
Stability Analysis of Batch Offline Action-Dependent Heuristic Dynamic Programming Using Deep Neural Networks


Abstract
1. Introduction
2. Problem Formulation
ADHDP Algorithm
3. Neural Network Implementation for BOADHDP
3.1. Action Value Function NN Approximation
3.2. Controller NN Approximation
3.3. Batch Offline ADHDP with Multiple-Hidden-Layer NN Algorithm
- Initialize , , , , . Initialize the NN architectures for and by setting , , and their respective weights. Let and .
- Collect transitions from system (1) and construct the database .
- At iteration , set and . Then, update the weights from all layers using (18) for . Finally, set .
- Set and . Then, update the weights from all layers using (26) for . Finally, set .
- If the condition is not met, update and go to Step 3. Else, stop the iterative algorithm.
4. UUB Convergence
4.1. Lyapunov Approach Description
4.2. Preliminary Results
4.3. Main Stability Analysis
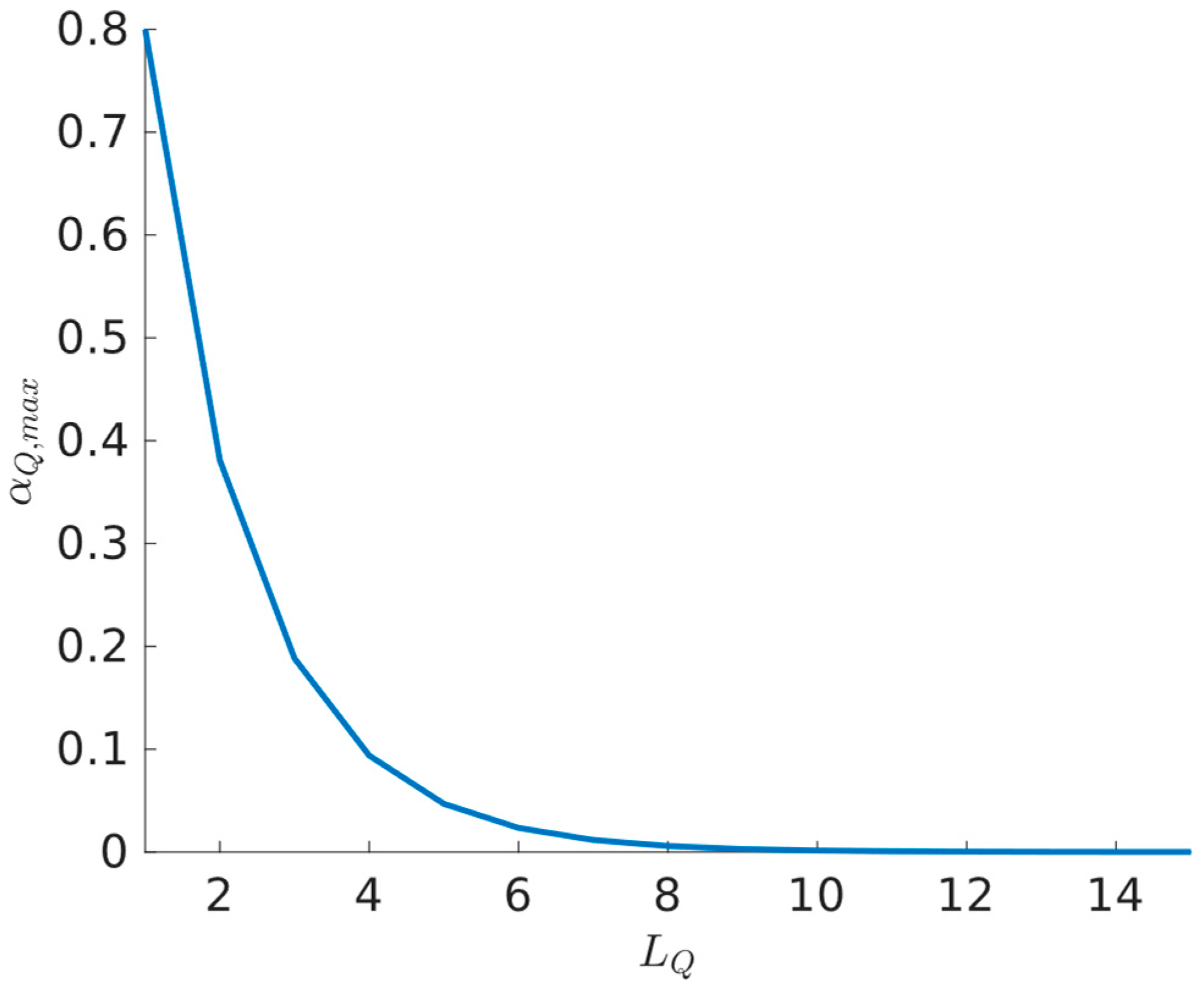
4.4. Results Interpretation
5. Simulation Study
5.1. Data Collection Settings on TRAS System
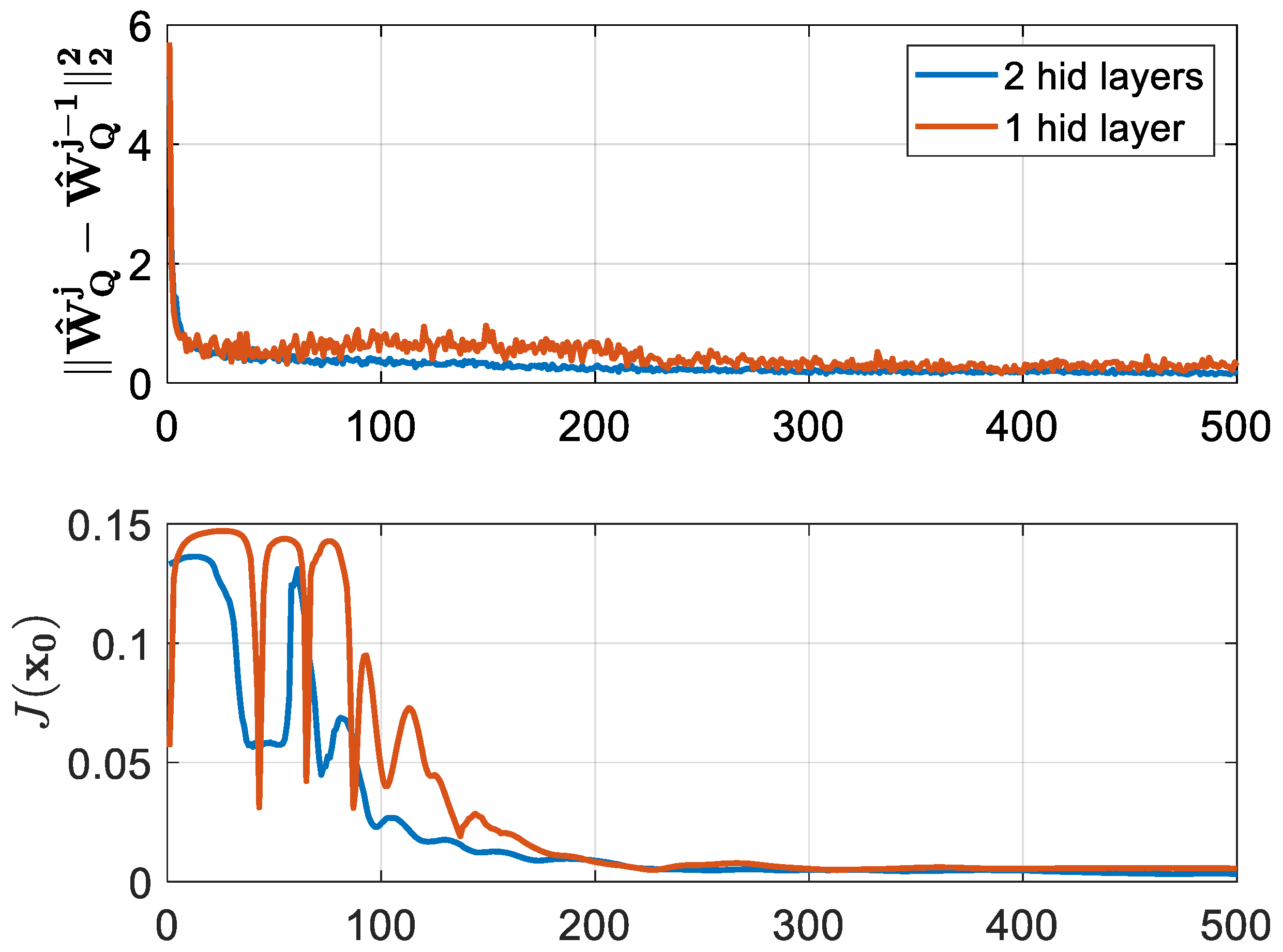
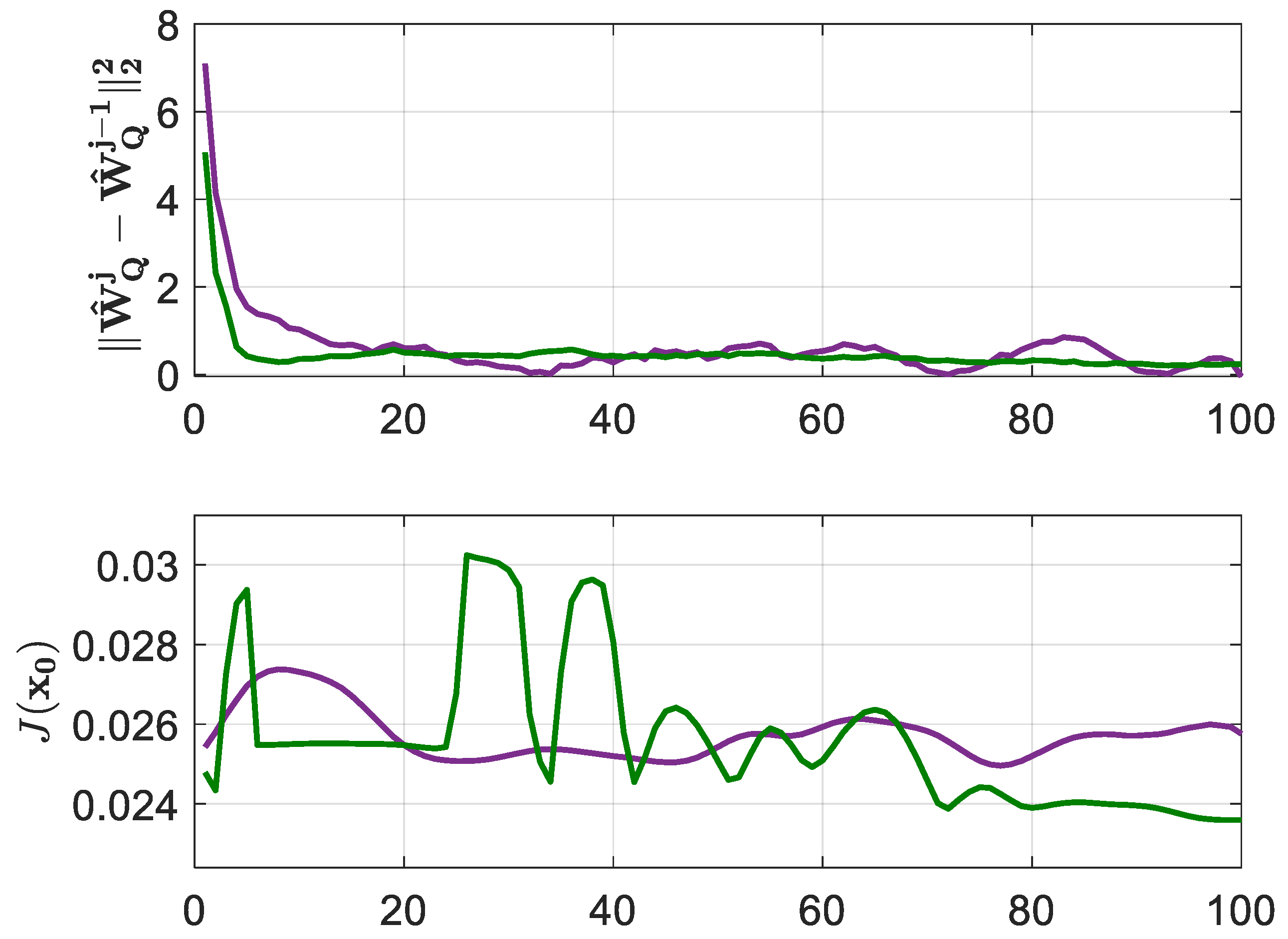
5.2. Comparison of BOADHDP with Single-Layer and Multilayer NN Approximations
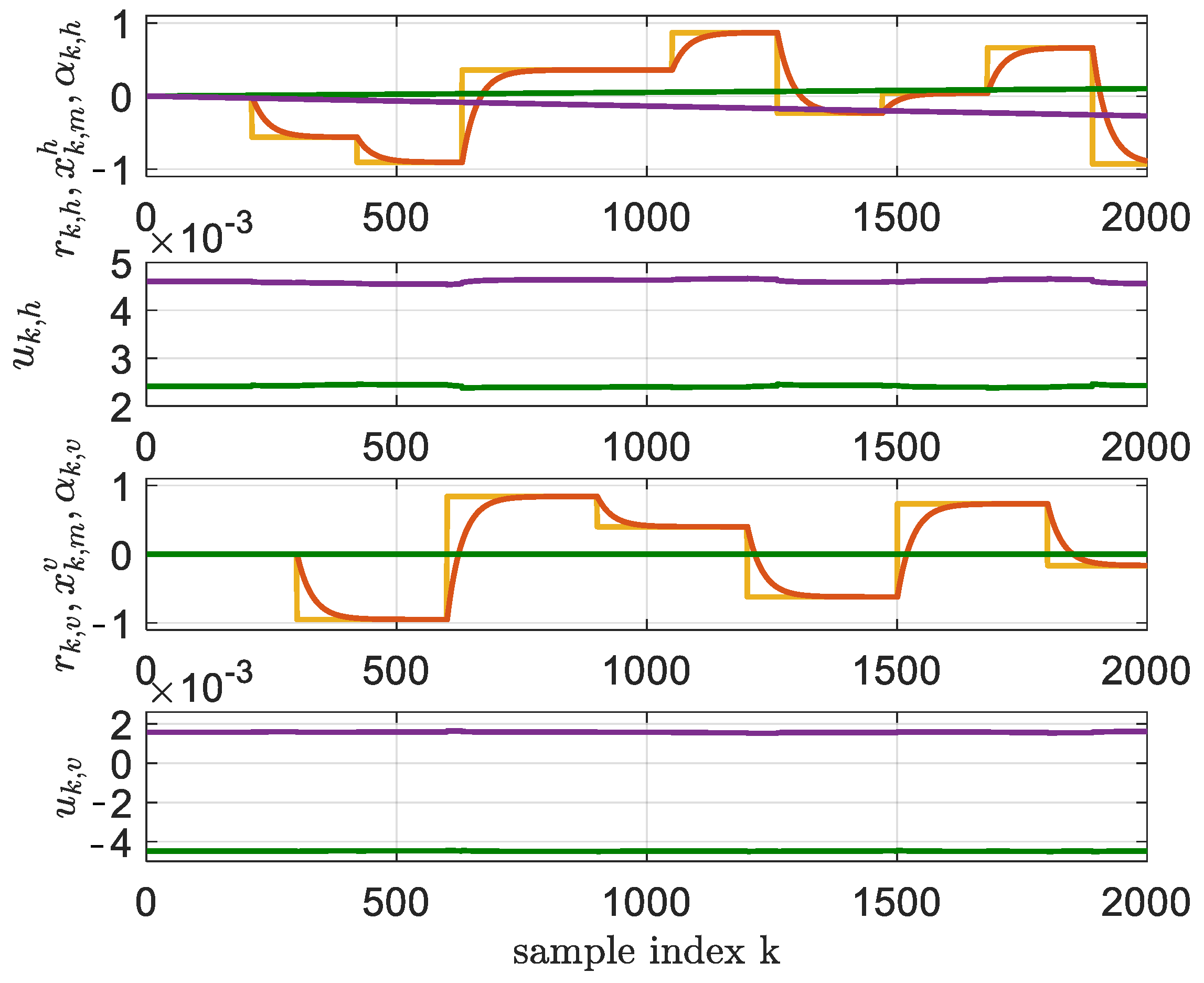
5.3. Comparison Between BOADHDP and the Online Adaptive ADHDP
6. Discussion and Conclusions
- First, our Lyapunov stability is extended to address NN approximators for action value functions and controllers with multiple hidden layers. Although NNs with a single hidden layer are universal approximators, their usage for highly nonlinear applications is hindered by their generalization capabilities. In contrast, multilayer NNs can learn complex features effectively, reducing overfitting and generalization issues. The results outlined in Theorem 1 indicate also an indirect proportionality between the number of NN hidden layers and the magnitude of the learning rate, providing a practical heuristic approach for practical ADP applications of multilayer NNs.
- Second, our theoretical Lyapunov stability analysis addresses the usage of batch offline learning of the action value function and controller NNs. Although successful ADP applications have been reported using adaptive update methods, their practical use is often constrained by the significant number of iterations required for convergence. The adoption of batch learning has, thus, become standard practice, necessitating a theoretical Lyapunov stability coverage.
- Finally, from a practical point of view, we validate the advantage of using BOADHDP with multilayer NNs through a case study on a twin rotor aerodynamical system (TRAS). This study compares BOADHDP using neural networks with a single layer and two hidden layers as function approximators. The results show that the normed action value function weight convergence is smoother with two-hidden-layer networks, also leading to a controller with an enhanced performance on the control benchmark ( for the single-layer NNs and for the two-layer implementation, namely a improvement). This demonstrates the superior capability of multilayer networks in managing complex, nonlinear control systems. Also, BOADHDP is compared with ADHDP algorithms from [21,22], with ADHDP algorithms from [21,22] obtaining and , respectively, on the control benchmark, while also requiring four times more collected transitions from the TRAS system. This proves both the efficiency of the BOADHDP with respect to the number of collected transitions and the performance of using batch offline learning methodologies, confirming the results from [28].
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Werbos, P.J. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Science. Ph.D. Thesis, Committee on Applied Mathematics, Harvard University, Cambridge, MA, USA, 1974. [Google Scholar]
- Bellman, R.E. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Werbos, P.J. Approximate dynamic programming for real time control and neural modeling. In Handbook of Intelligent Control: Neural, Fuzzy, and Adaptive Approaches; White, D.A., Sofge, D.A., Eds.; Van Nostrand Reinhold: New York, NY, USA, 1992; pp. 493–525. [Google Scholar]
- Al-Tamimi, A.; Lewis, F.L. Discrete-time nonlinear HJB solution using approximate dynamic programming: Convergence proof. IEEE Trans. Syst. Man Cybern. B 2008, 38, 943–949. [Google Scholar] [CrossRef] [PubMed]
- Prokhorov, D.V.; Wunsch, D.C. Adaptive critic designs. IEEE Trans. Neural Netw. 1997, 8, 997–1007. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Balakrishnan, S.N. Convergence analysis of adaptive critic based optimal control. In Proceedings of the American Control Conference, Chicago, IL, USA, 28–30 June 2000. [Google Scholar]
- White, D.A.; Sofge, D.A. Handbook of Intelligent Control: Neural, Fuzzy, and Adaptive Approaches; Van Nostrand Reinhold: New York, NY, USA, 1992. [Google Scholar]
- Padhi, R.; Unnikrishnan, N.; Wang, X.; Balakrishnan, S.N. A single network adaptive critic (SNAC) architecture for optimal control synthesis for a class of nonlinear systems. Neural Netw. 2006, 19, 1648–1660. [Google Scholar] [CrossRef] [PubMed]
- Balakrishnan, S.N.; Biega, V. Adaptive-critic-based neural networks for aircraft optimal control. J. Guid. Control Dyn. 1996, 19, 893–898. [Google Scholar] [CrossRef]
- Dierks, T.; Jagannathan, S. Online optimal control of affine nonlinear discrete-time systems with unknown internal dynamics by using time-based policy update. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1118–1129. [Google Scholar] [CrossRef] [PubMed]
- Venayagamoorthy, G.K.; Harley, R.G.; Wunsch, D.C. Comparison of heuristic dynamic programming and dual heuristic programming adaptive critics for neurocontrol of a turbogenerator. IEEE Trans. Neural Netw. 2002, 13, 764–773. [Google Scholar] [CrossRef] [PubMed]
- Ferrari, S.; Stengel, R.F. Online adaptive critic flight control. J. Guid. Control Dyn. 2004, 27, 777–786. [Google Scholar] [CrossRef]
- Ding, J.; Jagannathan, S. An online nonlinear optimal controller synthesis for aircraft with model uncertainties. In Proceedings of the AIAA Guidance, Navigation and Control Conference, Toronto, ON, Canada, 2–5 August 2010. [Google Scholar]
- Vrabie, D.; Pastravanu, O.; Lewis, F.; Abu-Khalaf, M. Adaptive optimal control for continuous-time linear systems based on policy iteration. Automatica 2009, 45, 477–484. [Google Scholar] [CrossRef]
- Dierks, T.; Jagannathan, S. Optimal control of affine nonlinear continuous-time systems. In Proceedings of the American Control Conference, Baltimore, MA, USA, 30 June–2 July 2010. [Google Scholar]
- Vamvoudakis, K.; Lewis, F. Online actor-critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica 2010, 46, 878–888. [Google Scholar] [CrossRef]
- Enns, R.; Si, J. Helicopter trimming and tracking control using direct neural dynamic programming. IEEE Trans. Neural Netw. 2003, 14, 929–939. [Google Scholar] [CrossRef]
- Liu, D.; Javaherian, H.; Kovalenko, O.; Huang, T. Adaptive critic learning techniques for engine torque and air–fuel ratio control. IEEE Trans. Syst. Man Cybern. B 2008, 38, 988–993. [Google Scholar]
- Ruelens, F.; Claessens, B.J.; Quaiyum, S.; De Schutter, B.; Babuška, R.; Belmans, R. Reinforcement learning applied to an electric water heater: From theory to practice. IEEE Trans. Smart Grid 2018, 9, 3792–3800. [Google Scholar] [CrossRef]
- He, P.; Jagannathan, S. Reinforcement learning-based output feedback control of nonlinear systems with input constraints. IEEE Trans. Syst. Man Cybern. B 2005, 35, 150–154. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Sun, J.; Si, J.; Guo, W.; Mei, S. A boundness result for the direct heuristic dynamic programming. Neural Netw. 2012, 32, 229–235. [Google Scholar] [CrossRef] [PubMed]
- Sokolov, Y.; Kozma, R.; Werbos, L.D.; Werbos, P.J. Complete stability analysis of a heuristic approximate dynamic programming control design. Automatica 2015, 59, 9–18. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Lillicrap, T.; Hunt, J.; Pritzel, A.; Heess, N.; Erez, Y.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the Internation Conference on Machine Learning, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Riedmiller, M. Neural Fitted Q Iteration–First Experiences with a Data Efficient Neural Reinforcement Learning Method. In Proceedings of the European Conference on Machine Learning, Porto, Portugal, 3–7 October 2005. [Google Scholar]
- Radac, M.-B.; Lala, T. Learning output reference model tracking for higher-order nonlinear systems with unknown dynamics. Algorithms 2019, 12, 121. [Google Scholar] [CrossRef]
- Watkins, C. Learning from Delayed Rewards. Ph.D. Thesis, Department of Computational Science, University of Cambridge, Cambridge, UK, 1989. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lala, T. Stability Analysis of Batch Offline Action-Dependent Heuristic Dynamic Programming Using Deep Neural Networks. Mathematics 2025, 13, 206. https://doi.org/10.3390/math13020206
Lala T. Stability Analysis of Batch Offline Action-Dependent Heuristic Dynamic Programming Using Deep Neural Networks. Mathematics. 2025; 13(2):206. https://doi.org/10.3390/math13020206
Chicago/Turabian StyleLala, Timotei. 2025. "Stability Analysis of Batch Offline Action-Dependent Heuristic Dynamic Programming Using Deep Neural Networks" Mathematics 13, no. 2: 206. https://doi.org/10.3390/math13020206
APA StyleLala, T. (2025). Stability Analysis of Batch Offline Action-Dependent Heuristic Dynamic Programming Using Deep Neural Networks. Mathematics, 13(2), 206. https://doi.org/10.3390/math13020206