools all feature vectors directly below from the second feature map, and then adds the two pooled results together. A similar procedure is performed for the bottom-right corner. This approach addresses cases where a corner of a bounding box is outside the object and cannot be localized based on local evidence. CornerNet adopts a one-stage paradigm: a modified version of an hourglass network [199] is used as the backbone, followed by two prediction modules, one for the top-left corners, and the other for the bottom-right corners. Each module, whose first part is a modified version of the residual block [120], has its own corner pooling module to pool features from the hourglass network before predicting the heatmaps, embeddings, and offsets. The heatmaps represent the locations of corners of different object categories, while the embedding vectors, inspired by A. Newell et al. [223], serve to group a pair of corners that belong to the same object. For training, CornerNet uses a variant of focal loss [29] that reduces the penalty given to negative locations within a radius determined by the size of the object, using an unnormalized 2D Gaussian.
One year later, CornerNet-Lite [224] improved the inference efficiency of CornerNet with two variants: CornerNet-Saccade and CornerNet-Squeeze. CornerNet-Saccade reduces the number of pixels processed via an attention mechanism inspired by saccades in human vision [225,226], while CornerNet-Squeeze minimizes computation per pixel by introducing a compact hourglass backbone, inspired by SqueezeNet [227] and MobileNets [228].
- CenterNet
In 2019, K. Duan et al. presented CenterNet [31]. While CornerNet [30] represents objects using pairs of corners, it often generates incorrect bounding boxes due to the lack of information about the inner of the cropped regions. CenterNet resolves this limitation by introducing a third keypoint at the geometric center of the bounding box, forming a triplet, instead of a pair, to represent objects (see Figure 7). This extra keypoint allows the model to capture the visual patterns within the proposed region and to verify the correctness of each bounding box. CenterNet, therefore, extends CornerNet [30] by embedding a heatmap for the center keypoints and predicting their offsets. For each bounding box, a central region is defined using a scale-aware schema to adaptively fit the size of the bounding box. A bounding box is preserved only if a center keypoint is detected in its central region; the class label of the center keypoint must match the class label of the bounding box. Moreover, in order to improve the detection of center keypoints and corners, the authors proposed two pooling strategies, respectively: center pooling, which takes the maximum values in both the horizontal and vertical directions, and cascade corner pooling, which takes the maximum values in both the boundary and internal directions of objects.
- ExtremeNet
In 2019, X. Zhou et al. presented ExtremeNet [32], a bottom-up object detection framework that detects objects by identifying five keypoints: four extreme points and one center (see Figure 7). It is related to previous works, including DPM [84], key-point estimation, e.g., human joint estimation [19,223,229,230,231], and the extreme clicking annotation strategy by D.P. Papadopoulos et al. [232]. Specifically, using an hourglass network [199], ExtremeNet predicts heatmaps (one per class) and offset maps, since, as in CornerNet [30], offset prediction is category-agnostic, but extreme-point specific. After predicting the five heatmaps per class, extreme points are extracted as peaks, i.e., pixels that are local maxima, and grouped in a purely geometric manner using center grouping: given four extreme points, their geometric center is computed and, if the center is predicted with a high response in the center map, the extreme points are considered as a valid detection. Furthermore, the authors introduced a form of Soft-NMS [233] to tackle the problem of ghost boxes, i.e., false positive detections that can occur with three equally spaced collinear objects of the same size and edge aggregation to address the case of multiple points being the extreme point on one edge, leading the model to predict a segment of low-confidence responses instead of a single strong peak.
- Other keypoint-based works
In addition to the methods discussed above, several other anchor-free keypoint-based detectors have been proposed. In 2015, D. Yoo et al. introduced AttentionNet [234], which iteratively refines bounding boxes by predicting directional shifts for the top-left and bottom-right keypoints of an object. PLN (Point Linking Network) [235] represents objects using corners, center points, and their links, KP-xNet [236] detects corners for objects of different sizes and aspect ratios using Matrix Networks (xNets), while CentripetalNet [237] improves corner matching by introducing centripetal shift, a technique to pair corner keypoints from the same instance.
Center-Based Detectors
Center-based detectors represent objects using the center (the center point or part) and usually regress bounding box dimensions and other properties directly from this point. One of the first anchor-free center-based detection frameworks is DenseBox [238], introduced in 2015 with a primary focus on face detection. DenseBox defines the output ground truth as a five-channel map; the positive labeled region in the first channel is a filled circle, centered on a face bounding box and with a radius proportional to the bounding box size. For localization, it predicts the distance from each positive pixel to the bounding box boundaries. After DenseBox [238], several methods have been proposed, among which we can identify the following milestones.
- FCOS and FoveaBox
In 2019, Z. Tian et al. presented FCOS (Fully Convolutional One-Stage) [33], a fully convolutional anchor-free detector. FCOS tackles object detection in a per-pixel prediction fashion, analogous to FCN for semantic segmentation [118]: unlike anchor-based detectors, FCOS directly regresses bounding boxes at pixel locations, treating them directly as training samples. Specifically, the location is considered a positive sample if it falls into any ground truth box, and a negative sample otherwise. For the classification task, the associated class label corresponds to the class label of the bounding box for positive samples, and to the background class for negatives. For the regression task, a four-dimensional real vector, encoding the distances from the location to the four sides of the bounding box, defines the regression targets. FCOS adopts multi-level prediction with FPN [18]: the heads are shared between different feature levels. Additionally, in order to suppress low-quality detected bounding boxes, produced by locations far away from the center of an object, FCOS introduces a center-ness branch, a single-layer network parallel to the classification branch. This branch predicts the center-ness of the location (see Figure 8), defined as the normalized distance from the location to the center of the object that the location is responsible for.

Figure 8.
On the left: FCOS [33] works by predicting a 4D vector encoding the location of a bounding box at each foreground pixel. The second plot on the left illustrates the ambiguity that arises when a location resides in multiple bounding boxes. On the right: the center-ness of FCOS [33] is shown, where red, blue, and other colors denote , and the values between them, respectively. Center-ness decays from 1 to 0 as the location deviates from the center of the object.
In 2020, T. Kong et al. proposed FoveaBox [34], a framework inspired by the fovea in human eyes [239] and similar to FCOS [33] but with notable differences: it eliminates the center-ness branch, employs a shrunk positive area for defining training samples, modifies the mapping of ground truth boxes to FPN [18] levels by presetting a size acceptance range for each level, and normalizes and regularizes the distances from the boundaries for the regression targets. Moreover, an enhanced version of FoveaBox employs feature alignment using deformable convolutions [128], refining the classification branch based on the predicted box offsets.
- FSAF
In 2019, C. Zhu et al. proposed FSAF (Feature Selective Anchor-Free) [35], an anchor-free module designed to select the optimal feature level for each object instance, removing the constraints imposed by anchor boxes. Specifically, the FSAF module can be plugged into one-stage detectors with a feature pyramid structure, such as RetinaNet [29]. For each pyramid level, an anchor-free branch is attached and comprises two additional convolutional layers, for the classification and regression, respectively. During training, a single object instance can be dynamically assigned to an arbitrary feature level within the feature pyramid. The authors defined as the projection of the object bounding box b onto the feature pyramid , and and as the effective and ignoring boxes, respectively, both proportional regions of . The ground truth for classification output consists of one map per class; the positive region corresponds to the effective box , while the ignoring region, i.e., where gradients are not propagated back to the network, is defined as . The remaining region of the ground truth map is the negative area. The ground truth for the regression output are four offset maps, agnostic to classes: for each pixel inside the effective box, the projected box is represented as a four-dimensional vector, whose components are the distances between the current pixel location and the boundaries of . During training, the FSAF module performs online feature selection to dynamically identify the optimal feature level based on the instance content, selecting the level that minimizes the focal loss [29] for classification and the IoU loss [240] for regression.
- Other center-based works
The one-stage center-based paradigm includes several additional detectors beyond those discussed above.
Some are directly based on FCOS [33], expanding its framework and introducing novel features. In 2020, Z. Tian et al. presented an improved version of FCOS [241], further refining the framework, while H. Qiu et al. presented BorderDet [242], which extends FCOS by introducing BorderAlign, a feature extractor that captures border features to refine the original center-based representation. In the same year, CenterMask [243] extended FCOS by adding a spatial attention-guided mask (SAG-Mask) branch for instance segmentation. [244] proposed an NMS-free version of FCOS by incorporating a PSS head for automatic selection of the single positive sample for each instance. FCOS has also inspired lightweight detectors for mobile devices, such as NanoDet [245] and PP-PicoDet [246].
Other approaches have explored different directions. UnitBox [240], presented in 2016, introduced a novel IoU loss function for bounding box prediction that regresses the four bounds of a predicted box as a whole unit. In 2018, J. Wang et al. incorporated UnitBox into the anchor-free branch of SFace [247], a face detection framework adopting a hybrid architecture (anchor-based and anchor-free) to tackle large-scale variations. CSP (Center and Scale Prediction) [248] simplified pedestrian detection into a straightforward task of center and scale prediction using a single Fully Convolutional Network (FCN). CenterNet [194], proposed in 2019, used keypoint estimation to identify the center of the object and regressed all other properties from this point. Two years later, CenterNet2 [193] was introduced as a probabilistic two-stage extension. SAPD (Soft Anchor-Point Detector) [249] adopted a training strategy with soft-weighted points and soft-selected pyramid levels. VarifocalNet [250], based on FCOS [33] and ATSS (Adaptive Training Sample Selection) [251], a training technique that automatically selects positive and negative samples according to the statistical characteristics of objects, adopted an IoU-Aware Classification Score (IACS) as a joint representation of object presence confidence and localization accuracy, and introduced a Varifocal Loss to train the detector to predict the IACS. In 2022, M. Zand et al. presented ObjectBox [252], which only used two corners of the central cell location for bounding box regression and introduced SDIoU loss to deal with boxes with different sizes. Another notable contribution is RTMDet (Real-Time Models for object Detection) [253], introduced in 2022.
YOLO Series
The YOLO (You Only Look Once) series is probably the most prominent and widely recognized family of object detectors in use today. Renowned for achieving an effective balance between inference speed and accuracy, the YOLO series exemplifies the greater efficiency of one-stage architectures compared to two-stage detectors. It includes both anchor-based and anchor-free approaches, reflecting the diverse methodologies encompassed within this category. This series began in 2016 with the work of J. Redmon et al., which introduced YOLOv1 [8], and has since evolved into a multitude of versions and sub-versions: as of this writing, the main line of development has reached YOLOv11 [254]. Versions YOLOv1 [8], YOLOv6 [39], YOLOv8 [255], YOLOv9 [41], YOLOv10 [256], and YOLOv11 [254] adopt an anchor-free, center-based approach, while YOLOv2 [36], YOLOv3 [37], YOLOv4 [38], YOLOv5 [257], and YOLOv7 [40] follow an anchor-based paradigm. In the following, we will focus on the core versions within the main line that have shaped its progression.
- YOLOv1
In 2016, J. Redmon et al. proposed YOLOv1 [8], an anchor-free detection framework that reframes detection as a single regression problem, directly predicting bounding box coordinates and class probabilities from the entire input image. The network architecture, inspired by GoogLeNet [258], includes 24 convolutional layers followed by 2 fully connected layers. Inspired by MultiGrasp [259], YOLOv1 divides the input image into an grid, as shown in Figure 9; if the center of an object falls into a grid cell, that grid cell is responsible for detecting that object. Each grid cell predicts B bounding boxes and C class probabilities. A bounding box prediction consists of five values: the coordinates of the box center, relative to the grid cell, width w, height h, both relative to the image size, and a confidence score representing the IoU with ground truth. In conclusion, the output is an tensor, with and by default, while the input resolution is set to . At test time, the conditional class probabilities and the individual box confidence predictions are multiplied, obtaining class-specific confidence scores for each box which encode both the probability of that class appearing in the box and how well the predicted box fits the object.
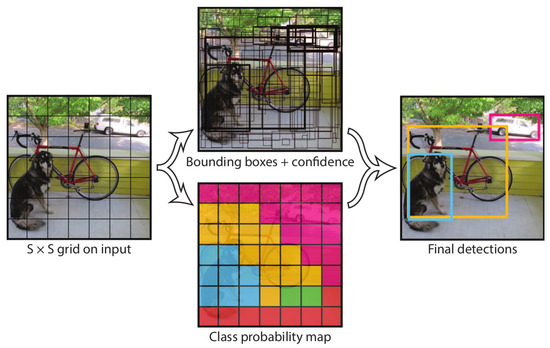
Figure 9.
YOLOv1 [8] detection pipeline: it divides the image into an grid and for each grid cell predicts B bounding boxes, their associated confidence scores, and C class probabilities. These outputs are encoded as an tensor.
This unified architecture makes YOLOv1 extremely fast, reaching 45 FPS on an NVIDIA Titan X and thus enabling real-time detection. However, YOLOv1 has some important limitations. It imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes (by default) and can only have one class, limiting the number of nearby objects that the model can predict. Moreover, it struggles to generalize to objects in new or unusual aspect ratios or configurations. Finally, YOLOv1 faces difficulties in localizing objects correctly, mainly due to its loss function, which treats errors the same in small and large bounding boxes.
- YOLOv2
In 2017, J. Redmon and A. Farhadi presented YOLOv2 [36], which builds on YOLOv1 [8] with several improvements, focusing mainly on improving recall and localization. YOLOv2 introduced anchor boxes, with dimensions optimized using k-means clustering. The class prediction mechanism is decoupled from the spatial location, enabling the model to predict class and objectness for each anchor box; the objectness still predicts the IoU of the ground truth and the proposed box and the class predictions predict the conditional probability of that class given that there is an object. A passthrough layer is added to improve the localization of small objects, by concatenating high and low resolution features. The model also adopts multi-scale training, to help the network to generalize across a variety of input dimensions. YOLOv2 adopts a custom backbone network, called Darknet-19, inspired by VGG models [119] and NIN (Network in Network) [260]. YOLOv2 is implemented using the Darknet neural network framework [261], written in C and NVIDIA CUDA [262]. Furthermore, the authors introduced YOLO9000, a modified version of YOLOv2 that integrates WordTree, a hierarchical model of visual concepts built using WordNet [263], to jointly train on classification and detection data.
- YOLOv3
In 2018, J. Redmon and A. Farhadi presented YOLOv3 [37], introducing several refinements over YOLOv2 [36]. YOLOv3 predicts an objectness score for each bounding box using logistic regression: this score should be 1 if the bounding box prior overlaps a ground truth object by more than any other prior. If the bounding box prior is not the best but does overlap a ground truth object by more than some threshold (by default ), the prediction is ignored as in Faster R-CNN [14]. Class predictions are performed using multi-label classification with independent logistic classifiers instead of softmax; this formulation helps in more complex domains, with many overlapping labels. Moreover, YOLOv3 adopts multi-scale prediction similar to FPN [18] and a new backbone network, called Darknet-53, much deeper than Darknet-19 [36]. YOLOv3, like YOLOv2, is implemented using the Darknet neural network framework [261].
In 2019, J. Choi et al. presented Gaussian YOLOv3 [264], which models the bounding box of YOLOv3, with a Gaussian parameter, and redesigns the loss function.
- YOLOv4
In 2020, A. Bochkovskiy et al. presented YOLOv4 [38], incorporating several improvements over YOLOv3 [37]. The backbone CSPDarknet53 [265] extends Darknet53 [37] with cross-stage partial connections (CSPNet) [265]. An SPP block [13] and a modified version of SAM [266] are attached to the backbone as additional modules, while a modified version of PANet [165] replaces the FPN [18] used in YOLOv3 [37]. CutMix [267], along with two new techniques introduced by the authors, Mosaic and Self-Adversarial Training (SAT), is used for data augmentation. YOLOv4 adopts several additional optimizations, categorized by the authors as Bag of Freebies (BoF), which improves training efficiency without increasing inference cost, and Bag of Specials (BoS), which enhances accuracy with minimal additional inference cost. Among the additional optimizations, BoF includes the elimination of grid sensitivity, using multiple anchors for a single ground truth, cosine annealing scheduler [268], random training shapes, genetic algorithms for selecting the optimal hyperparameters, DropBlock [269] regularization, Cross mini-Batch Normalization (CmBN), inspired by CBN [270], CIoU loss [271], and class label smoothing [272]. BoS includes DIoU-NMS [271], Mish [273] activation function, and MiWRC [274].
One year later, the same authors presented Scaled-YOLOv4 [275], whose main contribution is the introduction of new model-scaling techniques.
- YOLOv5
In 2020, G. Jocher, founder and CEO of Ultralytics, released YOLOv5, available only via a GitHub repository [257] without a paper published by the original authors; at the time of writing, the current version is v7.0. YOLOv5 adopts a modified CSPDarknet53 [265] as a backbone, a modified CSP-PAN [165,265], and SPPF (Spatial Pyramid Pooling Fast), an optimized version of SPP [13]. YOLOv5 employs various data augmentation techniques: Mosaic [38], Copy-Paste [276], random affine transformations, MixUp [277], HSV augmentation, random horizontal flip, and other augmentations from the Albumentations [278] library. The AutoAnchor strategy optimizes the prior anchor boxes to match the statistical characteristics of the ground truth boxes: it first applies a k-means function to dataset labels, and uses the k-means centroids as initial conditions for a Genetic Evolution (GE) algorithm, using CIoU loss [271] combined with BPR (Best Possible Recall) as a fitness function. Additionally, the formula for predicting the box coordinates is updated in order to reduce the grid sensitivity and prevent the model from predicting unbounded box dimensions. YOLOv5 marked the transition of the series from Darknet [261] to the PyTorch framework [279].
- YOLOv6
In 2022, C. Li et al. from the Meituan Vision AI Department presented YOLOv6 [39], an anchor-free detector. YOLOv6 adopts an efficient reparameterizable backbone, EfficientRep, inspired by RepVGG [280], and, for the neck, Rep-PAN, which enhances PAN [165] with RepBlock [280] for small models and with CSPStackRep Block, a more efficient CSP [265] block, for large models. The head is simplified into an Efficient Decoupled Head using a hybrid-channel strategy. TAL (Task Alignment Learning) [281] is used for label assignment. For loss functions, VFL (Varifocal Loss) [250] is used for classification, while SIoU loss [282] or GIoU loss [283] is used for box regression, depending on the model size. Additional industry-handy improvements include a self-distillation strategy [284], in which the teacher is limited to be the student itself but pre-trained, and a Mosaic [38] fading strategy to address performance drop caused by the absence of extra gray borders at evaluation. Moreover, to deal with performance degradation in quantizing reparameterization-based models, YOLOv6 incorporates RepOptimizer [285], along with QAT (Quantization-Aware Training) and channel-wise distillation [286].
In 2023, YOLOv6 was further enhanced with upgrades to its network design and training strategy, along with the release of new models, as highlighted in [287].
- YOLOv7
In 2023, C. Wang et al. presented YOLOv7 [40], which reintroduces the anchor-based paradigm. To improve network efficiency, YOLOv7 adopts E-ELAN (Extended-ELAN [288]), which retains the gradient transmission path of the original architecture, while increasing the cardinality of the added features through group convolution. YOLOv7 adopts RepConvN, a variant of RepConv [280] without identity connection, to design the architecture of the reparameterization model. YOLOv7 also introduces a compound model scaling method for concatenation-based models: when the depth factor of a computational block is scaled, the change in the output channel of that block is calculated and width factor scaling is proportionally performed on the transition layers. Moreover, the authors proposed two new label assignment strategies based on deep supervision [207]: additional BoF includes implicit knowledge inspired by YOLOR [289] and an EMA (Exponential Moving Average) model, a technique used in mean teacher [290], as the final inference model.
- YOLOv8
In 2023, Ultralytics released YOLOv8, available only via a GitHub repository [255] without a paper published by the original authors; at the time of writing, the current version is v8.3.54. YOLOv8 is an anchor-free detector, adopting the center-based paradigm. It adopts a backbone similar to YOLOv5 [257], based on CSPDarknet53 [265], with several modifications, including C2f, an optimized version of the C2 module (CSP [265] bottleneck with two convolutions), which reduces computational complexity by processing the last element of the split list through multiple bottleneck layers and concatenating the results. Like YOLOv5, it incorporates the SPPF (Spatial Pyramid Pooling Fast) [257] module. YOLOv8 adopts a decoupled head to independently process classification and regression tasks, and no objectness branch is included. CIoU loss [271] and DFL loss [291] are used for bounding box regression, and Binary Cross Entropy (BCE) for the classification task.
- YOLOv9
In 2024, C. Wang et al. proposed YOLOv9 [41]. YOLOv9 introduces a new auxiliary supervision framework called PGI (Programmable Gradient Information) to tackle the problem of input data losing information in deep networks as well as to introduce a deep supervision [207,258,292] method suitable for shallow and lightweight neural networks. PGI comprises three components: the main branch for inference, the auxiliary reversible branch, to address the information bottleneck [293], and multi-level auxiliary information to mitigate the error accumulation problem. YOLOv9 is released in a general and an extended version, based on YOLOv7 [40] and Dy-YOLOv7 [294], respectively. In the design of the network architecture, ELAN [288] is replaced with GELAN (Generalized Efficient Layer Aggregation Network), which extends ELAN by integrating CSPNet [265]. Additionally, the down-sampling module is simplified, and the anchor-free prediction head is optimized.
- YOLOv10
In 2024, A. Wang et al. presented YOLOv10 [256]. YOLOv10 adopts an NMS-free training strategy with dual label assignments and consistent matching metric; inspired by [295], the idea is to compensate for the suboptimal results of one-to-one matching by leveraging one-to-many assignment. YOLOv10 also introduces several architectural changes. The classification head adopts a lightweight architecture that consists of two depthwise separable convolutions [228,296]. Spatial reduction and channel increase operations are decoupled, enabling more efficient down-sampling, and a rank-guided block design scheme is introduced to reduce the complexity of redundant stages. Additionally, YOLOv10 implements an efficient partial self-attention (PSA) module design, to incorporate self-attention [11] without adding high computational complexity and memory footprint.
- Other works in the YOLO series
At the time of writing, YOLOv11 [254] has been released by Ultralytics, but official papers and detailed documentation are not yet available.
The main branch of YOLO development has served as the foundation for numerous parallel adaptations and extensions. The PP-YOLO series, named after PaddlePaddle [297], the deep learning platform used for its development, runs parallel to the YOLO series, starting with PP-YOLO [298], which is based on YOLOv3 [37]. This series includes PP-YOLO [298] and PP-YOLOv2 [299], both of which are anchor-based, and PP-YOLOE [300] and PP-YOLOE-R [301], which adopt an anchor-free approach. In 2021, C. Wang et al. presented YOLOR [289] (anchor-based), which adopts a multi-task learning approach, combining a general representation and task-specific sub-representations. In the same year, Z. Ge et al. proposed YOLOX [302], which builds on YOLOv3 [37] by adopting an anchor-free architecture and introducing various enhancements, including SimOTA, a simplified version of OTA [303], for label assignment. In 2022, X. Xu et al., from Alibaba Group, proposed DAMO-YOLO [304] (anchor-free) which incorporates various improvements, such as MAE-NAS [305] or AlignedOTA. The following year, Z. Wu et al., also from Alibaba Group, introduced YOLOX-PAI [306], an improved version of YOLOX. In 2024, X. Wang et al. proposed Gold-YOLO [307], introducing a novel Gather-and-Distribute (GD) mechanism. Other variants include YOLO-MS [308], YOLOCS [309], and YOLO-NAS [310]. Additionally, with the introduction of transformers [11], several attempts have been made to combine them with YOLO: ViT-YOLO [311], MSFT-YOLO [312], NRT-YOLO [313], YOLO-SD [314], and DEYO [315]. For a more comprehensive overview of the YOLO series, see [316].
Other One-Stage Works
Many other one-stage detectors have been proposed. G-CNN [317] introduces a grid-based object detector that iteratively refines a fixed multi-scale grid of bounding boxes to localize and classify objects. RON (Reverse connection with Objectness prior Networks) [318] enhances multi-scale object localization through reverse connections and introduces the objectness prior to reduce the search space for objects. STDN (Scale-Transferrable Detection Network) [319] employs super-resolution layers (scale-transfer layer), while TripleNet [320] proposes an encoder–decoder framework for joint object detection and semantic segmentation. DRNet (Dual Refinement Network) [321] incorporates an anchor-offset mechanism with anchor refinement, feature location refinement, and a deformable detection head. EfficientDet [274] proposes a weighted bi-directional feature pyramid network (BiFPN) for efficient multi-scale feature fusion and a compound scaling method that uniformly scales the resolution, depth, and width of the backbone, feature network, and box/class prediction networks simultaneously. RDSNet (Reciprocal Object Detection and Instance Segmentation Network) [322] extends RetinaNet [29] with a two-stream architecture that leverages reciprocal interactions between object detection and instance segmentation. TOOD (Task-aligned One-stage Object Detection) [281] aligns classification and localization tasks using a Task-aligned Head (T-Head) and task alignment learning (TAL). YOLOF [323] introduces a single-level feature detector with Dilated Encoder and Uniform Matching.
Some works propose general techniques to enhance one-stage frameworks. For example, in [324], ASFF (Adaptively Spatial Feature Fusion) is introduced to address the inconsistencies across different feature scales. Some methods focus on improving anchor-based one-stage detectors by addressing anchor alignment. Specifically, AlignDet [325] proposes a RoIConv operator to better align features with their corresponding anchors, while T. Kong et al. [326] and subsequently HSD [327] address the misalignment between training and inference that occurs when, during training, classification is optimized on default anchors but, during inference, the classification results are applied to regressed anchors generated by the regression branch. Other approaches focus on investigating training from scratch for one-stage detectors, such as ScratchDet [328] and LSN [329].
2.2.3. Transformer-Based Detectors
The success of transformers, introduced in 2017 by A. Vaswani et al. [11], in natural language processing (NLP), due to their ability to capture long-range dependencies in sequential data, has inspired researchers to explore their potential for computer vision applications, including object detection. Unlike traditional convolutional networks, transformers can model global context effectively due to their self-attention mechanism, which computes relationships between all elements in a sequence. The so-called transformer-based detectors have evolved along two main lines: the DETR series and the ViT series, presented below.
DETR Series
The DETR series builds upon DETR (DEtection TRansformer), introduced in 2020 by N. Carion et al. [10], and represents a family of detectors that leverage the direct use of transformer [11] architectures for object detection. In the following, the key milestones of the DETR series will be analyzed.
- DETR
In 2020, N. Carion et al. presented DETR (DEtection TRansformer) [10], a novel approach that formulates object detection as a direct set prediction problem. DETR consists of three key components, as shown in Figure 10: a conventional backbone, in particular a ResNet [120] model, an encoder–decoder transformer, and a feed-forward network (FFN) for predictions. The encoder follows the standard architecture described in [11], using the multi-head self-attention module, feed-forward network (FFN), and fixed positional encodings following [330,331]. The decoder also follows the standard architecture from [11], with the difference that DETR decodes objects in parallel [332,333,334,335] at each decoder layer, unlike the original transformer [11], which uses an auto-regressive model that predicts the output sequence one element at a time. The decoder receives N input embeddings that are learned positional encodings, called object queries, and, similarly to the encoder, they are added to the input of each attention layer. The N object queries are transformed into output embeddings, which are normalized using a shared normalization layer before being independently fed to the shared prediction heads. The shared FFN predicts the normalized center coordinates, height, and width of the box with respect to the input image, and the class label. Since DETR predicts a fixed size set of N bounding boxes, an additional special class label, similar to the “background” class in standard detectors, is used to represent that no object is detected within a slot. DETR adopts Hungarian loss, which is a linear combination of a negative log-likelihood for class prediction and a box loss. This loss is computed after performing an optimal bipartite matching between ground truth and predictions, using the efficient Hungarian algorithm [336], following prior work [337]: this enforces permutation invariance, and guarantees that each target element has a unique match. The box loss is a linear combination of the L1 loss and the GIoU loss [283]; both losses are normalized by the number of objects inside the batch. With its set-based loss, DETR does not need NMS by design.

Figure 10.
DETR [10] detection pipeline. DETR [10] combines a common CNN with a transformer architecture and directly predicts (in parallel) the final set of detections. During training, bipartite matching is used to uniquely pair predictions with ground truth boxes; unmatched predictions should yield a “no object” (Ø) class prediction.
DETR has two main drawbacks. First, compared to modern detectors, DETR requires significantly more training epochs to converge, mainly due to the difficulty in training the attention modules. Second, DETR has relatively low performance in detecting small objects because it cannot rely on high-resolution feature maps: the quadratic complexity of the self-attention module in the transformer encoder makes high-resolution inputs computationally prohibitive.
- Deformable DETR
In 2020, X. Zhu et al. presented Deformable DETR [42]. To overcome the two limitations of DETR [10], Deformable DETR introduces a deformable attention module, inspired by deformable convolutions [128,155]. This module attends to a small set of key sampling points around a reference point, regardless of the spatial size of the feature maps; by assigning only a small fixed number of keys for each query, the issues of convergence and feature spatial resolution can be mitigated. Moreover, the proposed module can be naturally extended for multi-scale feature maps, obtaining a multi-scale deformable attention module. This module is applied to both the encoder and decoder in DETR. In the encoder, it replaces the transformer attention modules, while, in the decoder, only the cross-attention modules are substituted, leaving self-attention modules unchanged. For each object query, the normalized coordinates of the reference point are predicted from its object query embedding, serving as the initial guess of the box center. The detection head then predicts the bounding box as relative offsets with respect to the reference point. Moreover, inspired by [338], Deformable DETR adopts an iterative bounding box refinement mechanism, where each decoder layer refines the bounding boxes based on the predictions from the previous layer.
- DAB-DETR
In 2022, S. Liu et al. proposed DAB-DETR (Dynamic Anchor Box DETR) [43]. The main contributions of DAB-DETR involve the decoder part of DETR [10]. Specifically, DAB-DETR adopts box coordinates as queries in transformer decoders and dynamically updates them layer by layer. This query formulation introduces explicit positional priors, which improve the query-to-feature similarity, speed up the training convergence of DETR, and enable the modulation of the positional attention map using the box width and height information. In more detail, inspired by Conditional DETR [339], DAB-DETR concatenates position and content information as queries and keys in the cross-attention module, decoupling the content and position contributions to the query-to-feature similarity. To rescale the positional embeddings, conditional spatial query [339] is performed. Both the positional embeddings in queries and keys are generated from 2D coordinates. Using coordinates as queries for learning makes it possible to update them layer by layer: following [42,340], anchors in each layer are updated after predicting relative positions by a prediction head. Additionally, DAB-DETR modulates the positional attention maps by dividing the relative anchor width and height from its x part and y part separately to smooth the Gaussian prior to better match with objects of different scales.
- DN-DETR
In 2022, F. Li et al. presented DN-DETR (DeNoising DETR) [44]. DN-DETR proposed a novel training method by introducing a query denoising task to help stabilize bipartite graph matching in the training process. According to the authors, the instability of the discrete bipartite graph matching, especially in the early stages of training, is in fact one of the causes of the slow convergence issue of DETR [10]. Specifically, DN-DETR builds upon DAB-DETR [43], maintaining the formulation of the decoder with box coordinates as queries. In DN-DETR there are two parts of decoder queries. One is the matching part, which adopts bipartite graph matching, receives learnable anchors as inputs, and, as in DETR, learns to approximate the ground truth box–label pairs with matched decoder outputs. The second is the denoising part, which receives noised ground truth (GT) box–label pairs, called GT objects, as inputs; noise is added to both their bounding boxes (center shifting and box scaling) and class labels (label flipping). The outputs of the denoising part aim to reconstruct GT objects. Moreover, DN-DETR specifies the decoder embedding as label embedding to support both box denoising and label denoising.
- DINO
In 2022, H. Zhang et al. presented DINO (DETR with Improved deNoising anchOr boxes) [45]. DINO is based on DN-DETR [44], DAB-DETR [43], and Deformable DETR [42]. Specifically, following DAB-DETR [43], queries are formulated in the decoder as dynamic anchor boxes and are refined step by step across decoder layers. Following DN-DETR [44], ground truth labels and boxes with noises are added into the transformer decoder layers to help stabilize bipartite matching during training. Moreover, deformable attention from Deformable DETR [42] is adopted for its computational efficiency. Additionally, DINO introduces three new methods. First, to improve the one-to-one matching and therefore help the model to avoid duplicate outputs of the same target, a Contrastive DeNoising (CDN) training is proposed, inspired by the DeNoising (DN) training of DN-DETR [44]. Second, DINO adopts a mixed query selection method to initialize the queries more effectively. Initial anchor boxes are selected as positional queries from the output of the encoder, using the top-K features, similar to [42,341], but leaving the content queries learnable. Third, DINO adopts a new box update schema, called look forward twice, where the parameters of layer i are influenced by losses of both layer i and layer . The idea is to leverage the refined box information from later layers to help optimize the parameters of their adjacent early layers.
- Other works in the DETR series
In addition to the works presented in detail, several other contributions within the DETR series have been proposed in order to tackle DETR [10] limitations. UP-DETR (Unsupervisedly Pre-train DETR) [342] proposes a pretext task, named random query patch detection in order to pre-train DETR. Efficient-DETR [341] identifies the random initialization of object containers, including object queries and reference points, as one of the causes of requiring multiple iterations. SMCA-DETR [343] replaces the original co-attention mechanism in DETR’s decoder with a Spatially Modulated Co-Attention (SMCA) mechanism to accelerate training convergence. TSP-DETR [344] identifies the Hungarian loss and the cross-attention mechanism as key factors for DETR’s slow convergence and proposes TSP-FCOS and TSP-RCNN. Conditional-DETR [339] introduces a conditional cross-attention mechanism to accelerate the training convergence of DETR. WB-DETR (DETR-based detector Without Backbone) [345] eliminates the CNN backbone from DETR, proving that CNN-based feature extraction is not essential for a transformer-based detector. PnP-DETR [346] proposes to reduce spatial redundancy and thereby improve DETR’s efficiency, by adopting a novel poll and pool (PnP) sampling module. Dynamic DETR [347] introduces dynamic attentions in both the encoder and decoder stages of DETR to overcome its limitations on small feature resolution and slow training convergence. Anchor DETR [340] introduces a new query design in which object queries are derived from anchor points. Sparse-DETR [348] introduces an encoder token sparsification mechanism and auxiliary detection loss to reduce the computational bottleneck in DETR and Deformable DETR. ETR [349] simplifies DETR by removing the encoder and introduces a Computationally Efficient Cross-scale Attention (CECA) module. FP-DETR [350] proposes a new method that fully pre-trains an encoder-only transformer and fine-tunes it for object detection using a task adapter. CF-DETR [351] improves DETR by introducing a Coarse-to-Fine (CF) decoder layer. Other works include AdaMixer [352], REGO [353], Co-DETR [354], ACT [355], MDETR [356], RefineBox [357], and RT-DETR [358].
ViT Series
The ViT series represents a family of detectors that adapt Vision Transformers (ViTs) [359], originally developed for image classification, to the task of object detection. In the following, ViT-FRCNN [46] and ViTDet [47] will be discussed in detail.
- ViT-FRCNN
In 2020, J. Beal et al. presented ViT-FRCNN [46], which extends a ViT [359] backbone for object detection by incorporating a detection network modeled after Faster R-CNN [15,16]. Specifically, ViT uses only the state corresponding to the input class token at the final transformer layer as the final feature to be fed into the classification head: the remaining tokens in the sequence are used only as features for the final class token to attend to. These unused outputs correspond to the input patches and could encode local information useful for performing object detection. ViT-FRCNN reinterprets the per-patch outputs in the final transformer states, excluding the class token, as a spatial feature map and feeds it to the detection network, as shown in Figure 11. Following Faster R-CNN [15,16], the detection network comprises a region proposal network (RPN) which identifies regions of interest, RoI-pooling, and lightweight heads for classification and bounding box regressions. ViT-FRCNN is trained at a much higher resolution than ViT [359], in an attempt to maintain as much resolution as possible, and to preserve the aspect ratio of the input image, as is standard practice for detection models.
Figure 11.
ViT-FRCNN [46] detection pipeline. ViT [359] backbone is extended to perform object detection by making use of the per-patch outputs in the final transformer layer. These outputs are reinterpreted as spatial feature map and passed to a detection network.
- ViTDet
In 2022, Y. Li et al. presented ViTDet (ViT Detector) [47], which adapts the ViT [359] backbone for object detection with minimal architectural modifications. Specifically, ViTDet addresses challenges such as handling multi-scale objects with a plain, i.e., single-scale, non-hierarchical backbone, like ViT, pre-trained on single-scale images, and overcoming the inefficiencies of applying a plain ViT architecture to high-resolution detection images. The goal is to introduce minimal modifications, only during fine-tuning, without redesigning the pre-training architecture. To replace the FPN [18], commonly used in hierarchical backbones, ViTDet introduces a simple feature pyramid where only the last feature map from the backbone is used, and on this map a set of convolutions or deconvolutions is applied in parallel to produce multi-scale feature maps. Unlike hierarchical backbones, which rely on lateral connections [18] for up-sampling, the authors found simple deconvolutions sufficient, attributing this to ViT’s reliance on positional embeddings. To adapt a pre-trained backbone, which performs global self-attention, to higher resolution inputs during fine-tuning, ViTDet employs window attention [11] with a few cross-window blocks. During fine-tuning, given a high-resolution feature map, it is divided into regular non-overlapping windows and self-attention is computed within each window. To allow information propagation, a small number (by default, four) cross-window blocks are used. A pre-trained backbone is evenly split into four subsets of blocks and a propagation strategy, global or convolutional, is applied in the last block of each subset. The backbones adopted are ViT-B, ViT-L, and ViT-H [359], pre-trained as MAEs (Masked Autoencoders) [360], while the detector heads follow Mask R-CNN [19] or Cascade Mask R-CNN [20,21].
- Other works in the ViT series
In addition to the methods presented above, several other works have explored the adaptation of ViT [359] to object detection. YOLOS [361] adapts ViT with minimal modifications: it replaces one [CLS] token for image classification with one hundred [DET] tokens for object detection and substitutes the image classification loss with the bipartite matching loss to perform set-based detection, following DETR [10]. While YOLOS directly adapts ViT for detection, many other works focus on the development or enhancement of ViT-like backbones, which are subsequently integrated into traditional detection frameworks such as RetinaNet [29], Mask R-CNN [19], Cascade Mask R-CNN [20,21], and others. These works include PVT [362], PVTv2 [363], Swin Transformer [364], Swin TransformerV2 [365], MViT [366], MViTv2 [367], PiT [368], UViT [369], XCiT [370], ViL [371], and ViT-Adapter [372].
3. Core Components and Future Trends
3.1. Loss Functions
This section provides a brief overview of loss functions for object detection, including those previously cited in the discussion of specific methods, and recent advancements. These loss functions are designed to address the two sub-tasks of object detection: classification and localization, each associated with its respective loss function, namely (classification loss) and (box regression loss).
The classification loss measures the divergence between the predicted and ground truth classes. Early detectors relied on standard cross-entropy loss; over time, new loss functions have been developed to overcome its limitations. Focal loss [29] is a dynamically scaled cross-entropy loss that addresses the problem of class imbalance. Quality Focal Loss (QFL) (QFL, part of Generalized Focal Loss, GFL) [291,373] extends focal loss with a joint representation of the classification score and the localization quality for supervision in classification. Varifocal Loss (VFL) [250] is based on focal loss, but handles the positive and negative samples asymmetrically. PolyLoss [374] decomposes loss functions into a series of weighted polynomial bases. Other examples include GHM-C [375], Consistent Loss [376], and ranking-based losses, such as aLRP Loss [377] (both classification and localization tasks), AP Loss [378,379], DR Loss [380], and RS Loss [381].
The box regression loss measures the discrepancy between the predicted and ground truth bounding boxes to refine object localization. L1 loss was the box regression loss used in early works; since then, specialized loss functions have been designed, including the IoU-series loss [240,252,271,282,283,382,383]. This series began with the IoU loss [240,382], which regresses the four bounds of a predicted box as a whole unit and is effective due to its consistency with the evaluation metrics. Subsequent variants include GIoU [283], DIoU [271], CIoU [271], -IoU [383], SIoU [282], and SDIoU [252]. Other examples include Distribution Focal Loss (DFL, part of Generalized Focal Loss, GFL) [291], and GHM-R [375].
3.2. Datasets
This section presents a brief overview of the most commonly used dataset benchmarks for generic 2D object detection. Examples of annotated images from these datasets are shown in Figure 12, while a summary of their key characteristics is provided in Table 1.
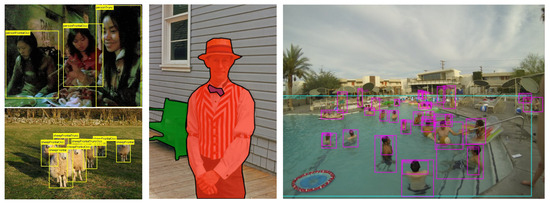
Figure 12.
Examples of images and their corresponding annotations from some of the most widely used object detection datasets. From left to right: Pascal VOC [81,82,83,384,385,386,387,388,389,390], MS-COCO [121], and Open Images [391,392,393].
3.2.1. Pascal VOC
The Pascal Visual Object Classes (VOC) [81,82,83,384,385,386,387,388,389,390] challenge was a series of annual competitions that started in 2005 and ended in 2012. Two versions of this challenge are the mostly used as standard benchmark: VOC-2007 [388] and VOC-2012 [83]. The VOC-2007 [388] challenge dataset includes 5k training images, with more than 12k labeled objects across 20 object classes, while the VOC-2012 [83] extends this to 11k training images and 27k labeled objects, maintaining the same number of classes.
3.2.2. ILSVRC
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [112] was a series of annual competitions running from 2010 to 2017. The dataset for the detection task includes 460k training images selected from ImageNet [394], belonging to 200 classes, making it two orders of magnitude larger than the Pascal VOC datasets.
3.2.3. MS-COCO
The Microsoft Common Objects in Context (MS-COCO) [121] is one of the most challenging object detection datasets available. It has been released in two main versions: the original in 2014 and an updated version in 2017 with revised data splits. MS-COCO includes 80 class categories, fewer than ILSVRC, but more object instances, more small objects, and more densely located objects. Since its introduction, MS-COCO’s popularity has grown, becoming the de facto standard benchmark for the object detection community. Table 2 presents the performance of the detectors introduced in the previous sections, evaluated on the MS-COCO test–dev split, highlighting their advancements over time.
3.2.4. Open Images
Google’s Open Images [391,392,393] is a dataset of ∼9M images annotated with image-level labels, object bounding boxes, object segmentation masks, and others. Since its initial launch in 2016, seven different versions have been released, with bounding boxes introduced from v2 [392]. The last version of the dataset contains a total of 16M bounding boxes for 600 object classes on M images, making it the largest existing dataset with object location annotations. The images are very diverse and often contain complex scenes with several objects (8.3 per image on average).
3.2.5. Objects365
Objects365 [395] is a large-scale object detection dataset, released in 2019. It includes more than 10M bounding boxes for 365 object classes on 600k training images.

Table 1.
Summary of widely used datasets for generic 2D object detection. For each dataset version, the table reports the number of classes and the number of images in the train, validation, and test splits. The numbers in parentheses indicate the total number of annotated object instances.
Table 1.
Summary of widely used datasets for generic 2D object detection. For each dataset version, the table reports the number of classes and the number of images in the train, validation, and test splits. The numbers in parentheses indicate the total number of annotated object instances.
| Dataset | Classes | Train | Val | Test |
|---|---|---|---|---|
| VOC-2007 [388] | 20 | 2501 (6301) | 2510 (6307) | 4952 |
| VOC-2012 [83] | 20 | 5717 (13,609) | 5823 (13,841) | 10,991 |
| ILSVRC-2014 [112] | 200 | 456,567 (478,807) | 20,121 (55,502) | 40,152 |
| ILSVRC-2017 [112] | 200 | 456,567 (478,807) | 20,121 (55,502) | 65,500 |
| MS-COCO-2014 [121] | 80 | 82,783 | 40,504 | 40,775 |
| MS-COCO-2017 [121] | 80 | 118,287 | 5000 | 40,670 |
| OpenImages-v7 [393] | 600 | 1,743,042 (14,610,229) | 41,620 (303,980) | 125,436 (937,327) |
| Objects365-2019 [395] | 365 | 600,000 (9,623,000) | 38,000 (479,000) | 100,000 (1,700,000) |
3.3. Evaluation Metrics
The evolution of object detection has progressed in parallel with that of its evaluation metrics. In early works on pedestrian detection, such as HOG [1], the evaluation metric was the miss rate versus FPPW (False Positives per Window); this metric was adopted, for example, in the INRIA dataset introduced in 2005 by N. Dalal et al. [1]. The typical assumption was that better PW (Per Window) scores will lead to better performance on entire images; in practice, PW scores can fail to predict per-image performance for a number of reasons [396,397]. With the introduction of the Caltech Pedestrian Dataset [396] in 2009 by P. Dollar et al., FPPW was replaced by FPPI (False Positives Per Image).
In recent years, mean Average Precision (mAP) has effectively become the de facto standard accuracy metric in object detection. The Precision (P) measures the proportion of correctly detected objects (True Positives, TP) among all detections, while the Recall (R) quantifies the proportion of correctly detected objects relative to all ground truth objects (Equation (1)). In object detection, the definition of positive and negative detections is based on the Intersection over Union (IoU), calculated as the ratio of the intersection area to union area of the predicted and ground truth bounding boxes (Equation (2)). A predicted bounding box is considered positive if its IoU with a ground truth box exceeds a predefined threshold; otherwise, it is classified as negative. The Average Precision () for a specific class c, computed as the area under the Precision–Recall curve, evaluates the accuracy of the detector of that class, while the mean Average Precision mAP represents the average across all the C classes (Equation (3)). The , and consequently the mAP, depend on the chosen IoU threshold: a higher IoU threshold imposes stricter requirements on the object localization accuracy. Historically, the IoU threshold was set to , and the corresponding has been the standard evaluation metric for the PASCAL VOC challenge since the 2007 edition [81,82,83,388,389,390]. However, to overcome the limitations of a fixed IoU threshold, the MS-COCO dataset [121] introduced , defined as the average of for IoU thresholds ranging from to at intervals of . Table 2 provides a summary of the performance of the detectors presented earlier, evaluated on the MS-COCO test–dev split using and .
Table 2.
Results on MS-COCO [121] test–dev split for the milestone object detectors discussed in the previous sections, where available.
Table 2.
Results on MS-COCO [121] test–dev split for the milestone object detectors discussed in the previous sections, where available.
| Year | Detector | Backbone | mAP | mAP |
|---|---|---|---|---|
| Two-stage | ||||
| 2015 | Fast R-CNN [14] | VGG-16 [119] | 19.7 | 35.9 |
| 2015 | Faster R-CNN [15,16] | VGG-16 [119] | 21.9 | 42.7 |
| 2016 | R-FCN (multi-scale) [17] | ResNet-101 [120] | 31.5 | 53.2 |
| 2017 | Faster R-CNN + FPN [18] | ResNet-101 [120] | 36.2 | 59.1 |
| 2017 | Mask R-CNN [19] | ResNeXt-101-FPN [18,202] | 39.8 | 62.3 |
| 2018 | Cascade R-CNN [20] | ResNet-101 [120] | 42.8 | 62.1 |
| One-stage | ||||
| 2016 | SSD512 [9] | VGG-16 [119] | 28.8 | 48.5 |
| 2017 | DSSD513 [23] | ResNet-101 [120] | 33.2 | 53.3 |
| 2017 | FSSD512 [25] | VGG-16 [119] | 31.8 | 52.8 |
| 2017 | RetinaNet-101-800 [29] | ResNet-101-FPN [18,120] | 39.1 | 59.1 |
| 2017 | YOLOv2 [36] | Darknet-19 [36] | 21.6 | 44.0 |
| 2018 | RefineDet512 (multi-scale) [26] | ResNet-101 [120] | 41.8 | 62.9 |
| 2018 | CornerNet511 (multi-scale) [30] | Hourglass-104 [199] | 42.1 | 57.8 |
| 2018 | YOLOv3 [37] | Darknet-53 [37] | 33.0 | 57.9 |
| 2019 | EFGRNet (multi-scale) [27] | ResNet-101 [120] | 43.4 | 63.8 |
| 2019 | ASSD513 [28] | ResNet-101 [120] | 34.5 | 55.5 |
| 2019 | CenterNet511-104 (multi-scale) [31] | Hourglass-104 [199] | 47.0 | 64.5 |
| 2019 | ExtremeNet (multi-scale) [32] | Hourglass-104 [199] | 43.7 | 60.5 |
| 2019 | FCOS [33] | ResNeXt-64x4d-101-FPN [202] | 44.7 | 64.1 |
| 2019 | FSAF (multi-scale) [35] | ResNeXt-101 [202] | 44.6 | 65.2 |
| 2020 | FoveaBox-align [34] | ResNeXt-101 [202] | 43.9 | 63.5 |
| 2020 | YOLOv4 [38] | CSPDarknet-53 [265] | 43.5 | 65.7 |
| 2023 | YOLOv7-E6E [40] | E-ELAN [40] based | 56.8 | 74.4 |
| Transformer-based | ||||
| 2020 | Deformable DETR (with TTA) [42] | ResNeXt-101 [202] + DCN [155] | 52.3 | 71.9 |
| 2022 | DINO (with TTA) [45] | SwinL [364] | 63.3 | - |
Other, less commonly used metrics include Average Recall (AR) and more recent ones, such as Localization Recall Precision (LRP) [398]. Beyond accuracy, efficiency metrics are also critical, especially for applications that require real-time performance or deployment on resource-constrained devices; standard metrics include inference time, Frames Per Second (FPS), model parameters, and FLOPs.
3.4. Future Trends
Despite significant advancements in object detection, several challenges remain areas of active research, as further refinements are still needed to enhance performance and applicability in real-world scenarios. Nowadays, research efforts focus on improving generalization to unseen domains, optimization for resource-constrained edge devices, and scalability to novel object categories without extensive labeled data. Addressing these aspects requires novel approaches that push beyond traditional detection frameworks. Below, we highlight some of the most promising research directions that are expected to shape the future of object detection and beyond.
- Domain Adaptation (DA): Traditional object detection models assume that training and test data are sampled from the same distribution. However, this assumption often does not hold in real-world applications, where detectors encounter new visual domains. Domain Adaptation (DA) addresses the challenge of domain shifts between the source and target domains. DA techniques can be broadly classified into three categories. Domain transfer techniques first translate source domain images into the target domain, and then fine-tune the detector on both source and target domain datasets (see [399,400]). The second set of methods aligns the distribution of source and target domains using an adversarial loss (see [401,402,403,404,405,406,407]), while the third type is based on Self-Training, which is often combined with the previous approaches (see [399,400,401,408]). Domain Adaptation remains an active research area, aiming to improve robustness and scalability in real-world scenarios.
- Open Vocabulary Object Detection (OVOD): OVOD aims to generalize beyond the limited number of base classes labeled during the training stage. The goal is to detect novel classes defined by an unbounded (open) vocabulary at inference, typically by incorporating language information to guide the detector. Different strategies have been proposed: knowledge distillation from VLMs, such as ViLD [409], LP-OVOD [410], and HierKD [411], region text pre-training, such as OVR-CNN [412] and GLIP [413,414], training with more balanced data, such as Detic [415], PB-OVOD [416], and MM-OVOD [417], prompting modeling, such as CORA [418], PromptDet [419], and PromptOVD [420], and region text alignment, such as OV-DETR [421], VLDet [422], and CoDet [423]. OVOD is expected to play a central role in addressing the growing demand for generalized AI solutions. For a more comprehensive overview of the OVOD methods, see [424].
- Vision–Language Models (VLMs): Vision–Language Models (VLMs) are a class of models designed to jointly process visual and textual information; they are typically pre-trained on massive image–text datasets. From early works such as CLIP [425] and ALIGN [426], the number of VLMs has grown rapidly. An increasing integration of VLMs into object detection frameworks is expected in the coming years. For a more comprehensive overview of VLMs, see [427].
- Vision Foundation Models (VFMs): Recent years have witnessed remarkable success in developing foundation models that are trained on large-scale broad data and, once trained, they operate as a basis and can be fine-tuned to a wide range of downstream tasks [428]. For vision tasks, notable examples in the context of object detection include GroundingDINO [429], GLIP [413,414], and Florence [430,431]. VFMs are becoming more and more versatile and pivotal, with their capabilities of generalizing across various vision tasks, including object detection, and are expected to expand significantly in the coming years. For a more comprehensive overview of VFMs, see [432].
- Neural Architecture Search (NAS): A promising direction for future research is the use of Neural Architecture Search (NAS) [433,434,435] to automatically design or optimize detection frameworks. In fact, NAS has been applied in several object detection frameworks, including NAS-FPN [132], DetNAS [436], Auto-FPN [133], SM-NAS [437], HitDetector [438], NAS-FCOS [439], SpineNet [440], FBNetV5 [441], and MobileDets [442]. It is reasonable to expect NAS to play an ever-growing role in the design of future detection systems.
- Lightweight Object Detection: Recent advancements have focused on lightweight object detection to enable inference on resource-constrained edge devices, such as mobile phones, IoT devices, and others. The goal is to design compact, low-latency models that maintain high accuracy while minimizing computational requirements. Examples include Tiny-DSOD [443], NanoDet [245], and YOLObile [444]. Given the widespread adoption of IoT devices and real-time applications, lightweight models will play a growing central role. For a more comprehensive overview, see [445].
4. Conclusions
This survey provides a comprehensive review of the evolution of 2D generic object detection, tracing its progression over the last twenty-five years from traditional handcrafted feature-based approaches to modern deep learning-driven methods. The categorization of modern object detection frameworks into three main paradigms—two-stage, one-stage, and transformer-based detectors—highlights the diverse approaches developed to tackle the challenges posed by object detection. Each paradigm has brought unique contributions to the field, from the region proposal and refinement techniques of two-stage detectors to the streamlined architectures of the one-stage approach, and the global context modeling enabled by transformer-based models. For each paradigm, this survey has outlined the key milestones and highlighted the technical innovations shaping the field’s historical trajectory and current state. In addition, we have explored essential components of object detection, including loss functions, datasets, and evaluation metrics. Despite the significant progress made, object detection remains an active research area. In this context, this survey also examined several future trends that are expected to shape the next generation of object detection methods.
By providing a systematic and critical analysis of past and present methodologies, this survey aims to serve as a valuable resource for researchers and practitioners, fostering further innovation in this rapidly evolving field.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Corfu, Greece, 20–25 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M.J. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. 511–518. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1106–1114. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Volume 12346, pp. 213–229. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Felzenszwalb, P.F.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29, 379–387. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High quality object detection and instance segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. arXiv 2017, arXiv:1705.09587. [Google Scholar]
- Li, Z.; Yang, L.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4203–4212. [Google Scholar]
- Nie, J.; Anwer, R.M.; Cholakkal, H.; Khan, F.S.; Pang, Y.; Shao, L. Enriched feature guided refinement network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 9536–9545. [Google Scholar]
- Yi, J.; Wu, P.; Metaxas, D.N. ASSD: Attentive single shot multibox detector. Comput. Vis. Image Underst. 2019, 189, 102827. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11218, pp. 765–781. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Zhou, X.; Zhuo, J.; Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 850–859. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea (South), 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 840–849. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. Dab-detr: Dynamic anchor boxes are better queries for detr. arXiv 2022, arXiv:2201.12329. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. DN-DETR: Accelerate detr training by introducing query denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13609–13617. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward transformer-based object detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Li, Y.; Mao, H.; Girshick, R.; He, K. Exploring plain vision transformer backbones for object detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Volume 13669, pp. 280–296. [Google Scholar]
- Tsochantaridis, I.; Joachims, T.; Hofmann, T.; Altun, Y.; Singer, Y. Large margin methods for structured and interdependent output variables. J. Mach. Learn. Res. 2005, 6, 1453–1484. [Google Scholar]
- Blaschko, M.B.; Lampert, C.H. Learning to localize objects with structured output regression. In Computer Vision–ECCV 2008, Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; Proceedings, Part I 10; Springer: Berlin/Heidelberg, Germany, 2008; pp. 2–15. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. In Proceedings of the European Conference on Computational Learning Theory, Barcelona, Spain, 13–15 March 1995; pp. 23–37. [Google Scholar]
- Sung, K.K.; Poggio, T. Example-based learning for view-based human face detection. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 39–51. [Google Scholar] [CrossRef]
- Rowley, H.A.; Baluja, S.; Kanade, T. Neural network-based face detection. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 23–38. [Google Scholar] [CrossRef]
- Osuna, E.; Freund, R.; Girosit, F. Training support vector machines: An application to face detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Juan, Puerto Rico, 17–19 June 1997; pp. 130–136. [Google Scholar]
- Schneiderman, H.; Kanade, T. A statistical method for 3D object detection applied to faces and cars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head, SC, USA, 13–15 June 2000; Volume 1, pp. 746–751. [Google Scholar]
- Yang, M.H.; Roth, D.; Ahuja, N. A SNoW-based face detector. Adv. Neural Inf. Process. Syst. 1999, 12, 862–868. [Google Scholar]
- Viola, P.; Jones, M.J.; Snow, D. Detecting pedestrians using patterns of motion and appearance. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 14–17 October 2003; Volume 2, pp. 734–741. [Google Scholar]
- Freeman, W.T.; Roth, M. Orientation histograms for hand gesture recognition. In Proceedings of the International Workshop on Automatic Face and Gesture Recognition, Zurich, Switzerland, 26–28 June 1995; pp. 296–301. [Google Scholar]
- Freeman, W.T.; Tanaka, K.i.; Ohta, J.; Kyuma, K. Computer vision for computer games. In Proceedings of the Second International Conference on Automatic Face and Gesture Recognition, Killington, Vermont, USA, 14–16 October 1996; pp. 100–105. [Google Scholar]
- Belongie, S.; Malik, J.; Puzicha, J. Matching shapes. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 1, pp. 454–461. [Google Scholar]
- Mohan, A.; Papageorgiou, C.; Poggio, T. Example-based object detection in images by components. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 349–361. [Google Scholar] [CrossRef]
- Papageorgiou, C.; Poggio, T. A trainable system for object detection. Int. J. Comput. Vis. 2000, 38, 15–33. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D. Cascade object detection with deformable part models. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2241–2248. [Google Scholar]
- Zhang, J.; Huang, K.; Yu, Y.; Tan, T. Boosted local structured hog-lbp for object localization. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1393–1400. [Google Scholar]
- Wang, X.; Han, T.X.; Yan, S. An HOG-LBP human detector with partial occlusion handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 32–39. [Google Scholar]
- Yu, Y.; Zhang, J.; Huang, Y.; Zheng, S.; Ren, W.; Wang, C.; Huang, K.; Tan, T. Object detection by context and boosted HOG-LBP. In Proceedings of the ECCV Workshop on PASCAL VOC, Heraklion, Crete, Greece, 11 September 2010. [Google Scholar]
- Ren, X.; Ramanan, D. Histograms of sparse codes for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3246–3253. [Google Scholar]
- Gould, S.; Gao, T.; Koller, D. Region-based segmentation and object detection. Adv. Neural Inf. Process. Syst. 2009, 22, 655–663. [Google Scholar]
- Malisiewicz, T.; Gupta, A.; Efros, A.A. Ensemble of exemplar-svms for object detection and beyond. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 89–96. [Google Scholar]
- Amit, Y.; Trouvé, A. Pop: Patchwork of parts models for object recognition. Int. J. Comput. Vis. 2007, 75, 267–282. [Google Scholar] [CrossRef]
- Burl, M.C.; Weber, M.; Perona, P. A probabilistic approach to object recognition using local photometry and global geometry. In Computer Vision–ECCV’98, Proceedings of the 5th European Conference on Computer Vision, Freiburg, Germany, 2–6 June 1998; Proceedings, Volume II 5; Springer: Berlin/Heidelberg, Germany, 1998; pp. 628–641. [Google Scholar]
- Crandall, D.; Felzenszwalb, P.F.; Huttenlocher, D. Spatial priors for part-based recognition using statistical models. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 10–17. [Google Scholar]
- Epshtein, B.; Ullman, S. Semantic hierarchies for recognizing objects and parts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 18–23 June 2007; pp. 1–8. [Google Scholar]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Pictorial structures for object recognition. Int. J. Comput. Vis. 2005, 61, 55–79. [Google Scholar] [CrossRef]
- Fergus, R.; Perona, P.; Zisserman, A. Object class recognition by unsupervised scale-invariant learning. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 16–22 June 2003; Volume 2, pp. 264–271. [Google Scholar]
- Fischler, M.A.; Elschlager, R.A. The representation and matching of pictorial structures. IEEE Trans. Comput. 1973, 100, 67–92. [Google Scholar] [CrossRef]
- Ioffe, S.; Forsyth, D.A. Probabilistic methods for finding people. Int. J. Comput. Vis. 2001, 43, 45–68. [Google Scholar] [CrossRef]
- Jin, Y.; Geman, S. Context and hierarchy in a probabilistic image model. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2145–2152. [Google Scholar]
- Schneiderman, H.; Kanade, T. Object detection using the statistics of parts. Int. J. Comput. Vis. 2004, 56, 151–177. [Google Scholar] [CrossRef]
- Adelson, E.H.; Anderson, C.H.; Bergen, J.R.; Burt, P.J.; Ogden, J.M. Pyramid methods in image processing. RCA Eng. 1984, 29, 33–41. [Google Scholar]
- Andrews, S.; Tsochantaridis, I.; Hofmann, T. Support vector machines for multiple-instance learning. Adv. Neural Inf. Process. Syst. 2002, 15, 561–568. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2008 (VOC2008) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2008/workshop/index.html (accessed on 13 November 2024).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2009 (VOC2009) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2009/workshop/index.html (accessed on 13 November 2024).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html (accessed on 13 November 2024).
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; McAllester, D. Object detection grammars. In Proceedings of the International Conference on Computer Vision Workshops, Barcelona, Spain, 6–13 November 2011; p. 691. [Google Scholar]
- Girshick, R.; Felzenszwalb, P.F.; McAllester, D. Object detection with grammar models. Adv. Neural Inf. Process. Syst. 2011, 24, 442–450. [Google Scholar]
- Girshick, R.B. From Rigid Templates to Grammars: Object Detection with Structured Models; The University of Chicago: Chicago, IL, USA, 2012. [Google Scholar]
- Sadeghi, M.A.; Forsyth, D. 30hz object detection with dpm v5. In Computer Vision–ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part I 13; Springer: Cham, Switzerland, 2014; pp. 65–79. [Google Scholar]
- Yan, J.; Lei, Z.; Wen, L.; Li, S.Z. The fastest deformable part model for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2497–2504. [Google Scholar]
- Dean, T.; Ruzon, M.A.; Segal, M.; Shlens, J.; Vijayanarasimhan, S.; Yagnik, J. Fast, accurate detection of 100,000 object classes on a single machine. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1814–1821. [Google Scholar]
- Azizpour, H.; Laptev, I. Object detection using strongly-supervised deformable part models. In Computer Vision–ECCV 2012, Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Proceedings, Part I 12; Springer: Berlin/Heidelberg, Germany, 2012; pp. 836–849. [Google Scholar]
- Yang, Y.; Ramanan, D. Articulated human detection with flexible mixtures of parts. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2878–2890. [Google Scholar] [CrossRef]
- Dong, J.; Chen, Q.; Yan, S.; Yuille, A. Towards unified object detection and semantic segmentation. In Computer Vision–ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13; Springer: Cham, Switzerland, 2014; pp. 299–314. [Google Scholar]
- Gokberk Cinbis, R.; Verbeek, J.; Schmid, C. Segmentation driven object detection with fisher vectors. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2968–2975. [Google Scholar]
- Lampert, C.H.; Blaschko, M.B.; Hofmann, T. Beyond sliding windows: Object localization by efficient subwindow search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 24–26 June 2008; pp. 1–8. [Google Scholar]
- Van De Sande, K.; Gevers, T.; Snoek, C. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1582–1596. [Google Scholar] [CrossRef]
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Ke, Y.; Sukthankar, R. PCA-SIFT: A more distinctive representation for local image descriptors. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 2, pp. 506–513. [Google Scholar]
- Dollár, P.; Tu, Z.; Perona, P.; Belongie, S.J. Integral channel features. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2009; pp. 1–11. [Google Scholar]
- Dollár, P.; Belongie, S.J.; Perona, P. The fastest pedestrian detector in the west. In Proceedings of the British Machine Vision Conference, Aberystwyth, UK, 31 August–3 September 2010; pp. 1–11. [Google Scholar]
- Dollár, P.; Appel, R.; Kienzle, W. Crosstalk cascades for frame-rate pedestrian detection. In Computer Vision–ECCV 2012, Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Proceedings, Part II 12; Springer: Berlin/Heidelberg, Germany, 2012; pp. 645–659. [Google Scholar]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A general framework for object detection. In Proceedings of the Sixth International Conference on Computer Vision, Bombay, India, 4–7 January 1998; pp. 555–562. [Google Scholar]
- Lienhart, R.; Maydt, J. An extended set of haar-like features for rapid object detection. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; Volume 1, pp. 900–903. [Google Scholar]
- Leibe, B.; Leonardis, A.; Schiele, B. Robust object detection with interleaved categorization and segmentation. Int. J. Comput. Vis. 2008, 77, 259–289. [Google Scholar] [CrossRef]
- Gall, J.; Lempitsky, V. Class-specific hough forests for object detection. In Decision Forests for Computer Vision and Medical Image Analysis; Springer: London, UK, 2013; pp. 143–157. [Google Scholar]
- Barinova, O.; Lempitsky, V.; Kholi, P. On detection of multiple object instances using hough transforms. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1773–1784. [Google Scholar] [CrossRef]
- Wang, X.; Yang, M.; Zhu, S.; Lin, Y. Regionlets for generic object detection. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 17–24. [Google Scholar]
- Vedaldi, A.; Gulshan, V.; Varma, M.; Zisserman, A. Multiple kernels for object detection. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 606–613. [Google Scholar]
- Vaillant, R.; Monrocq, C.; Le Cun, Y. Original approach for the localisation of objects in images. IEE Proc.-Vis. Image Signal Process. 1994, 141, 245–250. [Google Scholar] [CrossRef]
- Rowley, H.; Baluja, S.; Kanade, T. Human face detection in visual scenes. Adv. Neural Inf. Process. Syst. 1995, 8, 875–881. [Google Scholar]
- Rowley, H.A.; Baluja, S.; Kanade, T. Rotation invariant neural network-based face detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Santa Barbara, CA, USA, 23–25 June 1998; pp. 38–44. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Van de Sande, K.E.; Uijlings, J.R.; Gevers, T.; Smeulders, A.W. Segmentation as selective search for object recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 1879–1886. [Google Scholar]
- Grauman, K.; Darrell, T. The pyramid match kernel: Discriminative classification with sets of image features. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–20 October 2005; Volume 2, pp. 1458–1465. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 14–17 October 2003; Volume 2, pp. 1470–1477. [Google Scholar]
- Zitnick, C.L.; Dollár, P. Edge boxes: Locating object proposals from edges. In Computer Vision–ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13; Springer: Cham, Switzerland, 2014; pp. 391–405. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3297. [Google Scholar]
- Shrivastava, A.; Sukthankar, R.; Malik, J.; Gupta, A. Beyond skip connections: Top-down modulation for object detection. arXiv 2016, arXiv:1612.06851. [Google Scholar]
- Cheng, B.; Wei, Y.; Shi, H.; Feris, R.; Xiong, J.; Huang, T. Revisiting RCNN: On Awakening the Classification Power of Faster RCNN. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 473–490. [Google Scholar]
- Shrivastava, A.; Gupta, A. Contextual priming and feedback for Faster R-CNN. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14; Springer: Cham, Switzerland, 2016; pp. 330–348. [Google Scholar]
- Dai, J.; He, K.; Li, Y.; Ren, S.; Sun, J. Instance-sensitive fully convolutional networks. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VI 14; Springer: Cham, Switzerland, 2016; pp. 534–549. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Singh, B.; Davis, L.S. An analysis of scale invariance in object detection SNIP. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3578–3587. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G.; Zhang, X.; Deng, Y.; Sun, J. Light-head r-cnn: In defense of two-stage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Kim, S.W.; Kook, H.K.; Sun, J.Y.; Kang, M.C.; Ko, S.J. Parallel feature pyramid network for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 239–256. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. NAS-FPN: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7036–7045. [Google Scholar]
- Xu, H.; Yao, L.; Zhang, W.; Liang, X.; Li, Z. Auto-FPN: Automatic network architecture adaptation for object detection beyond classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 6648–6657. [Google Scholar]
- Hu, M.; Li, Y.; Fang, L.; Wang, S. A2-FPN: Attention aggregation based feature pyramid network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 15343–15352. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AugFPN: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12592–12601. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In Computer Vision–ECCV 2014, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part VII 13; Springer: Cham, Switzerland, 2014; pp. 297–312. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Hypercolumns for object segmentation and fine-grained localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 447–456. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Convolutional feature masking for joint object and stuff segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3992–4000. [Google Scholar]
- O Pinheiro, P.O.; Collobert, R.; Dollár, P. Learning to segment object candidates. Adv. Neural Inf. Process. Syst. 2015, 28, 1990–1998. [Google Scholar]
- Pinheiro, P.O.; Lin, T.Y.; Collobert, R.; Dollár, P. Learning to refine object segments. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14; Springer: Cham, Switzerland, 2016; pp. 75–91. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Instance-aware semantic segmentation via multi-task network cascades. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3150–3158. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully convolutional instance-aware semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4438–4446. [Google Scholar]
- Dollár, P.; Welinder, P.; Perona, P. Cascaded pose regression. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1078–1085. [Google Scholar]
- Cao, X.; Wei, Y.; Wen, F.; Sun, J. Face alignment by explicit shape regression. Int. J. Comput. Vis. 2014, 107, 177–190. [Google Scholar] [CrossRef]
- Yan, J.; Lei, Z.; Yi, D.; Li, S. Learn to combine multiple hypotheses for accurate face alignment. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013; pp. 392–396. [Google Scholar]
- Gidaris, S.; Komodakis, N. Object detection via a multi-region and semantic segmentation-aware CNN model. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1134–1142. [Google Scholar]
- Ouyang, W.; Wang, X.; Zeng, X.; Qiu, S.; Luo, P.; Tian, Y.; Li, H.; Yang, S.; Wang, Z.; Loy, C.C.; et al. Deepid-net: Deformable deep convolutional neural networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2403–2412. [Google Scholar]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV 14; Springer: Cham, Switzerland, 2016; pp. 354–370. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 845–853. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-outside net: Detecting objects in context with skip pooling and recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Wang, X.; Shrivastava, A.; Gupta, A. A-Fast-RCNN: Hard positive generation via adversary for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3039–3048. [Google Scholar]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of localization confidence for accurate object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11218, pp. 816–832. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 6053–6062. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 821–830. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable ConvNets V2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9308–9316. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 14454–14463. [Google Scholar]
- Lenc, K.; Vedaldi, A. R-CNN minus R. arXiv 2015, arXiv:1506.06981. [Google Scholar]
- Zeng, X.; Ouyang, W.; Yang, B.; Yan, J.; Wang, X. Gated bi-directional cnn for object detection. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VII 14; Springer: Cham, Switzerland, 2016; pp. 354–369. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Zhang, X.; Sun, J. Object detection networks on convolutional feature maps. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1476–1481. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Lerer, A.; Lin, T.Y.; Pinheiro, P.O.; Gross, S.; Chintala, S.; Dollár, P. A multipath network for object detection. arXiv 2016, arXiv:1604.02135. [Google Scholar]
- Li, J.; Wei, Y.; Liang, X.; Dong, J.; Xu, T.; Feng, J.; Yan, S. Attentive contexts for object detection. IEEE Trans. Multimed. 2016, 19, 944–954. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhao, C.; Wang, J.; Zhao, X.; Wu, Y.; Lu, H. CoupleNet: Coupling global structure with local parts for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4146–4154. [Google Scholar]
- Peng, C.; Xiao, T.; Li, Z.; Jiang, Y.; Zhang, X.; Jia, K.; Yu, G.; Sun, J. MegDet: A large mini-batch object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6181–6189. [Google Scholar]
- Zhai, Y.; Fu, J.; Lu, Y.; Li, H. Feature selective networks for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4139–4147. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Occlusion-aware R-CNN: Detecting pedestrians in a crowd. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 657–674. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation networks for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3588–3597. [Google Scholar]
- Lee, H.; Eum, S.; Kwon, H. Me r-cnn: Multi-expert r-cnn for object detection. IEEE Trans. Image Process. 2019, 29, 1030–1044. [Google Scholar] [CrossRef]
- Najibi, M.; Singh, B.; Davis, L.S. Autofocus: Efficient multi-scale inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 9744–9754. [Google Scholar]
- Levinshtein, A.; Sereshkeh, A.R.; Derpanis, K. DATNet: Dense auxiliary tasks for object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 1408–1416. [Google Scholar]
- Song, G.; Liu, Y.; Wang, X. Revisiting the sibling head in object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11560–11569. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. DetectoRS: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 10213–10224. [Google Scholar]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for small object detection. In Computer Vision–ACCV 2016, Proceedings of the 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers; Part V 13; Springer: Cham, Switzerland, 2017; pp. 214–230. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4974–4983. [Google Scholar]
- Du, X.; Zoph, B.; Hung, W.C.; Lin, T.Y. Simple training strategies and model scaling for object detection. arXiv 2021, arXiv:2107.00057. [Google Scholar]
- Yang, B.; Yan, J.; Lei, Z.; Li, S.Z. Craft objects from images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 6043–6051. [Google Scholar]
- Ouyang, W.; Wang, K.; Zhu, X.; Wang, X. Chained cascade network for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1956–1964. [Google Scholar]
- Vu, T.; Jang, H.; Pham, T.X.; Yoo, C. Cascade RPN: Delving into high-quality region proposal network with adaptive convolution. Adv. Neural Inf. Process. Syst. 2019, 32, 1430–1440. [Google Scholar]
- Wang, J.; Chen, K.; Yang, S.; Loy, C.C.; Lin, D. Region proposal by guided anchoring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2965–2974. [Google Scholar]
- Gidaris, S.; Komodakis, N. Locnet: Improving localization accuracy for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 789–798. [Google Scholar]
- Gidaris, S.; Komodakis, N. Attend refine repeat: Active box proposal generation via in-out localization. arXiv 2016, arXiv:1606.04446. [Google Scholar]
- Xiang, Y.; Choi, W.; Lin, Y.; Savarese, S. Subcategory-aware convolutional neural networks for object proposals and detection. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 924–933. [Google Scholar]
- Zhong, Q.; Li, C.; Zhang, Y.; Xie, D.; Yang, S.; Pu, S. Cascade region proposal and global context for deep object detection. Neurocomputing 2020, 395, 170–177. [Google Scholar] [CrossRef]
- Erhan, D.; Szegedy, C.; Toshev, A.; Anguelov, D. Scalable object detection using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2155–2162. [Google Scholar]
- Szegedy, C.; Reed, S.; Erhan, D.; Anguelov, D.; Ioffe, S. Scalable, high-quality object detection. arXiv 2014, arXiv:1412.1441. [Google Scholar]
- Shen, Z.; Xue, X. Do more dropouts in pool5 feature maps for better object detection. arXiv 2014, arXiv:1409.6911. [Google Scholar]
- Xu, H.; Lv, X.; Wang, X.; Ren, Z.; Bodla, N.; Chellappa, R. Deep regionlets for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11215, pp. 827–844. [Google Scholar]
- Tychsen-Smith, L.; Petersson, L. DeNet: Scalable real-time object detection with directed sparse sampling. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 428–436. [Google Scholar]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7363–7372. [Google Scholar]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 9656–9665. [Google Scholar]
- Duan, K.; Xie, L.; Qi, H.; Bai, S.; Huang, Q.; Tian, Q. Corner proposal network for anchor-free, two-stage object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Volume 12348, pp. 399–416. [Google Scholar]
- Zhong, Z.; Sun, L.; Huo, Q. An anchor-free region proposal network for Faster R-CNN-based text detection approaches. Int. J. Doc. Anal. Recognit. (IJDAR) 2019, 22, 315–327. [Google Scholar] [CrossRef]
- Zhou, X.; Koltun, V.; Krähenbühl, P. Probabilistic two-stage detection. arXiv 2021, arXiv:2103.07461. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Qiu, H.; Li, H.; Wu, Q.; Cui, J.; Song, Z.; Wang, L.; Zhang, M. CrossDet: Crossline representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3175–3184. [Google Scholar]
- Qiu, H.; Li, H.; Wu, Q.; Cui, J.; Song, Z.; Wang, L.; Zhang, M. CrossDet++: Growing crossline representation for object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1093–1108. [Google Scholar] [CrossRef]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. Adv. Neural Inf. Process. Syst. 2013, 26, 2553–2561. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 483–499. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5987–5995. [Google Scholar]
- Pang, Y.; Xie, J.; Li, X. Visual haze removal by a unified generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3211–3221. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.G.; Chen, Y.; Xue, X. DSOD: Learning deeply supervised object detectors from scratch. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1937–1945. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.G.; Chen, Y.; Xue, X. Object detection from scratch with deep supervision. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 398–412. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-Supervised Nets. In Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics, San Diego, CA, USA, 9–12 May 2015; Volume 38, pp. 562–570. [Google Scholar]
- Shen, Z.; Shi, H.; Feris, R.; Cao, L.; Yan, S.; Liu, D.; Wang, X.; Xue, X.; Huang, T.S. Learning object detectors from scratch with gated recurrent feature pyramids. arXiv 2017, arXiv:1712.00886. [Google Scholar]
- Zheng, L.; Fu, C.; Zhao, Y. Extend the shallow part of single shot multibox detector via convolutional neural network. In Proceedings of the Tenth International Conference on Digital Image Processing (ICDIP 2018), Shanghai, China, 11–14 May 2018; Volume 10806. 1080613. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11215, pp. 404–419. [Google Scholar]
- Zhang, Z.; Qiao, S.; Xie, C.; Shen, W.; Wang, B.; Yuille, A.L. Single-shot object detection with enriched semantics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5813–5821. [Google Scholar]
- Cao, G.; Xie, X.; Yang, W.; Liao, Q.; Shi, G.; Wu, J. Feature-fused SSD: Fast detection for small objects. In Proceedings of the Ninth International Conference on Graphic and Image Processing (ICGIP 2017), Qingdao, China, 14–16 October 2017; Volume 10615, p. 106151E. [Google Scholar]
- Yang, J.; Wang, L. Feature fusion and enhancement for single shot multibox detector. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 2766–2770. [Google Scholar]
- Ren, J.; Chen, X.; Liu, J.; Sun, W.; Pang, J.; Yan, Q.; Tai, Y.W.; Xu, L. Accurate single stage detector using recurrent rolling convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 752–760. [Google Scholar]
- Pang, Y.; Wang, T.; Anwer, R.M.; Khan, F.S.; Shao, L. Efficient featurized image pyramid network for single shot detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7336–7344. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2Det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Chandio, A.; Gui, G.; Kumar, T.; Ullah, I.; Ranjbarzadeh, R.; Roy, A.M.; Hussain, A.; Shen, Y. Precise single-stage detector. arXiv 2022, arXiv:2210.04252. [Google Scholar]
- Sung, K.K. Learning and Example Selection for Object and Pattern Detection. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1995. [Google Scholar]
- Fu, C.Y.; Shvets, M.; Berg, A.C. RetinaMask: Learning to predict masks improves state-of-the-art single-shot detection for free. arXiv 2019, arXiv:1901.03353. [Google Scholar]
- Jaeger, P.F.; Kohl, S.A.; Bickelhaupt, S.; Isensee, F.; Kuder, T.A.; Schlemmer, H.P.; Maier-Hein, K.H. Retina U-Net: Embarrassingly simple exploitation of segmentation supervision for medical object detection. In Proceedings of the Machine Learning for Health Workshop, Vancouver, BC, Canada, 13 December 2019; Volume 116, pp. 171–183. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Yang, T.; Zhang, X.; Li, Z.; Zhang, W.; Sun, J. MetaAnchor: Learning to detect objects with customized anchors. Adv. Neural Inf. Process. Syst. 2018, 31, 318–328. [Google Scholar]
- Newell, A.; Huang, Z.; Deng, J. Associative embedding: End-to-end learning for joint detection and grouping. Adv. Neural Inf. Process. Syst. 2017, 30, 2277–2287. [Google Scholar]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. Cornernet-lite: Efficient keypoint based object detection. arXiv 2019, arXiv:1904.08900. [Google Scholar]
- Bahill, A.T.; Clark, M.R.; Stark, L. The main sequence, a tool for studying human eye movements. Math. Biosci. 1975, 24, 191–204. [Google Scholar] [CrossRef]
- Yarbus, A.L. Eye Movements and Vision; Springer: New York, NY, USA, 2013. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1302–1310. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7103–7112. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11210, pp. 472–487. [Google Scholar]
- Papadopoulos, D.P.; Uijlings, J.R.; Keller, F.; Ferrari, V. Extreme clicking for efficient object annotation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4940–4949. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar]
- Yoo, D.; Park, S.; Lee, J.Y.; Paek, A.S.; So Kweon, I. AttentionNet: Aggregating weak directions for accurate object detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2659–2667. [Google Scholar]
- Wang, X.; Chen, K.; Huang, Z.; Yao, C.; Liu, W. Point linking network for object detection. arXiv 2017, arXiv:1706.03646. [Google Scholar]
- Rashwan, A.; Kalra, A.; Poupart, P. Matrix Nets: A new deep architecture for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea (South), 27–28 October 2019; pp. 2025–2028. [Google Scholar]
- Dong, Z.; Li, G.; Liao, Y.; Wang, F.; Ren, P.; Qian, C. CentripetalNet: Pursuing high-quality keypoint pairs for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10516–10525. [Google Scholar]
- Huang, L.; Yang, Y.; Deng, Y.; Yu, Y. Densebox: Unifying landmark localization with end to end object detection. arXiv 2015, arXiv:1509.04874. [Google Scholar]
- Iwasaki, M.; Inomata, H. Relation between superficial capillaries and foveal structures in the human retina. Investig. Ophthalmol. Vis. Sci. 1986, 27, 1698–1705. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A simple and strong anchor-free object detector. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1922–1933. [Google Scholar] [CrossRef]
- Qiu, H.; Ma, Y.; Li, Z.; Liu, S.; Sun, J. Borderdet: Border feature for dense object detection. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16; Springer: Cham, Switzerland, 2020; pp. 549–564. [Google Scholar]
- Lee, Y.; Park, J. CenterMask: Real-time anchor-free instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13903–13912. [Google Scholar]
- Zhou, Q.; Yu, C. Object detection made simpler by eliminating heuristic NMS. IEEE Trans. Multimed. 2023, 25, 9254–9262. [Google Scholar] [CrossRef]
- RangiLyu. NanoDet-Plus: Super Fast and High Accuracy Lightweight Anchor-Free Object Detection Model. 2021. Available online: https://github.com/RangiLyu/nanodet (accessed on 27 October 2024).
- Yu, G.; Chang, Q.; Lv, W.; Xu, C.; Cui, C.; Ji, W.; Dang, Q.; Deng, K.; Wang, G.; Du, Y.; et al. PP-PicoDet: A better real-time object detector on mobile devices. arXiv 2021, arXiv:2111.00902. [Google Scholar]
- Wang, J.; Yuan, Y.; Li, B.; Yu, G.; Jian, S. Sface: An efficient network for face detection in large scale variations. arXiv 2018, arXiv:1804.06559. [Google Scholar]
- Liu, W.; Liao, S.; Ren, W.; Hu, W.; Yu, Y. High-level semantic feature detection: A new perspective for pedestrian detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5187–5196. [Google Scholar]
- Zhu, C.; Chen, F.; Shen, Z.; Savvides, M. Soft anchor-point object detection. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IX 16; Springer: Cham, Switzerland, 2020; pp. 91–107. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sunderhauf, N. Varifocalnet: An iou-aware dense object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 8514–8523. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9756–9765. [Google Scholar]
- Zand, M.; Etemad, A.; Greenspan, M. Objectbox: From centers to boxes for anchor-free object detection. In Proceedings of the European Conference on Computer Vision. Springer, Tel Aviv, Israel, 23–27 October 2022; Volume 13670, pp. 390–406. [Google Scholar]
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. Rtmdet: An empirical study of designing real-time object detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO. 2024. Available online: https://zenodo.org/records/14551695 (accessed on 2 March 2025).
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO. 2023. Available online: https://zenodo.org/records/14551695 (accessed on 2 March 2025).
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Jocher, G. Ultralytics YOLOv5. 2020. Available online: https://zenodo.org/records/7347926 (accessed on 2 October 2024).
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Redmon, J.; Angelova, A. Real-time grasp detection using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1316–1322. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2014, arXiv:1312.4400. [Google Scholar]
- Redmon, J.; Darknet: Open Source Neural Networks in C. 2013–2016. Available online: http://pjreddie.com/darknet/ (accessed on 13 December 2024).
- Nickolls, J.; Buck, I.; Garland, M.; Skadron, K. Scalable parallel programming with cuda: Is cuda the parallel programming model that application developers have been waiting for? Queue 2008, 6, 40–53. [Google Scholar] [CrossRef]
- Miller, G.A.; Beckwith, R.; Fellbaum, C.; Gross, D.; Miller, K.J. Introduction to WordNet: An on-line lexical database. Int. J. Lexicogr. 1990, 3, 235–244. [Google Scholar] [CrossRef]
- Choi, J.; Chun, D.; Kim, H.; Lee, H.J. Gaussian yolov3: An accurate and fast object detector using localization uncertainty for autonomous driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 502–511. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 6022–6031. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. Adv. Neural Inf. Process. Syst. 2018, 31, 10750–10760. [Google Scholar]
- Yao, Z.; Cao, Y.; Zheng, S.; Huang, G.; Lin, S. Cross-iteration batch normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 12331–12340. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 13029–13038. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 2918–2928. [Google Scholar]
- Zhang, H. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8024–8035. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13733–13742. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned one-stage object detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3490–3499. [Google Scholar]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Hinton, G. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Ding, X.; Chen, H.; Zhang, X.; Huang, K.; Han, J.; Ding, G. Re-parameterizing your optimizers rather than architectures. arXiv 2022, arXiv:2205.15242. [Google Scholar]
- Shu, C.; Liu, Y.; Gao, J.; Yan, Z.; Shen, C. Channel-wise knowledge distillation for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5291–5300. [Google Scholar]
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. Yolov6 v3. 0: A full-scale reloading. arXiv 2023, arXiv:2301.05586. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing network design strategies through gradient path analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. Adv. Neural Inf. Process. Syst. 2017, 30, 1195–1204. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Wang, L.; Lee, C.Y.; Tu, Z.; Lazebnik, S. Training deeper convolutional networks with deep supervision. arXiv 2015, arXiv:1505.02496. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Lin, Z.; Wang, Y.; Zhang, J.; Chu, X. Dynamicdet: A unified dynamic architecture for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6282–6291. [Google Scholar]
- Chen, Y.; Chen, Q.; Hu, Q.; Cheng, J. Date: Dual assignment for end-to-end fully convolutional object detection. arXiv 2022, arXiv:2211.13859. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Ma, Y.; Yu, D.; Wu, T.; Wang, H. PaddlePaddle: An open-source deep learning platform from industrial practice. Front. Data Domputing 2019, 1, 105–115. [Google Scholar]
- Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.; Shen, H.; Ren, J.; Han, S.; Ding, E.; et al. PP-YOLO: An effective and efficient implementation of object detector. arXiv 2020, arXiv:2007.12099. [Google Scholar]
- Huang, X.; Wang, X.; Lv, W.; Bai, X.; Long, X.; Deng, K.; Dang, Q.; Han, S.; Liu, Q.; Hu, X.; et al. PP-YOLOv2: A practical object detector. arXiv 2021, arXiv:2104.10419. [Google Scholar]
- Xu, S.; Wang, X.; Lv, W.; Chang, Q.; Cui, C.; Deng, K.; Wang, G.; Dang, Q.; Wei, S.; Du, Y.; et al. PP-YOLOE: An evolved version of YOLO. arXiv 2022, arXiv:2203.16250. [Google Scholar]
- Wang, X.; Wang, G.; Dang, Q.; Liu, Y.; Hu, X.; Yu, D. PP-YOLOE-R: An efficient anchor-free rotated object detector. arXiv 2022, arXiv:2211.02386. [Google Scholar]
- Ge, Z. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Ge, Z.; Liu, S.; Li, Z.; Yoshie, O.; Sun, J. Ota: Optimal transport assignment for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 303–312. [Google Scholar]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. Damo-yolo: A report on real-time object detection design. arXiv 2022, arXiv:2211.15444. [Google Scholar]
- Sun, Z.; Lin, M.; Sun, X.; Tan, Z.; Li, H.; Jin, R. Mae-det: Revisiting maximum entropy principle in zero-shot nas for efficient object detection. arXiv 2021, arXiv:2111.13336. [Google Scholar]
- Wu, Z.; Zou, X.; Zhou, W.; Huang, J. YOLOX-PAI: An improved YOLOX, stronger and faster than YOLOv6. arXiv 2022, arXiv:2208.13040. [Google Scholar]
- Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; Han, K. Gold-YOLO: Efficient object detector via gather-and-distribute mechanism. Adv. Neural Inf. Process. Syst. 2024, 36, 51094–51112. [Google Scholar]
- Chen, Y.; Yuan, X.; Wu, R.; Wang, J.; Hou, Q.; Cheng, M.M. Yolo-ms: Rethinking multi-scale representation learning for real-time object detection. arXiv 2023, arXiv:2308.05480. [Google Scholar] [CrossRef]
- Huang, L.; Li, W.; Shen, L.; Fu, H.; Xiao, X.; Xiao, S. YOLOCS: Object detection based on dense channel compression for feature spatial solidification. arXiv 2023, arXiv:2305.04170. [Google Scholar] [CrossRef]
- Aharon, S.; Louis-Dupont; Masad, O.; Yurkova, K.; Lotem Fridman; Lkdci; Khvedchenya, E.; Rubin, R.; Bagrov, N.; Tymchenko, B.; et al. Super-Gradients. 2021. Available online: https://zenodo.org/records/10944954 (accessed on 3 March 2025).
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-based YOLO for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Montreal, QC, Canada, 11–17 October 2021; pp. 2799–2808. [Google Scholar]
- Guo, Z.; Wang, C.; Yang, G.; Huang, Z.; Li, G. Msft-yolo: Improved yolov5 based on transformer for detecting defects of steel surface. Sensors 2022, 22, 3467. [Google Scholar] [CrossRef]
- Liu, Y.; He, G.; Wang, Z.; Li, W.; Huang, H. NRT-YOLO: Improved YOLOv5 based on nested residual transformer for tiny remote sensing object detection. Sensors 2022, 22, 4953. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Gao, S.; Zhou, L.; Liu, R.; Zhang, H.; Liu, J.; Jia, Y.; Qian, J. YOLO-SD: Small ship detection in SAR images by multi-scale convolution and feature transformer module. Remote Sens. 2022, 14, 5268. [Google Scholar] [CrossRef]
- Ouyang, H. Deyo: Detr with yolo for step-by-step object detection. arXiv 2022, arXiv:2211.06588. [Google Scholar]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Najibi, M.; Rastegari, M.; Davis, L.S. G-CNN: An iterative grid based object detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2369–2377. [Google Scholar]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. Ron: Reverse connection with objectness prior networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5244–5252. [Google Scholar]
- Zhou, P.; Ni, B.; Geng, C.; Hu, J.; Xu, Y. Scale-transferrable object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 528–537. [Google Scholar]
- Cao, J.; Pang, Y.; Li, X. Triply supervised decoder networks for joint detection and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7392–7401. [Google Scholar]
- Chen, X.; Yu, J.; Kong, S.; Wu, Z.; Wen, L. Joint anchor-feature refinement for real-time accurate object detection in images and videos. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 594–607. [Google Scholar] [CrossRef]
- Wang, S.; Gong, Y.; Xing, J.; Huang, L.; Huang, C.; Hu, W. RDSNet: A new deep architecture forreciprocal object detection and instance segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12208–12215. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You only look one-level feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 13039–13048. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Chen, Y.; Han, C.; Wang, N.; Zhang, Z. Revisiting feature alignment for one-stage object detection. arXiv 2019, arXiv:1908.01570. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Shi, J. Consistent optimization for single-shot object detection. arXiv 2019, arXiv:1901.06563. [Google Scholar]
- Cao, J.; Pang, Y.; Han, J.; Li, X. Hierarchical shot detector. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 9704–9713. [Google Scholar]
- Zhu, R.; Zhang, S.; Wang, X.; Wen, L.; Shi, H.; Bo, L.; Mei, T. ScratchDet: Training single-shot object detectors from scratch. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2268–2277. [Google Scholar]
- Wang, T.; Anwer, R.M.; Cholakkal, H.; Khan, F.S.; Pang, Y.; Shao, L. Learning rich features at high-speed for single-shot object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 1971–1980. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; pp. 4052–4061. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention augmented convolutional networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 3285–3294. [Google Scholar]
- Oord, A.; Li, Y.; Babuschkin, I.; Simonyan, K.; Vinyals, O.; Kavukcuoglu, K.; Driessche, G.; Lockhart, E.; Cobo, L.; Stimberg, F.; et al. Parallel wavenet: Fast high-fidelity speech synthesis. In Proceedings of the International Conference on Machine Learning, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; pp. 3915–3923. [Google Scholar]
- Gu, J.; Bradbury, J.; Xiong, C.; Li, V.O.; Socher, R. Non-autoregressive neural machine translation. arXiv 2017, arXiv:1711.02281. [Google Scholar]
- Ghazvininejad, M.; Levy, O.; Liu, Y.; Zettlemoyer, L. Mask-predict: Parallel decoding of conditional masked language models. arXiv 2019, arXiv:1904.09324. [Google Scholar]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Stewart, R.; Andriluka, M.; Ng, A.Y. End-to-end people detection in crowded scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2325–2333. [Google Scholar]
- Teed, Z.; Deng, J. Raft: Recurrent all-pairs field transforms for optical flow. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16; Springer: Cham, Switzerland, 2020; pp. 402–419. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional DETR for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3651–3660. [Google Scholar]
- Wang, Y.; Zhang, X.; Yang, T.; Sun, J. Anchor DETR: Query design for transformer-based object detection. arXiv 2021, arXiv:2109.07107. [Google Scholar]
- Yao, Z.; Ai, J.; Li, B.; Zhang, C. Efficient detr: Improving end-to-end object detector with dense prior. arXiv 2021, arXiv:2104.01318. [Google Scholar]
- Dai, Z.; Cai, B.; Lin, Y.; Chen, J. UP-DETR: Unsupervised pre-training for object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 1601–1610. [Google Scholar]
- Gao, P.; Zheng, M.; Wang, X.; Dai, J.; Li, H. Fast convergence of detr with spatially modulated co-attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3601–3610. [Google Scholar]
- Sun, Z.; Cao, S.; Yang, Y.; Kitani, K.M. Rethinking transformer-based set prediction for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3591–3600. [Google Scholar]
- Liu, F.; Wei, H.; Zhao, W.; Li, G.; Peng, J.; Li, Z. WB-DETR: Transformer-based detector without backbone. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2959–2967. [Google Scholar]
- Wang, T.; Yuan, L.; Chen, Y.; Feng, J.; Yan, S. PnP-DETR: Towards efficient visual analysis with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4641–4650. [Google Scholar]
- Dai, X.; Chen, Y.; Yang, J.; Zhang, P.; Yuan, L.; Zhang, L. Dynamic DETR: End-to-end object detection with dynamic attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2968–2977. [Google Scholar]
- Roh, B.; Shin, J.; Shin, W.; Kim, S. Sparse detr: Efficient end-to-end object detection with learnable sparsity. arXiv 2021, arXiv:2111.14330. [Google Scholar]
- Lin, J.; Mao, X.; Chen, Y.; Xu, L.; He, Y.; Xue, H. D^2ETR: Decoder-Only DETR with Computationally Efficient Cross-Scale Attention. arXiv 2022, arXiv:2203.00860. [Google Scholar]
- Wang, W.; Cao, Y.; Zhang, J.; Tao, D. FP-DETR: Detection transformer advanced by fully pre-training. In Proceedings of the International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- Cao, X.; Yuan, P.; Feng, B.; Niu, K. CF-DETR: Coarse-to-fine transformers for end-to-end object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 22 February–1 March 2022; Volume 36, pp. 185–193. [Google Scholar]
- Gao, Z.; Wang, L.; Han, B.; Guo, S. Adamixer: A fast-converging query-based object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5354–5363. [Google Scholar]
- Chen, Z.; Zhang, J.; Tao, D. Recurrent glimpse-based decoder for detection with transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5250–5259. [Google Scholar]
- Zong, Z.; Song, G.; Liu, Y. DETRs with collaborative hybrid assignments training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6725–6735. [Google Scholar]
- Zheng, M.; Gao, P.; Zhang, R.; Li, K.; Wang, X.; Li, H.; Dong, H. End-to-end object detection with adaptive clustering transformer. arXiv 2020, arXiv:2011.09315. [Google Scholar]
- Kamath, A.; Singh, M.; LeCun, Y.; Synnaeve, G.; Misra, I.; Carion, N. MDETR - Modulated detection for end-to-end multi-modal understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1760–1770. [Google Scholar]
- Chen, Y.; Chen, Q.; Sun, P.; Chen, S.; Wang, J.; Cheng, J. Enhancing your trained detrs with box refinement. arXiv 2023, arXiv:2307.11828. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs beat YOLOs on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 15979–15988. [Google Scholar]
- Fang, Y.; Liao, B.; Wang, X.; Fang, J.; Qi, J.; Wu, R.; Niu, J.; Liu, W. You only look at one sequence: Rethinking transformer in vision through object detection. Adv. Neural Inf. Process. Syst. 2021, 34, 26183–26197. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 548–558. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11999–12009. [Google Scholar]
- Fan, H.; Xiong, B.; Mangalam, K.; Li, Y.; Yan, Z.; Malik, J.; Feichtenhofer, C. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6804–6815. [Google Scholar]
- Li, Y.; Wu, C.Y.; Fan, H.; Mangalam, K.; Xiong, B.; Malik, J.; Feichtenhofer, C. MViTv2: Improved multiscale vision transformers for classification and detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4804. [Google Scholar]
- Heo, B.; Yun, S.; Han, D.; Chun, S.; Choe, J.; Oh, S.J. Rethinking spatial dimensions of vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11916–11925. [Google Scholar]
- Chen, W.; Du, X.; Yang, F.; Beyer, L.; Zhai, X.; Lin, T.Y.; Chen, H.; Li, J.; Song, X.; Wang, Z.; et al. A simple single-scale vision transformer for object localization and instance segmentation. arXiv 2021, arXiv:2112.09747. [Google Scholar]
- Ali, A.; Touvron, H.; Caron, M.; Bojanowski, P.; Douze, M.; Joulin, A.; Laptev, I.; Neverova, N.; Synnaeve, G.; Verbeek, J.; et al. Xcit: Cross-covariance image transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 20014–20027. [Google Scholar]
- Zhang, P.; Dai, X.; Yang, J.; Xiao, B.; Yuan, L.; Zhang, L.; Gao, J. Multi-scale vision longformer: A new vision transformer for high-resolution image encoding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2978–2988. [Google Scholar]
- Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y. Vision transformer adapter for dense predictions. arXiv 2022, arXiv:2205.08534. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized Focal Loss V2: Learning reliable localization quality estimation for dense object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 11632–11641. [Google Scholar]
- Leng, Z.; Tan, M.; Liu, C.; Cubuk, E.D.; Shi, X.; Cheng, S.; Anguelov, D. Polyloss: A polynomial expansion perspective of classification loss functions. arXiv 2022, arXiv:2204.12511. [Google Scholar]
- Li, B.; Liu, Y.; Wang, X. Gradient harmonized single-stage detector. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8577–8584. [Google Scholar]
- Sun, F.; Kong, T.; Huang, W.; Tan, C.; Fang, B.; Liu, H. Feature pyramid reconfiguration with consistent loss for object detection. IEEE Trans. Image Process. 2019, 28, 5041–5051. [Google Scholar] [CrossRef]
- Oksuz, K.; Cam, B.C.; Akbas, E.; Kalkan, S. A ranking-based, balanced loss function unifying classification and localisation in object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 15534–15545. [Google Scholar]
- Chen, K.; Li, J.; Lin, W.; See, J.; Wang, J.; Duan, L.; Chen, Z.; He, C.; Zou, J. Towards accurate one-stage object detection with ap-loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5119–5127. [Google Scholar]
- Chen, K.; Lin, W.; Li, J.; See, J.; Wang, J.; Zou, J. AP-loss for accurate one-stage object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3782–3798. [Google Scholar] [CrossRef]
- Qian, Q.; Chen, L.; Li, H.; Jin, R. DR Loss: Improving object detection by distributional ranking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12161–12169. [Google Scholar]
- Oksuz, K.; Cam, B.C.; Akbas, E.; Kalkan, S. Rank & sort loss for object detection and instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 2989–2998. [Google Scholar]
- Zhou, D.; Fang, J.; Song, X.; Guan, C.; Yin, J.; Dai, Y.; Yang, R. Iou loss for 2d/3d object detection. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Québec City, QC, Canada, 16–19 September 2019; pp. 85–94. [Google Scholar]
- He, J.; Erfani, S.; Ma, X.; Bailey, J.; Chi, Y.; Hua, X.S. α-IoU: A family of power intersection over union losses for bounding box regression. Adv. Neural Inf. Process. Syst. 2021, 34, 20230–20242. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Everingham, M.; Zisserman, A.; Williams, C.K.; Van Gool, L.; Allan, M.; Bishop, C.M.; Chapelle, O.; Dalal, N.; Deselaers, T.; Dorkó, G.; et al. The 2005 pascal visual object classes challenge. In Machine Learning Challenges, Evaluating Predictive Uncertainty, Visual Object Classification, and Recognising Tectual Entailment, Proceedings of the First PASCAL Machine Learning Challenges Workshop, MLCW 2005, Southampton, UK, 11–13 April 2005; Revised Selected Papers; Springer: Berlin/Heidelberg, Germany, 2006; pp. 117–176. [Google Scholar]
- Everingham, M.; Zisserman, A.; Williams, C.K.I.; Van Gool, L. The PASCAL Visual Object Classes Challenge 2006 (VOC2006) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2006/results.pdf (accessed on 2 October 2024).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2007/workshop/index.html (accessed on 2 October 2024).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2010 (VOC2010) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2010/workshop/index.html (accessed on 2 October 2024).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2011 (VOC2011) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2011/workshop/index.html (accessed on 2 October 2024).
- Krasin, I.; Duerig, T.; Alldrin, N.; Veit, A.; Abu-El-Haija, S.; Belongie, S.; Cai, D.; Feng, Z.; Ferrari, V.; Gomes, V.; et al. OpenImages: A Public Dataset for Large-Scale Multi-Label and Multi-Class Image Classification. 2016. Available online: https://github.com/openimages (accessed on 2 October 2024).
- Krasin, I.; Duerig, T.; Alldrin, N.; Ferrari, V.; Abu-El-Haija, S.; Kuznetsova, A.; Rom, H.; Uijlings, J.; Popov, S.; Veit, A.; et al. OpenImages: A Public Dataset for Large-Scale Multi-Label and Multi-Class Image Classification. 2017. Available online: https://github.com/openimages (accessed on 2 October 2024).
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Duerig, T.; et al. The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. arXiv 2018, arXiv:1811.00982. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, Florida, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; Sun, J. Objects365: A large-scale, high-quality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October 27–2 November 2019; pp. 8429–8438. [Google Scholar]
- Dollár, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: A benchmark. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, Florida, USA, 20-.25 June 2009; pp. 304–311. [Google Scholar]
- Dollar, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Oksuz, K.; Cam, B.C.; Akbas, E.; Kalkan, S. Localization recall precision (LRP): A new performance metric for object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Volume 11211, pp. 521–537. [Google Scholar]
- Inoue, N.; Furuta, R.; Yamasaki, T.; Aizawa, K. Cross-domain weakly-supervised object detection through progressive domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5001–5009. [Google Scholar]
- Rodriguez, A.L.; Mikolajczyk, K. Domain adaptation for object detection via style consistency. arXiv 2019, arXiv:1911.10033. [Google Scholar]
- Kim, S.; Choi, J.; Kim, T.; Kim, C. Self-training and adversarial background regularization for unsupervised domain adaptive one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 27 October–2 November 2019; pp. 6091–6100. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster r-cnn for object detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3339–3348. [Google Scholar]
- Saito, K.; Ushiku, Y.; Harada, T.; Saenko, K. Strong-weak distribution alignment for adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6956–6965. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 97–105. [Google Scholar]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3723–3732. [Google Scholar]
- Xu, Y.; Sun, Y.; Yang, Z.; Miao, J.; Yang, Y. H2FA R-CNN: Holistic and hierarchical feature alignment for cross-domain weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14309–14319. [Google Scholar]
- Yu, F.; Wang, D.; Chen, Y.; Karianakis, N.; Shen, T.; Yu, P.; Lymberopoulos, D.; Lu, S.; Shi, W.; Chen, X. Unsupervised domain adaptation for object detection via cross-domain semi-supervised learning. arXiv 2019, arXiv:1911.07158. [Google Scholar]
- Gu, X.; Lin, T.Y.; Kuo, W.; Cui, Y. Open-vocabulary object detection via vision and language knowledge distillation. arXiv 2021, arXiv:2104.13921. [Google Scholar]
- Pham, C.; Vu, T.; Nguyen, K. LP-OVOD: Open-vocabulary object detection by linear probing. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 768–777. [Google Scholar]
- Ma, Z.; Luo, G.; Gao, J.; Li, L.; Chen, Y.; Wang, S.; Zhang, C.; Hu, W. Open-vocabulary one-stage detection with hierarchical visual-language knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14054–14063. [Google Scholar]
- Zareian, A.; Rosa, K.D.; Hu, D.H.; Chang, S.F. Open-vocabulary object detection using captions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 14393–14402. [Google Scholar]
- Li, L.H.; Zhang, P.; Zhang, H.; Yang, J.; Li, C.; Zhong, Y.; Wang, L.; Yuan, L.; Zhang, L.; Hwang, J.N.; et al. Grounded language-image pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10955–10965. [Google Scholar]
- Zhang, H.; Zhang, P.; Hu, X.; Chen, Y.C.; Li, L.; Dai, X.; Wang, L.; Yuan, L.; Hwang, J.N.; Gao, J. Glipv2: Unifying localization and vision-language understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 36067–36080. [Google Scholar]
- Zhou, X.; Girdhar, R.; Joulin, A.; Krähenbühl, P.; Misra, I. Detecting twenty-thousand classes using image-level supervision. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Volume 13669, pp. 350–368. [Google Scholar]
- Gao, M.; Xing, C.; Niebles, J.C.; Li, J.; Xu, R.; Liu, W.; Xiong, C. Open vocabulary object detection with pseudo bounding-box labels. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Volume 13670, pp. 266–282. [Google Scholar]
- Kaul, P.; Xie, W.; Zisserman, A. Multi-modal classifiers for open-vocabulary object detection. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23-29 July 2023; Volume 202, pp. 15946–15969. [Google Scholar]
- Wu, X.; Zhu, F.; Zhao, R.; Li, H. CORA: Adapting clip for open-vocabulary detection with region prompting and anchor pre-matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7031–7040. [Google Scholar]
- Feng, C.; Zhong, Y.; Jie, Z.; Chu, X.; Ren, H.; Wei, X.; Xie, W.; Ma, L. Promptdet: Towards open-vocabulary detection using uncurated images. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Volume 13669, pp. 701–717. [Google Scholar]
- Song, H.; Bang, J. Prompt-guided transformers for end-to-end open-vocabulary object detection. arXiv 2023, arXiv:2303.14386. [Google Scholar]
- Zang, Y.; Li, W.; Zhou, K.; Huang, C.; Loy, C.C. Open-vocabulary detr with conditional matching. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Volume 13669, pp. 106–122. [Google Scholar]
- Lin, C.; Sun, P.; Jiang, Y.; Luo, P.; Qu, L.; Haffari, G.; Yuan, Z.; Cai, J. Learning object-language alignments for open-vocabulary object detection. arXiv 2022, arXiv:2211.14843. [Google Scholar]
- Ma, C.; Jiang, Y.; Wen, X.; Yuan, Z.; Qi, X. CoDet: Co-occurrence guided region-word alignment for open-vocabulary object detection. Adv. Neural Inf. Process. Syst. 2024, 36, 71078–71094. [Google Scholar]
- Wu, J.; Li, X.; Xu, S.; Yuan, H.; Ding, H.; Yang, Y.; Li, X.; Zhang, J.; Tong, Y.; Jiang, X.; et al. Towards open vocabulary learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5092–5113. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the International Conference on Machine Learning, Virtual Event, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Zhang, J.; Huang, J.; Jin, S.; Lu, S. Vision-language models for vision tasks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5625–5644. [Google Scholar] [CrossRef]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Liu, S.; Zeng, Z.; Ren, T.; Li, F.; Zhang, H.; Yang, J.; Jiang, Q.; Li, C.; Yang, J.; Su, H.; et al. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Volume 15105, pp. 38–55. [Google Scholar]
- Yuan, L.; Chen, D.; Chen, Y.L.; Codella, N.; Dai, X.; Gao, J.; Hu, H.; Huang, X.; Li, B.; Li, C.; et al. Florence: A new foundation model for computer vision. arXiv 2021, arXiv:2111.11432. [Google Scholar]
- Xiao, B.; Wu, H.; Xu, W.; Dai, X.; Hu, H.; Lu, Y.; Zeng, M.; Liu, C.; Yuan, L. Florence-2: Advancing a unified representation for a variety of vision tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 4818–4829. [Google Scholar]
- Awais, M.; Naseer, M.; Khan, S.; Anwer, R.M.; Cholakkal, H.; Shah, M.; Yang, M.H.; Khan, F.S. Foundational models defining a new era in vision: A survey and outlook. arXiv 2023, arXiv:2307.13721. [Google Scholar]
- Zoph, B. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing neural network architectures using reinforcement learning. arXiv 2016, arXiv:1611.02167. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Chen, Y.; Yang, T.; Zhang, X.; Meng, G.; Xiao, X.; Sun, J. DetNAS: Backbone search for object detection. Adv. Neural Inf. Process. Syst. 2019, 32, 6638–6648. [Google Scholar]
- Yao, L.; Xu, H.; Zhang, W.; Liang, X.; Li, Z. SM-NAS: Structural-to-modular neural architecture search for object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12661–12668. [Google Scholar]
- Guo, J.; Han, K.; Wang, Y.; Zhang, C.; Yang, Z.; Wu, H.; Chen, X.; Xu, C. Hit-detector: Hierarchical trinity architecture search for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11402–11411. [Google Scholar]
- Wang, N.; Gao, Y.; Chen, H.; Wang, P.; Tian, Z.; Shen, C.; Zhang, Y. NAS-FCOS: Fast neural architecture search for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11940–11948. [Google Scholar]
- Du, X.; Lin, T.Y.; Jin, P.; Ghiasi, G.; Tan, M.; Cui, Y.; Le, Q.V.; Song, X. SpineNet: Learning scale-permuted backbone for recognition and localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11589–11598. [Google Scholar]
- Wu, B.; Li, C.; Zhang, H.; Dai, X.; Zhang, P.; Yu, M.; Wang, J.; Lin, Y.; Vajda, P. Fbnetv5: Neural architecture search for multiple tasks in one run. arXiv 2021, arXiv:2111.10007. [Google Scholar]
- Xiong, Y.; Liu, H.; Gupta, S.; Akin, B.; Bender, G.; Wang, Y.; Kindermans, P.J.; Tan, M.; Singh, V.; Chen, B. Mobiledets: Searching for object detection architectures for mobile accelerators. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, virtual, 19–25 June 2021; pp. 3825–3834. [Google Scholar]
- Li, Y.; Li, J.; Lin, W.; Li, J. Tiny-DSOD: Lightweight object detection for resource-restricted usages. arXiv 2018, arXiv:1807.11013. [Google Scholar]
- Cai, Y.; Li, H.; Yuan, G.; Niu, W.; Li, Y.; Tang, X.; Ren, B.; Wang, Y. YOLObile: Real-time object detection on mobile devices via compression-compilation co-design. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; Volume 35, pp. 955–963. [Google Scholar]
- Mittal, P. A comprehensive survey of deep learning-based lightweight object detection models for edge devices. Artif. Intell. Rev. 2024, 57, 242. [Google Scholar] [CrossRef]
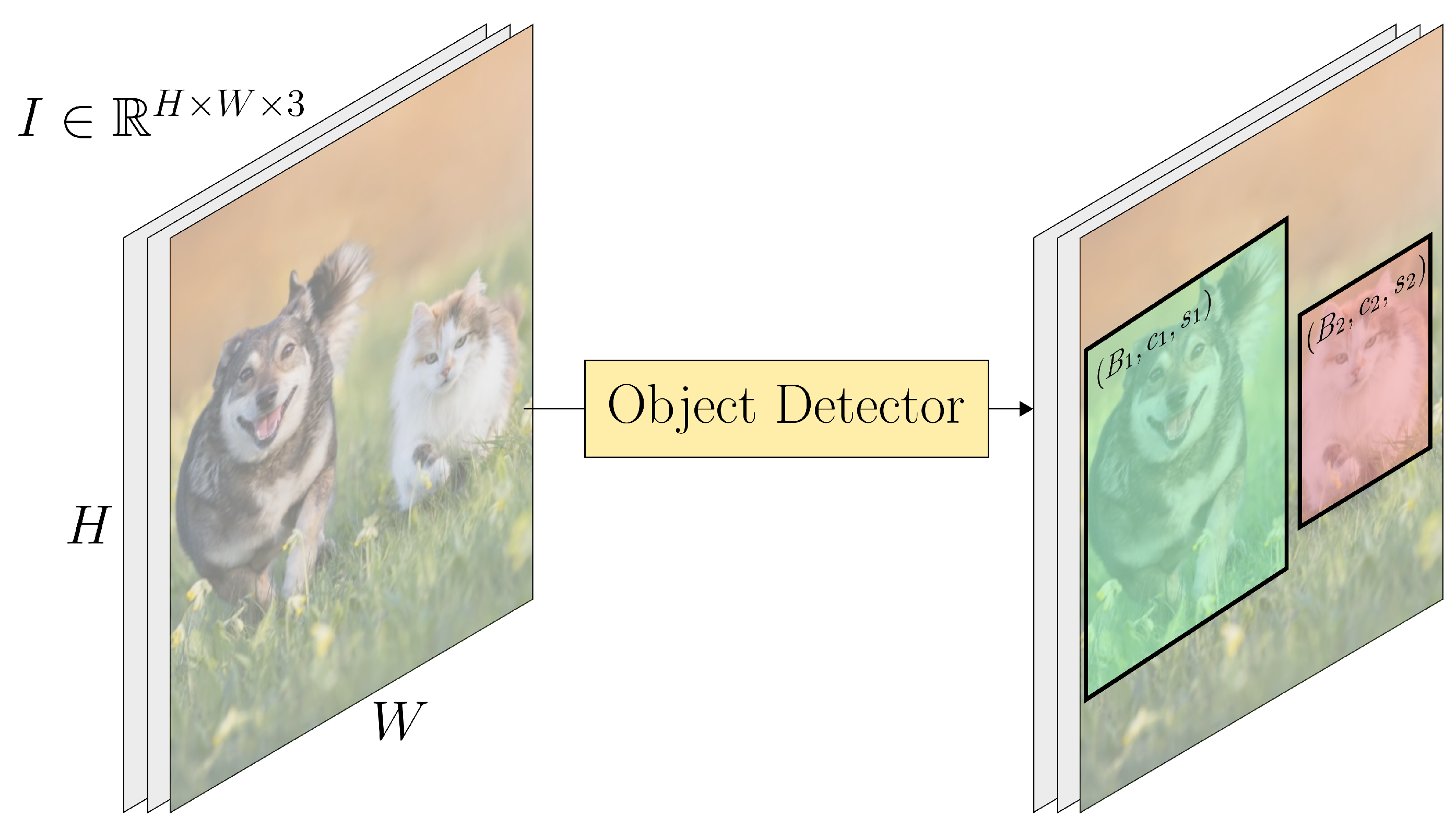

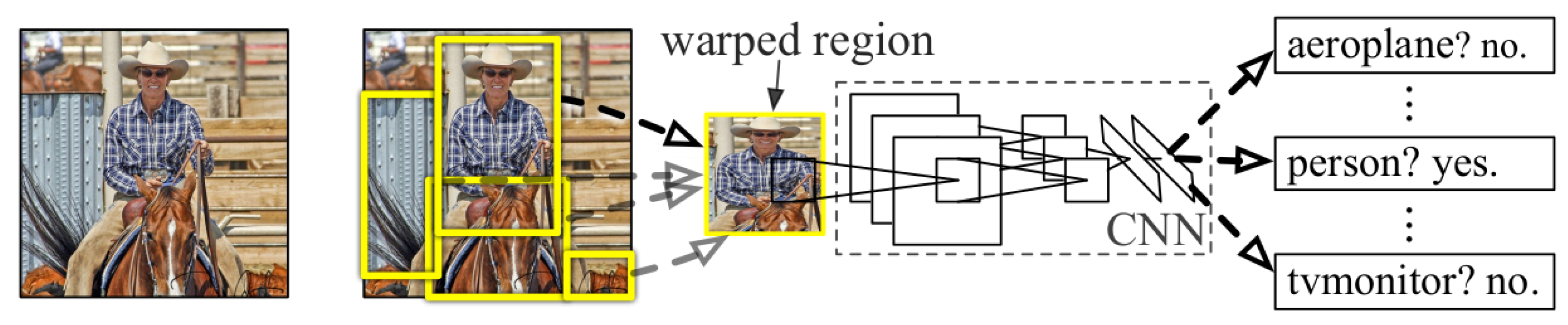

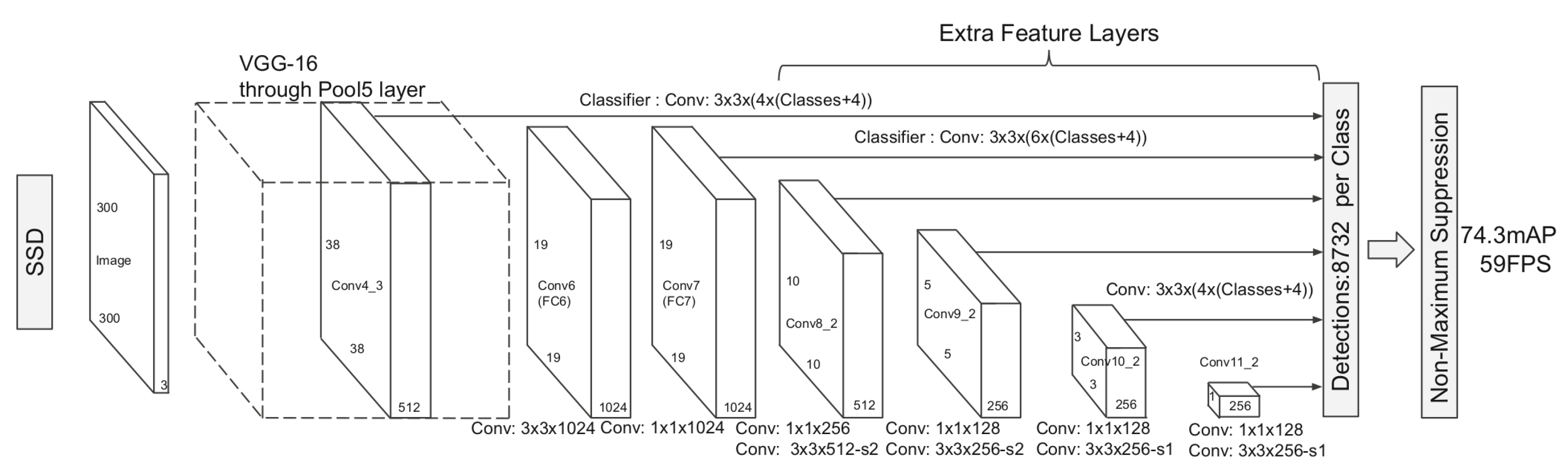


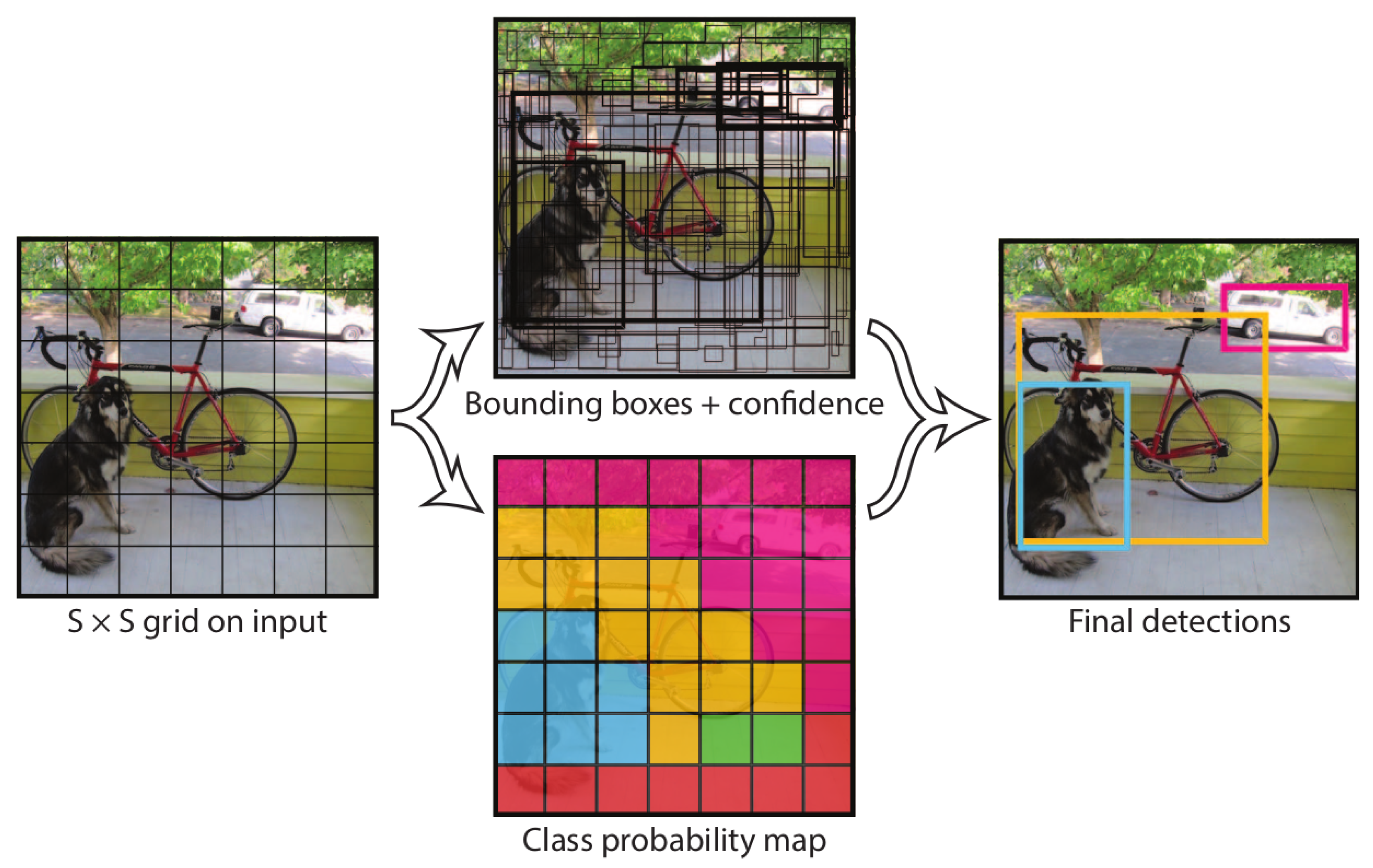

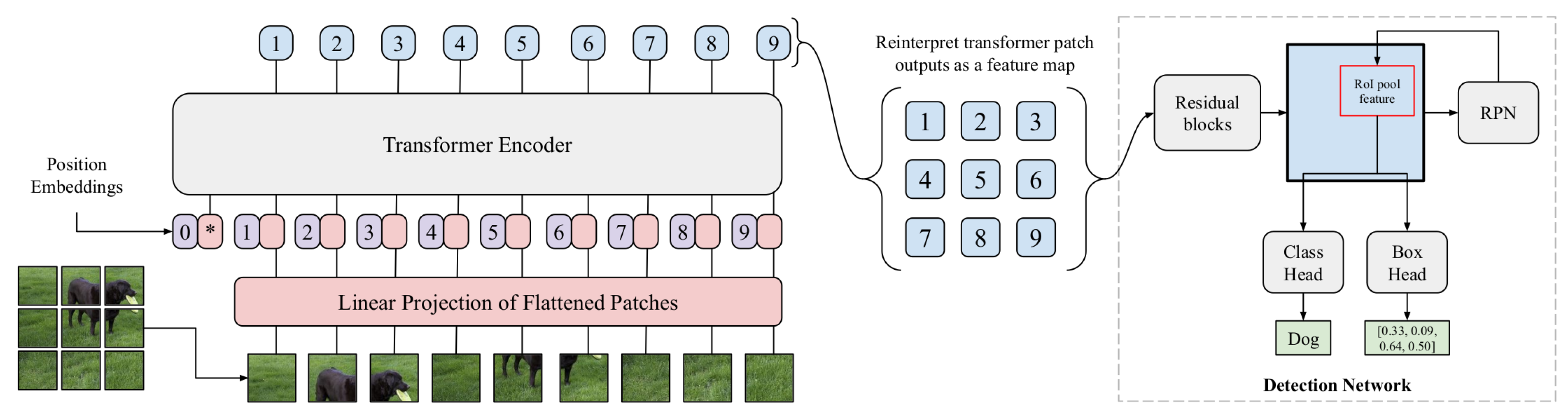
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).