Abstract
This paper introduces a novel unsupervised domain adaptation (UDA) method, MeTa Discriminative Class-Wise MMD (MCWMMD), which combines meta-learning with a Class-Wise Maximum Mean Discrepancy (MMD) approach to enhance domain adaptation. Traditional MMD methods align overall distributions but struggle with class-wise alignment, reducing feature distinguishability. MCWMMD incorporates a meta-module to dynamically learn a deep kernel for MMD, improving alignment accuracy and model adaptability. This meta-learning technique enhances the model’s ability to generalize across tasks by ensuring domain-invariant and class-discriminative feature representations. Despite the complexity of the method, including the need for meta-module training, it presents a significant advancement in UDA. Future work will explore scalability in diverse real-world scenarios and further optimize the meta-learning framework. MCWMMD offers a promising solution to the persistent challenge of domain adaptation, paving the way for more adaptable and generalizable deep learning models.
Keywords:
unsupervised domain adaptation; maximum mean discrepancy (MMD); discriminative class-wise MMD (DCWMMD); meta-learning; deep kernel; feature distributions; domain shift; transfer learning MSC:
68T05
1. Introduction
The success of deep learning relies heavily on large annotated datasets. However, annotating a substantial number of images with object content is a time-consuming and labor-intensive task. The advent of Generative Adversarial Networks (GANs) [1] has partially alleviated this issue, facilitating advancements in deep learning by enabling the creation of synthetic data. Despite this progress, existing learning algorithms often struggle with limited generalization across different datasets—a challenge known as domain adaptation (DA). Traditional recognition tasks typically assume that training data (source domain) and testing data (target domain) share a common distribution. In practice, this assumption rarely holds, as test data can come from diverse sources and modalities, leading to poor generalization and the phenomenon known as domain shift.
Various methods have been proposed to tackle domain adaptation [2,3,4,5,6], focusing mainly on aligning feature distributions between domains by measuring and minimizing differences. Another approach in UDA leverages meta-learning to generalize across new, unlabeled domains by learning adaptable representations. For instance, Vettoruzzo et al. [7] proposed a meta-learning framework that optimizes model parameters to achieve effective adaptation across domains with minimal labeled data, showing strong adaptability even with limited unlabeled test samples. This method emphasizes efficient domain adaptation, leveraging knowledge from prior domains to improve generalization under distribution shifts. Recent advancements in deep unsupervised domain adaptation (UDA) have introduced more sophisticated strategies. For instance, a comprehensive 2022 review [8] examined developments such as feature alignment, self-supervision, and representation learning, highlighting current trends and future directions. A 2023 approach employing domain-guided conditional diffusion models [9] demonstrated enhanced transfer performance by generating synthetic samples for the target domain, thus bridging domain gaps more effectively. Additionally, cross-domain contrastive learning [10] has shown promise in promoting domain-invariant features by minimizing feature distances across domains, and manifold-based techniques like Discriminative Manifold Propagation [11] have leveraged probabilistic criteria and metric alignment to achieve both transferability and discriminability.
Domain-Adversarial Neural Networks (DANNs) [4] introduced adversarial training with a gradient reversal layer, laying the groundwork for adversarial domain adaptation approaches. ADDA (Adversarial Discriminative Domain Adaptation) [5] further improved this framework by incorporating untied weight sharing for flexible feature alignment. Deep Adaptation Networks (DANs) [6] employed Maximum Mean Discrepancy (MMD) for kernel-based feature alignment, establishing an influential precedent in UDA. Techniques such as CyCADA [12] combined pixel-level and feature-level adaptations to comprehensively mitigate domain shifts, while MCD (Maximum Classifier Discrepancy) [13] used classifier-based discrepancy maximization to enhance target domain adaptation.
A significant challenge in domain adaptation lies in effectively measuring these distances [2,14]. Classical metrics such as Quadratic [15], Kullback–Leibler [16], and Mahalanobis [17] distances often lack flexibility and fail to generalize across models. Maximum Mean Discrepancy (MMD) [18], which embeds distribution metrics within a Reproducing Kernel Hilbert Space, has gained traction due to its robust theoretical foundation and application in various settings, such as transfer learning [19], kernel Bayesian inference [20], approximate Bayesian computation [21], and MMD GANs [22]. Despite its simplicity, selecting the optimal bandwidth for Gaussian kernels in MMD remains challenging. Liu et al. [23] addressed this by introducing a parameterized deep kernel, known as Maximum Mean Discrepancy with a Deep Kernel (MMDDK), which adapts kernel parameters for more precise domain alignment.
MMD effectively aligns overall domain distributions but struggles with precise class-wise feature alignment. Long et al. [24] addressed this by proposing Class-Wise Maximum Mean Discrepancy (CWMMD), which maps samples from both domains into a shared space and calculates the MMD for each category, summing them to derive the CWMMD. However, these approaches often involve linear transformations, which may not capture complex relationships needed for deeper alignment. Wang et al. [25] provided insights into the MMD’s theoretical foundations, highlighting its role in extracting shared semantic features across diverse categories while maximizing intra-class distances between source and target domains. This approach, however, reduced feature discriminativeness and relied on linear transformations with L2 norm estimations, which may not suffice for general, nonlinear relationships [26,27]. In contrast, deep neural networks, particularly convolutional neural networks (CNNs), excel at learning expressive, nonlinear transformations. Our previous work [28] proposed training a CNN architecture to automatically learn task-specific feature representations.
Meta-learning, or “learning to learn”, has gained attention for its ability to rapidly adapt to new tasks [29,30]. This proposal introduces a novel UDA method that leverages a class-wise, deep kernel-based MMD, optimized through meta-learning. This approach aims to enhance the adaptability and performance of UDA models by incorporating flexible, data-driven kernel learning mechanisms.
The contributions of this paper are summarized as follows: (1) It presents the development of the novel MCWMMD framework, which combines meta-learning with a Class-Wise MMD approach, specifically enhancing class-wise distribution alignment for unsupervised domain adaptation (UDA). (2) It introduces a meta-module that dynamically learns a deep kernel, optimizing domain alignment by adapting to the unique characteristics of each class distribution. (3) It provides a demonstration of improved cross-domain recognition performance, validated through extensive experiments on diverse benchmark datasets, showcasing the framework’s adaptability and effectiveness.
2. Related Work and Key Concepts
This section delves into the foundations and advancements of the Maximum Mean Discrepancy (MMD) metric, a widely used method for measuring the difference between distributions in domain adaptation tasks. We review the evolution of MMD, discussing its theoretical underpinnings, variations, and applications across different models. Additionally, we explore how recent research has extended the MMD to address more complex distributional challenges, including conditional and joint distributions, and we highlight the limitations that these methods seek to overcome. This study considers only two domains for domain adaptation, one source domain and one target domain. and represent the sample sets from the source domain and the target domain, respectively, and (or ) represents the union of all sample sets in both domains, i.e., . More symbols and notations are presented in a nomenclature table provided in Table 1.

Table 1.
Parameters and variables.
2.1. Domain Adaptation
In machine learning, domain adaptation (DA) is a subfield of transfer learning that focuses on the scenario where there is a significant difference between the data distribution of the training set (source domain) and the test set (target domain). The goal of domain adaptation is to adapt a model trained on the source domain so that it performs well on the target domain despite the differences in data distributions.
The source domain is the domain from which we have access to labeled data. Let denote the set of labeled data points from the source domain , where represents the -th data point, and is the corresponding label indicating the class to which belongs. The label belongs to a set of predefined class labels . The target domain is the domain to which we want to apply the learned model, but where we only have access to unlabeled data. Let denote the set of unlabeled data points from the target domain . Each data point belongs to one of the classes in , but its corresponding label is not observed during training. The source and target domains share a common set of class labels . This implies that, theoretically, the same classes exist in both domains, but the way these classes are represented (i.e., the data distribution) may differ. For instance, the source domain might consist of high-resolution images, while the target domain could consist of lower-resolution images or images taken under different lighting conditions. This distributional difference between the domains poses significant challenges for traditional machine learning models, which typically assume that the training and test data are drawn from the same distribution. To address this challenge, domain adaptation techniques often involve aligning the data distributions between the source and target domains by transforming the feature space or modifying the learning algorithm. One effective method for this is Maximum Mean Discrepancy (MMD), which minimizes the distance between the distributions of the source and target domains in a common latent space. By reducing this distribution shift, MMD helps improve the model’s generalization ability on the target domain, making it a crucial technique for successful domain adaptation.
2.2. RKHS, Kernels, and the Kernel Trick
A Reproducing Kernel Hilbert Space (RKHS) [31] is a powerful mathematical framework widely used in kernel-based learning algorithms. In an RKHS, every function can be represented as an inner product involving a kernel function , which serves as a measure of similarity between data points. Specifically, for any function in the RKHS and any point , the value of at can be represented as shown in Equation (1), where denotes the inner product in the RKHS, and is the kernel function centered at .
The kernel function implicitly maps data into a high-dimensional feature space, enabling the capture of complex relationships that may not be apparent in the original lower-dimensional space. A widely used kernel is the Gaussian (or RBF) kernel, defined as shown in Equation (2), where is a parameter that controls the width of the kernel. The Gaussian kernel measures the similarity between two points, and , based on their distance.
The kernel trick is a crucial technique that enables efficient computation in high-dimensional spaces without explicitly performing mapping. This trick leverages the kernel function to compute the inner product between two points in the feature space directly in the input space without needing to know the explicit form of the mapping . For example, let and be the mappings of data points and into the feature space. The inner product in and can be directly evaluated as shown in Equation (3), where is the kernel function. This means that the product of two elements in the high-dimensional feature space can be evaluated directly in the original input space using the kernel function, such as the Gaussian kernel given in Equation (2).
By utilizing the kernel trick, algorithms can efficiently handle nonlinear patterns in the data, making RKHS, kernels, and the kernel trick fundamental components of modern machine learning. This approach simplifies the learning process and reduces computational complexity, enabling operations that would typically require high-dimensional computations to be performed directly in the original input space.
2.3. Maximum Mean Discrepancy (MMD)
Assume that the random samples and come from two probability distributions and , respectively. The kernel mean embeddings for these distributions are given by and , where the function maps the samples into a Reproducing Kernel Hilbert Space (RKHS) . The Maximum Mean Discrepancy (MMD) [18] between and is defined as the difference between these means in the RKHS, as shown in Equation (4), where is the set of functions in the unit ball of the universal RKHS. By squaring the MMD, we can use the kernel trick to compute it directly on the samples with a kernel function without needing the explicit form of , as illustrated in Equation (5). The Gaussian kernel shown in Equation (2) is usually used as the kernel function. In practice, for samples and , the MMD formula can be adjusted to yield an unbiased estimate, as described in Equation (6).
2.4. The Mean Discrepancy with a Deep Kernel
While the Maximum Mean Discrepancy (MMD) defined in a Reproducing Kernel Hilbert Space (RKHS) is a powerful tool for measuring the mean difference between two samples, one of the significant challenges lies in the selection of the bandwidth for the Gaussian kernel used in the computation. The choice of is crucial as it directly impacts the sensitivity of the MMD to differences in distributions. However, there is no definitive method for optimally selecting this bandwidth, which can limit the effectiveness of the MMD in practice. To address the issue of bandwidth selection, Liu et al. [23] introduced the Maximum Mean Discrepancy with a Deep Kernel (MMDDK), as described in Equation (7). In this approach, represents a deep neural network that is employed to extract features from the input data. Within this learned feature space, an inner kernel is applied, typically a Gaussian function with bandwidth , as shown in Equation (8). Additionally, an inner kernel is applied directly in the input space, also using a Gaussian function but with bandwidth , as depicted in Equation (9).
The MMDDK framework innovatively combines these kernels by defining a composite kernel function that integrates both the feature space kernel and the input space kernel. The bandwidth parameters and , the weight , and the deep network parameters are all jointly optimized through a deep learning approach. This joint optimization allows for adaptive bandwidth selection and improved alignment between the source and target distributions.
The entire MMDDK framework is denoted by , where , encapsulating all the parameters involved in the model. The training process aims to maximize an objective function , as shown in Equation (10), which balances the MMD-based discrepancy measure and the variance , defined in Equation (11) and Equation (12), respectively. Here, refers to the alternative hypothesis in a two-sample test, , where is a regularization constant that ensures stability in the optimization process. The function , as defined in Equation (13), calculates the contribution of pairs of samples from both domains, integrating the kernel evaluations across different sample pairs to compute the overall discrepancy. This MMDDK approach addresses the limitations of traditional MMD by allowing for more flexible and adaptive kernel learning, improving the effectiveness of domain adaptation in scenarios where the optimal bandwidth is difficult to determine. The assumption of equal sample sizes in both domains (i.e., ) simplifies the computations and ensures that the statistical properties of the test remain robust.
2.5. Class-Wise Maximum Mean Discrepancy
In domain adaptation, the key challenge arises from the differences between the source and target domains in both marginal and conditional distributions. The marginal distribution captures the overall sample distribution within a domain, while the conditional distribution refers to the distribution of samples within specific classes. Although the Maximum Mean Discrepancy (MMD) is a powerful tool for measuring distributional differences, its common application focuses solely on aligning marginal distributions, often neglecting the alignment of samples with the same labels across domains. This can result in suboptimal performance, particularly when the conditional distributions between the source and target domains differ significantly. To address this issue, Long et al. [24] proposed Joint Distribution Adaptation (JDA), which extends the use of MMD to align both marginal and conditional distributions within a shared linear transformation space. JDA aims to generate feature representations that not only bridge the domain gap but are also robust to significant distributional differences.
In JDA, the source domain samples, , and the target domain samples, , are mapped onto a common feature space through a linear orthogonal transformation. Here, and denote the number of samples in the source and target domains, respectively, and is the dimension of the samples. The transformation matrix , which is of size, maps the original data points into a -dimensional feature space. The transformed data points for the source domain are given by , and similarly, for the target domain by . The primary objective of this transformation is to minimize the discrepancy between the means of the transformed samples from the source and target domains in this new feature space. The discrepancy is formalized in Equation (14), which represents the MMD they define, where the terms and represent the mean vectors of the transformed data points from the source and target domains, respectively. Their goal is to minimize the Euclidean distance between these two mean vectors, which effectively aligns the marginal distributions of the two domains in the new feature space. On the right side of Equation (14), the trace operation is used to express the squared Euclidean distance between the means in a matrix form; the matrix is the concatenated data matrix containing both the source and target samples, resulting in a matrix of size ; and the matrix , defined in Equation (15), is constructed to measure the pairwise relationships between samples in the source and target domains. The elements define how the relationship between pairs of samples is weighted during the optimization process. When both samples and belong to the source domain (), the element is assigned a positive weight . Similarly, when both samples belong to the target domain (), the weight is . These positive weights contribute to aligning the means of the samples within each domain. For pairs where one sample is from the source domain and the other from the target domain, is assigned a negative weight . These negative weights are crucial for minimizing the discrepancy between the source and target domain means by penalizing large differences between them. The matrix plays a pivotal role in the optimization objective by guiding the linear transformation to map the source and target samples into a common feature space where their distributions are aligned. The trace operation in Equation (14) sums the weighted differences across all pairs of samples, driving the minimization process towards the optimal alignment of both marginal and conditional distributions. The JDA method, through the use of the linear transformation matrix and the carefully constructed matrix , effectively addresses the limitations of traditional MMD by jointly aligning both marginal and conditional distributions. This joint alignment is crucial for improving the performance of domain adaptation tasks, particularly in scenarios where the source and target domains exhibit significant distributional differences. The mathematical framework provided by Equations (14) and (15) ensures that the adaptation process considers the complex relationships between the source and target domains, leading to more robust and generalizable models.
The challenge of matching conditional distributions (i.e., distributions conditioned on class labels) arises from the difficulty of doing so without labeled data in the target domain. To address this, Long et al. [24] proposed using pseudo labels for the target samples. These pseudo labels can be inferred by applying classifiers trained on the labeled source data to the unlabeled target data. This allows for the approximation of class-conditional distributions in the target domain, enabling the calculation of the discrepancy between class-conditional distributions in the source and target domains. To quantify this discrepancy, Long et al. introduced the Class-Wise Maximum Mean Discrepancy (CWMMD), which modifies the standard MMD to focus on class-conditional distributions. The formulation of CWMMD is given in Equation (16), where and represent the data samples belonging to the c-th class from the source and target domains, respectively; and are the numbers of samples in the c-th class for the source and target domains, respectively; and is a projection matrix that maps the data into a common subspace where the distributions are compared. The term on the left-hand side of Equation (16) represents the squared Euclidean distance between the class-conditional distributions of the source and target domains after projection by . The right-hand side expresses this same discrepancy in its matrix trace form, where denotes the combined source and target data and is a class-specific matrix that encodes the relationships between pairs of samples from the source and target domains within the same class, as defined in Equation (17).
To achieve effective transfer learning, Long et al. proposed the Joint Distribution Adaptation (JDA) framework, which combines the marginal MMD (addressed in Equation (14) with the class-conditional CWMMD addressed in Equation (16). The resulting optimization problem is shown in Equation (18), where combines the marginal and conditional discrepancies into a single objective, where corresponds to the marginal distribution, is a regularization term that controls the scale of the projection matrix , ensuring the problem is well posed and prevents overfitting, and the constraint restricts the total variation in the projected data to a fixed value, preserving important statistical information. Here, is a centering matrix that ensures the projected data are centered, with representing the total number of samples. This optimization problem is designed to find the optimal projection matrix that aligns both marginal and conditional distributions across domains, thereby enabling effective domain adaptation even when the target domain lacks labeled data.
2.6. Discriminative Class-Wise MMD Based on Euclidean Distance
The use of MMD aims to extract shared common features between the source and target domains by minimizing the mean difference for each pair of classes, even when their distributions are distinct. How is this achieved in practice? Wang et al. [25] provided valuable insights, illustrating that the principles of MMD closely mirror human transferable learning behaviors. Their approach treats each category as a distinct group, analyzing and adjusting the means of specific categories in both the source and target domains. For example, in the case of a specific class shared by the source and target domains, the category means are progressively aligned by minimizing the mean difference between the pairs, maximizing their intra-class distances. As the domain adaptation (DA) process progresses, the means of these classes from the two domains converge, reducing joint variance and improving feature alignment. This process reflects how humans naturally extract shared features from underlying semantics, capturing broad patterns while forgoing some finer details. The progressive alignment of category means exemplifies how MMD enhances feature generalization across domains, facilitating robust domain adaptation.
Wang et al. [25] presented Lemmas 1–3 as follows, where Lemmas 2 and 3 were both proven by them, and Lemma 1 follows the identity about the inter-class (or between-class) distance according to [32]:
Lemma 1.
The inter-class scatter is defined as the squared inter-class distance and can be expressed as
where , is the inter-class scatter matrix, is the number of data instances in the i-th category, represents the mean of data samples from the -th category, and represents the mean of the whole data samples. For brevity, we omit the proofs.
Lemma 2.
The squared inter-class distance equals to the data variance minus the squared intra-class distance:
where is the variance, is the squared intra-class (or within-class) distance, , and .
Lemma 3.
The following identity describes the Class-Wise Maximum Mean Discrepancy (CWMMD):
where
and
where denotes the number of data instances in the -th category from domain i (where i can be either source s or target t), and . Additionally, represents the mean of data in the -th category from domain , while denotes the mean of data in the -th category from both the source and target domains combined. The subscription st of signifies that both the source and target domains are considered together.
Notably, in this paper, we correct a statement proposed by Wang et al. The original statement, “The inter-class distance equals the data variance minus the intra-class distance”, should be revised to “The squared inter-class distance equals the data variance minus the squared intra-class distance”.
Let = be the squared inter-class distance in the transformed space based on transformation matrix for class between the source and target domains. Then, let so that Equation (18) can be written as Equation (25). According to the identity, , derived by Wang et al. [25], Equation (25) can be written as Equation (26), where is the squared intra-class distance between the source and target domains, and is their variance. Therefore, minimizing the squared inter-class distance is equivalent to maximizing the squared intra-class distance while simultaneously minimizing their variance , thereby reducing feature distinguishability. To propose a solution, a balance parameter is directly applied to the hidden squared intra-class distance in to regulate its variation, as shown in Equation (27).
2.7. Discriminative Class-Wise MMD Based on Gaussian Kernels
Wang et al. [25] extended the work of Long et al. [24] by introducing a discriminative Class-Wise MMD, which retains the use of linear transformations to project samples into the feature space and employs the Euclidean distance to measure the mean difference between the distributions of samples from two domains. However, linear transformations are generally less effective and efficient compared to nonlinear transformations, such as those applied in the Reproducing Kernel Hilbert Space (RKHS), where more complex patterns and relationships between domains can be captured.
In our previous research [28], we redefined the MMD proposed by Wang et al. by incorporating a Gaussian kernel within the RKHS framework, as RKHS based on the Gaussian kernel is universal [33]. This modification enables the MMD to be computed more efficiently and flexibly using the kernel trick, enhancing its applicability to a broader range of scenarios. Firstly, we redefined the squared inter-class distance , the squared intra-class distance , and the variance as ,, and , respectively, in Definitions 1 through 3. We then proved that under the Gaussian kernel MMD, the MMD representing the inter-class distance between the source and target domains can be decomposed into the intra-class distance and variance within the source and target domains.
Definition 1.
The squared inter-class distance between the source and target domains is defined as , where is the squared inter-class distance for class c between the source and target domains, as shown in Equation (28).
Definition 2.
The squared intra-class distance between the source and target domains is defined as , where is the squared intra-class distance for class c between the source and target domains, as shown in Equation (29).
Definition 3.
The variance between the source and target domains is defined as , where is the total variance for class c between the source and target domains, as shown in Equation (30).
Theorem 1.
.
Our previous work [28] established Theorem 1 and provided proof. Traditional MMD, without categorization, is the inter-class distance of samples from the two domains, referred to as marginal MMD, defined in Equation (31). Class-Wise MMD refers to the inter-class distance of samples from specific categories in the two domains, termed conditional MMD. For example, is the squared MMD or the squared inter-class distance for class c between the two domains and can be defined as . As a result, the loss function based on Class-Wise Maximum Mean Discrepancy is defined as the sum of and the squared inter-class distance and the squared marginal MMD, as shown in Equation (32), which can also be written as Equation (33) according to Theorem 1. To address the reduction in feature discriminability, we adopt the strategy proposed by Wang et al. [25], introducing a balance parameter to the hidden squared intra-class distance within the squared inter-class distance . This modification adjusts the loss function, resulting in , as shown in Equation (34).
3. The Proposed Method
The proposed unsupervised domain adaptation (UDA) approach primarily utilizes Discriminative Class-Wise Maximum Mean Discrepancy (MMD) to align the class-level data distributions of the source and target domains, which addresses the issue of reduced feature distinguishability when MMD minimizes the mean deviation between two different domains, thereby effectively achieving the goal of UDA. However, the MMD used here is learned with a meta-module MTMMD to obtain MMD with deep kernels (MMDDK). The framework of the proposed method is directly called MeTa Discriminative Class-Wise MMD (MCWMMD), as shown in Figure 1. The orange block represents the feature extractor F, which is responsible for extracting domain-invariant features. The green block represents the classifier C, which predicts class labels based on the extracted features. The light red block represents the meta-module MTMMD, referred to as “MMDDK”, which is designed to measure the distance between feature distributions of samples from the two domains.
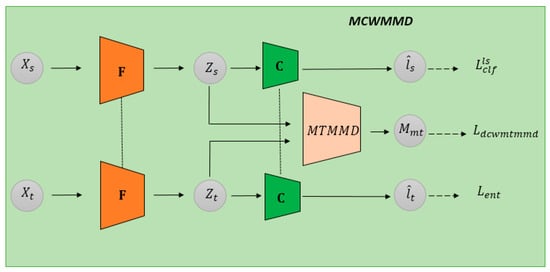
Figure 1.
Training framework for MCWMMD.
The training objective of the meta-module MTMMD is to enhance its ability to discriminate between the two domains. This is achieved by updating MMDDK to maximize the feature distance measurement values of samples from the two domains. Conversely, the training objective of the MCWMMD module is to update the feature extractor F so that the feature distance measurement values of samples from the two domains, computed using the current MTMMD, are minimized.
These opposing training objectives result in a process resembling adversarial training, where the two modules iteratively adjust to counteract each other. This alternating training process allows each module to improve its performance while balancing the influence of the other. The remainder of this section will introduce the detailed training processes of these two modules.
3.1. Deep Kernel Training Network
According to the Maximum Mean Discrepancy with Deep Kernels (MMDDK) defined by Liu et al. [23], as explained in Equation (7), we construct a training network for MMDDK, as depicted in Figure 2. The input to the training network for MMDDK is the feature vector extracted from the MCWMMD network, where two vectors, and (referred to as first-order features), are used to compute the Gaussian function value in Equation (9). Additionally, they are separately input into another feature extractor to obtain and (referred to as second-order features), which are used to compute the Gaussian function value in Equation (8). Subsequently, the two Gaussian function values and are combined using the operator defined in Equation (7) to calculate the deep kernel distance . The parameters ,, weight , and network parameters of the network are jointly trained using this deep neural network, denoted as , where . Its training is based on maximizing the objective function in Equation (10). The network training algorithm is presented in Algorithm 1.
| Algorithm 1 Training the MMDDK | |
| Input: ; Initialize ; repeat until convergence mini-batch from ; mini-batch from ; | |
| ; | #using (11) |
| ; | #using (12) with |
| / ; | #using (10) |
| #update parameters: | |
| ; | #maximizing J |
| end repeat | |
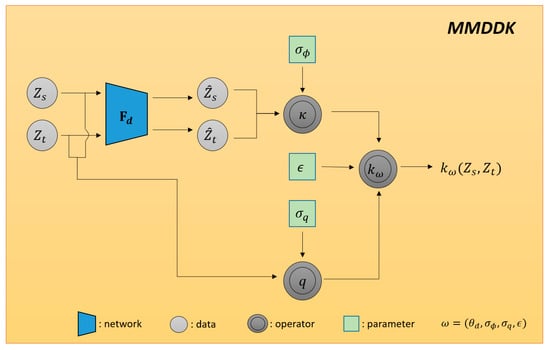
Figure 2.
Training framework for MMDDK.
3.2. Meta-Learning of Maximum Mean Discrepancy
In this section, we redefine and compute the Maximum Mean Discrepancy (MMD) originally defined and calculated by Wang et al. [25] in the context of linear transformation spaces, but now in the Reproducing Kernel Hilbert Space (RKHS) using the kernel trick for straightforward MMD computation. Consequently, we also redefine their definitions of between-class distance squared (), within-class distance squared (), and variance (), and demonstrate that under the Gaussian kernel-based MMD, the between-class distance-squared MMD between the source and target domains can be decomposed into the sum of within-class distance-squared MMDs from both domains and their variance difference.
As described in Section 2, minimizing the between-class distance squared is equivalent to maximizing the within-class distance squared for both the source and target domains while simultaneously minimizing their total variance , which leads to decreased feature discriminability. To address this issue, a balancing parameter () is applied to the hidden within-class distance squared within , proposing the discriminability class-level loss function defined in Equation (34), which can be rewritten as Equation (35).
For convenience, let us define . Hence, Equation (35) can also be rewritten as Equation (36), where the second term represents the sum of marginal MMD and conditional MMD, and the coefficient adjusts between 0 and 2, i.e., 0 .
Although we adopt the Discriminative Class-Wise Maximum Mean Discrepancy (DCWMMD), where MMD is computed based on a Gaussian function in a Reproducing Kernel Hilbert Space (RKHS), there is no reliable method to select the appropriate bandwidth value for the Gaussian function. Therefore, in this study, we choose the Maximum Mean Discrepancy with Deep Kernels (MMDDK) proposed by Liu et al. [23], where the bandwidth is learned by the network, endowing the MMDDK with stronger discriminative power. To further adapt the MMDDK to the mean discrepancy calculations for different domain pairs, we employ meta-learning to learn this MMDDK, resulting in a method called MeTa Maximum Mean Discrepancy (MTMMD), which is more suitable for efficient optimization using gradient descent [34,35].
Our proposed MTMMD network architecture, as shown in Figure 3, is based on concepts similar to previous meta-learning loss functions [36]. It parameterizes the Maximum Mean Discrepancy through a neural network , which receives the second-order features and predicted by the MMDDK model , along with bandwidths and and the weight . We aim to learn the parameters such that when is updated through , the final performance is optimal. The learning of parameters involves maximizing not only the original objective function but also the meta-learning objective function output by . The parameters and are alternately updated, as shown in Equations (37) and (38).
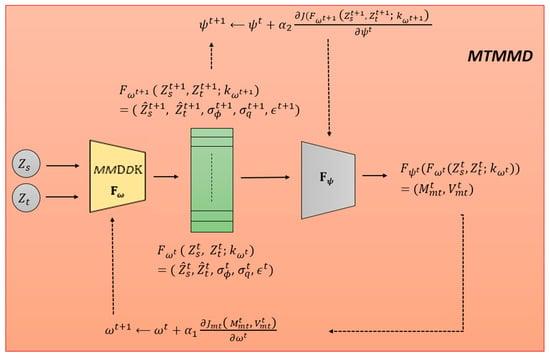
Figure 3.
MTMMD network training process.
The primary goal of both updates is to maximize the value of the mean discrepancy function; hence, we aim for both and to be maximized, with the parameter adjustments being positive multiples of the partial derivatives. The MTMMD network training architecture is illustrated in Figure 3. Since MMDDK and MTMMD are trained together, the gradient values of the MMDDK objective function are also used to update its parameters , modifying Equations (37)–(39). The MTMMD network training and inference algorithms are presented in Algorithms 2 and 3, respectively. Subsequently, the domain adaptation training uses the two-domain mean discrepancy loss function, where the in is replaced by the meta-learning in Equation (40), resulting in the loss function in Equation (41).
The MMDDK model passes its predictions to the meta-module MTMMD , which outputs , where is the mean discrepancy value and is the variance. We optimize to ensure that when optimizing the MMDDK model for with , the updated performs better (i.e., there is a higher value of the MMDDK objective function J). To achieve this, we take a gradient step on the meta-module’s objective function to update the MMDDK model parameters , and then we update by evaluating using the MMDDK objective function .
| Algorithm 2 Training MTMMD | |
| Input: ; Initialize and : sets of parameters for MMDDK Model and MTMDD Model , ; # ; for t 0 to T do mini-batch from ; mini-batch from ; ; # #alternatively update parameters ω and ψ: | |
| ; | #using (11) |
| ; | #using (12) with |
| #using (10) | |
| if t is even then | |
| ; ; | |
| ; | #maximizing |
| else | |
| ; | #maximizing J |
| end for | |
| Algorithm 3 MTMMD Inferencing |
| Input: and ; mini-batch from ; mini-batch from ; ; #; ; return |
3.3. MeTa Discriminative Class-Wise Maximum Mean Discrepancy
The proposed UDA approach, based on MeTa Discriminative Class-Wise Maximum Mean Discrepancy (MCWMMD), includes a feature extractor for extracting domain-invariant features for the classifier , as shown in Figure 1. Inputs and are fed into the feature extractor , resulting in outputs and . These outputs are then input into the classifier for classification predictions, producing and . In practice, the batch size for both the source domain and the target domain is set to , with a total of category labels. The feature extractor extracts features from input samples and , and outputs and , respectively. These features, and , are then input into the classifier for classification. In the diagram, and are depicted twice to correspond to the data paths of the source and target domains, with a dashed line in between to indicate shared parameters. The MTMMD network will be trained by minimizing the total loss function , as defined in Equation (42), where is defined in Equation (41) and is defined in Equation (44). It is a label-smoothed version of the classification cross-entropy in Equation (43), designed to encourage samples to fall into compact, uniform, and well-separated clusters. The original prediction is replaced by , where 1 is a vector of ones with dimensions, and is the smoothing parameter. Additionally, represents the predicted label entropy of the target sample, as shown in Equation (45). The network training algorithm for this MCWMMD module is presented in Algorithm 4.
| Algorithm 4 Training MCWMMD model | |
| Input: Initialize parameters and # train the model parameters and on and repeat until convergence mini-batch from mini-batch from ; F F #generate pseudo labels: | |
| ; | #classify target samples |
| #obtain pseudo labels | |
| # (()) ; | |
| # evaluate losses: | |
| ; | #using (41) |
| #using (44) | |
| ; | #using (45) |
| #using (42) | |
| # update andto minimize | |
| ; | |
| end repeat | |
4. Experimental Results
This section presents a comprehensive evaluation of the JDA approach on standard UDA datasets for image classification tasks. The details of the data preparation process are outlined in Section 4.1, while the experimental setup, including model configurations and parameters, is discussed in Section 4.2. Finally, Section 4.3 provides the experimental results and comparisons with baseline methods to demonstrate the effectiveness of the proposed approach.
4.1. Data Preparation
The proposed approach was evaluated on both digit and office object datasets. The digit datasets used in this study included the MNIST (Modified National Institute of Standards and Technology) database [37], USPS (U.S. Postal Service) [38], and SVHN (Street View House Numbers) [39]. The MNIST and USPS consist of grayscale images of handwritten digits, with the MNIST offering 60,000 training samples and 10,000 testing samples and USPS comprising 9298 images, divided into 7291 training and 2007 testing samples. In contrast, SVHN provides 73,257 color training images and 26,032 testing images, depicting digits captured in a street-view context. Figure 4 shows sample images from the MNIST, USPS, and SVHN, with training samples highlighted in blue.

Figure 4.
Digit data: (a) MNIST, (b) USPS, and (c) SVHN.
For the office object datasets, we used Office-31 [40] and Office-Home [41]. The Office-31 dataset consists of 4652 images within 31 categories collected from three distinct domains: Amazon (A), which contains images from online merchants; DSLR (D), with high-resolution images taken using a digital SLR camera; and Webcam (W), featuring low-resolution images captured using a web camera. This dataset covers 31 common office object categories, totaling 4110 images. The Office-Home dataset introduces a more complex domain shift, with four distinct domains—Art (Ar), Clipart (Cl), Product (Pr), and Real World (Rw)—spanning 65 object categories and approximately 15,500 images, each offering varied visual styles. Figure 5 and Figure 6 provide sample images from the Office-31 and Office-Home datasets, respectively.

Figure 5.
Office-31 data: (a) Webcam, (b) DSLR, and (c) Amazon.

Figure 6.
Office-Home data.
4.2. Experimental Setting
An initial learning rate of 0.001 was used for all experiments, decayed by a factor of 0.1 every 10 epochs. The batch size was set to 128 for the digit datasets and 64 for the office object datasets. The Adam optimizer was used with parameters β1= 0.99 and β2 = 0.999, and it was chosen for its ability to handle sparse gradients. Training lasted for 50 epochs on the digit datasets and 100 epochs on the office object datasets to ensure convergence. A regularization term of 0.0005 was applied to prevent overfitting. The Gaussian kernel used in the MMD calculations had an initial bandwidth of 1.0, dynamically optimized through the meta-learning framework. At the beginning of each epoch, pseudo-labels for all target domain training data were generated based on the current classifier parameters. This iterative process helped refine domain alignment while maintaining computational efficiency.
Experiments were conducted on a server equipped with NVIDIA RTX 2080 GPUs (manufactured by NVIDIA Corporation, Santa Clara, CA, USA) and 256 GB of system RAM (provided by ADATA, Taiwan). The implementation was carried out using Python with the PyTorch deep learning library (version 1.8), along with NumPy and SciPy for data preprocessing and statistical computations.
4.3. Results
ResNet-18 and ResNet-50 [42] were employed as the network architectures for feature extraction from the digit and office object datasets, respectively. Both models were fine-tuned using pre-trained ImageNet parameters. The performance of the proposed method was evaluated on the above-mentioned datasets: digit datasets, Office-31, and Office-Home. For the digit datasets, we tested domain adaptation between pairs such as MNIST to USPS (M → U), USPS to MNIST (U → M), and SVHN to MNIST (S → M). In the Office-31 dataset, we examined six domain adaptation pairs (e.g., Amazon to DSLR (A → D) and Webcam to DSLR (W → D)). For the Office-Home dataset, we created 12 domain adaptation pairs across four domains (Art, Clipart, Product, and Real-World), including examples like Art to Clipart (Ar → Cl), Product to Real-World (Pr → Rw), and so on.
Table 2 compares our method with several domain adaptation techniques on the digit datasets, including ADDA [5], ADR [43], CDAN [44], CyCADA [12], SWD [45], SHOT [46], and our previous work, DCWMMD [28]. Table 3 provides a comparison of the Office-31 dataset, including methods such as that by Wang et al. [25], DAN [6], DANN [4], ADDA, MADA [47], SHOT, CAN [3], MDGE [2], DACDM [9], CDCL [10], DMP [11], and DCWMMD [28]. Table 4 compares the results of the Office-Home dataset with methods like that used by Wang et al., DAN, DACDM [9], DMP [11], and DCWMMD. Please note that the results are directly referenced from published papers. The best-performing method for each source-to-target combination is highlighted in bold. The bold numbers in the tables indicate the best-performing accuracy for each source-to-target combination. The “Source-only” category represents a classifier trained solely on source data, while “Target-supervised” denotes a classifier trained and tested on target domain data, typically representing lower and upper bounds for domain adaptation performance.
Table 2.
Accuracies (%) of several approaches on some digit datasets.
Table 3.
Accuracies (%) for domain adaptation experiments on the Office-31 dataset.
Table 4.
Accuracies (%) for domain adaptation experiments on the Office-Home dataset.
In Table 2, our method achieves an average accuracy of 98.60% across digit datasets, outperforming other methods and closely approaching the target-supervised scenario. This highlights the robustness of our approach in aligning domain distributions and achieving class-wise alignment. Table 3 presents the results of the Office-31 dataset, where our method achieved an average accuracy of 91.62%, consistently outperforming other unsupervised adaptation methods and closely matching the target-supervised benchmark. This result underscores the effectiveness of our Class-Wise MMD optimization method in adapting complex, real-world data. In Table 4, our method achieves an average accuracy of 75.43% on the Office-Home dataset, a challenging multi-domain setting with diverse visual characteristics. These results highlight the adaptability and robustness of our approach as it generalizes effectively across multiple domains and significantly closes the gap with the target-supervised benchmark. This performance demonstrates our method’s capability to handle complex domain shifts while maintaining high accuracy across diverse visual domains.
t-SNE (t-distributed Stochastic Neighbor Embedding) [48] is a nonlinear dimensionality reduction technique commonly used to visualize high-dimensional data in a lower-dimensional space (typically 2D or 3D). By preserving local structures within the data, t-SNE excels in representing clusters and relationships, making it particularly useful for visualizing stochastic settings and complex data distributions. In this study, we employ t-SNE to visualize the feature representations learned by our model for both the source and target domains, highlighting the effectiveness of the proposed domain adaptation approach.
Columns (a) and (b) of Figure 7 depict the distributions of source features and target features, respectively, with different digits represented by distinct colors. Specifically, the 10 colors correspond to the digits 0 through 9, where each color uniquely represents a digit for clear differentiation in the visualization. Column (c) of Figure 7 provides an integrated view of both distributions to highlight their alignment. As observed, the source and target features are well aligned, demonstrating the effectiveness of our approach. The t-SNE visualization effectively highlights the alignment between source and target feature distributions, reflecting the improved feature alignment achieved by our method compared to the baseline.

Figure 7.
t-SNE visualization of three tasks on digit datasets: (a) source, (b) target, and (c) source (red color) + target (blue color) (best viewed in color).
5. Discussion and Conclusions
The proposed method, MeTa Discriminative Class-Wise MMD (MCWMMD), represents a significant advancement in unsupervised domain adaptation by integrating meta-learning with a Class-Wise Maximum Mean Discrepancy (MMD) approach. While traditional MMD methods align overall distributions between source and target domains, they often fail to achieve precise class-wise alignment, reducing feature distinguishability and generalization performance. MCWMMD addresses these limitations by introducing dynamic kernel adaptability and a focus on class-wise alignment, resulting in robust and domain-invariant representations.
A key innovation of MCWMMD is its dynamic kernel adaptability, achieved through a meta-module that adjusts kernel parameters based on class-specific features. This enables more precise domain alignment compared to traditional static kernels, significantly enhancing alignment and generalization. The alternating training process between the feature extractor and the meta-module, inspired by adversarial training, further refines the model’s ability to handle complex domain shifts. However, this adaptability introduces computational complexity, which could be a limitation for time-sensitive applications. Future research could explore simplifying the meta-module to reduce overhead while preserving adaptability.
The method’s class-wise alignment approach applies MMD in a class-specific manner, ensuring that each class is individually aligned between source and target domains. This produces compact, domain-invariant, and class-discriminative feature clusters, ultimately improving cross-domain classification performance. However, its reliance on accurate pseudo-labels for class-wise alignment may lead to errors when the pseudo-label quality is low. Developing robust pseudo-labeling strategies is a crucial direction for future research.
MCWMMD is also optimized for scalability through efficient batch processing and streamlined meta-module training, enabling practical application to large datasets without compromising alignment accuracy. However, scaling it extremely large or dynamically evolving datasets remains a challenge. Future work could investigate distributed or online learning paradigms to extend the method’s applicability to these scenarios.
Despite its strengths, MCWMMD involves complex meta-module training and adversarial-like processes, which may pose implementation challenges, particularly for practitioners with limited computational resources. Further validation in real-world scenarios with highly diverse and complex domain shifts is also needed. Promising future directions include simplifying the meta-module for enhanced accessibility, improving pseudo-labeling mechanisms, and extending the method to handle online and incremental domain adaptation for dynamic datasets. Additionally, exploring cross-domain generalization to unseen categories or settings could further enhance the method’s adaptability.
In summary, MCWMMD advances unsupervised domain adaptation by combining meta-learning with a Class-Wise MMD approach, addressing the limitations of traditional techniques. Its dynamic kernel adaptability and focus on class-wise alignment enable robust feature alignment and generalization. While challenges such as computational complexity and reliance on pseudo-labels remain, MCWMMD provides a strong foundation for future innovations, paving the way for more adaptable and generalizable deep learning models.
Author Contributions
Conceptualization, H.-W.L., C.-T.T. and H.-J.L.; Methodology, H.-W.L.; Software, T.-T.H. and C.-T.T.; Validation, H.-W.L. and C.-T.T.; Formal Analysis, H.-J.L.; Investigation, T.-T.H. and H.-W.L.; Resources, T.-T.H.; Data Curation, C.-H.Y.; Writing—Original Draft Preparation, H.-J.L.; Writing—Review and Editing, H.-W.L.; Visualization, C.-H.Y.; Supervision, H.-W.L.; Project Administration, H.-J.L.; Funding Acquisition, H.-J.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Science and Technology Council, Taiwan, R.O.C., under grant NSTC 113-2221-E-032-020.
Data Availability Statement
(1) SVHN dataset [39]: available online: https://www.openml.org/search?type=data&sort=runs&id=41081&status=active (accessed on 1 March 2024). (2) Office-31 dataset [40]: Introduced by Kate Saenko et al. in Adapting Visual Category Models to New Domain. (3) Office-Home dataset [41]. Available online: https://www.hemanthdv.org/officeHomeDataset.html (accessed on 1 March 2024). (4) t-SNE [48]: available online: http://www.jmlr.org/papers/v9/vandermaaten08a.html (accessed on 1 March 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lin, Y.; Chen, J.; Cao, Y.; Zhou, Y.; Zhang, L.; Tang, Y.Y.; Wang, S. Cross-domain recognition by identifying joint subspaces of source domain and target Domain. IEEE Trans. Cybern. 2017, 47, 1090–1101. [Google Scholar] [CrossRef]
- Khan, S.; Guo, Y.; Ye, Y.; Li, C.; Wu, Q. Mini-batch dynamic geometric embedding for unsupervised domain adaptation. Neural Process. Lett. 2023, 55, 2063–2080. [Google Scholar] [CrossRef]
- Zhang, W.; Ouyang, W.; Li, W.; Xu, D. Collaborative and adversarial network for unsupervised domain adaptation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2962–2971. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Learning transferable features with deep adaptation networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 97–105. [Google Scholar]
- Vettoruzzo, A.; Bouguelia, M.-R.; Rögnvaldsson, T.S. Meta-learning for efficient unsupervised domain adaptation. Neurocomputing 2024, 574, 127264. [Google Scholar] [CrossRef]
- Liu, X.; Yoo, C.; Xing, F.; Oh, H.; El Fakhri, G.; Kang, J.-W.; Woo, J. Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives. arXiv 2022, arXiv:2208.07422v1. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, S.; Jiang, W.; Zhang, Y.; Lu, J.; Kwok, J.T. Domain-Guided Conditional Diffusion Model for Unsupervised Domain Adaptation. arXiv 2023, arXiv:2309.14360v1. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Wu, Z.; Weng, Z.; Chen, J.; Qi, G.-J.; Jiang, Y.-G. Cross-Domain Contrastive Learning for Unsupervised Domain Adaptation. arXiv 2022, arXiv:2106.05528v2. [Google Scholar] [CrossRef]
- Luo, Y.-W.; Ren, C.-X.; Dai, D.-Q.; Yan, H. Unsupervised Domain Adaptation via Discriminative Manifold Propagation. IEEE Trans. Pattern Anal. Machine Intell. 2022, 44, 1653–1669. [Google Scholar] [CrossRef] [PubMed]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K. Cycada: Cycle-consistent adversarial domain adaptation. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1989–1998. [Google Scholar]
- Saito, K.; Watanabe, K.; Ushiku, Y.; Harada, T. Maximum Classifier Discrepancy for Unsupervised Domain Adaptation. arXiv 2018, arXiv:1712.02560v4. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster R-CNN for object detection in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3339–3348. [Google Scholar]
- Si, S.; Tao, D.; Geng, B. Bregman divergence based regularization for transfer subspace learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 929–942. [Google Scholar] [CrossRef]
- Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Wortman, J. Learning bounds for domain adaptation. In Proceedings of the Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 129–136. [Google Scholar]
- Ding, Z.; Fu, Y. Robust transfer metric learning for image classification. IEEE Trans. Image Process. 2017, 26, 660–670. [Google Scholar] [CrossRef]
- Gretton, A.; Borgwardt, K.; Rasch, M.; Sch, B.; Smola, A. A kernel two-sample test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain adaptation via transfer component analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Song, L.; Gretton, A.; Bickson, D.; Low, Y.; Guestrin, C. Kernel belief propagation. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 707–715. [Google Scholar]
- Park, M.; Jitkrittum, W.; Sejdinovic, D. K2-ABC: Approximate bayesian computation with kernel embeddings. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, Cadiz, Spain, 9–11 May 2016; pp. 398–407. [Google Scholar]
- Li, Y.; Swersky, K.; Zemel, R.S. Generative moment matching networks. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1718–1727. [Google Scholar]
- Liu, F.; Xu, W.; Lu, J.; Zhang, G.; Gretton, A.; Sutherland, D. Learning deep kernels for non-parametric two-sample tests. arXiv 2020, arXiv:2002.09116. [Google Scholar]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; IEEE Computer Society: Sydney, Australia, 2013; pp. 2200–2207. [Google Scholar]
- Wang, W.; Li, H.; Ding, Z.; Wang, Z. Rethink maximum mean discrepancy for domain adaptation. arXiv 2020, arXiv:2007.00689. [Google Scholar] [CrossRef]
- Devroye, L.; Lugosi, G. Combinatorial Methods in Density Estimation; Springer: New York, NY, USA, 2001. [Google Scholar] [CrossRef]
- Baraud, Y.; Birgé, L. Rho-estimators revisited: General theory and applications. Ann. Statist. 2018, 46, 3767–3804. [Google Scholar] [CrossRef]
- Lin, H.-W.; Tsai, Y.; Lin, H.J.; Yu, C.-H.; Liu, M.-H. Unsupervised domain adaptation deep network based on discriminative class-wise MMD. AIMS Math. 2024, 9, 6628–6647. [Google Scholar] [CrossRef]
- Andrychowicz, M.; Denil, M.; Colmenarejo, S.G.; Hoffman, M.W.; Pfau, D.; Schaul, T.; de Freitas, N. Learning to learn by gradient descent by gradient descent. arXiv 2016, arXiv:1606.04474v2. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Aronszajn, N. Theory of reproducing kernels. Trans. Am. Math. Soc. 1950, 68, 337–404. [Google Scholar] [CrossRef]
- Zheng, S.; Ding, C.; Nie, F.; Huang, H. Harmonic mean linear discriminant analysis. IEEE Trans. Knowl. Data Eng. 2019, 31, 1520–1531. [Google Scholar] [CrossRef]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.-P.; Sch, B.; Smola, A.J. Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics 2006, 22, e49–e57. [Google Scholar] [CrossRef]
- Gao, W.; Shao, M.; Shu, J.; Zhuang, X. Meta-BN Net for few-shot learning. Front. Comput. Sci. 2023, 17, 171302. [Google Scholar] [CrossRef]
- Bechtle, S.; Molchanov, A.; Chebotar, Y.; Grefenstette, E.; Righetti, L.; Sukhatme, G.; Meier, F. Meta-learning via learned loss. arXiv 2019, arXiv:1906.05374. [Google Scholar]
- Müller, R.; Kornblith, S.; Hinton, G. When does label smoothing help? In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hull, J.J. A database for handwritten text recognition research. IEEE Trans. Pattern Anal. Machine Intell. 1994, 16, 550–555. [Google Scholar] [CrossRef]
- SVHN Dataset. Available online: https://www.openml.org/search?type=data&sort=runs&id=41081&status=active (accessed on 1 March 2024).
- Saenko, K.; Kulis, B.; Fritz, M.; Darrell, T. Adapting visual category models to new domains. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6314, pp. 213–226. [Google Scholar] [CrossRef]
- Office-Home Dataset. Available online: https://www.hemanthdv.org/officeHomeDataset.html (accessed on 1 March 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Saito, K.; Ushiku, Y.; Harada, T.; Saenko, K. Adversarial dropout regularization. arXiv 2018, arXiv:1711.01575. [Google Scholar] [CrossRef]
- Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Conditional adversarial domain adaptation. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 1647–1657. [Google Scholar]
- Lee, C.Y.; Batra, T.; Baig, M.H.; Ulbricht, D. Sliced wasserstein discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10285–10295. [Google Scholar]
- Liang, J.; Hu, D.; Feng, J. Do we really need to access the source data? Source hypothesis transfer for unsupervised domain adaptation. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; Volume 119, pp. 6028–6039. [Google Scholar]
- Pei, Z.; Cao, Z.; Long, M.; Wang, J. Multi-adversarial domain adaptation. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. Available online: http://www.jmlr.org/papers/v9/vandermaaten08a.html (accessed on 1 March 2024).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).