High-utility itemset mining (HUIM) [
8] aims to discover itemsets with high utility values in databases. The development of various algorithms has enhanced the efficiency of solving HUIM, starting with the two-phase algorithm [
8]. This algorithm generates candidate itemsets in the first phase and identifies high-utility itemsets in the second phase, requiring multiple database scans, making it time-consuming. Subsequent algorithms, such as UP-Growth and UP-Growth+ [
9], were introduced to reduce the number of database scans and candidates generated by utilizing their own techniques. However, they still struggle with the computational complexity of candidate generation processes. To address the challenges of candidate generation, single-phase algorithms like HUI-Miner [
10], FHM [
11], d2HUP [
12], HUP-Miner [
13], EFIM [
14], IMHUP [
15], mHUIMiner [
16], HMiner [
17], UPB-Miner [
18], iMEFIM [
19], and Hamm [
20] were developed. These algorithms minimize database scans using tailored data structures or techniques such as database projection and merging. They significantly improve the HUIM process by reducing the search space with effective pruning strategies. Beyond classical algorithms, specialized methods have been developed for various HUIM extensions to address real-world application needs, such as mining closed
[
32], sequential
[
33], top-k
[
34,
35], correlated
[
36], itemsets ignoring internal utilities [
37], high average-utility itemsets [
38,
39], high-utility occupancy itemsets [
40,
41], significant utility discriminative itemsets [
42], and solving HUIM in incremental [
43,
44] or time-stamped data [
45], and so on.
However, none of the abovementioned studies considered the investment associated with itemsets during the mining process. As a result, while they identified itemsets with high utilities, they failed to reflect the true efficiency of these itemsets. This oversight limits decision-making for maximizing profit, as it disregards the investment values of the itemsets.
To address this limitation, the problem of high-efficiency itemset mining (HEIM) [
23] was recently introduced, considering both utility and investment. According to HEIM, the importance of an itemset is determined by dividing its utility by its investment, defining this ratio as efficiency. HEIM aims to find all itemsets whose efficiency meets a user-defined threshold. However, due to the nature of the efficiency calculation, the efficiency measure does not exhibit monotonic or anti-monotonic properties. In other words, the efficiency values of the itemsets do not allow predicting in advance whether their supersets (or subsets) will be efficient, which complicates the problem computationally, due to the large search space. The first solution to this problem, the HEPM [
23] algorithm, introduced an upper-bound called an efficiency upper-bound (
), which overestimates the efficiency values of itemsets to satisfy anti-monotonicity, aiding in pruning the search space. HEPM uses a level-based candidate generation and testing strategy, conducting multiple database scans to generate candidates and filter them by calculating their actual efficiency, making it time-consuming due to the extensive number of scans and candidates. The working principle of HEPM is as follows. It employs a two-phased approach to identify
in a dataset. In Phase 1, the algorithm explores the search space using a breadth-first search strategy. It begins by scanning the dataset to collect the
values for each item. Items whose
values meet a given
threshold are identified as candidate 1-itemsets. Subsequently, the algorithm iteratively generates candidate 2-itemsets from 1-itemsets, candidate 3-itemsets from 2-itemsets, and so on, continuing until no new candidates can be generated. In each iteration, the algorithm produces candidate (
k + 1)-itemsets based on the current
k-itemsets. A new (
k + 1)-itemset is formed by appending the last item of one
k-itemset to another
k-itemset, provided they share the same (
k − 1) items. During the examination of the search space, the newly generated candidates are filtered based on their
values. The final result of Phase 1 is the complete set of candidate itemsets. In Phase 2, the algorithm scans the database for each candidate itemset to calculate its actual efficiency. Itemsets having efficiencies that meet the
threshold are returned as
, which constitute the final output.
To overcome the issues seen in HEPM, the HEPMiner [
23] algorithm was developed, utilizing a compact-list structure called an efficiency-list (
). The
of items stores the necessary information to mine
. The
of a
k-itemset, where
k ≥ 2, is constructed by joining the
of two
-itemsets that share the same prefix itemset. HEPMiner further prunes the search space using additional upper-bounds, such as
and
, alongside a matrix called an estimated efficiency co-occurrence structure (
) for storing
values of each 2-itemset. The working principle of HEPMiner is as follows. First, it calculates the
of each item by scanning the database once. Then, it compares the
value of each item with a given
threshold. In the second database scan, it disregards the items that do not meet the threshold and sorts the remaining items in each transaction alphabetically. During this process, it generates an
list for each remaining item and an
structure to store the
values of 2-itemsets. Afterward, the algorithm starts exploring the search space. For each itemset it visits in the search space, it first checks whether it is a
. Then, it calculates the
value of the itemset and decides whether the extensions should be pruned. If the extensions are to be explored, it constructs
lists for all 1-item extensions of the itemset. It discards the extensions with a
value lower than
. It also decides whether
lists need to be constructed for itemsets based on the corresponding value stored in the
structure. The algorithm then continues exploring the search space recursively using a depth-first search strategy, along with the newly constructed
lists. Using the values stored in the
lists, the algorithm can easily calculate the efficiency of the itemsets,
and
. For more details on the
,
,
, and
structures and their construction, please refer to the original paper [
23]. Although HEPMiner is more efficient than HEPM, it suffers from costly join operations required during the construction of lists. Subsequently, the MHEI [
24] algorithm was introduced, employing a depth-first search with horizontal database representation. MHEI reduces database scanning costs through database projection and transaction merging, storing transaction identifiers for each item in the projected databases. It also introduced four upper-bounds, called sub-tree efficiency (
), stricter sub-tree efficiency (
), local efficiency (
), and stricter local efficiency (
), to enhance pruning effectiveness. The MHEI algorithm operates as follows. First, it performs a database scan to calculate the
values for each item and eliminates items whose
values do not meet the
threshold, as in HEPMiner. The remaining promising items are then sorted based on a predefined order. During the second database scan, the algorithm considers only the promising items and reorganizes transactions according to the specified order of the items. If any transaction becomes empty after removing unpromising items, it is removed from the database. The rearranged transactions are then subjected to a sorting process to keep similar transactions close to each other. This facilitates the merging of identical projected transactions in later steps. The algorithm then scans the reorganized database, calculating the
values for each item and storing the IDs of the transactions it finds in a list called
. Accordingly, items whose
values do not satisfy the
threshold are eliminated. Following this, MHEI performs a depth-first search to explore the search space. This is an iterative process where a prefix itemset,
X (initially an empty set), is extended by adding a single item and evaluating the potential for further extensions. For each single-item extension of
X with an item
i, denoted as
Z =
, the projected database of
X is scanned to compute the efficiency value of
Z and obtain its projected dataset. If the efficiency value of
Z satisfies the
threshold,
Z is identified as a
. Subsequently, for the per item
v that follows
i in the processing order, the values
and
, as well as the
of
v within the projected database of
Z, are obtained. Any item (along with
Z) whose
value satisfies
is considered a potential single-item extension of
Z, while items with
values satisfying
are considered for future extensions of
Z. Extensions with
and
values below
are discarded. The new prefix becomes
Z, and the same process is repeated until the exploration procedure terminates. Note that, to reduce database scanning costs, the algorithm applies a transaction merging step to each projected database. Additionally, the
of itemsets is only used to examine the required transactions, which provides further time savings. For detailed information on the calculation of upper-bounds, transaction merging, and database projection, please refer to the original paper [
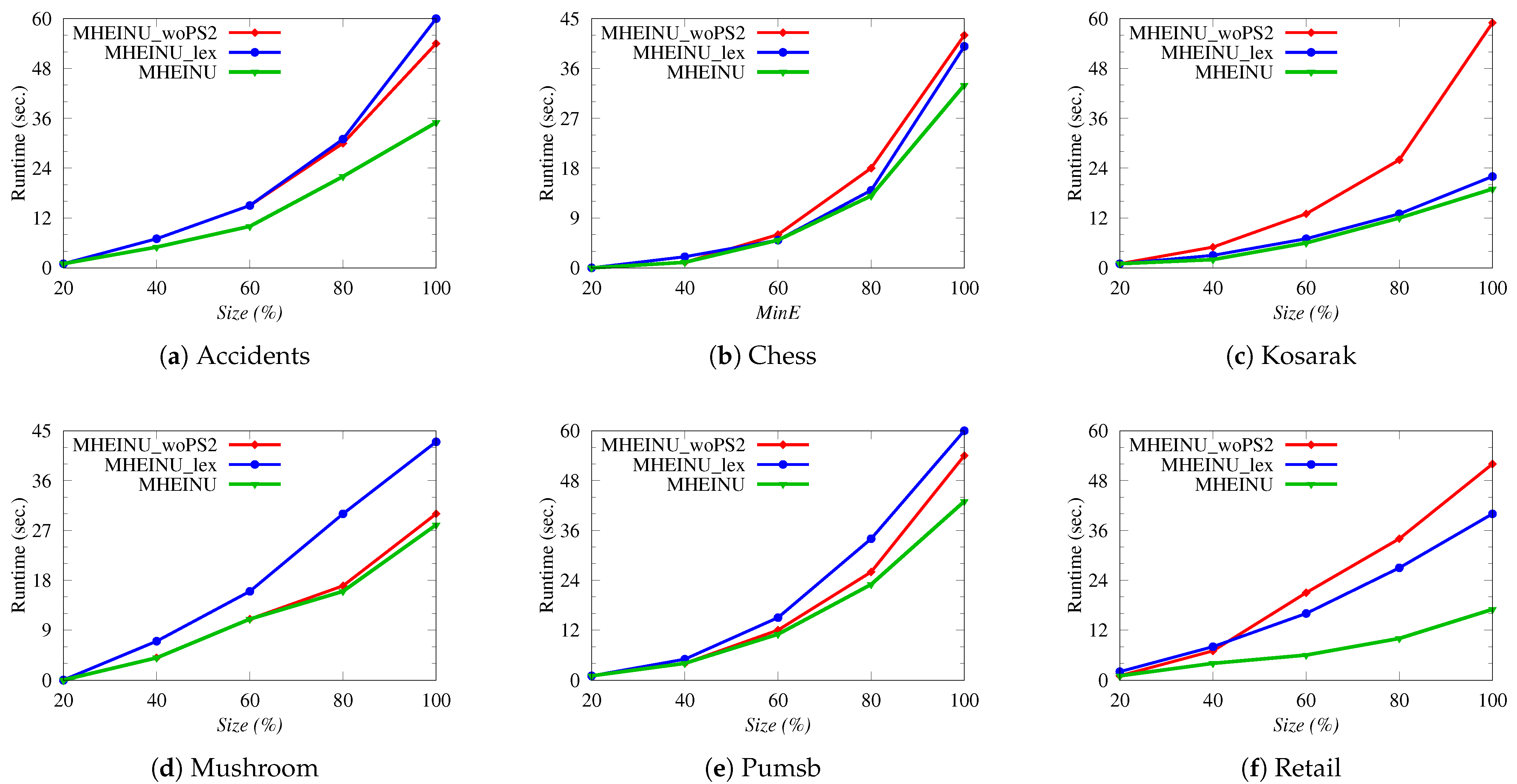
24]. MHEI outperforms both HEPM and HEPMiner in runtime, memory consumption, and the number of generated candidates [
24]. Additionally, the HEIM problem has been extended to the high-average-efficiency itemset mining (HAEIM) problem, which more fairly evaluates the efficiency of itemsets of different lengths [
46]. In HAEIM, the importance of itemsets is determined using a metric called average-efficiency. The average-efficiency of an itemset is calculated by dividing its efficiency by its length (the number of items in the itemset).
However, all existing HEIM algorithms assume that databases contain only positive utilities, leading to incomplete discovery of when applied to databases that also contain negative utilities. The primary reason for this is that the upper-bound models used by existing algorithms may underestimate the actual efficiency values of itemsets in the presence of negative utilities. This causes the search space to be pruned incorrectly, missing important , and provides decision-makers with incomplete insights, which can hinder their ability to make informed decisions. To address this limitation, this study focuses on developing techniques for the complete and correct discovery of in databases that contain both positive and negative utilities. This ensures that decision-makers are provided with comprehensive and reliable data, allowing them to optimize future strategies based on a full understanding of past behaviors. This is especially valuable in real-world applications, where negative utility can represent costs or losses, as seen in retail promotions, bundled services, or investment strategies.






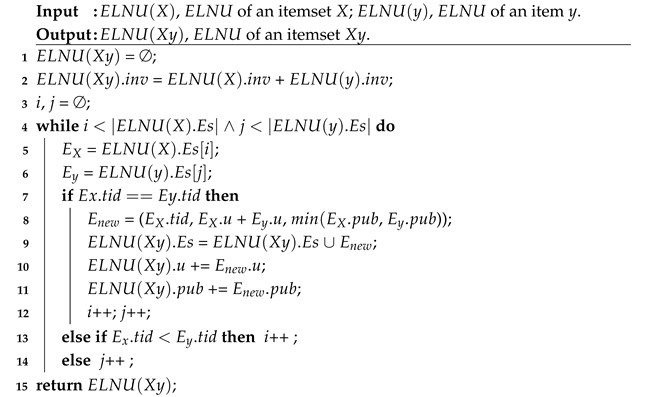

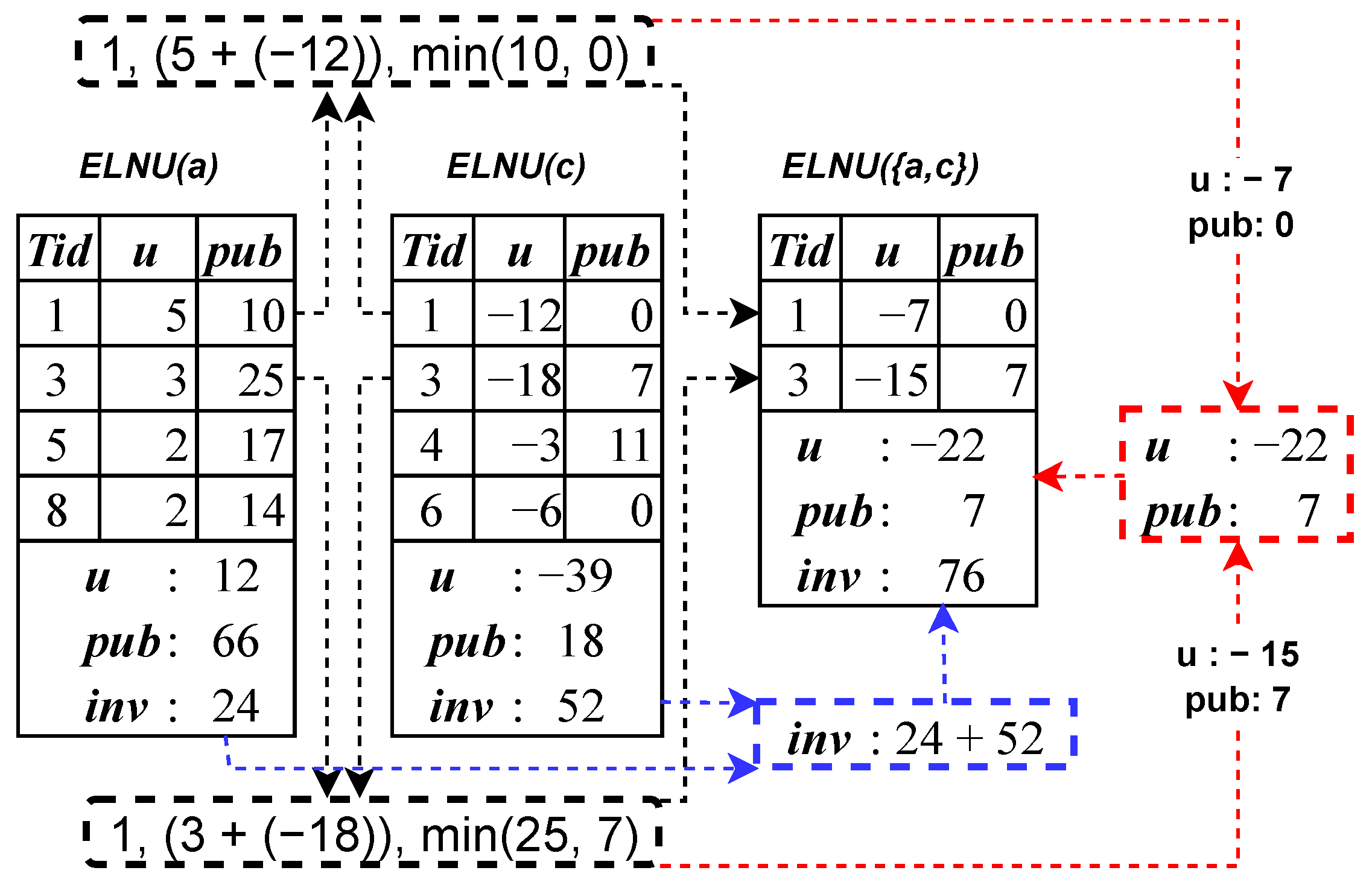
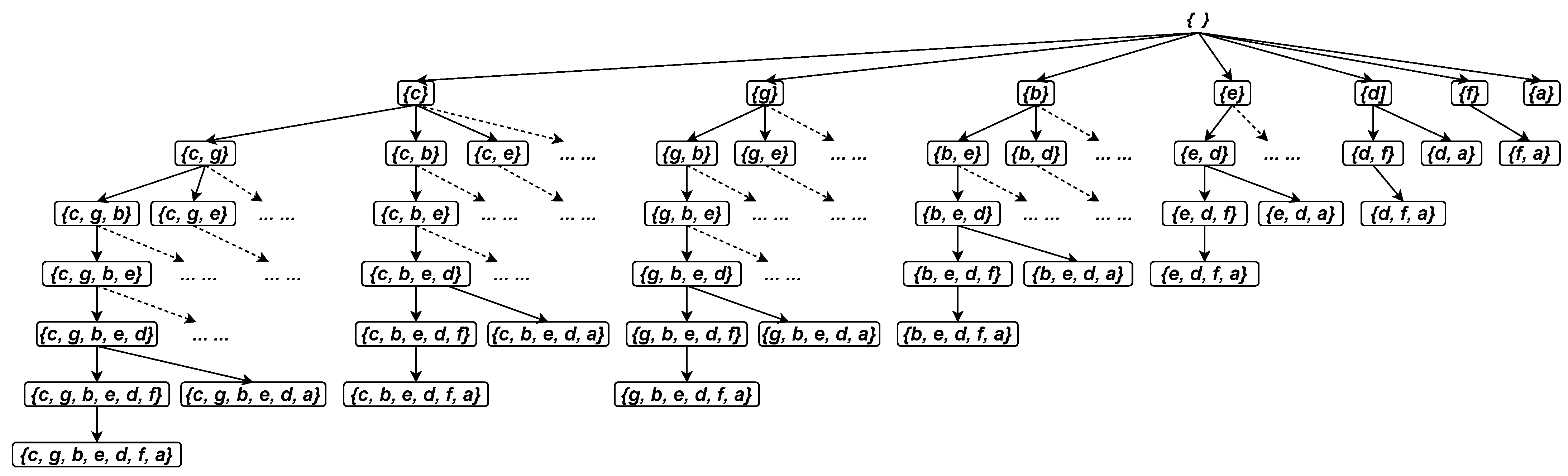
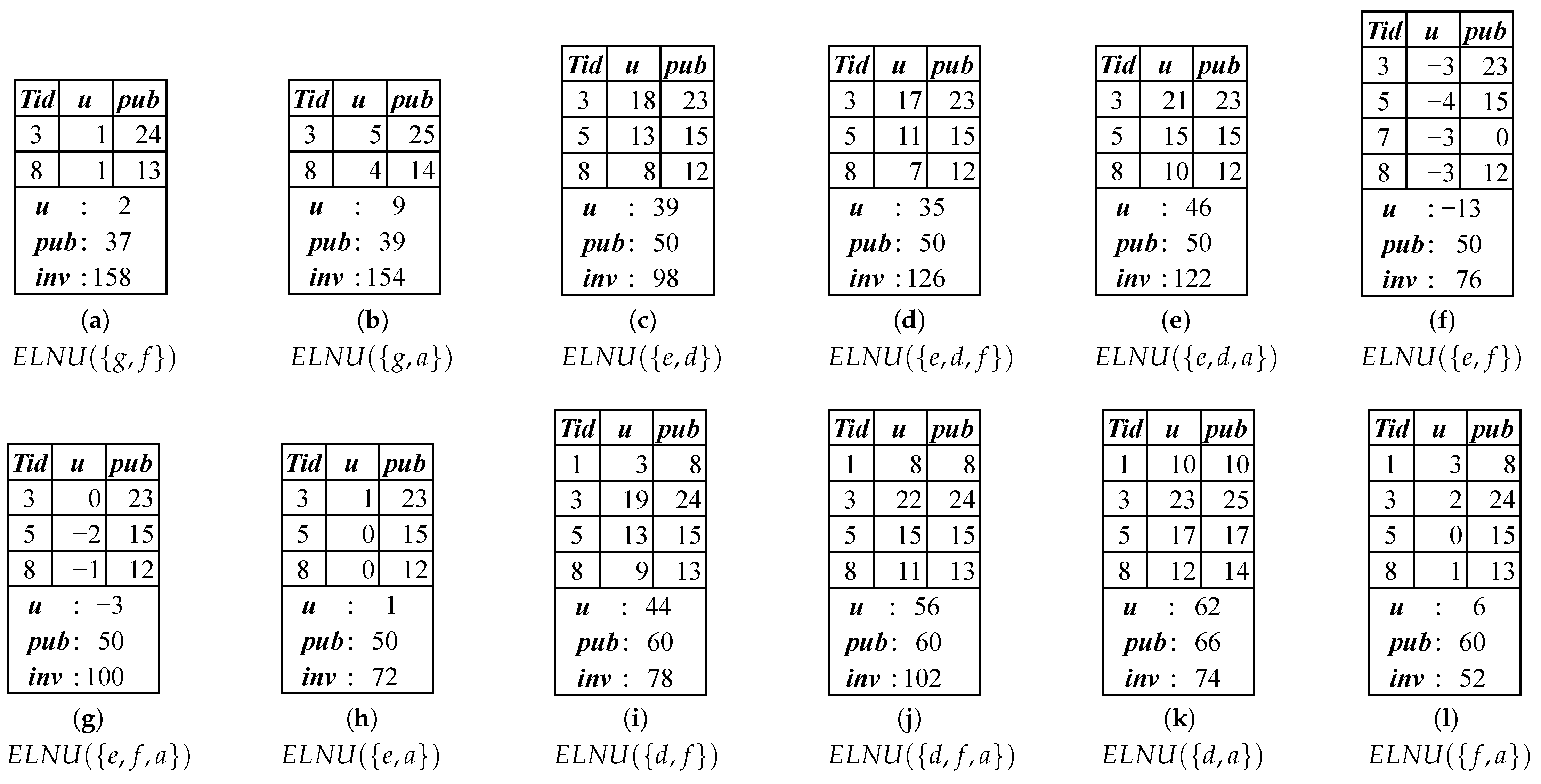
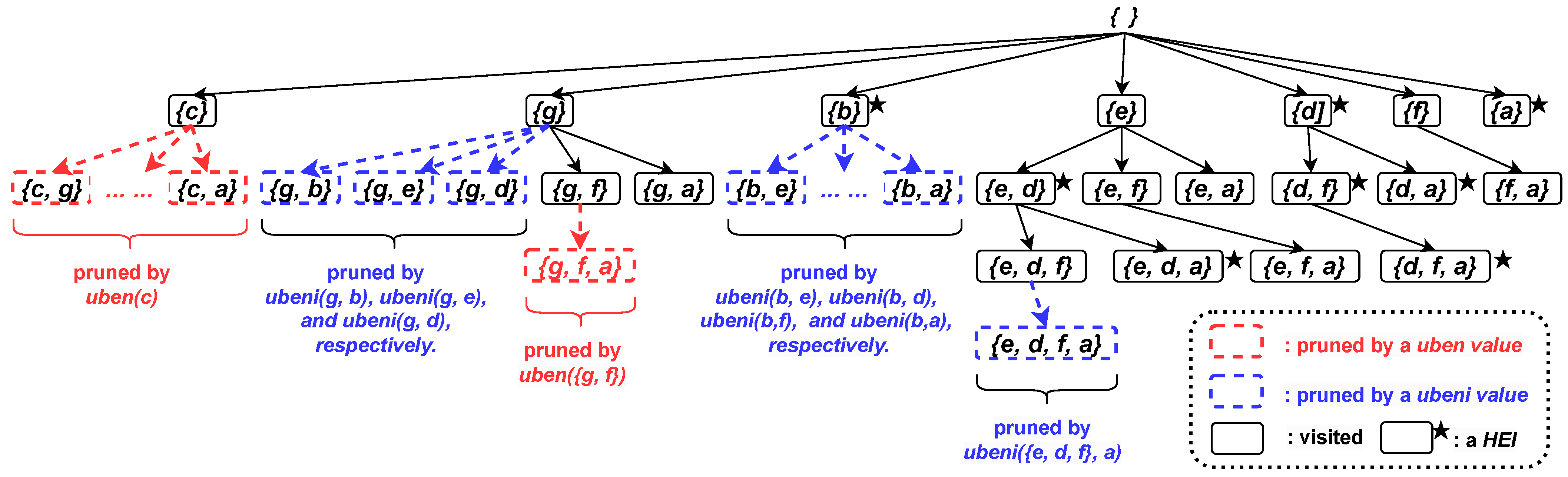
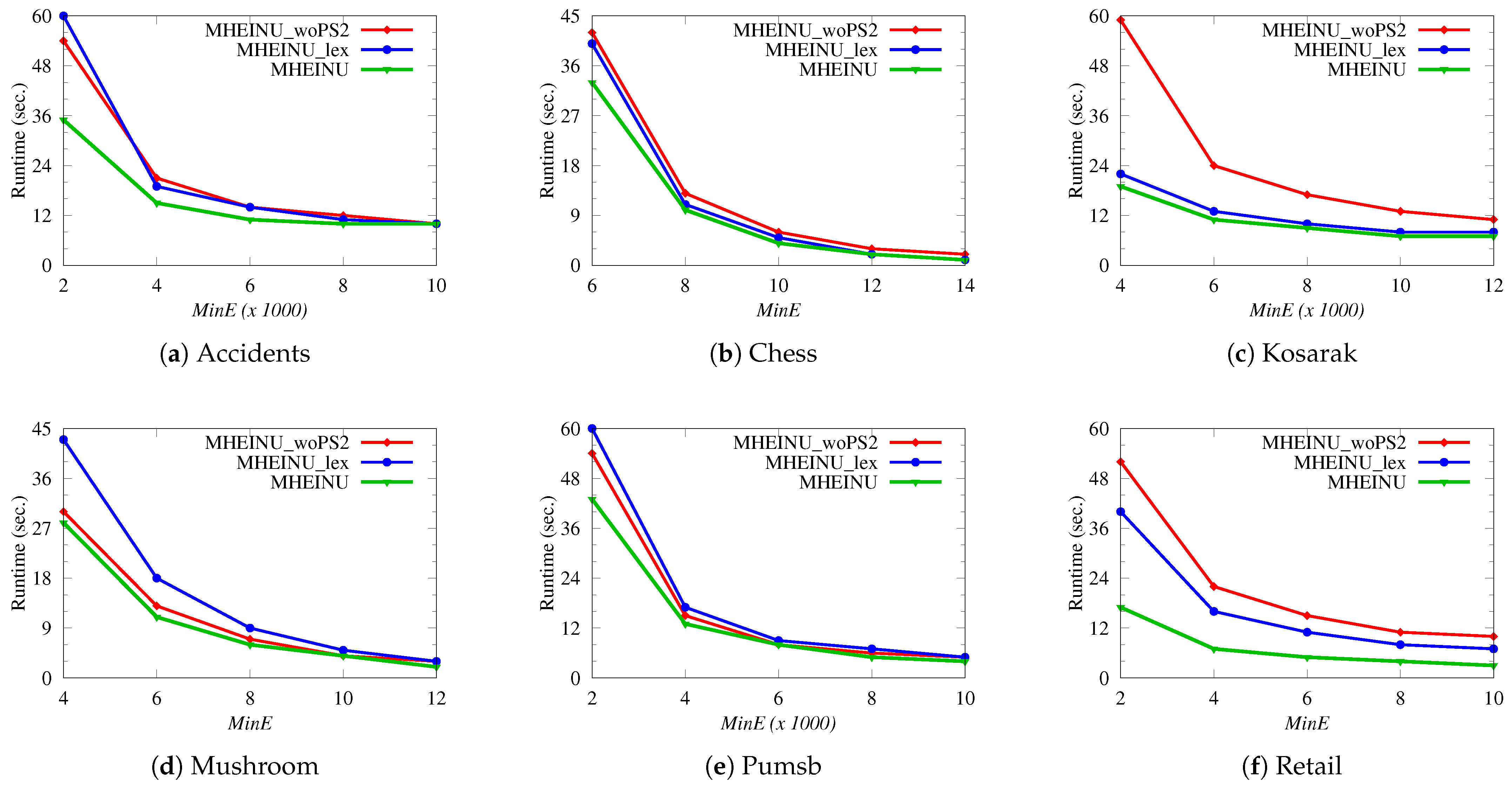
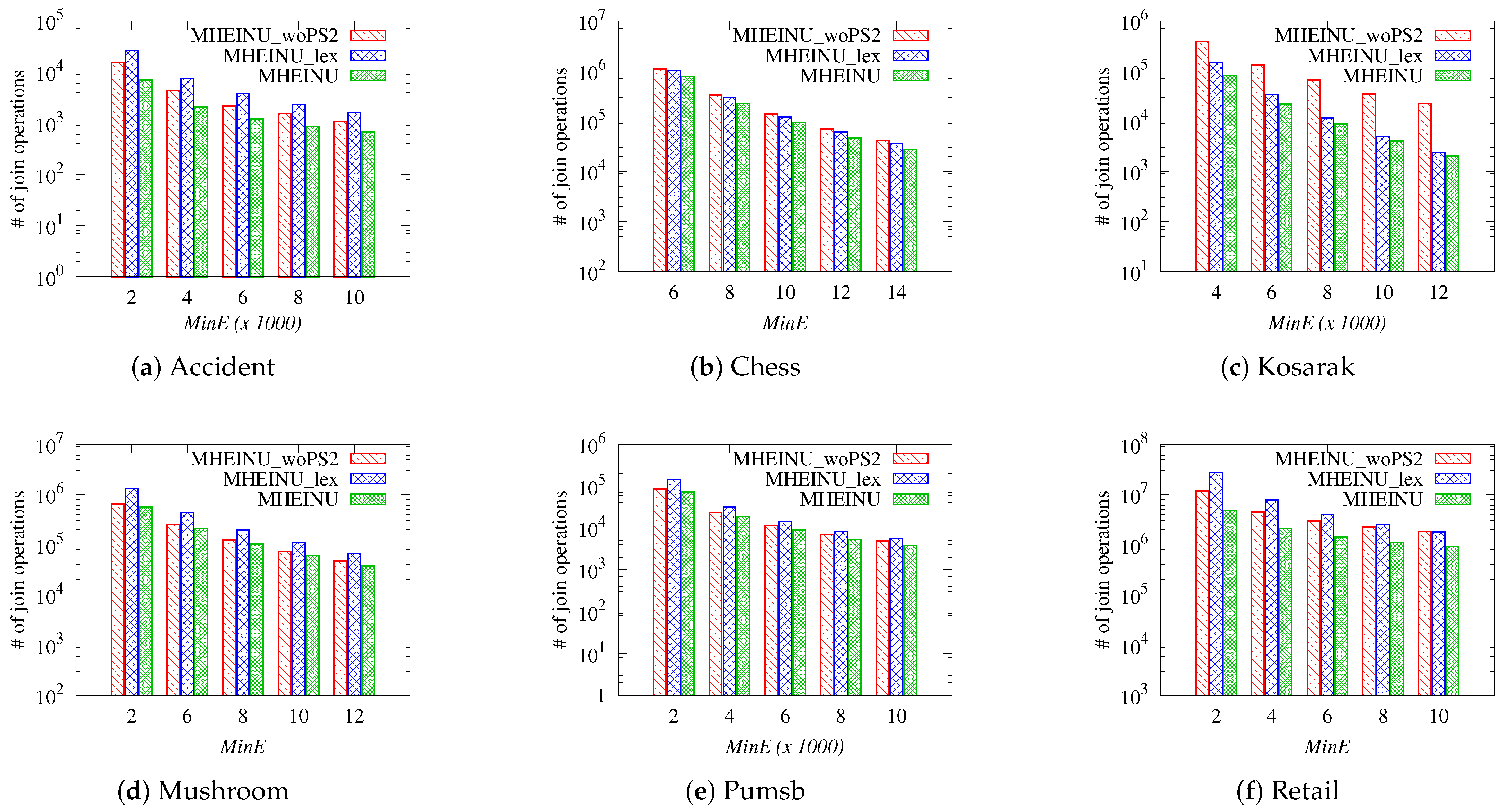
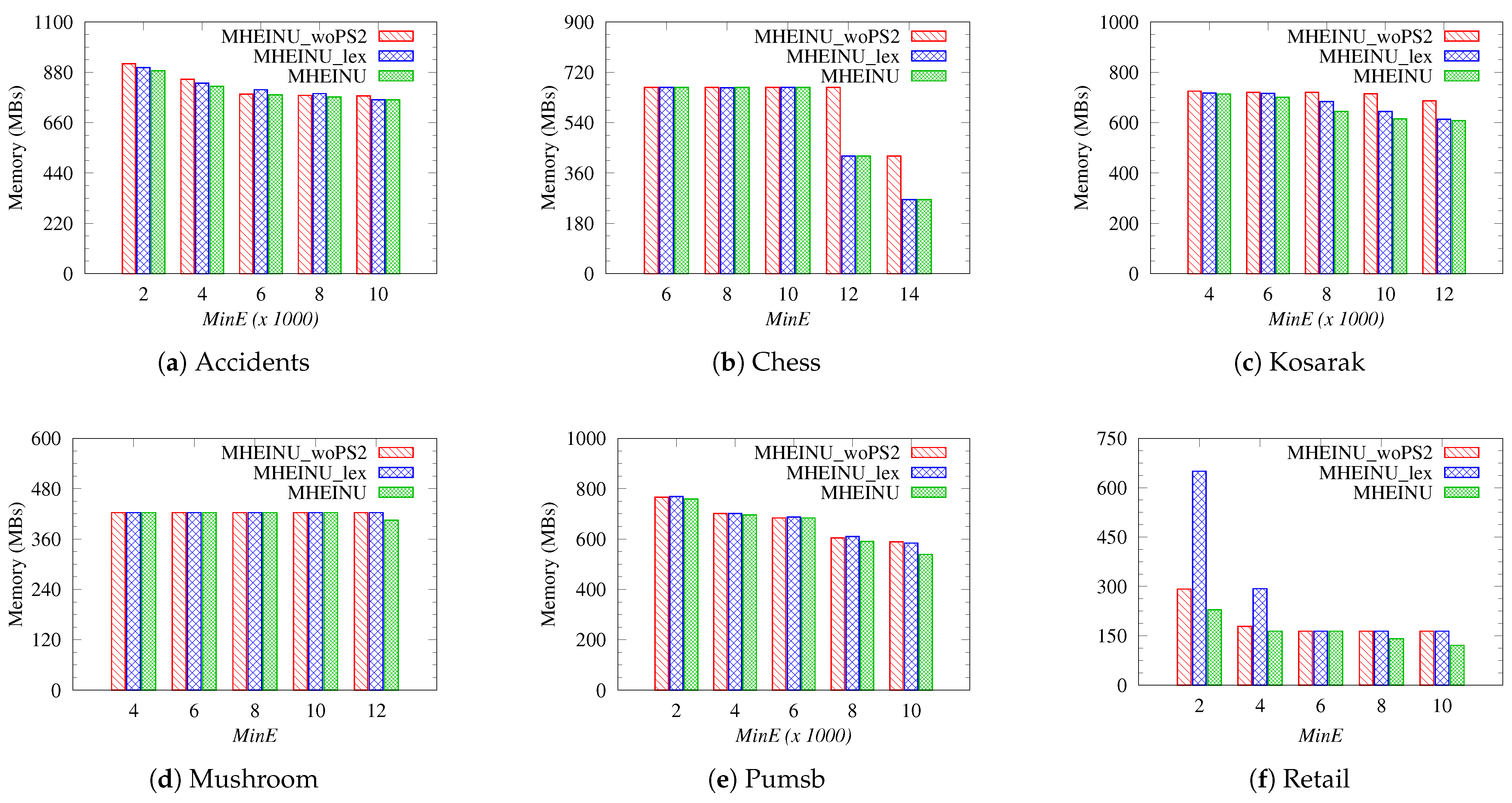

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}