1. Introduction
Let
be the stochastic process defined by
where
,
is a Poisson process with rate or intensity
and
is called the
response function. The random variables
are the arrival times of the events of the Poisson process, and
is a sequence of independent random variables that are identically distributed as a random variable
Y.
The process
is known as a
filtered Poisson process (FPP); see [
1] (p. 145). It has applications in various fields. In [
2], Lefebvre and Guilbault used these processes to model a river flow. The authors also estimated return periods in hydrology based on FPPs.
In hydrology, an appropriate response function is of the form
where
c is a positive constant. This is the response function that will be used in this paper.
Remark 1. Notice that with the response function defined in Equation (2), we can express in terms of :Moreover, since the Poisson process has independent increments, the summation in the above equation is independent of . Filtered Poisson processes have applications in physics, operation research, finance and actuarial science, among other fields. Many theoretical and applied papers have been written on FPPs or generalizations of these processes. Racicot and Moses [
3] used FPPs in vibration problems. Hero [
4] estimated the time shift of a non-homogeneous FPP in the presence of additive Gaussian noise. Grigoriu [
5] developed methods in order to find properties of the output of linear and non-linear dynamic systems to random actions represented by FPPs. Novikov et al. [
6] considered first-passage problems for FPPs. Yin et al. [
7] modelled snow loads as FPPs. Theodorsen et al. [
8] obtained statistical properties of an FPP with additive random noise. Alazemi et al. [
9] computed estimators of FPP intensities. In Grant and Szechtman [
10], the process
is replaced by a non-homogeneous Poisson process.
In this paper, we consider a controlled version of
:
where
is a positive constant and the control
is assumed to be a continuous function.
Let
be the
first-passage time random variable defined by
where
. Our aim is to minimize the expected value of the cost function
where
and
are positive constants and
is the terminal cost function. Because the parameter
is positive, the optimizer wants to minimize the expected time that the controlled process will spend in the interval
, while taking into account the quadratic control costs and the terminal cost. We could assume instead that
is negative, so that the objective would be to maximize the expected time in the continuation region
.
This type of problem, in which the optimizer controls a stochastic process until a certain event occurs, is known as a
homing problem. Whittle [
11] has considered these problems for
n-dimensional diffusion processes. In [
12], he generalized the cost criterion by taking the risk-sensitivity of the optimizer into account.
The author has written numerous papers on homing problems for different types of stochastic processes. Recently, he and Yaghoubi have solved homing problems for queueing systems and for continuous-time Markov chains; see [
13].
Next, we define the
value function
It gives the expected cost obtained if the optimizer chooses the optimal value of the control
in the interval
.
In
Section 2, the dynamic programming equation satisfied by the value function will be derived. Then, in
Section 3, various cases for the distribution of the random variable
Y, which denotes the size of the jumps, will be considered. Explicit results will be obtained for the value function and the optimal control. To do so, we will have to solve a non-linear integro-differential equation.
2. Dynamic Programming Equation
We have, for
,
For a
that is small,
Moreover, using Bellman’s principle of optimality (see [
14]), we can express the second integral in Equation (
8) in terms of the value function:
where
It follows that it is sufficient to find the optimal value of the control
at the initial instant:
Next,
so that
Hence, we can write that
Now, we have
and
where
is the arrival time of the first event of the Poisson process
. That is, given that
, the random variable
has a uniform distribution on the interval
. It follows, making use of the law of total probability for continuous random variables, that
where
is the probability density function of the random variable
Y (the
parent random variable of
).
We deduce from Taylor’s theorem that
Furthermore,
which implies that
Similarly,
for any
. Hence,
From what precedes, we may write that
That is,
Finally, dividing both sides of the above equation by
and taking the limit as
decreases to zero, we obtain the following proposition.
Proposition 1. The value function satisfies the dynamic programming equation (DPE)for . Moreover, we have the boundary condition Remark 2. Since the stochastic process has jumps, the terminal cost function can be used to penalize a final value of the process that is well above the boundary at . For example, in the application of filtered Poisson processes in hydrology, the manager of a dam may have the objective of keeping the water level below a given value d. If this water level exceeds the maximum desired value by much, the consequences can be very serious. The optimizer must therefore choose a value of the control variable that minimizes this risk as much as possible.
Now, we deduce from the DPE that the optimal control
is given by
Hence, substituting this expression into Equation (
26), we find that in order to obtain the value function, we must solve the non-linear integro-differential equation (IDE)
subject to the boundary condition in Equation (
27).
In the next section, various cases will be considered for the distribution of the size Y of the jumps.
3. Particular Cases
Case I. Suppose first that the random variable
Y is actually a constant
. Then,
Assume that
and
for any
. Equation (
29) reduces to
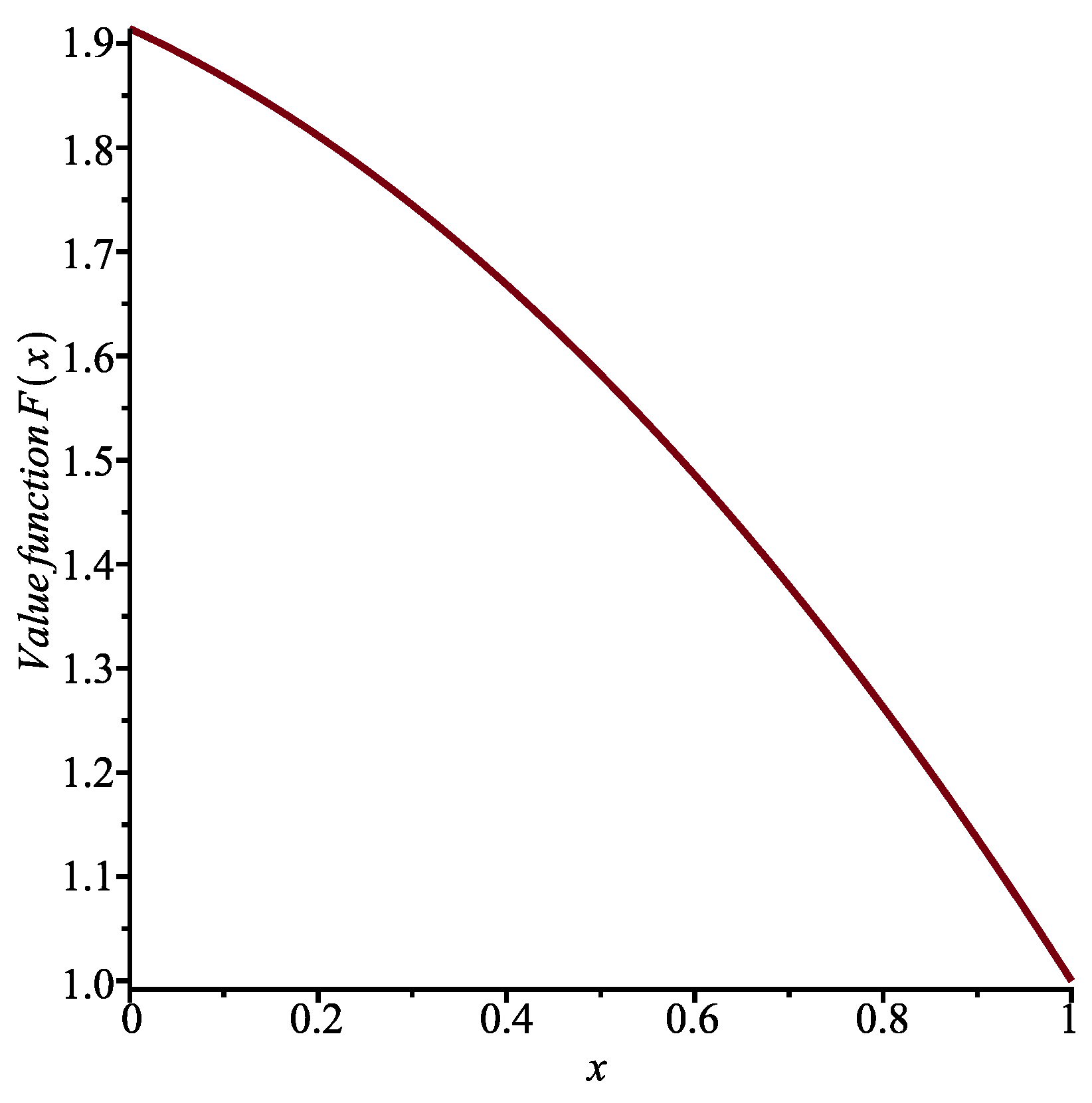
Let us take
. The solution to the above first-order non-linear ordinary differential equation (ODE) that satisfies the boundary condition
is (see
Figure 1)
Remark 3. There is a second solution to Equation (31) that is such that , namelyHowever, because θ is positive, the value function must also be positive in the interval , as well as decreasing with increasing x. The function in the above equation is increasing and negative for . Therefore, it must be discarded. The optimal control is an affine function:
Case II. Suppose that, in the previous case, the terminal cost function
is rather
. It follows that
We must now solve
Choosing the same constants as those in Case I and
, the mathematical software program
Maple finds that the solution to the above equation is
where
is an arbitrary constant and LambertW is a special function defined in such a way that
Solving Equation (
36) with the software program
Mathematica yields an equivalent expression in terms of the
ProductLog function, which gives the principal solution for
w in the equation
. However, both software programs fail to give the solution that satisfies the boundary condition
, together with the other conditions in our problem:
must be positive and decreasing with
.
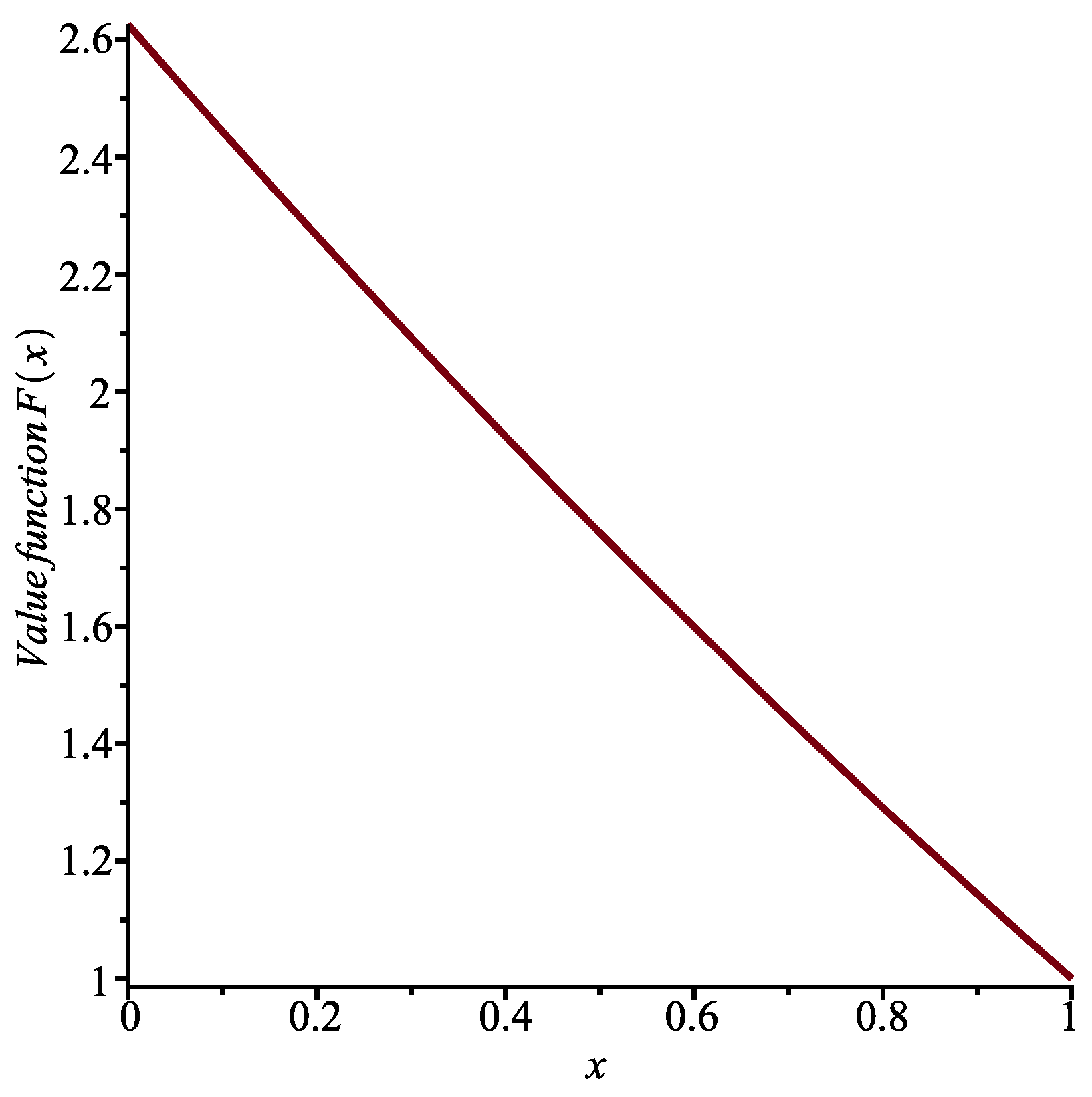
Making use of the NDSolve function in
Mathematica, which employs a numerical technique, we obtain the graph shown in
Figure 2. The solution that we are looking for is represented by the full line. From this function, we can determine the optimal control
.
Remark 4. Maple and Mathematica can solve (simple) integral equations, but not integro-differential equations directly. This is the reason why we must try to transform the equation into a (non-linear) ordinary differential equation. There are, however, many papers on numerical solutions of integro-differential equations; see, for example, [15]. Case III. Next, we assume that
Exp
, so that
We then have
(a) First, we take
for
, as those in Case I. It follows that
Moreover, we can write that
We must solve the IDE
We calculate
Hence, differentiating Equation (
43) with respect to
x, we find that
satisfies the second-order non-linear ODE
This equation is subject to the boundary condition
. Furthermore, we deduce from Equation (
43) (and the fact that
must be negative) that
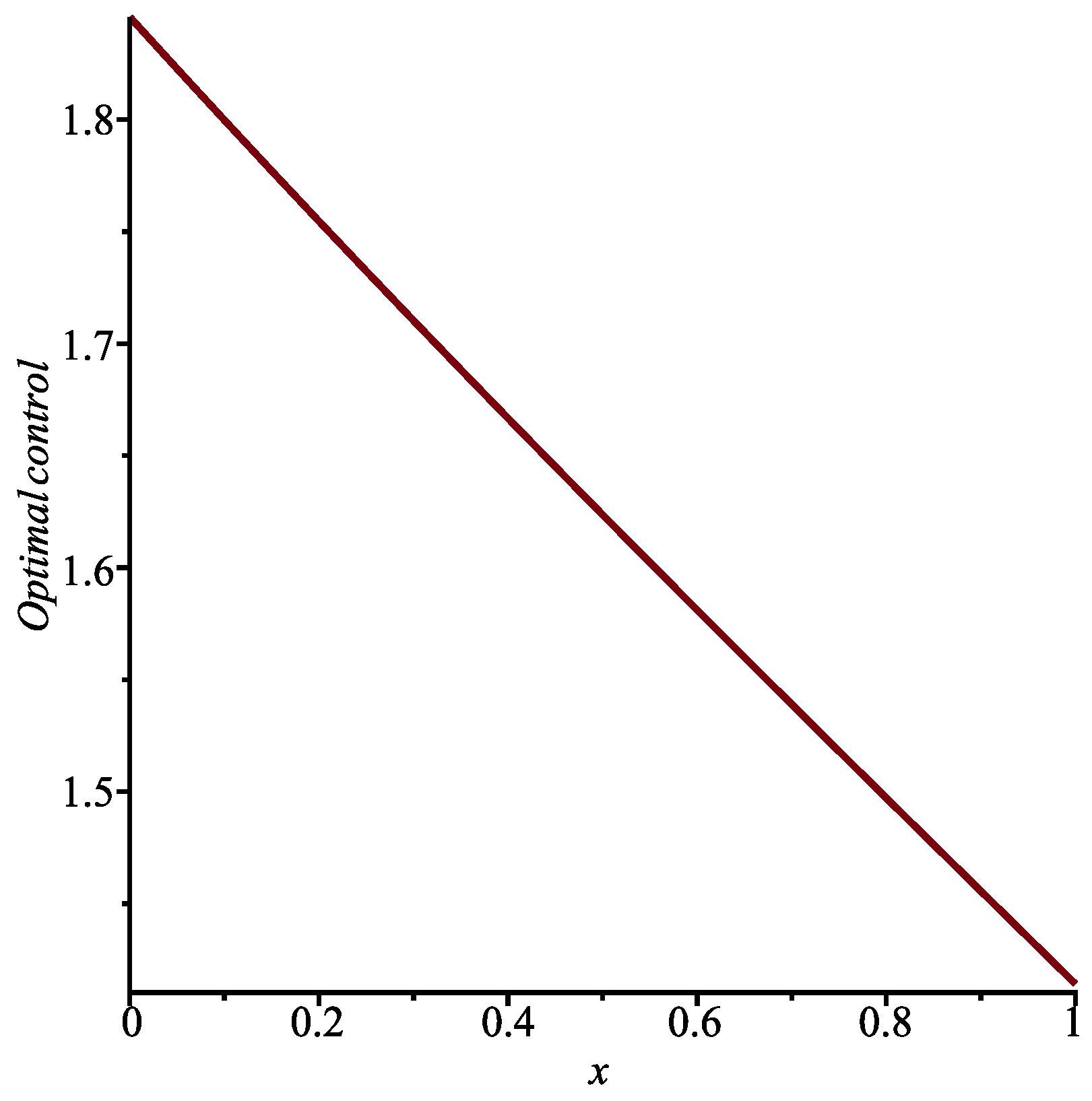
Choosing the same constants as those in Case I and
, we can obtain (using a numerical method) both the value function
and the optimal control
in the interval
; see
Figure 3 and
Figure 4.
(b) If
for
, as in Case II, we calculate
It follows that the function
satisfies the IDE
Proceeding as in (a), we find that
satisfies Equation (
45). However, the second boundary condition becomes
Hence, with the above constants, we now obtain that
.
Case IV. Finally, we suppose that
U
, with
. We have
(i) When
, we must solve the IDE
It follows that
satisfies the equation
Now, we can write that
so that, if
is small,
Assuming that
, we thus have
where
is an arbitrary constant.
(ii) In the case when
, the IDE becomes
Differentiating with respect to
x, we have
To obtain an approximate expression for the function
, we can first try to solve the above ODE, subject to the condition
and the value of
deduced from Equation (
56). Next, we can use the continuity of
to determine the value of the constant
in Equation (
55).
The Inverse Problem
As we have seen above, finding the value function for a given density function is generally a difficult task. To end this paper, we will consider the inverse problem: if we assume that is of a certain form, is there at least one density function (and a terminal cost function K) for which the function can indeed be considered as the value function in a particular case of our homing problem?
Case I. The simplest case is of course the one when
is a positive constant
. Moreover, we assume that
as well. Then, Equation (
29) reduces to
Hence, we deduce that
cannot be a constant, unless
. The corresponding optimal control would be identical to 0. This result is in fact obvious, because if
and
, it is clear that
cannot be smaller than
, which is obtained by choosing
. Furthermore, as we mentioned earlier, the value function
should be decreasing as
x increases when
, and therefore should not be a constant.
Suppose however that we replace the parameter
in the cost function
by
. The IDE (
29) will then become
Assume that
and that
(so that
, as required). Then, if
U
, we obtain the equation
Thus, the value function will indeed be equal to the constant
(and
) if and only if
Note that the aim would be to keep the controlled process in the interval
for as long as possible (taking into account the quadratic control costs), rather than trying to minimize the expected time spent by the process in
.
Case II. Next, we look for value functions of the form
for
, where
and
, and we assume that
. Substituting the expression for
and
into the IDE (
29), we obtain, after simplification, that we must have
It follows that this solution is valid for any (positive) random variable
Y having an expected value
such that
where
. The optimal control would be
.
This case could be generalized by taking , with .
4. Discussion
In this paper, a homing problem for FPPs was set up and solved explicitly in various particular cases. This is the first time such problems were considered for FPPs. These processes have applications in numerous fields. Therefore, the results that we obtained may be useful for people working in these fields.
To obtain exact solutions to our problem, we had to solve a non-linear integro-differential equation, which is the main limitation of the technique used in this paper. Sometimes, this equation can be transformed into a differential equation. However, solving this differential equation, subject to the appropriate boundary conditions, is in itself a difficult problem.
We can at least try to find approximate analytical expressions for the value function and the optimal control. When this is not possible, we can resort to numerical methods or simulation.
A possible extension of the work presented in this paper would be to treat the case when the parameter in the cost function is negative, so that there is a reward as long as the controlled process is in the continuation region. As mentioned above, in the application of the FPPs in hydrology, the problem could be to maintain the level of a river below a critical value for as long as possible, beyond which the risk of flooding is high. We could also add some noise in the form of a diffusion process to the model. Having time-varying parameters is another possibility. However, then the equation satisfied by the value function would include a partial derivative with respect to time, making the task of finding an explicit solution to this equation even more challenging.



{kind=link}
{kind=link}
{kind=link}
{kind=link}