
Non-Convex Metric Learning-Based Trajectory Clustering Algorithm

Abstract
1. Introduction
- (1)
- Based on the remarkable property in which the Laplace norm can effectively approximate the rank of a metric matrix, the non-convex metric learning method with nearest neighbor structure preservation and low-rank constraints is developed to optimize the metric matrix to improve the accuracy of the sample similarity metric in the process of trajectory feature encoding and clustering. The resultant non-convex issue can be efficiently addressed by leveraging the difference of convex functions algorithm (DCA) and alternating direction method of multipliers (ADMM) approaches.
- (2)
- Raw trajectories can be divided into several homogeneity sub-trajectories based on the extracted kinematic parameters of trajectory points under the minimum description length principle, and its feature set is obtained by calculating the statistic characteristics of sub-trajectories.
- (3)
- The segmented trajectory can be encoded as a fixed-length vector by leveraging the bag-of-words model, along with the developed metric learning method, to obtain its feature descriptor. Subsequently, all feature descriptors can be clustered using the K-means clustering algorithm in conjunction with the proposed metric learning approach, thereby facilitating effective trajectory clustering.
2. Non-Convex Low-Rank Metric Learning
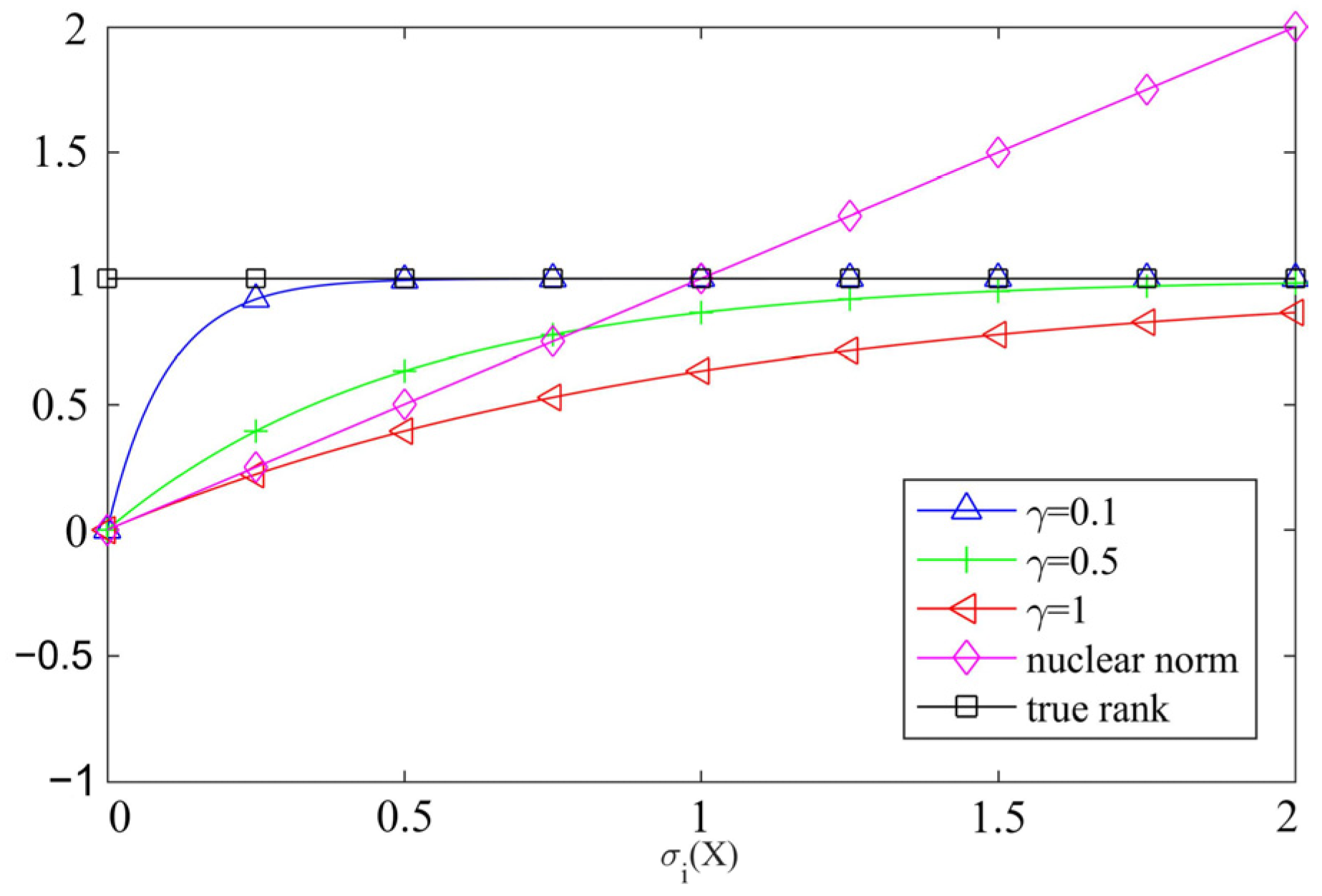
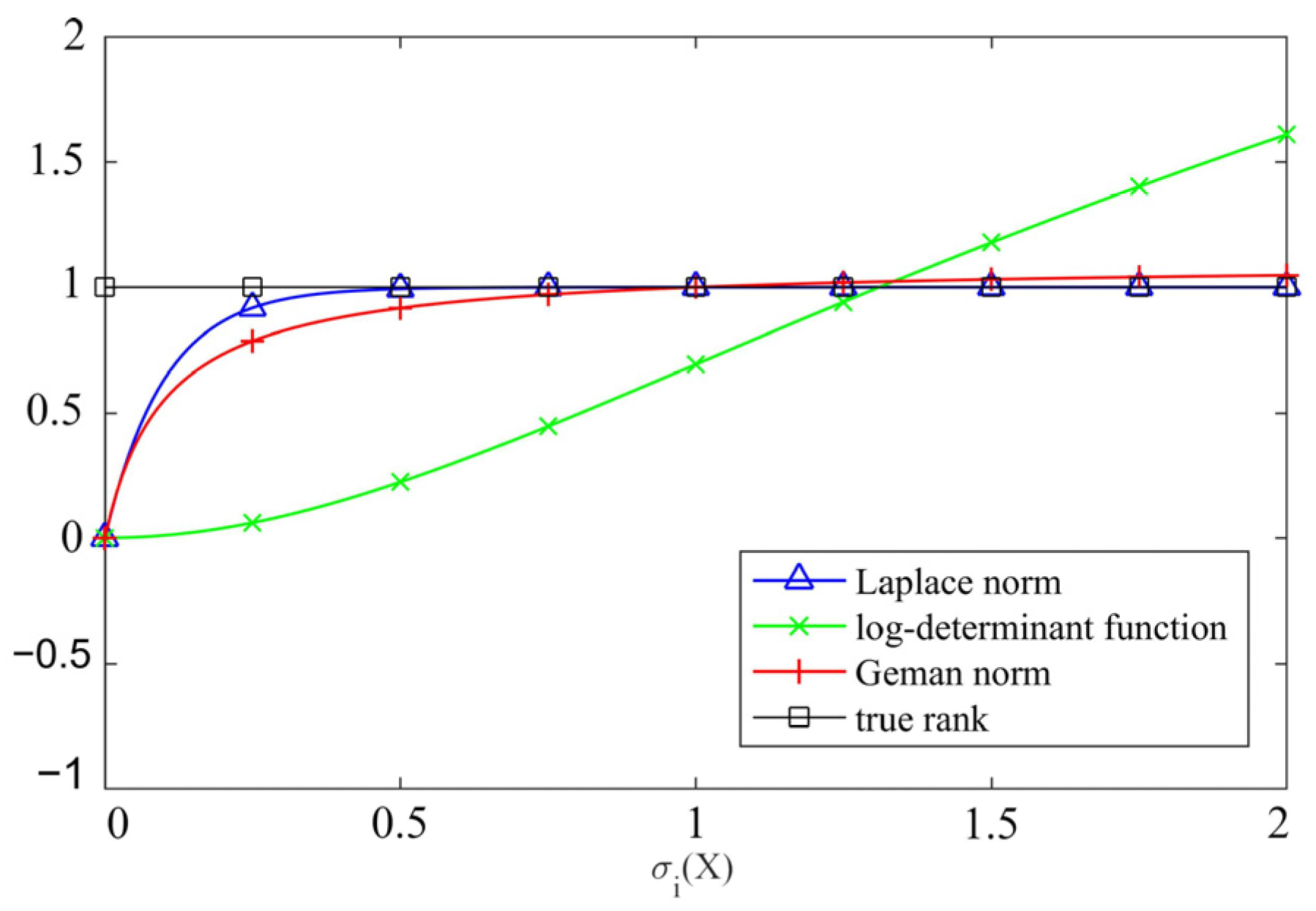
2.1. Laplace Norm
2.2. Metric Learning Manifold Constraints
2.3. Metric Matrix Low-Rank Constraint
2.4. Solving Metric Learning Issue with Low-Rank and Manifold Constraints
| Algorithm 1. Non-convex low-rank metric learning method |
| Input: training samples Initialization: for unit matrix), while do with (3) while do with (23) 3. Fixing with (27) 4. Fixing and with (28) 5. Update penalty parameter with (30) 6. end while 7. end while Output: |
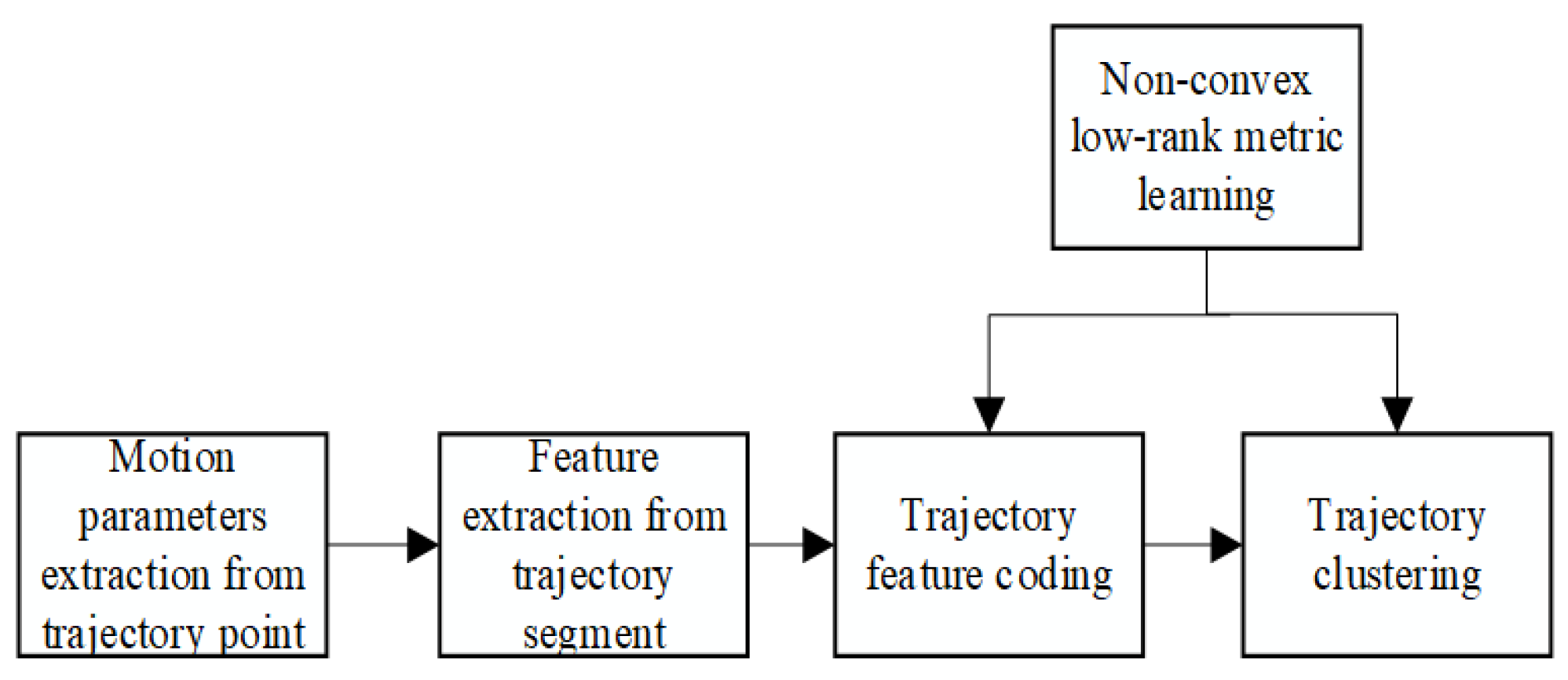
3. Trajectory Clustering with the Bag-of-Words Model and Metric Learning
3.1. Trajectory Point Motion Parameters Extraction
3.2. Trajectory Segment Feature Extraction
3.3. Trajectory Feature Encoding
3.4. Trajectory Clustering
| Algorithm 2. Bag-of-words model and metric learning-based clustering approach |
| Input: Trajectory dataset 1. Extract trajectory point motion parameters based on Equations (31)–(33). 2. Segment trajectories by using GRASP-UTS, and extract trajectory segment features. 3. Encode trajectory features based on the bag-of-words model and the metric matrix obtained via the proposed low-rank metric learning method. 4. Cluster trajectories by employing K-means and the metric matrix acquired using the developed low-rank metric learning method. Output: Trajectory class clusters |
3.5. Analysis of Computational Complexity
4. Experimental and Simulation Analysis
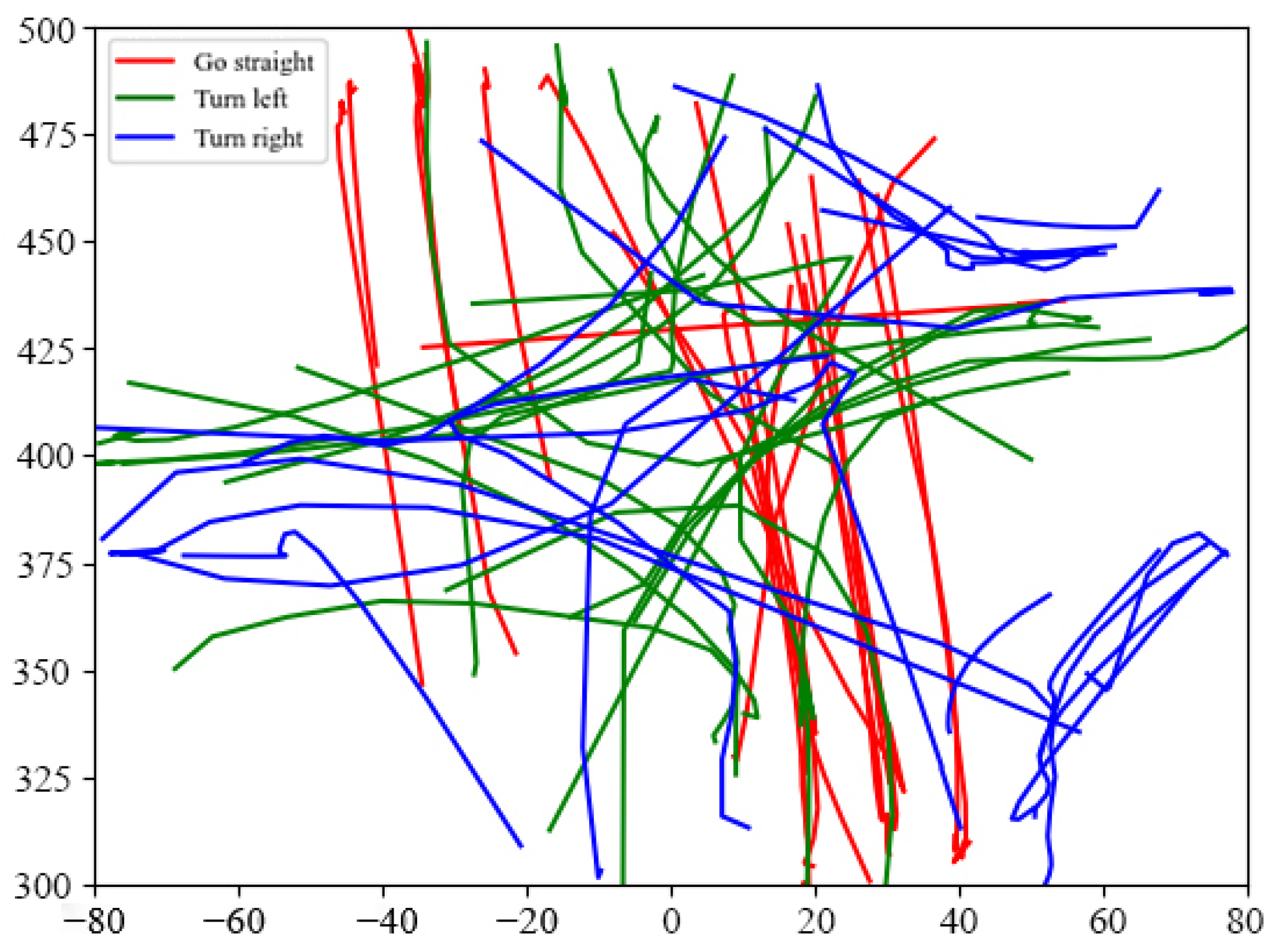
4.1. Experimental Dataset and Environment
4.2. Evaluation Metrics
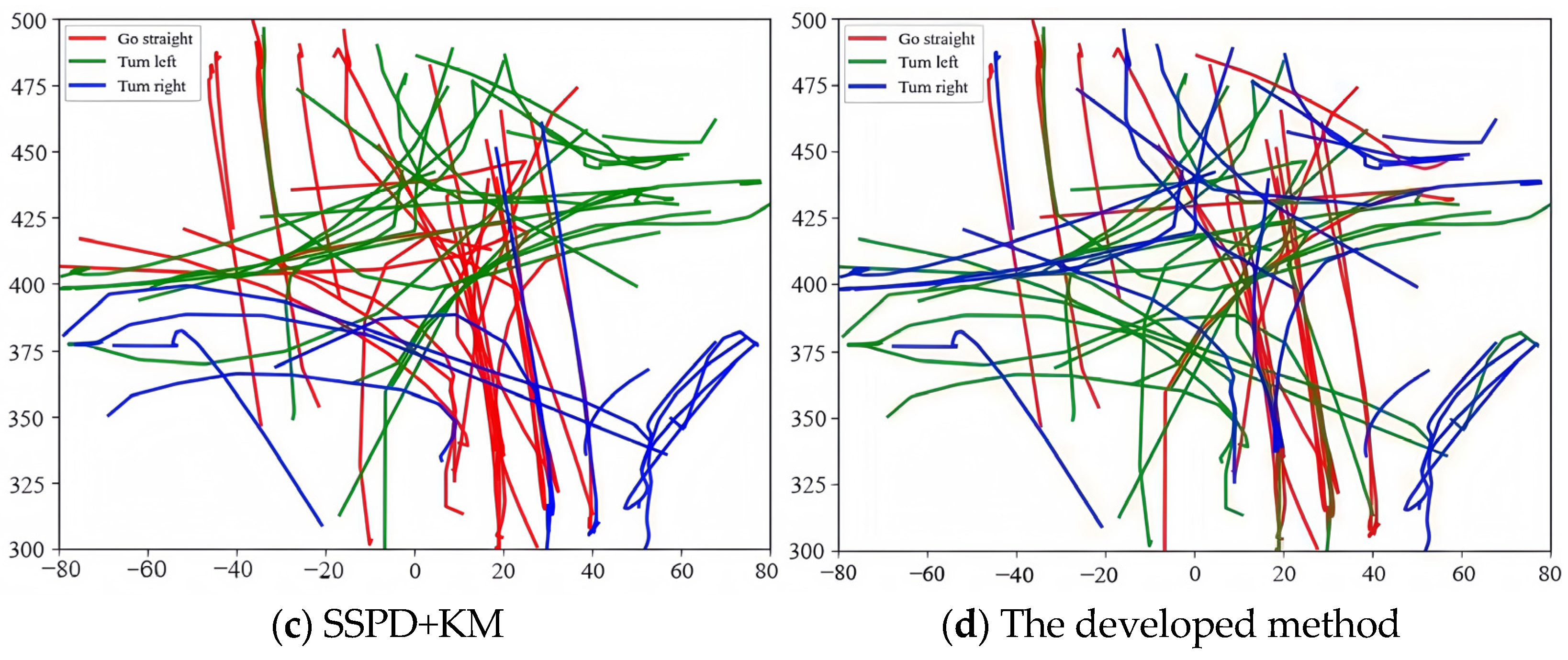
4.3. Simulation Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xie, J.; Liu, X.; Wang, M. SFKNN-DPC: Standard deviation weighted distance based density peak clustering algorithm. Inf. Sci. 2024, 653, 119788. [Google Scholar] [CrossRef]
- Jiang, J.; Pan, D.; Ren, H.; Jiang, X.; Li, C.; Wang, J. Self-supervised trajectory representation learning with temporal regularities and travel semantics. In Proceedings of the 2023 IEEE 39th International Conference on Data Engineering (ICDE), Anaheim, CA, USA, 3–7 April 2023; pp. 843–855. [Google Scholar]
- Yang, Y.; Cai, J.; Yang, H.; Zhang, J.; Zhao, X. TAD: A trajectory clustering algorithm based on spatial-temporal density analysis. Expert Syst. Appl. 2020, 139, 112846. [Google Scholar] [CrossRef]
- Yang, J.; Liu, Y.; Ma, L.; Ji, C. Maritime traffic flow clustering analysis by density based trajectory clustering with noise. Ocean Eng. 2022, 249, 111001. [Google Scholar] [CrossRef]
- Yu, Q.; Luo, Y.; Chen, C.; Chen, S. Trajectory similarity clustering based on multi-feature distance measurement. Appl. Intell. 2019, 49, 2315–2338. [Google Scholar] [CrossRef]
- Sousa, R.S.D.; Boukerche, A.; Loureiro, A.A. Vehicle trajectory similarity: Models, methods, and applications. In ACM Computing Surveys (CSUR); Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–32. [Google Scholar]
- Niu, X.; Chen, T.; Wu, C.Q.; Niu, J.; Li, Y. Label-based trajectory clustering in complex road networks. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4098–4110. [Google Scholar] [CrossRef]
- Besse, P.C.; Guillouet, B.; Loubes, J.-M.; Royer, F. Review and perspective for distance-based clustering of vehicle trajectories. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3306–3317. [Google Scholar] [CrossRef]
- Kumar, D.; Wu, H.; Rajasegarar, S.; Leckie, C.; Krishnaswamy, S.; Palaniswami, M. Fast and scalable big data trajectory clustering for understanding urban mobility. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3709–3722. [Google Scholar] [CrossRef]
- Ma, D.; Fang, B.; Ma, W.; Wu, X.; Jin, S. Potential routes extraction for urban customized bus based on vehicle trajectory clustering. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11878–11888. [Google Scholar] [CrossRef]
- Tao, Y.; Both, A.; Silveira, R.I.; Buchin, K.; Sijben, S.; Purves, R.S.; Laube, P.; Peng, D.; Toohey, K.; Duckham, M. A comparative analysis of trajectory similarity measures. GISci. Remote Sens. 2021, 58, 643–669. [Google Scholar] [CrossRef]
- Wang, S.; Bao, Z.; Culpepper, J.S.; Cong, G. A survey on trajectory data management, analytics, and learning. ACM Comput. Surv. 2021, 54, 39. [Google Scholar] [CrossRef]
- Yao, D.; Zhang, C.; Zhu, Z.; Huang, J.; Bi, J. Trajectory clustering via deep representation learning. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 3880–3887. [Google Scholar]
- Zhong, C.; Cheng, S.; Kasoar, M.; Arcucci, R. Reduced-order digital twin and latent data assimilation for global wildfire prediction. Nat. Hazards Earth Syst. Sci. 2023, 23, 1755–1768. [Google Scholar] [CrossRef]
- Taghizadeh, S.; Elekes, A.; Schäler, M.; Böhm, K. How meaningful are similarities in deep trajectory representations? Inf. Syst. 2021, 98, 101452. [Google Scholar] [CrossRef]
- Liang, M.; Liu, R.W.; Li, S.; Xiao, Z.; Liu, X.; Lu, F. An unsupervised learning method with convolutional auto-encoder for vessel trajectory similarity computation. Ocean Eng. 2021, 225, 108803. [Google Scholar] [CrossRef]
- Michelioudakis, E.; Artikis, A.; Paliouras, G. Online semi-supervised learning of composite event rules by combining structure and mass-based predicate similarity. Mach. Learn. 2024, 113, 1445–1481. [Google Scholar] [CrossRef]
- Sun, P.; Yang, L. Low-rank supervised and semi-supervised multi-metric learning for classification. Knowl. Based Syst. 2022, 236, 107787. [Google Scholar] [CrossRef]
- Macqueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; Volume 233, pp. 281–297. [Google Scholar]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An Efficient Data Clustering Databases Method for Very Large Databases. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Montreal, QC, Canada, 4–6 June 1996; pp. 103–114. [Google Scholar]
- Wang, W.; Yang, J.; Muntz, R. STING: A Statistical Information Grid Approach to Spatial Data Mining. In Proceedings of the 23rd International Conference on Very Large Data Bases, Athens, Greece, 25–29 August 1997; pp. 186–195. [Google Scholar]
- Sheikholeslami, G.; Chatterjee, S.; Zhang, A. WaveCluster: A wavelet-based clustering approach for spatial data in very large databases. VLDB J. 2000, 8, 289–304. [Google Scholar] [CrossRef]
- Fisher, D. Knowledge acquisition via incremental clustering. Mach. Learn. 1987, 2, 139–182. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.; Sander, J. OPTICS: Ordering Points To Identify the Clustering Structure. In Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data, Philadelphia, PA, USA, 1–3 June 1999; Volume 28, pp. 49–60. [Google Scholar]
- Ma, S.; Wang, T.; Tang, S.; Yang, D.; Gao, J. A New Fast Clustering Algorithm Based on Reference and Density. In Advances in Web-Age Information Management; Springer: Berlin/Heidelberg, Germany, 2002; pp. 214–225. [Google Scholar]
- Agrawal, K.P.; Garg, S.; Sharma, S.; Patel, P. Development and validation of OPTICS based spatio-temporal clustering technique. Inf. Sci. 2016, 369, 388–401. [Google Scholar] [CrossRef]
- Hüsch, M.; Schyska, B.U.; Bremen, L.V. CorClustST-Correlation-based clustering of big spatio-temporal datasets. Future Gener. Comput. Syst. 2020, 110, 610–619. [Google Scholar] [CrossRef]
- Huang, L.; Xu, Z.; Zhang, Z.; He, Y.; Zan, M. A fast iterative shrinkage/thresholding algorithm via laplace norm for sound source identification. IEEE Access 2020, 8, 115335–115344. [Google Scholar] [CrossRef]
- Greenacre, M.; Groenen, P.; Hastie, T.; d’Enza, A.I.; Markos, A.; Tuzhilina, E. Principal component analysis. Nat. Rev. Methods Primers 2022, 2, 1–100. [Google Scholar] [CrossRef]
- Yuan, C.; Yang, L. An efficient multi-metric learning method by partitioning the metric space. Neurocomputing 2023, 529, 56–79. [Google Scholar] [CrossRef]
- Lei, C.; Zhu, X. Unsupervised feature selection via local structure learning and sparse learning. Multimedia Tools Appl. 2018, 77, 29605–29622. [Google Scholar] [CrossRef]
- Islam, A.; Radke, R. Weakly supervised temporal action localization using deep metric learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2020; pp. 547–556. [Google Scholar]
- Sun, G.; Cong, Y.; Wang, Q.; Xu, X. Online low-rank metric learning via parallel coordinate descent method. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 207–212. [Google Scholar]
- Chen, S.; Shen, Y.; Yan, Y.; Wang, D.; Zhu, S. Cholesky Decomposition-Based Metric Learning for Video-Based Human Action Recognition. IEEE Access 2020, 8, 36313–36321. [Google Scholar] [CrossRef]
- Ma, X.; Li, G.; Wang, Y.; Li, H.; Yang, W. Seismic Deconvolution Based on a Non-Convex L1-L2 Norm Constraint. In Proceedings of the 81st EAGE Conference and Exhibition, London, UK, 3–6 June 2019; pp. 1–5. [Google Scholar]
- Tono, K.; Takeda, A.; Gotoh, J. Efficient DC algorithm for constrained sparse optimization. arXiv 2017, arXiv:1701.08498. [Google Scholar]
- Wang, J.; Zhang, F.; Huang, J.; Wang, W.; Yuan, C. A nonconvex penalty function with integral convolution approximation for compressed sensing. Signal Process. 2019, 158, 116–128. [Google Scholar] [CrossRef]
- Junior, A.S.; Times, V.C.; Renso, C.; Matwin, S.; Cabral, L.A. A semi-supervised approach for the semantic segmentation of trajectories. In Proceedings of the 2018 19th IEEE International Conference on Mobile Data Management (MDM), Aalborg, Denmark, 25–28 June 2018; pp. 145–154. [Google Scholar]
- Etemad, M.; Júnior, A.S.; Hoseyni, A.; Rose, J.; Matwin, S. A Trajectory Segmentation Algorithm Based on Interpolation-based Change Detection Strategies. In Proceedings of the EDBT/ICDT Workshops, Lisbon, Portugal, 26 March 2019; pp. 51–58. [Google Scholar]
- Nivash, S.; Ganesh, E.N.; Harisudha, K.; Sreeram, S. Extensive analysis of global presidents’ speeches using natural language. In Sentimental Analysis and Deep Learning: Proceedings of ICSADL; Springer: Singapore, 2022; pp. 829–850. [Google Scholar]
- Mateos-Nunez, D.; Cortes, J. Distributed saddle-point subgradient algorithms with Laplacian averaging. IEEE Trans. Autom. Control 2016, 62, 2720–2735. [Google Scholar] [CrossRef]
- Liang, M.; Liu, R.W.; Gao, R.; Xiao, Z.; Zhang, X.; Wang, H. A survey of distance-based vessel trajectory clustering: Data pre-processing, methodologies, applications, and experimental evaluation. arXiv 2024, arXiv:2407.11084. [Google Scholar]
- Feng, X.; Cen, Z.; Hu, J.; Zhang, Y. Vehicle trajectory prediction using intention-based conditional variational autoencoder. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3514–3519. [Google Scholar]
- Zhang, H.; Fu, R. A Hybrid Approach for Turning Intention Prediction Based on Time Series Forecasting and Deep Learning. Sensors 2020, 20, 4887. [Google Scholar] [CrossRef]
- Ghazal, T.M.; Hussain, M.Z.; Said, R.A.; Nadeem, A.; Hasan, M.K.; Ahmad, M.; Khan, M.A.; Naseem, M.T. Performances of k-means clustering algorithm with different distance metrics. Intell. Autom. Soft Comput. 2021, 29, 735–742. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clustering Method | Straight | Left Turn | Right Turn | Accuracy |
|---|---|---|---|---|
| LCSS + KM | 0.70/0.48 | 0.40/0.53 | 0.45/0.56 | 51.67% |
| Hausdorff + KM | 0.65/0.65 | 0.45/0.39 | 0.60/0.71 | 56.67% |
| SSPD + KM | 0.85/0.68 | 0.65/0.59 | 0.45/0.69 | 65.00% |
| The proposed algorithm | 0.90/0.95 | 0.57/0.60 | 0.55/0.55 | 71.67% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, X.; Wang, H. Non-Convex Metric Learning-Based Trajectory Clustering Algorithm. Mathematics 2025, 13, 387. https://doi.org/10.3390/math13030387
Lei X, Wang H. Non-Convex Metric Learning-Based Trajectory Clustering Algorithm. Mathematics. 2025; 13(3):387. https://doi.org/10.3390/math13030387
Chicago/Turabian StyleLei, Xiaoyan, and Hongyan Wang. 2025. "Non-Convex Metric Learning-Based Trajectory Clustering Algorithm" Mathematics 13, no. 3: 387. https://doi.org/10.3390/math13030387
APA StyleLei, X., & Wang, H. (2025). Non-Convex Metric Learning-Based Trajectory Clustering Algorithm. Mathematics, 13(3), 387. https://doi.org/10.3390/math13030387