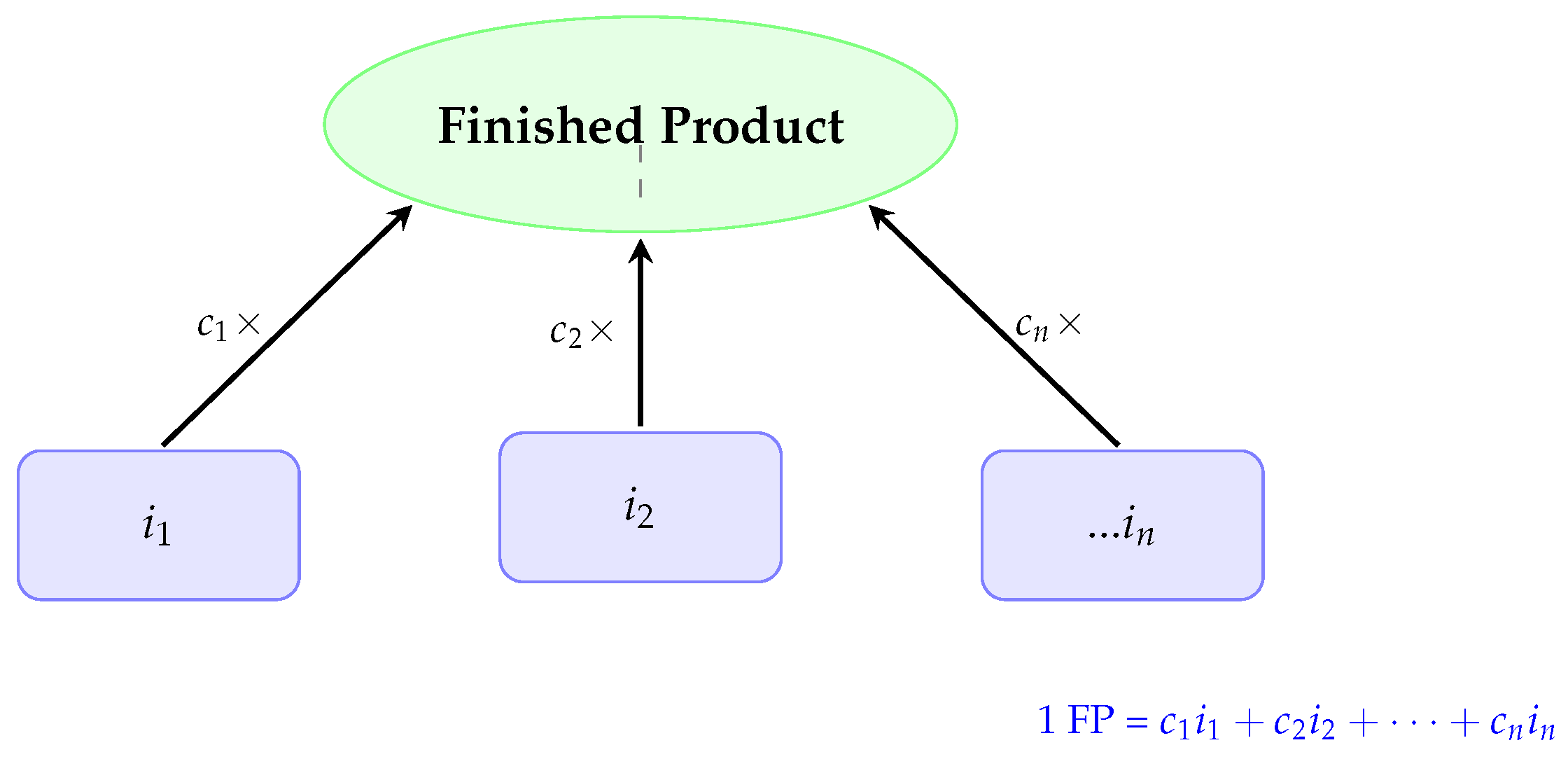
1. Introduction
In the context of supply chain and inventory management, planning plays a critical role in the effectiveness of replenishment strategies [
1]. Well-designed planning processes help maintain optimal inventory levels, balancing the risk of overstocking—which leads to increased storage costs—with the risk of stockouts, which can cause lost sales and diminished customer satisfaction [
2]. By ensuring the timely availability of products, components, or raw materials to meet production schedules or customer demand, effective planning contributes directly to improved service levels and enhanced customer loyalty [
3]. These challenges are further compounded under conditions of uncertainty, where variability in demand and supplier lead times can significantly disrupt replenishment decisions.
In replenishment management, planning is essential to maintaining a balance between supply and demand, minimizing costs, and ensuring customer satisfaction [
4]. Effective planning enables the optimal implementation of replenishment policies [
5], aligning inventory decisions with strategic business objectives such as cost reduction and high product availability. These policies adjust order quantities and stock levels based on real-time market conditions. The effectiveness of such planning depends largely on its ability to adapt to various sources of uncertainty arising from collaborative operations between manufacturers and customers, interactions with suppliers of raw materials or critical components, and even internal manufacturing processes [
6]. The nature of this uncertainty is multifaceted [
7], often resulting in increased operational costs, reduced profitability, and diminished customer satisfaction [
8]. Numerous studies emphasize key sources of uncertainty in manufacturing environments, including demand variability, fluctuations in supplier lead times, quality issues, and capacity constraints [
9].
Demand uncertainty significantly impacts supply chain design. While stochastic programming models outperform deterministic approaches in optimizing strategic and tactical decisions [
10], most studies overlook lead time variability caused by real-world disruptions. Companies typically address supply uncertainty through safety stocks and safety lead times [
11], which trade off shortage risks against higher inventory costs. The key challenge lies in finding the optimal balance between these competing costs. For a long time, lead time uncertainty received relatively little attention in the literature, with most research in inventory management focusing predominantly on demand uncertainty [
12]. In assembly systems, component lead times are often subject to uncertainty; they are rarely deterministic and typically exhibit variability [
13].
The literature on stochastic lead times in assembly systems has seen significant contributions that have shaped current approaches to inventory control under uncertainty [
14]. A notable study by [
15] investigates a single-level assembly system under the assumptions of stochastic lead times, fixed and known demand, unlimited production capacity, a lot-for-lot policy, and a multi-period dynamic setting. In this work, lead times are modeled as independent and identically distributed (i.i.d.) discrete random variables. The authors focus on optimizing inventory policies by balancing component holding costs and backlogging costs for finished products, ultimately deriving optimal safety stock levels when all components share identical holding costs. This problem is further extended in [
16], which considers a different replenishment strategy—the Periodic Order Quantity (POQ) policy. In [
17], the lot-for-lot policy is retained, but a service level constraint is introduced. A branch and bound algorithm is employed to manage the combinatorial complexity associated with lead time variability. Subsequent studies [
18,
19,
20] build on this foundation by refining models to better capture lead time uncertainty in single-level assembly systems, while also proposing extensions to multi-level systems and providing a more detailed analysis of the trade-offs between holding and backlogging costs.
Modeling multi-product, multi-component assembly systems under demand uncertainty is inherently complex. Ref. [
21] proposes a modular framework for supply planning optimization, though its effectiveness depends on computational reductions and assumptions about probability distributions. For Assembly-to-Order systems, ref. [
22] develops a cost-minimization model incorporating lead time uncertainty, solved via simulated annealing. Several studies [
23,
24,
25,
26] address single-period supply planning for two-level assembly systems with stochastic lead times and fixed end-product demand. Using Laplace transforms, evolutionary algorithms, and multi-objective methods, they optimize component release dates and safety lead times to minimize total expected costs (including backlogging and storage costs). Ref. [
2] later improved upon [
18]’s work, while [
27] extended the framework to multi-level systems under similar assumptions.
Despite these advances, many existing models rely on oversimplified assumptions about delivery times and demand, limiting their applicability in real industrial contexts [
21]. This highlights the urgent need for new optimization frameworks that better capture real-world complexities and component interdependencies in assembly systems. In this work, we enhance the method of [
15] by explicitly incorporating (1) stochastic demand models, (2) ordering, holding, and stockout penalty costs, and (3) a Markov decision process (MDP) formulation enabling stochastic modeling of lead time and demand uncertainties.
Traditional optimization approaches for these problems face three key challenges:
Overly simplistic assumptions: Classical deterministic or stochastic optimization methods often require explicit assumptions about demand and delivery time distributions, which may not hold in practice due to complex, unknown, or non-stationary stochastic processes [
28].
Curse of dimensionality: The high-dimensional state and action spaces in multi-component, multi-period inventory problems cause an explosion in computational complexity, rendering classical dynamic programming and linear programming approaches impractical [
29,
30].
Static or computationally intensive decision-making: Many existing methods rely on static policies or require frequent re-optimization to adapt to changing system dynamics, which is computationally expensive and slow in real-time environments [
31].
To overcome these limitations, this paper employs deep reinforcement learning (DRL), specifically the Deep Q-Network (DQN) algorithm, which learns optimal replenishment policies through continuous interaction with the inventory environment without requiring explicit distributional assumptions. DQN’s neural network-based function approximation enables generalization across high-dimensional states, mitigating the curse of dimensionality [
32,
33]. Furthermore, DQN dynamically adapts policies online, providing scalable, flexible solutions suited for complex, stochastic supply chain problems [
34].
Recent trends in production planning and control (PPC) emphasize integrating artificial intelligence and machine learning, especially reinforcement learning, to handle increasing supply chain complexity and uncertainty [
35,
36]. Industry 4.0’s shift towards automation and decision-making autonomy further motivates adoption of data-driven, adaptive methods like DQN for inventory management [
37].
Recent studies have explored the integration of deep reinforcement learning (DRL) into inventory management, particularly for complex multi-echelon systems. For instance, a modified Dyna-Q algorithm incorporating transfer learning has been proposed to address the cold-start problem in inventory control for newly launched products without historical demand data [
38]. In another direction, a novel Q-network architecture based on radial basis functions (RBFs) has been introduced to simplify neural network design in DRL [
39]. To further address scalability challenges, the Iterative Multi-agent Reinforcement Learning (IMARL) framework combines graph neural networks and multi-agent learning for large-scale supply chains [
40].
This study develops a discrete inventory optimization model for single-level assembly systems (multi-component, multi-period) under stochastic demand and delivery conditions. Our main contributions include integrating multiple logistics cost components, relaxing common assumptions (e.g., uniform delivery distributions, fixed demand), introducing component-level stockout calculations, and employing DQN for efficient policy learning. The model supports integer decision variables for MRP compatibility while addressing dual uncertainties in demand and delivery.
The remainder of the paper is organized as follows:
Section 2 defines the problem setting and sources of uncertainty.
Section 3 presents the MDP formulation.
Section 4 details the DQN methodology and implementation.
Section 5 analyzes experimental results, demonstrating the efficacy of the proposed approach. Finally,
Section 6 concludes with a summary of contributions, limitations, and future work.
5. Results and Discussion
The environment parameters define the operational characteristics of the inventory system, such as the number of components, penalty and holding costs, demand and lead time uncertainties, and the structure of consumption. These parameters ensure the simulation accurately reflects the complexities of real-world supply chains. The agent parameters govern the learning process, including the neural network architecture, learning rate, exploration behavior, and training configuration. The inclusion of a replay buffer further enhances learning stability by breaking temporal correlations in the training data. The DQN algorithm is employed to learn optimal ordering policies over time. By interacting with the environment through episodes, the agent receives feedback in the form of rewards, which reflect the balance between minimizing shortage penalties and storage costs. To facilitate the simulation and make the analysis more interpretable, simple parameter values were used in the first table, including limited lead time possibilities and a small range of demand values. Additionally, the reward function was normalized (reward divided by 10,000) to simplify numerical computations and stabilize the learning process. Despite this simplification, the implemented environment and reinforcement learning algorithms are fully generalizable: they can handle any number of components (n), multiple lead time scenarios, and a range of demand values (m), making the model adaptable to more complex and realistic settings. However, scaling up to larger instances requires significant computational resources, as the state and action spaces grow exponentially. Therefore, a powerful machine is recommended to run simulations efficiently when moving beyond the simplified test case.
The algorithm is developed using the Python version: 3.11.13 programming language, which is particularly well-suited for research in reinforcement learning and operations management due to its expressive syntax and the availability of advanced scientific libraries. The implementation employs NumPy version: 2.0.2 for efficient numerical computation, particularly for manipulating multi-dimensional arrays and performing vectorized operations that are essential for simulating the environment and computing rewards. Visualization of training performance and inventory dynamics is facilitated through Matplotlib version: 3.10.0, which provides robust tools for plotting time series and comparative analyses. The core reinforcement learning model is implemented using PyTorch version: 2.6.0+cu124, a state-of-the-art deep learning framework that supports dynamic computation graphs and automatic differentiation. PyTorch is used to construct and train the deep q-network (DQN), manage the neural network architecture, optimize parameters through backpropagation, and handle experience replay to stabilize the learning process. Collectively, these libraries provide a powerful and flexible platform for modeling and solving complex inventory optimization problems under stochastic conditions.
The formulation and relative weighting of cost components critically affect the learning behavior and convergence of the DQN agent. To maintain numerical stability, we normalized the reward function by dividing it by 10,000. Empirical results showed that overemphasizing shortage costs led to excessive inventory, while high holding cost weights increased shortages. Large ordering costs caused delayed or infrequent ordering. These findings highlight the significant impact of reward design on policy outcomes. Although we selected weights based on empirical performance, a formal sensitivity analysis remains a valuable direction for future research.
With this reward structure and cost weighting scheme established, we proceed to evaluate the agent’s learning performance and policy behavior during training.
5.1. Performance and Policy Evaluation
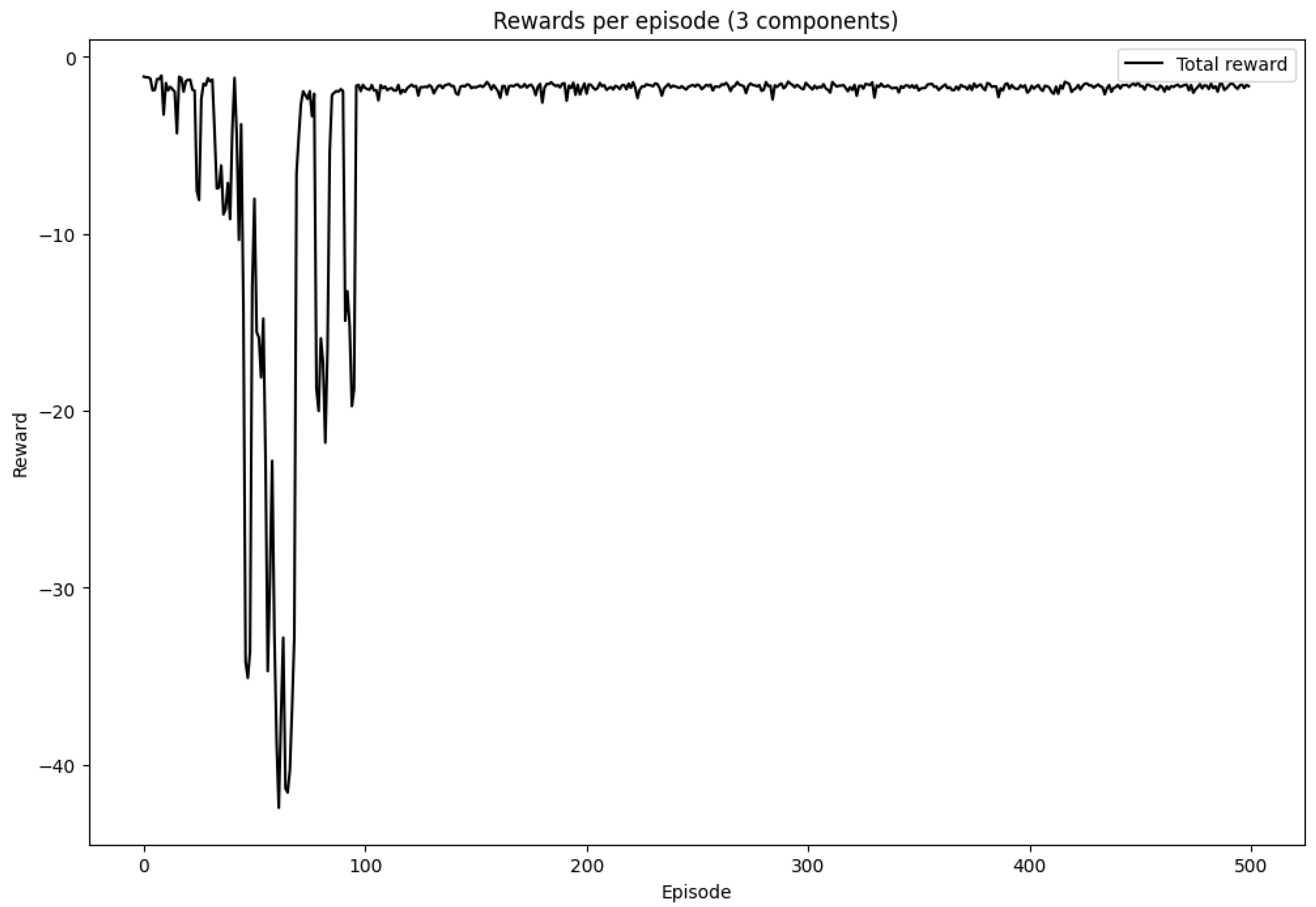
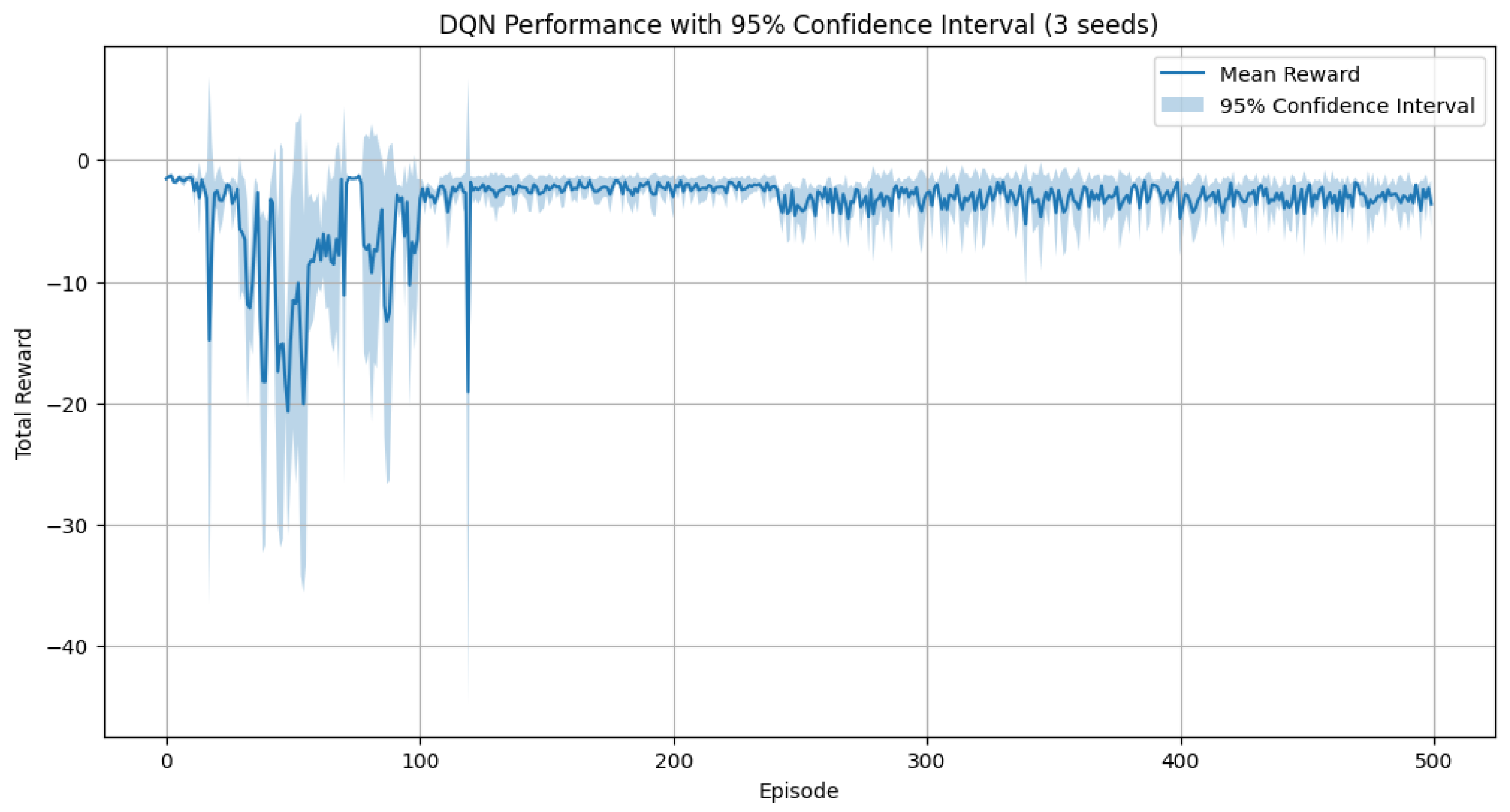
Figure 3. Average reward per episode during training. The reward function is based on the negative of the total cost (holding, shortage, and ordering) and is normalized by dividing by 10,000 for numerical stability. The learning curve demonstrates convergence over time.
5.2. Quantitative Performance Summary
To complement the qualitative learning curves, we conducted a rigorous quantitative evaluation of our proposed DQN-based approach. We computed key statistical metrics over 500 independent training runs, including:
Mean total cost (i.e., cumulative negative reward),
Average number of stockouts per episode,
Global service level,
Standard deviation of total cost (to capture variability),
Total number of training episodes,
Training time (minutes),
Component-wise availability.
Table 4 summarizes these results, providing a comprehensive assessment of performance and robustness.
These quantitative results confirm that our approach maintains a high service level while effectively balancing stockouts and inventory costs, demonstrating both reliability and robustness.
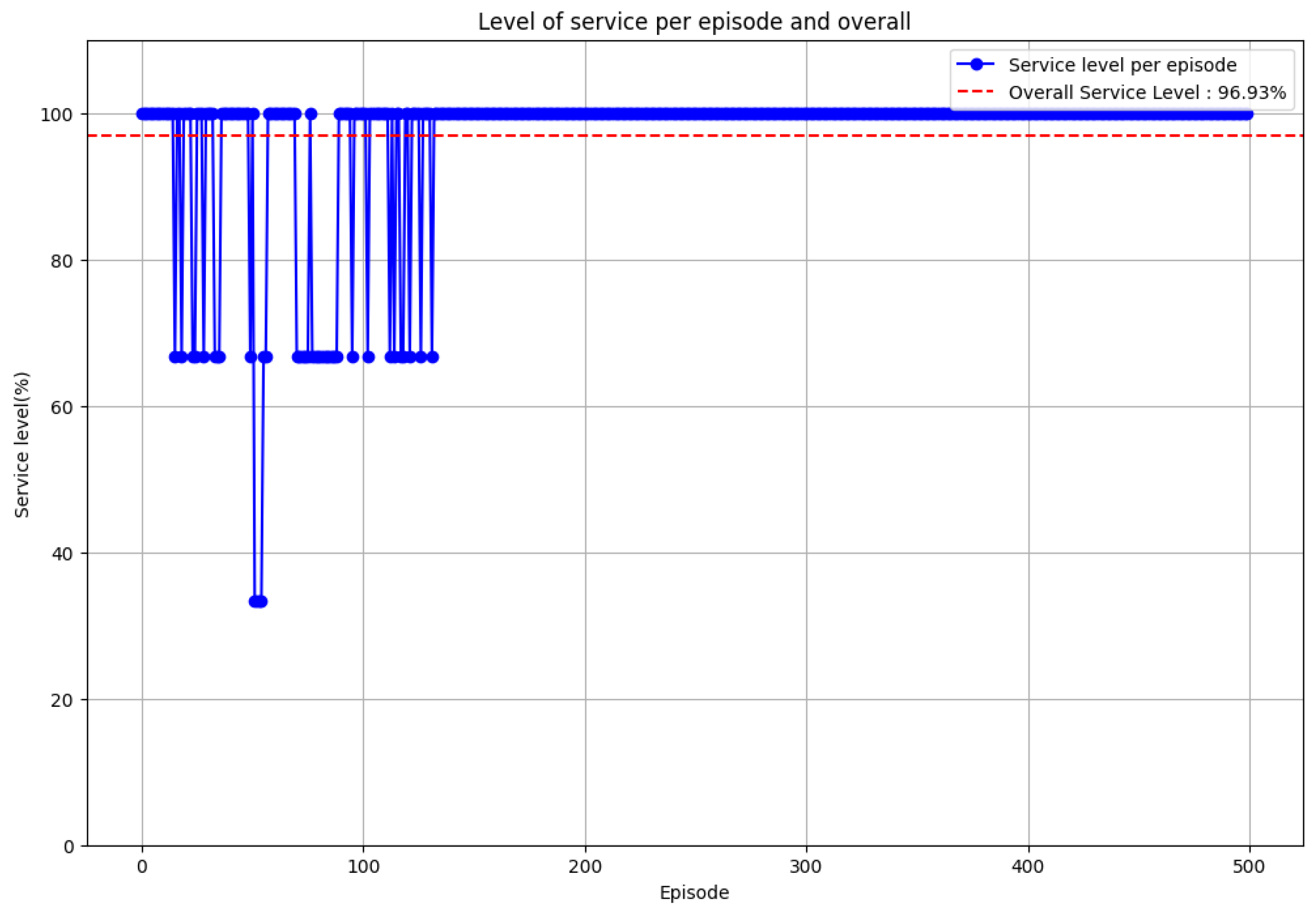
5.3. Global Service Level Plot
Figure 4 illustrates the evolution of the global service level over training episodes, further emphasizing the stability and effectiveness of the learned policy.
5.4. Policy and Inventory Evolution
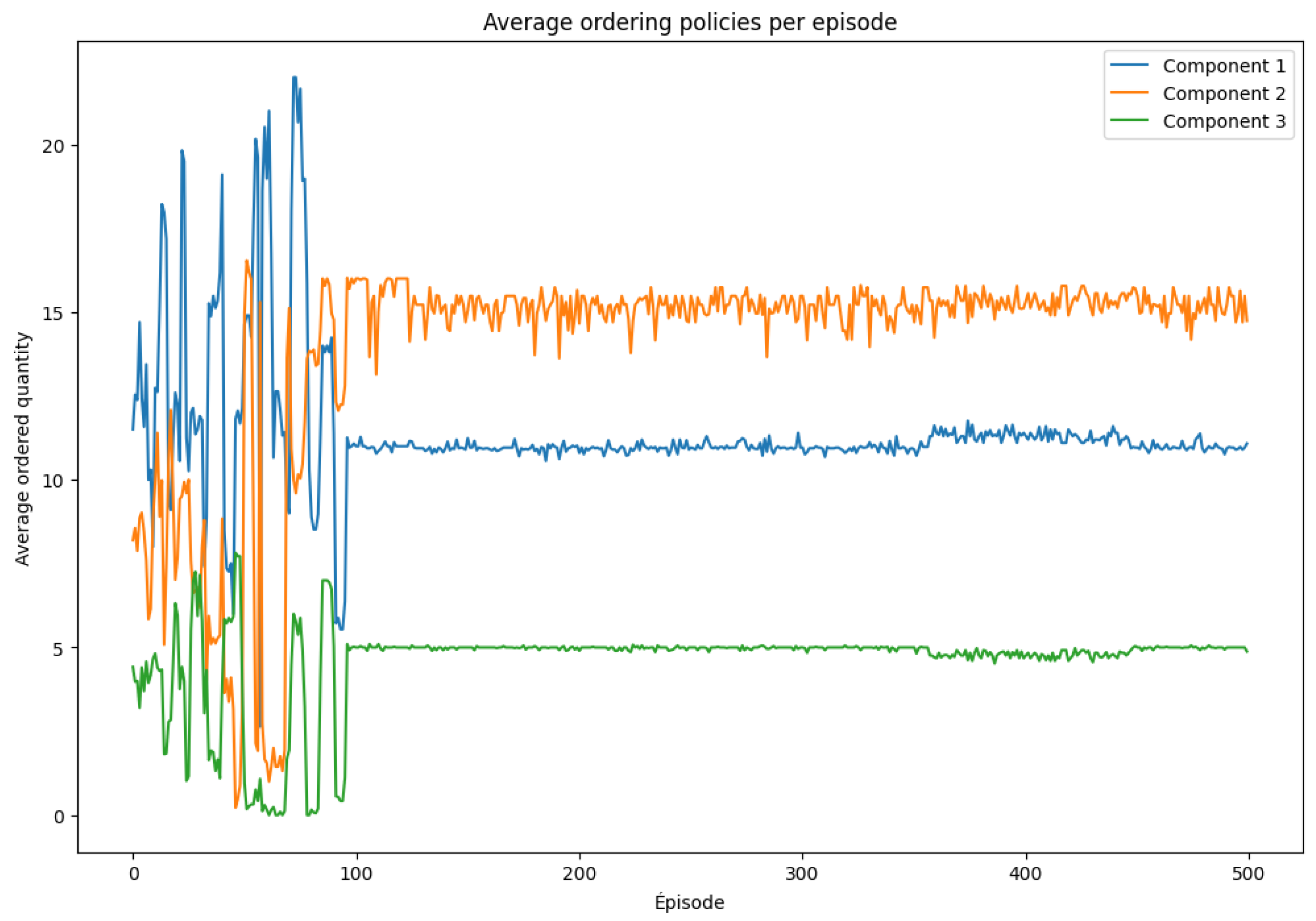
Figure 5 illustrates the agent’s learned ordering policies over training episodes. Early in training, the ordered quantities fluctuate significantly, reflecting the exploration phase of learning. As training progresses, the policy converges toward more stable and consistent ordering behaviors. Notably, Component 2 is ordered most frequently and in larger quantities, indicating its higher importance or greater risk of shortage. In contrast, Component 3 is ordered less often, which may be attributed to lower consumption rates or more favorable lead times.
The evolution of average stock levels is shown in
Figure 6. Initially, stock levels exhibit considerable volatility, including frequent shortages (negative inventory values). Over time, the agent learns to anticipate demand and lead time uncertainties more effectively, resulting in smoother inventory trajectories. The final stock levels-particularly higher for component 2 underscore its strategic importance and confirm the ordering strategy observed in
Figure 5.
Together, these results clearly demonstrate the capability of the DQN algorithm to adaptively optimize inventory policies under uncertainty. The convergence of rewards, consistency in ordering patterns, and stabilization of stock levels collectively validate the effectiveness and robustness of the learned policy.
5.5. Computational Efficiency and Scalability
Our experiments, conducted on a MacBook Air M1 (2020), designed by Apple Inc. (Cupertino, CA, USA), and assembled in China with 8 GB RAM and a 256 GB SSD via Google Colab, show that training a three-component system for 500 episodes with 50 steps each takes approximately 7 min, demonstrating computational efficiency on moderate hardware for small-scale problems. However, scaling up to more components, complex lead times, and varied demand significantly enlarges the action space, increasing training time and memory demands. This highlights a practical trade-off between model complexity and available computational resources.
5.6. Comparison of Decision Latency Across Policies
We aim to quantify and compare the decision latency of the proposed Deep Q-Network (DQN)policy with three classical replenishment strategies: the (Q, R) policy, the (s, S) policy, and the Newsvendor model. Decision latency is defined here as the time elapsed from observing the system state to issuing a replenishment action. This metric is critical in real-time supply chain systems where decisions must be made quickly in response to dynamic changes in inventory levels and demand.
5.6.1. DQN-Based Inventory Replenishment Decision Process
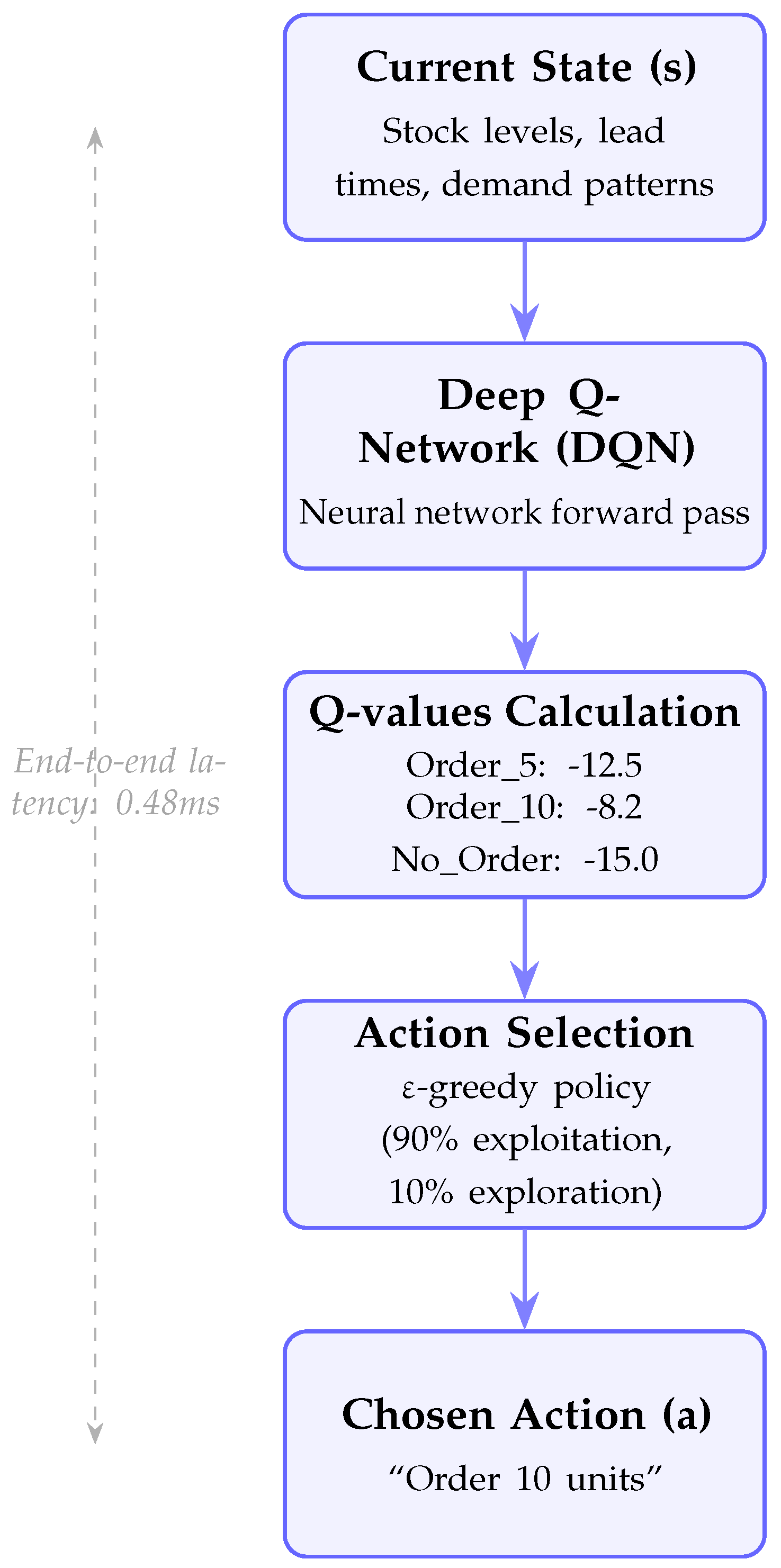
The
Figure 7 outlines the DQN’s decision-making process for inventory control: it takes the current state as input, computes Q-values via a forward pass, selects the optimal action, and outputs a replenishment decision. This inference process is fast (e.g., 0.48 ms), enabling real-time application in dynamic supply environments.
5.6.2. Policy Logic and Latency Source
Table 5 presents a qualitative comparison of the policies under consideration, including their decision logic and what we aim to measure for latency. While classical policies rely on simple threshold or closed-form expressions, the DQN involves neural network inference, which may introduce non-negligible computational delay.
5.6.3. Measurement of Inference Time
The inference time for each policy was measured over 500 runs using time.perf_coun-ter(), and only the computation time of decision logic was considered (excluding simulation steps or reward calculation). For the DQN policy, the action was computed by executing the forward pass through the trained neural network using the select_action function, integrated within our custom simulation environment, InventoryMDPEnv. This environment was specifically developed for this research to simulate stochastic assembly systems with uncertain demand and lead times. It allows realistic evaluation of inference latency within a dynamic and controlled decision-making context. To ensure fairness, all policies—including (Q, R), (s, S), and Newsvendor—were also executed under the same environment, taking identical state inputs and returning replenishment actions. This guarantees a consistent basis for latency measurement across all strategies.
Inference Diagnostic Example: Representative outputs from the DQN agent during a single inference step (one complete episode with max-steps = 1 (one run)) are summarized in
Table 6, demonstrating policy decision latency, resulting inventory actions under initial stock conditions, and the selected action index, and its corresponding Q-value.
Table 7 summarizes the inference time results collected over 500 independent runs using our custom
InventoryMDPEnv simulation environment.
Analysis:: The DQN policy demonstrates significantly higher inference times compared to classical threshold-based policies due to the computational overhead of neural network forward passes over a large action space. For the 3-component system, the average DQN inference time is approximately 0.27 ms, which is about 80–120 times slower than rule-based methods (e.g., (Q, R), (s, S), Newsvendor). Nevertheless, this remains well within practical real-time constraints for inventory replenishment decisions.
Figure 8 illustrates that the DQN policy incurs a noticeably higher inference time relative to classical inventory management approaches.
5.6.4. Reasons for DQN Inference Delay
Despite being suitable for real-time decision-making, the DQN policy exhibits higher inference latency than classical models due to several factors:
The DQN outputs a Q-value for every possible action in the discrete action space. In our system, the action space is defined using the following rule:
This results in a
MultiDiscrete action space, where the total number of possible joint actions is:
Table 8 shows an example of how the action space size grows combinatorially based on component-specific parameters.
- -
Neural Network Output Size
- -
CPU-Only Inference
Inference is run on CPU (e.g., MacBook Air or Google Colab CPU backend), without GPU acceleration. PyTorch forward passes on CPU are typically 5–20× slower than on GPU for high-dimensional output layers.
- -
Simulation and System-Level Factors
Extra delays may stem from the simulation environment InventoryMDPEnv (our custom simulator), which handles transitions, order queues, and lead-time sampling. Background CPU load and memory garbage collection also introduce runtime variance.
5.7. Evaluation with Multiple Random Seeds and Confidence Metrics
To ensure the robustness, reproducibility, and generalizability of our proposed Deep Q-Network (DQN) policy, we conducted all experiments using three independent random seeds: 42, 123, and 999. Each seed initialized the random number generators for NumPy version: 2.0.2, PyTorch, and Python’s random module, thereby controlling the initialization of network weights, environment behavior, and replay buffer sampling.
For each seed, the DQN agent was trained from scratch and evaluated over a fixed number of episodes. After aggregating the results from all seeds, we computed both central performance metricsand 95% confidence intervalsfor each episode using the following formulation:
This approach provides statistically meaningful insights into the stabilityand variabilityof learning outcomes due to stochastic factors in both environment and policy optimization. In addition to cumulative reward, we evaluated the DQN policy using the following operational performance metrics:
Service Level: the percentage of component units available to satisfy assembly demand without shortage.
The service level percentage is calculated as:
where:
- -
: Stock vector at timestep t (for N components)
Total Stockouts: the number of timesteps at which at least one component was unavailable when required.
The stockout count is defined as:
5.8. Baseline Policy Comparison
To benchmark the effectiveness of the learned DQN policy, we compared it with three classical inventory control strategies: 1. (Q, R) Policy (Quantity-Reorder Point): A continuous review policy that orders fixed quantity Q whenever inventory drops below reorder point R. Our implementation uses component-specific parameters (Q = [3, 3, 2], R = [2, 2, 1]), ordering the predetermined quantity for each component when stock falls below its reorder threshold. 2. (s, S) Policy (Min-Max): A periodic review policy that orders up to level S when inventory falls below s. We implemented this with s = [1, 1, 1] and S = [4, 4, 3], triggering replenishment to the target level S for each component when current stock is below its minimum threshold s. 3. Newsvendor Policy (Optimal Quantile Rule): A single-period model that determines optimal order quantities based on demand distribution quantiles. Our simplified implementation maintains target inventory levels [2, 2, 2], ordering exactly enough to reach these predetermined targets regardless of demand distribution. The policies were evaluated under identical simulation settings, using the same cost structure, lead time distributions, and demand distribution as the DQN agent.
Key differences in implementation approach:
The (Q, R) policy makes independent per-component decisions when thresholds are crossed.
The (s, S) policy coordinates batch replenishment across components at periodic intervals.
The Newsvendor policy maintains fixed target inventory levels per component.
All baseline policies are static and hand-tuned, whereas the DQN policy learns adaptively from the environment.
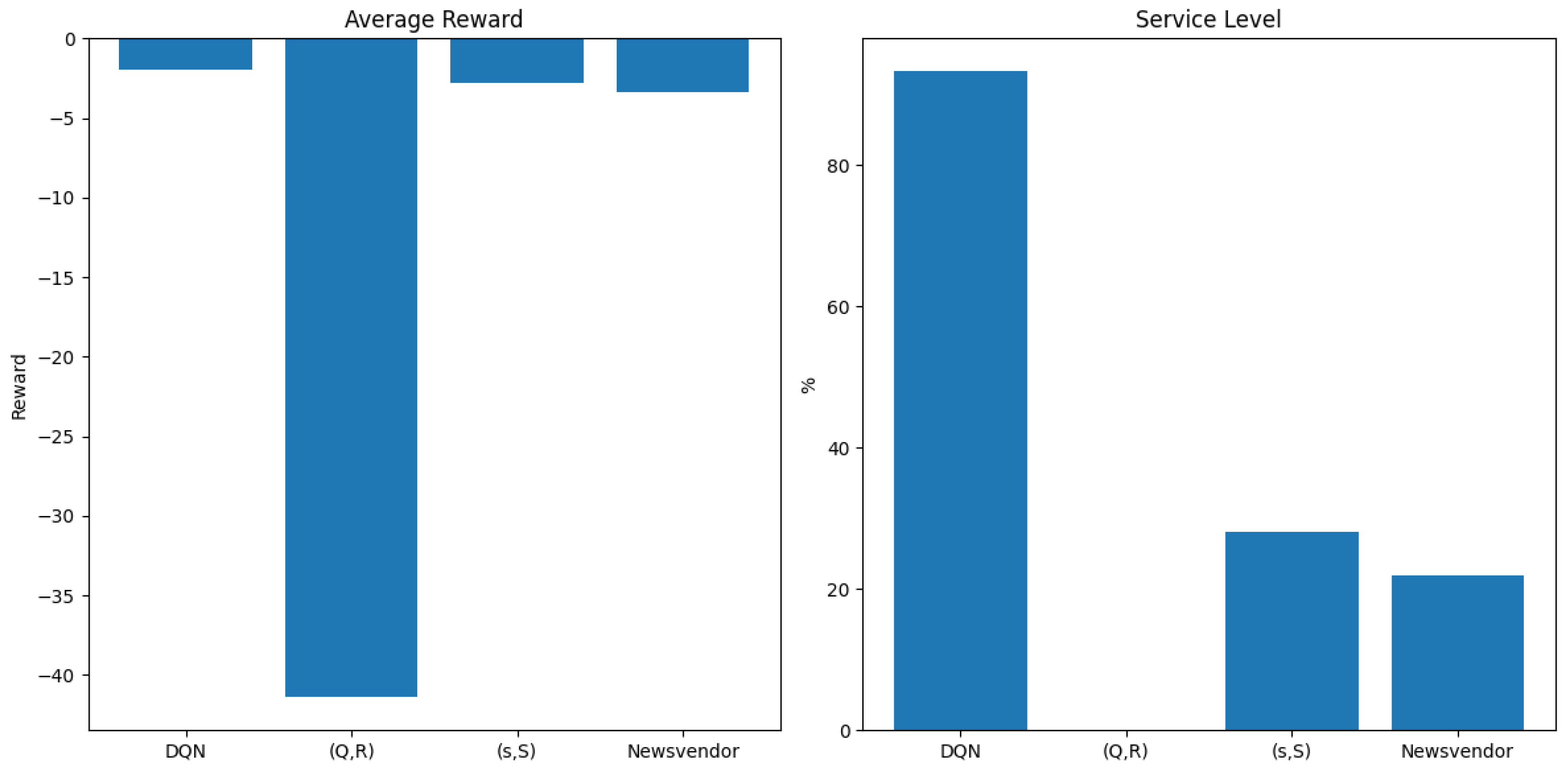
Table 10 presents a comparative summary of the DQN and baseline inventory policies in terms of reward, service level, stockouts, and decision latency.
Figure 10 compares the DQN policy with three classical baselines in terms of average reward and service level.
These results demonstrate that the DQN-based replenishment policy significantly outperforms classical baselinesin terms of service level and stockout reduction, albeit at the cost of slightly higher inference time. This trade-off remains acceptable in real-time production settings where high service availability is critical.
5.9. Impact of Lead Times on Ordered Quantities
When a component has a longer and more uncertain lead time, the agent tends to adapt its ordering strategy to mitigate the risk of stockouts. This often results in placing orders more frequently in anticipation of potential delays. Additionally, the agent may choose to maintain a higher inventory level as a buffer, ensuring that production is not interrupted due to late deliveries.
Table 11 presents a detailed analysis of the relationship between each component’s consumption level, its lead time uncertainty, and the resulting ordering behavior by the agent. Components with higher consumption but more reliable lead times, such as
, allow for stable and moderate ordering. In contrast, components like
and especially
, which are subject to longer and more uncertain delivery delays, require the agent to compensate by increasing order frequency. This strategic adjustment helps to avoid shortages despite the variability in supplier lead times. The table summarizes these insights for each component.
To better understand the agent’s ordering behavior,
Table 12 addresses key questions regarding the observed stock levels for each component. Although one might expect ordering decisions to align directly with consumption coefficient, this is not always the case. In reality, the agent adjusts order quantities and stock levels by taking into account both the demand and the uncertainty in lead times. As shown below, components with a higher risk of delivery delays tend to be stocked more heavily, even if their consumption coefficient is relatively low, while components with reliable lead times require less buffer stock.
Summary of Effects
Final Observation: The agent adjusts decisions based on lead time risks, not just consumption rates.
Table 13 summarizes the lead time characteristics and the corresponding agent strategies for each component, highlighting how uncertainty in delivery impacts stock levels.
5.10. Impact of Uncertain Demand on Order Quantities
The expected demand for the finished product is:
Table 14 presents the expected demand per component, calculated by multiplying the consumption coefficients
by the average demand.
This suggests that, in an ideal case without lead time risks, the order quantities should follow the ratio:
5.11. Variability in Demand and Its Effect
In addition to lead time uncertainties, the agent must also consider variability in demand and cost-related trade-offs when determining order quantities. The decision-making process is not only influenced by the likelihood of delayed deliveries but also by how demand fluctuates over time and how different types of costs interact.
Table 15 outlines the key factors that affect the agent’s ordering behavior and explains their respective impacts on the optimal policy formulation.
5.12. Interplay Between Demand Uncertainty and Lead Time Risks
If the observed order quantities do not strictly follow the expected pattern , this may be due to the agent anticipating delivery delays and adjusting order sizes accordingly. Such adjustments also reflect an effort to minimize shortage costs, potentially resulting in overstocking components with uncertain lead times. Additionally, the agent may adopt a dynamic policy that evolves over time in response to past shortages, modifying future decisions based on observed system performance. Demand uncertainty forces the agent to carefully balance risk and cost, and while component should theoretically be ordered the most due to its high consumption, the impact of lead time variability and the need to hedge against delays can significantly alter this behavior.
5.13. Good Points in Our Model
Model convergence: The total reward stabilizes after approximately 100 episodes, indicating that the agent has found an efficient replenishment policy.
Improved ordering decisions: The ordered quantities for each component become more consistent, avoiding excessive fluctuations observed at the beginning.
Reduction of stockouts: Despite some variations, the average stock levels tend to remain positive, meaning the agent learns to anticipate demand and delivery lead times.
Adaptation to uncertainties: The agent appears to adapt to random lead times and adjusts its orders accordingly.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}