Abstract
In this paper, the theoretical stability of batch offline action-dependent heuristic dynamic programming (BOADHDP) is analyzed for deep neural network (NN) approximators for both the action value function and controller which are iteratively improved using collected experiences from the environment. Our findings extend previous research on the stability of online adaptive ADHDP learning with single-hidden-layer NNs by addressing the case of deep neural networks with an arbitrary number of hidden layers, updated offline using batched gradient descend updates. Specifically, our work shows that the learning process of the action value function and controller under BOADHDP is uniformly ultimately bounded (UUB), contingent on certain conditions related to NN learning rates. The developed theory demonstrates an inverse relationship between the number of hidden layers and the learning rate magnitude. We present a practical implementation involving a twin rotor aerodynamical system to emphasize the impact difference between the usage of single-hidden-layer and multiple-hidden-layer NN architectures in BOADHDP learning settings. The validation case study shows that BOADHDP with multiple hidden layer NN architecture implementation obtains on the control benchmark, while the single-hidden-layer NN architectures obtain , outperforming the former by 1.58% by using the same collected dataset and learning conditions. Also, BOADHDP is compared with online adaptive ADHDP, proving the superiority of the former over the latter, both in terms of controller performance and data efficiency.
Keywords:
ADP; ADHDP; deep neural networks; batch learning; Lyapunov stability; uniformly ultimately bounded; gradient descent; Q-function; action value function MSC:
68T05
1. Introduction
Adaptive dynamic programming (ADP) has emerged as a powerful methodology for tuning control systems in modern applications, where complexity, nonlinearity, and uncertainty are commonplace. Originating from Werbos’ pioneering work [1], which was based on the seminal work on dynamic programming conducted by Bellman [2], ADP soon became a notable stream of research, with multiple ADP designs developed. Among the ADP designs, two distinct classes of solutions have emerged: heuristic dynamic programming (HDP) and dual heuristic programming (DHP) [3]. In the HDP framework, reinforcement learning is employed to determine the cost-to-go from the current state. The HDP convergence for the general nonlinear systems is presented in [4]. Conversely, in DHP, neural networks are used to learn the derivative of the cost function relative to the states, known as the costate vector [5]. The DHP convergence for linear systems was established in [6]. For both of those two classes of algorithms, there exists the action-dependent (AD) adaptation [7]. ADP has also addressed the class of discrete-time control problems [8,9,10,11,12,13] and continuous time systems [14,15,16].
Apart from the theoretical contributions, ADP designs have been validated on a wide array of real applications. In [17], ADP is applied to a helicopter tracking and trimming control task. In [18], neural network controllers tuned with the ADHDP method are applied to an engine torque and exhaust air–fuel ratio control for an automotive engine. A practical implementation in the context of an electric water heater is presented in [19], where the collected sensor data were used to learn in a model-free manner the Q-function and the controller.
Convergence and stability proofs of the iterative processes involved in ADP-like techniques have also been developed. In [6], the adaptive critic method is described, where two networks approximate the controller and the Lagrangian multipliers associated with the optimal control, respectively. The convergence of the interleaved successive update of the two networks has been analyzed. In [20], an online generalized ADP is issued for a system with input constraints. Then, using a Lyapunov approach, a uniformly ultimate boundedness (UUB) stability is proved. The convergence of the value-iteration HDP is established for the nonlinear discrete-time systems in [4]. In paper [21], the authors derive the UUB stability for direct HDP algorithms, proving that the actor and critic weights remain bounded. The actor and critic were approximated by a multilayer perceptron (MLP) with three layers: input, hidden, and output. However, the updated weights were only the ones from the hidden and output layers, like in a linear basis function approach. To overcome the practical limitations imposed by linear basis-function-type approximators, such as scalability and overfitting, the authors from paper [22] extended the stability analysis from [21] to MLPs to update both the input-to-hidden-layer weights and the hidden-to-output weights.
Current research in the field of reinforcement learning (RL), which studies the class of stochastic systems and controllers, shows significant performances when using deep NNs for control applications for both discretized systems [23] and continuous control tasks [24]. The advantage of deep neural networks over single-layer networks lies in their increased approximation capacity, which is achieved through multiple hidden layers. These layers enable the composition of features at different abstraction levels, creating a robust hierarchical representation. This hierarchical structure allows deep networks to learn and model complex nonlinear relationships within data more effectively than shallow networks. Thus, using multilayer NNs in ADP applications can enhance learning convergence and the overall controller performance. Also, using batch learning methods, which update the NN weights using collected past experiences simultaneously, is more data efficient compared to the single-transition learning, where the weights are updated one transition at a time. This also breaks the temporal correlations, helping NNs better generalize across a system’s state space. Typically, batch learning is combined with offline learning, where the weights are updated exclusively using a fixed dataset of transitions, without any adaptation during the controller’s runtime. Methods such as those in [19,24,25,26] demonstrate the benefits of using batch learning through a technique known as experience replay. In contrast, ref. [27] highlights an approach where the entire dataset of collected transitions is used for learning, in an offline manner.
This paper makes two key contributions. First, we provide a novel theoretical stability of ADHDP when utilizing deep neural networks as function approximators for both the action value function and the controller and for when batch learning is issued on the entire dataset of collected transitions from the system. This stands as an improvement over the stability analyses performed in [21,22], which were based on single-hidden-layer NN architectures updated online, with each transition collected during the system runtime. To this end, we prove that the batched offline ADHDP (BOADHDP) learning process is uniformly ultimately bounded (UUB) by using the Lyapunov stability approach. We show that the stability of the learning process is dependent on some conditions imposed on the NN learning rates and that these conditions also provide a relationship between the learning rate magnitudes and the number of hidden layers in the networks. Second, we issue a validation study on a twin rotor aerodynamical system (TRAS) to emphasize the superiority of employing multiple hidden layers in the NN approximators in the BOADHDP learning process. We also issue some comparison between BOADHDP and the online adaptive ADHDP algorithms from [21,22].
The rest of the paper is organized as follows. Section 2 describes the theoretical underpinnings of BOADHDP. Section 3 presents the multilayer neural network approximation of the action value function and controller. Section 4 provides the main theoretical results for the stability of BOADHDP. Section 5 illustrates the TRAS validation case study. Finally, the discussion and concluding remarks are presented in Section 6.
2. Problem Formulation
Let the discrete-time nonlinear system described by the state equation be
where denotes the time index, the system state, the control input, the unknown continuously differentiable system function, and and the compact subsets of and , respectively. The control input is generated by , with a time-invariant, continuous state feedback controller function with respect to the state . For convention, vectors with are column vectors, while the ones without the transposition are row vectors.
For the optimal control problem, the objective is to find the optimal controller that minimizes the infinite value function, defined as follows:
where function , having , is known as the penalty function, defined as , where is the penalty term describing the system’s desired behavior as a positive semidefinite function, and is a square positive definite command weighting matrix, as in [4]. The optimal value function [1] is defined as
The optimal controller is found by applying the argmin() operator to Equation (3), as
With the system function unknown, one cannot apply the well-known ADP methods for the system (1) directly in order to arrive at (3) and (4). Therefore, the introduction of action value functions is mandatory to handle the model-free case.
The action value function proposed by [28] evaluates both the current state and the command. It is defined as
Compared to the value function (2), the action value function represents the cost of issuing a command in a state , plus the value function of the next state . Mainly, Equation (5) evaluates all possible actions followed by the controller . Equation (5) can also be written, according to [28], as
From [28], similarly to the value function (3), the optimal action value function is defined as
and the optimal controller is represented by
ADHDP Algorithm
Arriving at the optimal action value function and controller requires an iterative procedure consisting of steps, where the action value function and controller are continuously updated, according to [28]. Starting with an initial controller and an action value function, e.g., , the action value function evaluation is issued by
Then, the controller is updated using
At the iteration, the action value function update is
while the controller update law is
The iteration scheme consisting of the repetitive application of Equations (11) and (12) runs as .
Remark 1.
A policy iteration algorithm requires an initially known stabilizing controller , whereas, for value iteration schemes, this need is avoided.
In the next section, the implementation of the controller and action value function update is issued using a neural network function approximation for and .
3. Neural Network Implementation for BOADHDP
The recurrent ADP scheme described by Equations (11) and (12) is practically implemented using function approximators for the action value function and controller. To this end, neural networks (NNs) are used, due to their universal function approximation property, which is able to handle multidimensional nonlinear systems (1). The tuning of the NN weights from each individual layer requires both input–output training data and the employment of the backpropagation mechanism, which can be best described as a gradient-based update rule.
The training data for the controller and action value function are collected from the controlled system (1) and take the form of transition tuples stored in a dataset , with . The main objective of the data collection phase is to uniformly sample the state space , sufficiently exploring the systems’ dynamics.
The action value function and controller NN weight tuning algorithm, using a gradient descent, is described in Section 3.1 and Section 3.2. The weight gradient update uses the entirety of the collected transitions from , compared to the methods from [21,22] which use only one transition per gradient update. This method is called batch optimization, and its utilization is a common practice for the application of RL and ADP applied to complex nonlinear systems.
For the batch learning implementation, the action value function and controller update is made simultaneously for the entire dataset . Therefore, let , of size , and of size be vectors that lump all states and commands collected in the dataset . Also, let be the matrix of the concatenation of the states and command matrices converted into a matrix resembling the action value function input.
Stating and as the action value function and controller functions, respectively, approximated by NNs, and with and representing the entirety of the action value function and controller weights, respectively, the gradient descend update is next detailed.
3.1. Action Value Function NN Approximation
The action value function NN has the scope of approximating (11). Having as inputs the state and , the state action function NN is described as
where
and is the total number of layers, is the ideal hidden-layer weight matrix from the iteration j and layer , and is the number of neurons from layer . The size of is . Here, represents the activation function and can take any form, such as , , , and so on. The vector is the layer activation output. For the first layer, we have .
Generally, weights , for are generally unknown due to the existing approximation errors in the weight update backpropagation rule. Hence, working with the real action value function is not realistic, but only with some approximations of it. Noting with the entirety of the action value function weights, the output of the approximate action value function NN has the form of
where
and where represents an estimation of the ideal weights for . To update the action value function NN weights, an internal gradient update loop is issued for the steps, having the weights initialized with . At each iteration , the following optimization problem needs to be solved,
where
and
having .
Here, represents the prediction error in the form of a TD error. The state action function weights are updated by the rule
where is the action value function NN learning rate and
The sign corresponds to the Hadamard product. Then, the weights of are actualized as .
3.2. Controller NN Approximation
The controller NN has the scope of approximating . Noting with the entirety of the controller weights, and having as input the state , the output is computed as
where
and where represents an estimation of the iteration j of the ideal weights for the layers. Noting with the estimation of the ideal weights, the output of the controller NN is
with
and where represents an estimation of the real weights. To update the controller weights, one needs to issue an internal gradient update loop for the steps, having the weights initialized with . At each iteration , the following optimization problem needs to be minimized for the entirety of the collected dataset, as follows,
where
and
where represents the controller NN learning rate.
The update of each individual weights is
where
To issue the update (28), it is necessary to compute the gradient of the action value function with respect to the controller output. This is computed as
where and are the identity matrix, of dimensions , and , a matrix of zeros. Then, the weights of are actualized as .
3.3. Batch Offline ADHDP with Multiple-Hidden-Layer NN Algorithm
Next, the BOADHDP algorithm using multiple-hidden-layer NN function approximators is detailed. The algorithm consists of consecutive steps where the action value and controller NNs are updated.
- Initialize , , , , . Initialize the NN architectures for and by setting , , and their respective weights. Let and .
- Collect transitions from system (1) and construct the database .
- At iteration , set and . Then, update the weights from all layers using (18) for . Finally, set .
- Set and . Then, update the weights from all layers using (26) for . Finally, set .
- If the condition is not met, update and go to Step 3. Else, stop the iterative algorithm.
4. UUB Convergence
In this section, the convergence of the NN weights to a fixed point is examined. By using a Lyapunov function, the stability of the weight evolution to the fixed point is proved to be UUB under some specific conditions.
4.1. Lyapunov Approach Description
Each iteration of the BOADHDP algorithm consists of a total cumulated number of gradient steps for both action value function and controller. Let a new iteration index be defined as , namely , which represents a fine-grained iteration over both gradient action value function and controller. During , only the action value function neural network weights are updated using (18), while remains unchanged. On the other side, for , only the controller weights are updated using (26), while the action value function weights remain unchanged. To simplify the notation, we substitute and with and , respectively.
Let and represent the optimal weights of the action value function NN and the controller NN, and let the weight estimation errors between the approximation of the real weights and the optimal ones be , .
Therefore, the difference between the estimated weights and the optimal ones at each layer of both the action value function and the controller NN at each iteration is, according to (18) and (26),
Then, based on (14), (18), (22), and (29), define the following dynamical system with the nonlinear difference equation system, where represents a nonlinear function,
Definition 1.
The equilibrium point of a system (32) is said to be uniformly ultimately bounded (UUB) with bound if, for any and , there exists a positive number independent of , such that for all when .
4.2. Preliminary Results
In the following, the UUB property of the system (32) is demonstrated for the update rules (18) and (26), both of which make the weights of the two approximating NNs enter a region with the center in the optimal weights and . Some fundamental assumptions are next introduced.
Assumption 1.
The optimal NN weights for the action value function and the controller and the activation function are bounded by positive constants, i.e., , , .
Lemma 1.
Under Assumption 1, it is implied that the first difference of is given by
Proof.
Let be described as
Using (19), (20), and (30), we get
Based on this, we have
□
Lemma 2.
Under Assumption 1, it is implied that the first difference of , for is given by
Proof.
For any , with , we have
Based on (19), (20), and (30), we get
with . Based on (38) and (39), one gets
□
Lemma 3.
Under Assumption 1, it is implied that the first difference of is given by
Proof.
Let be described as
Based on (27), (28), and (31), let
Therefore,
□
Lemma 4.
Under Assumption 1, it is implied that the first difference of , for , is given by
Proof.
For any , with , we have
Based on (27), (28), and (31), we get
with . Based on (46) and (47), one gets
□
4.3. Main Stability Analysis
This section provides the main stability theory for the error estimation of system (32).
Theorem 1.
Running BOADHDP algorithm from Section 3.3, which iteratively updates and using (18) and (26), the action value function and controller weights converge to their optimal weights and , respectively, such that and if
Proof.
According to (18) and (26), we have, for each layer of action value function and controller NN,
Let the Lyapunov function candidate be defined for each weight matrix according to each action value function and controller NN layer and be described as
The joint action value function and controller Lyapunov function is
Let the difference of the Lyapunov candidates be
and the joint Lyapunov differences be .
Next, the proof is divided in two parts: one proving that , if inequality (49) is respected, and one proving that , if inequality (50) is respected.
(a) Let , according to Lemma 1, and , for all layers based on Lemma 2.
The sum , , is lower than 0 if
For the terms corresponding to layer from (58), we have
Also, is written as
Based on the TD error definition (17), we can write . Then, (59) is described as
Also, (60) is described as
For the terms corresponding to all layers from (58), we have
Also, the term is described as
With , based on (20), we get, for all NN layers from ,
Based on the normed Hadamard product property , with and being matrices of the same size, (65) is described as
Therefore, based on (61)–(64), the inequality (58) is written as
Let the following norm bounds be defined as follows:
Then, based on Assumption 1, the inequality (67) can be written as
To guarantee that (68) is negative, the learning rate needs to be selected as follows:
(b) Let , according to Lemma 3, and for all layers based on Lemma 4.
The sum , , is lower than 0 if
For the terms corresponding to layer from (70), we have
Also, is described as
For the terms corresponding to all layers from (70), we have
Also, the term is described as
Having , can be written similarly to (65), as
Based on the normed Hadamard product property, one gets
Therefore, based on (71)–(74), the inequality (70) is
Let the following norm bounds be defined as follows:
Based on Assumption 1, the inequality (77) can be written as
To guarantee that (78) is negative, the learning rate needs to be selected as follows:
In conclusion, by having the inequalities (69) and (79) respected, we get □
4.4. Results Interpretation
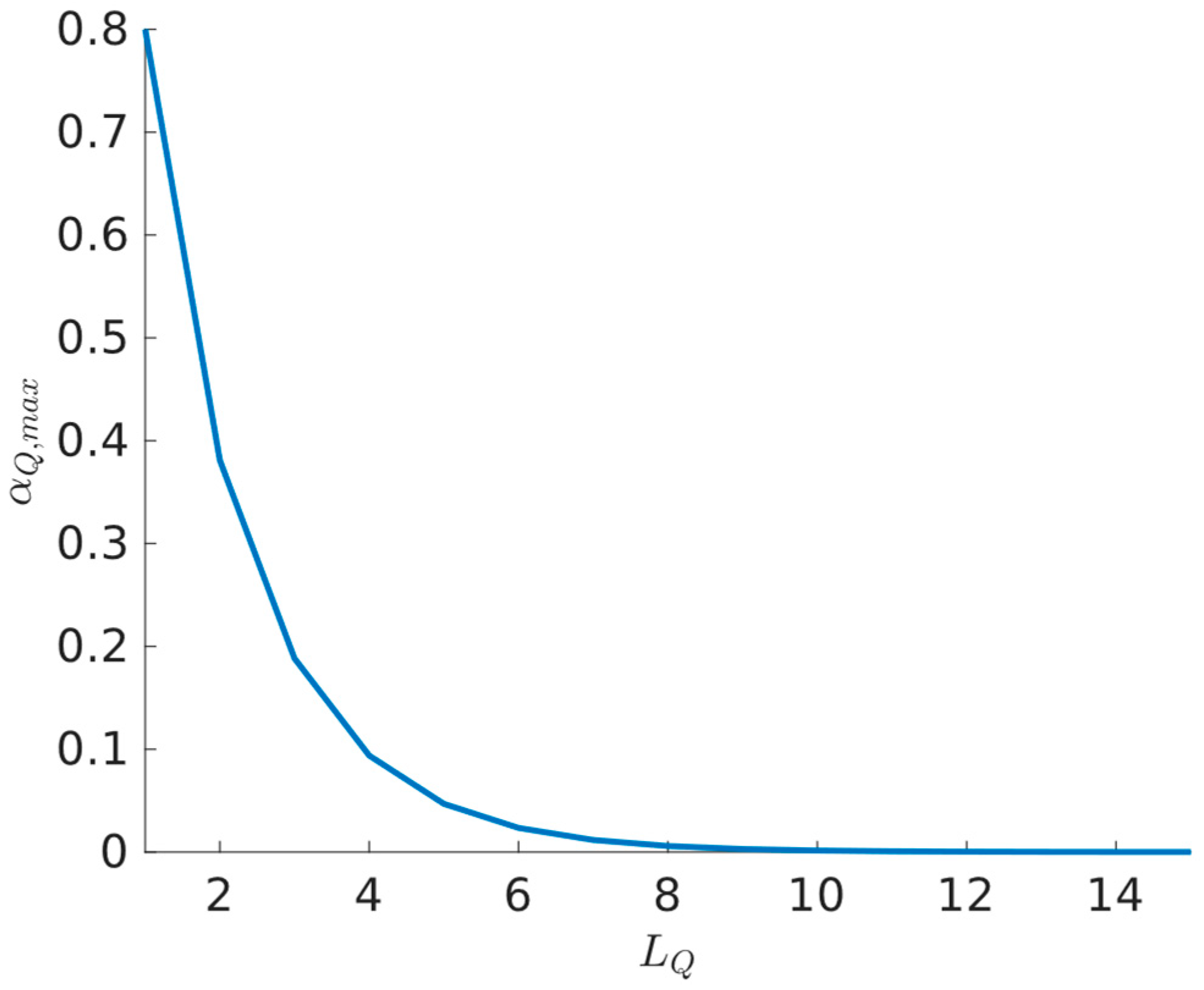
According to (69) and (79), as the number of hidden layers increases, the upper bounds for the learning rates and decrease. This is due to the denominators in (69) and (79) being larger than their respective numerators, primarily because the denominators include squared terms. Therefore, the number of hidden layers in both neural networks is inversely proportional to the magnitude of their respective learning rates. For illustrative purposes, the action value function learning rate bound was plotted along the hidden layers in Figure 1, based on (69). The norm bounds of the weights were selected as and for the activation function .
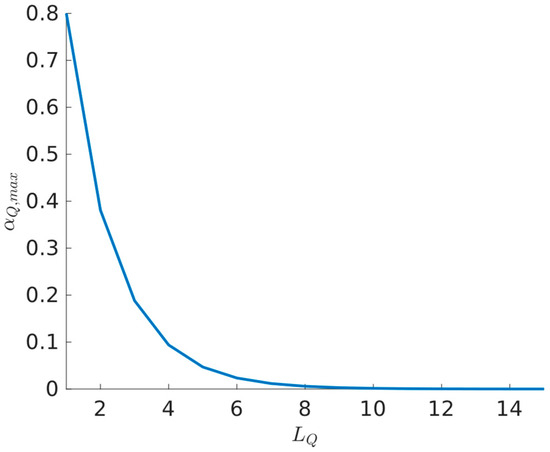
Figure 1.
Relation between the number of NN layers and the bound of the learning rate .
Remark 2.
This inversely proportional relationship between the number of NN hidden layers and the learning rate can be attributed to the gain in complexity of the NN optimization surface as the number of hidden layer increases. A high learning rate in such a scenario can lead to erratic updates in the intricate optimization surface, potentially causing the divergence of the learning process. While a smaller learning rate increases the risk of getting stuck in local minima, it is beneficial for a stable learning.
5. Simulation Study
Next, the impact of employing multiple hidden layers in the NN approximators, batch learning, and offline computation in the ADHDP learning process, namely the BOADHDP algorithm from Section 3.3, was tested on an ORM tracking task on the TRAS system. First, the system is described along with the data collection settings for BOADHDP. This is followed by a comparison between the BOADHDP learning process using single-hidden-layer NNs and the one using two-hidden-layer NNs for approximating the action value function and the controller. Finally, the online adaptive ADHDHP algorithms from [21,22] are compared with BOADHDP, highlighting the advantages of the latter.
5.1. Data Collection Settings on TRAS System
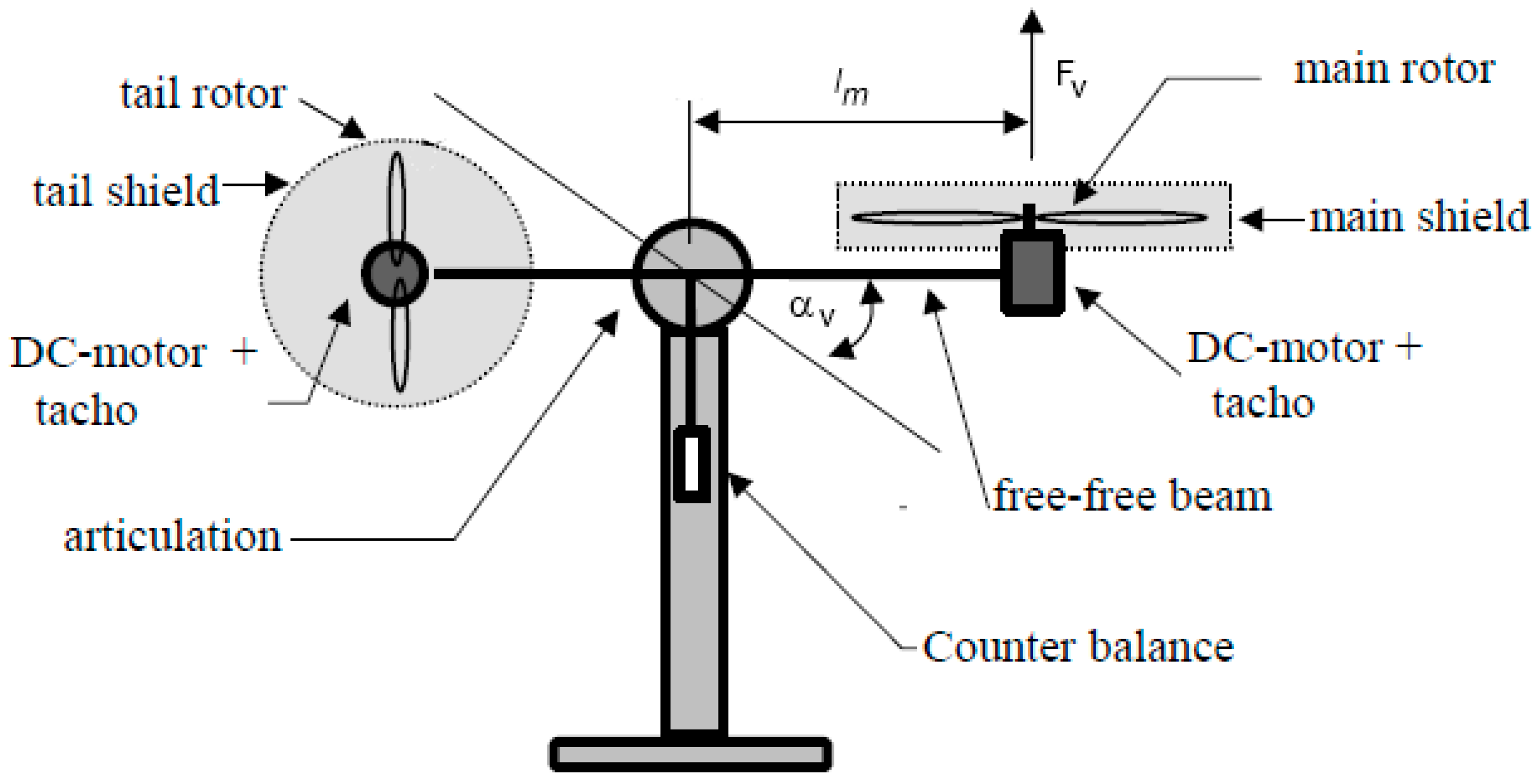
The nonlinear system was characterized as a two-input and two-output system. The horizontal motion, or azimuth, operates as an integrator, whereas the vertical, or pitch, motion experiences different gravitational effects when moving upward versus downward. There was also an interconnection between these two channels. In Figure 2, a system setup is shown. The model used was a simplified deterministic continuous-time state-space representation, consisting of two interconnected state-space subsystems:
where is the saturation function in the interval . The horizontal azimuth control input was and the vertical pitch control was . The system output was represented by the azimuth angle and by the pitch angle . Nonlinear static characteristics were derived from experimental data through polynomial fitting as in [29]:
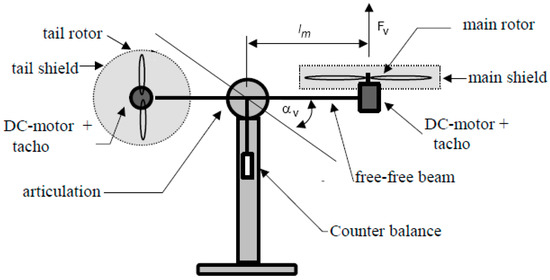
Figure 2.
TRAS system setup [29].
The process was discretized by using a zero-order hold sampler on both inputs and outputs. With a sampling time of , the following discrete-time model was obtained,
where the system state was and the control input was , as in [29].
In the ORM tracking paradigm, the controlled system outputs track the output of the ORM model. In this application, the ORM was defined as in [29] and had the form of
where and are step input reference signals. Therefore, an extended state that comprises both the TRAS and the ORM states was defined as .
For data collection, the linear diagonal controller
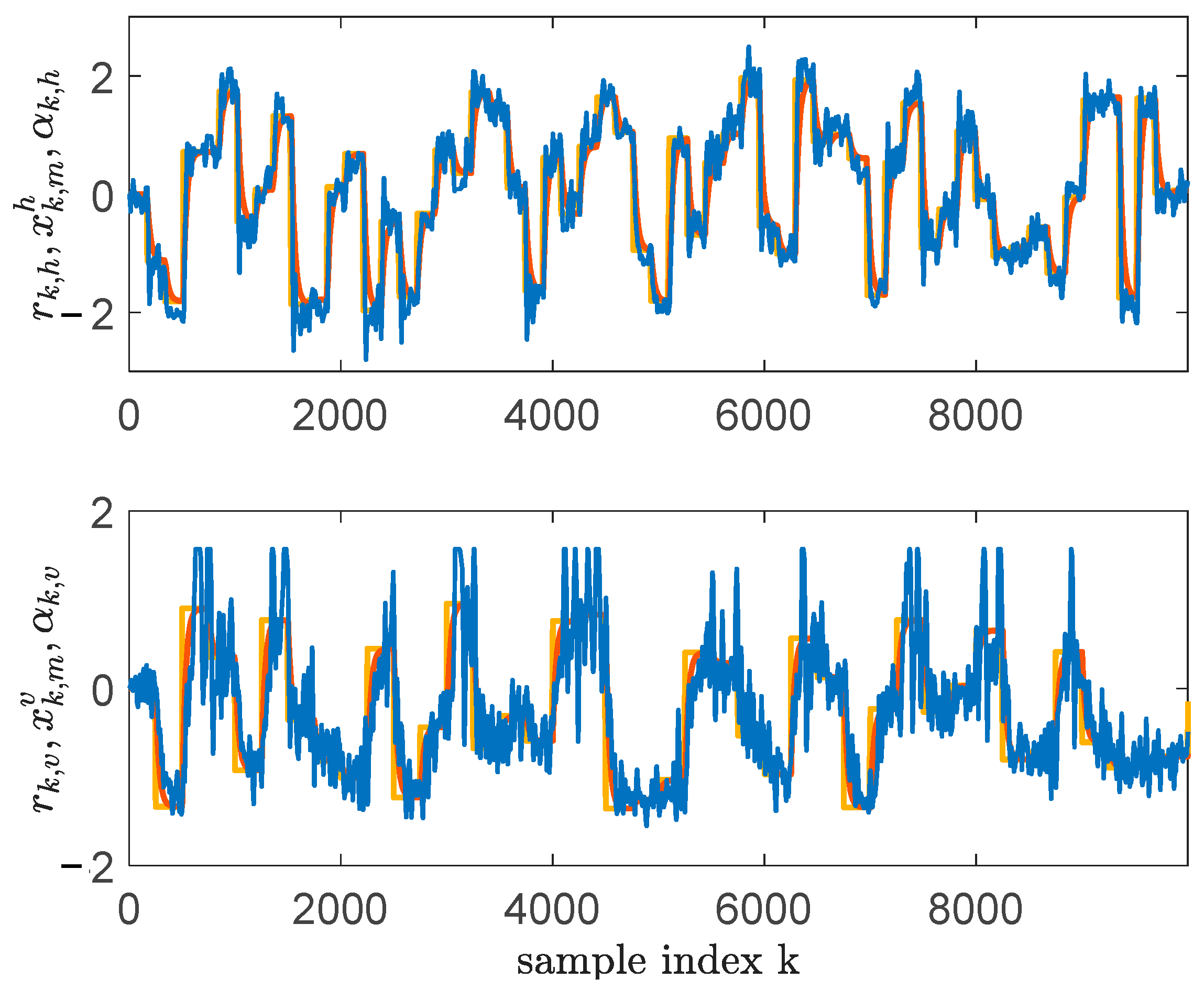
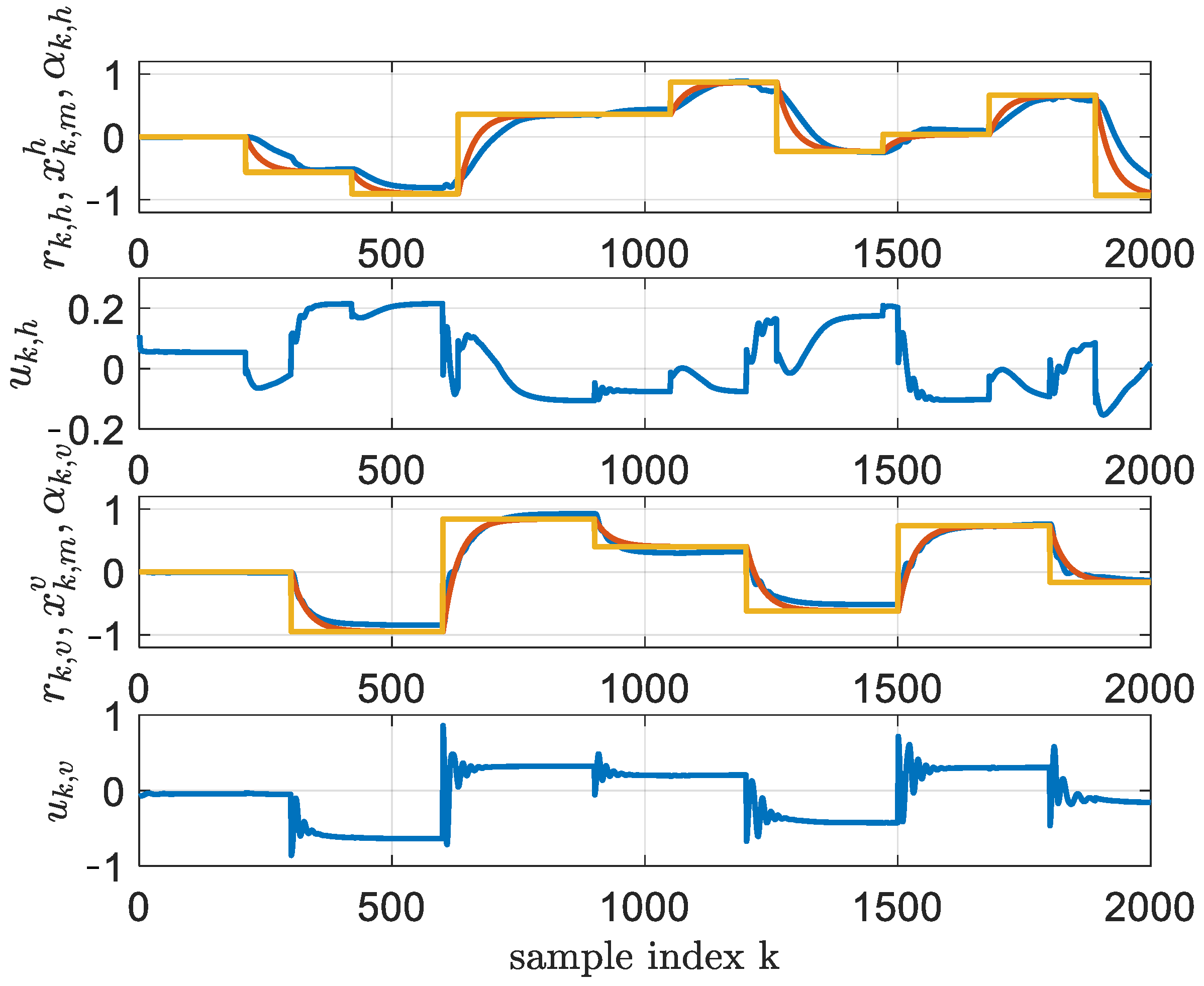
was used in a closed loop with system (85), where the controller parameters were tuned using VRFT as in [29]. Having the closed loop stabilized, the successive step referenced input signals with amplitudes ranging in an interval of , and were generated at s and s for the azimuth and pitch respectively. To guarantee a satisfactory exploration of the system’s state-space domain, a random noise was added at each two timesteps. The random noise added on had an amplitude of and the one added on had an amplitude of . A total of transitions were collected, creating, therefore, the dataset , with . An excerpt of the data exploration is shown in Figure 3. Next, BOADHDP was issued for action value function and controller NN approximations for both the single-hidden-layer (, ) and the multilayer case (, ).
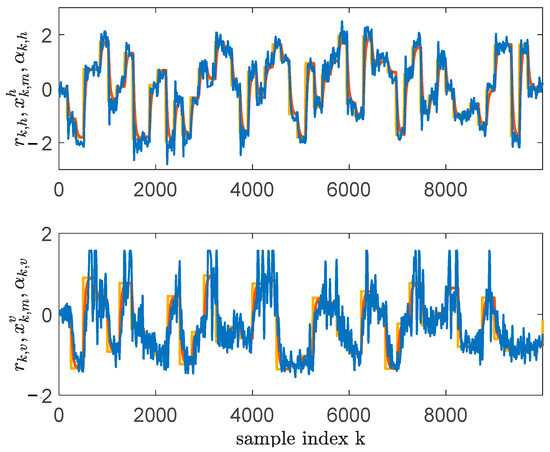
Figure 3.
Data collection in relation to the TRAS system: and (yellow); and (red); and (blue).
5.2. Comparison of BOADHDP with Single-Layer and Multilayer NN Approximations
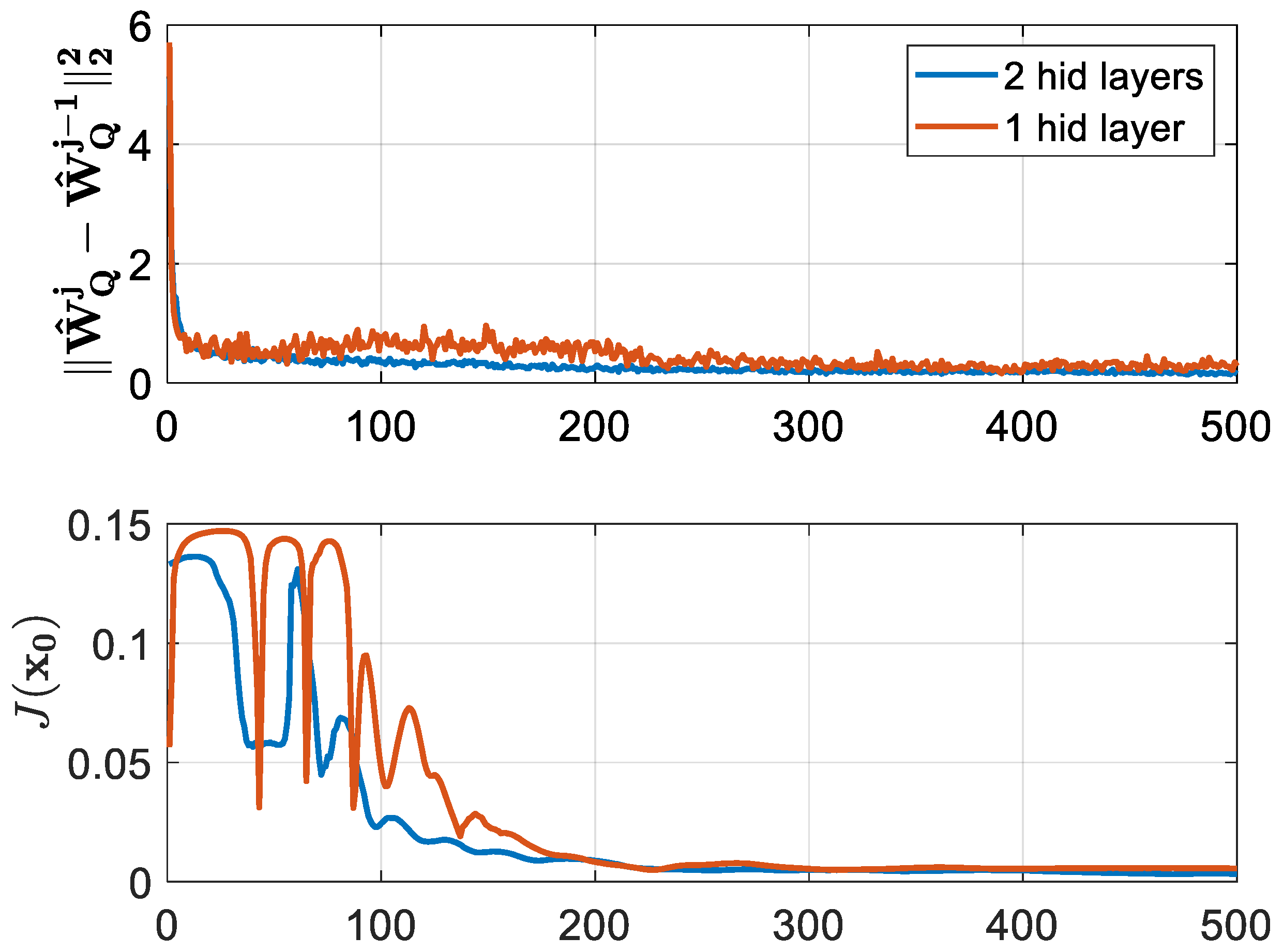
For the single-layer NNs, the form of the action value function was 12-50-1 and that of the controller was 10-10-2. The activation functions of the hidden layer were hyperbolic tangents and the ones of the output layer were linear. The weights were initialized using the Xavier initialization [29]. The internal gradient updates were and and the learning rates were selected to be and . The penalty function took the form of . The algorithm ran for a total number of 500 iterations. The performance of the NN controller was tested on a simulated scenario. In this scenario, the tracking capabilities were tested on a random reference signal generated from for 2000 timesteps. Therefore, at each BOADHDP iteration, the performance of the controller was measured by the function on the simulated scenario, for . The convergence of the action value function and the values of is shown in Figure 4 in an orange color. This was computed by checking the norm between the weights from successive BOADHDP iterations, namely the norm . The decreasing behavior of the successive weight norms from the first plot in Figure 4 proves the convergence of the action value function. The second plot presents the performance of the value function under the simulated scenario for the controller obtained from each iteration , namely . The tracking performance of the controller obtained at iteration is shown in Figure 5. In this figure, the performance of the TRAS system (85) in a closed loop with the controller is shown. The evolution in time of the output of the horizontal and the vertical axes is plotted in a blue color along with the reference signal (yellow) and reference model (orange), showing the tracking capacity of the controller.
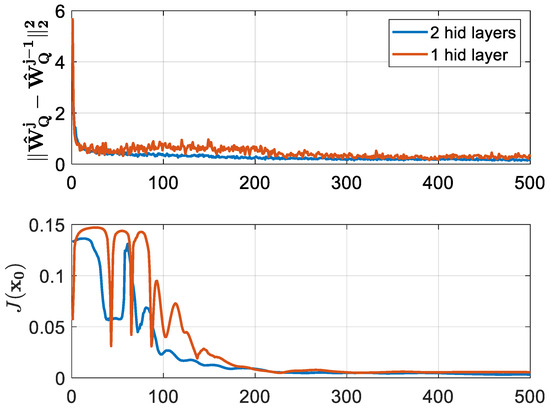
Figure 4.
BOADHDP convergence in the TRAS system.
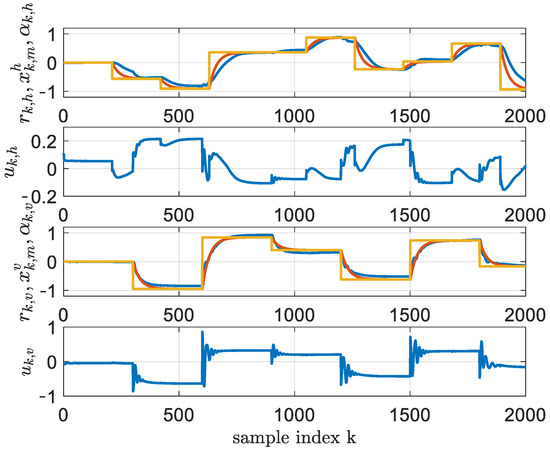
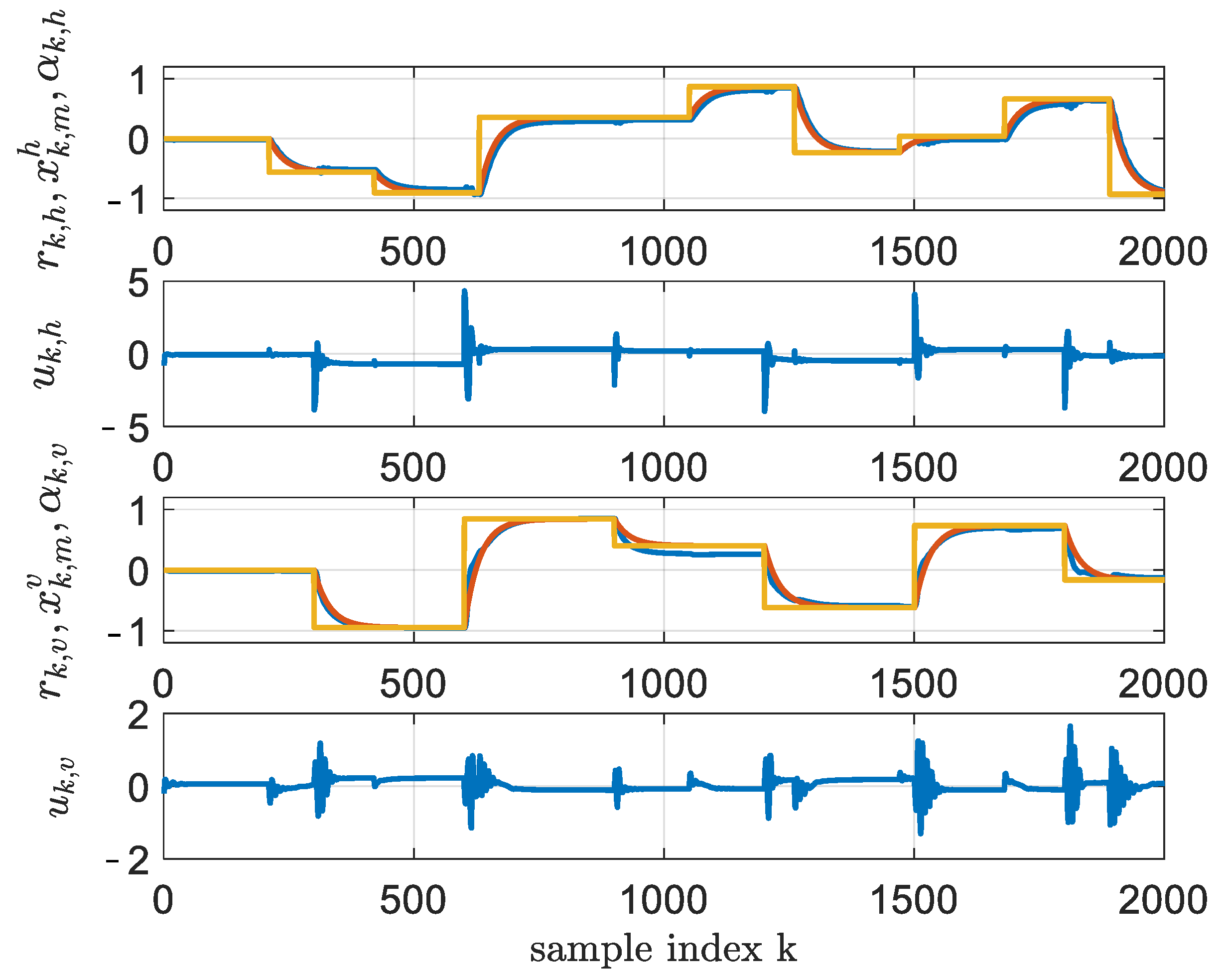
Figure 5.
One-hidden-layer controller learned through BOADHDP, at iteration and (yellow); and (red); and (blue). The commands and are for the horizontal and vertical axes (blue).
For the multilayer NN setup, the form of the action value function was 15-50-10-2 and that of the controller was 10-10-4-2. The activation functions of the two hidden layers were hyperbolic tangents and the ones from the output layer were linear. The weights were initialized using the Xavier initialization [29]. The internal gradient updates were and , and the learning rates took the values of and . The algorithm ran for a total number of 500 iterations. The convergence of the action value function and the values of is shown in Figure 4 in a blue color. The tracking performance of the controller obtained at iteration is shown in Figure 5.
From Figure 4, it can be seen that the convergence of the two-layer NN approximators for the action value function and the controller delivered more stable results. First, the norm of the action value function successive weight differences from the first plot was less noisy and provided a faster convergence in the two-layer case than the single-layer NN. Then, in the second plot, the function converged faster to a lower value that correlated with a performant controller. Also, the values of was for the single-layer NNs and for the two-layer implementation. The two-layer implementation outperformed the single-layer one by 1.58%. The difference in tracking performance can be seen in Figure 5 and Figure 6, where the horizontal motion tracking improved in the case of the two-layer NN controller.
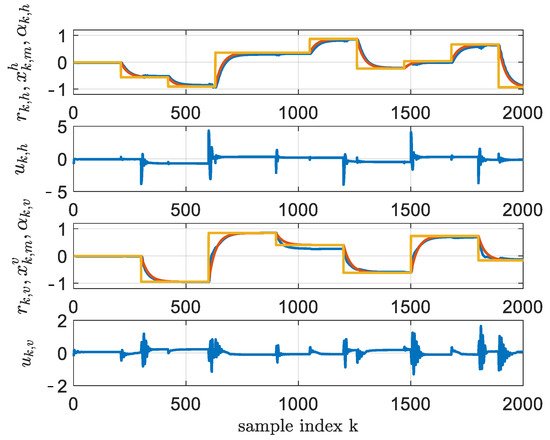
Figure 6.
Two-hidden-layer controller learned through BOADHDP, at iteration and (yellow); and (red); and (blue). The commands and are for the horizontal and vertical axes (blue).
5.3. Comparison Between BOADHDP and the Online Adaptive ADHDP
Next, the online adaptive ADHDP algorithms from [21,22] were applied to the TRAS system. The difference between ADHDP methods [] was that the former one only updates the weights from the hidden to the output layer, while the latter updates the entire NN weights.
For these algorithms, we used the same NN architectures as in the single-layer NN from BOADHDP, namely the form of the action value function NN was 12-50-1 and that of the controller was 10-10-2. The activation functions of the hidden layer were hyperbolic tangents and the ones of the output layer were linear. The weights were also initialized using the Xavier initialization [29]. The learning rates were selected to be and . The penalty function took the form of .
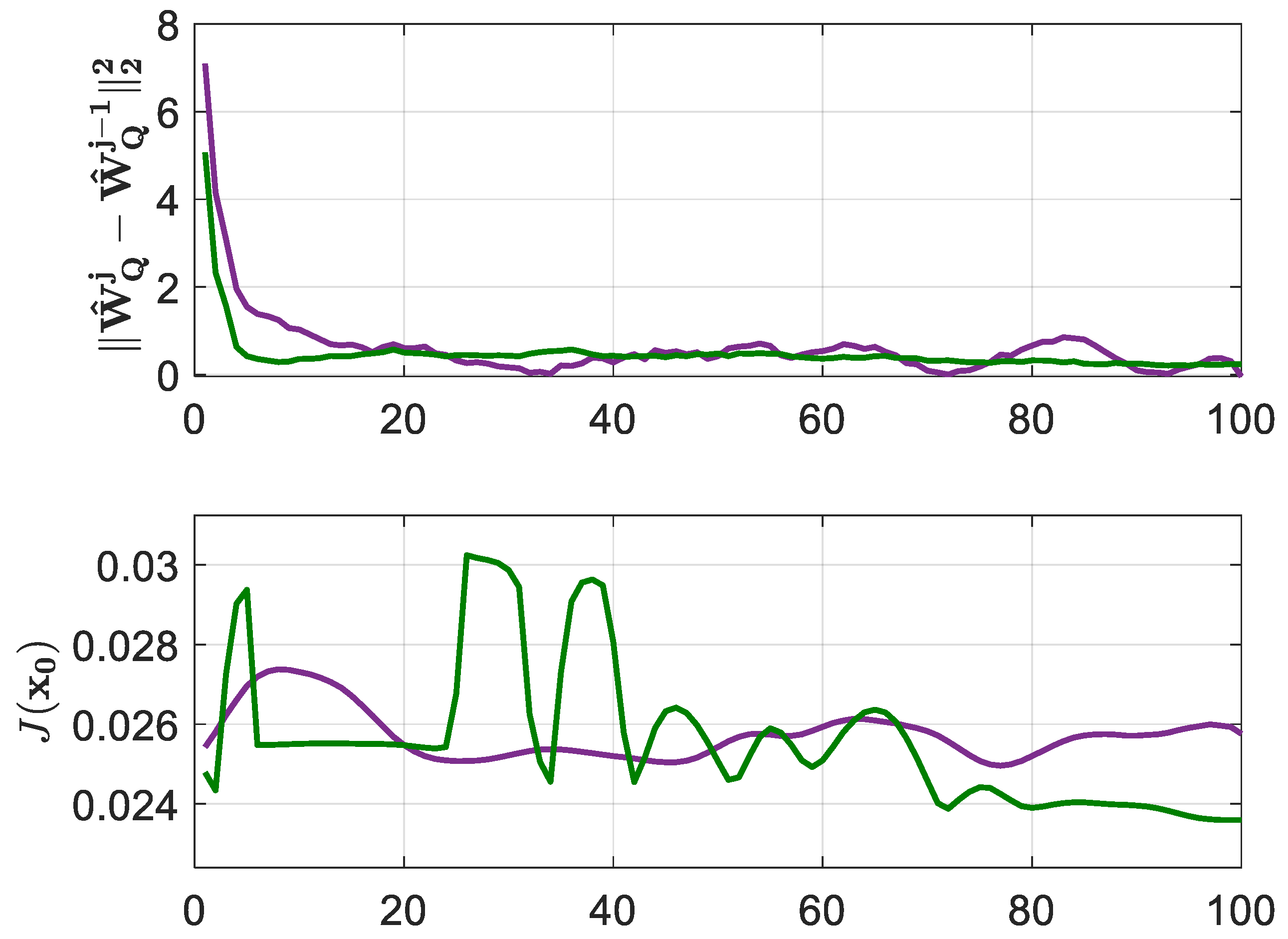
Compared with BOADHDP, in these implementations, the adaptation of the NNs was made online, using only the transitions along with each time step of the simulated system. The algorithm ran for 200,000 time steps. Every 2000 steps, the controller weights were fixed and their performance was measured by the function under a simulated scenario, for . The convergence of the action value function and of the controller performance of the simulated scenario can be seen in Figure 7 for the ADHDP algorithms from [21,22]. The tracking performance of the ADHDP algorithms from [21,22] on the TRAS system using the aforementioned learning settings is presented in Figure 8. The value of the was for the ADHDP algorithm from [21] and for the ADHDP algorithm from [22].
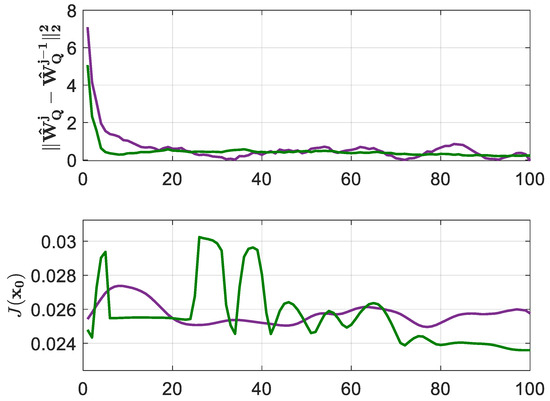
Figure 7.
ADHDP convergence in relation to the TRAS system. ADHDP algorithm from [21] in purple and ADHDP algorithm from [22] in green.
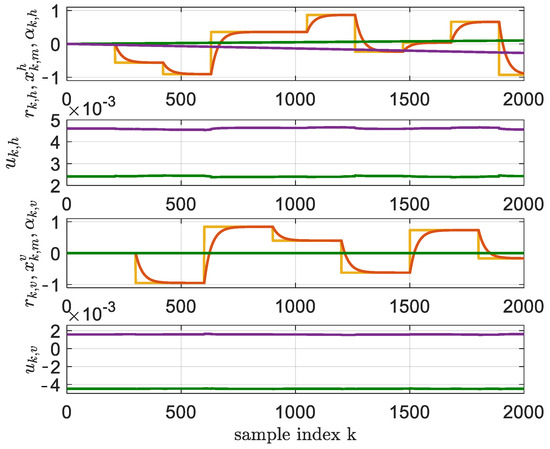
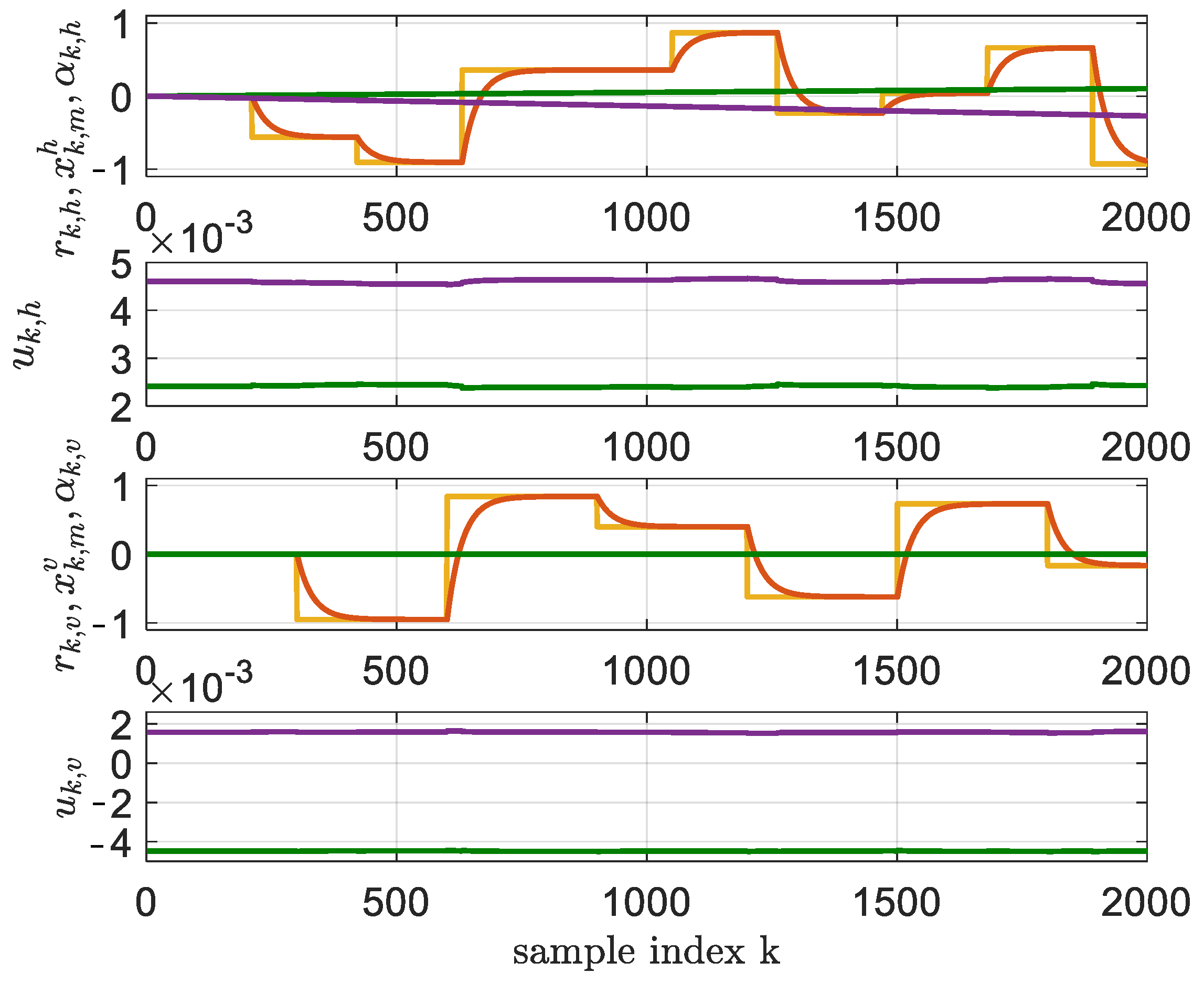
Figure 8.
Tracking performance of the ADHDP algorithms from [21,22], at iteration and (yellow); and (red); and (green—ADHDP algorithm from [21], purple—ADHDP algorithm from [22]). The commands and are for the horizontal and vertical axes (green—ADHDP algorithm from [21], purple—ADHDP algorithm from [22]).
The values of the BOADHDP and ADHDP algorithms from [21,22] are summarized in Table 1. Also, from Figure 5 and Figure 8, it can be observed that the online adaptive ADHDP algorithms could not deliver the same performance as their batch and offline counterpart, BOADHDP. Furthermore, the ADHDP algorithms presented in [21,22] failed to enhance controller performance, even though they utilized four times as many collected transitions from the system. This difference in the performance of the BOADHDP algorithm stems, in part, from the batch nature of the learning process. By processing multiple collected transitions from the state action space at the same time during NN actualization, the gradient for the action value and controller NNs is averaged over all the transitions. In turn, this makes the NN update more stable. By issuing the gradient update in an offline manner, the same collected transitions are used at each iteration, making the convergence speed faster. This stands in accordance with the observations from [28], where the authors proved the advantages of batch learning in comparison to the online adaptive single-transition learning from the classical ADHDP methods. Also, from this case study, it can be seen that the number of transitions required for learning was higher in the online adaptive case than in the batch offline case.

Table 1.
Comparison between the BOADHDP (single- and multiple-hidden-layer NN approximations) and the ADHDP algorithms from [21,22].
6. Discussion and Conclusions
In this paper, we study the theoretical stability of BOADHDP with deep neural networks as function approximators for the action value function and the controller. To this end, we introduce a stability criterion for the iteratively updated action value function and controller NN. The theory uses the Lyapunov stability approach and shows that the weight estimation errors are UUB if some inequality constraints on the learning rate magnitudes are respected. This research extends the previous results from the literature, such as [21,22], both theoretically and practically.
- First, our Lyapunov stability is extended to address NN approximators for action value functions and controllers with multiple hidden layers. Although NNs with a single hidden layer are universal approximators, their usage for highly nonlinear applications is hindered by their generalization capabilities. In contrast, multilayer NNs can learn complex features effectively, reducing overfitting and generalization issues. The results outlined in Theorem 1 indicate also an indirect proportionality between the number of NN hidden layers and the magnitude of the learning rate, providing a practical heuristic approach for practical ADP applications of multilayer NNs.
- Second, our theoretical Lyapunov stability analysis addresses the usage of batch offline learning of the action value function and controller NNs. Although successful ADP applications have been reported using adaptive update methods, their practical use is often constrained by the significant number of iterations required for convergence. The adoption of batch learning has, thus, become standard practice, necessitating a theoretical Lyapunov stability coverage.
- Finally, from a practical point of view, we validate the advantage of using BOADHDP with multilayer NNs through a case study on a twin rotor aerodynamical system (TRAS). This study compares BOADHDP using neural networks with a single layer and two hidden layers as function approximators. The results show that the normed action value function weight convergence is smoother with two-hidden-layer networks, also leading to a controller with an enhanced performance on the control benchmark ( for the single-layer NNs and for the two-layer implementation, namely a improvement). This demonstrates the superior capability of multilayer networks in managing complex, nonlinear control systems. Also, BOADHDP is compared with ADHDP algorithms from [21,22], with ADHDP algorithms from [21,22] obtaining and , respectively, on the control benchmark, while also requiring four times more collected transitions from the TRAS system. This proves both the efficiency of the BOADHDP with respect to the number of collected transitions and the performance of using batch offline learning methodologies, confirming the results from [28].
Our findings highlight the advantages of BOADHDP with deep neural networks in practical applications, underscoring the improved stability and performance in control tasks. Future research may explore extending this batched multilayer approach to adaptive learning scenarios. From a practical point of view, applications entailing deep neural networks and batch learning applications might benefit from this analysis.
Funding
This research received no external funding.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the author on request.
Acknowledgments
I would like to thank Ioan Silea for reading this manuscript and for providing constructive feedback that improved the quality of our research.
Conflicts of Interest
The author declares no conflicts of interest.
References
- Werbos, P.J. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Science. Ph.D. Thesis, Committee on Applied Mathematics, Harvard University, Cambridge, MA, USA, 1974. [Google Scholar]
- Bellman, R.E. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Werbos, P.J. Approximate dynamic programming for real time control and neural modeling. In Handbook of Intelligent Control: Neural, Fuzzy, and Adaptive Approaches; White, D.A., Sofge, D.A., Eds.; Van Nostrand Reinhold: New York, NY, USA, 1992; pp. 493–525. [Google Scholar]
- Al-Tamimi, A.; Lewis, F.L. Discrete-time nonlinear HJB solution using approximate dynamic programming: Convergence proof. IEEE Trans. Syst. Man Cybern. B 2008, 38, 943–949. [Google Scholar] [CrossRef] [PubMed]
- Prokhorov, D.V.; Wunsch, D.C. Adaptive critic designs. IEEE Trans. Neural Netw. 1997, 8, 997–1007. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Balakrishnan, S.N. Convergence analysis of adaptive critic based optimal control. In Proceedings of the American Control Conference, Chicago, IL, USA, 28–30 June 2000. [Google Scholar]
- White, D.A.; Sofge, D.A. Handbook of Intelligent Control: Neural, Fuzzy, and Adaptive Approaches; Van Nostrand Reinhold: New York, NY, USA, 1992. [Google Scholar]
- Padhi, R.; Unnikrishnan, N.; Wang, X.; Balakrishnan, S.N. A single network adaptive critic (SNAC) architecture for optimal control synthesis for a class of nonlinear systems. Neural Netw. 2006, 19, 1648–1660. [Google Scholar] [CrossRef] [PubMed]
- Balakrishnan, S.N.; Biega, V. Adaptive-critic-based neural networks for aircraft optimal control. J. Guid. Control Dyn. 1996, 19, 893–898. [Google Scholar] [CrossRef]
- Dierks, T.; Jagannathan, S. Online optimal control of affine nonlinear discrete-time systems with unknown internal dynamics by using time-based policy update. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1118–1129. [Google Scholar] [CrossRef] [PubMed]
- Venayagamoorthy, G.K.; Harley, R.G.; Wunsch, D.C. Comparison of heuristic dynamic programming and dual heuristic programming adaptive critics for neurocontrol of a turbogenerator. IEEE Trans. Neural Netw. 2002, 13, 764–773. [Google Scholar] [CrossRef] [PubMed]
- Ferrari, S.; Stengel, R.F. Online adaptive critic flight control. J. Guid. Control Dyn. 2004, 27, 777–786. [Google Scholar] [CrossRef]
- Ding, J.; Jagannathan, S. An online nonlinear optimal controller synthesis for aircraft with model uncertainties. In Proceedings of the AIAA Guidance, Navigation and Control Conference, Toronto, ON, Canada, 2–5 August 2010. [Google Scholar]
- Vrabie, D.; Pastravanu, O.; Lewis, F.; Abu-Khalaf, M. Adaptive optimal control for continuous-time linear systems based on policy iteration. Automatica 2009, 45, 477–484. [Google Scholar] [CrossRef]
- Dierks, T.; Jagannathan, S. Optimal control of affine nonlinear continuous-time systems. In Proceedings of the American Control Conference, Baltimore, MA, USA, 30 June–2 July 2010. [Google Scholar]
- Vamvoudakis, K.; Lewis, F. Online actor-critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica 2010, 46, 878–888. [Google Scholar] [CrossRef]
- Enns, R.; Si, J. Helicopter trimming and tracking control using direct neural dynamic programming. IEEE Trans. Neural Netw. 2003, 14, 929–939. [Google Scholar] [CrossRef]
- Liu, D.; Javaherian, H.; Kovalenko, O.; Huang, T. Adaptive critic learning techniques for engine torque and air–fuel ratio control. IEEE Trans. Syst. Man Cybern. B 2008, 38, 988–993. [Google Scholar]
- Ruelens, F.; Claessens, B.J.; Quaiyum, S.; De Schutter, B.; Babuška, R.; Belmans, R. Reinforcement learning applied to an electric water heater: From theory to practice. IEEE Trans. Smart Grid 2018, 9, 3792–3800. [Google Scholar] [CrossRef]
- He, P.; Jagannathan, S. Reinforcement learning-based output feedback control of nonlinear systems with input constraints. IEEE Trans. Syst. Man Cybern. B 2005, 35, 150–154. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Sun, J.; Si, J.; Guo, W.; Mei, S. A boundness result for the direct heuristic dynamic programming. Neural Netw. 2012, 32, 229–235. [Google Scholar] [CrossRef] [PubMed]
- Sokolov, Y.; Kozma, R.; Werbos, L.D.; Werbos, P.J. Complete stability analysis of a heuristic approximate dynamic programming control design. Automatica 2015, 59, 9–18. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Lillicrap, T.; Hunt, J.; Pritzel, A.; Heess, N.; Erez, Y.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the Internation Conference on Machine Learning, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Riedmiller, M. Neural Fitted Q Iteration–First Experiences with a Data Efficient Neural Reinforcement Learning Method. In Proceedings of the European Conference on Machine Learning, Porto, Portugal, 3–7 October 2005. [Google Scholar]
- Radac, M.-B.; Lala, T. Learning output reference model tracking for higher-order nonlinear systems with unknown dynamics. Algorithms 2019, 12, 121. [Google Scholar] [CrossRef]
- Watkins, C. Learning from Delayed Rewards. Ph.D. Thesis, Department of Computational Science, University of Cambridge, Cambridge, UK, 1989. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).